【Pandas】3.2-数据预处理:行的基本操作
对于结构化数据,每一行代表了一个具体样本(比如每个用户的年龄、身高等),不同的列则是每个样本相应的某种特征(年龄列、身高列等)。
因此当使用Pandas处理和分析数据时,通常列的执行频次会高于行相关的操作:比如对列求均值才有实际含义,返回的结果代表了年龄的均值、身高的均值等;而对行求均值会将不同量纲的年龄与身高代入计算,得到的结果并没有意义。
所以Pandas中对行的高频操作可能较少,根据博主自己的实践经验,在此初步总结为下面2种行的常用基本操作,分别是
- 行索引的修改
- 行的删除
首先模拟一份数据集,年龄中有负数便于演示删除操作
import numpy as np
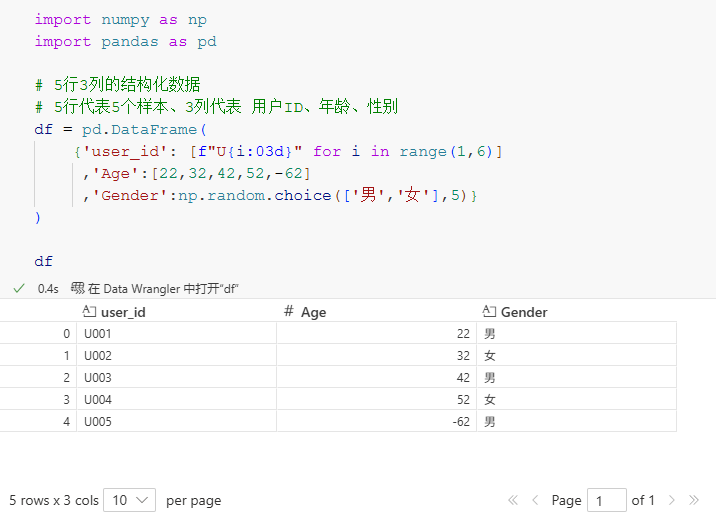
import pandas as pd# 5行3列的结构化数据
# 5行代表5个样本、3列代表 用户ID、年龄、性别
df = pd.DataFrame({'user_id': [f"U{i:03d}" for i in range(1,6)],'Age':[22,32,42,52,-62],'Gender':np.random.choice(['男','女'],5)}
)df
1-行索引的修改
(1)-手动设置行索引 — set_index()方法
DataFrame的行索引/index默认是根据行的实际物理位置,生成的类似np.range(df.shape[0)的等差数列,但有时可能会需要将原始数据中具有特殊意义的字段设为行索引,比如用户ID、特殊的时间戳等。
对此Pandas提供了 set_index()方法,其主要参数为:
df.set_index(# key: 指定为行索引的列名col_namekeys='col_name'# 将 col_name 列设为行索引后,在原始数据中是否删除该列?# drop默认为True:True代表删除;False代表保留,drop=True/False# 是否修改原始数据# inplace默认为False,不修改原始数据,inplace=False/True
)
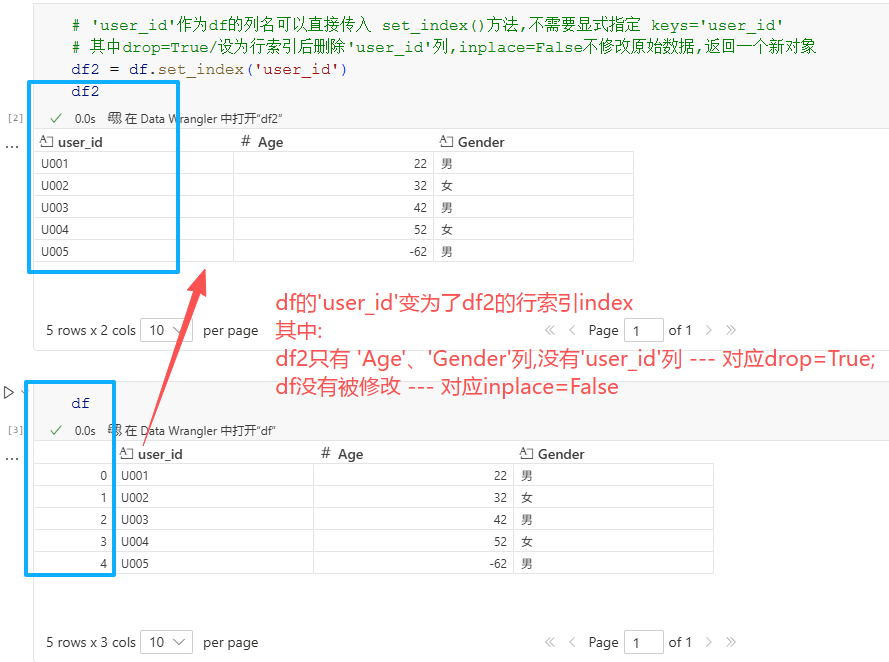
如果需要将df的 'user_id’列设为行索引,代码与结果如下:
# 'user_id'作为df的列名可以直接传入 set_index()方法,不需要显式指定 keys='user_id'
# 其中drop=True/设为行索引后删除'user_id'列,inplace=False不修改原始数据,返回一个新对象
df2 = df.set_index('user_id')
df2
(2)-还原为默认索引 — reset_index()方法
如果在手动设置行索引后发现对分析没有帮助,需要恢复为原始索引时,Pandas提供了reset_index()方法,其主要参数如下:
df.reset_index(# 假设现在的行索引是: col_at_index 列# 再将行索引还原为默认索引后,是否要删除 col_at_index 列# 默认drop=False,会将 col_at_index 列重新添加到 原始数据中# drop=True,则会删除 col_at_index 列drop=False/True# 是否修改原始数据# inplace默认为False,不修改原始数据,inplace=False/True
)
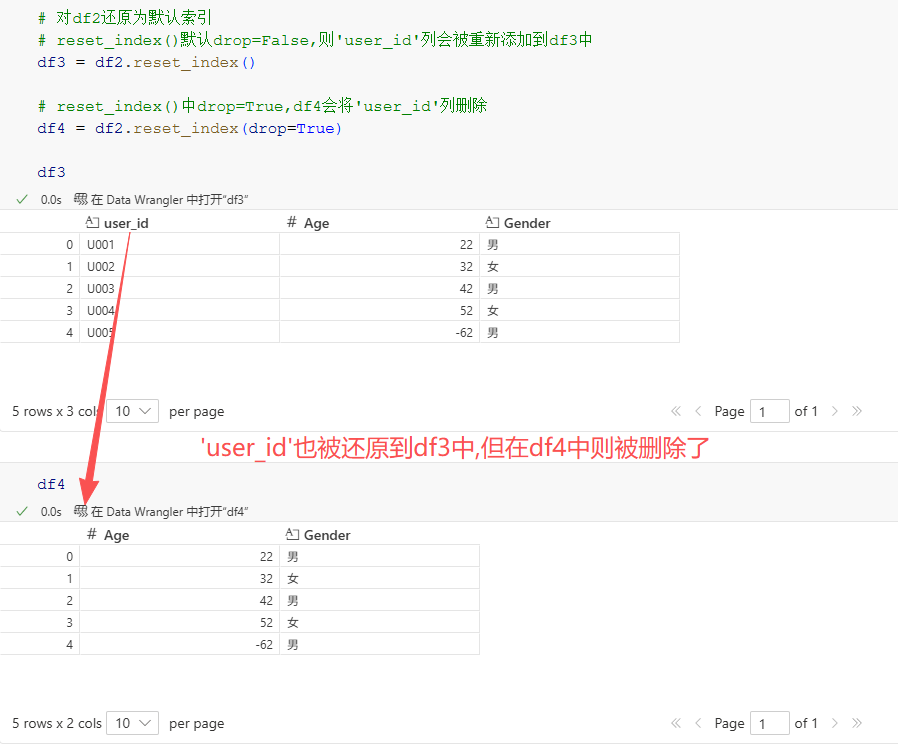
下面展示了将df2还原为默认索引时,drop=False/True的结果对比,代码与结果如下:
# 对df2还原为默认索引
# reset_index()默认drop=False,则'user_id'列会被重新添加到df3中
df3 = df2.reset_index()# reset_index()中drop=True,df4会将'user_id'列删除
df4 = df2.reset_index(drop=True)df3
2-行的删除 — drop()方法
行的删除通常出现在处理一些异常样本时,并非一定要选择删除,也可以选择替换处理,但具体如何替换就需要根据数据类型与特定选择,本文这里重点关注行的删除操作。
Pandas中提供了drop()方法用于行的删除:
df.drop(# df_useless代表了 df 中符合删除条件的df子集# 具体符合什么删除条件就需要具体问题具体分析# 比如本文中 df['Age']列中出现了负数的年龄# 就可以设置 df[df['Age']<0] 或者 df.query('Age<0') 得到 符合删除条件的df_useless# 再将df_useless.index传入,即可完成删除操作index=df_useless.index# 是否修改原始数据# inplace默认为False,不修改原始数据,inplace=False/True
)
就以删除df中年龄为负数的用户为例,展示drop()方法的删除原理。
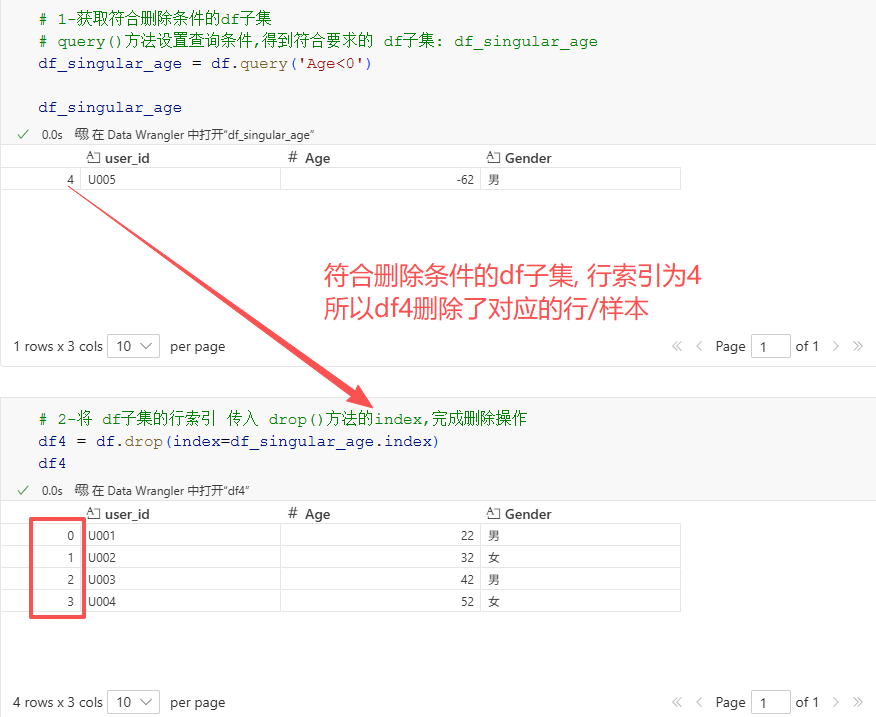
首先要查询出符合删除条件的df子集,此处选择query()方法查询:
# 1-获取符合删除条件的df子集
# query()方法设置查询条件,得到符合要求的 df子集: df_singular_age
df_singular_age = df.query('Age<0')df_singular_age
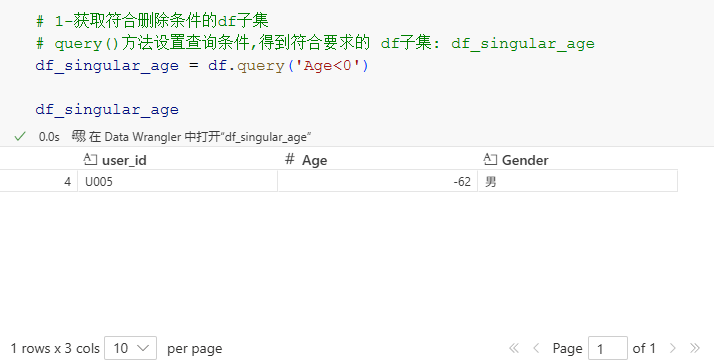
再将df_singular_age.index作为drop()方法中需要删除的行索引,即可完成删除操作:
# 2-将 df子集的行索引 传入 drop()方法的index,完成删除操作
df4 = df.drop(index=df_singular_age.index)
df4