java后端工程师进修ing(研一版 || day41)
今日总结
- java随征录——kafka消息中间件(依赖zoopkeeper版)
- 科研随探录——cv(学完kafka开始科研)
- 八股随笔录——MySQL面试篇(5/7)
- 代码随想录——二叉搜索树中的插入操作
详细内容
java随征录
线程与线程之间的数据交互
各线程的栈内存可以通过堆内存实现数据的交互,不需要其他的消息中间件
进程与进程之间的数据交互
由于进程与进程之间申请的内存是不一样的,每个进程的空间是独立的,所以不能通过内存来共享
二者存在的问题
1.当发送方的发送速率大于接收方,消息就会发生内存积压问题
2.发送方无法选择性发送给指定接收方的消息,缺少灵活性
综上,在分布式开发中,消息中间件(缓冲区)应用而生
JMS(java消息服务)
- P2P(点对点模型)
- PS模型(发布/订阅模型)
kafka消息中间件(依赖zoopkeeper版)
他是一个高吞吐量的分布式发布-订阅消息系统,可以在多个系统之间高效的传送大量数据。同时,支持消息以磁盘日志的方式持久化存储,保证数据不丢失。
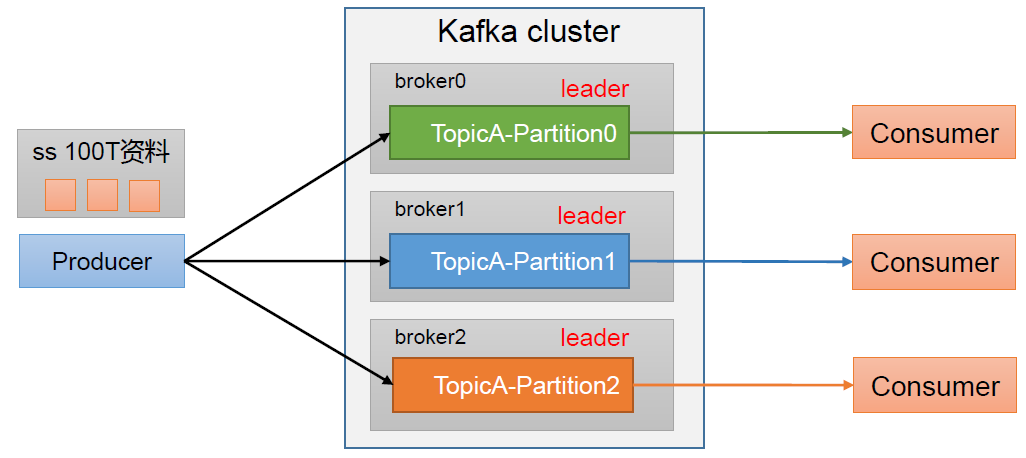
kafka的使用
- 安装kafka前,需要确保java环境是否已经安装,kafka是基于java开发的
- 下载好后,需要解压文件,修改properties配置文件,设置kafka服务参数,也要配置与zookeeper集群的连接
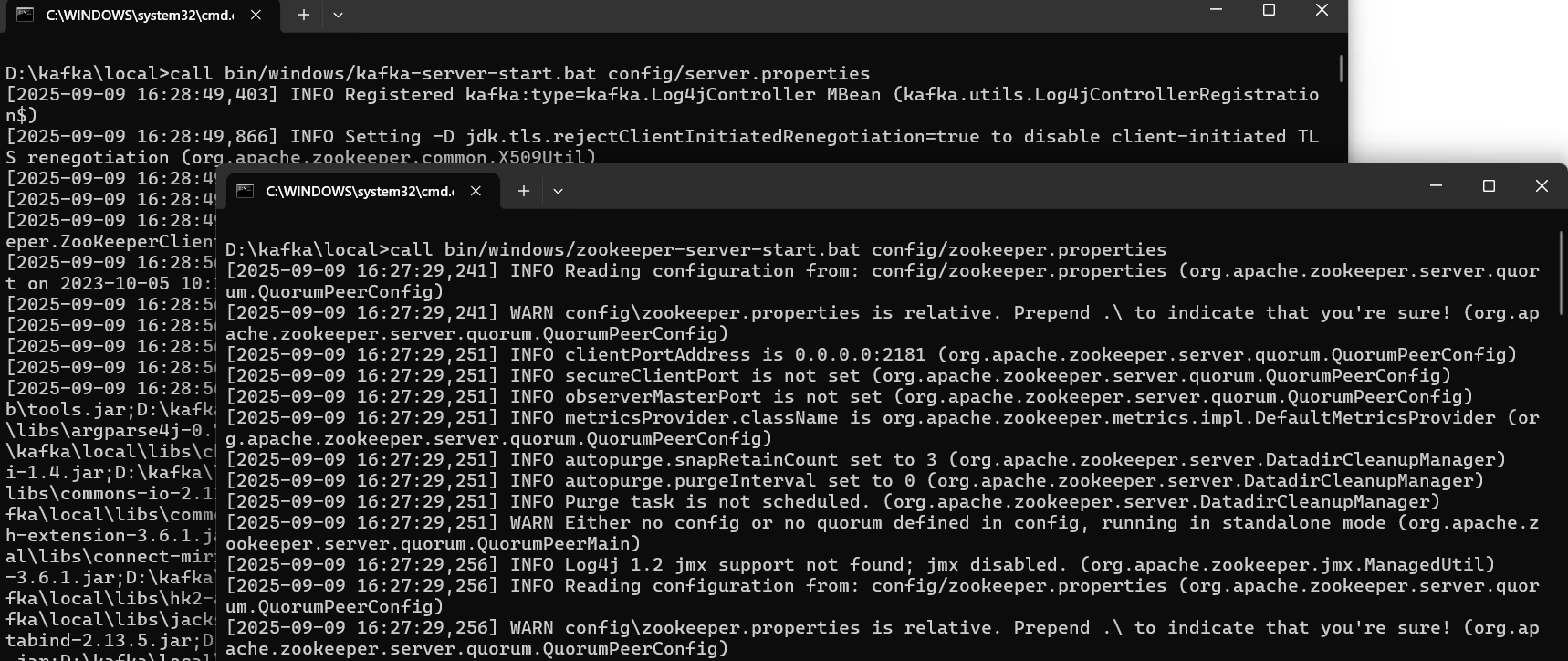
- 在启动kafka前,实现要先启动zookeeper,在启动kafka。(命令如下)注意:启动成功后,会生成一份zookeeper的主题信息文件和kafka的日志文件
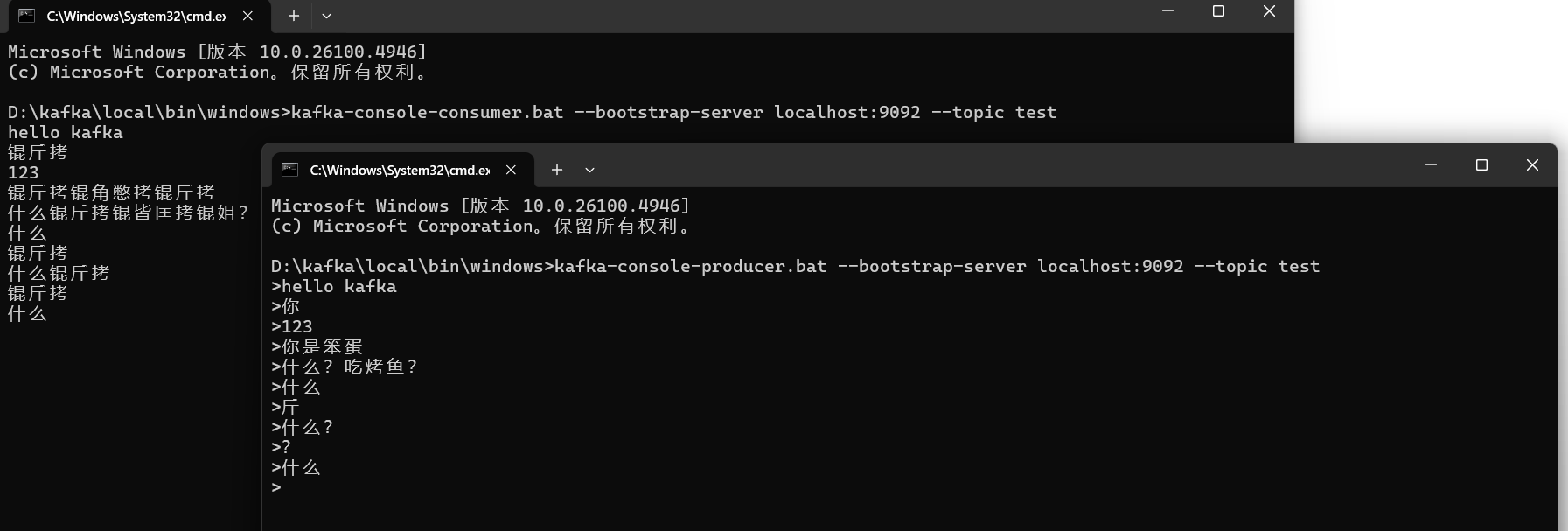
4. 之后在启动bin/windows目录下的生产者和消费者的批处理文件。便可通过kafka传递信息。如下(中文乱码)
科研随探录
八股随笔录
- 查询数据时,到了B+树的叶子节点,之后的查找数据是如何做的?
数据页中有一个页目录(存储每组最后一条记录的地址偏移量,地址偏移量也被称为槽),起到记录索引作用。因为记录是按照主键值从小到大的顺序排序的。因此通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽,定位到槽后,在找对应的记录。
- B+树的特性是什么?
1,在B+树中,数据都存储在叶子节点上,非叶子节点只存储索引信息;而B树的非叶子节点存储索引信息也存储部分数据
2,B+树的叶子节点使用链表相连,便于范围查询和顺序访问。B树的叶子节点没有链表连接
3,B+树的查找性能更稳定,每次查找都到叶子节点;而B树的查找可能在非叶子节点找到数据,性能不稳定。
代码随想录
给定二叉搜索树(BST)的根节点 root 和要插入树中的值 value ,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。
注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回 任意有效的结果 。
示例 :
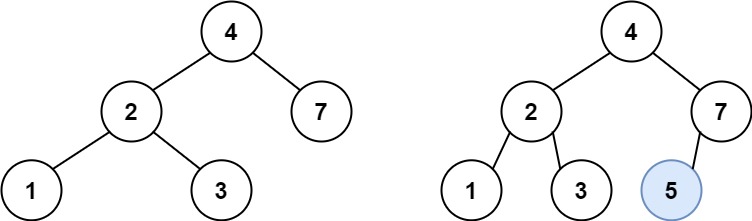
输入:root = [4,2,7,1,3], val = 5 输出:[4,2,7,1,3,5] 解释:另一个满足题目要求可以通过的树是:
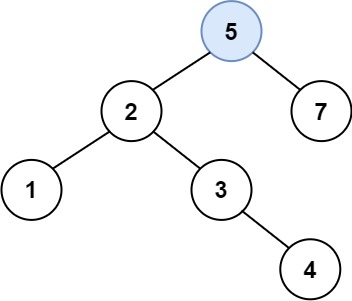
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public TreeNode insertIntoBST(TreeNode root, int val) {if(root == null) {return new TreeNode(val);}if(root.val > val) {root.left = insertIntoBST(root.left, val);}if(root.val < val) {root.right = insertIntoBST(root.right,val);}return root;}
}