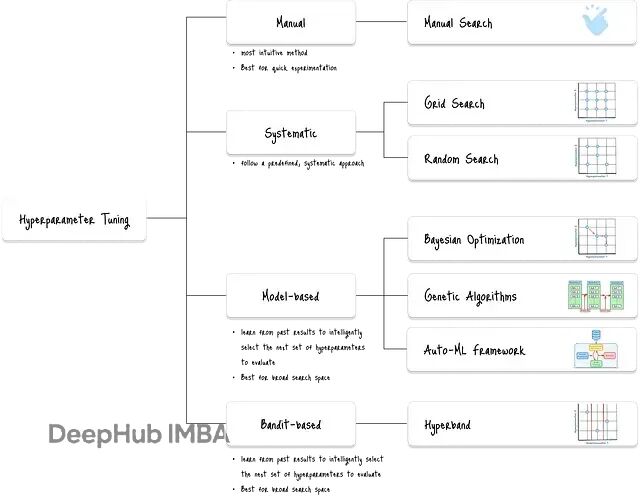
深度学习调参新思路:Hyperband早停机制提升搜索效率
Hyperband是机器学习中一个相当实用的超参数调优算法,核心思路是用逐次减半来分配计算资源。说白了就是让一堆配置先跑几轮,表现差的直接踢掉,剩下的继续训练更多轮次。
这个方法的巧妙之处在于平衡了探索和利用。你既要试足够多的配置组合(探索),又要给有潜力的配置足够的训练时间(利用)。传统方法要么试得不够多,要么每个都试要很久浪费时间。
本文我们来通过调优一个lstm来展示Hyperband的工作机制,并和贝叶斯优化、随机搜索、遗传算法做了对比。结果挺有意思的。
Hyperband的工作原理
Hyperband结合了多臂老虎机策略和逐次减半算法(SHA)。多臂老虎机问题其实就是在探索新选择和利用已知好选择之间做权衡。
SHA则是具体的资源分配策略如下:给随机采样的配置分配固定预算(比如训练轮数),每轮评估后踢掉表现最差的,把剩余预算分给剩下的。Hyperband更进一步,用不同的初始预算跑多次SHA,这样既能快速筛选,又不会遗漏那些需要长时间训练才能显现优势的配置。
相比其他调优方法,Hyperband在处理大搜索空间时速度和效率优势明显。
下图展示了Hyperband如何逐步给获胜配置(#4)分配更多资源,虽然最开始的预算分配是随机的:
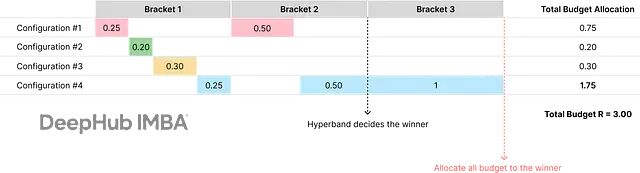
Hyperband工作流程
整个过程从Bracket 1开始,创建很多超参数配置,每个分配少量预算。然后逐步减少配置数量,同时增加幸存者的预算。到了Bracket 2,只给Bracket 1的幸存者(配置#1和#4)更多预算。最终在Bracket 3把全部预算给最优配置#4。
这种做法能有效探索广泛配置范围,同时快速淘汰表现差的,在探索和利用间找到平衡。
算法的四个关键步骤
定义预算和减半因子
首先要定义最大资源预算R(单个模型能训练的总轮数)和减半因子η(决定淘汰激进程度的预设因子)。减半因子常用2、3或4。每步都用η来减少配置数量,用η来增加幸存者预算。
计算Bracket数量
算法跑一系列bracket,每个bracket是用不同起始预算的完整SHA运行。最大bracket索引s_max的计算公式是:
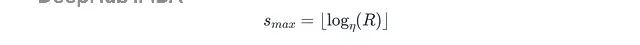
其中η是减半因子,R是最大资源预算。算法从s_max个bracket迭代到零。
运行逐次减半
对每个bracket s,Hyperband确定起始的超参数配置数量n_s。有意思的是,初始预算小的bracket配置数量大,初始预算大的bracket配置数量小。
配置数量的数学定义:
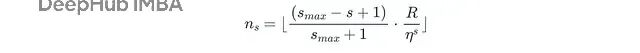
其中n_s是当前bracket要评估的配置数量,R是最大资源预算,η是减半因子,s_max是最大bracket数,s是当前bracket索引。
每个bracket的初始预算r_s计算公式:
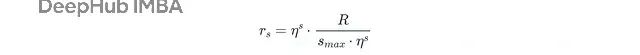
Hyperband先采样n_s个随机超参数配置,用初始预算r_s轮训练每个。然后根据性能选出前n_s/η个配置。这些"幸存者"继续训练更多轮,总共r_s⋅η轮。
这个减半候选数量、增加预算的过程持续进行,直到bracket中只剩一个配置或达到最大预算。
选择最终配置
所有bracket跑完后,选择表现最好的配置作为最终结果。Hyperband的效率就来自快速丢弃表现差的配置,把资源用来训练更有前景的配置。
演示:支持向量分类器
我们用SVC来演示具体工作过程,调优正则化参数C和核系数gamma。
搜索空间:C取[0.1, 1, 10, 100],gamma取[‘scale’, ‘auto’, 0.1, 1, 10]
设置最大预算R = 81,减半因子η = 3。
最大bracket索引计算得出:
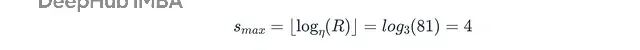
所以Hyperband会为s = 4, 3, 2, 1, 0运行bracket。每个bracket有不同的起始配置数量和初始预算:
- Bracket 1 (s = 4):1个配置,初始预算9
- Bracket 2 (s = 3):3个配置,初始预算3
- Bracket 3 (s = 2):9个配置,初始预算1
- Bracket 4 (s = 1):27个配置,初始预算1/3
- Bracket 5 (s = 0):81个配置,初始预算1/9
以Bracket 3为例说明SHA过程:
初始运行时,Hyperband随机采样9个超参数配置,用1轮小预算训练每个,记录性能,保留前3个最佳配置丢弃其余6个。
第二轮,3个幸存者用3轮更大预算训练,保留前1个最佳配置。
最终轮,剩余配置用9轮最终预算训练,记录最终性能。
总预算R = 81就这样分布在各个bracket中,高效找到最佳配置。
实际用例:LSTM股价预测实验
我们用更复杂的LSTM网络来验证Hyperband效果,目标是预测NV股票收盘价。
从Alpha Vantage API获取历史日线数据,加载到Pandas DataFrame并预处理。训练集用于模型训练和验证,测试集单独保存避免数据泄漏。
import torch
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer # create target and input vals
target_col = 'close'
y = df.copy()[target_col].shift(-1) # avoid data leakage
y = y.iloc[:-1] # drop the last row (as y = nan) input_cols = [col for col in df.columns if col not in [target_col, 'dt']] # drop dt as year, month, date can capture sequence
X = df.copy()[input_cols]
X = X.iloc[:-1] # drop the last row # create trainning and test dataset (trianing will split into train and val for wfv)
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=800, shuffle=False, random_state=42
) # preprocess
cat_cols = ['year', 'month', 'date']
num_cols = list(set(input_cols) - set(cat_cols))
preprocessor = ColumnTransformer( transformers=[ ('num', StandardScaler(), num_cols), ('cat', OneHotEncoder(handle_unknown='ignore'), cat_cols) ]
)
X_train = preprocessor.fit_transform(X_train)
X_test = preprocessor.transform(X_test) # convert the dense numpy arrays to pytorch tensors
X_train = torch.from_numpy(X_train.toarray()).float()
y_train = torch.from_numpy(y_train.values).float().unsqueeze(1)
X_test = torch.from_numpy(X_test.toarray()).float() y_test = torch.from_numpy(y_test.values).float().unsqueeze(1)
原始数据包含6,501个NV历史股价记录样本:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6501 entries, 0 to 6500
Data columns (total 15 columns): # Column Non-Null Count Dtype
--- ------ -------------- ----- 0 dt 6501 non-null datetime64[ns] 1 open 6501 non-null float32 2 high 6501 non-null float32 3 low 6501 non-null float32 4 close 6501 non-null float32 5 volume 6501 non-null int32 6 ave_open 6501 non-null float32 7 ave_high 6501 non-null float32 8 ave_low 6501 non-null float32 9 ave_close 6501 non-null float32 10 total_volume 6501 non-null int32 11 30_day_ma_close 6501 non-null float32 12 year 6501 non-null object 13 month 6501 non-null object 14 date 6501 non-null object
dtypes: datetime64[ns](1), float32(9), int32(2), object(3) memory usage: 482.6+ KB
基于多对一架构在PyTorch上定义LSTMModel类:
import torch
import torch.nn as nn class LSTMModel(nn.Module): def __init__(self, input_dim, hidden_dim, layer_dim, output_dim, dropout): super(LSTMModel, self).__init__() self.hidden_dim = hidden_dim self.layer_dim = layer_dim self.dropout = dropout self.lstm = nn.LSTM( input_dim, hidden_dim, layer_dim, batch_first=True, dropout=dropout ) self.fc = nn.Linear(hidden_dim, output_dim) def forward(self, x): h0 = torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).to(x.device) c0 = torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).to(x.device) o_t, _ = self.lstm(x, (h0.detach(), c0.detach())) o_final = self.fc(o_t[:, -1, :]) return o_final
Hyperband在更广搜索空间中表现更好,定义以下搜索空间:
import random def search_space(): return { 'lr': 10**random.uniform(-6, -1), 'hidden_dim': random.choice([16, 32, 64, 128, 256]), 'layer_dim': random.choice([1, 2, 3, 4, 5]), 'dropout': random.uniform(0.1, 0.6), 'batch_size': random.choice([16, 32, 64, 128, 256]) }
为时间序列数据定义滑动窗口验证的train_and_val_wfv函数:
def train_and_val_wfv(hyperparams, budget, X, y, train_window, val_window): total_val_loss = 0 all_loss_histories = [] num_folds = (X.size(0) - train_window - val_window) // val_window + 1 for i in range(num_folds): train_start = i * val_window train_end = train_start + train_window val_start = train_end val_end = val_start + val_window # ensure not to go past the end of the dataset if val_end > X.size(0): break # create folds X_train_fold = X[train_start:train_end] y_train_fold = y[train_start:train_end] X_val_fold = X[val_start:val_end] y_val_fold = y[val_start:val_end] # train and validate on the current fold fold_val_loss, fold_loss_history = train_and_val( hyperparams=hyperparams, budget=budget, X_train=X_train_fold, y_train=y_train_fold, X_val=X_val_fold, y_val=y_val_fold ) total_val_loss += fold_val_loss all_loss_histories.append(fold_loss_history) # compute ave. loss avg_val_loss = total_val_loss / num_folds return avg_val_loss, all_loss_histories
run_hyperband函数接受搜索空间函数、验证函数、总预算R和减半因子eta四个参数。代码中R设为100,eta为3,滑动窗口交叉验证的训练和验证窗口分别为3,000和500。
def run_hyperband(search_space_fn, val_fn, R, eta): s_max = int(log(R, eta)) overall_best_config = None overall_best_loss = float('inf') all_loss_histories = [] # outer loop: iterate through all brackets for s in range(s_max, -1, -1): n = int(R / eta**s) r = int(R / n) main_logger.info(f'... running bracket s={s}: {n} configurations, initial budget={r} ...') # geerate n random hyperparameter configurations configs = [get_hparams_fn() for _ in range(n)] # successive halving for i in range(s + 1): budget = r * (eta**i) main_logger.info(f'... training {len(configs)} configurations for budget {budget} epochs ...') evaluated_results = [] for config in configs: loss, loss_history = train_val_fn(config, budget) evaluated_results.append((config, loss, loss_history)) # record loss histories for plotting all_loss_histories.append((evaluated_results, budget)) # sort and select top configurations evaluated_results.sort(key=lambda x: x[1]) # keep track of the best configuration found so far if evaluated_results and evaluated_results[0][1] < overall_best_loss: overall_best_loss = evaluated_results[0][1] overall_best_config = evaluated_results[0][0] num_to_keep = floor(len(configs) / eta) configs = [result[0] for result in evaluated_results[:num_to_keep]] if not configs: break return overall_best_config, overall_best_loss, all_loss_histories, s_max # define budget, halving factor
R = 100
eta = 3 # wfv setting
train_window = 3000
val_window = 500 # run sha
best_config, best_loss, all_loss_histories, s_max = run_hyperband( search_space_fn=search_space, val_fn=lambda h, b: train_and_val_wfv(h, b, X_train, y_train, train_window=train_window, val_window=val_window), R=R, eta=eta )
实验结果
最佳超参数配置:
- lr: 0.0001614172022855225
- hidden_dim: 128
- layer_dim: 3
- dropout: 0.5825758700895215
- batch_size: 16
最佳验证损失(MSE):0.0519
下图的实线跟踪训练过程中的平均验证损失,垂直虚线表示Hyperband算法修剪表现差模型的时点:
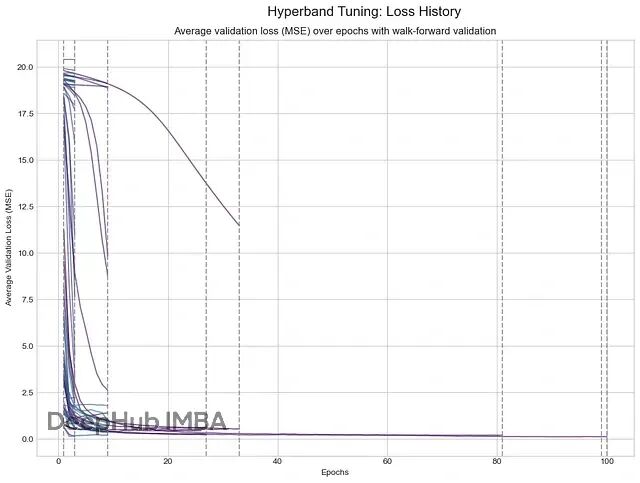
早期停止的线条(主要是紫色)是表现差的配置,因损失过高被修剪掉。少数持续到100轮的线条(主要是青绿色和蓝色)是最成功的配置,损失开始时快速下降然后稳定在很低值,说明性能优异。这就是Hyperband的高效之处:快速淘汰差配置,不用浪费时间长期训练它们。
与其他调优方法的对比
为了客观比较,这里用相同搜索空间、模型和训练验证窗口,对贝叶斯优化、随机搜索、遗传算法各跑了20次试验。
贝叶斯优化
贝叶斯优化用概率模型(如高斯过程)建模验证误差,选择下一个最优超参数配置评估。
最佳配置:lr 0.00016768631941614767, hidden_dim 256, layer_dim 3, dropout 0.3932769195043036, batch_size 64
最佳验证损失(MSE):0.0428
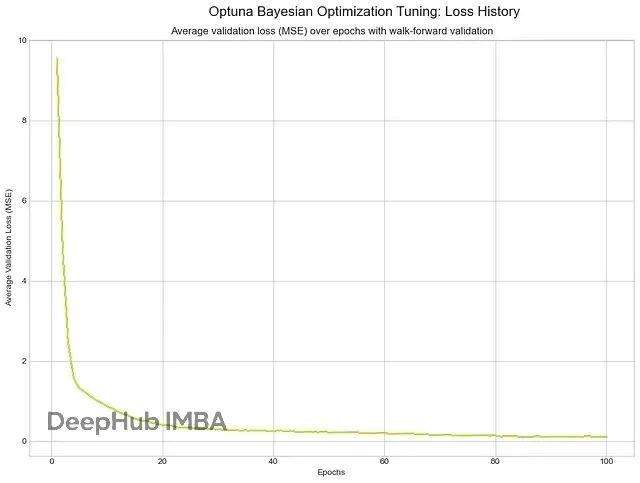
贝叶斯优化损失历史
随机搜索
随机搜索从搜索空间随机采样固定数量配置,不利用过去试验结果。
最佳配置:lr 0.0004941205117774383, hidden_dim 128, layer_dim 2, dropout 0.3398469430820351, batch_size 64
最佳验证损失(MSE):0.03620
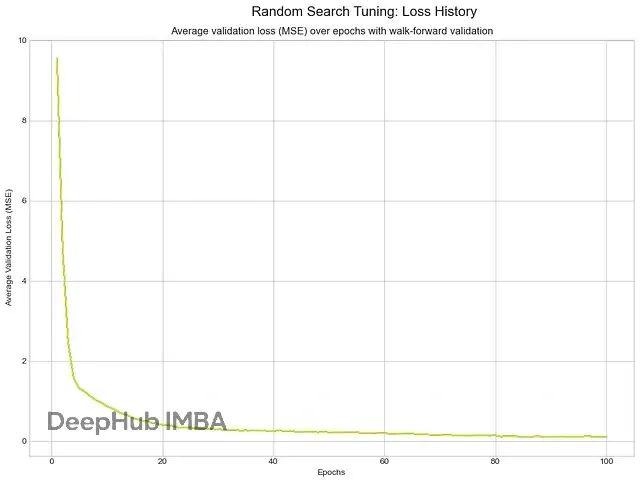
随机搜索损失历史
遗传算法
受生物进化启发,遗传算法维护超参数配置群体,用变异和交叉概念生成新的潜在更优配置。
最佳配置:lr 0.006441170552290832, hidden_dim 128, layer_dim 3, dropout 0.2052570911345997, batch_size 128
最佳验证损失(MSE):0.1321
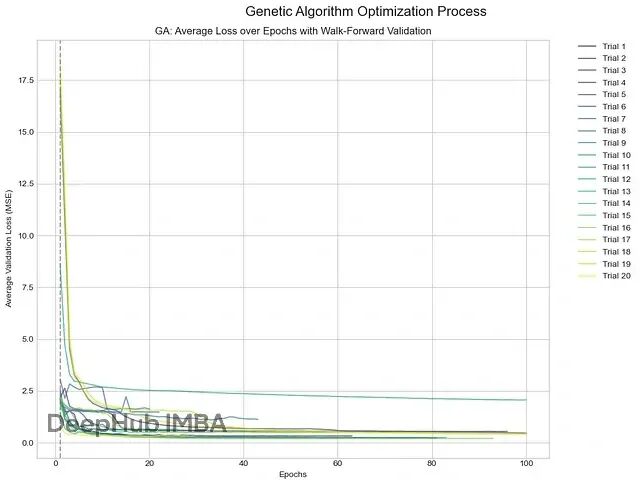
遗传算法损失历史
结果分析
有意思的是,随机搜索(0.0362)和贝叶斯优化(0.0428)在最终验证损失上略优于Hyperband(0.0519)。这说明效率和找到全局最优间存在权衡。
Hyperband的效率来自早期积极修剪表现差配置,这样能节省大量时间,但风险是可能意外淘汰"大器晚成"的配置,也就是那些需要长时间训练才能显现优势的配置。
在这个案例中,随机搜索和贝叶斯优化更成功。随机搜索给每个模型完整训练预算,让高性能配置达到全部潜力。贝叶斯优化的智能搜索在找最佳超参数集方面也比Hyperband的早停方法更有效。
改进Hyperband性能的策略
想要改善Hyperband性能,可以调整其参数或与其他调优方法结合。
调整关键参数方面,设置大的R(总预算)能让更多"大器晚成"模型证明价值,减少过早修剪好配置的机会。设置小的eta(减半因子)允许更温和的修剪过程,让更多配置进入下一bracket(eta=3丢弃三个配置,eta=1只丢弃一个)。
而更有前景的是将Hyperband与贝叶斯优化结合。BOHB(Bayesian Optimization and HyperBand)是这样的混合方法,用Hyperband的逐次减半作框架,但用贝叶斯优化的概率模型替换随机采样。BOHB用贝叶斯优化选择最有前景的候选者输入Hyperband的bracket中。
这种方法结合了两者优点:Hyperband的快速结果加上贝叶斯优化的强最终性能。
总结
Hyperband是个挺实用的超参数优化算法,能有效平衡广泛搜索空间的探索和有前景配置的利用。其快速修剪差配置的能力使其比传统网格搜索和随机搜索明显更快更可扩展。
虽然贝叶斯优化等方法可能在样本效率上更高,但Hyperband的简单性和可并行性让它成为很多机器学习任务的有力选择,特别是训练成本昂贵时。
还是那句话没有银弹。选择哪种调优方法还得看具体场景:如果你有足够计算资源且更在乎最终性能,贝叶斯优化可能更合适;如果你需要快速得到不错结果,Hyperband是个好选择;如果预算有限,随机搜索也不失为简单有效的baseline。
关键是理解每种方法的权衡,根据实际需求做选择。
https://avoid.overfit.cn/post/08d708548fdd4c19b4d9ff7973e9e612
作者:Kuriko IWAI