YOLO11训练自己数据集的注意事项、技巧
首先要进行YOLO11的训练,整体流程如下篇博客
https://blog.csdn.net/wwwwww7733/article/details/149427671?spm=1001.2014.3001.5502![]() https://blog.csdn.net/wwwwww7733/article/details/149427671?spm=1001.2014.3001.5502
https://blog.csdn.net/wwwwww7733/article/details/149427671?spm=1001.2014.3001.5502
一、构建数据集
标注推荐使用X-AnyLabeling,使用教程在下面博客
https://blog.csdn.net/wwwwww7733/article/details/150265423?spm=1001.2014.3001.5502![]() https://blog.csdn.net/wwwwww7733/article/details/150265423?spm=1001.2014.3001.5502数据集要保证以下这些条件,效果才会好,效果才能得到保证
https://blog.csdn.net/wwwwww7733/article/details/150265423?spm=1001.2014.3001.5502数据集要保证以下这些条件,效果才会好,效果才能得到保证
-
样本充分:每个类别尽量保证 ≥1,500 张图像,实例数量 ≥10,000。
-
场景多样性:采集包含时间、天气、角度、设备、光照等多种变化,模拟真实部署环境。
-
标注完善:图中所有目标都必须标注,遗漏会被错误认为背景,影响训练。
-
标注准确:边框应紧贴物体,避免空隙与严重偏离。
-
负样本(背景图)引入:建议加入约 0–10% 的纯背景图,减少误检率。
-
格式统一与使用标准:使用 COCO、YOLO 等标准格式,便于工具调用与评估。
-
记得留有部分数据作测试集,这样能更直观看出每个版本模型的精度变化
数据是重中之重的,很难一次或几次标好,要一直进行循环更新
二、模型选择与预训练策略
-
从预训练权重开始:使用 COCO 上预训练的模型作为起点,收敛更快、效果更好。
-
按需选择模型大小:大模型性能更好但更慢,nano/small 适合快速实验;medium/large/xl 适合性能优先者。
-
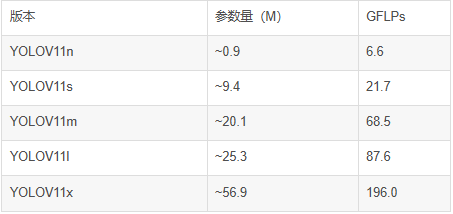
YOLO11 性能优势:与YOLOV8相比YOLO11m 在 COCO 上获得更高 mAP,参数量却减少了 22%。
-
也根据自己的数据量进行选择,小几千1-3k选择n模型就可以了
-
权衡速度与精度:在实时系统、自主存活等需求下,可选择 YOLO11n 以获得更高推理速度。
三、训练超参数
这些的基础上都是你认为你的数据标注已经很好很完美了再进行超参数调优,不然没有意义
数据标注带来的提升是巨大的
1. 建立 Baseline
-
默认配置优先:先使用默认参数训练 baseline,再对比评估其他设置。
2. 训练周期与早停机制
-
设置 Epochs 初值为 200,若未过拟合可延长训练周期至 300等。
-
启用 Early Stopping:配置
patience(例如 20),若指标无提升则提前停止训练,节省资源。
3. Learning Rate 策略
-
使用 LR 调度:通过
lrf等设置动态调整 lr,防止训练震荡或过早收敛。
4. Mixed Precision & GPU 资源优化
-
开启 AMP(amp=True),减少显存压力,加速训练。
-
使用 batch = -1 或指定比例,让系统自动选 optimal batch size,提高显存利用,使用百分之60显存。
-
启用缓存(cache 参数),减少 IO 延迟,加快数据加载。
5. 多尺度训练
-
启用
scale参数,在训练过程中随机调整图像尺寸(如 0.5~1.5 倍),提高对不同目标尺度的鲁棒性。
6. 子集训练
-
快速迭代调试:使用
fraction参数控制训练集大小(例如 10%),帮助快速排查配置问题。
7. 单目标检测
-
model.train(..., single_cls=True);只关注单个类别时,开启这个可以有效提高检测精度
作用:让模型将所有类别的目标都视为同一个类别进行学习
8. 分布式训练
-
支持多 GPU 分布式训练,加快大数据大模型训练速度。
训练启动命令
from ultralytics import YOLOmodel = YOLO('yolo11n.pt')
model.train(data='/home/boshi/AI_programming/ultralytics-main/ultralytics/cfg/datasets/coco.yaml',imgsz=960,epochs=300,batch=16,device='0',workers=8,single_cls=True,# -------- 优化器&学习率 --------optimizer='AdamW',lr0=0.002, lrf=0.05, momentum=0.92,weight_decay=0.0008,warmup_epochs=10,cos_lr=True,patience=50,# -------- 数据增强 --------mosaic=0.3, mixup=0.0, copy_paste=0.6, fliplr=0.0, flipud=0.0,hsv_h=0.01, hsv_s=0.3,hsv_v=0.2,translate=0.08,scale=0.4,shear=2,perspective=0.0,close_mosaic=30, project='runs/train/9.9water-oil2',name='water-oil-v2'
)四、提升检测效果
-
困难样本挖掘,即训练后发现哪张图片效果不好,加入到训练集中,重新训练
-
循环更新标注,标注质量非常重要