Python中ORM的理解
一、Python ORM 的核心定位:连接对象与关系的 “Python 式桥梁”
Python ORM 是适配 Python 语法特性的 “对象 - 关系映射” 技术,其核心使命是解决Python 面向对象编程(OOP) 与关系型数据库(RDB) 之间的 “范式差异”:在 Python 中,数据以 “实例对象”“列表”“字典” 等形式存在;而在数据库中,数据以 “表”“行”“列” 的结构化形式存储。
Python ORM 通过建立 “类 - 表”“实例属性 - 表字段”“对象关联 - 表关系” 的映射关系,让开发者无需关注 SQL 语法,直接用 Python 原生语法(如创建实例、调用方法、属性赋值)完成数据库的 CRUD 操作。
Python ORM 的核心价值
a.契合 Python 开发习惯:遵循 “简洁优雅” 的 Python 哲学,用最少的代码实现数据库操作,例如用User(name="Alice")替代INSERT INTO user (name) VALUES ('Alice')。
b.降低开发门槛:对不熟悉 SQL 的 Python 开发者,只需掌握 OOP 语法即可操作数据库;对熟悉 SQL 的开发者,也可通过 “原生 SQL 接口” 灵活扩展。
c.提升代码可维护性:将数据库逻辑与业务逻辑分离,当数据库类型(如从 MySQL 切换到 PostgreSQL)变更时,仅需修改 ORM 配置,无需改动业务代码。
d.保障数据安全:默认支持 “参数化查询”,自动过滤特殊字符,从根源避免 SQL 注入攻击(无需手动处理字符串拼接风险)。
e.生态无缝集成:与 Python 主流 Web 框架(Django、Flask、FastAPI)深度兼容,开箱即用。
二、Python ORM 的工作原理
1. 映射配置:定义 “Python 类 - 数据库表” 的对应关系
这是 ORM 工作的基础,Python ORM 通常通过 “类属性注解”“类继承” 或 “代码约定”(如类名小写即为表名)定义映射关系,核心配置包括:
- 类与表映射:Python 的User类对应数据库的user表(默认遵循 “蛇形命名法”,可手动指定表名);
- 属性与字段映射:User类的id属性对应user表的id字段,支持自动类型转换(如 Python 的datetime.datetime对应 MySQL 的datetime);
- 主键映射:指定主键字段及生成策略(自增、UUID、默认值等);
- 关联关系映射:定义表之间的 “一对一”“一对多”“多对多” 关系(如User的orders属性对应order表的user_id外键)

2. 对象操作:用 Python 语法发起数据库请求
开发者通过 ORM 提供的 API,以 “操作 Python 对象” 的方式发起数据库操作,完全无需编写 SQL。常见操作如下:
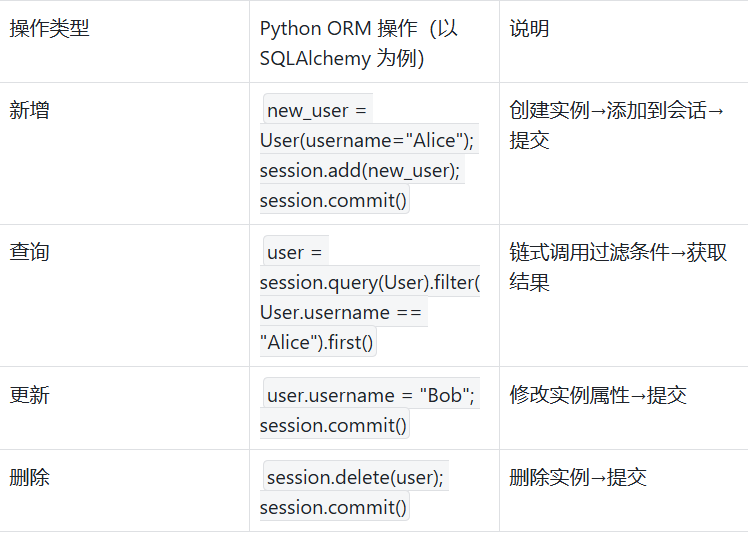
3. SQL 生成:ORM 自动转化为原生 SQL
Python ORM 会根据 “映射配置” 和 “对象操作类型”,自动生成符合数据库语法的原生 SQL。例如:
当执行session.add(User(username="Alice"))并提交时,SQLAlchemy 生成:

当执行session.query(User).filter(User.id == 1)时,生成:

当执行关联查询session.query(User).join(Order).filter(Order.amount > 100)时,生成:

4. 结果映射:SQL 执行结果转化为 Python 对象
数据库返回的查询结果是 “结构化行数据”(如 SQLite 的Row对象),ORM 会根据映射配置自动将其转化为 Python 开发者熟悉的 “实例对象” 或 “对象列表”。例如:
- 执行user = session.query(User).first()后,返回的user是User类的实例,可直接通过user.username访问字段值;
- 执行users = session.query(User).all()后,返回的users是User实例的列表,可通过循环遍历for u in users: print(u.id)处理数据。
三.基础操作
1. 导入必要包
from sqlalchemy import create_engine, Column, Integer, String, UniqueConstraintfrom sqlalchemy.orm import declarative_base, sessionmaker
- create_engine:创建数据库连接引擎
- Column, Integer, String:定义表字段类型
- UniqueConstraint:定义唯一约束
- declarative_base:创建ORM基类
- sessionmaker:创建会话工厂
2. 创建数据库连接(Engine)
engine = create_engine('sqlite:///provinces.db', echo=True)
- 作用:创建一个数据库连接引擎,告诉 SQLAlchemy 你要连接哪个数据库。
- 这里用的是 SQLite,数据库文件名是 provinces.db,如果文件不存在会自动创建。
- engine 是 SQLAlchemy 连接数据库的核心对象,负责管理数据库连接池。
- echo=True 打印执行的SQL,方便调试(可以不加)
3. 定义基类
Base = declarative_base()
- Base 是所有 ORM 模型的基类,所有你定义的映射类(模型)都必须继承它。
- 作用:它维护了模型类和数据库表之间的映射关系,以及元数据(metadata)。
- metadata 是 SQLAlchemy 用来保存数据库结构信息的对象,比如表名、字段、约束等。
4.定义模型(映射省份表)

- 定义一个 ORM 模型 Province,映射到数据库里的 province 表。
- id 是主键且有索引,name 和 code 都是唯一且不能为空的字符串字段。
- 通过模型,你可以用 Python 对象操作数据库表。
5. 创建数据表
Base.metadata.create_all(engine)
- metadata:是 Base 维护的数据库结构信息集合,包含所有继承了 Base 的模型定义。
- create_all(engine) 的作用是根据 metadata 中定义的模型,自动在数据库中创建对应的表。
- 这里的 engine 是连接数据库的引擎,告诉 metadata 具体在哪个数据库执行创建操作。
- 为什么用 Base.metadata? 因为所有模型都继承自 Base,它集中管理了所有模型的表结构。