【项目】在AUTODL上使用langchain实现《红楼梦》知识图谱和RAG混合检索(二)RAG部分
RAG主要是为了解决大模型的幻觉问题,步骤如下:
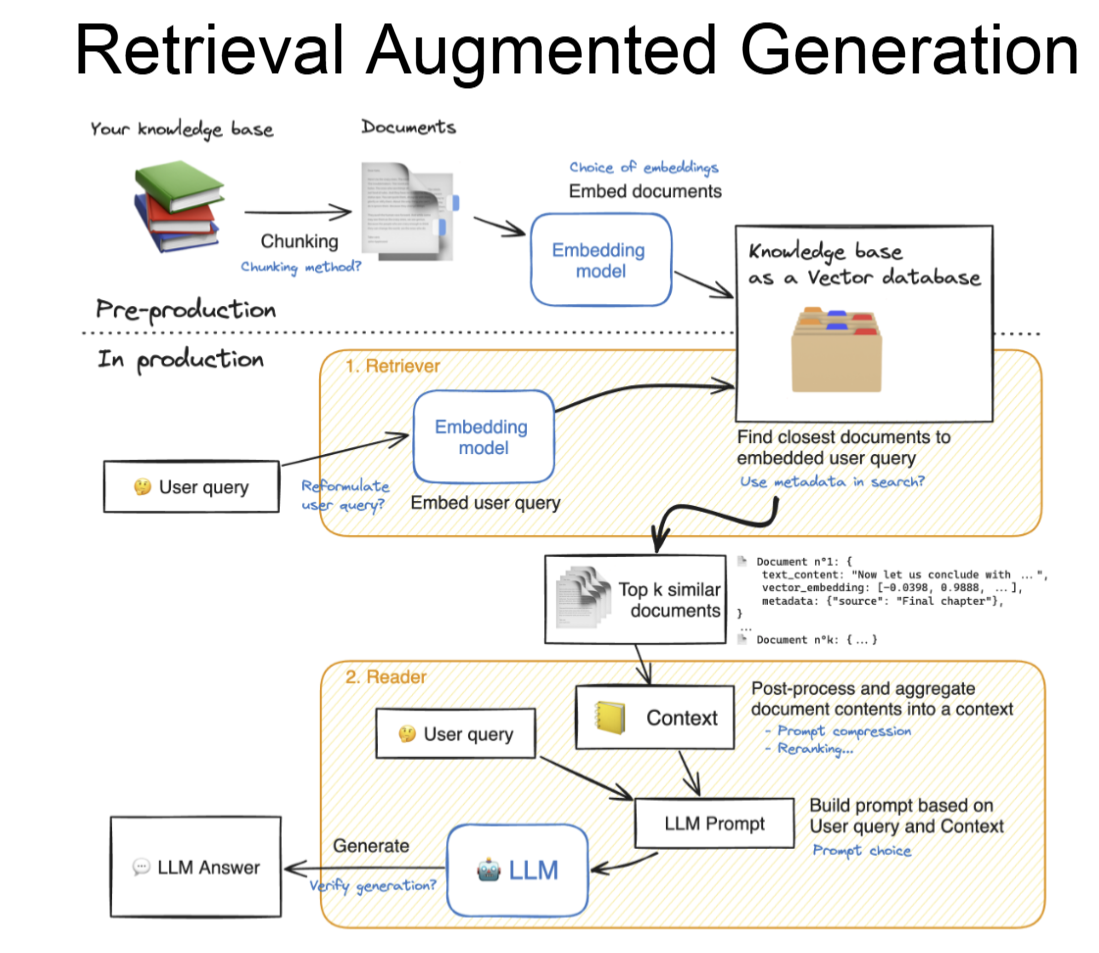
导入文件并切片
from langchain.document_loaders import TextLoader
loader=TextLoader('/root/hong.txt',encoding="utf-8")
documents=loader.load()
from langchain.text_splitter import CharacterTextSplitter,RecursiveCharacterTextSplitter
text_splitter=RecursiveCharacterTextSplitter(chunk_size=128,chunk_overlap=50,separators=["\n\n","\n","。","!","?","//"])#分割优先级列表
texts=text_splitter.create_documents([documents[0].page_content],metadatas=[documents[0].metadata])
texts导入向量模型,将切片变成嵌入向量
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain.vectorstores import Chroma
from modelscope import snapshot_download
model_path=snapshot_download("AI-ModelScope/m3e-base", revision='master')
model_kwargs={'device':'cuda'}
encode_kwargs={'normalize_embeddings':True}#标准化嵌入向量
embedding=HuggingFaceBgeEmbeddings(model_name=model_path,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs,query_instruction='为文本生成向量表示用于文本检索'
)导入向量数据库
db=Chroma.from_documents(documents,embedding)
db.similarity_search('贾宝玉前身是什么')导包
from langchain_core.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough,RunnableWithMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain.prompts.chat import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda定义链,并添加多轮对话的记忆能力
llm=ChatOpenAI(model=your model,temperature=0,max_tokens=None,max_retries=2,api_key=your key,base_url=your url
)
retriever=db.as_retriever()
#将向量数据库封装为一个 Retriever 对象,可以执行语义搜索,返回最相关的文档片段。#提示词模板(历史+上下文)
prompt=ChatPromptTemplate.from_messages([('system','你是一个《红楼梦》知识助手。请根据上下文回答问题:\n\n{context}'),MessagesPlaceholder(variable_name='chat_history'),# 历史消息占位符('human','{question}')
])#定义检索函数
def format_docs(docs):return '\n\n'.join(doc.page_content for doc in docs)
#将检索到的多个文档内容拼接成一个字符串,用两个换行符 \n\n 分隔。def add_context(input_dict):question=input_dict['question']docs=retriever.invoke(question)context=format_docs(docs)return {**input_dict,'context':context}
#接收一个包含问题的字典,检索相关文档,添加上下文,返回增强后的字典。contextualize_q_chain=RunnableLambda(add_context)
#将普通的 Python 函数 add_context 包装成一个 LangChain 的 Runnable,使其可以参与 LangChain 的链式调用(pipeline)
#我们之前定义的函数:接收 {'question': ...},检索相关文档,添加 'context' 字段。输出:{'question': '...', 'context': '...'}#定义最终的链
rag_chain=contextualize_q_chain | prompt | llm | StrOutputParser()#prompt会把 context 和 question(以及后面的 chat_history)填充进模板,生成一个格式化的提示词。
#StrOutputParser()将 LLM 输出的 AIMessage 对象解析为纯字符串(str)。#管理消息历史(多轮会话)
store={}
#定义一个全局字典 store,用于持久化保存每个会话的历史消息
def get_session_history(session_id:str)-> BaseChatMessageHistory:if session_id not in store:store[session_id]=ChatMessageHistory()return store[session_id]
#这是一个回调函数,LangChain 用它来获取指定会话的历史消息。with_message_history=RunnableWithMessageHistory(rag_chain,get_session_history,input_messages_key='question',history_messages_key='chat_history'
)
#RunnableWithMessageHistory 是 LangChain 提供的一个包装器,为普通的 chain 添加对话历史管理能力。config={'configurable':{'session_id':'abc123'}}# #使用 from_llm 快捷方法构建一个带检索功能的对话链。
# response=with_message_history.invoke(
# {'question':'贾宝玉前身是什么?'},
# config=config
# )
# #调用链,传入问题。
# print(response)