考研复习-计算机网络-第四章-网络层
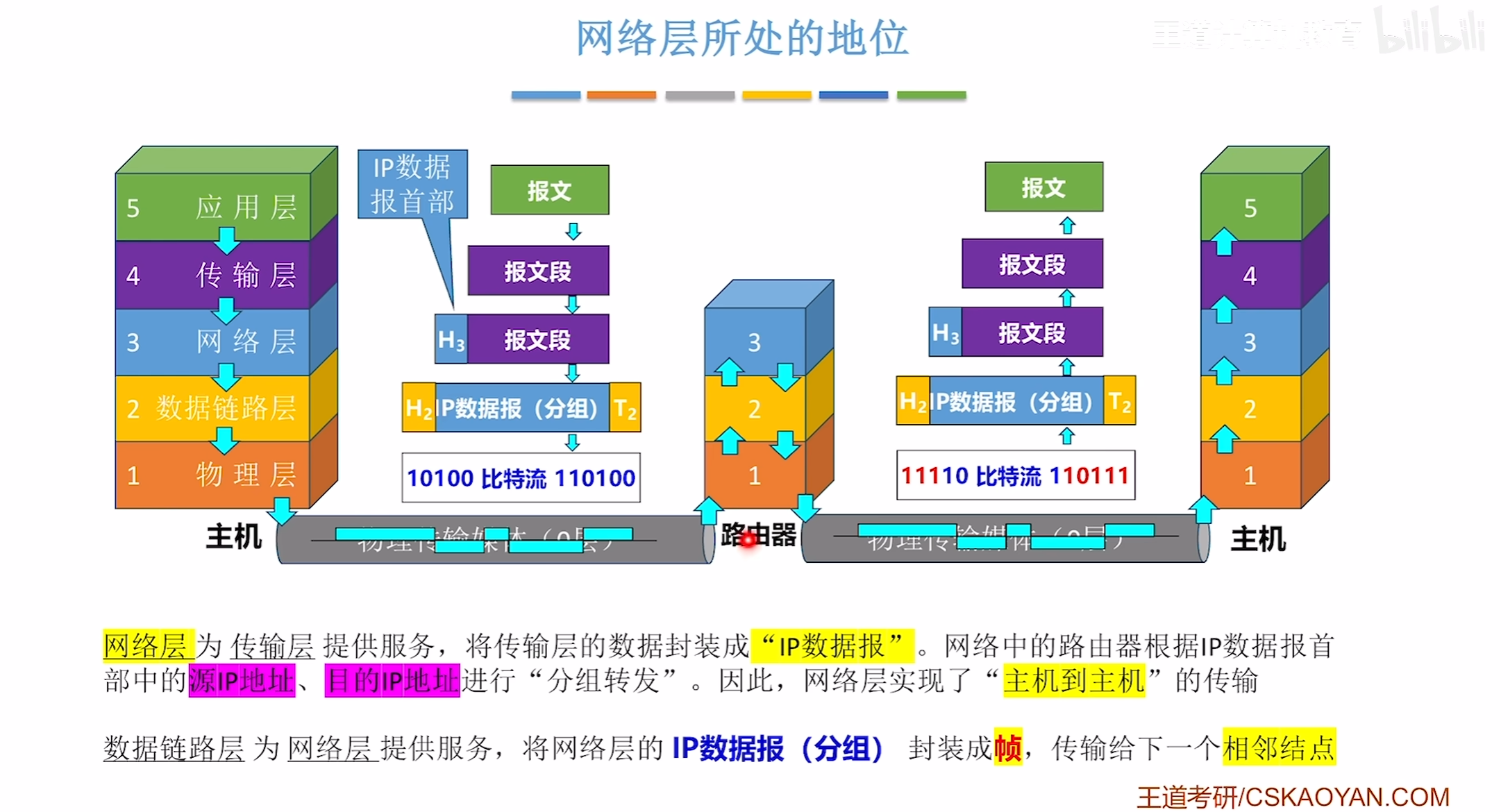
网络层大致概念
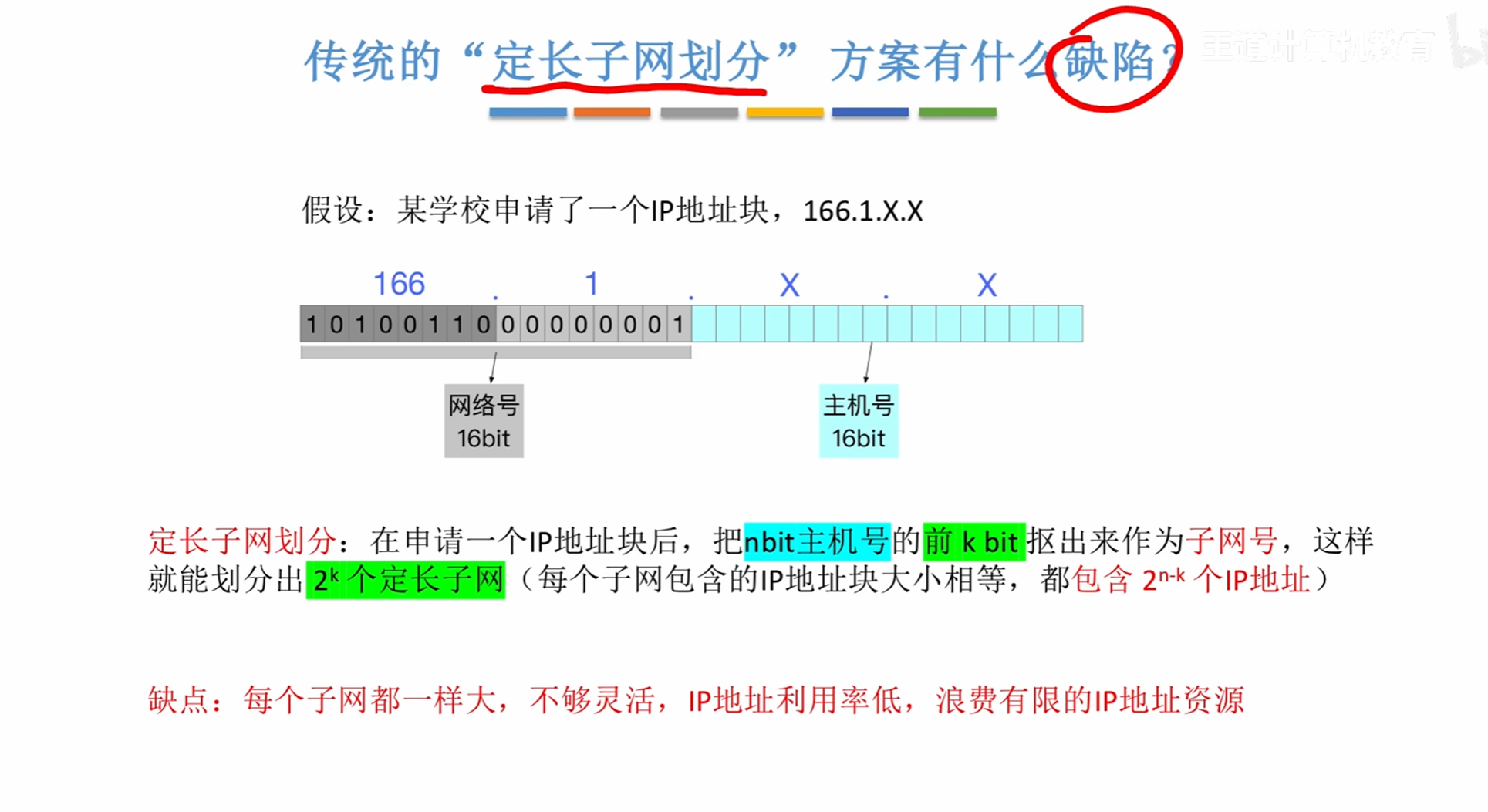
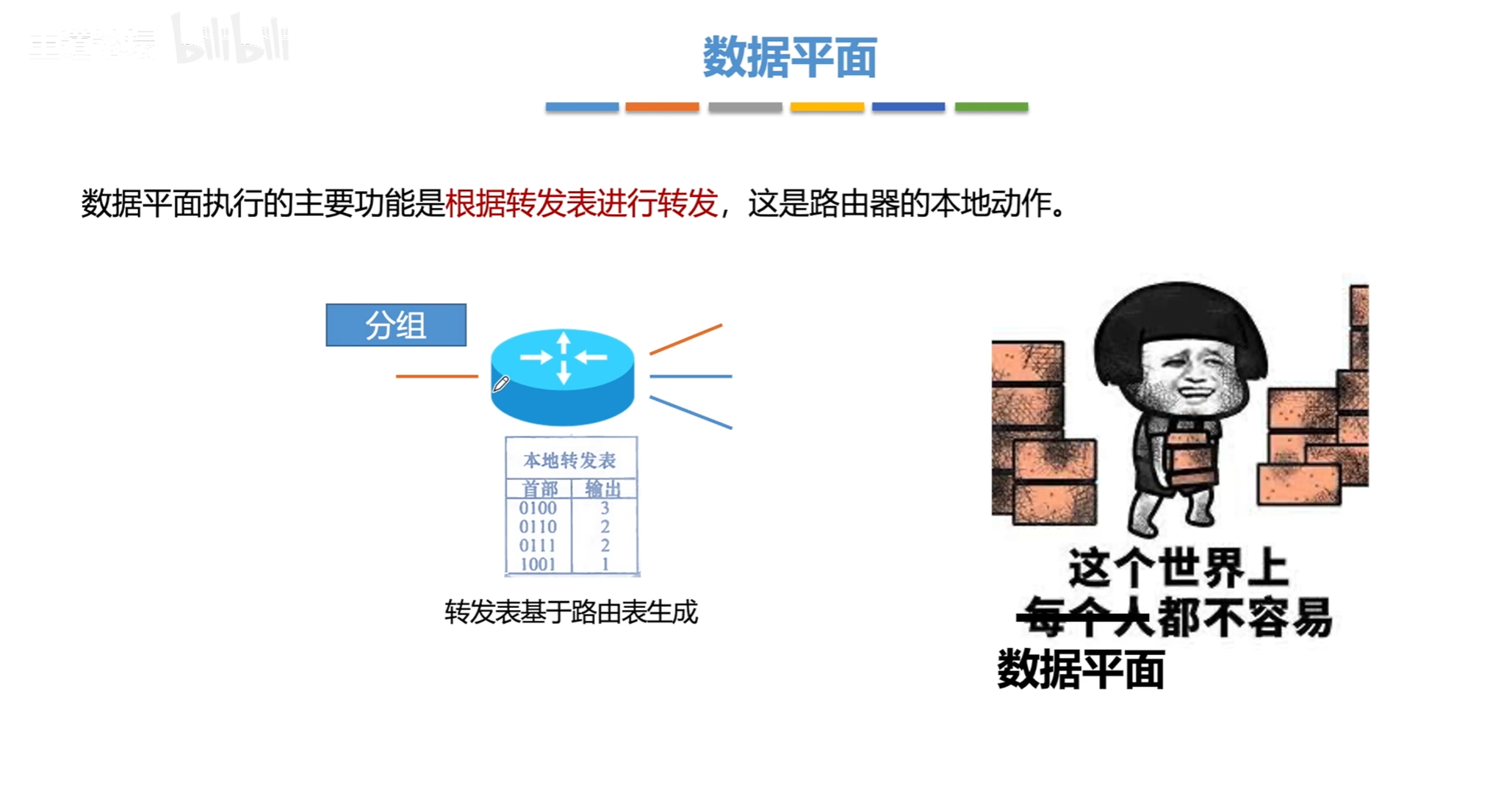
IPV4 超重点!
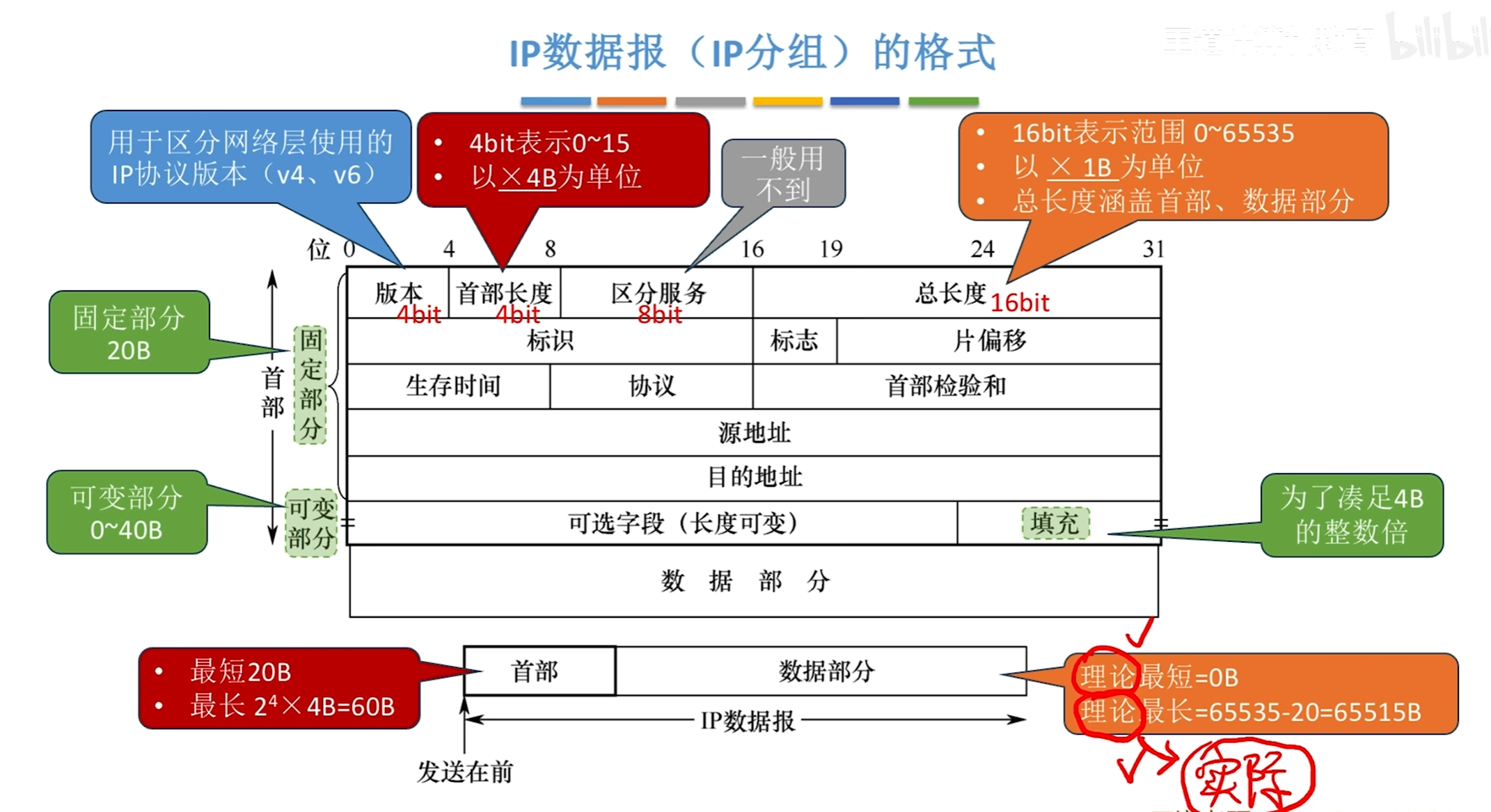
IP数据报格式
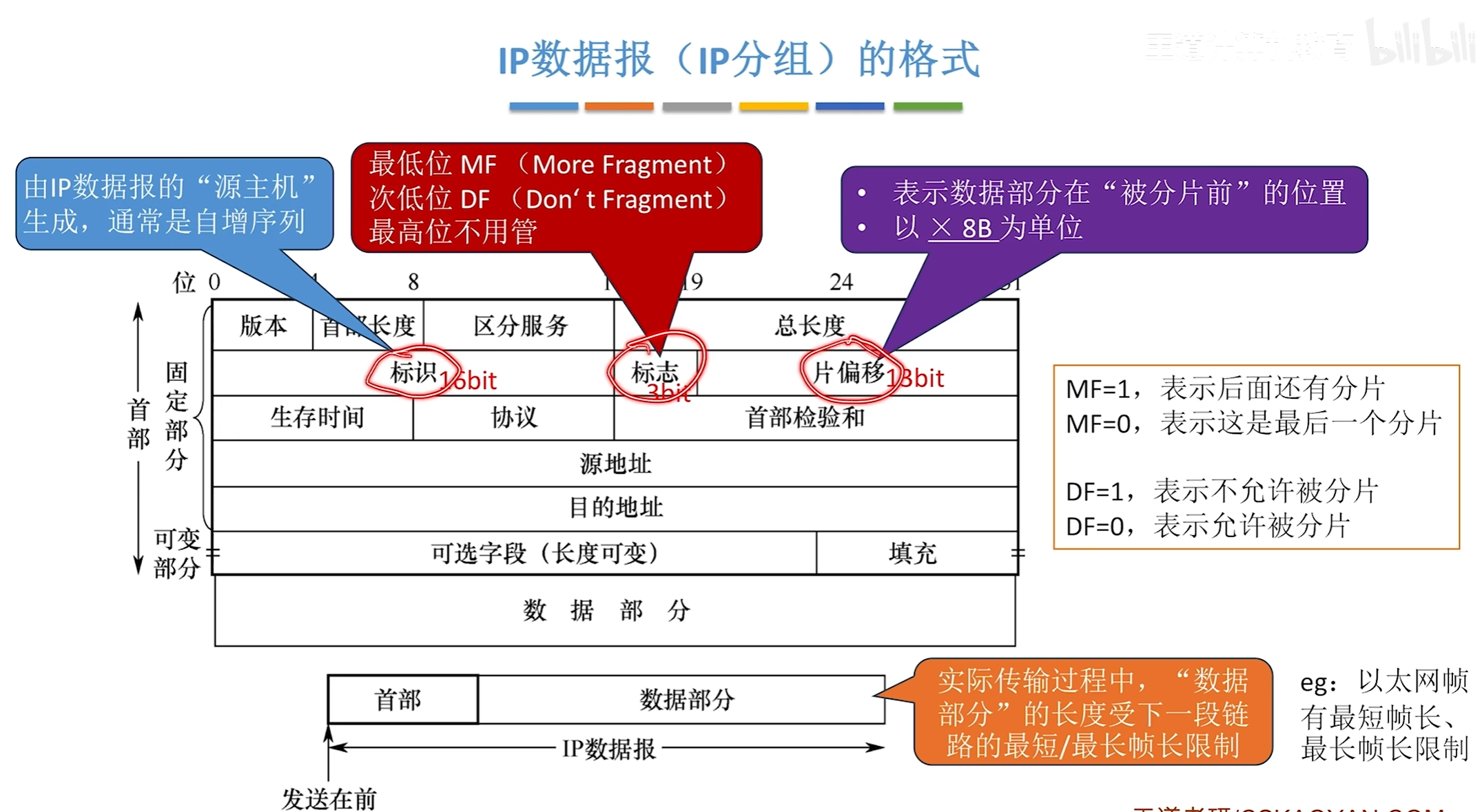
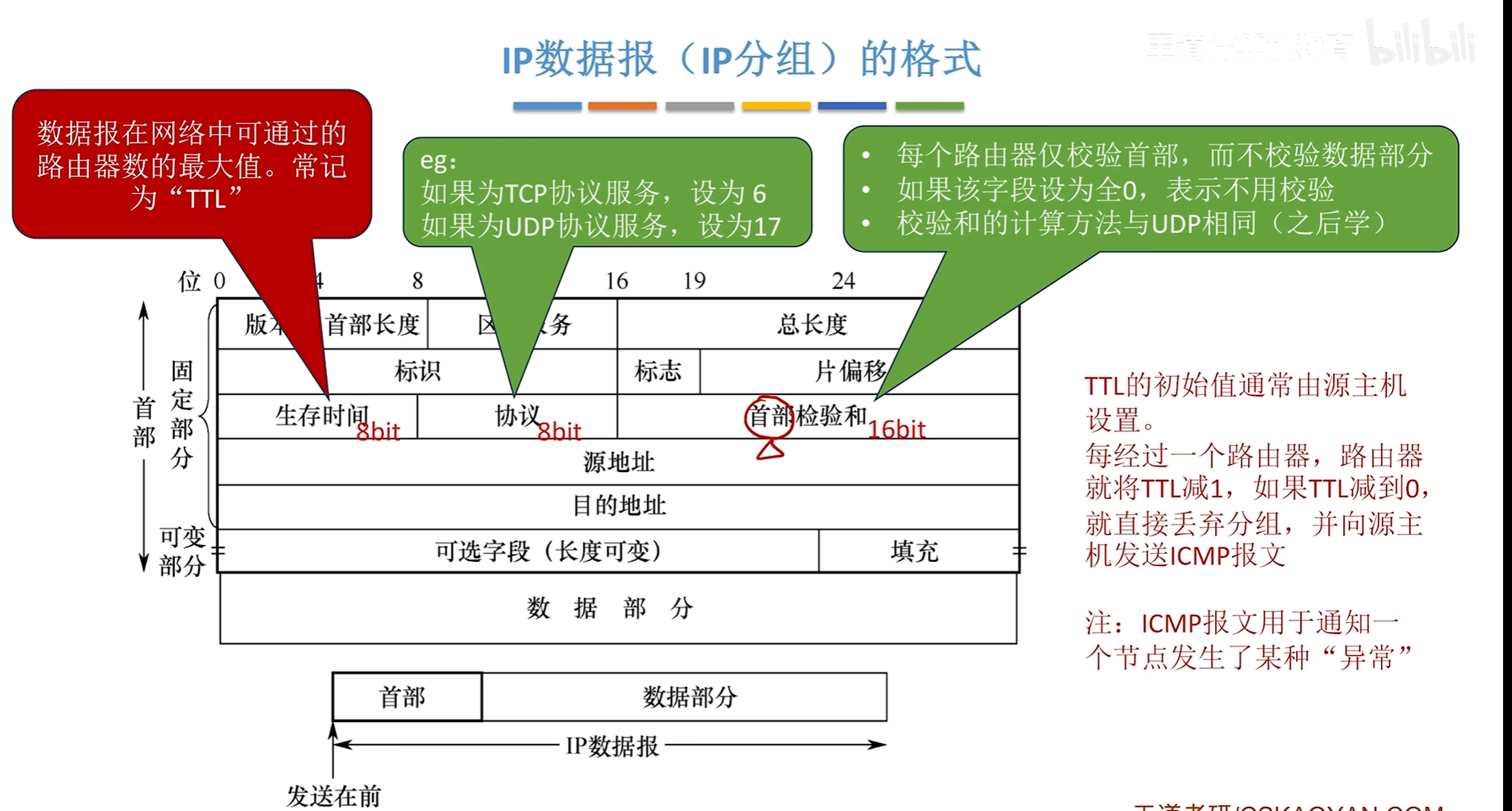
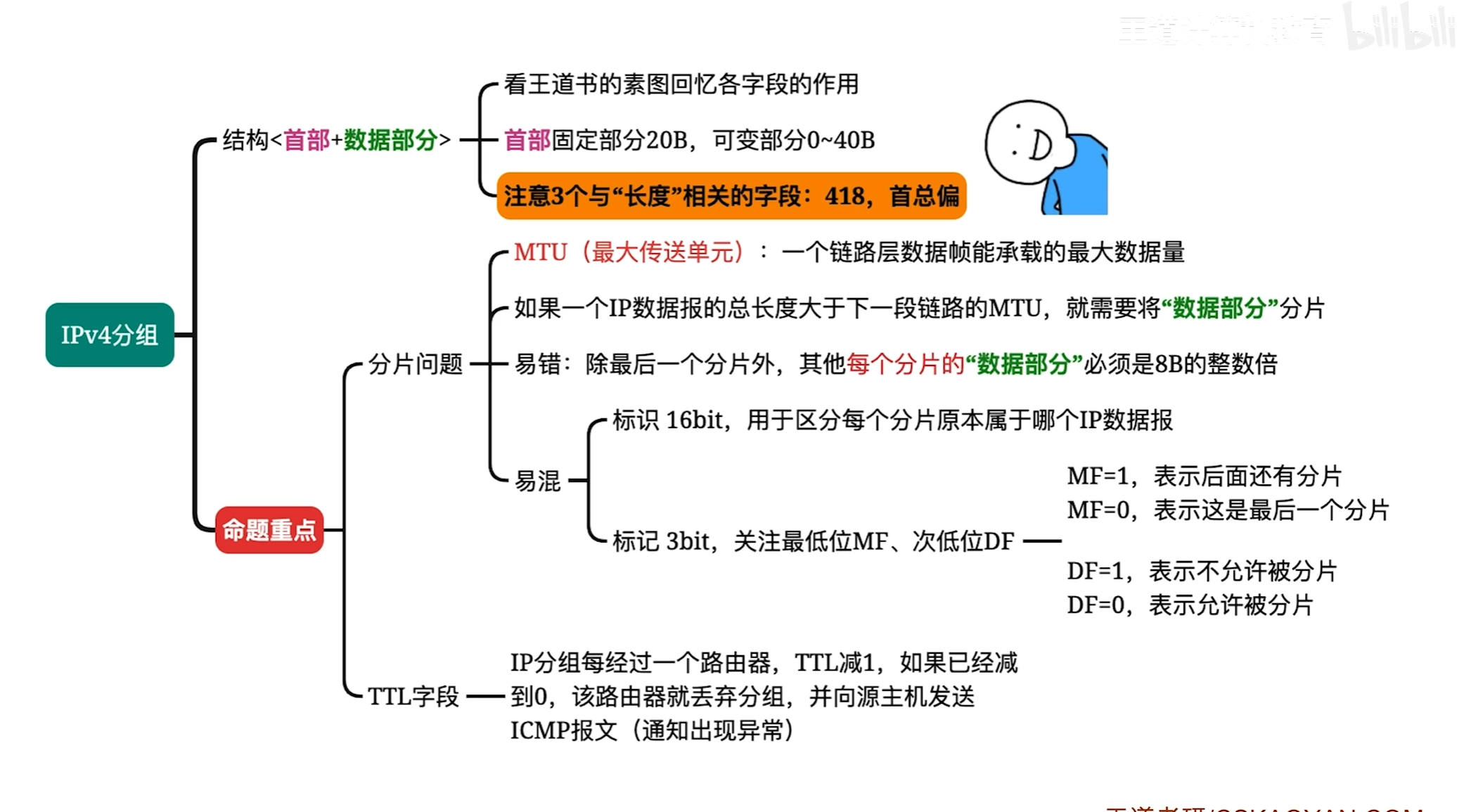
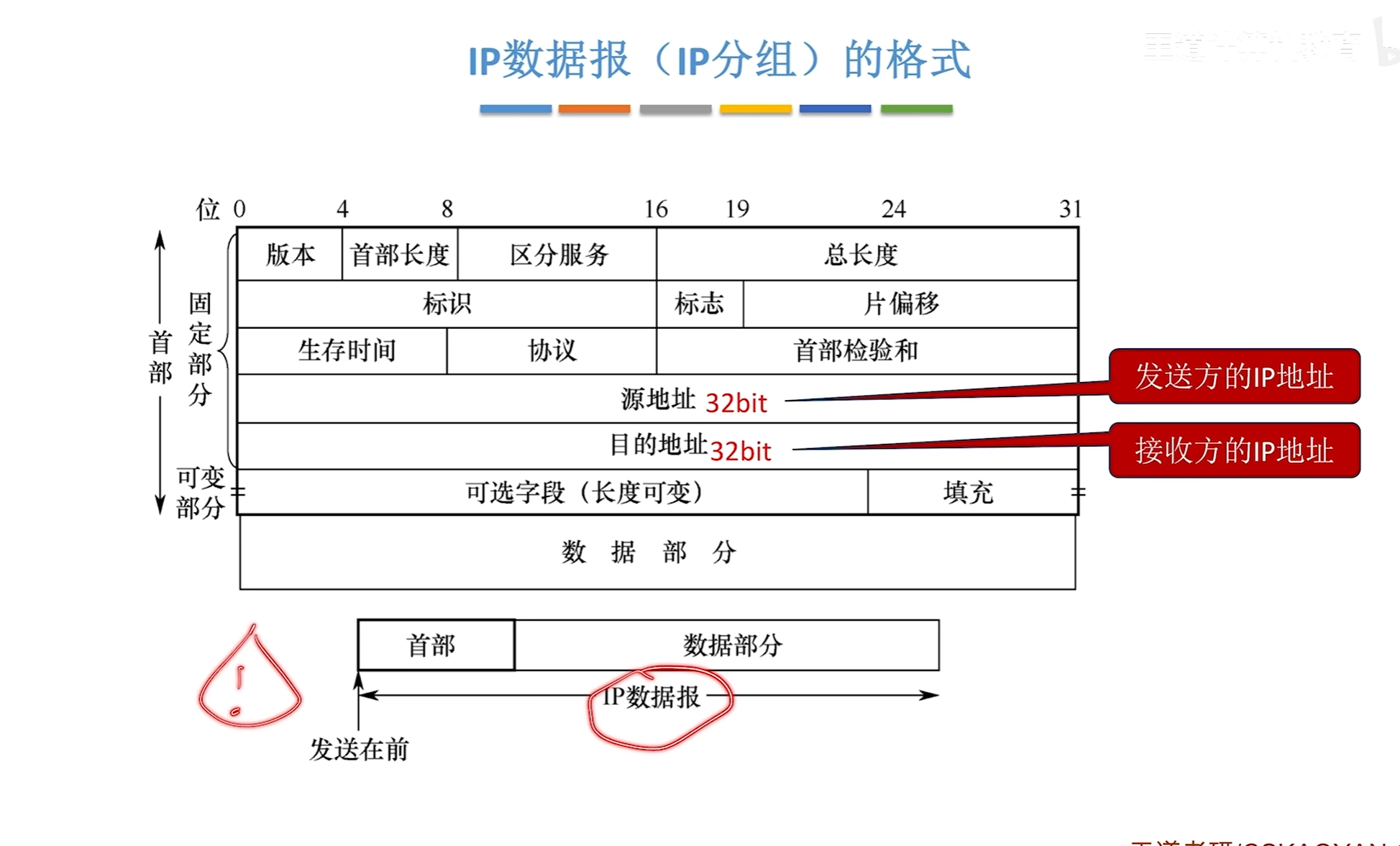
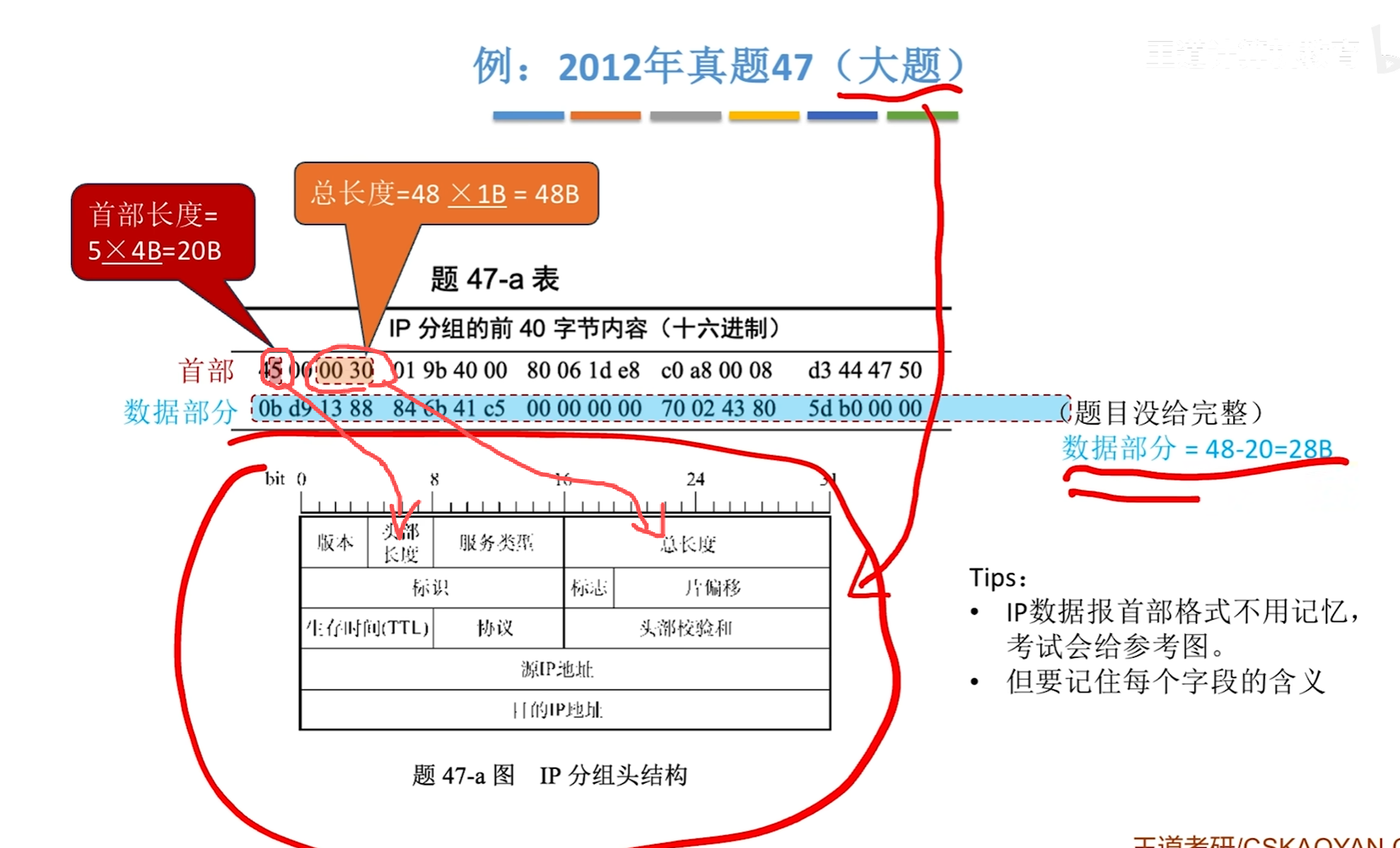
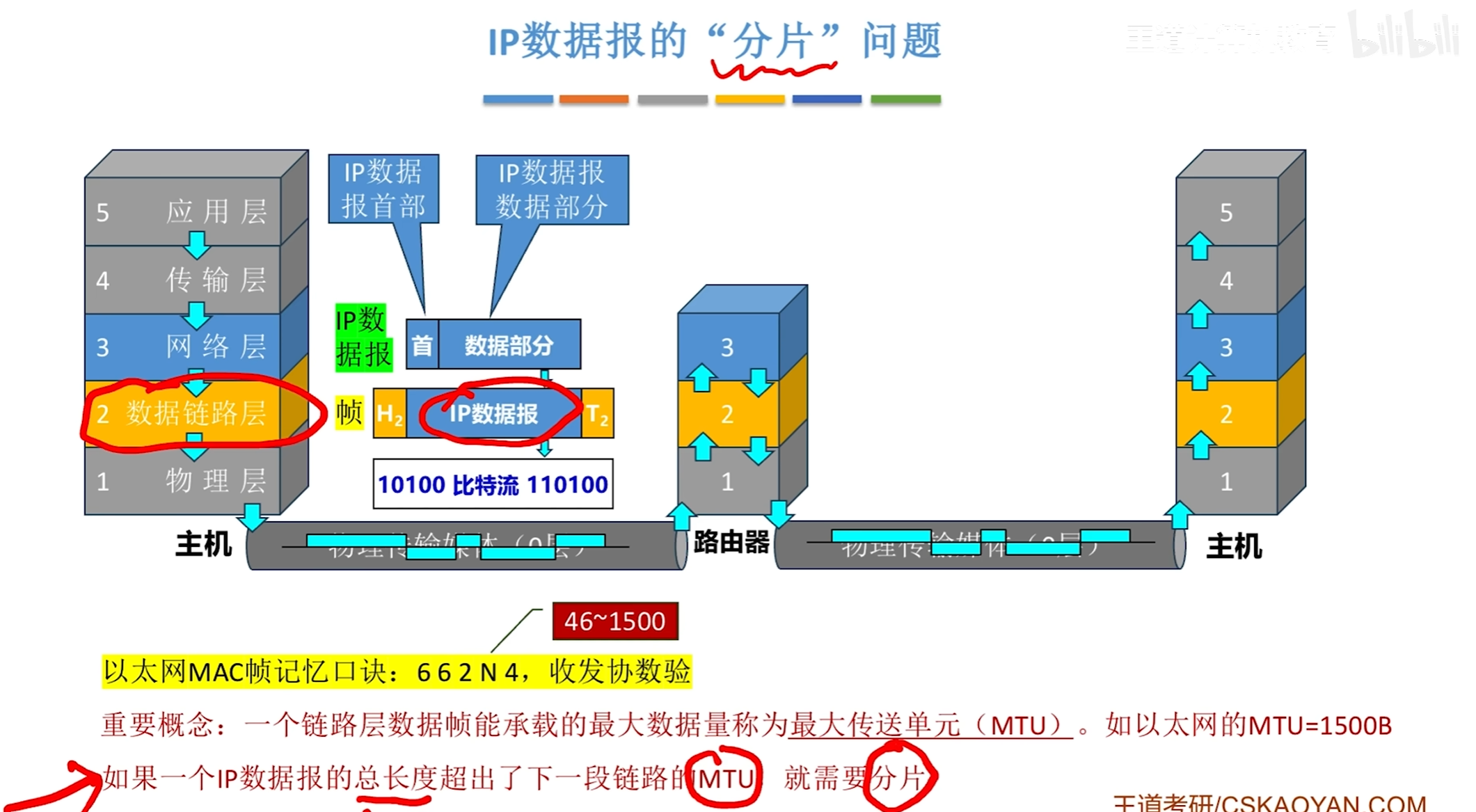
IP数据报分片问题
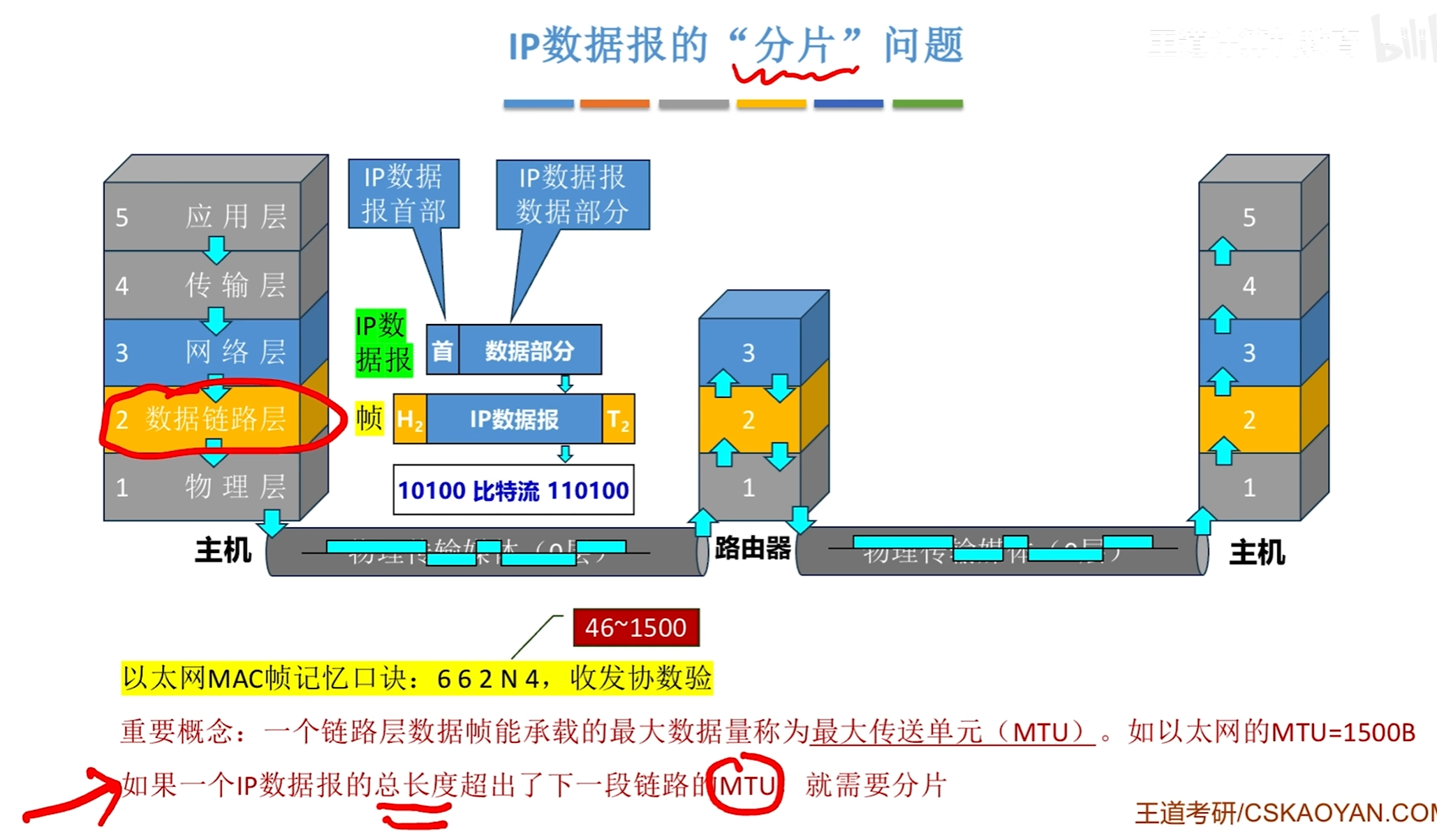
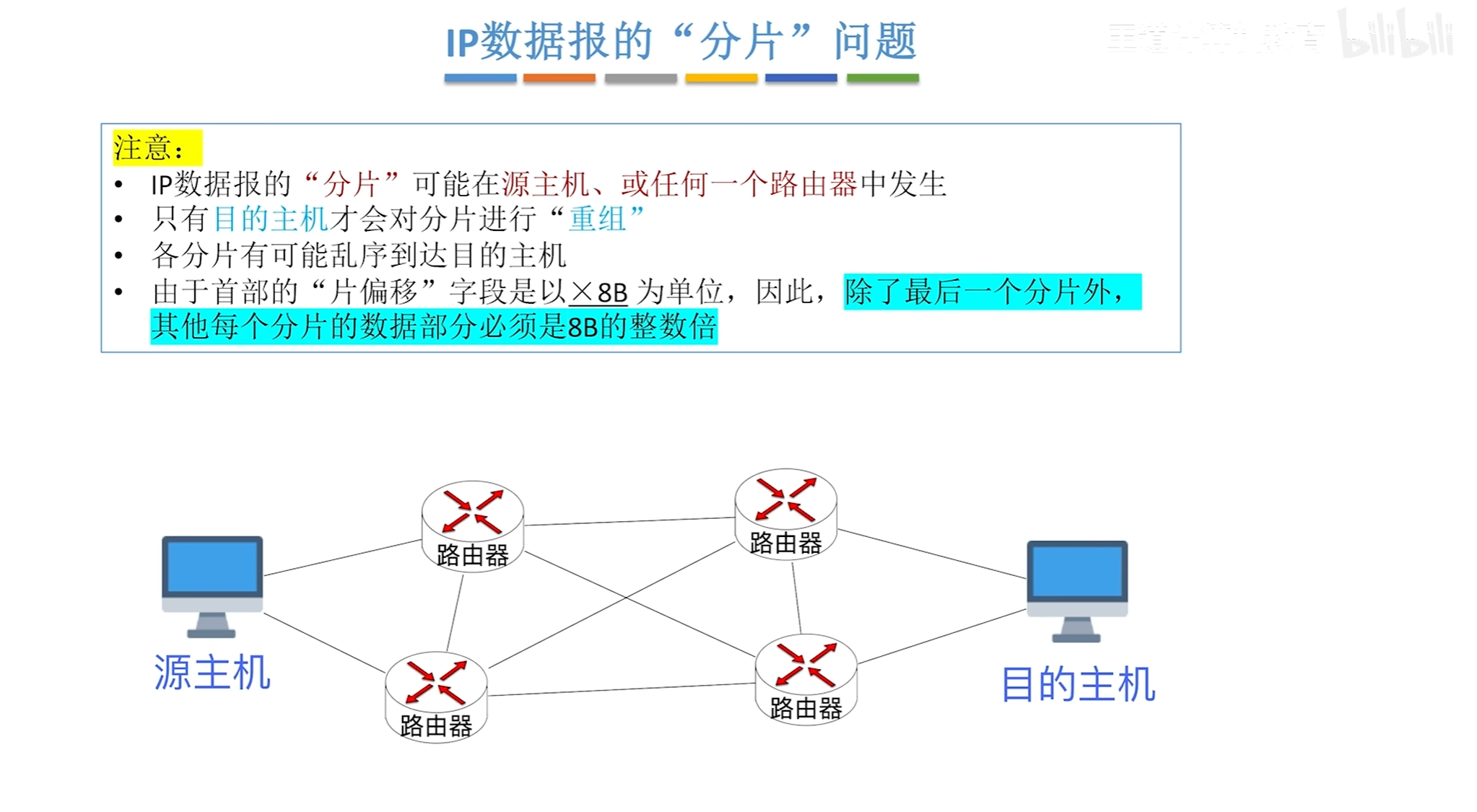
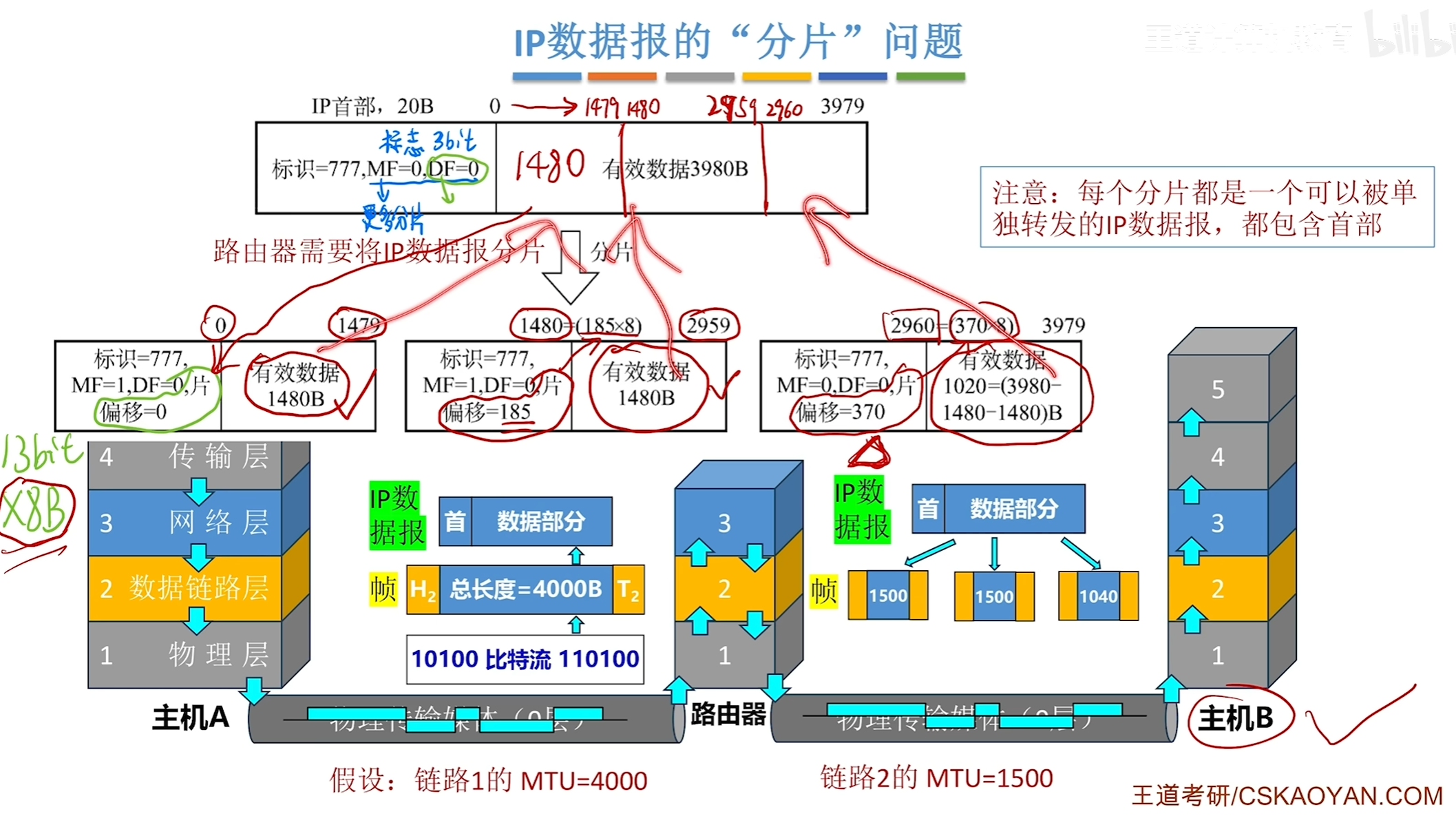
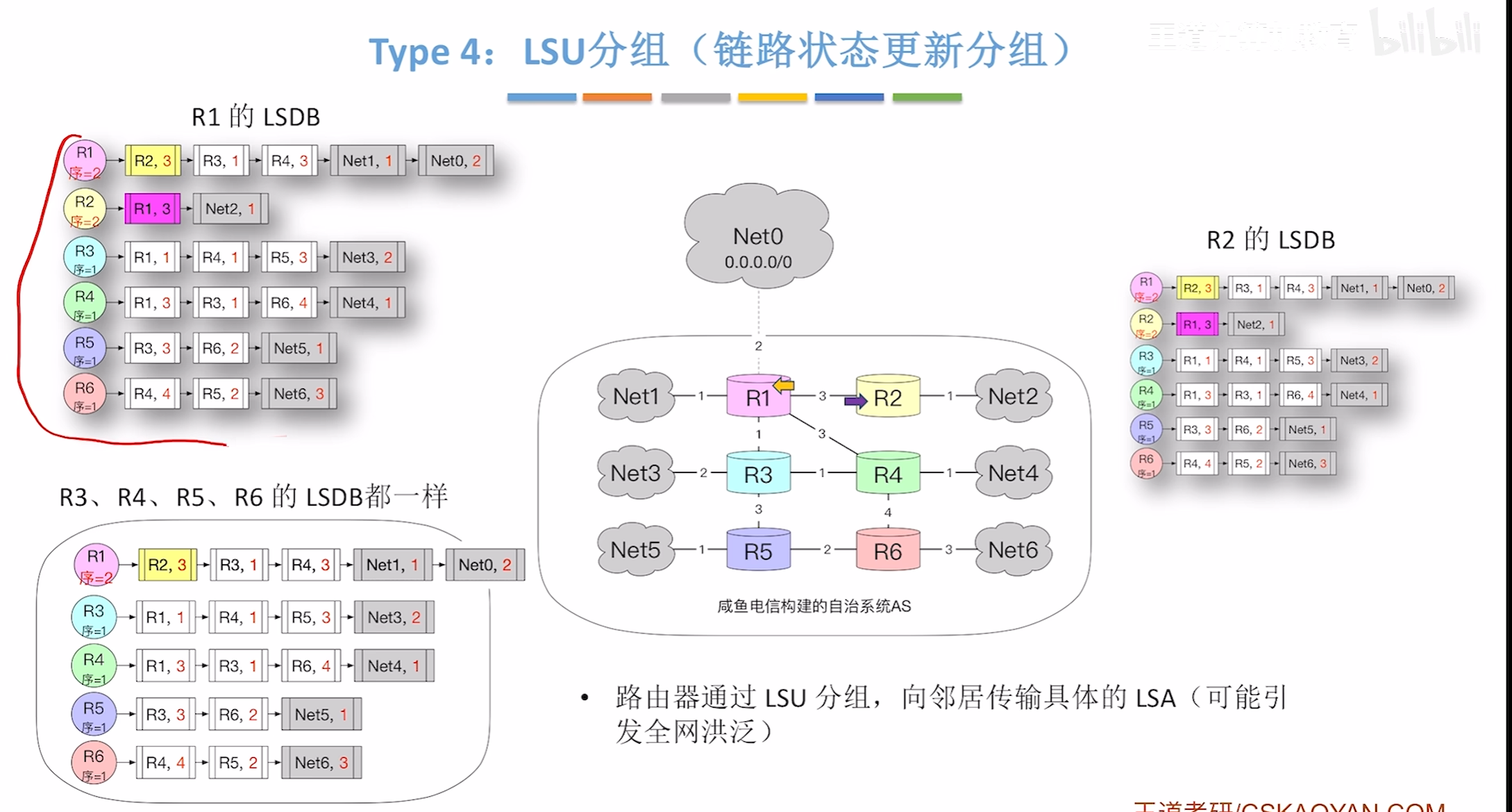
即可以根据不同的路径分别进行转发,分完片之后,其中首部信息中
标识:表示他们所属的原本的IP数据报
MF:为1时表示后面还有更多的分片
DF:0表示该数据报可分片为1表示不可分片
片偏移计算是通过在原本片内的哪个位置除以8即可得到偏移量
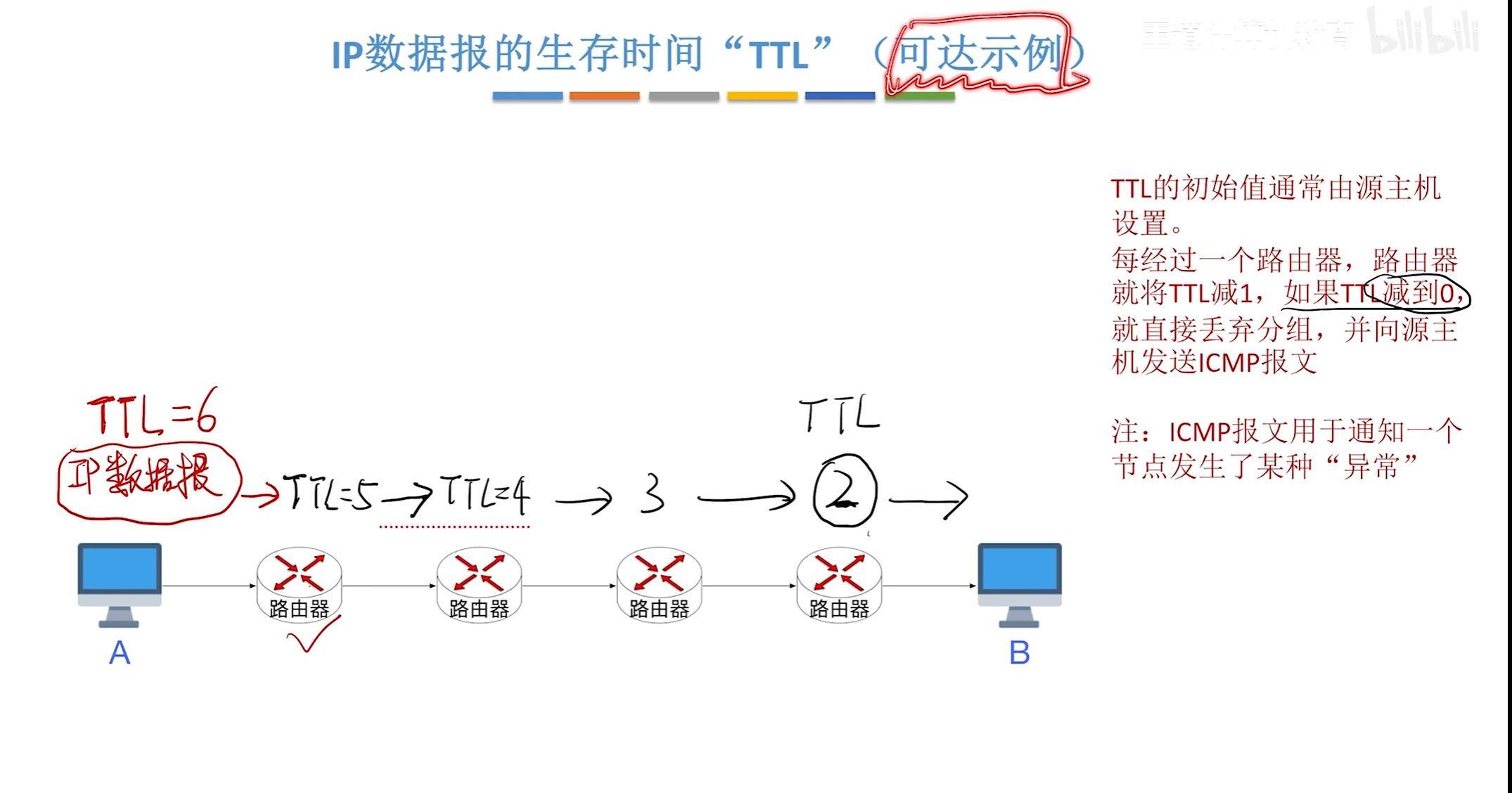
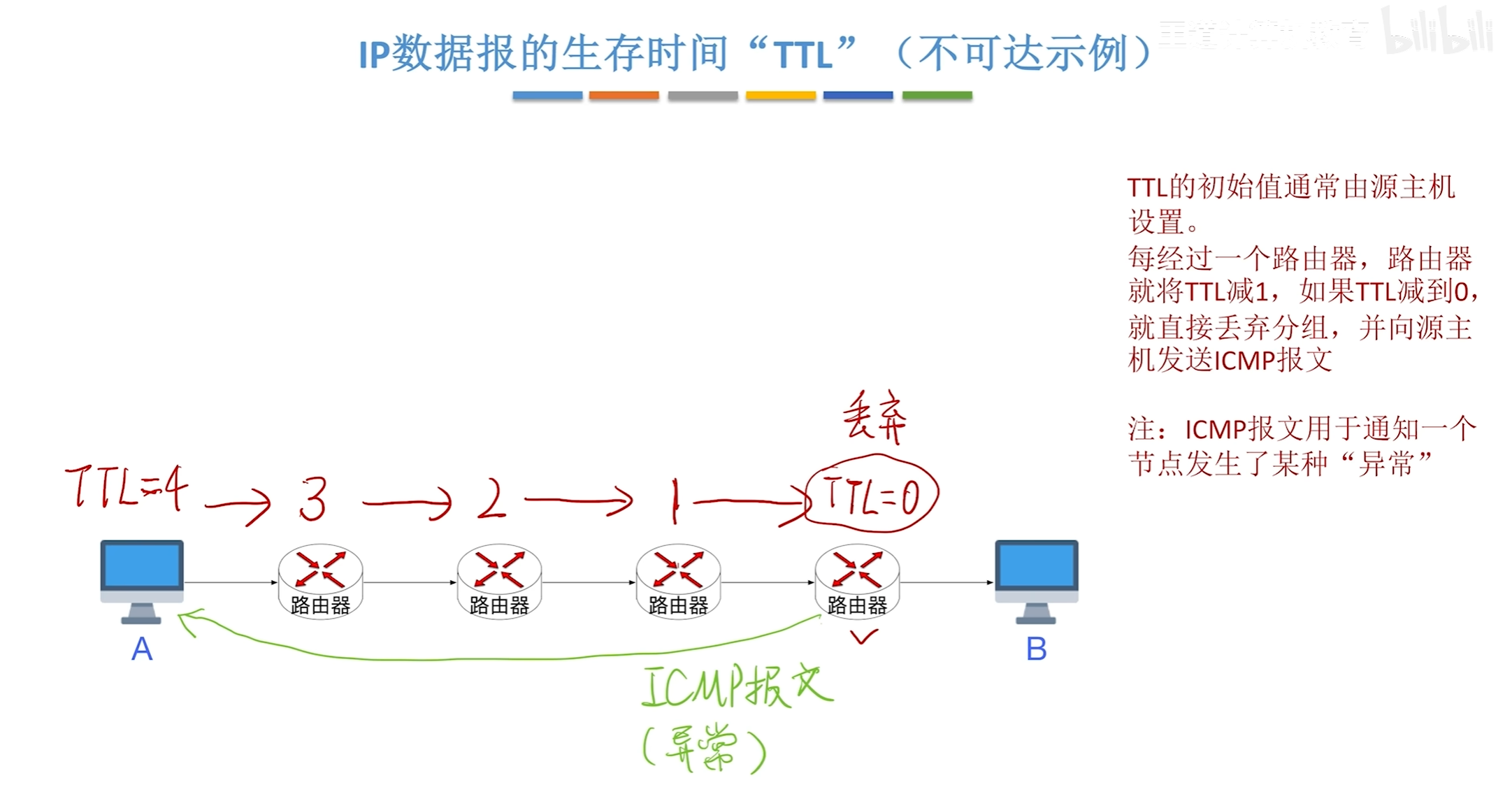
IP数据报生存时间TTL
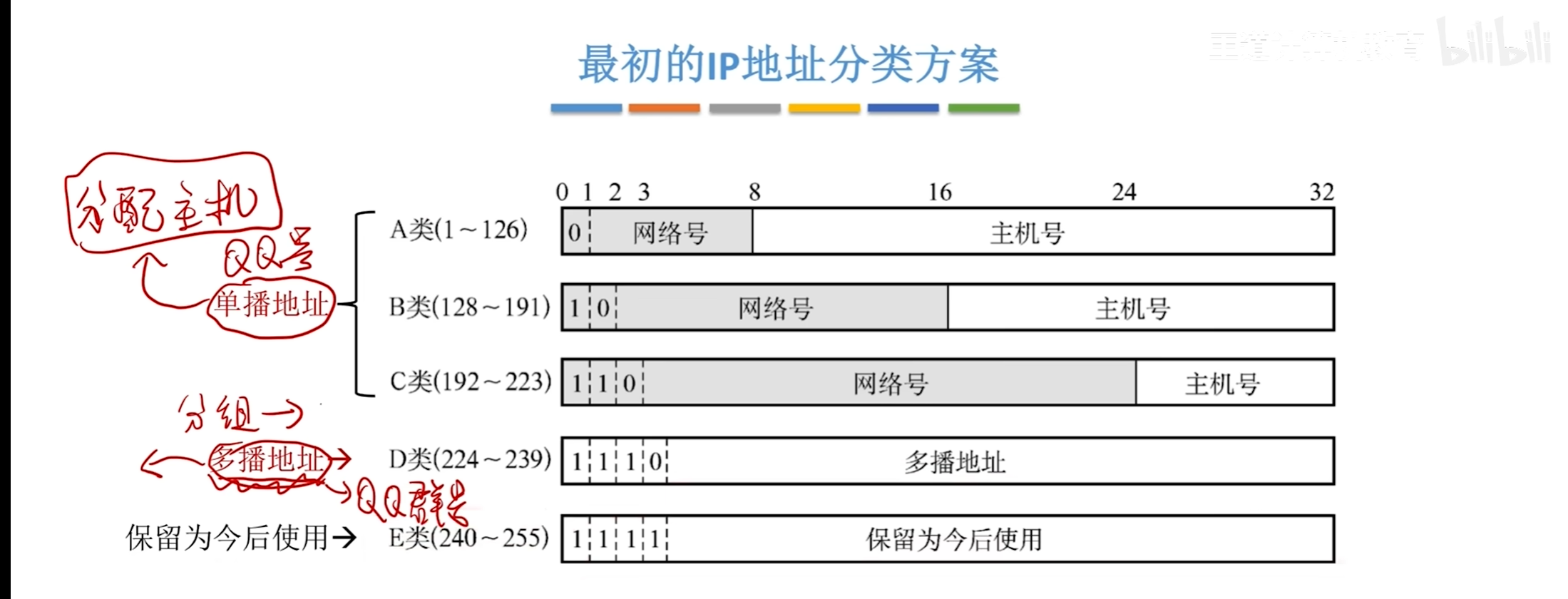
IP地址分类
其中32bit表示成10进制为
0.0.0.0这四位数每使用8bit来表示
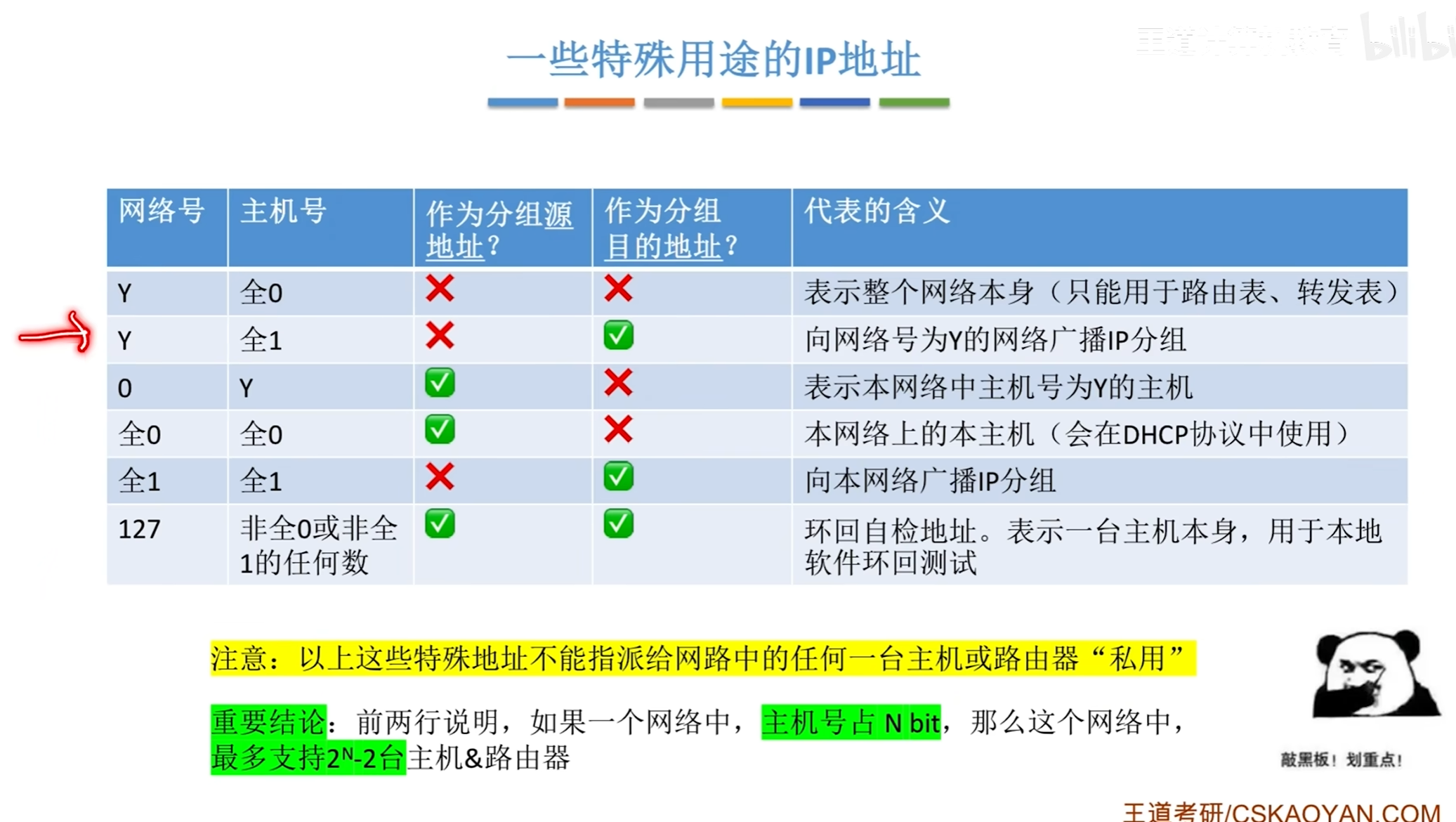
而A类地址因为开头是0,所以其最多只能表示到0-127,其中全1代表着一类特殊地址
同样的B类地址因为开头是10,即从128-192,全1排掉
C类地址同理
其中A类地址网络号占8位
B类16位
C类24位

其中这决定了从属于同一个路由器的网络其网络号相同
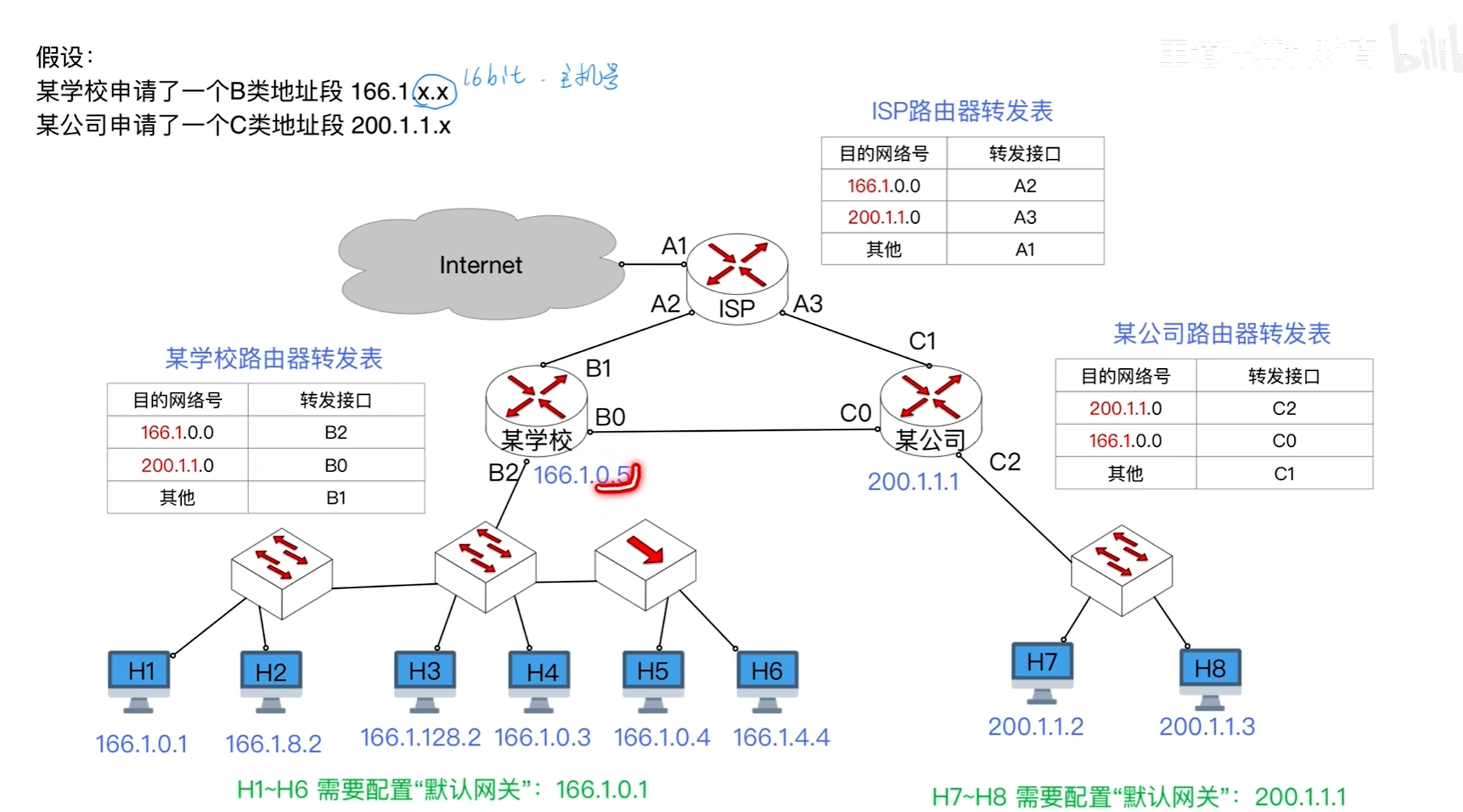
默认网关是告诉默认发送的路由器是哪一个路由器每一个接入的主机都要配置好
并根据目的地址的网络号进行对应端口的转发
特殊的ip地址
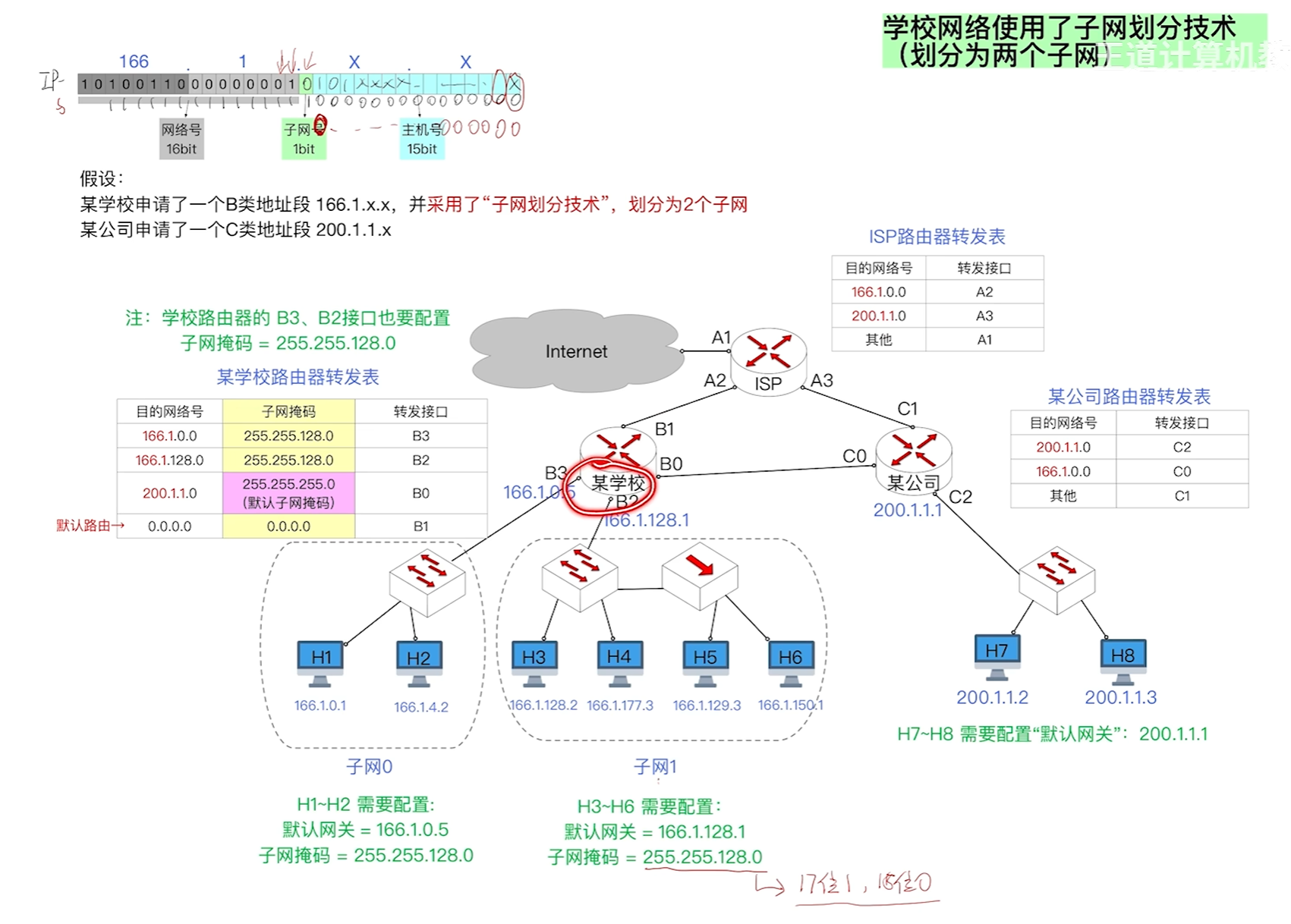
p44宝典
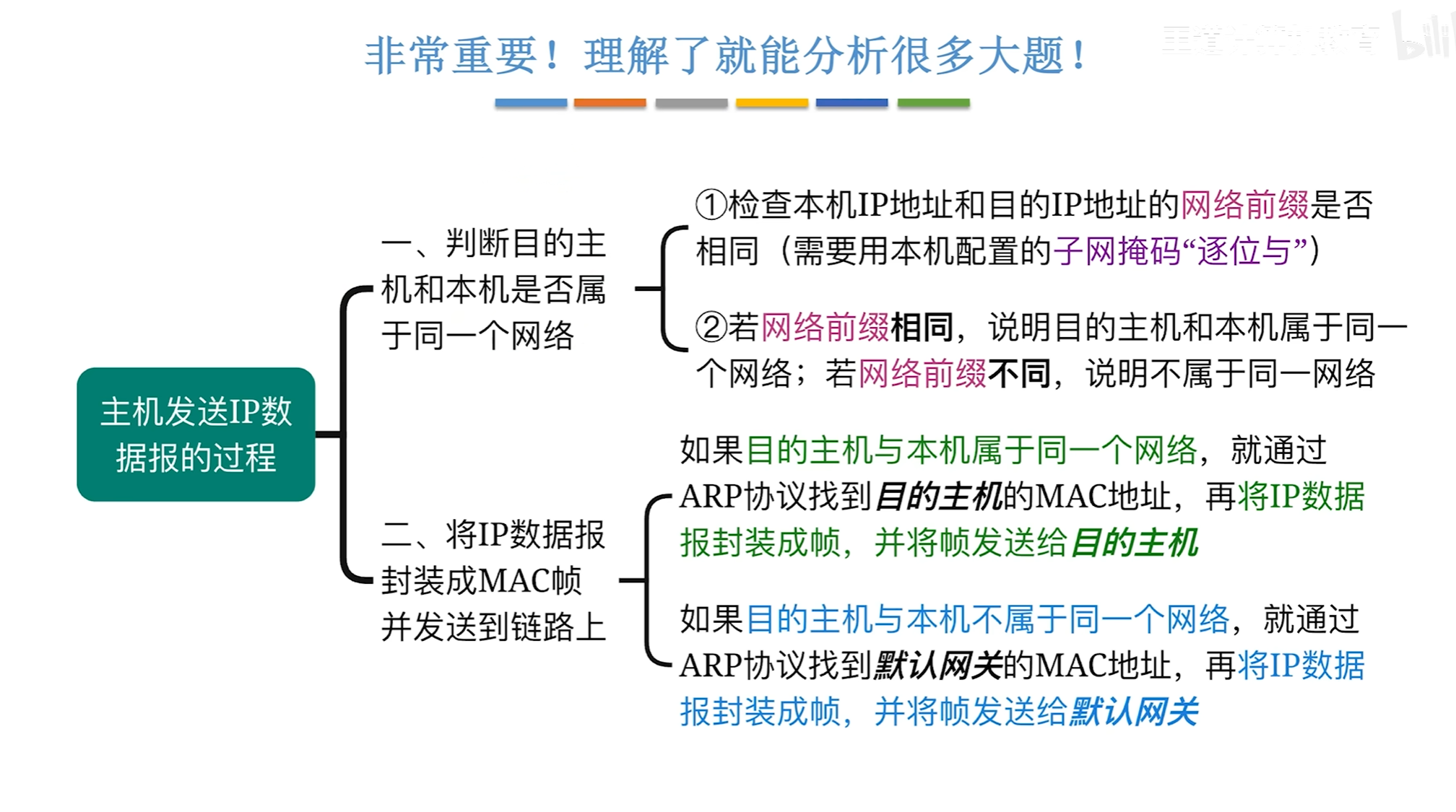
子网划分及ip数据报的发送过程
p45宝典

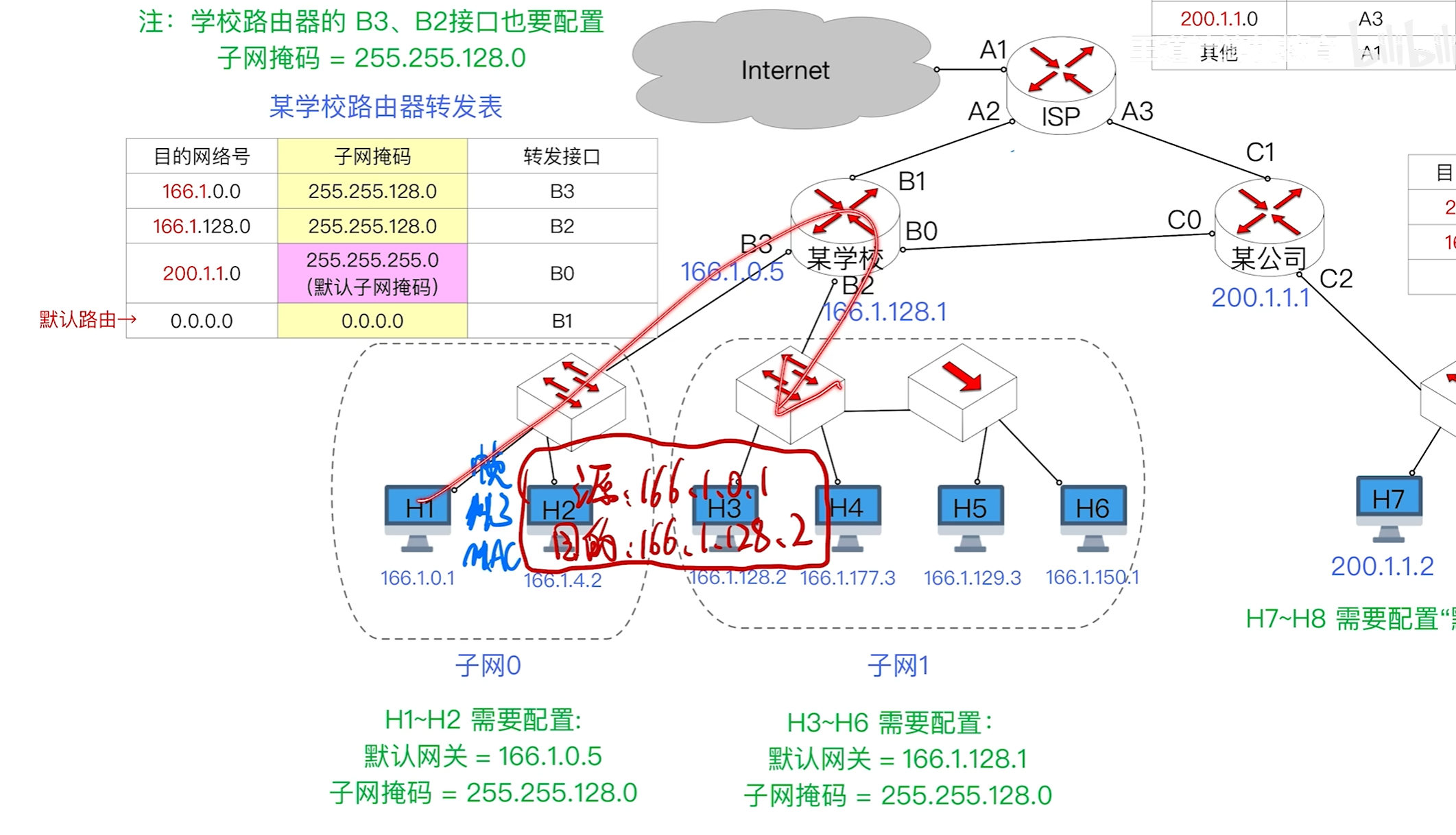
当配备了子网掩码时,一个ip数据报在发送前需要和子网掩码进行与运算,得到网络前缀,若相同则不需要交给路由器进行转发,只需要在内部进行发送即可
如果不是则需要交给路由器,再由路由器进行子网掩码的运算对比路由表中的表像,如果匹配就会发送
若某个地址路由表中没有那么就会与默认路由进行对比,其中子网掩码全0进行与运算得到的也是全0那么就会从默认路由的转发端口转发出去。
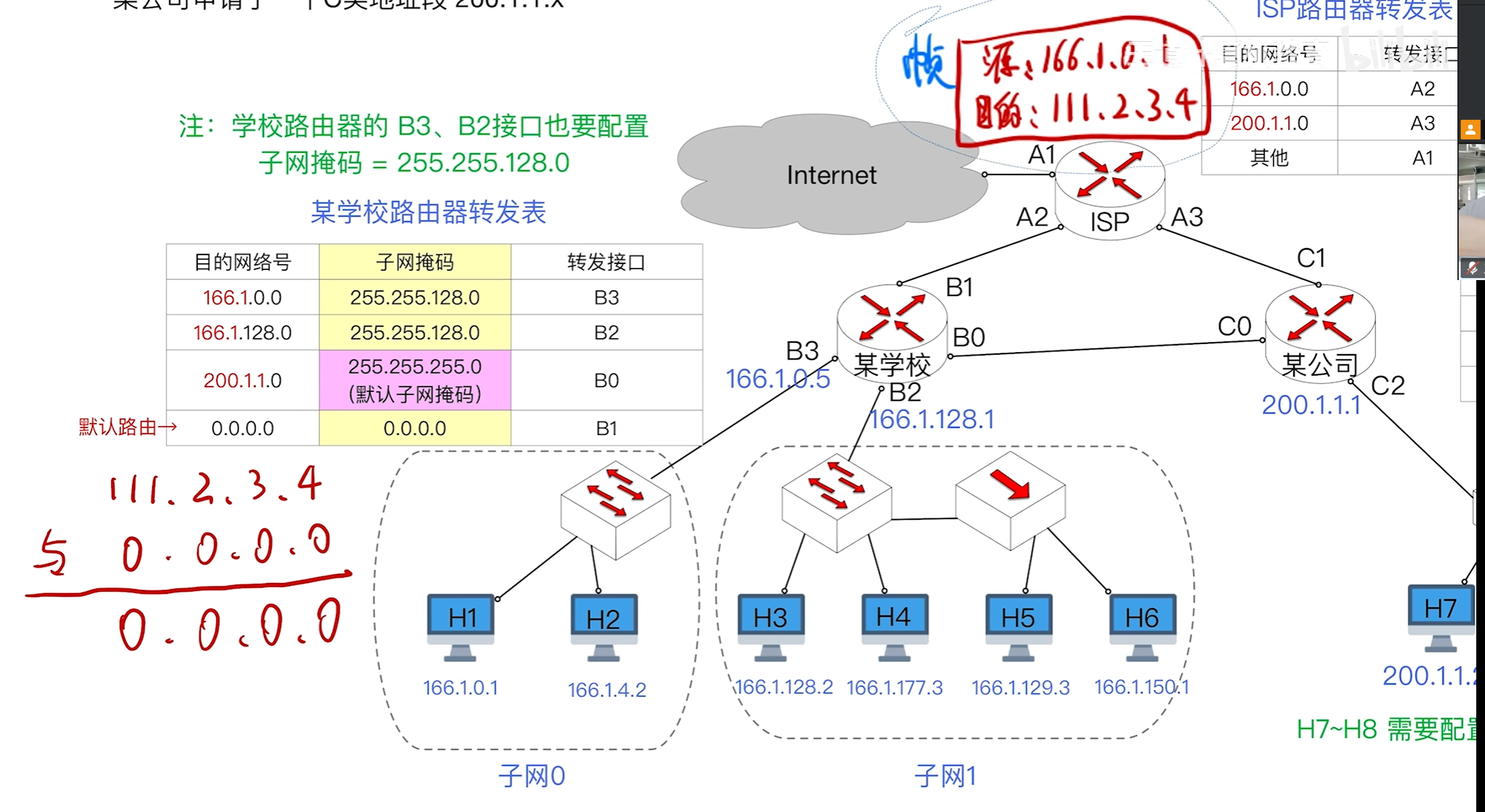
若ip数据报的出口和入口的接口相同那么就会直接丢弃而不会转发

ip数据报的发送的过程
无分类编址CIDR

变长子网
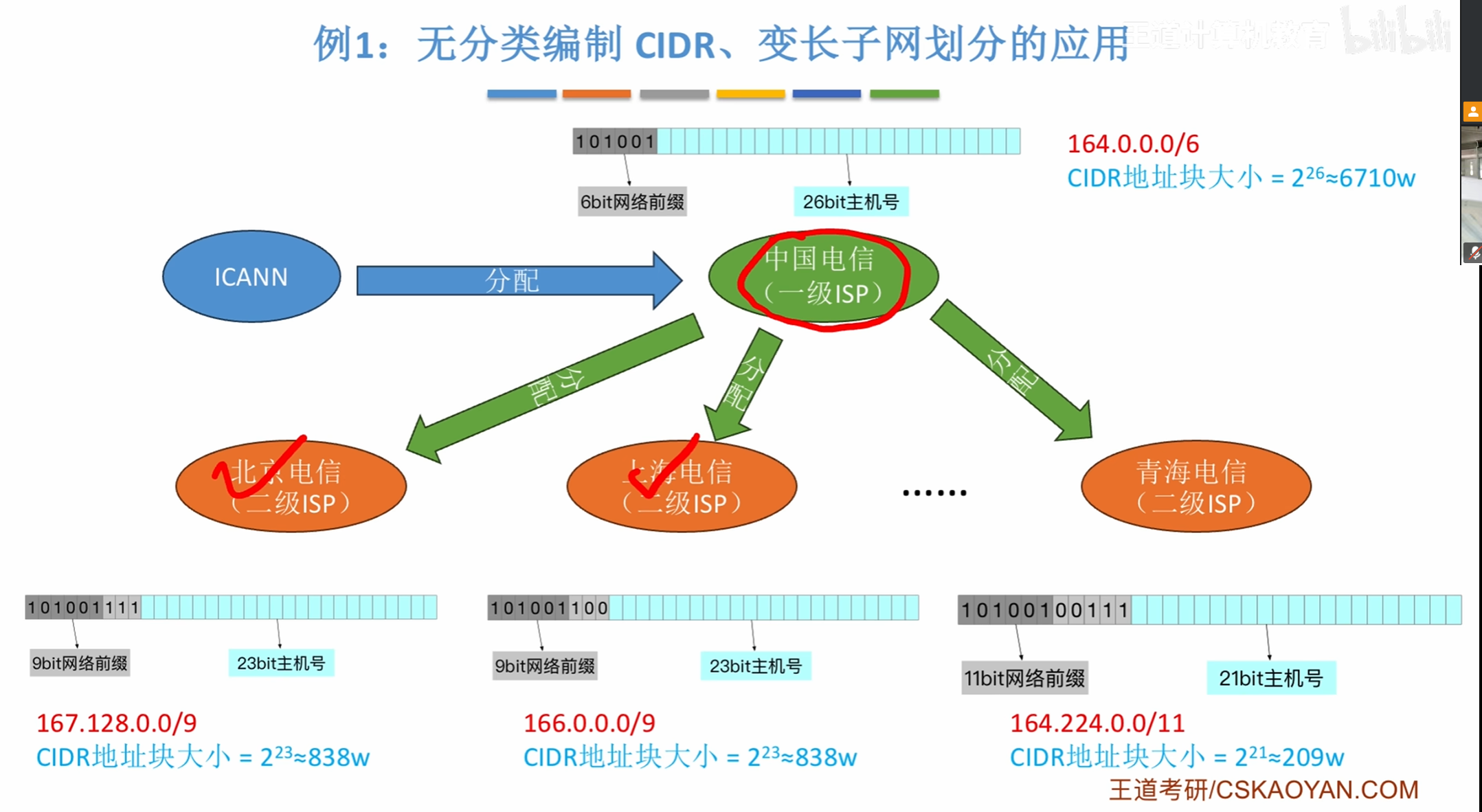
例子

假定一个子网中只有一个主机会出现什么情况?
只有一台主机并且上级只有8个ip地址,即三位二进制数
那么如果划分出一个子网给这一台主机,那么该主机需要占用四个ip地址
首先,主机号全0全1不能使用那么假定我们只分配1位二进制数给这个子网,减去全01那么就没有可用的ip地址
当两位ip地址时我们就可以进行分配
可用ip地址为=2^2-2=2
这才满足要求
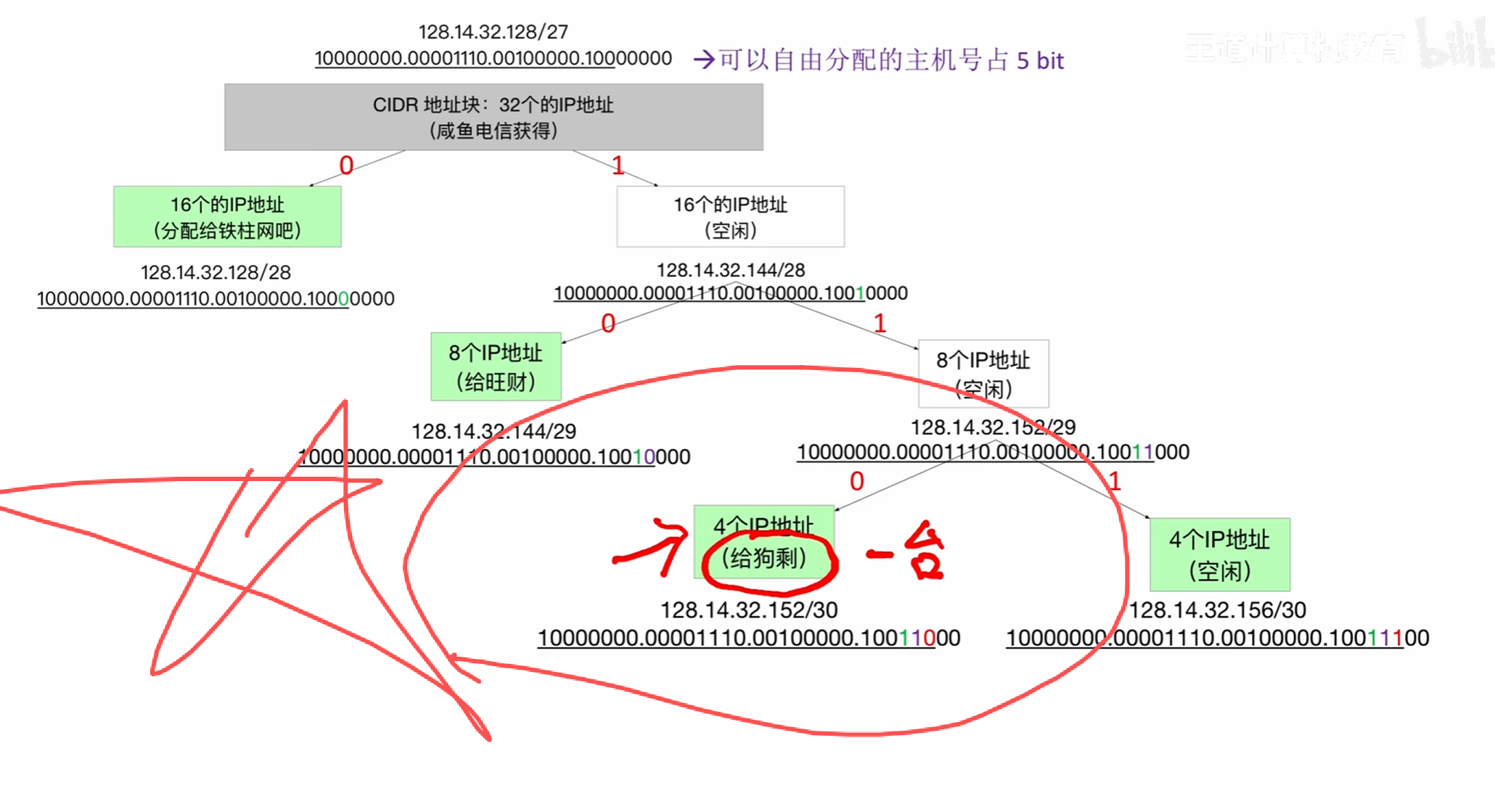
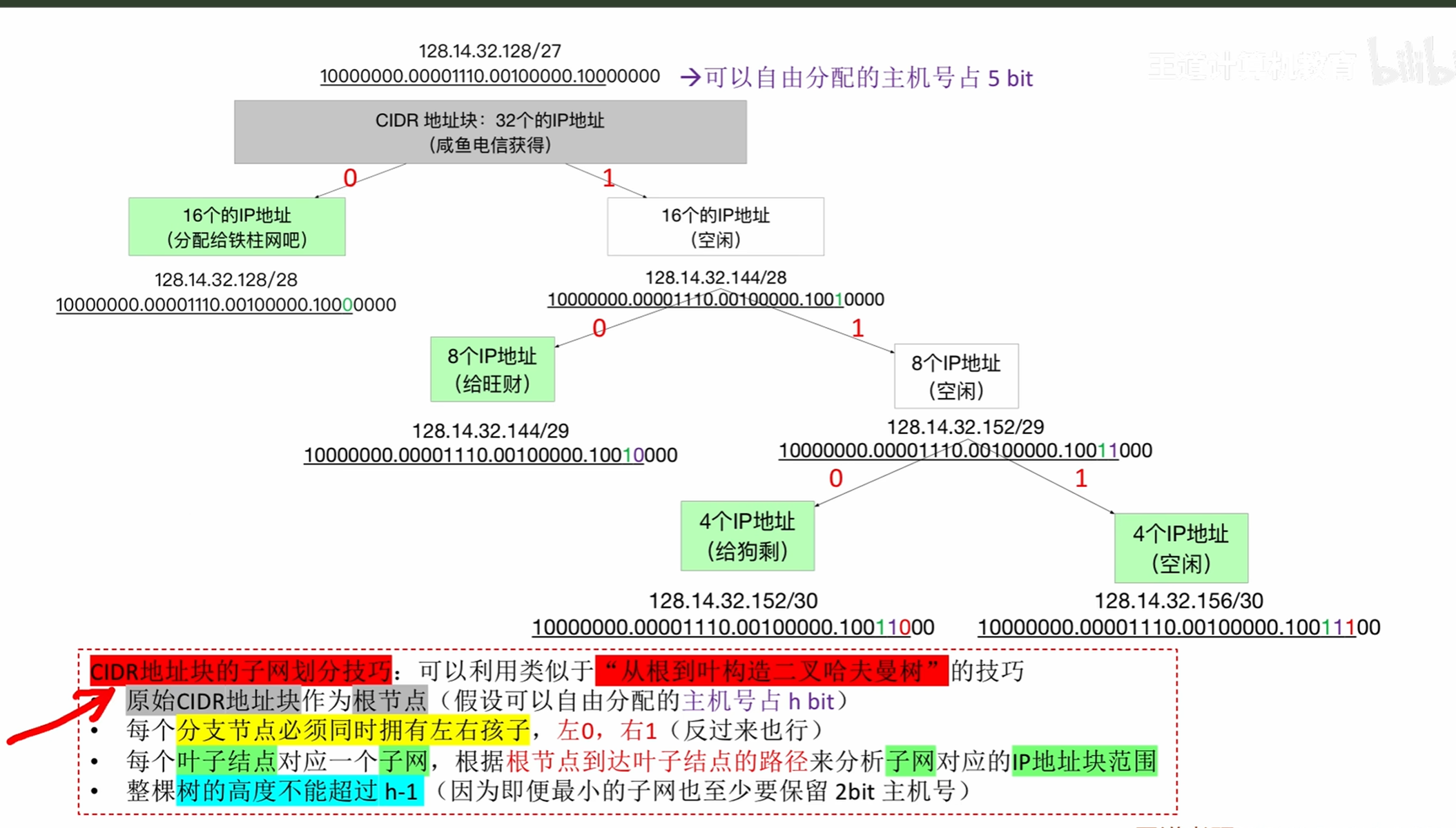
每次都取出一个0和1构造一个子网
遵循哈夫曼树左0右1的原则。

对于该题我们可以进行哈夫曼树的构造每一个叶子节点对应一个子网
五个叶子节点就是一个对应得子网
路由聚合
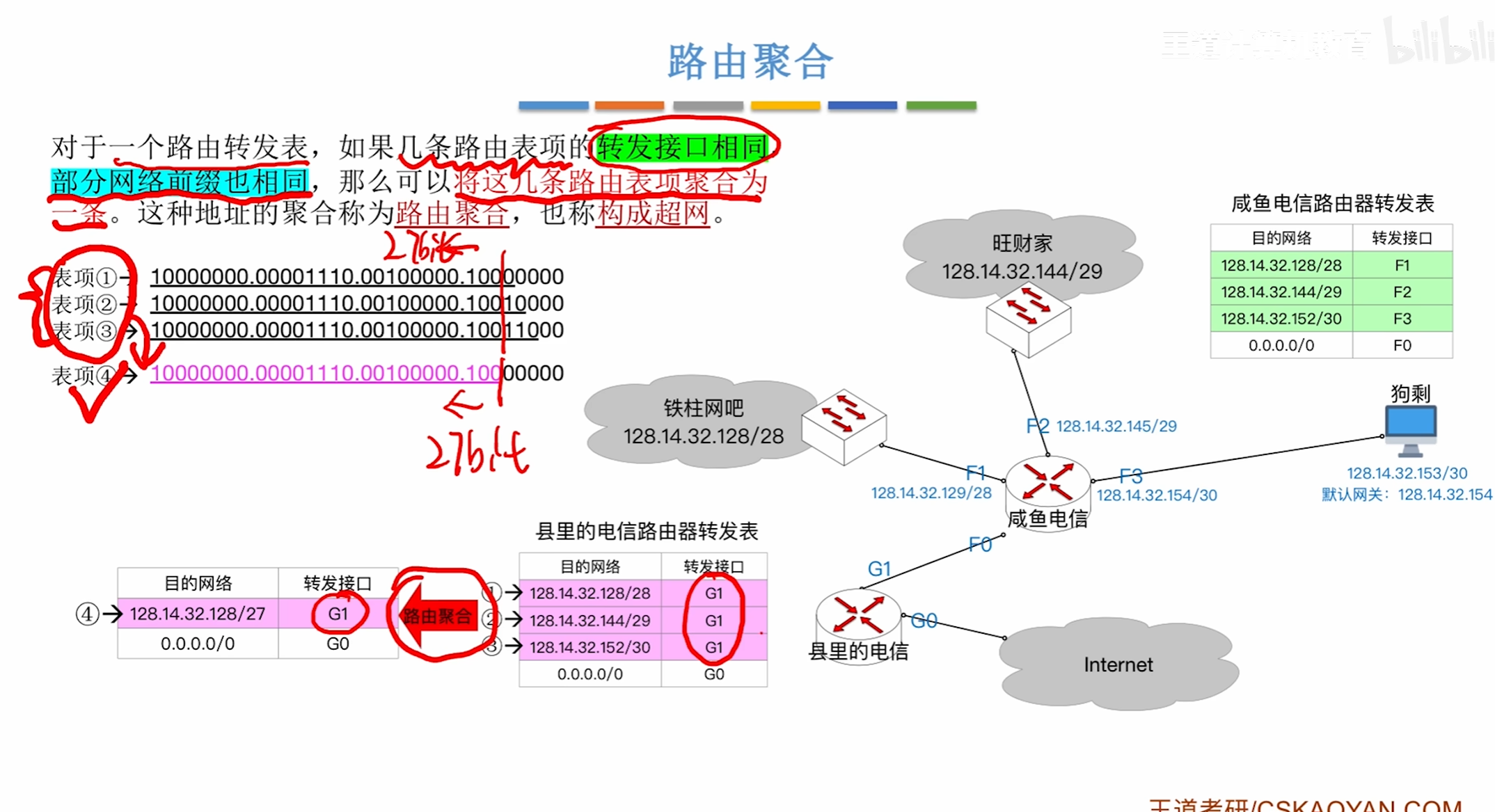
可能会造成无效转发

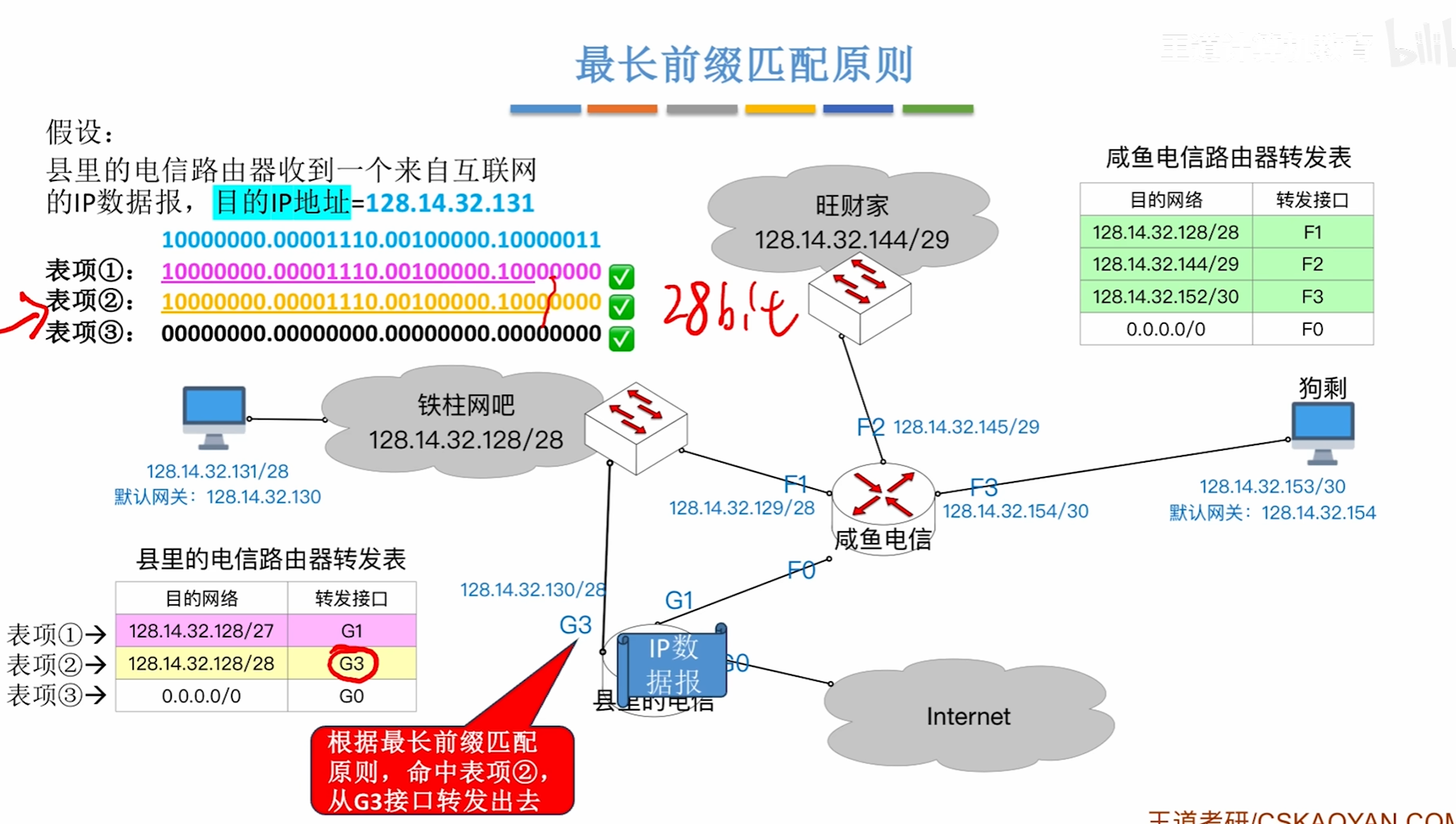
最长前缀匹配原则
即如果一个路由表中多个表项得网络号都能匹配优先选择最长的能匹配到得网络号
NAT技术
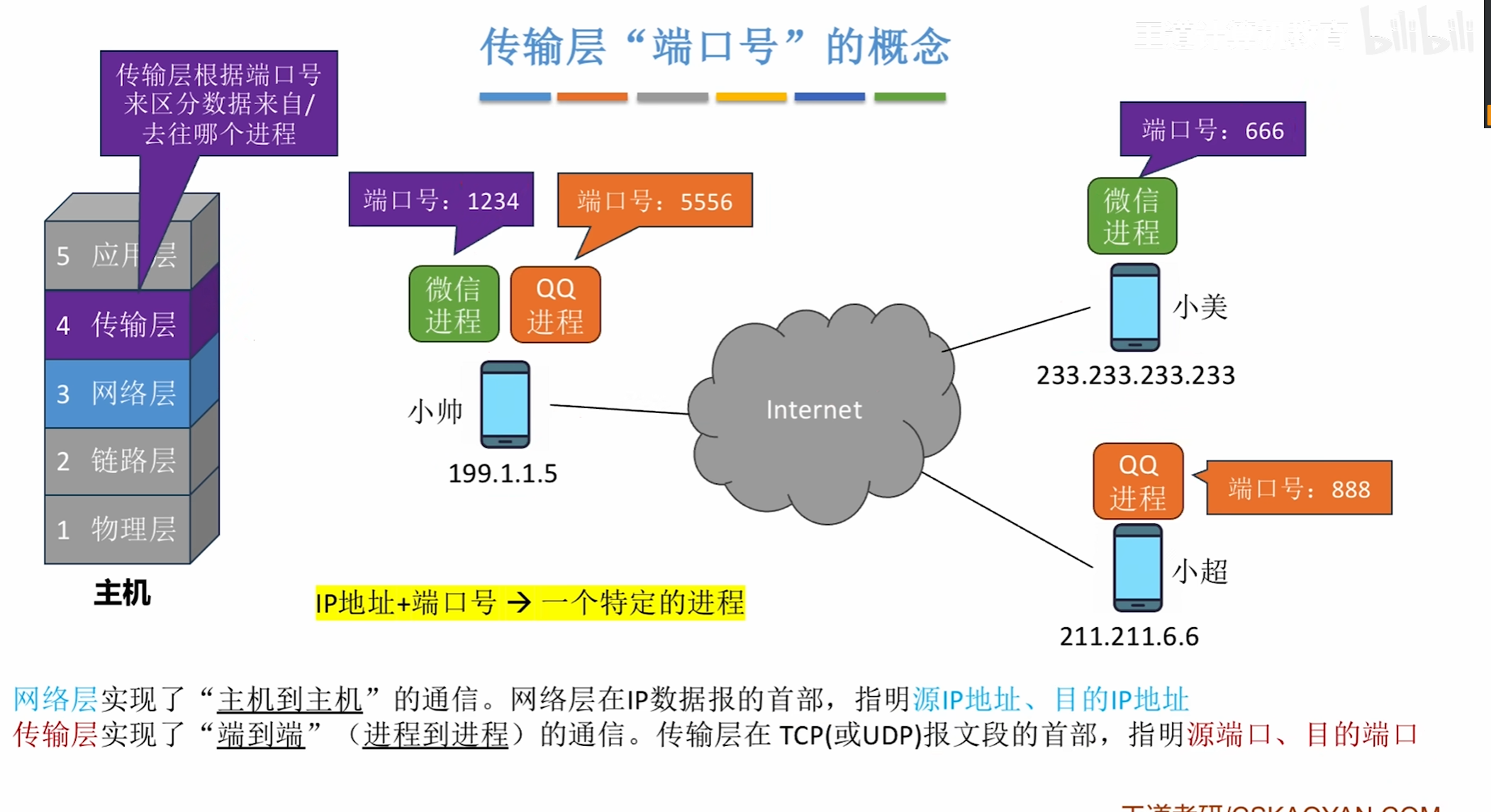
简单的来说就是让同一个局域网内的多台主机共享一个唯一的IP
并通过端口号加以区分
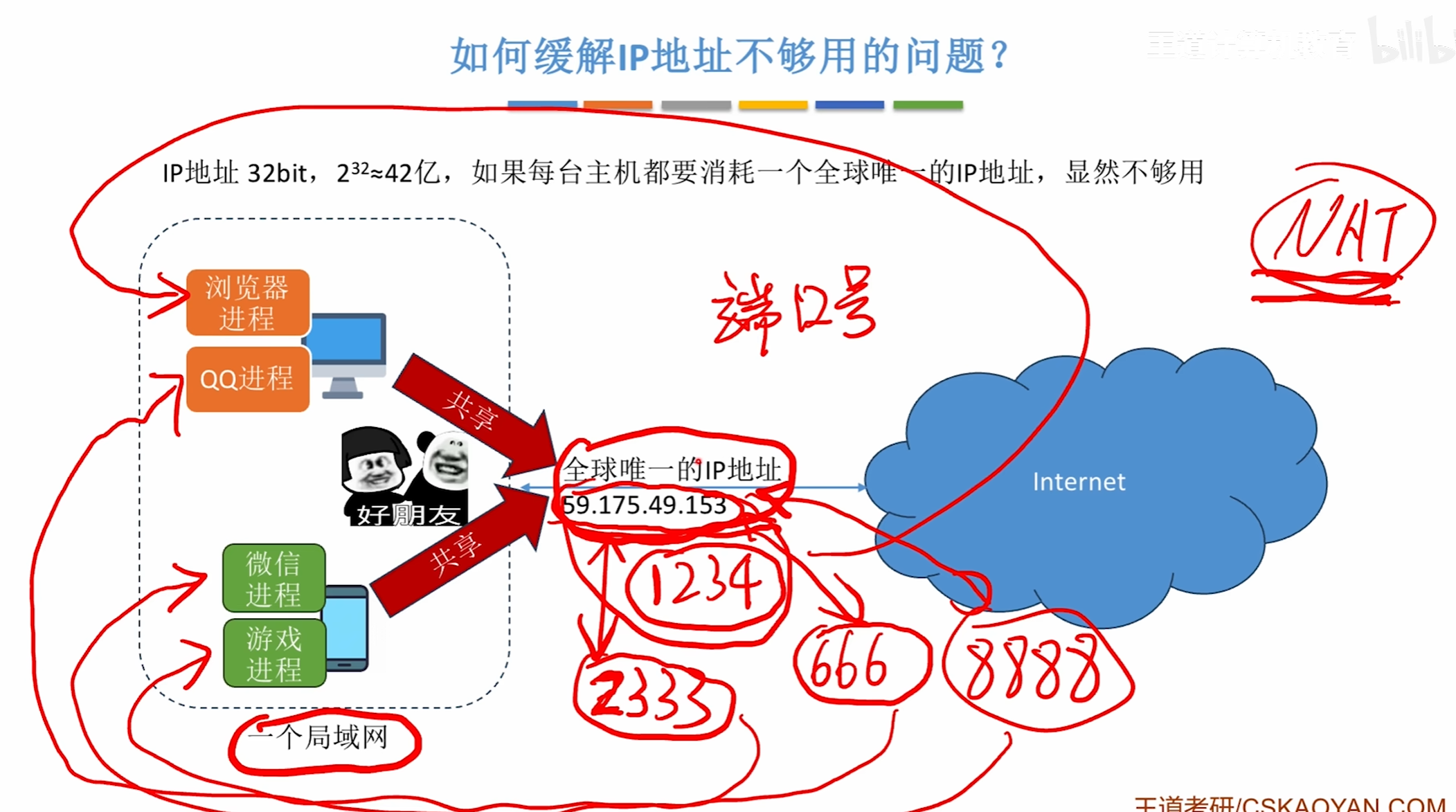
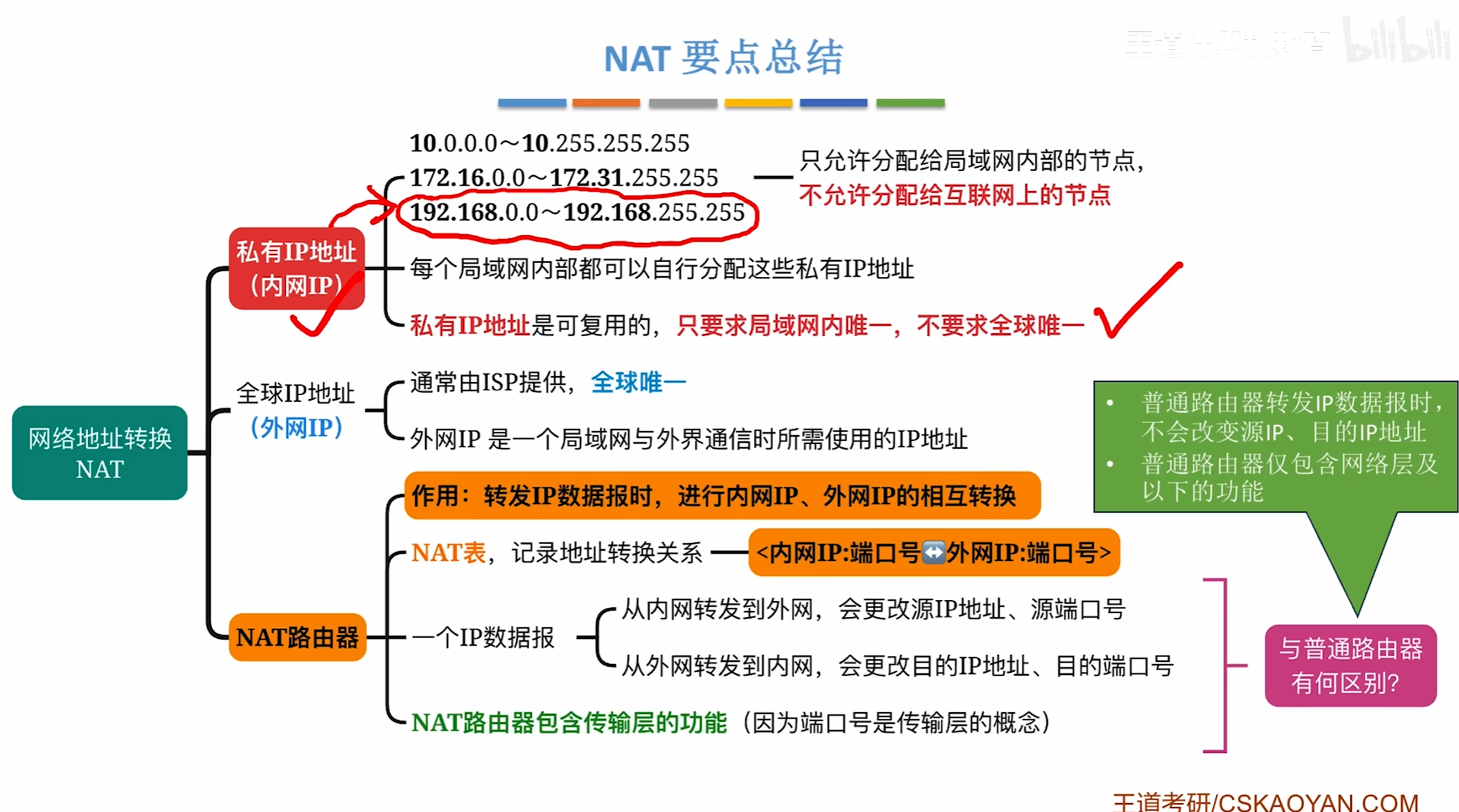
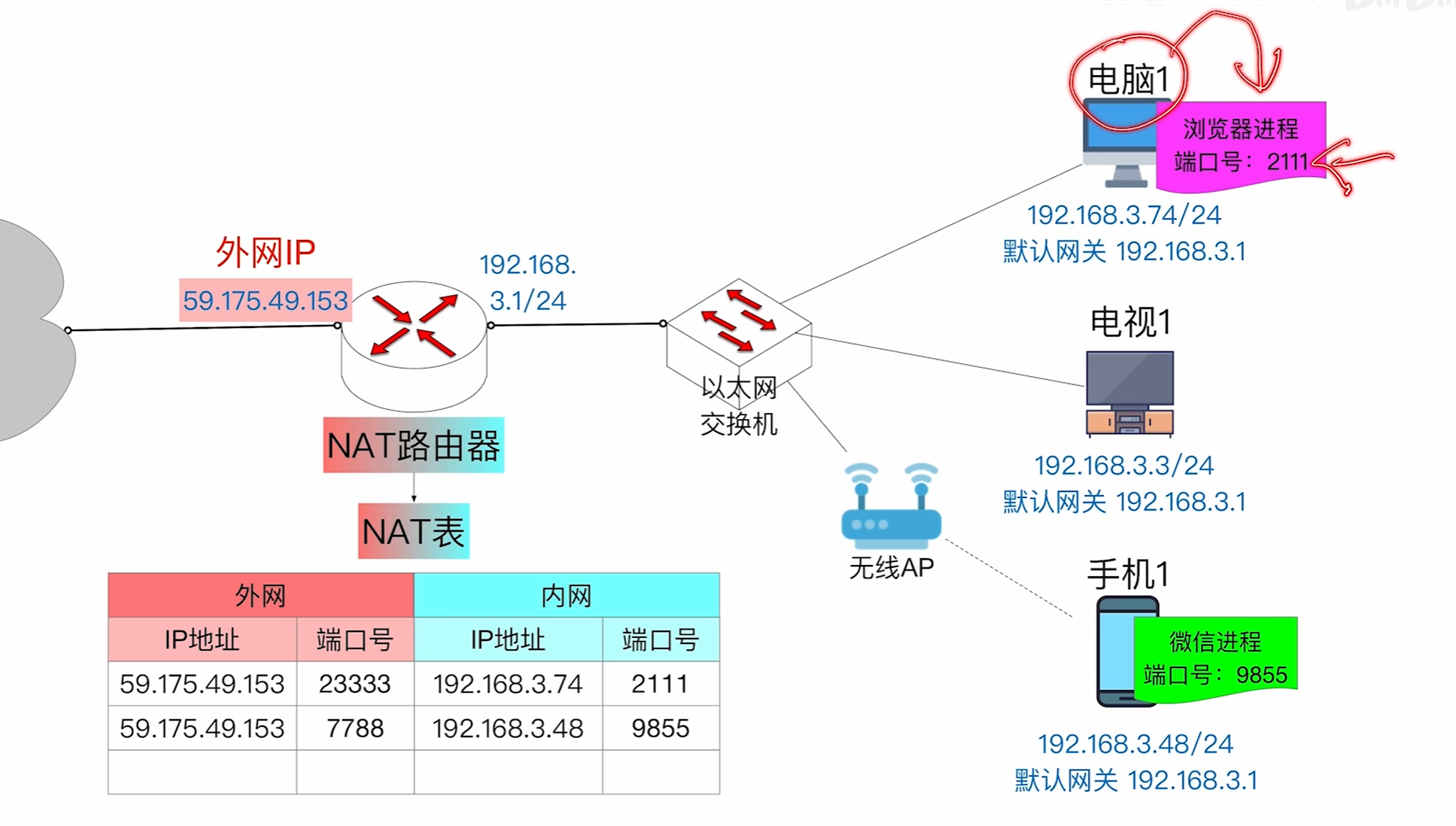
NAT技术会将外网ip地址和内网进行映射
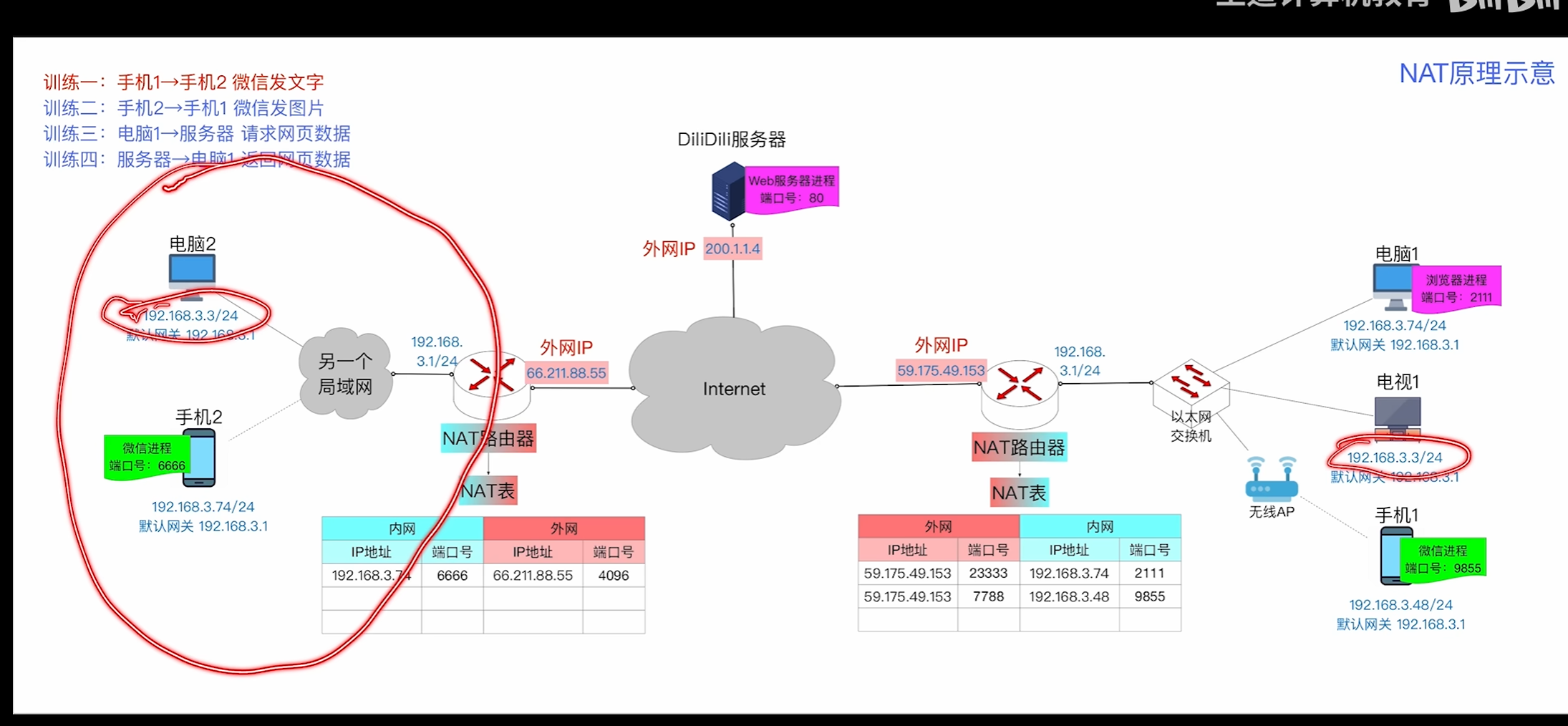
相同的ip地址可以在不同的局域网分配给不同的设备
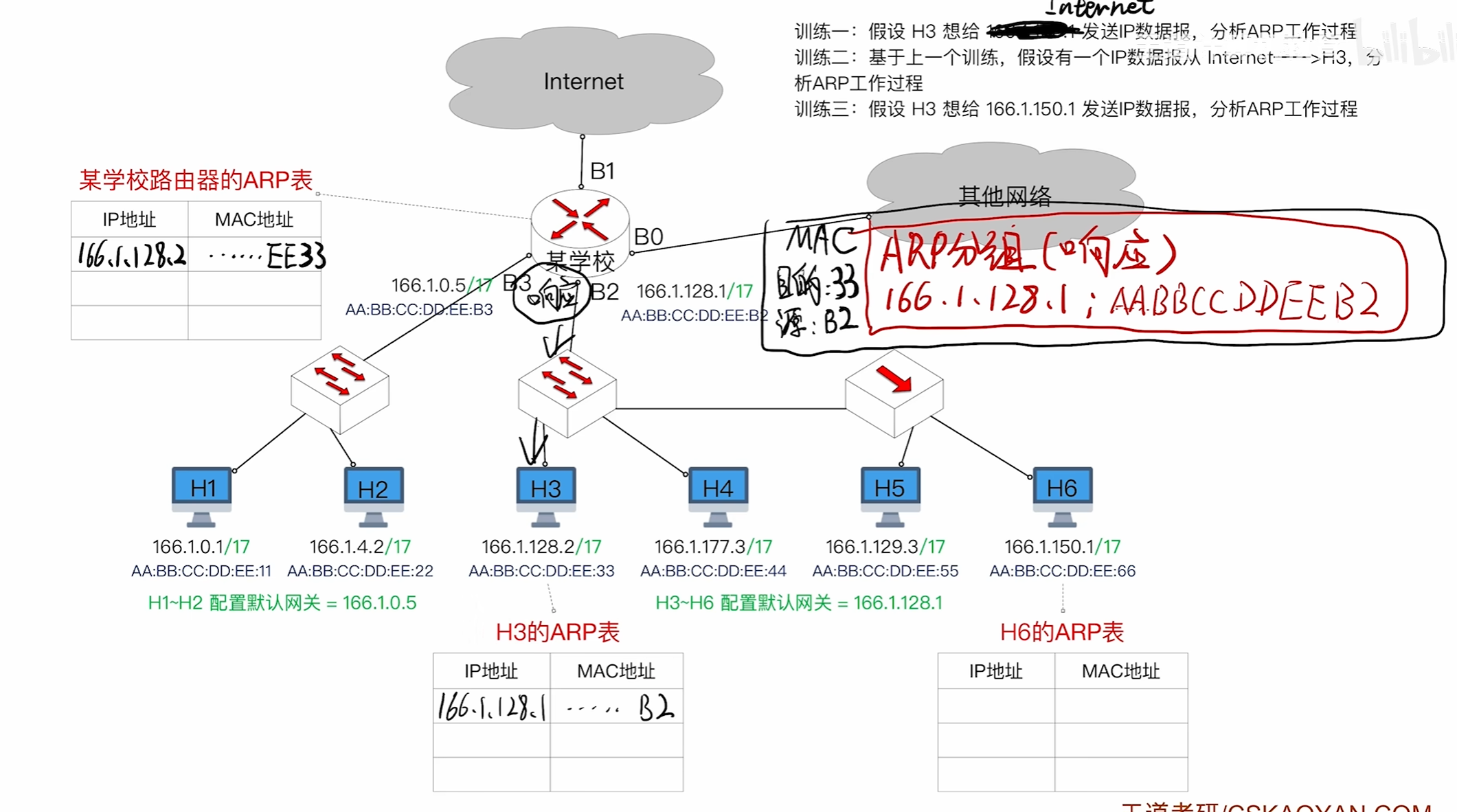
ARP协议
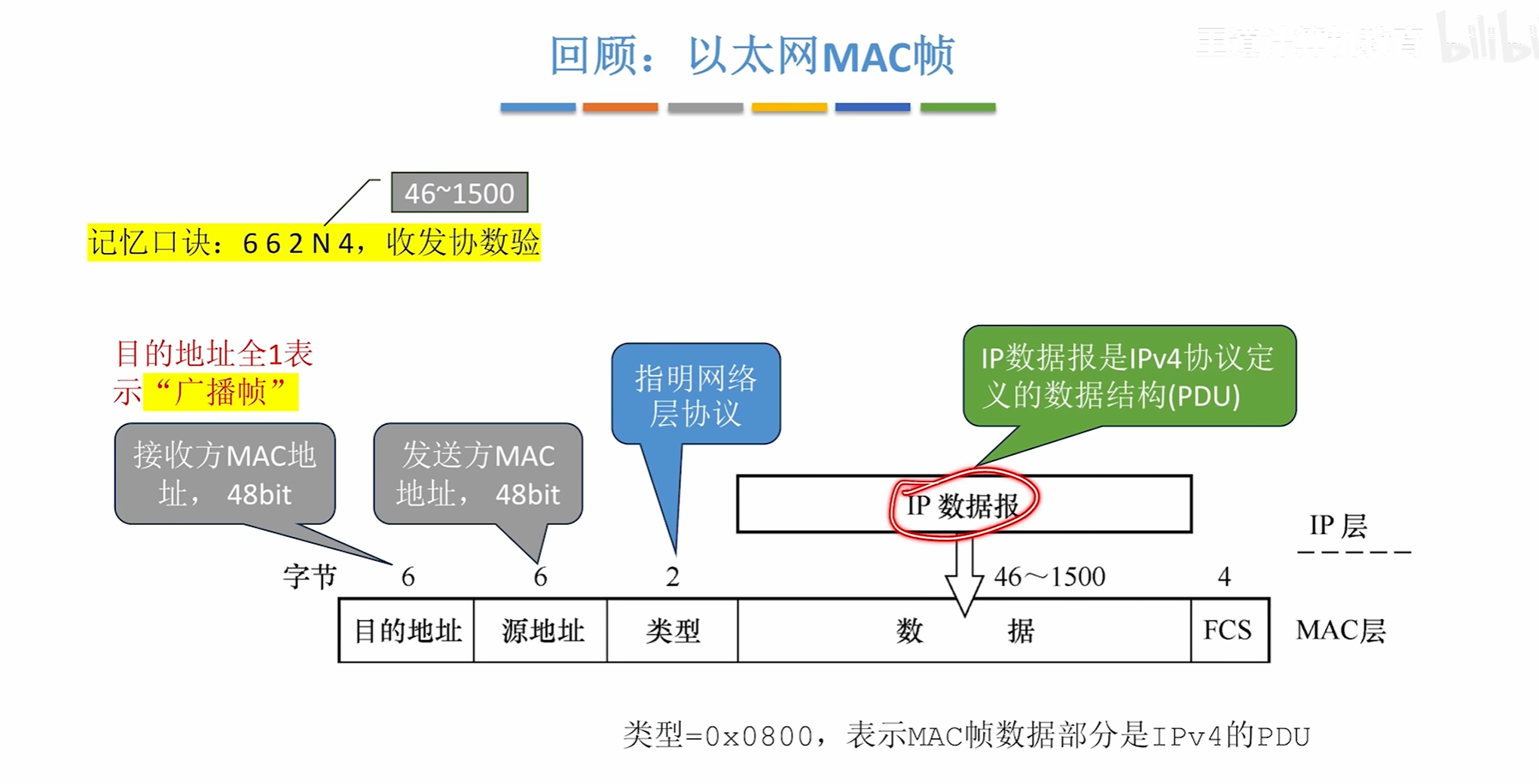
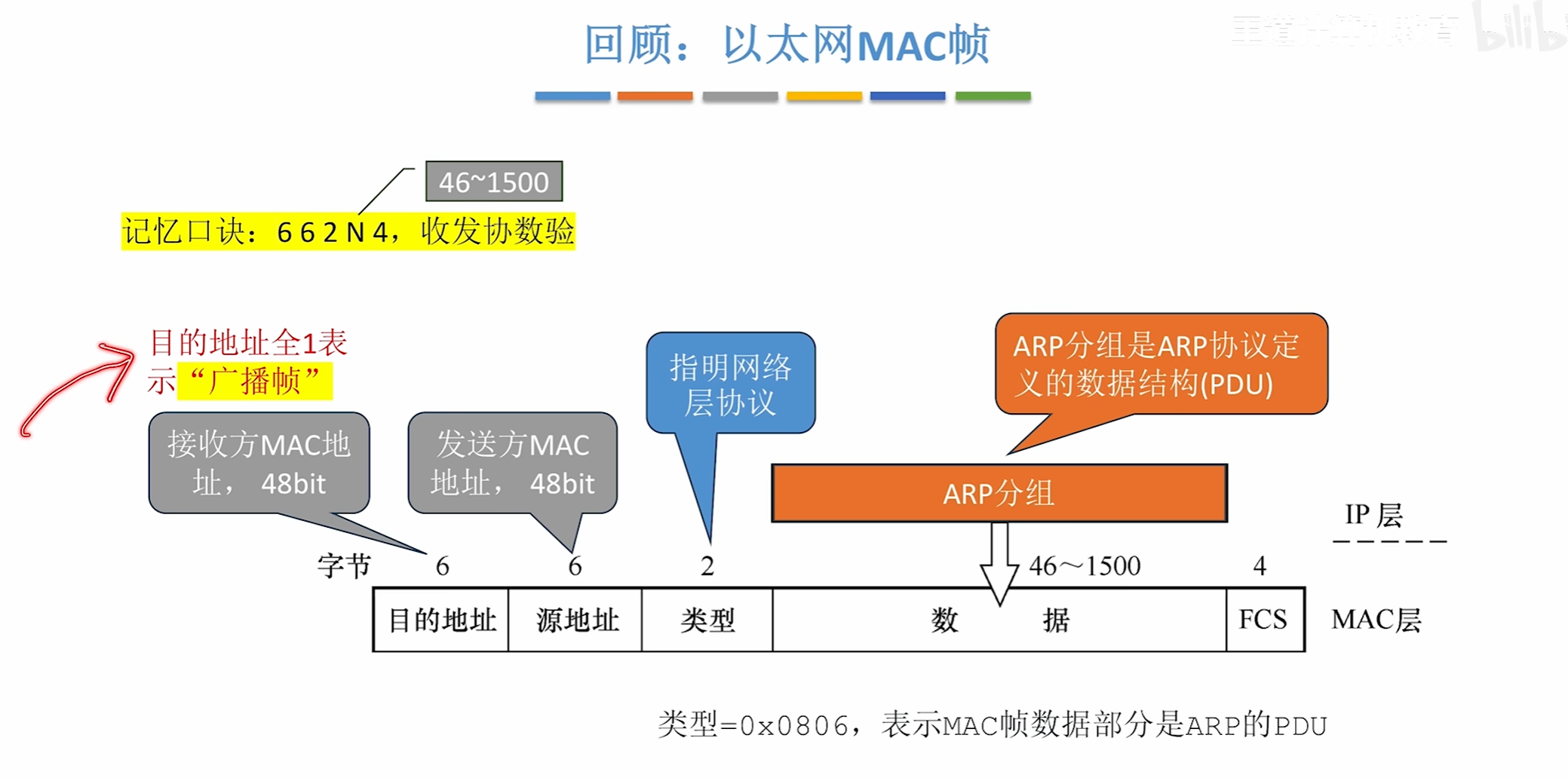
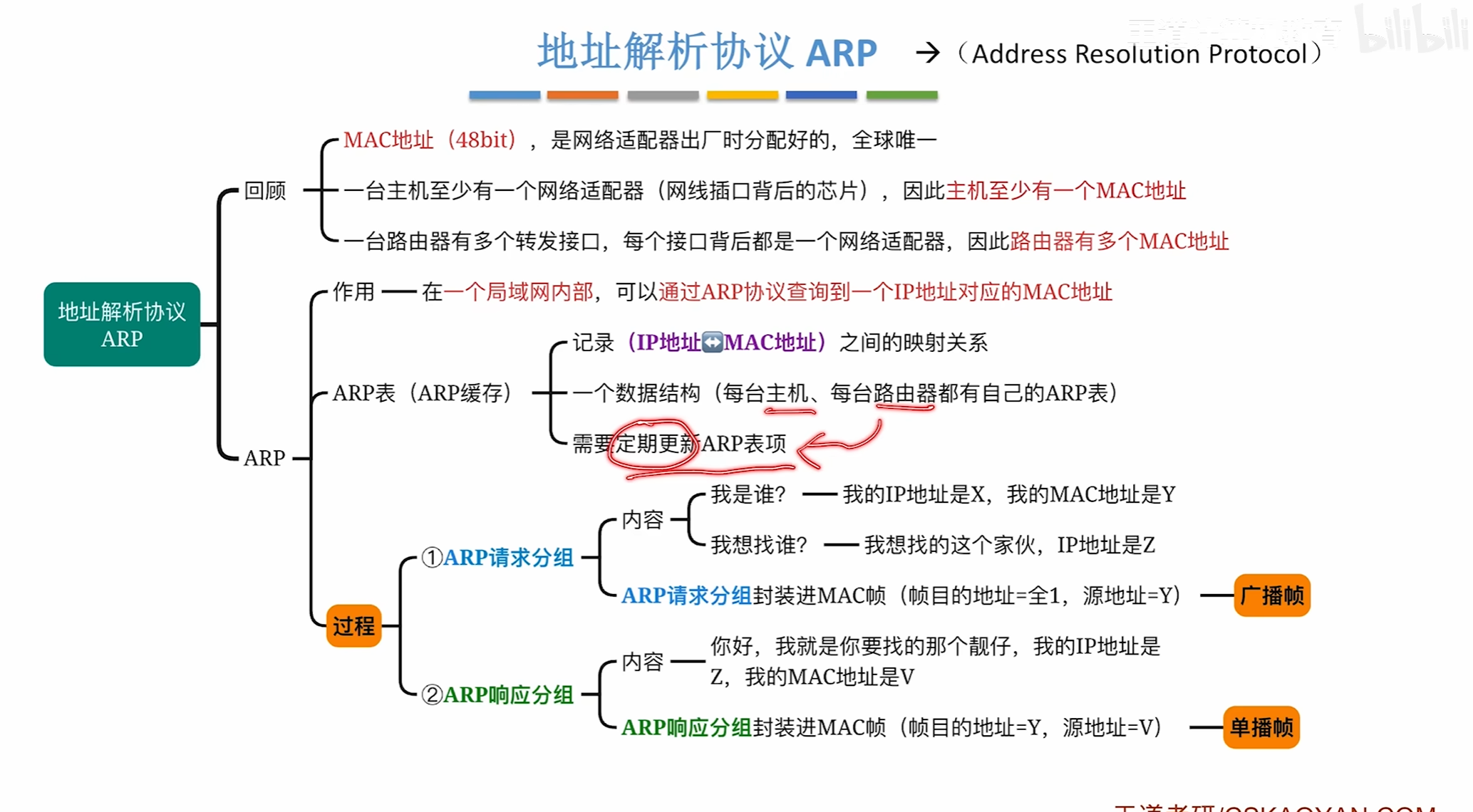
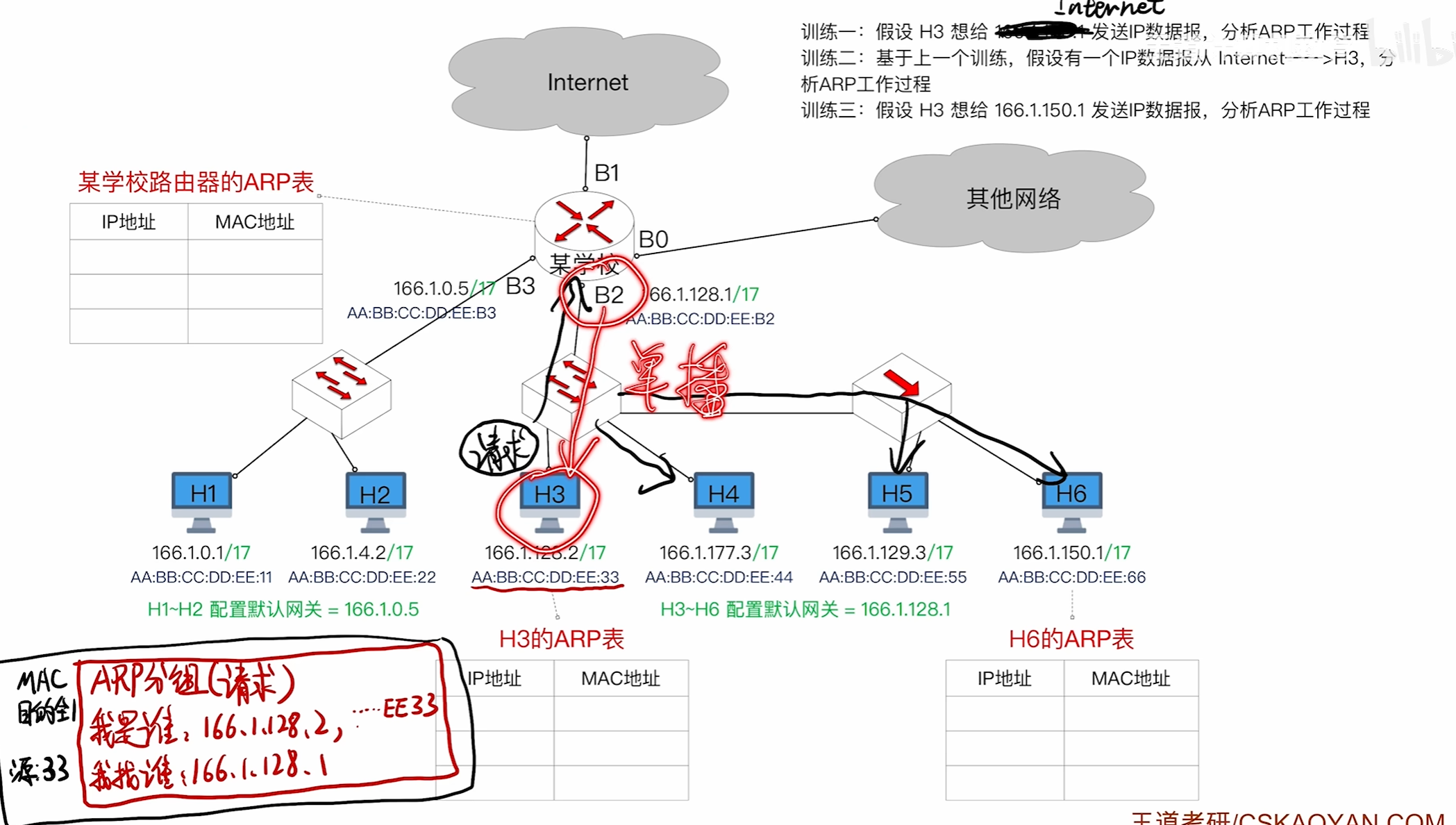
ARP的工作过程
首先由H1构造一个ARP请求分组数据报
将自己的信息写上去,然后此时还不知道目的ip地址在哪所以会先进行一次广播
该交换机上的所有设备都会收到该消息,但只有路由器会接受检查接受发现是自己的ip地址
然后就会回复一个单播帧告诉H3路由器的MAC地址是多少
其中接受ARP请求报文的路由器会顺便将H3的信息写入ARP表中
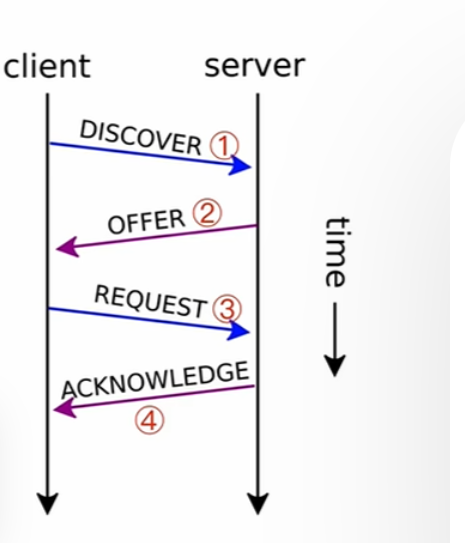
DHCP
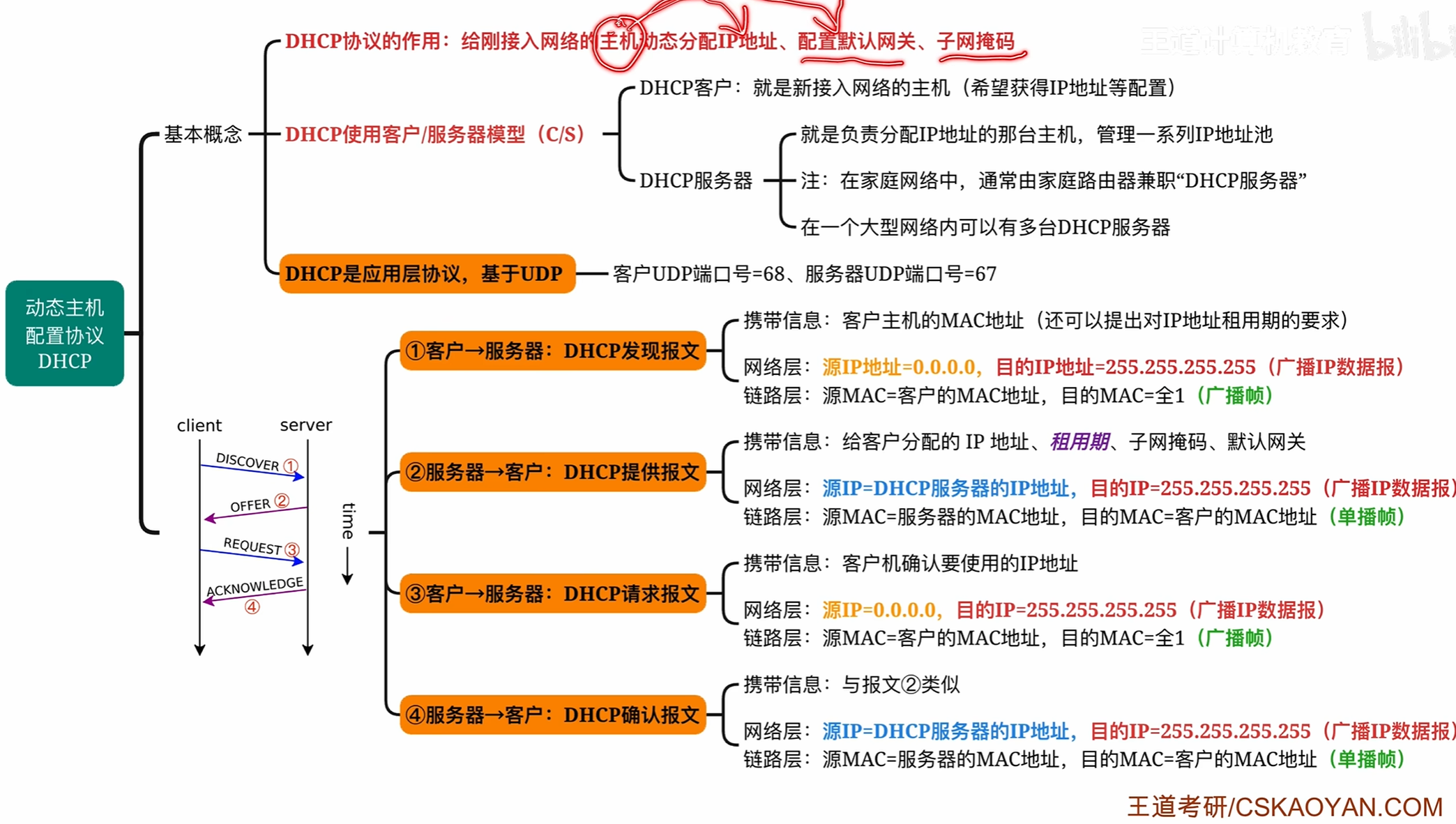
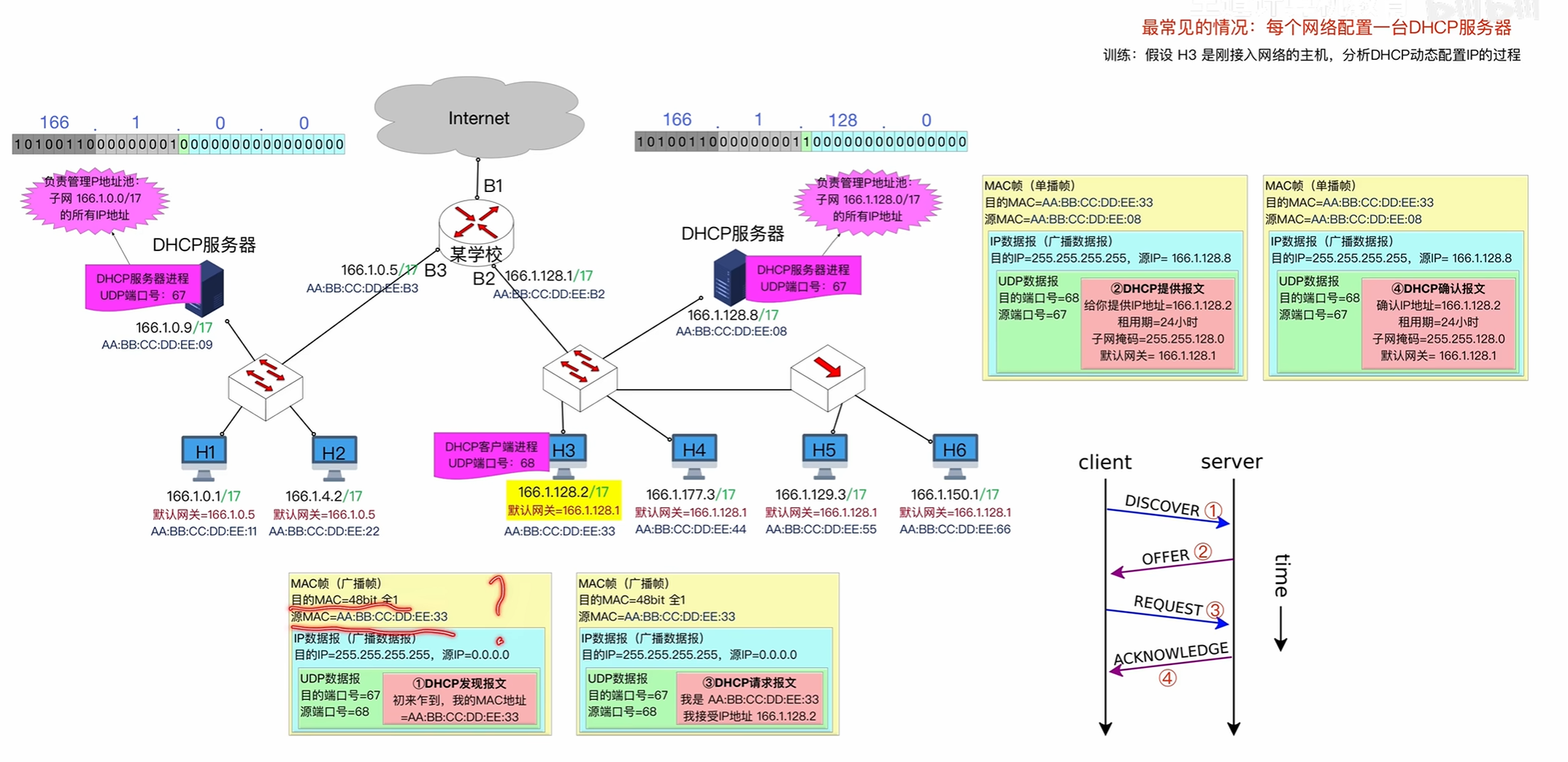
其中这是一个新主机接入网络时要进行的步骤
discover请求帧
因为一开始刚接入网络还没有自己的ip地址所以原ip地址为0表示自己是本网络上的主机
接着他也不知道DHCP的地址所以需要将ip数据包发送成一个广播帧
即目的ip全1
MAC帧会写入自己的mac地址,其中目的地址依旧全1广播帧
其中所有的主机节点都会收到MAC帧但是并不会接受
因为当他们拆解数据报到UDP数据报时,检查发现目的端口号为67
而67是网络协议中一个特殊的端口号不能存在进程特意使用这个端口号所以其他的主机会将其丢弃
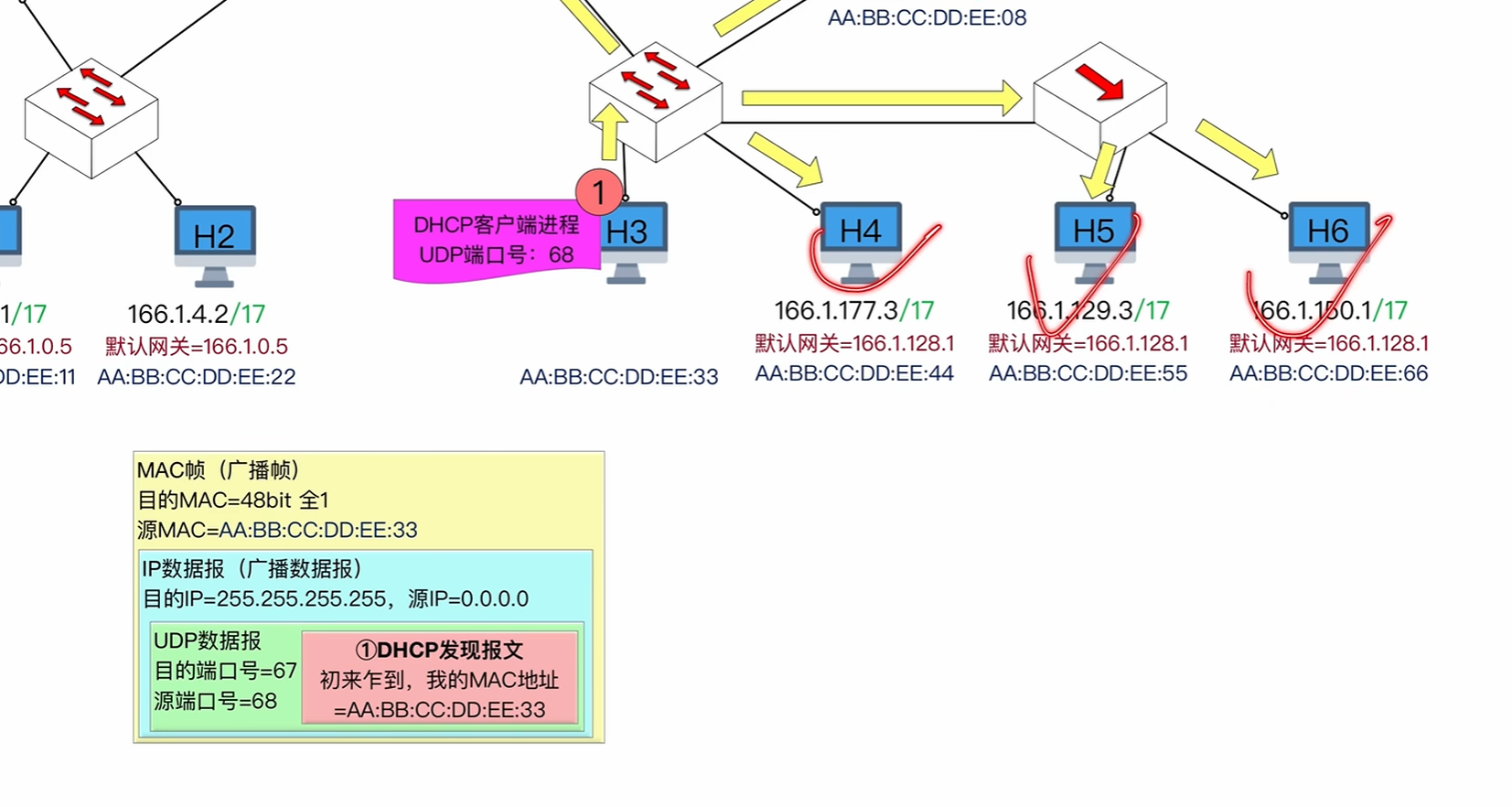
offer报文
其中offer报文如下
会指名给设备的ip地址和目的ip地址
但是ip数据报依旧是广播地址,因为目前该设备还没有分配到ip地址
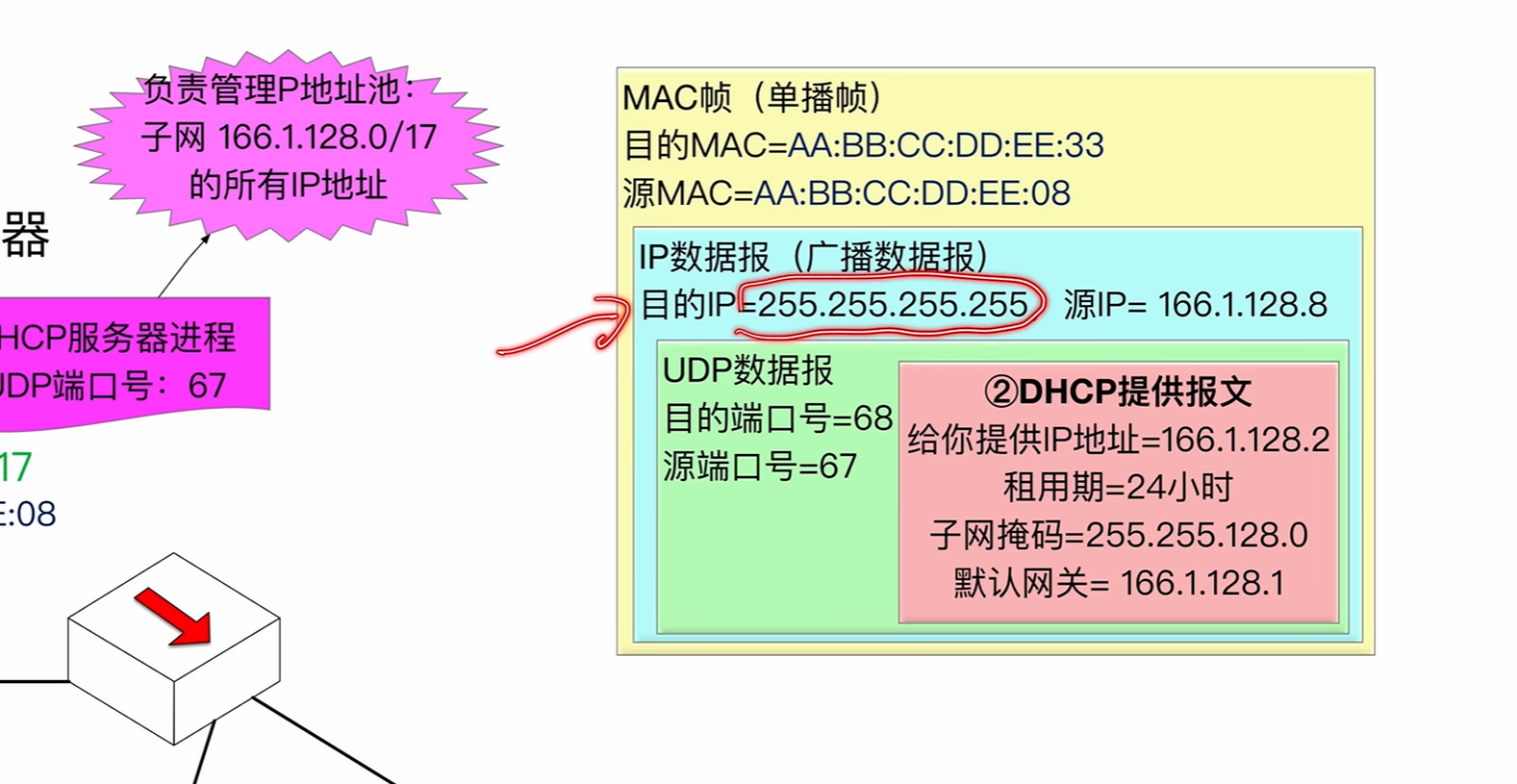
request报文
告知dhcp我是谁
其中为什么依然是广播报文因为在一个局域网中会有多个DHCP服务器,当第一次discover请求发送出去的时候会受到多个offer但是最终设备只会选择一个ip地址作为自己的地址所以他还需要广播出去,告诉别的DHCP我选择的ip地址是哪一个

Acknowledge报文
同样需要广播因为还没有拥有自己的ip地址
但是MAC帧能够精准送达

ICMP协议
会直接写在ip数据报中,作为数据部分
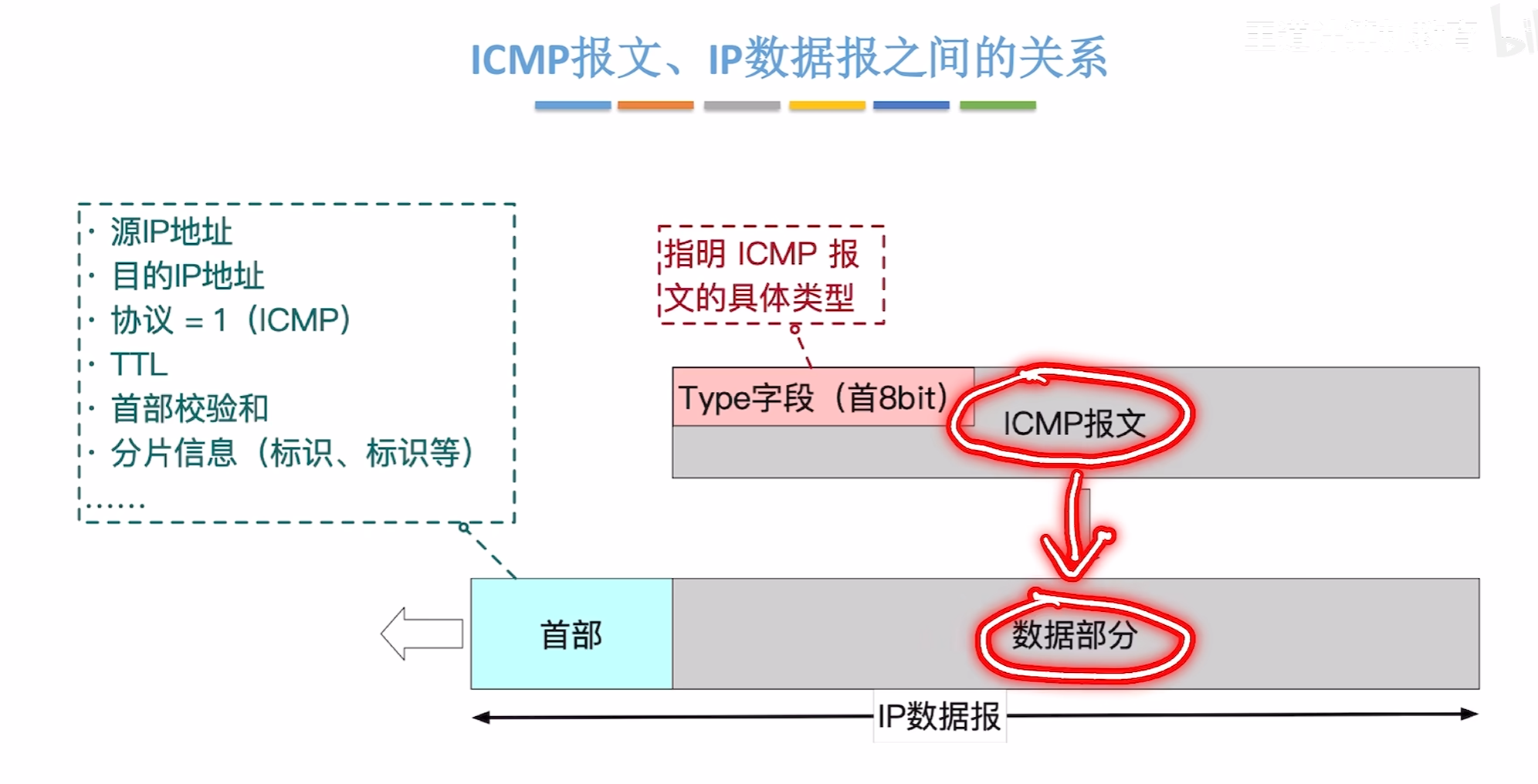
其中ICMP报文的type类型是下图所示的差错报告报文
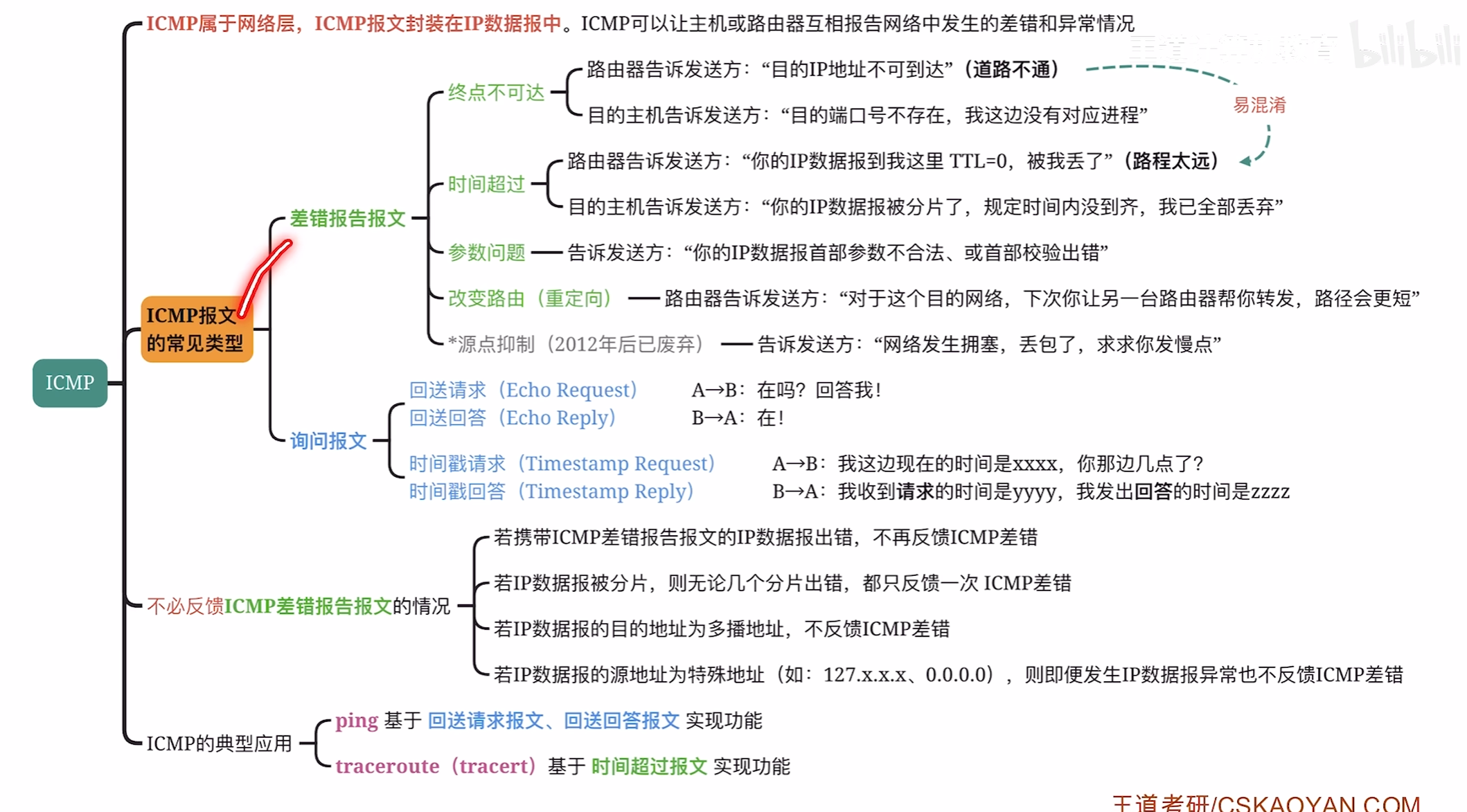
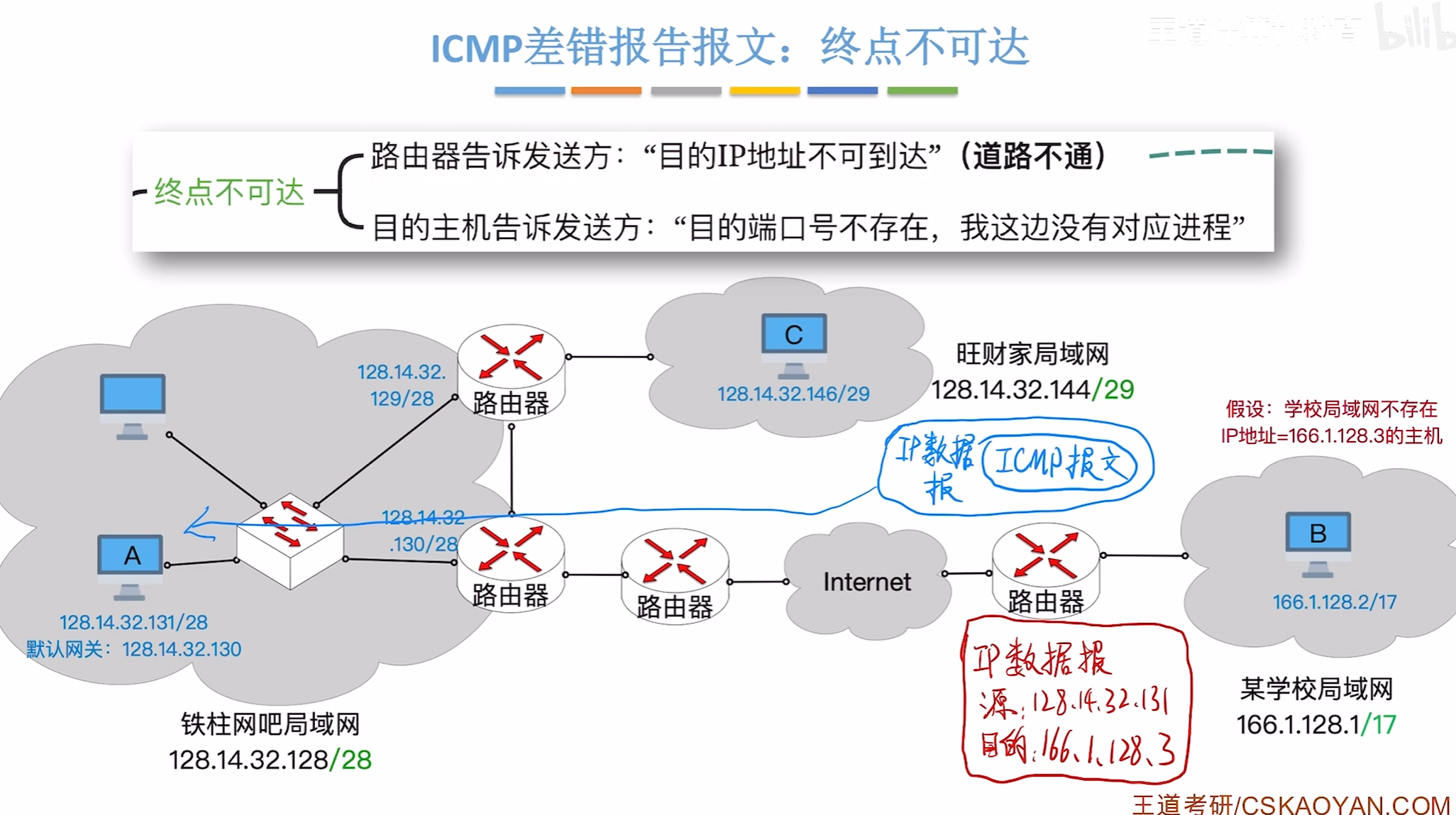
终点不可达
比如你的目的地址不存在或者端口号不存在,交付上层传输层发现端口号不在也会报错
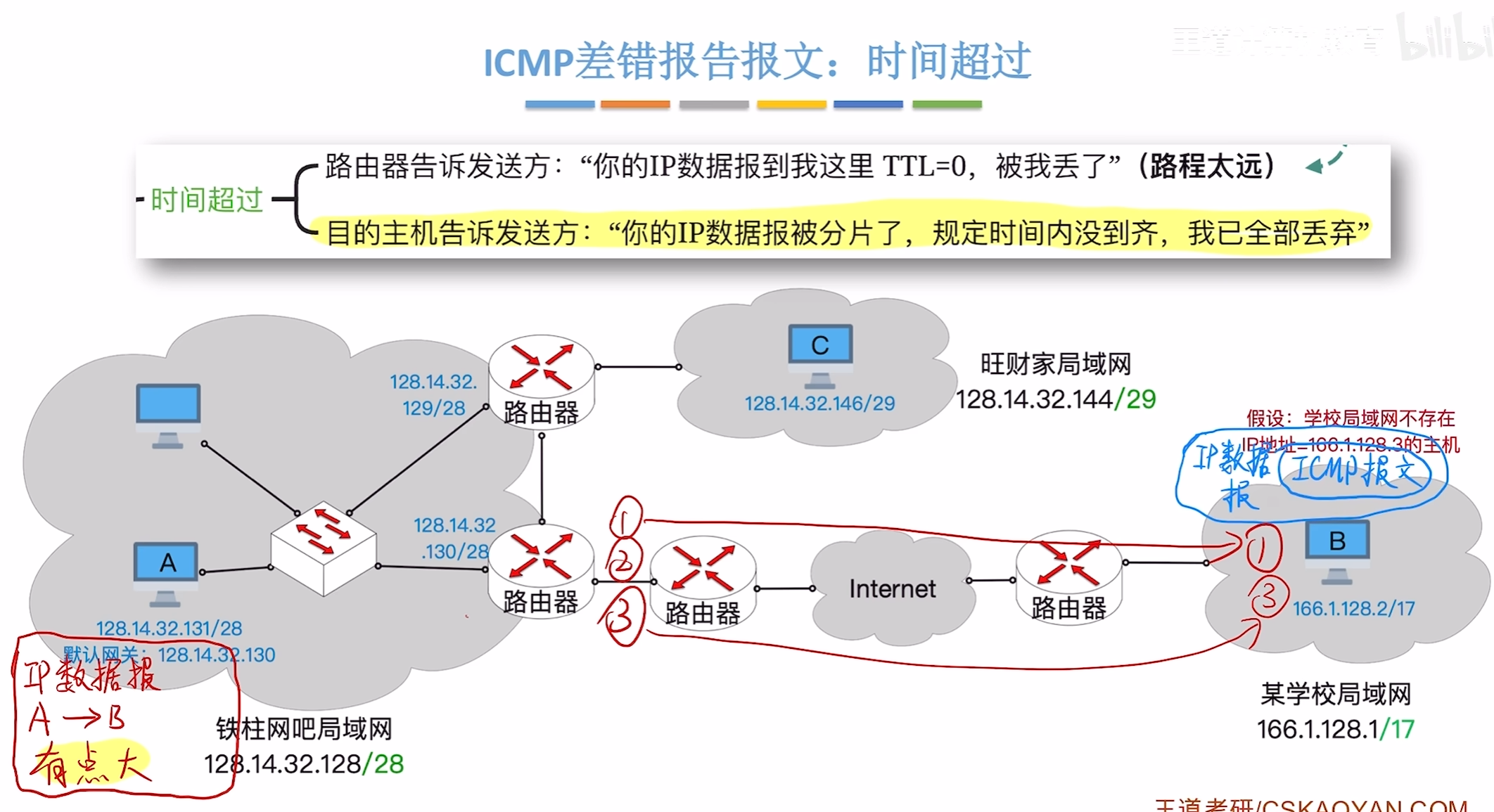
时间超过
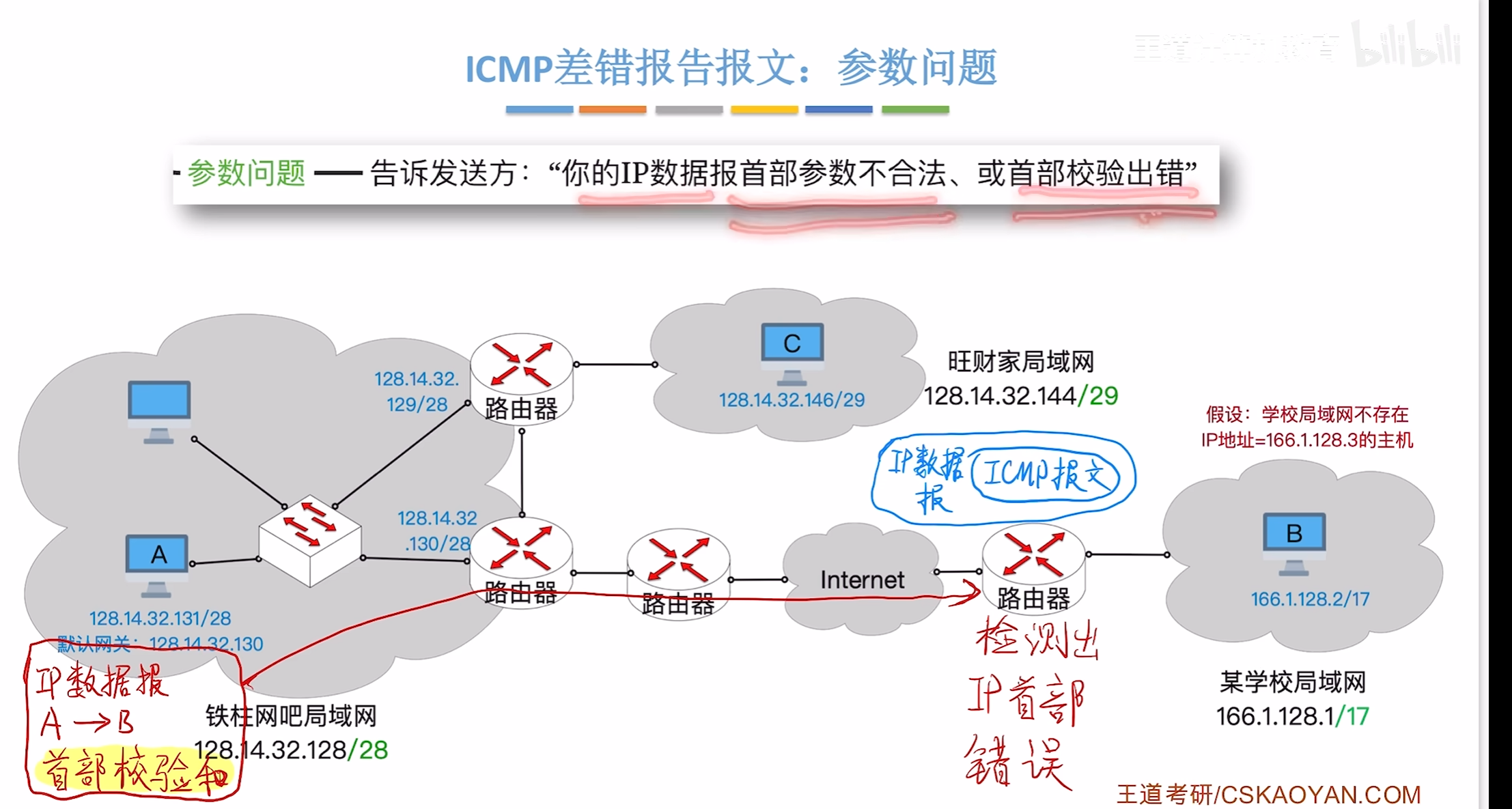
参数问题
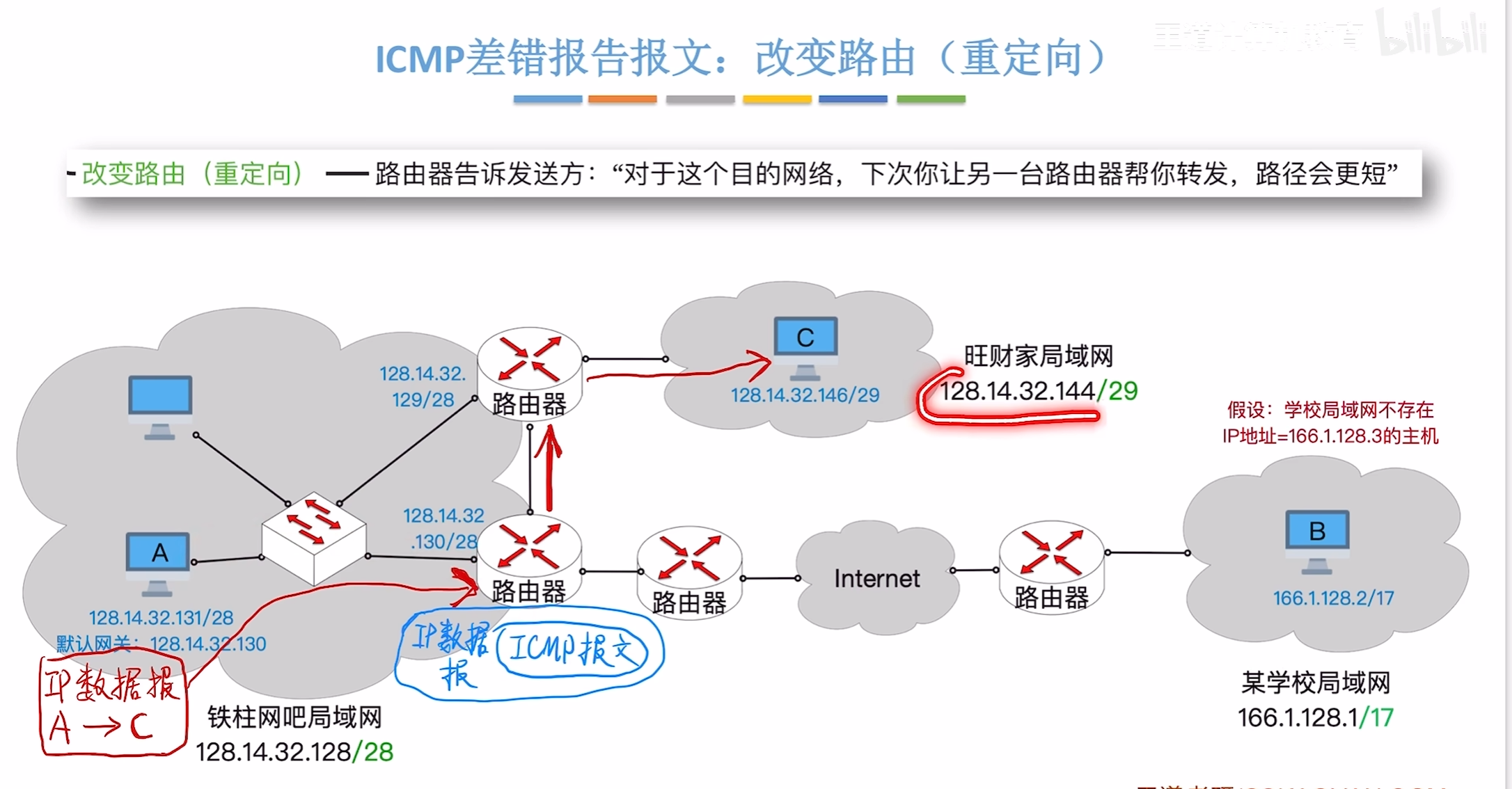
路由重定向
源点抑制
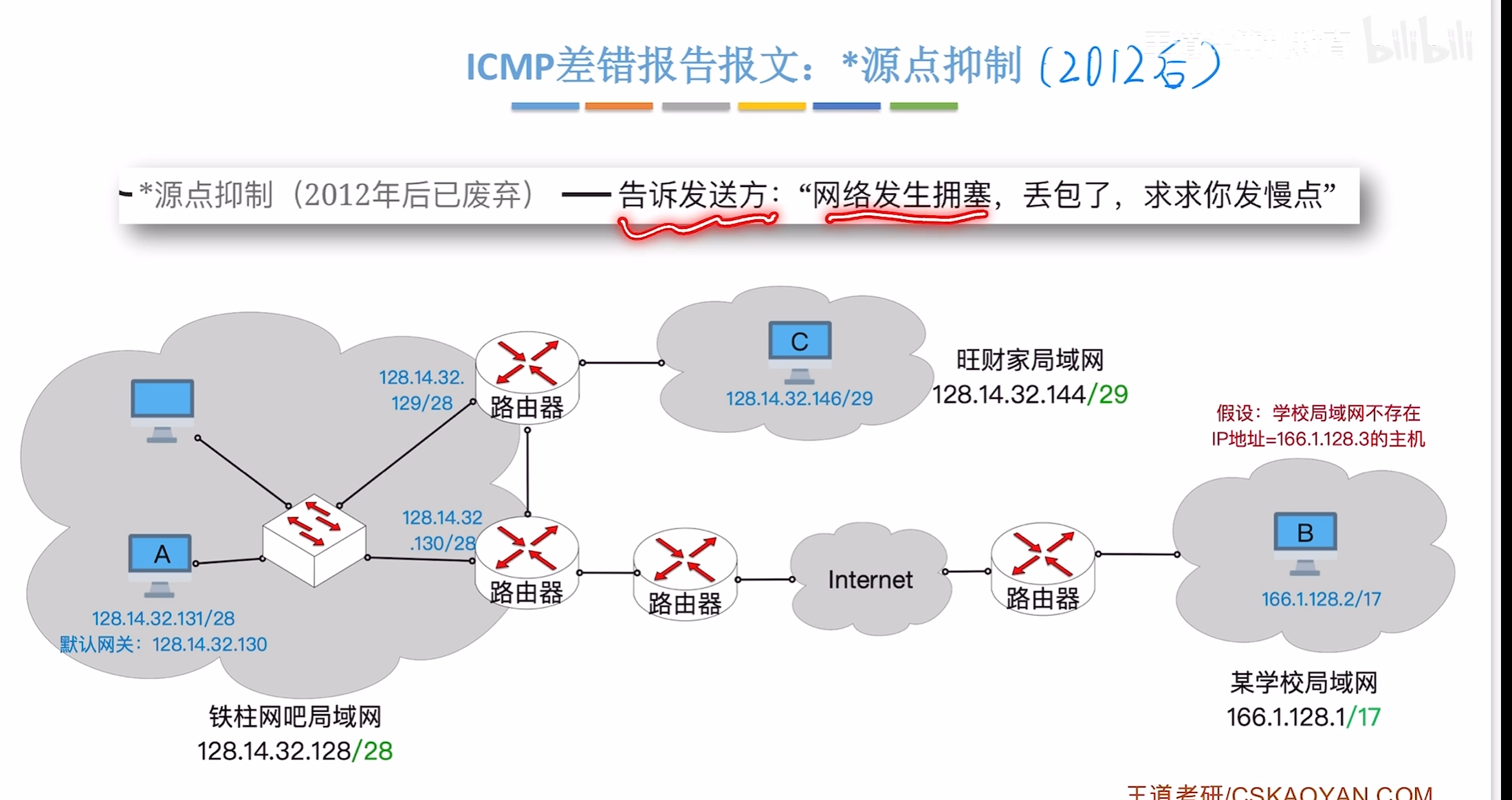
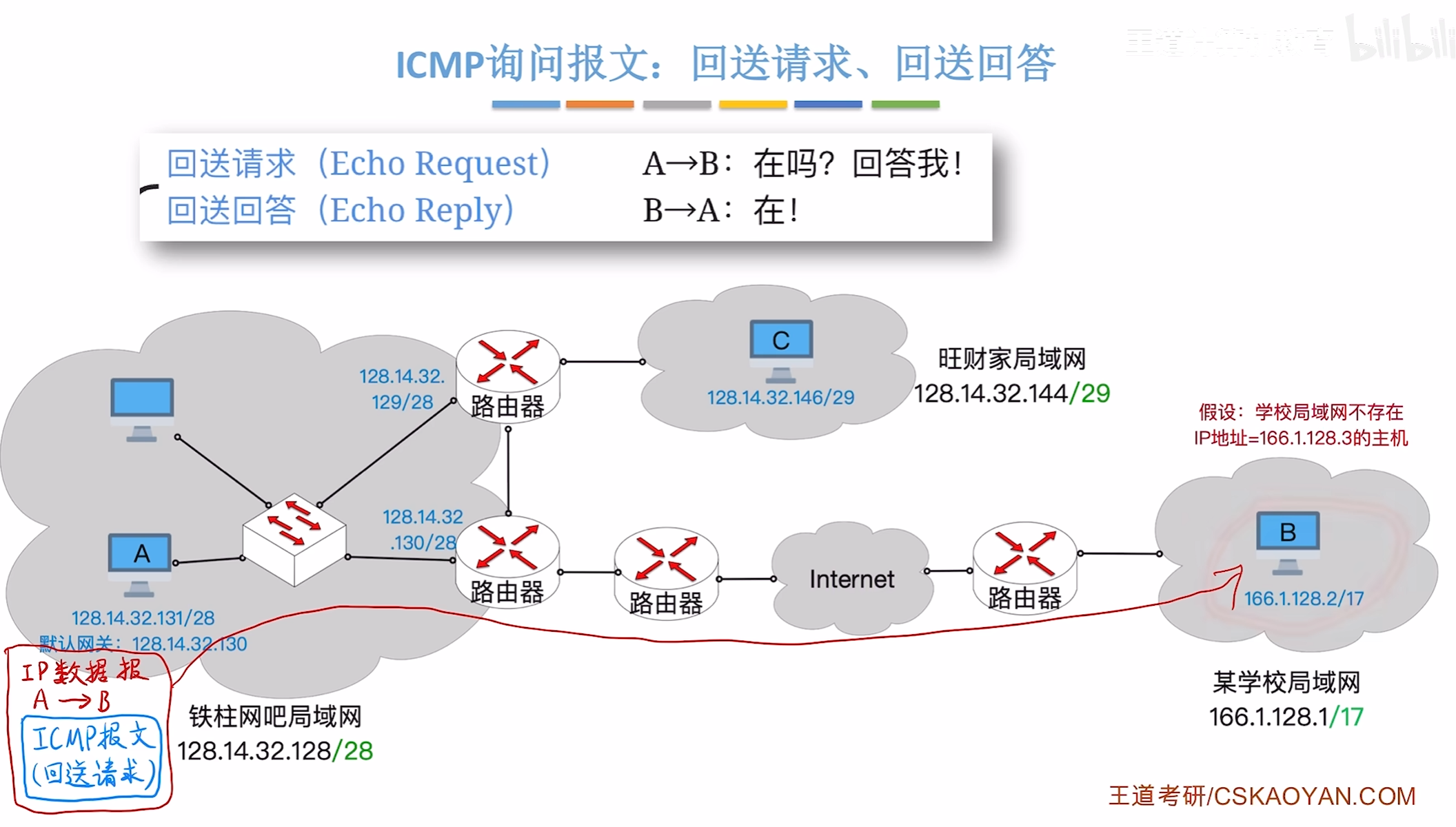
询问报文
回送请求,回送回答
测试和另一个节点的链接
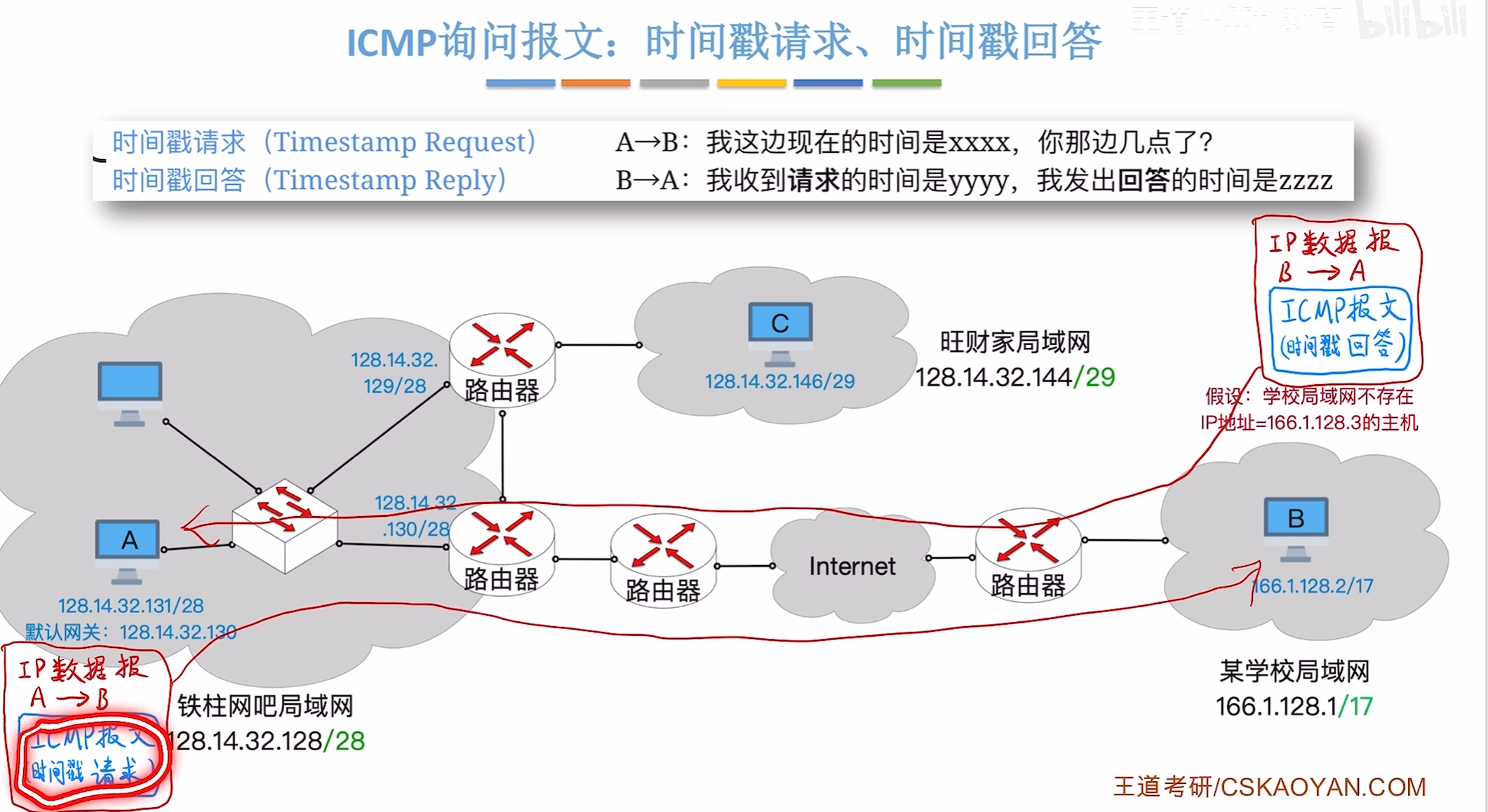
时间戳请求
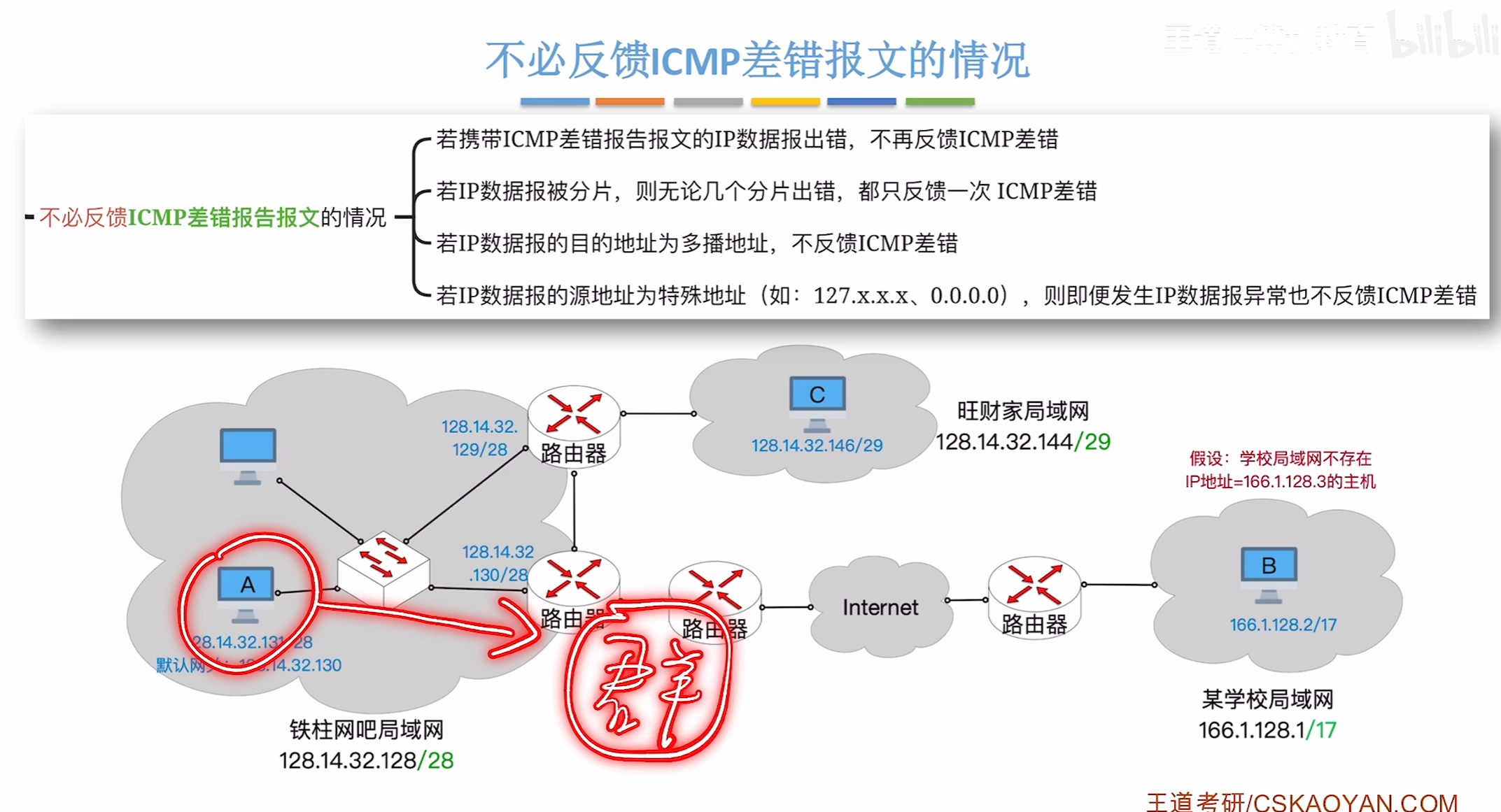
不会反馈差错的情况
traceroute
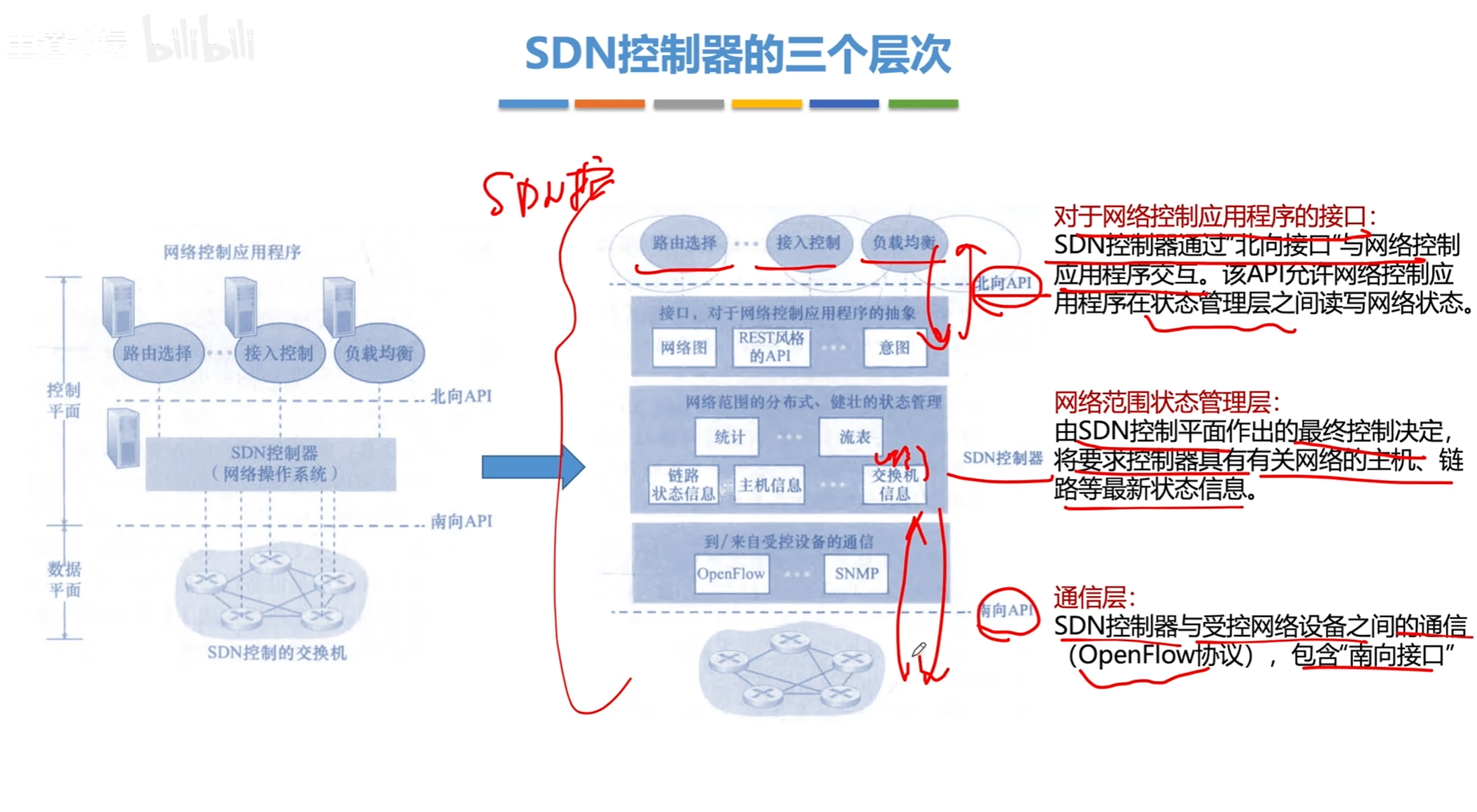
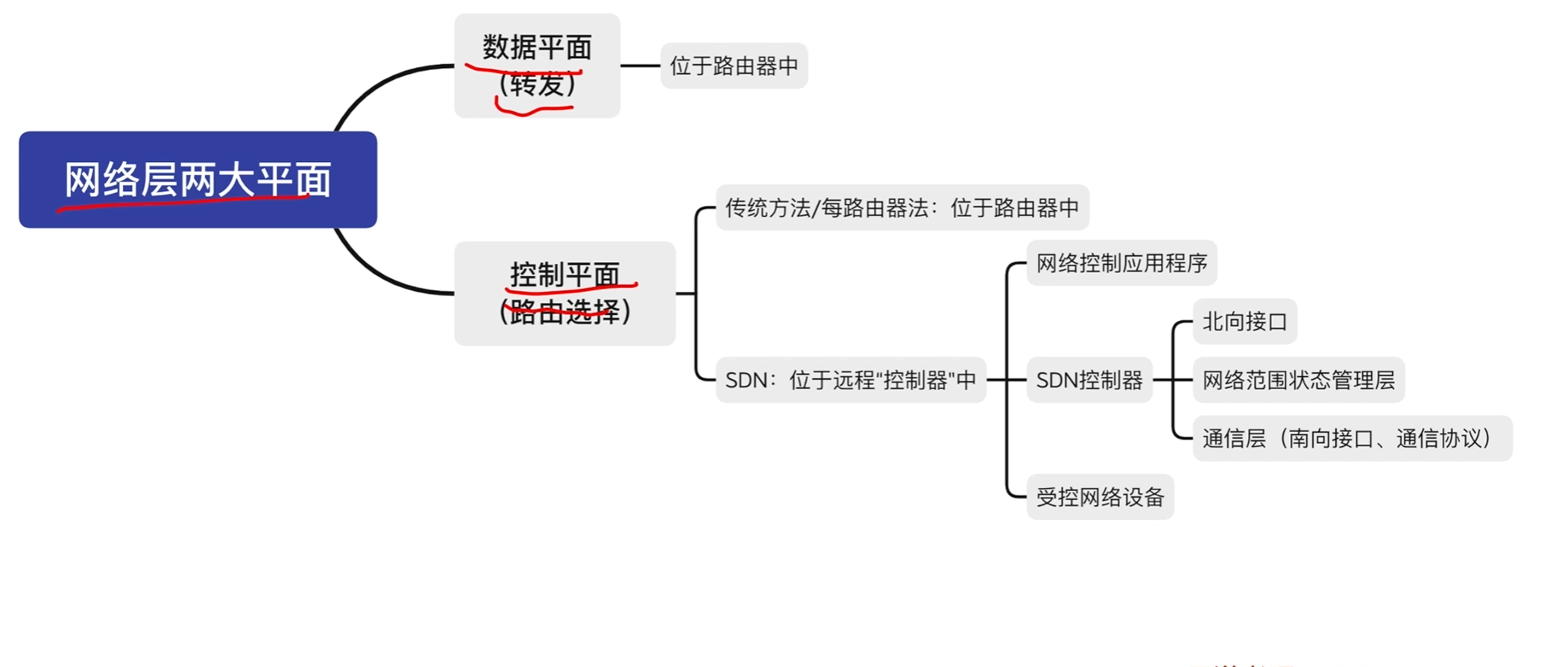
SDN
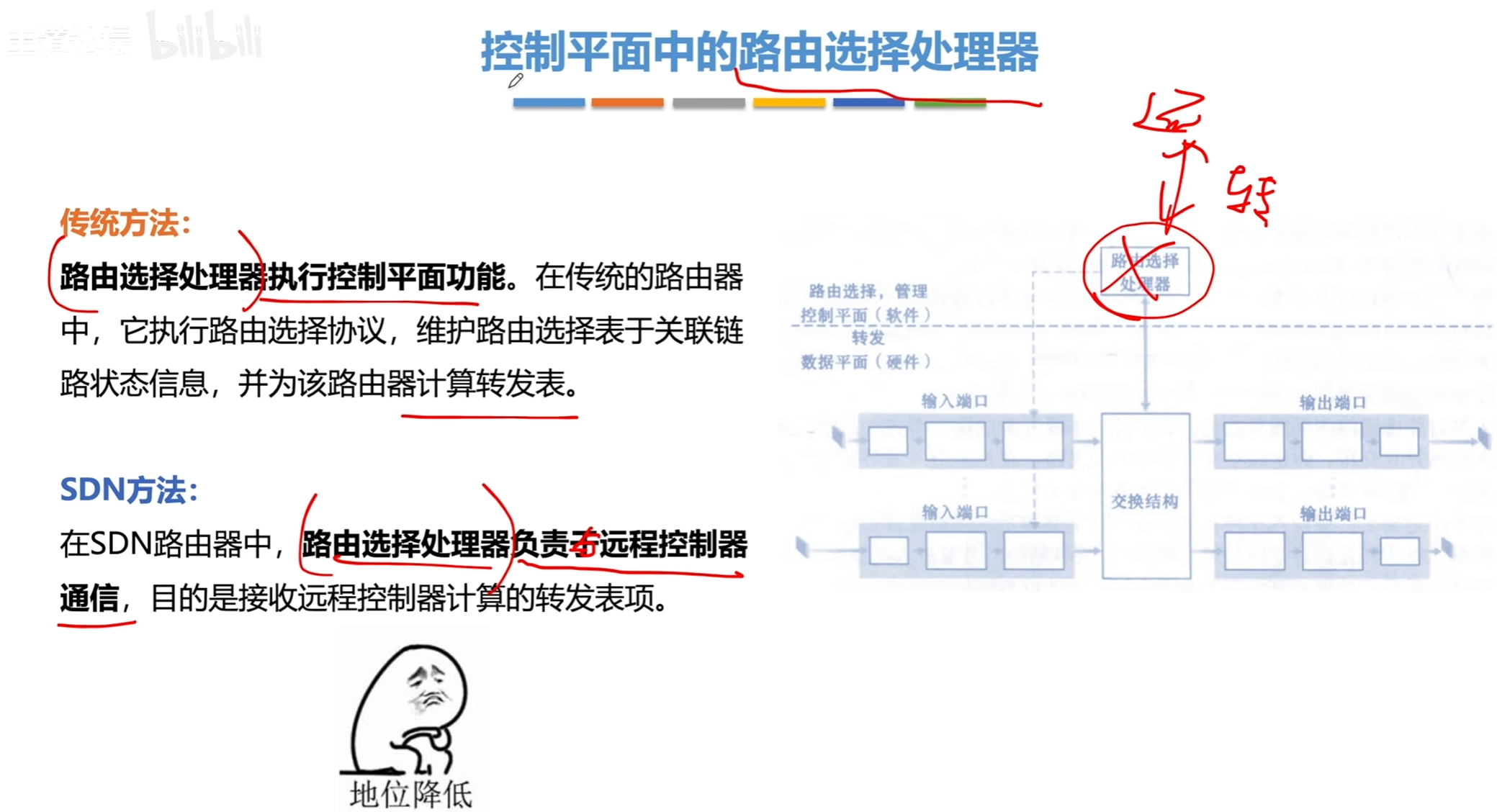
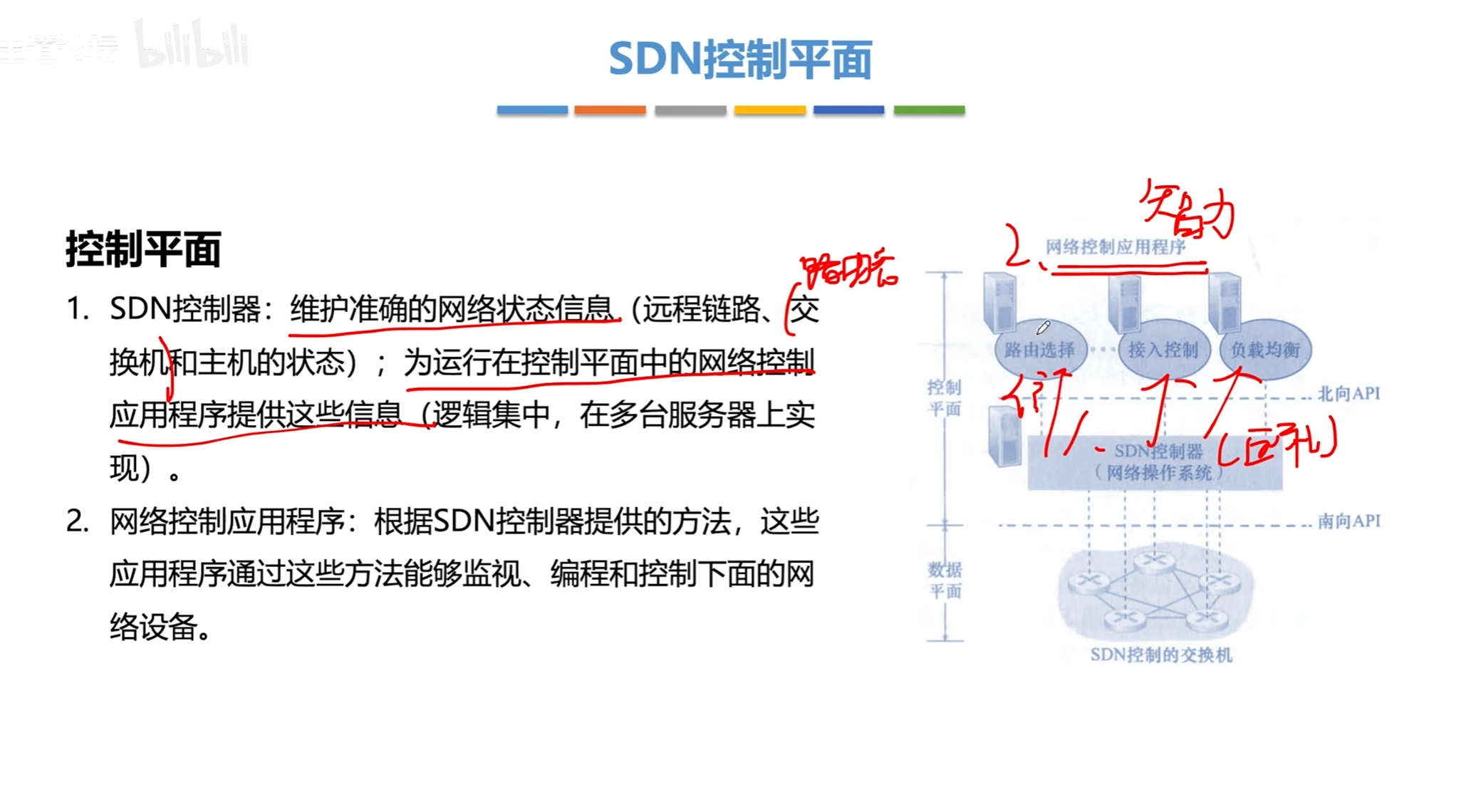
SDN三个层次
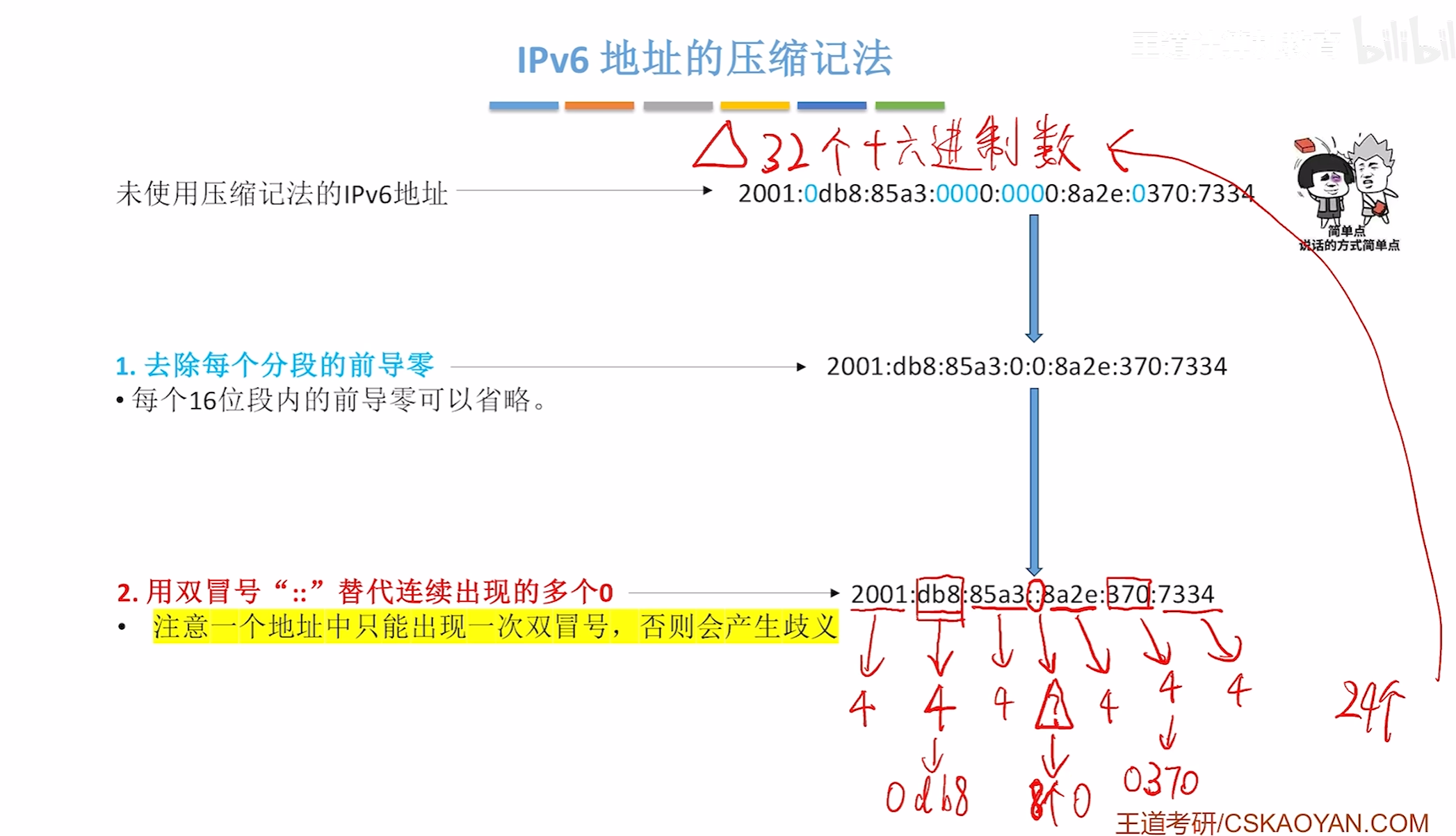
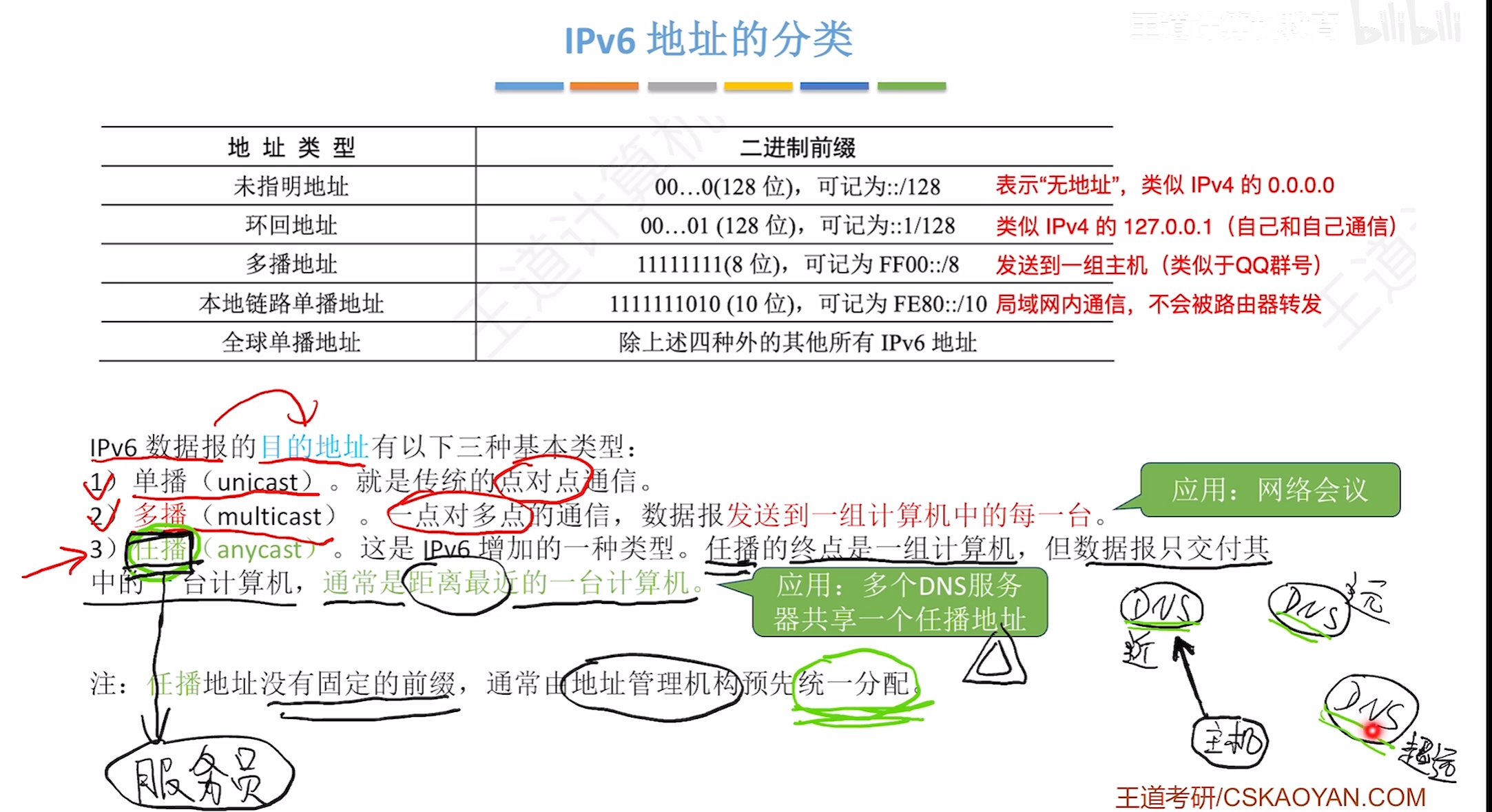
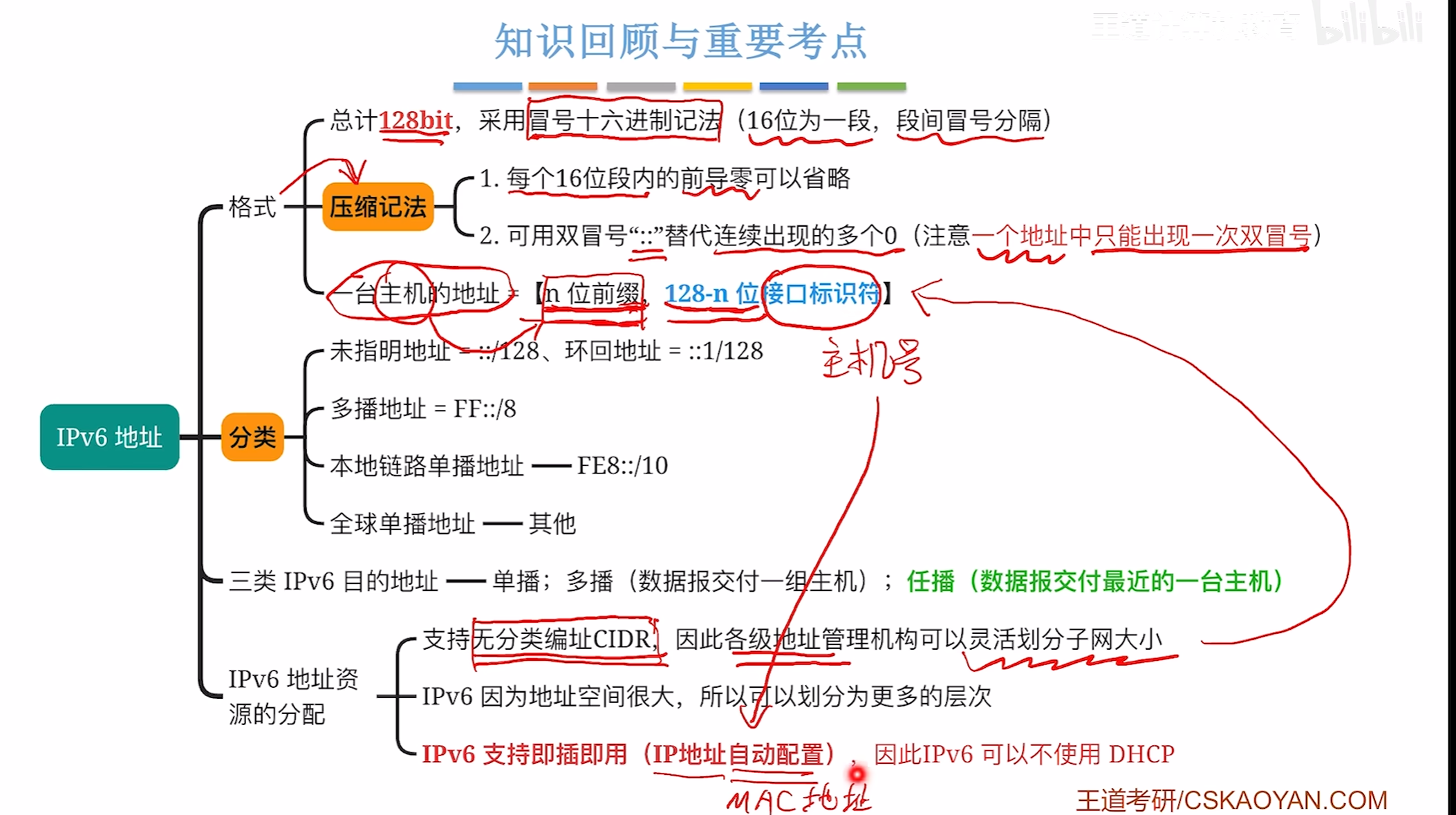
IPV6
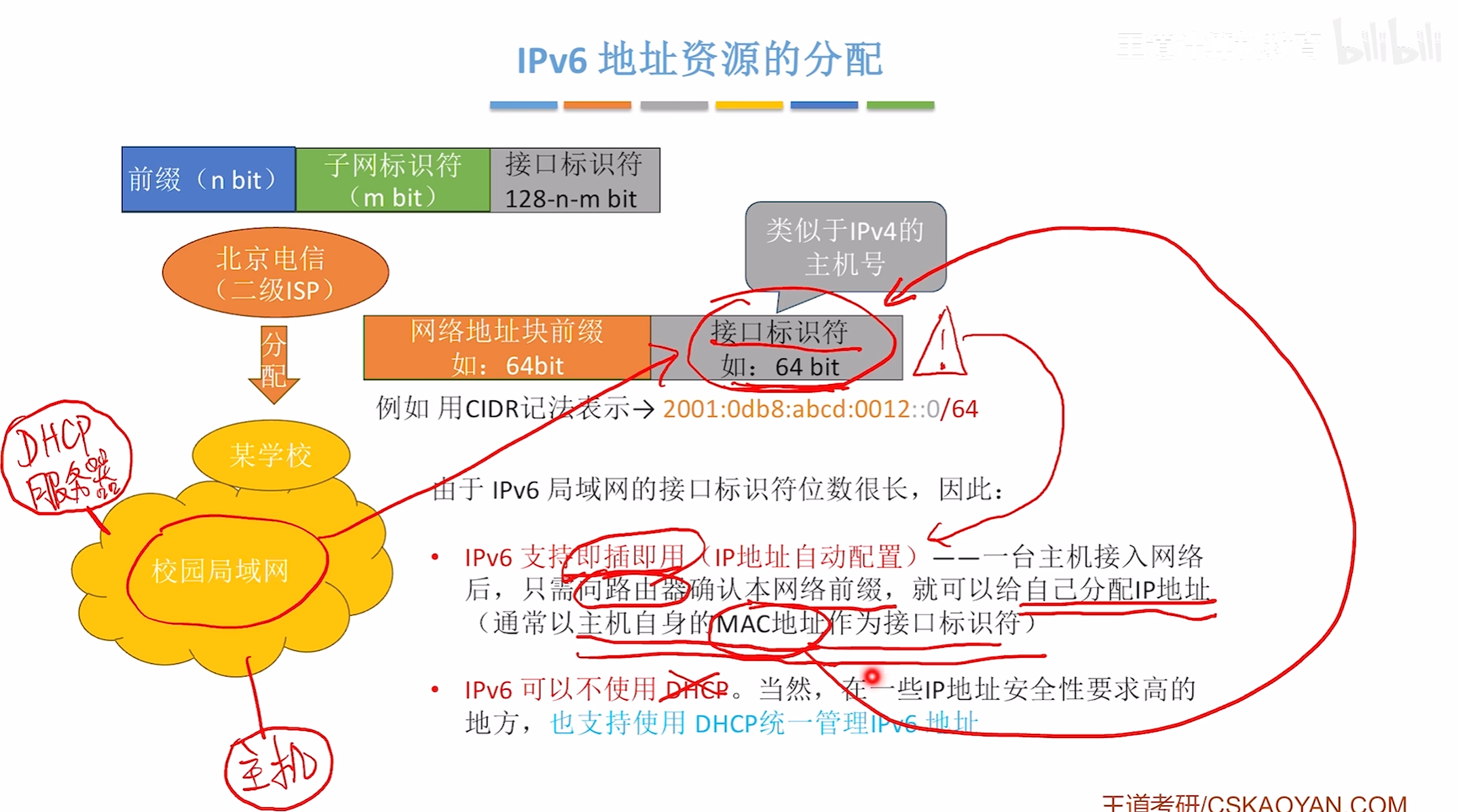
IPV6分类
例题

总结
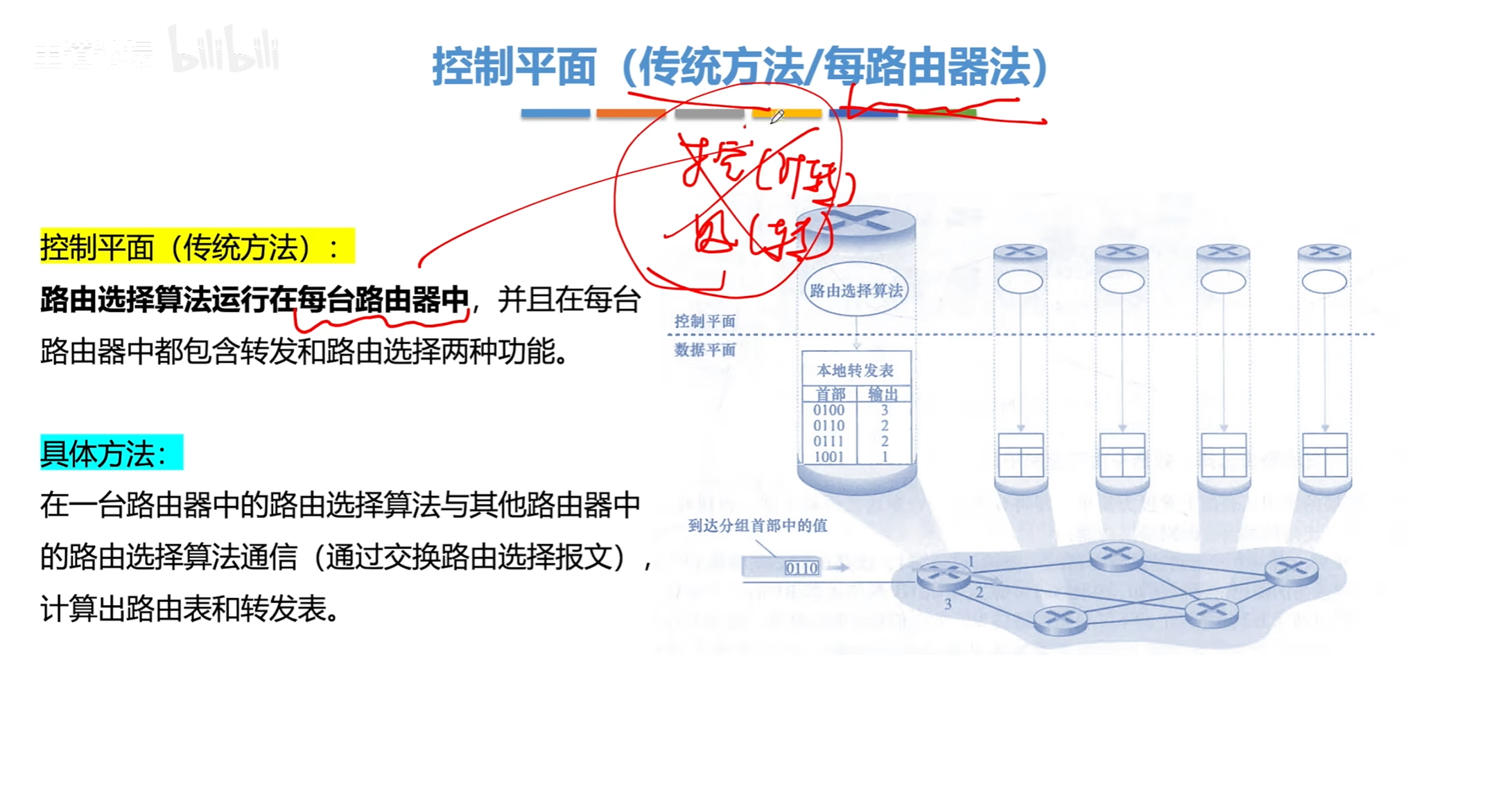
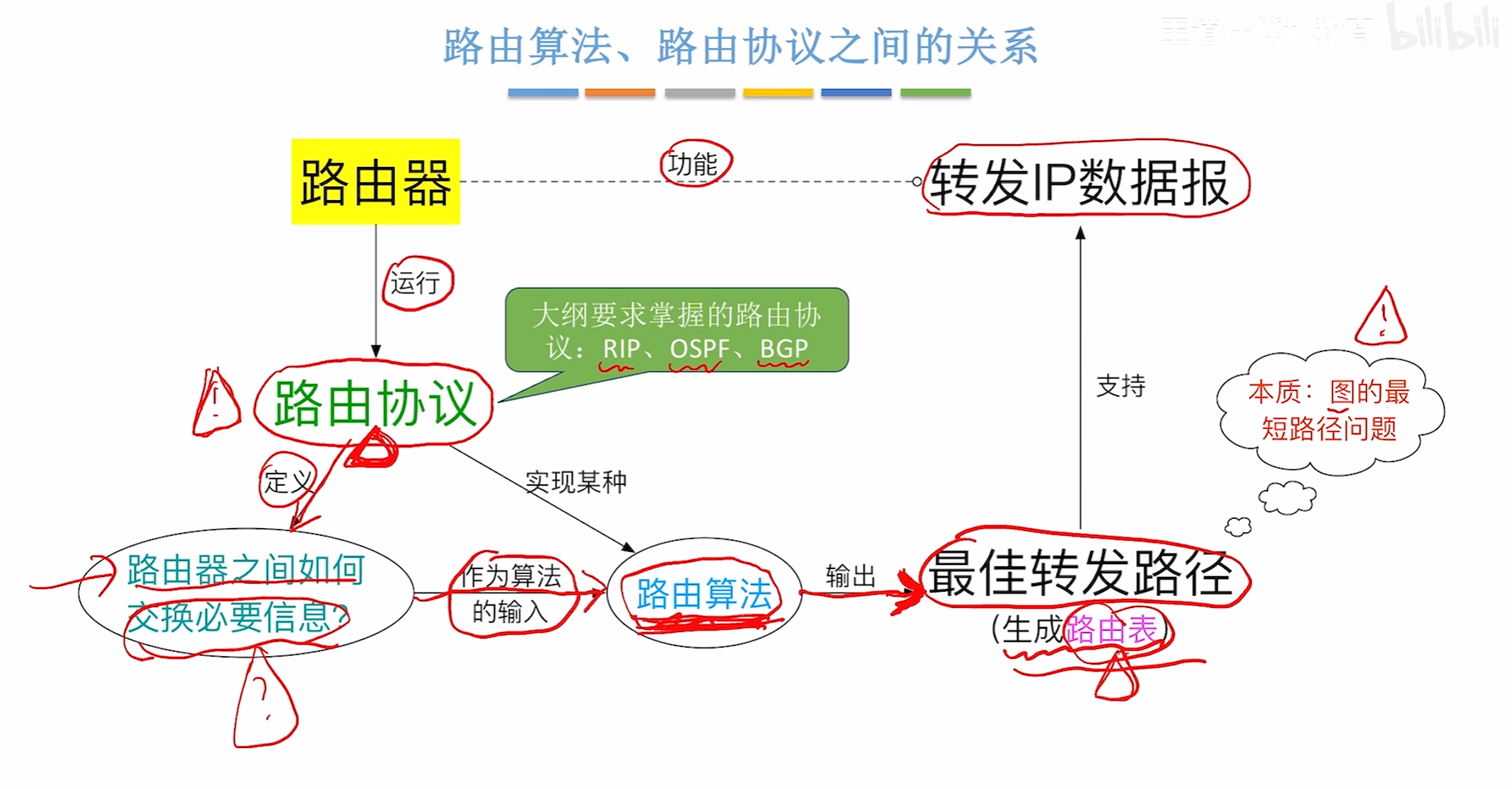
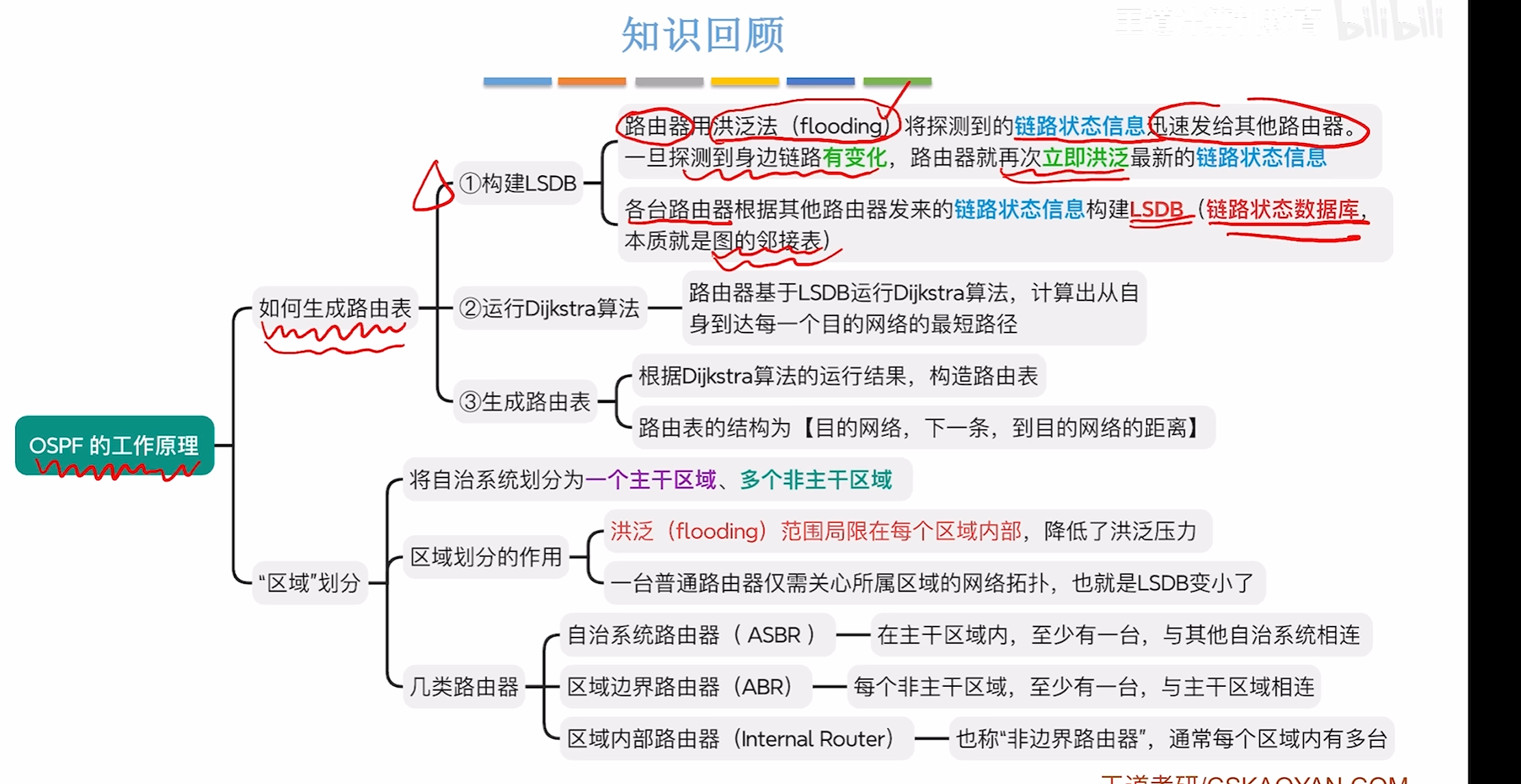
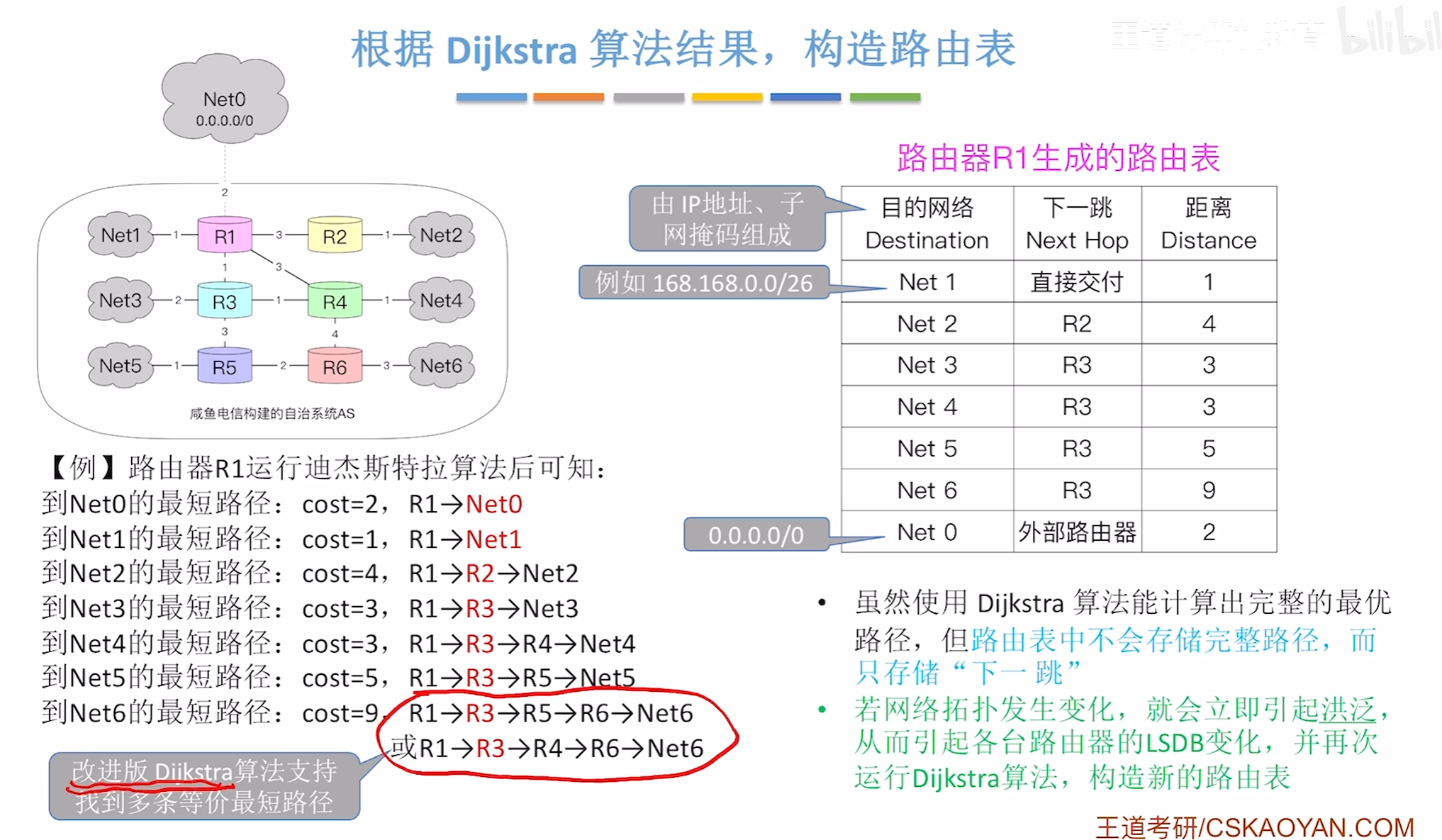
路由算法与路由协议
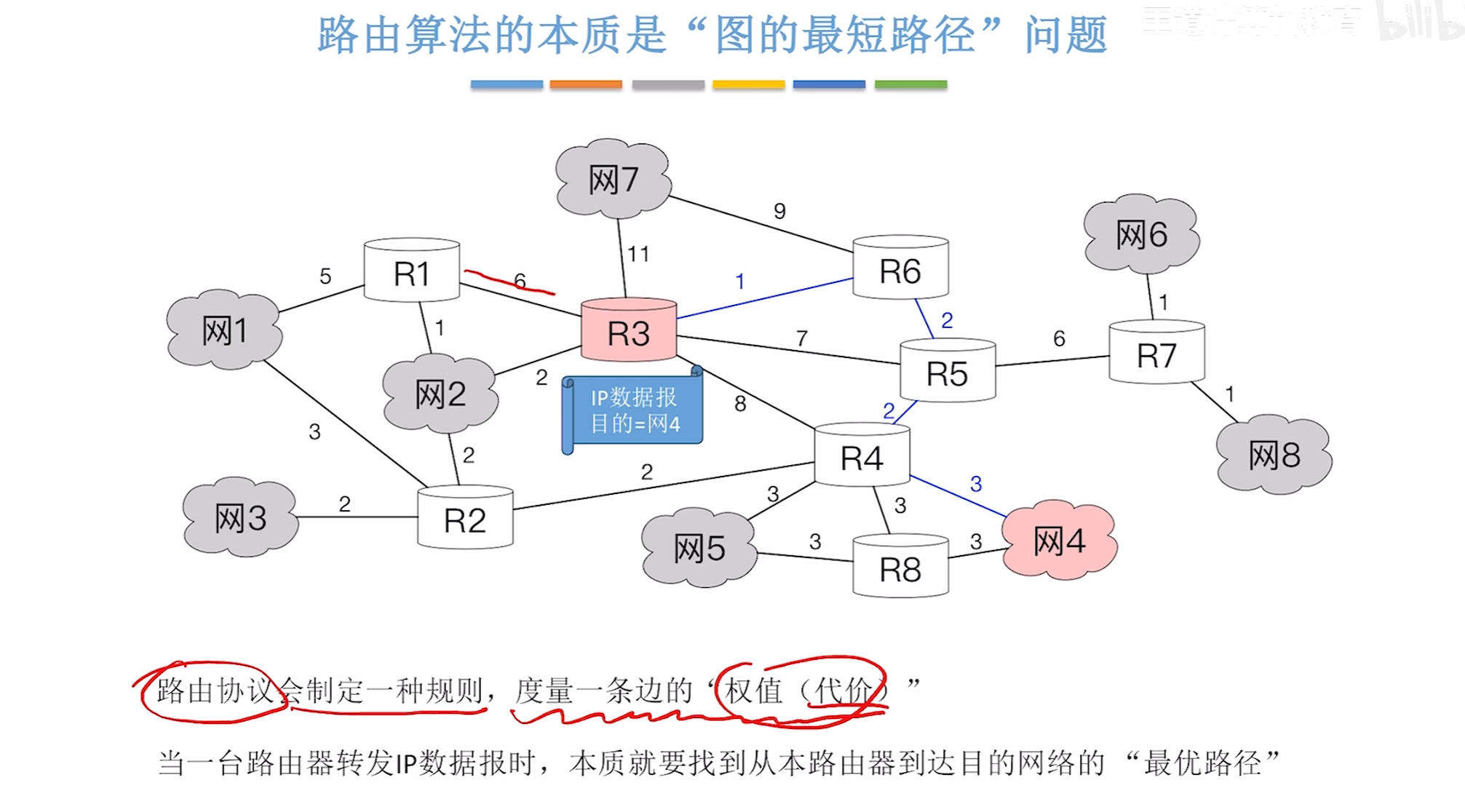
路由算法分类
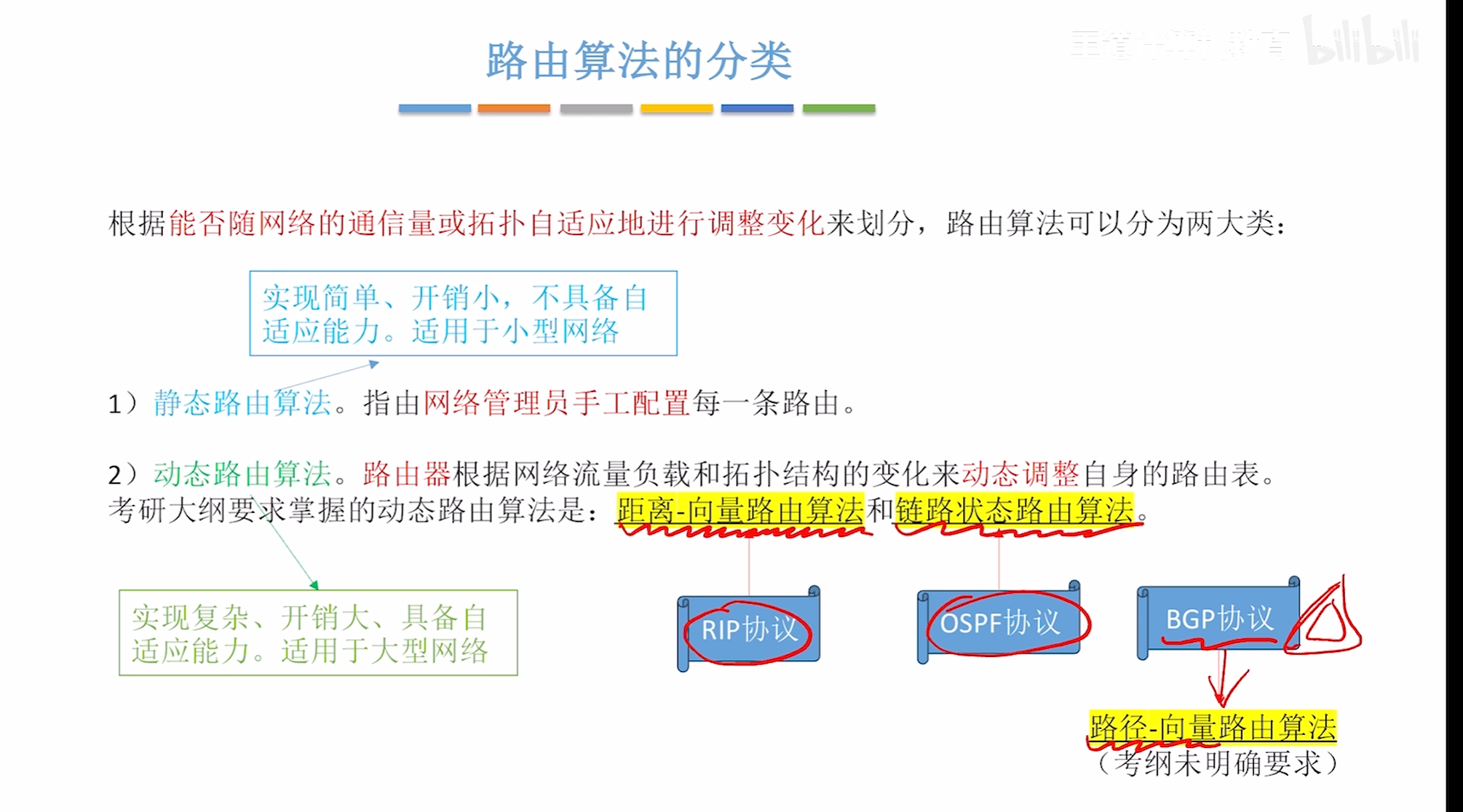
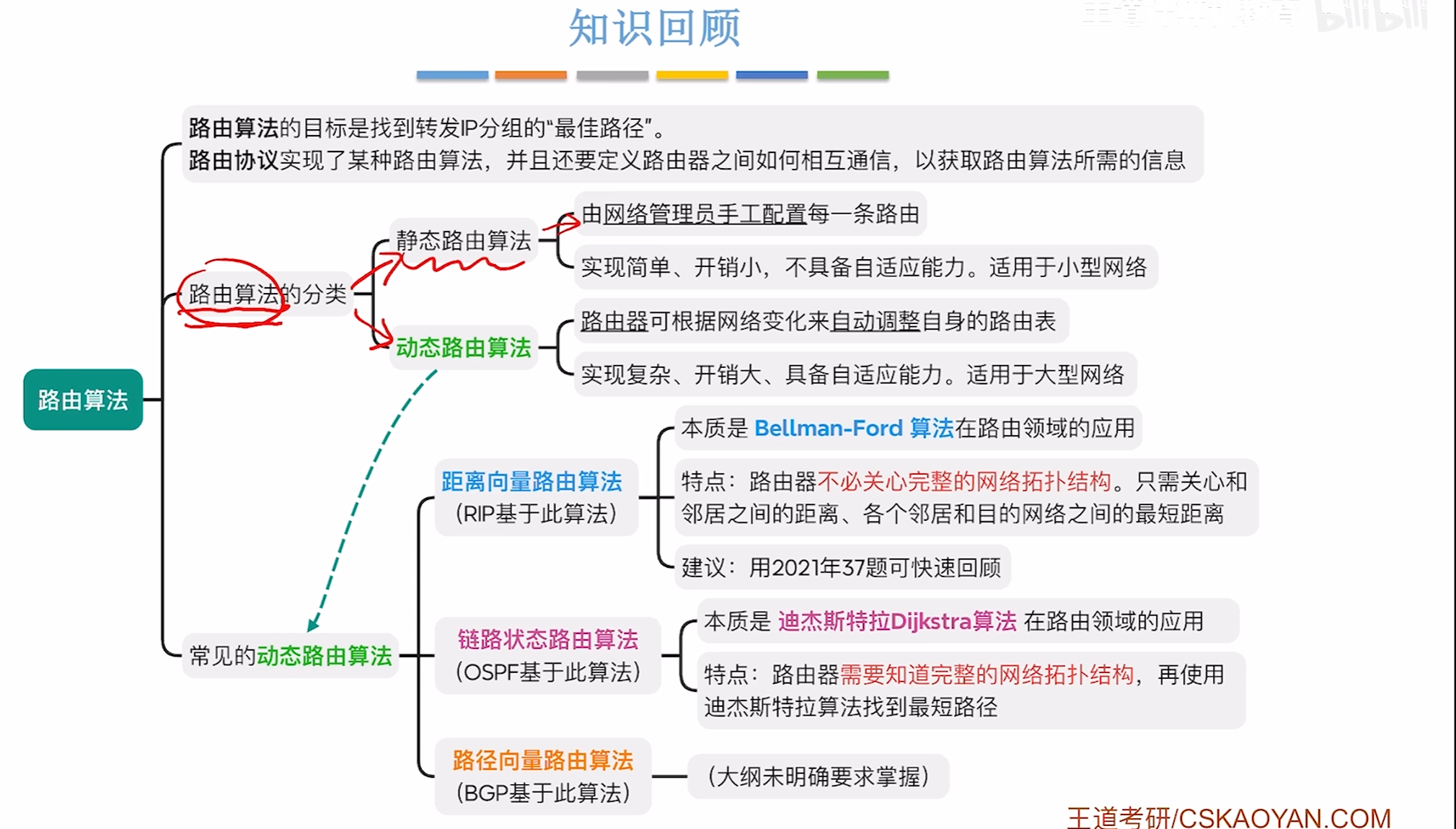
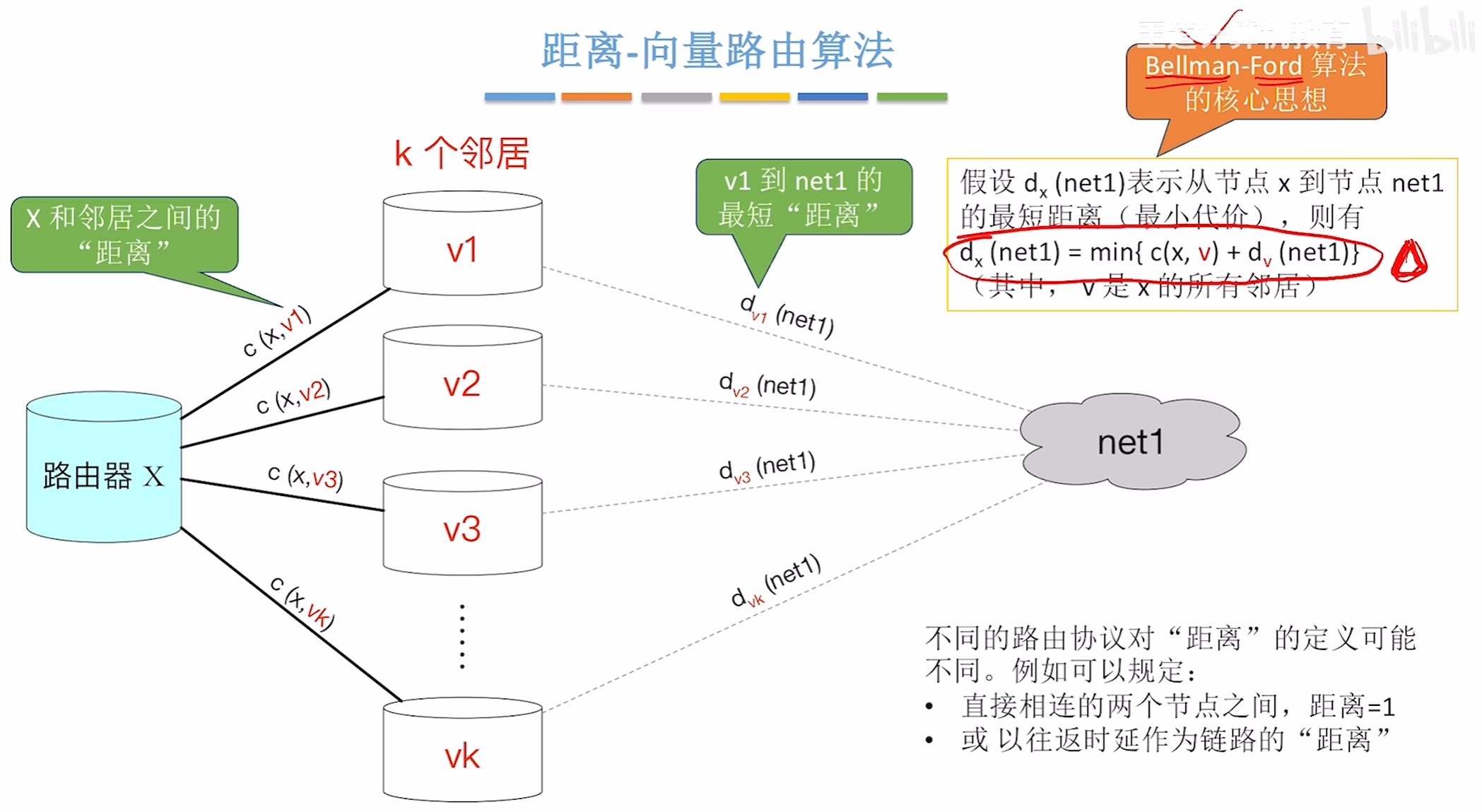
距离向量-路由算法
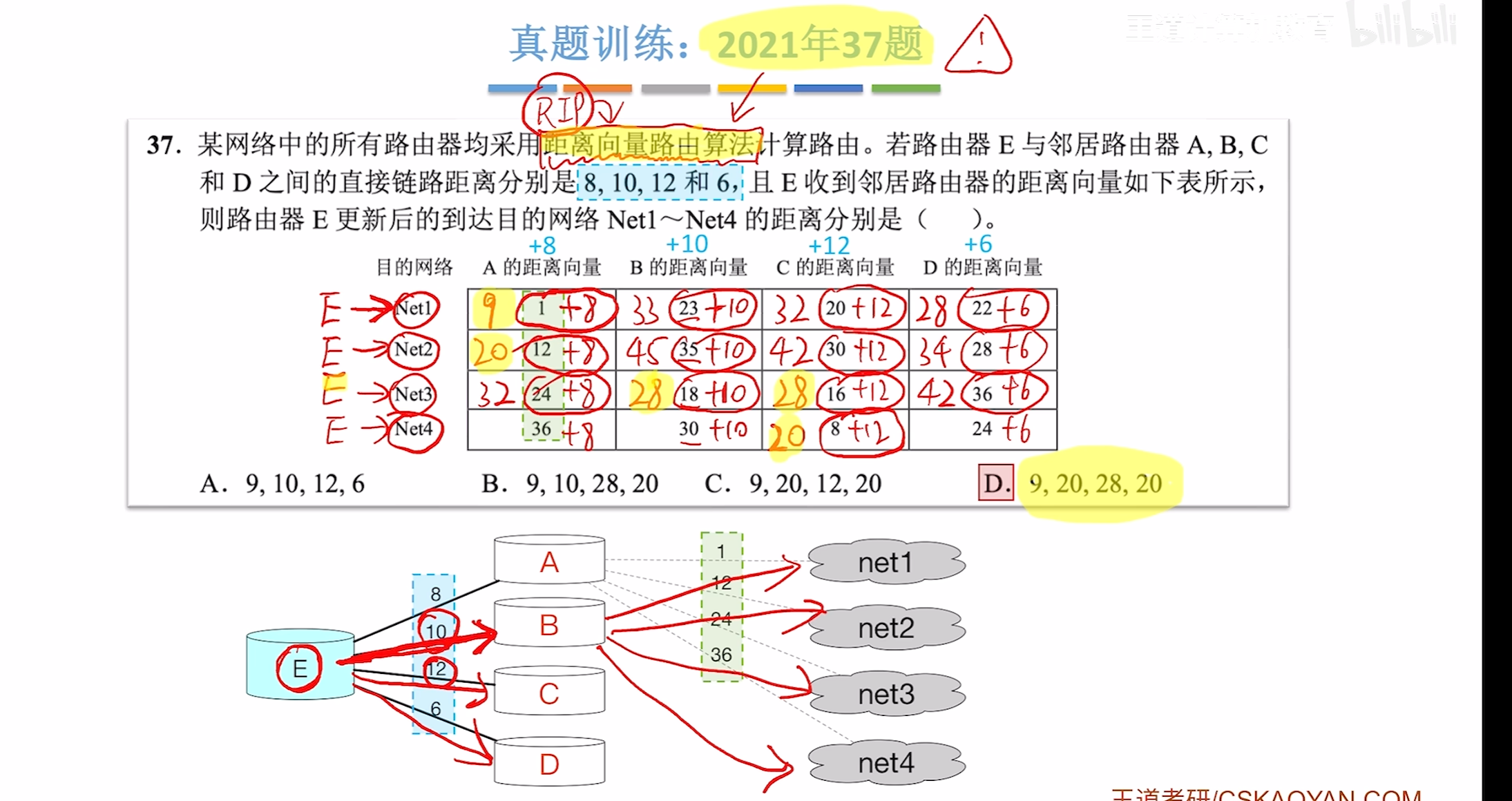
例题
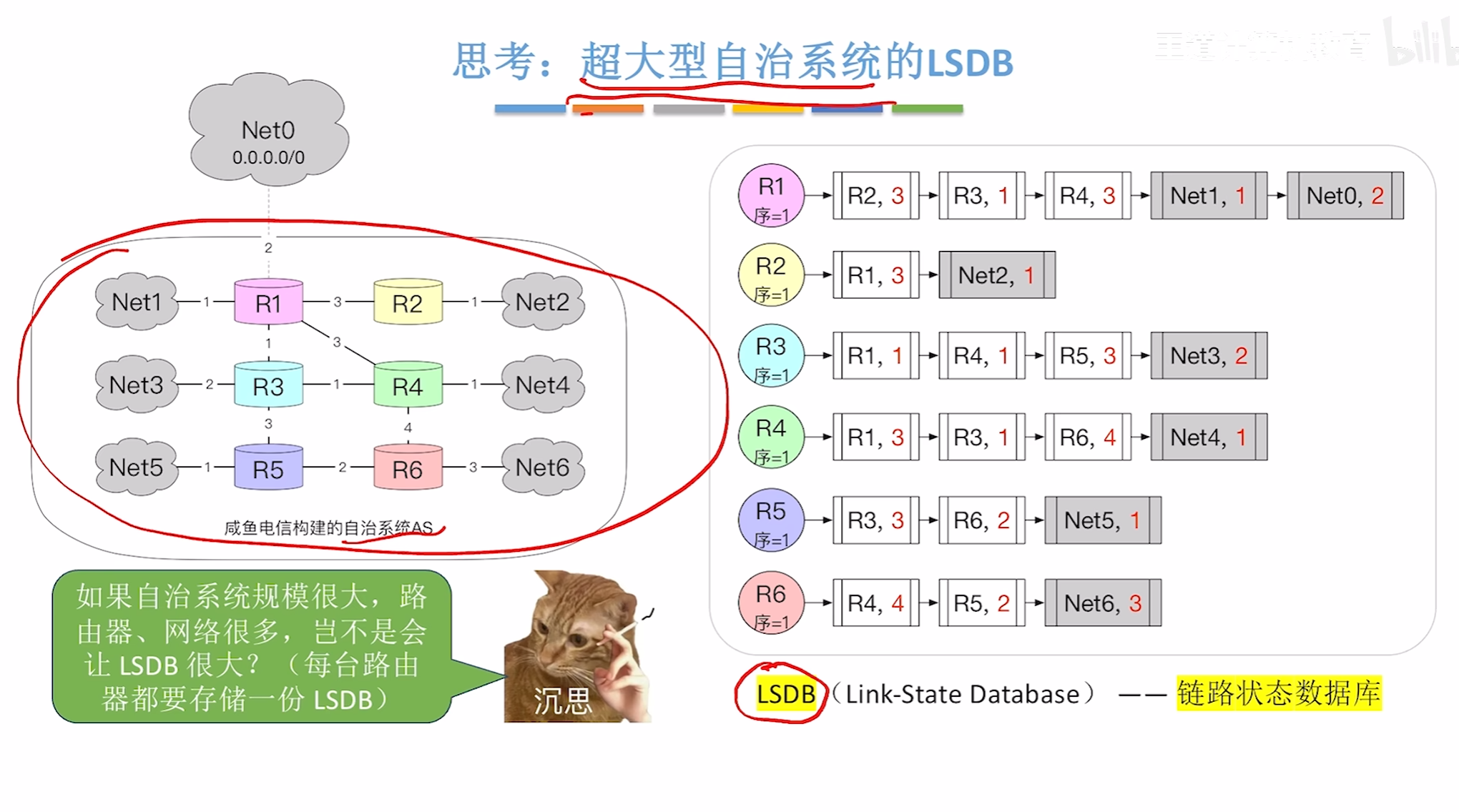
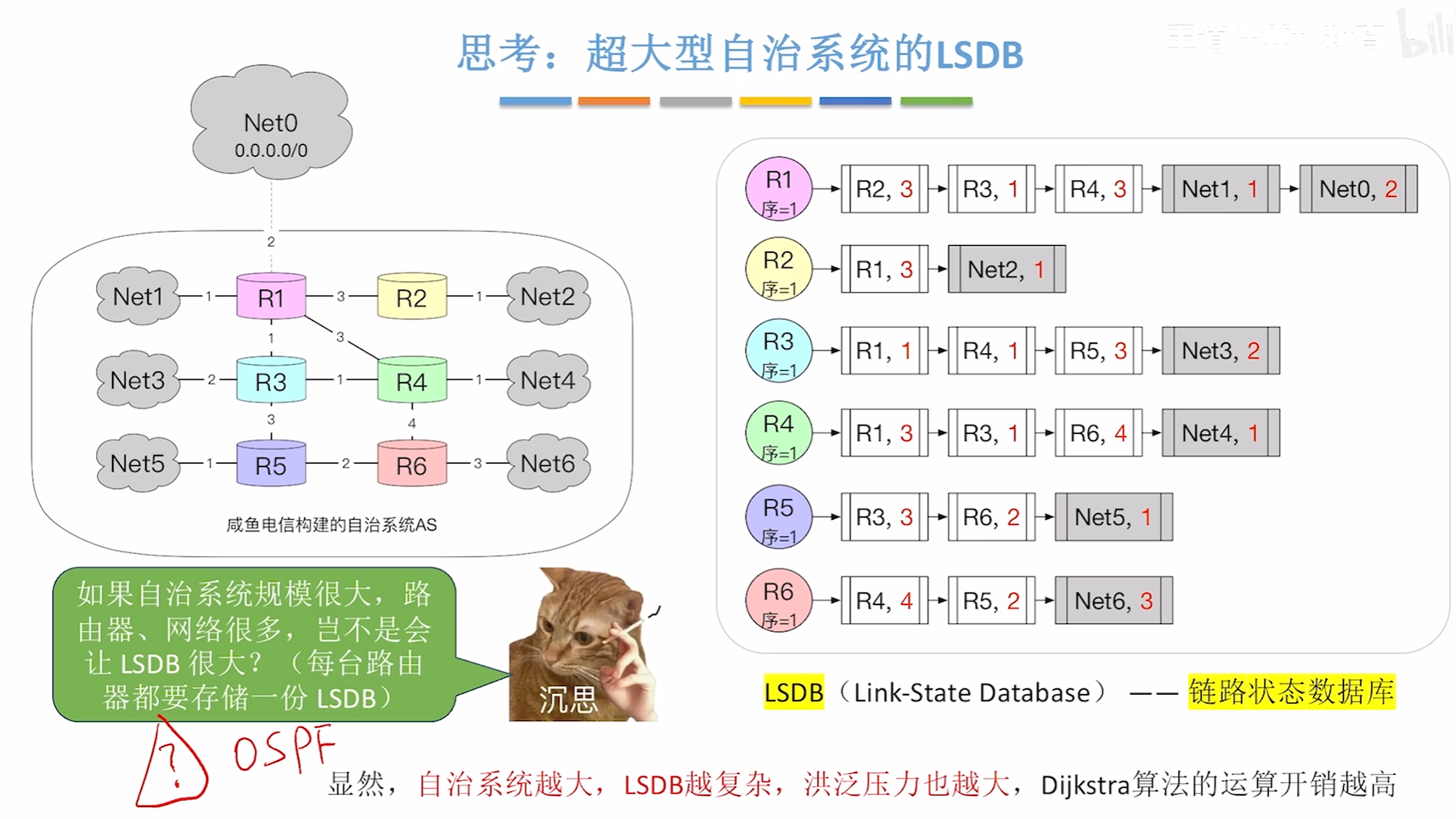
电路状态算法
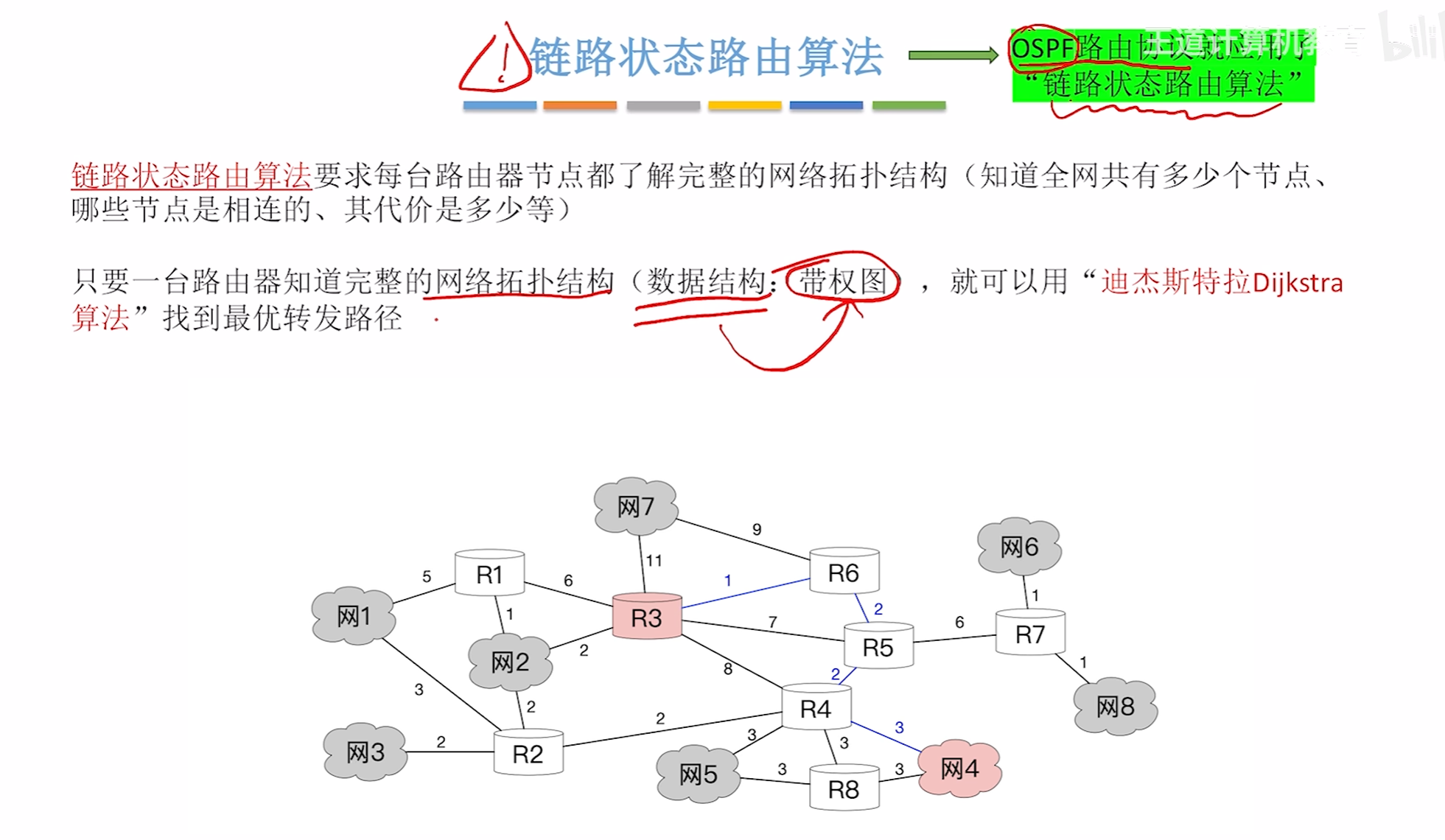
分层路由协议
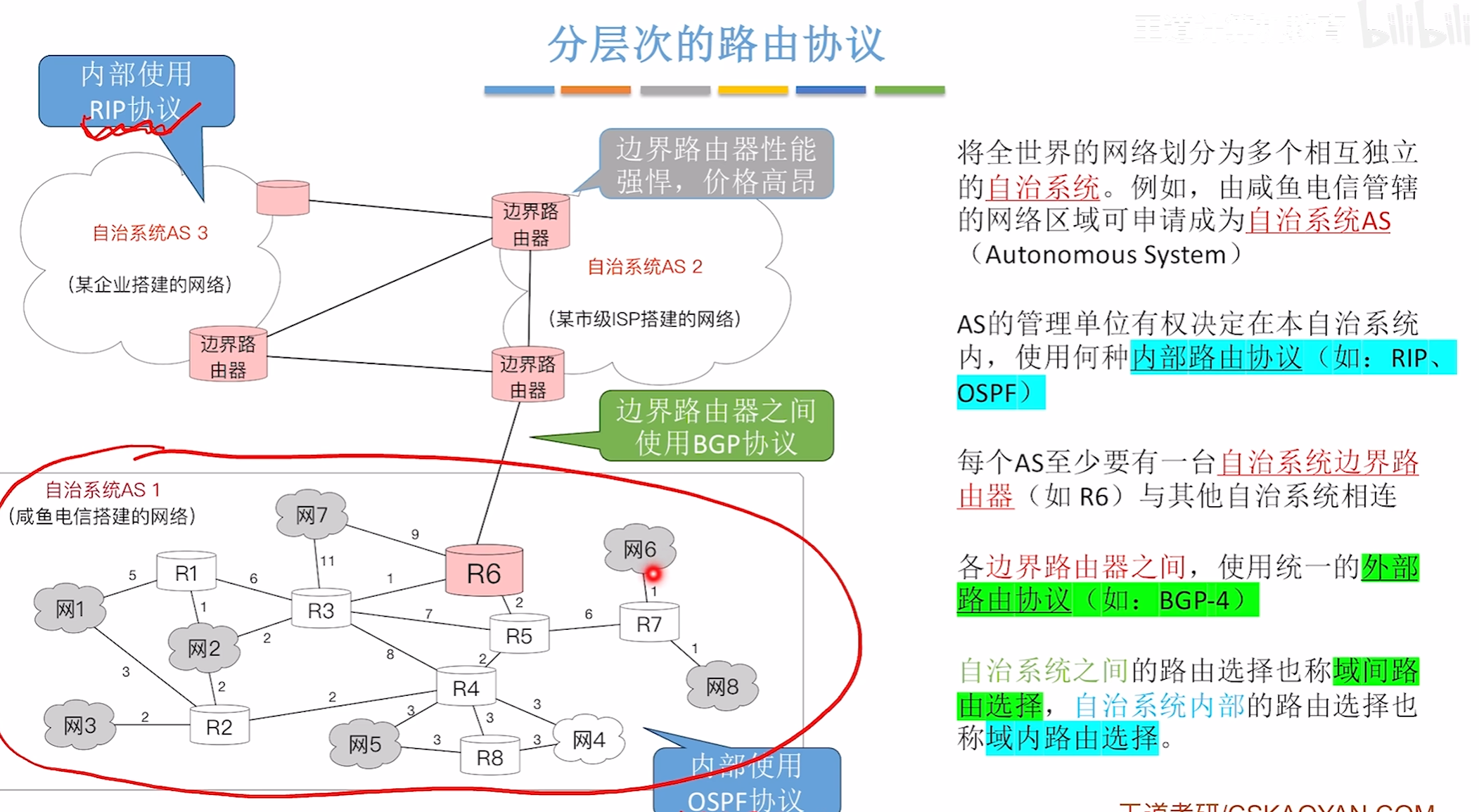


RIP路由协议

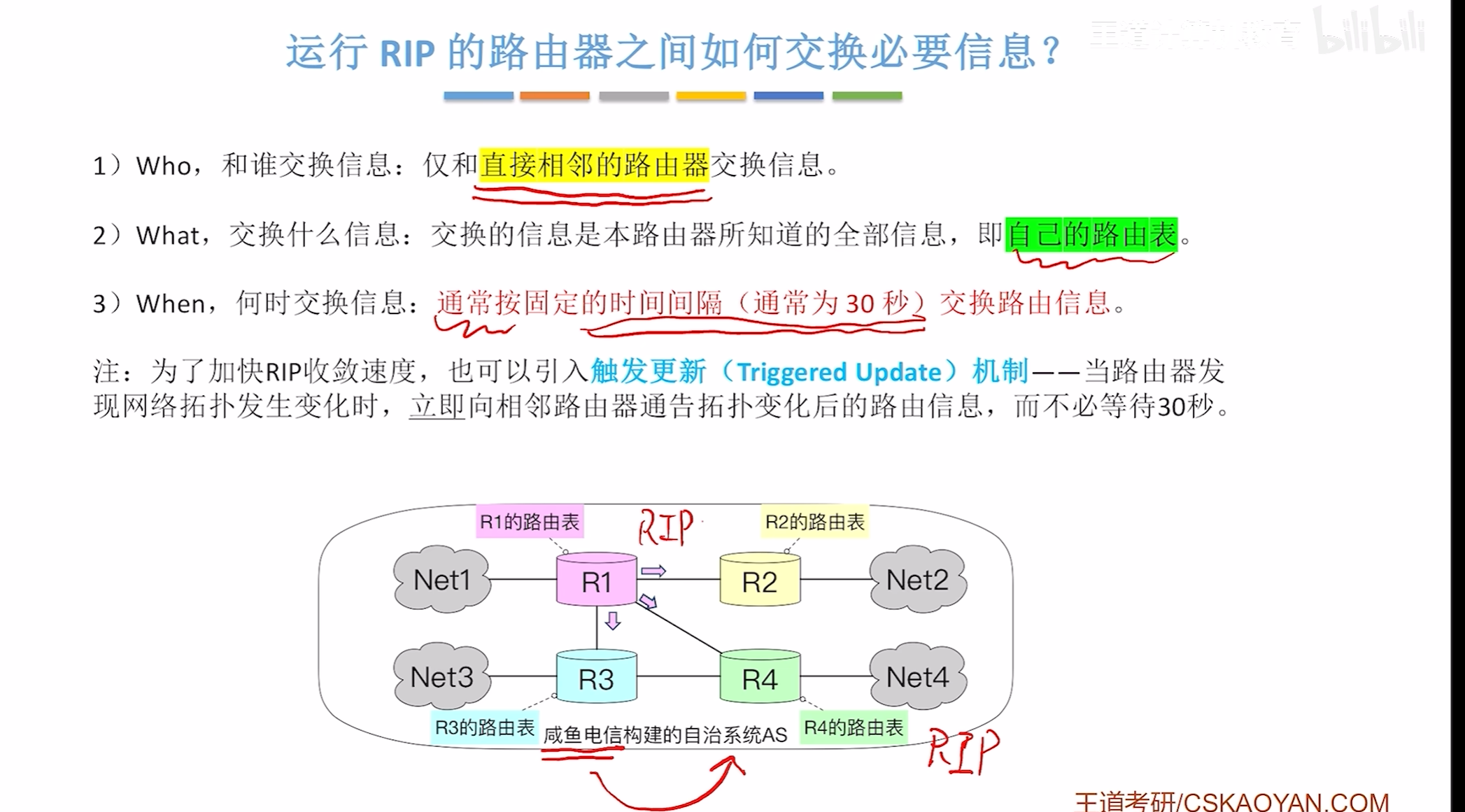
RIP运行的路由器如何交换信息
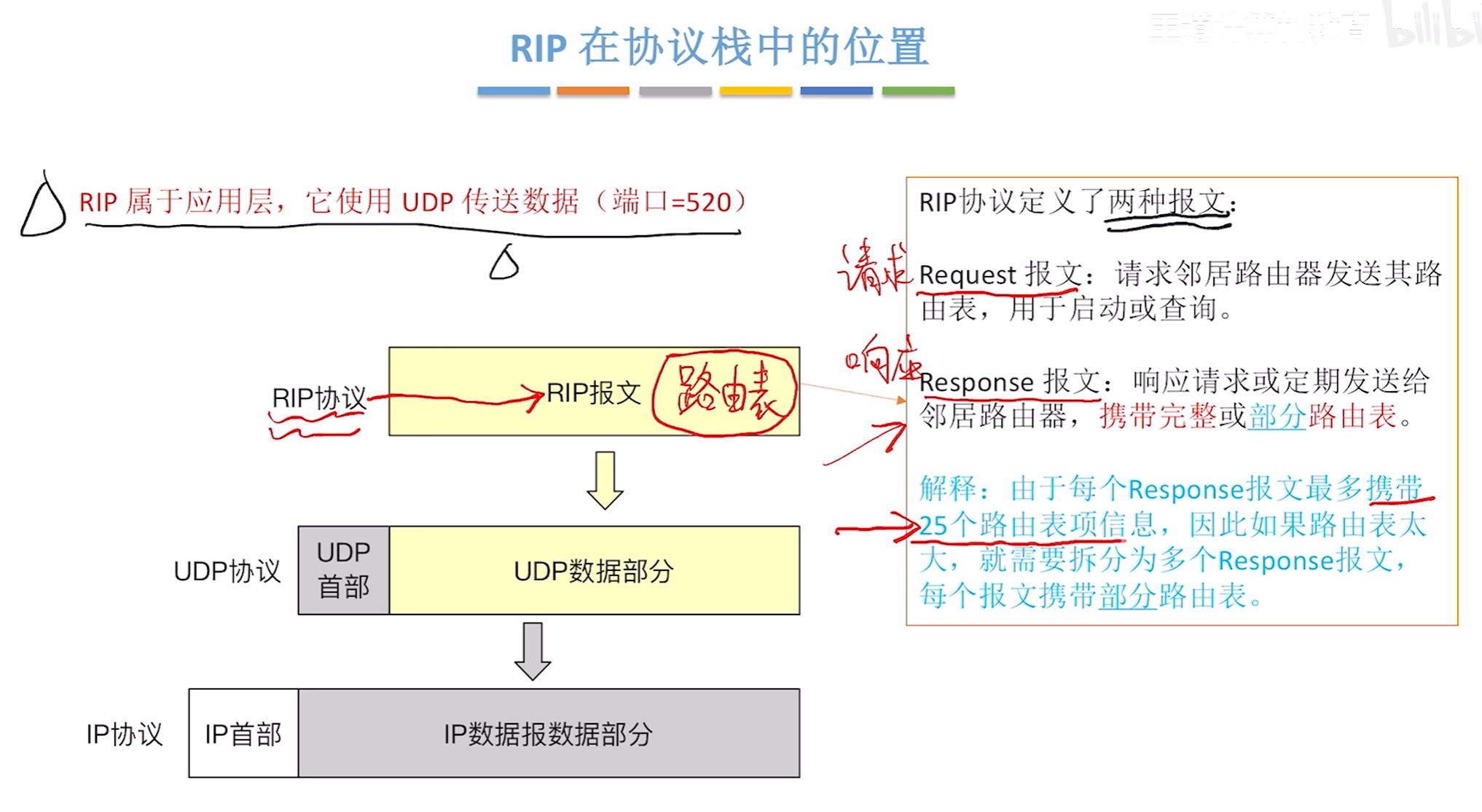
RIP在协议栈中的位置
RIP的工作过程
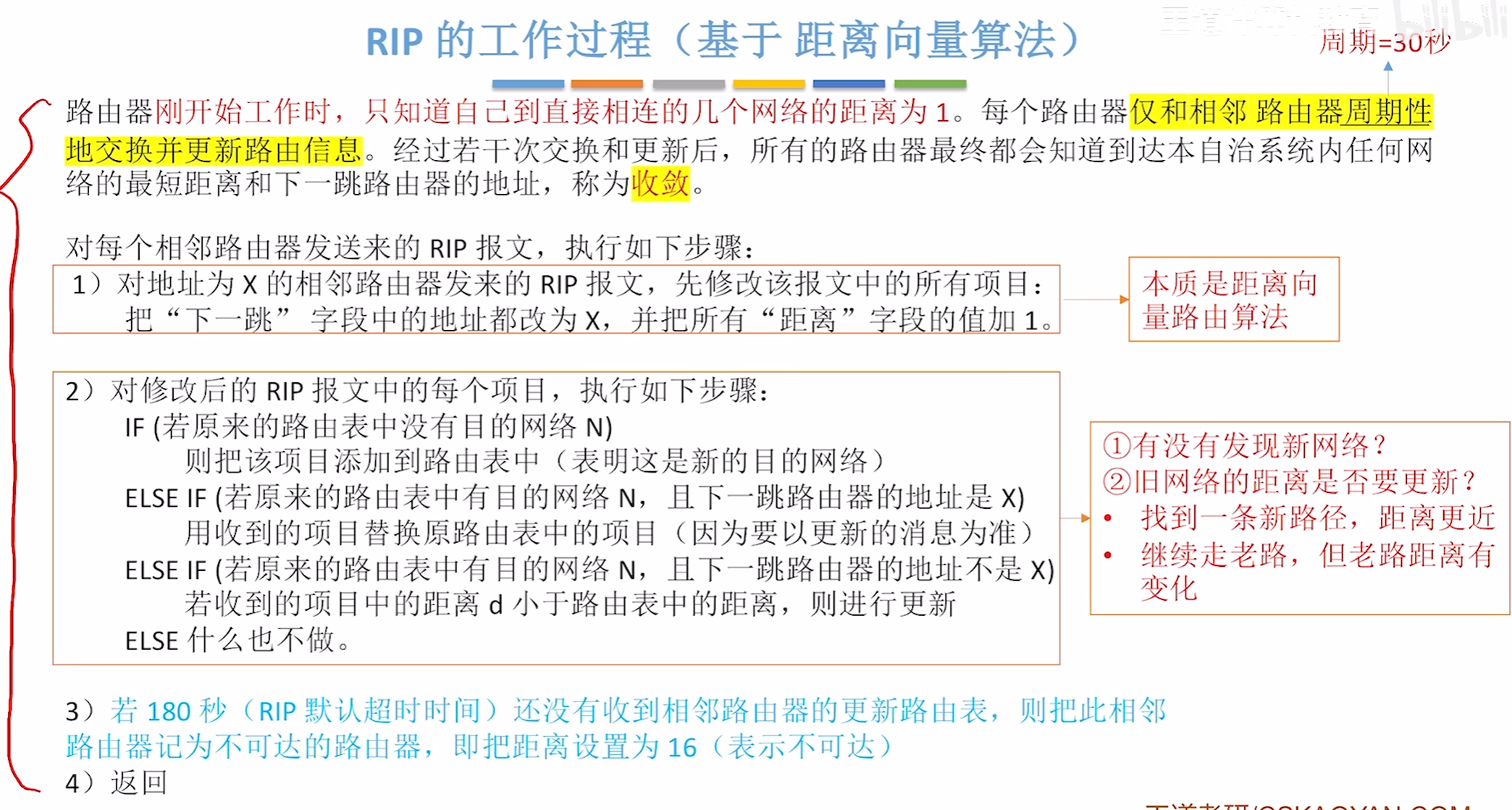
初始
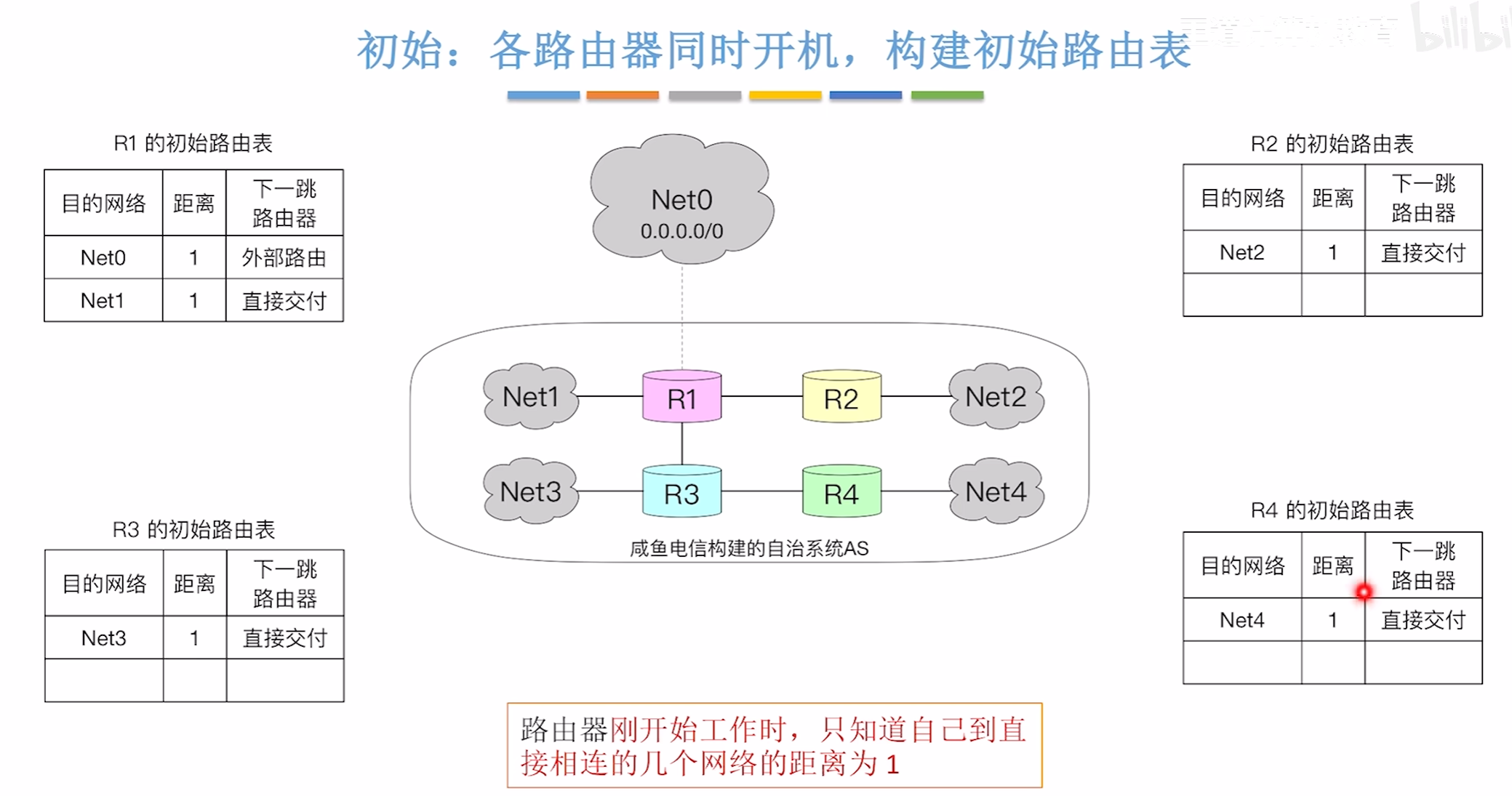 0时刻
0时刻
各路由器开始交换信息时
目的网络不变
距离+1
下一跳的路由器修改为给自己发送报文的路由器
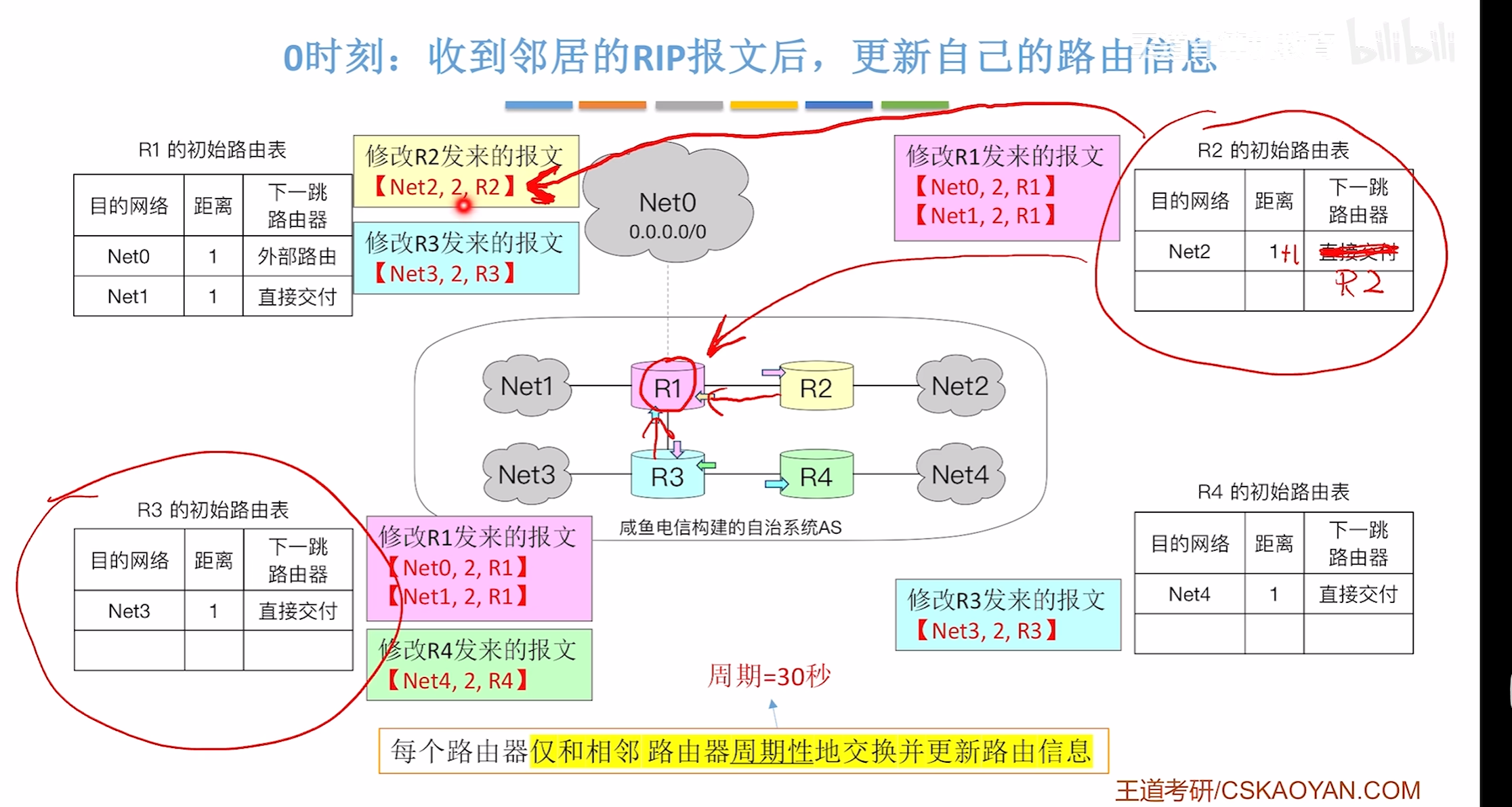
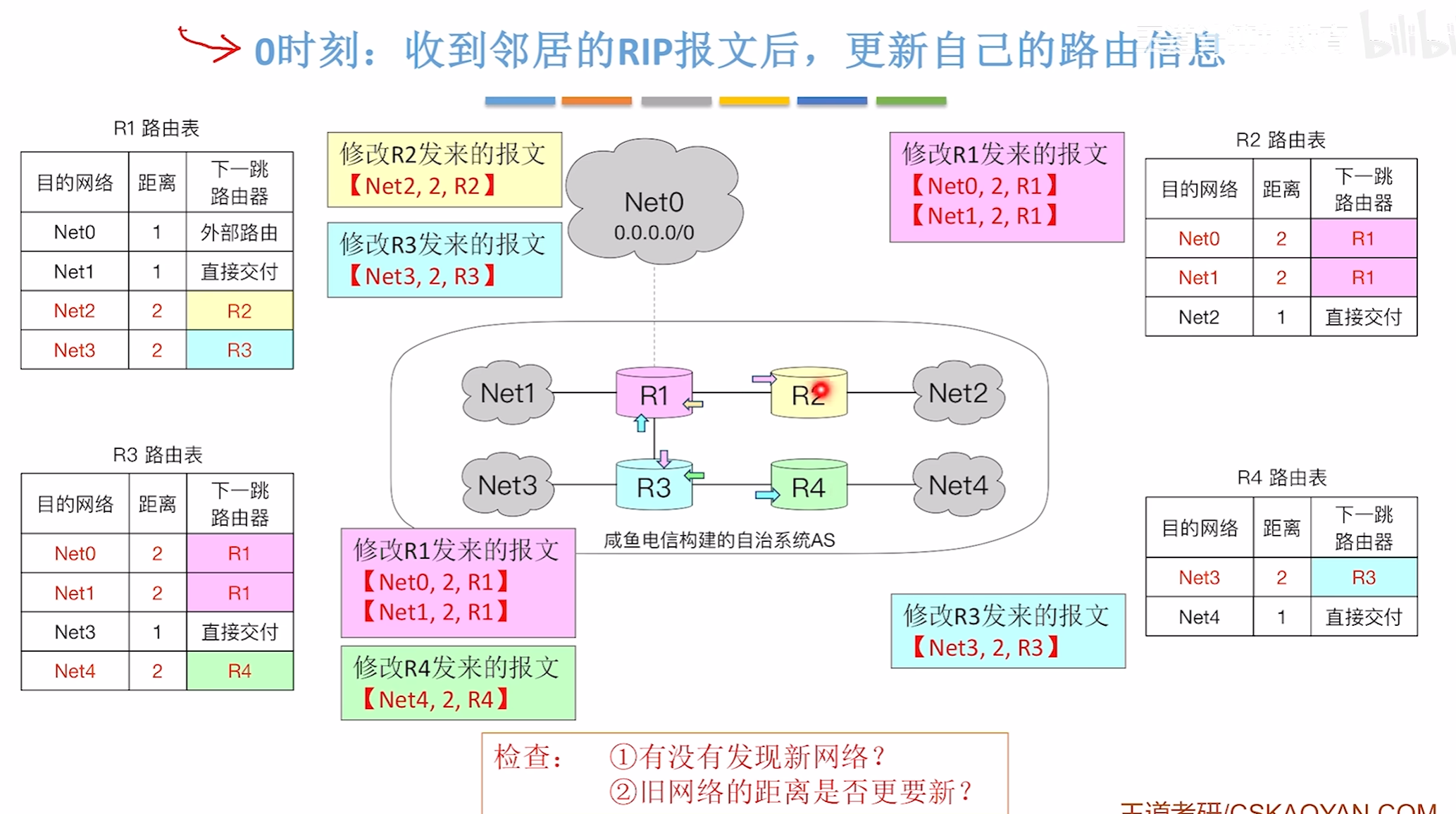
30时刻
在收到各个报文后会先进行修改,然后再运行距离向量算法判断是否该更新原本的路由表
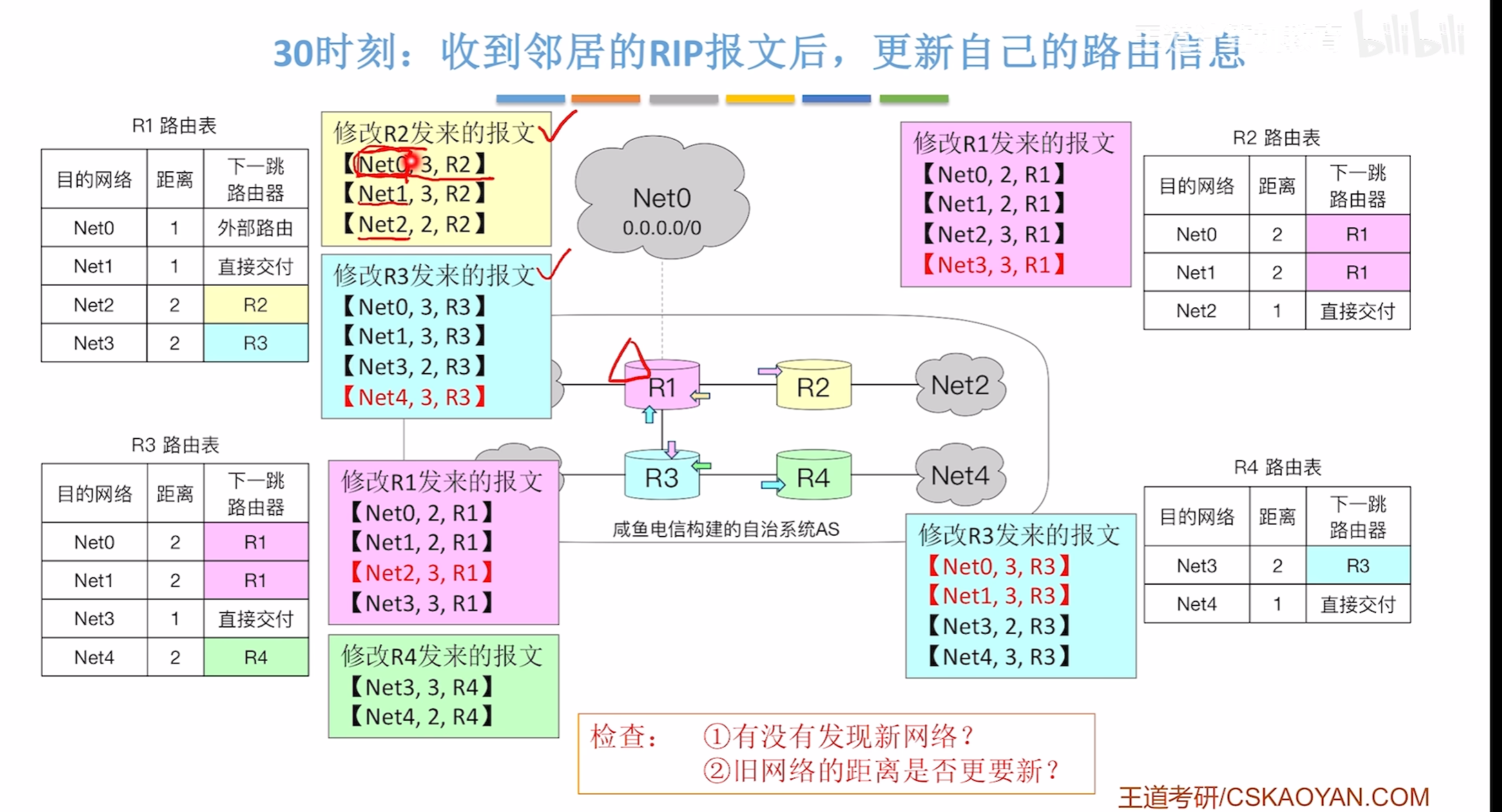
60时刻
收敛代表着路由表不会再更新
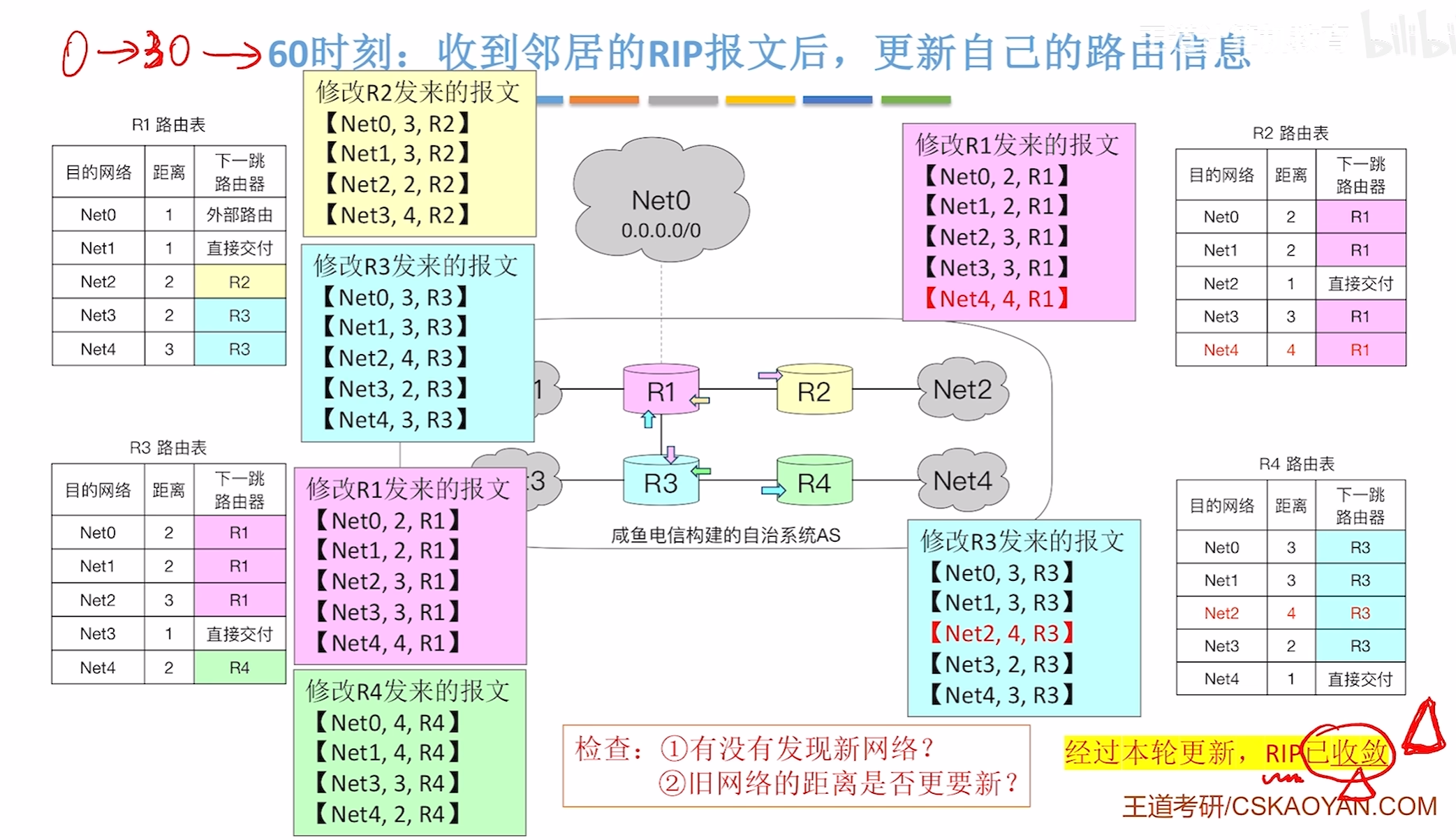
120时刻,我们修改了网络拓补,路由表信息应该发生变化
我们将R4和R1链接一条网线
我们发现R4的路径要比以前更短所以我们要修改路径,同时R4也是因为收到了R1的报文需要更新替换
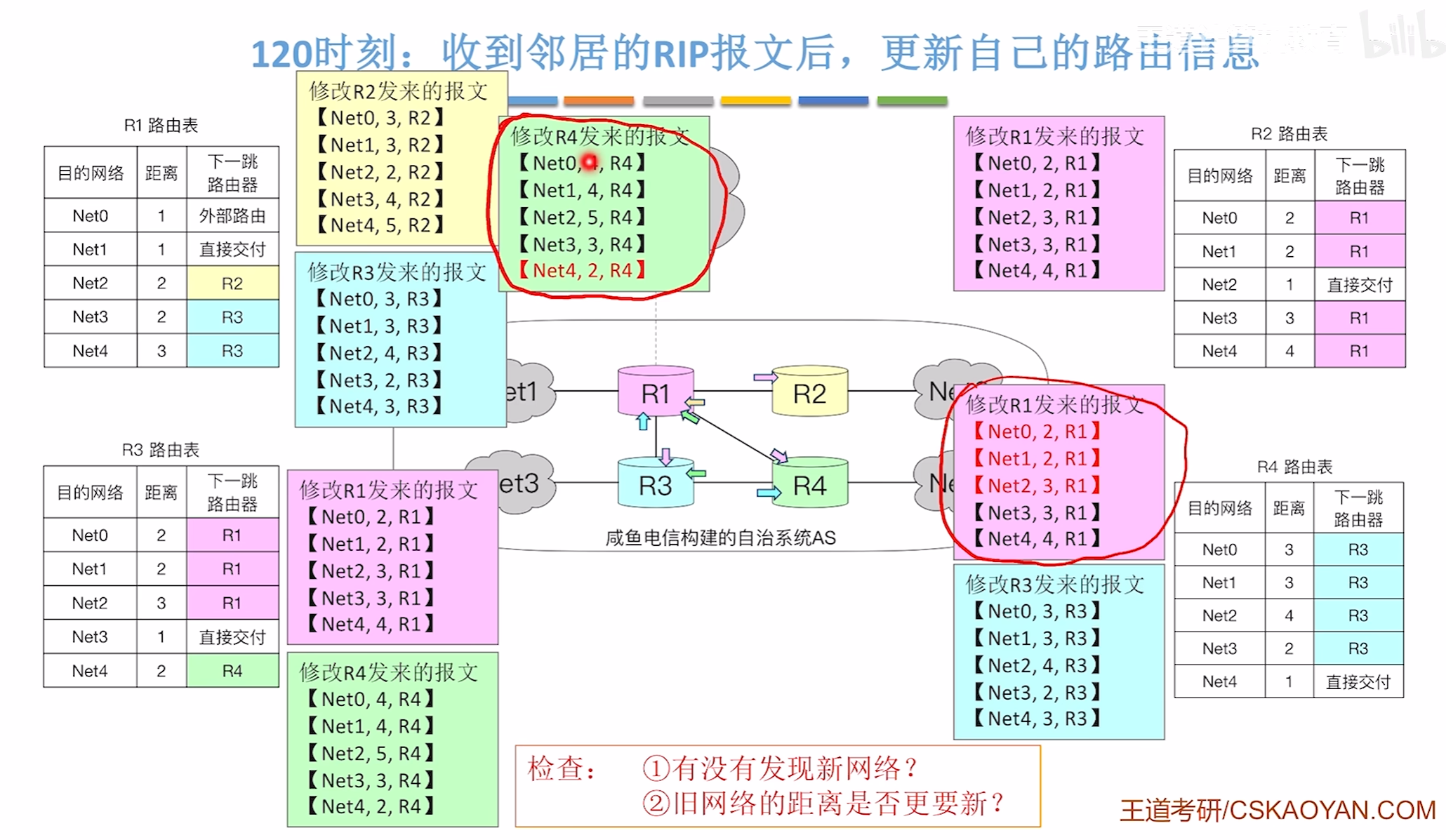
150时刻
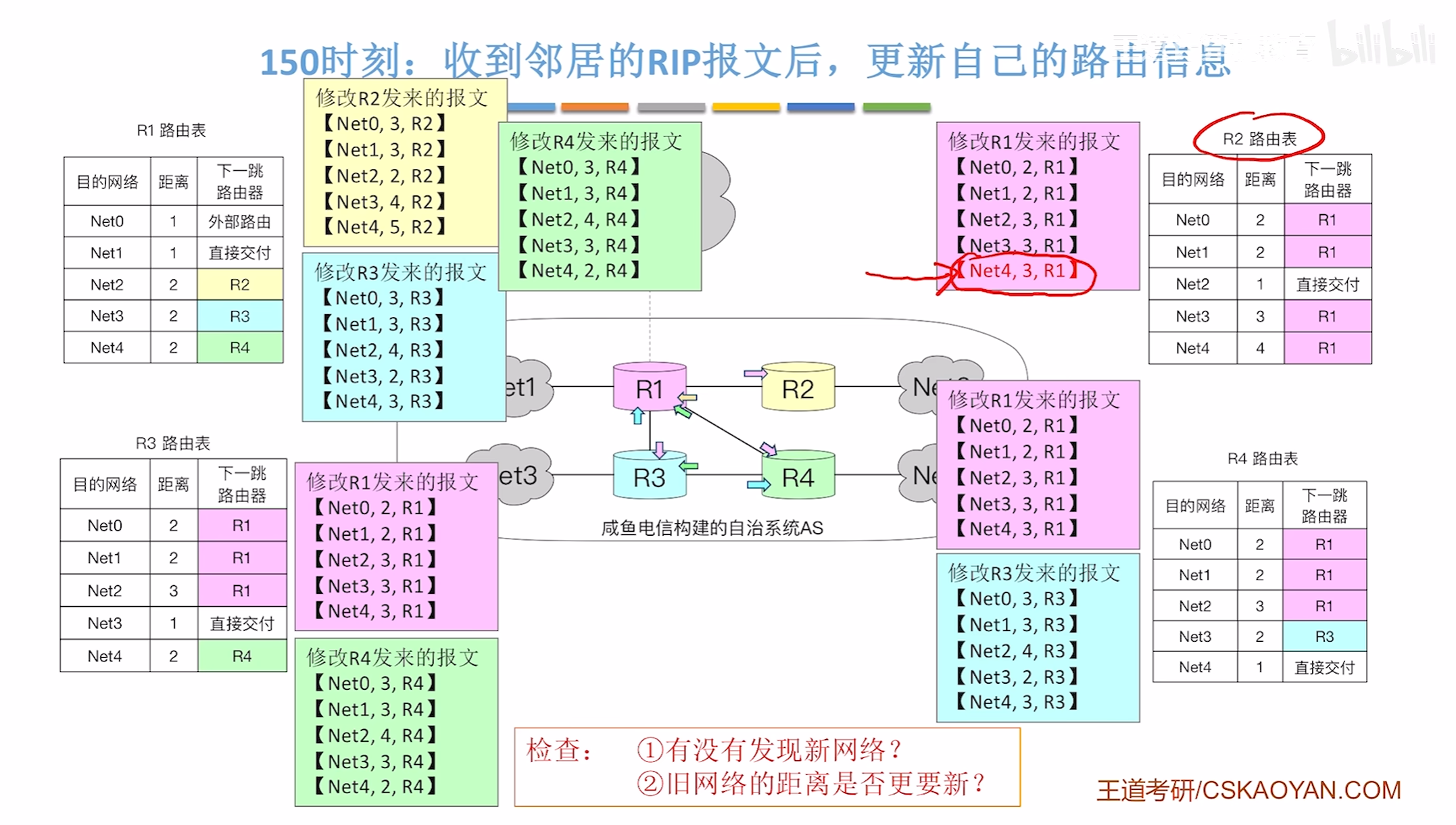
160时刻,电路出现故障
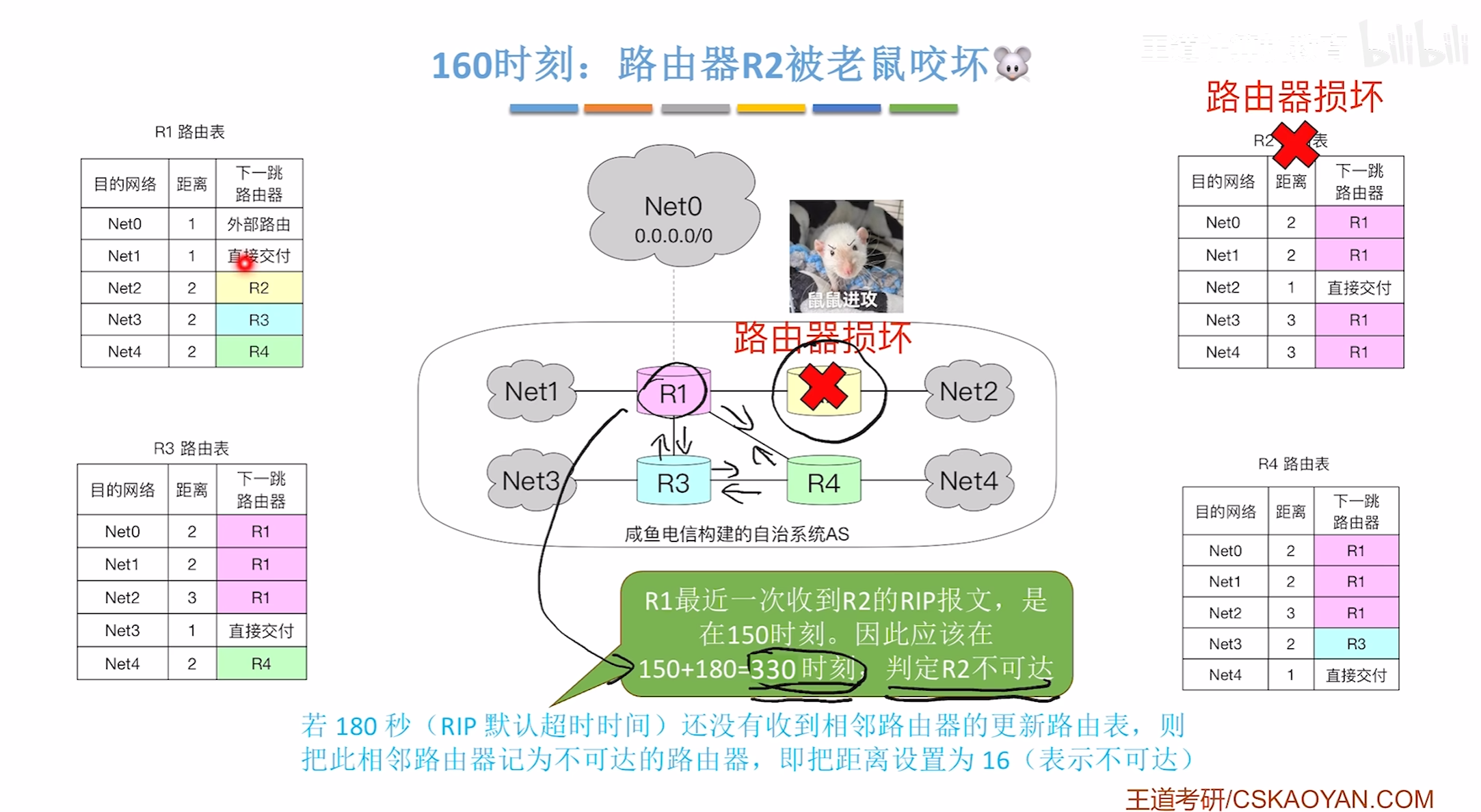
330时刻,R2超时未更新则判定损坏不可达,但是意外出现
此时R3/4 发来了路由表告诉R1R2可达,所以就会出现这种路由错误
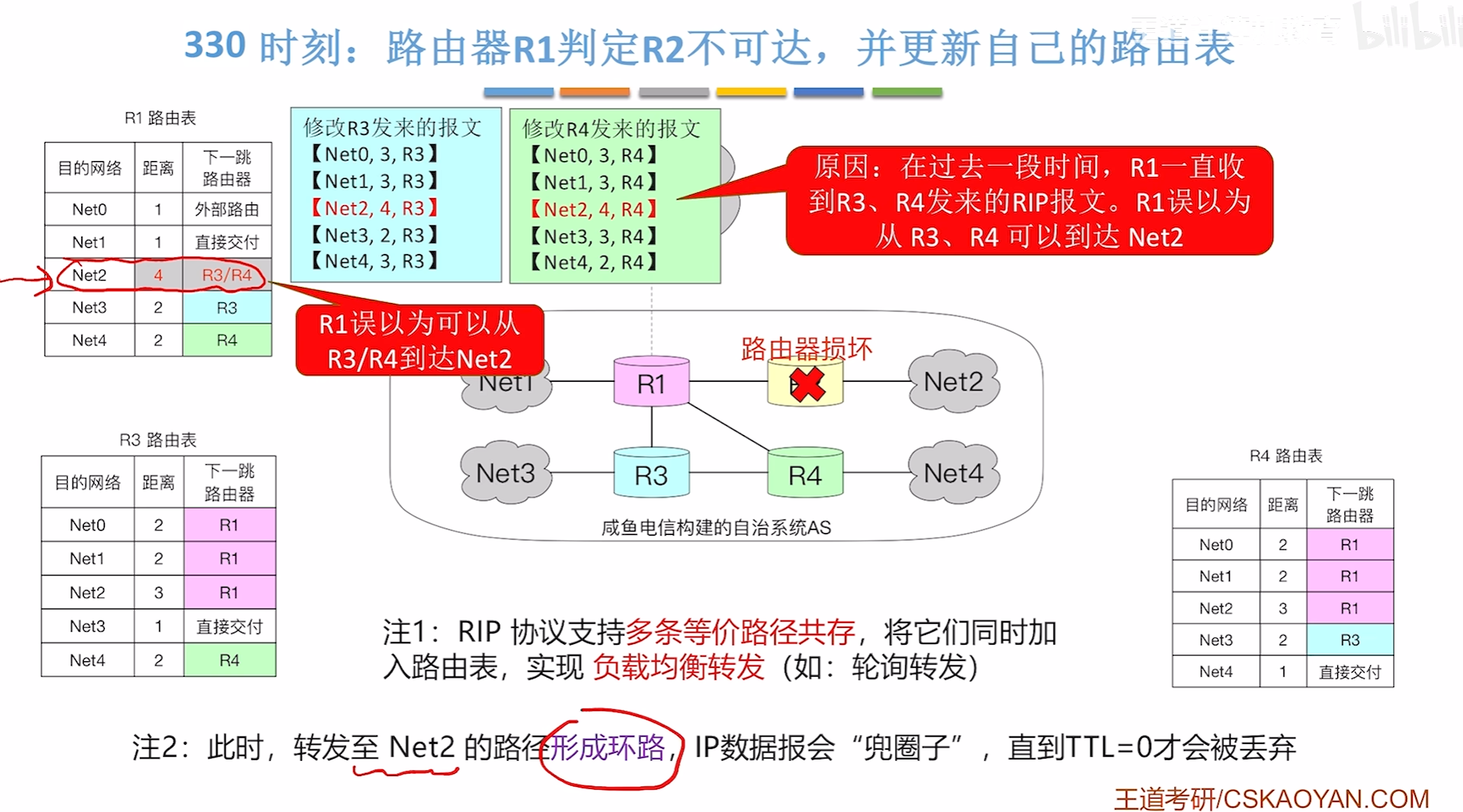
R3/4都会错误的修改路由表信息,更新距离信息
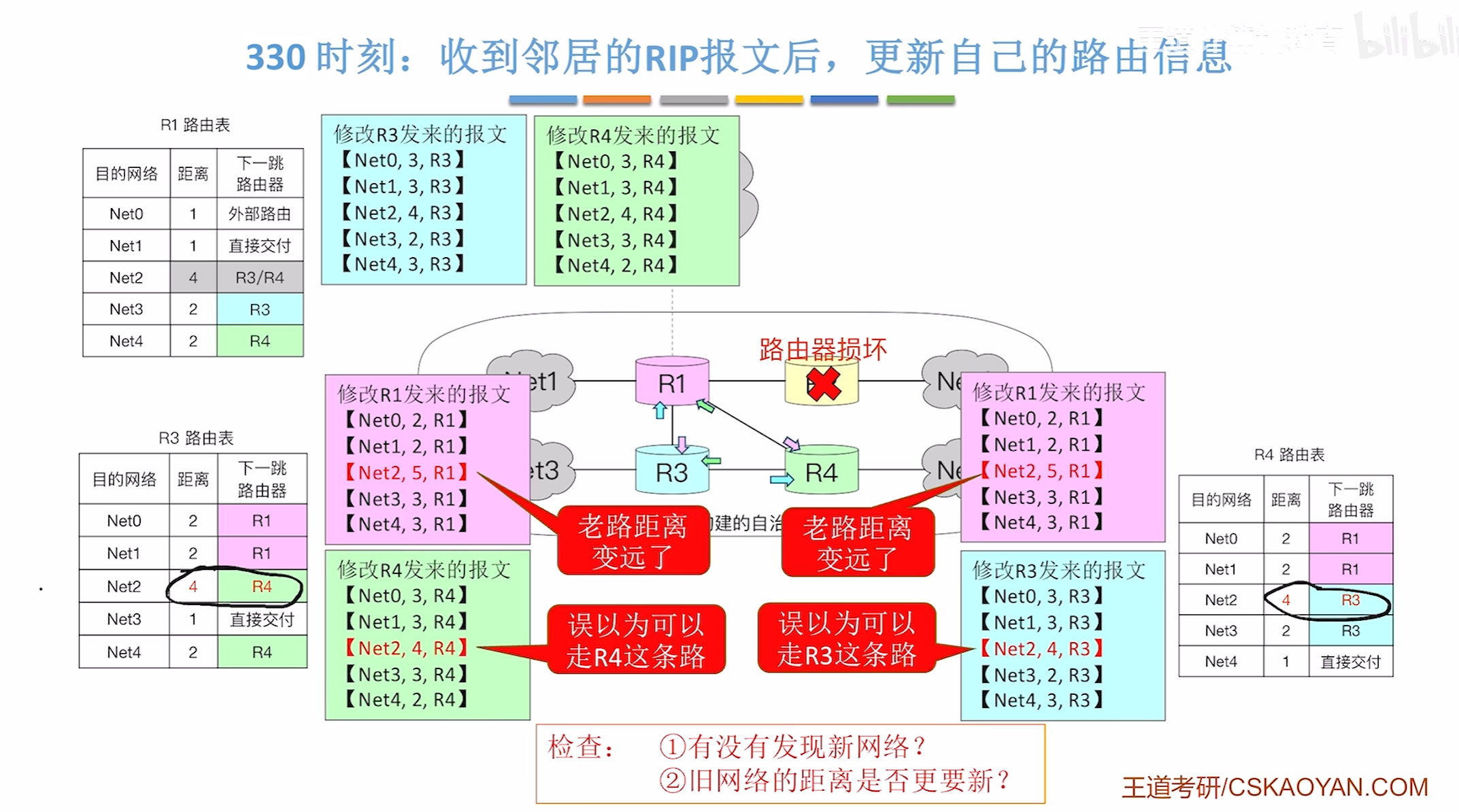
360时刻
再次更新路由表
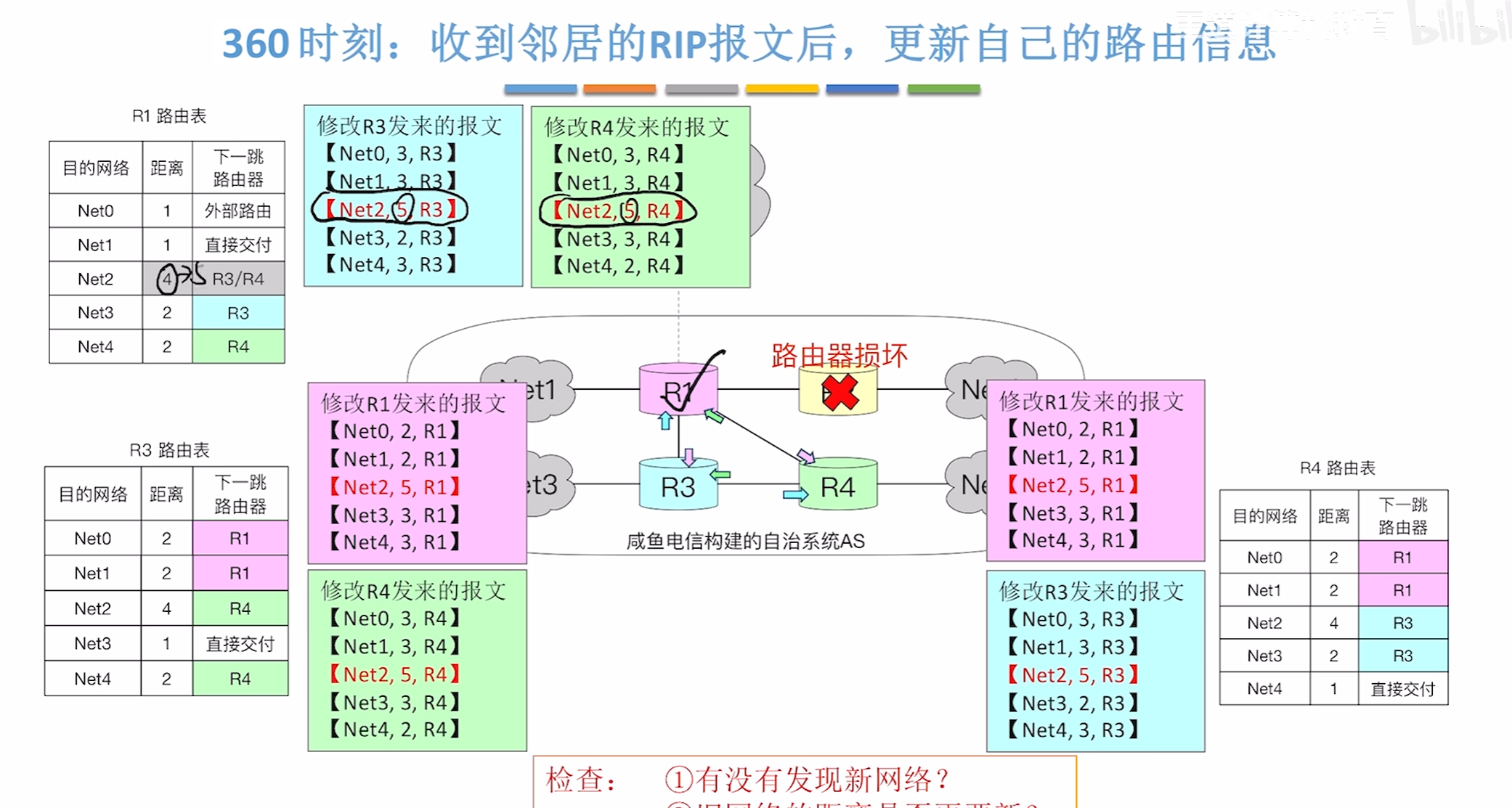
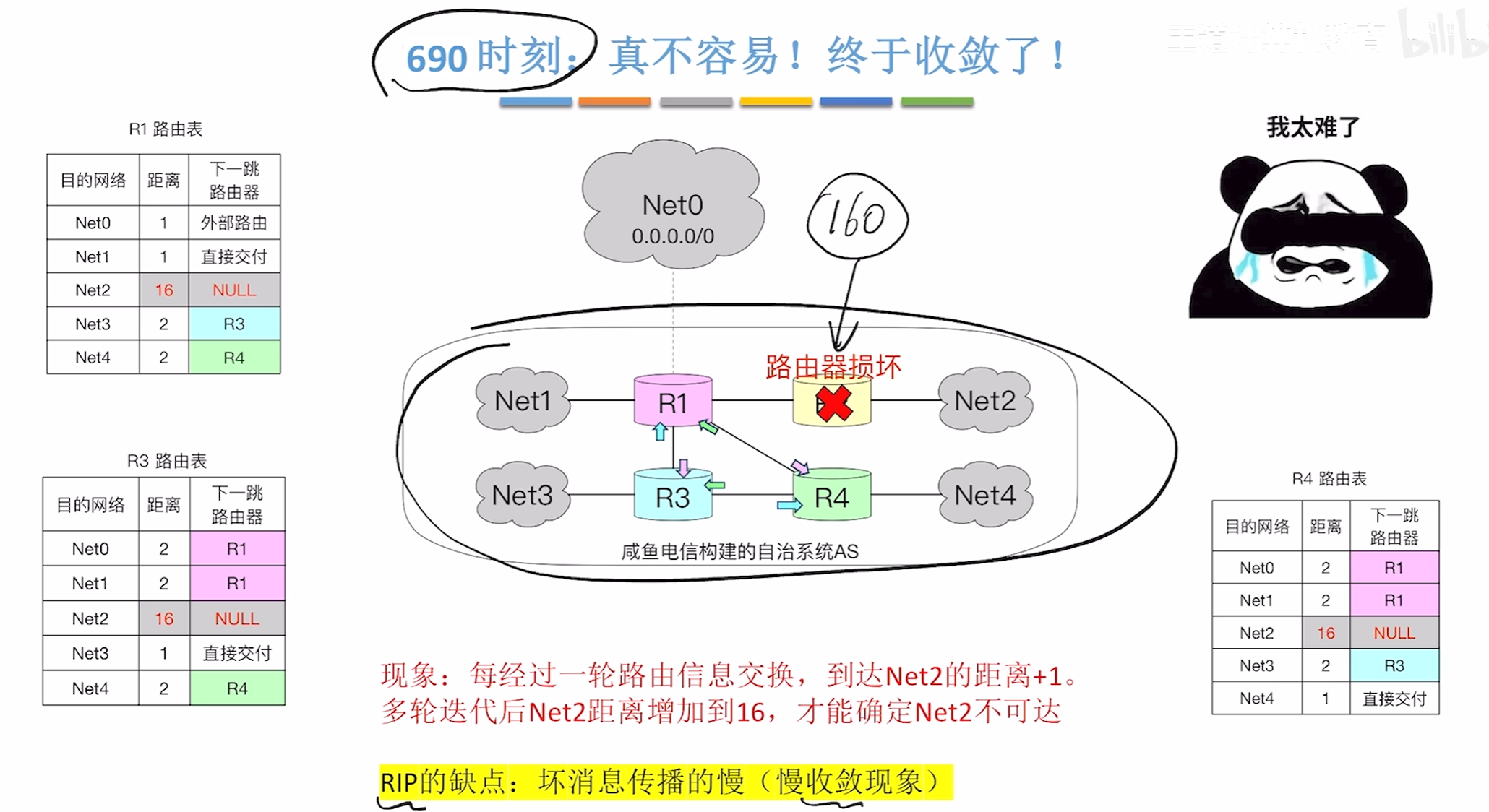
690时刻故障排查成功
多次迭代后的结果
坏消息传得慢

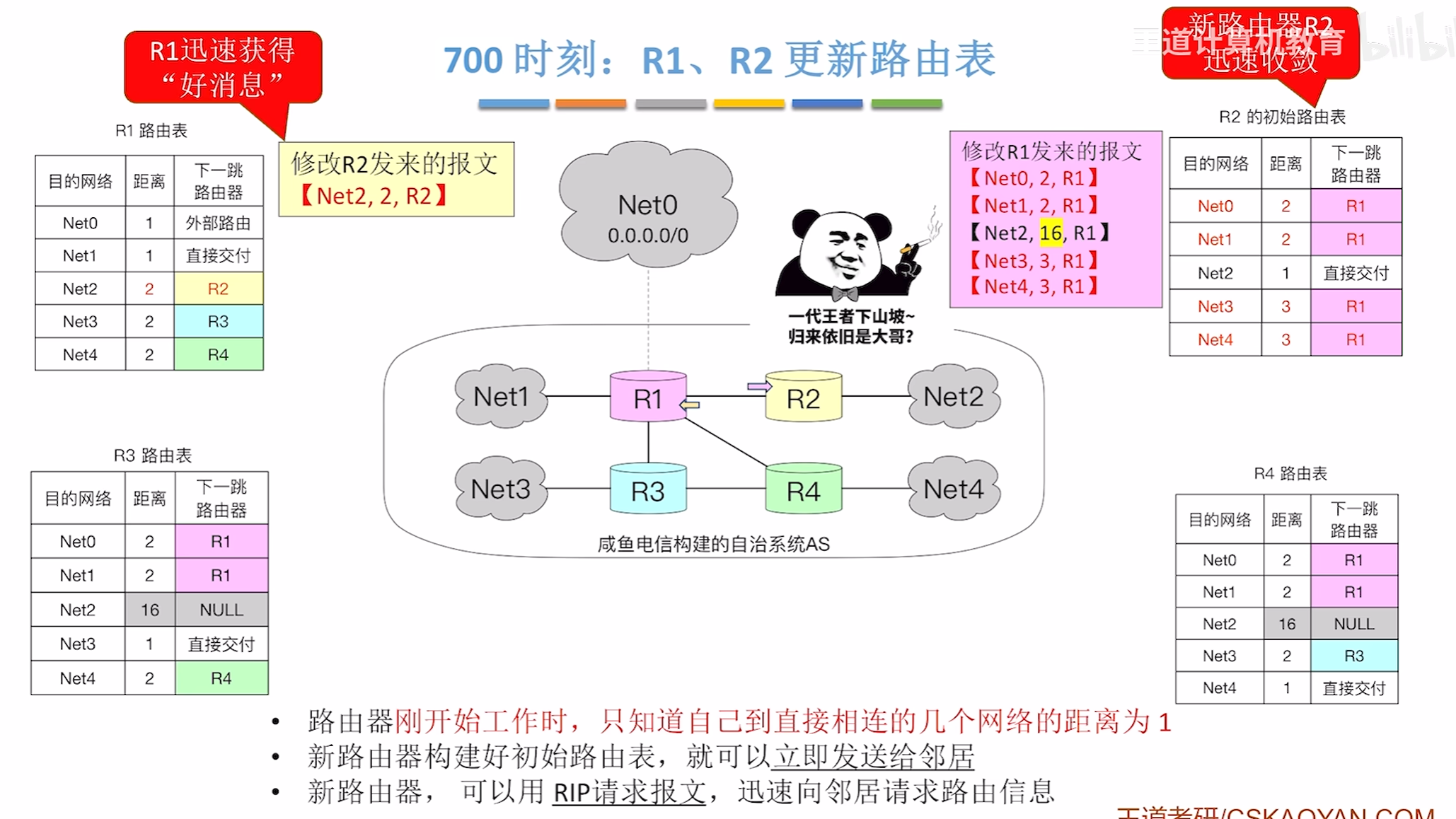
700时刻好消息传得快的体现
R2立马收敛
720时刻全部人都了解R2回来
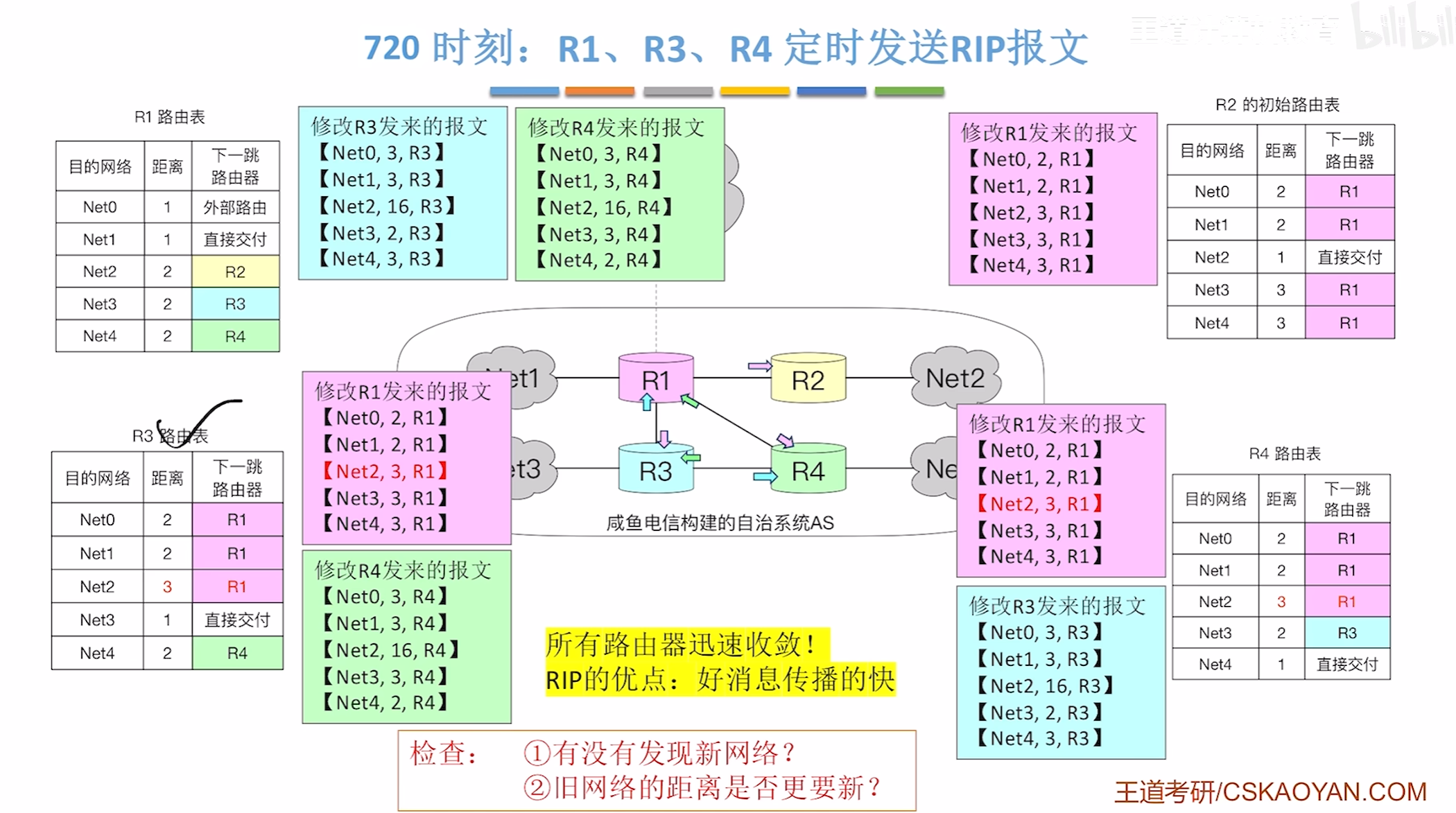
RIP的优缺点

ospf路由协议
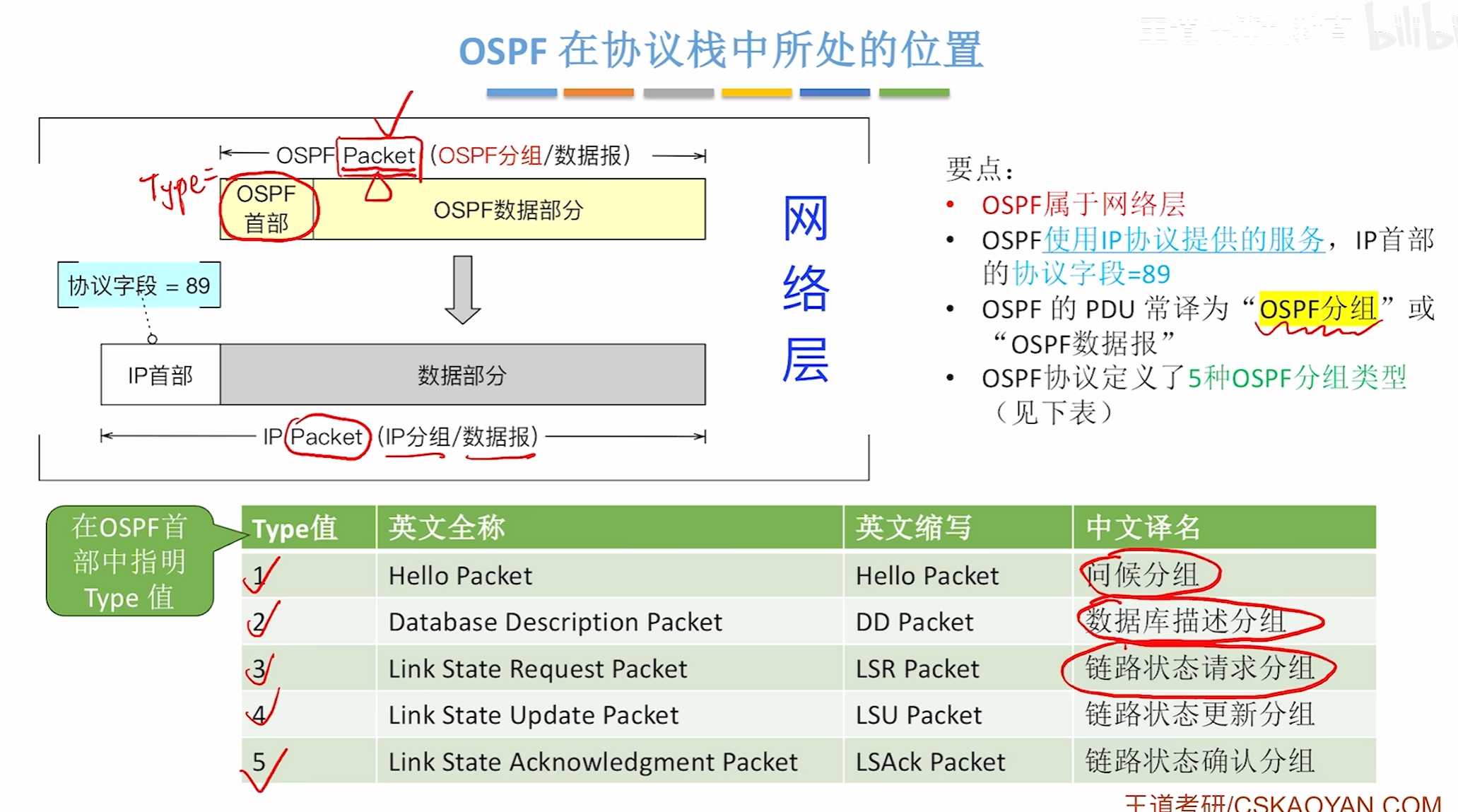
在协议栈中的位置
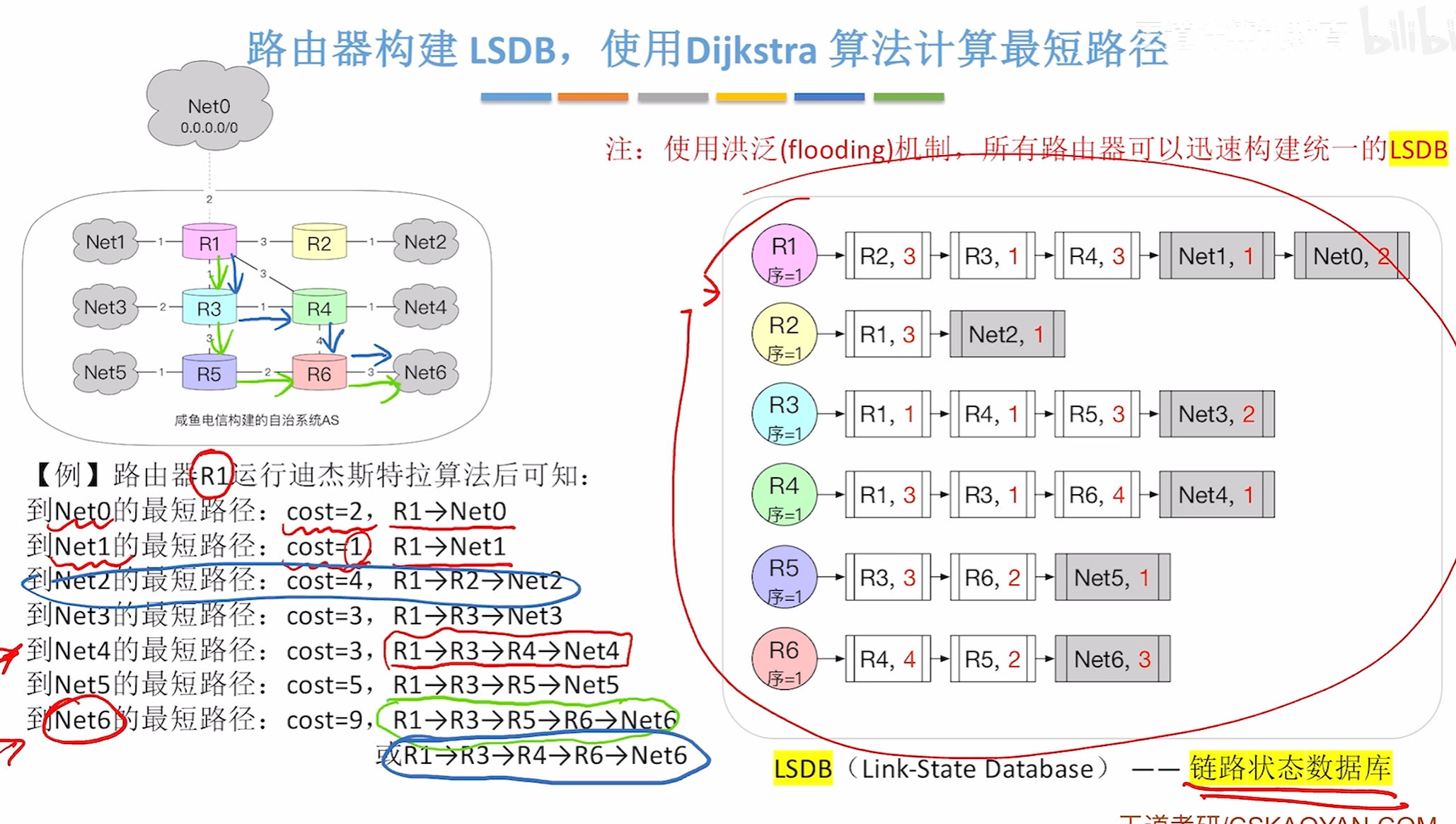
大致原理
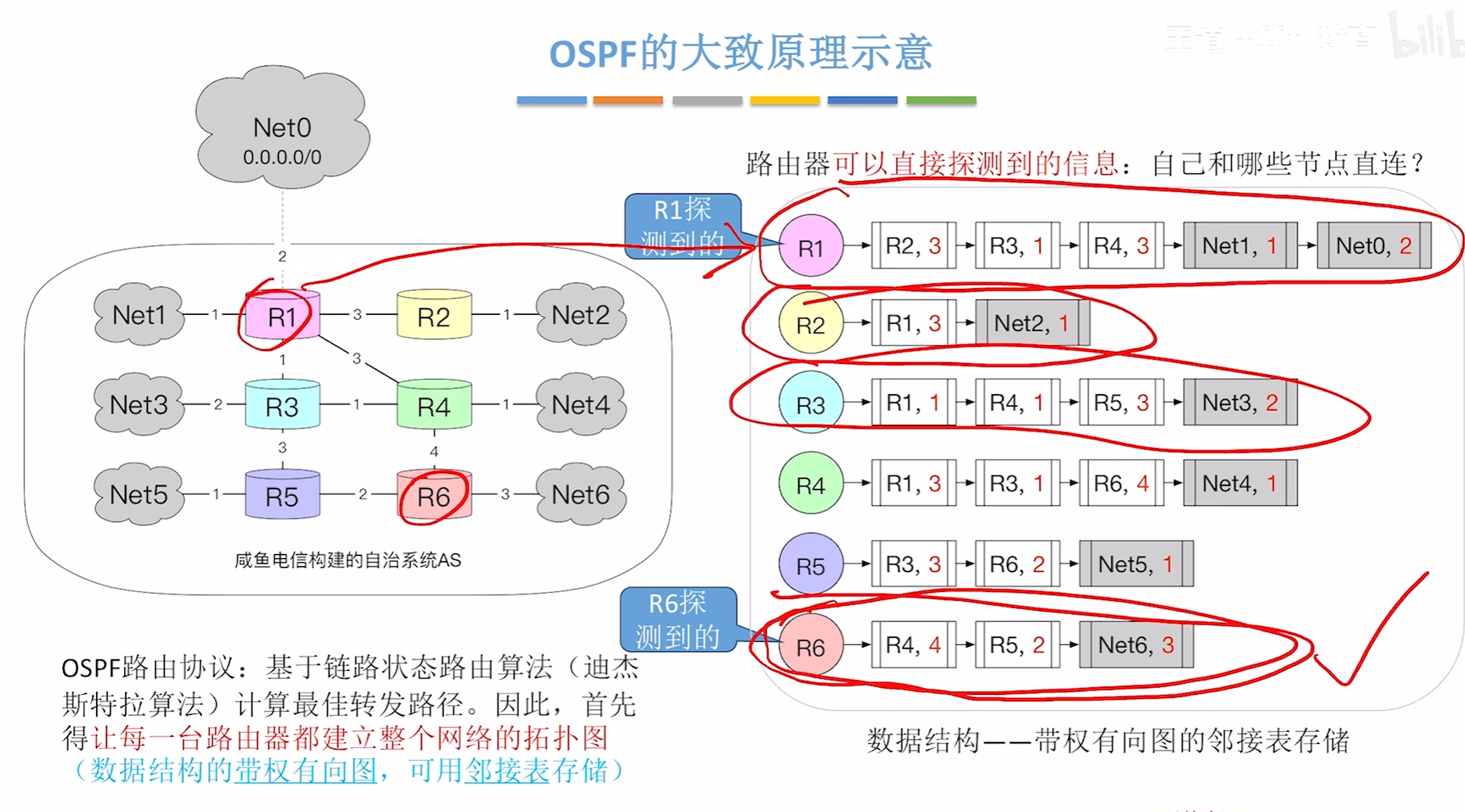
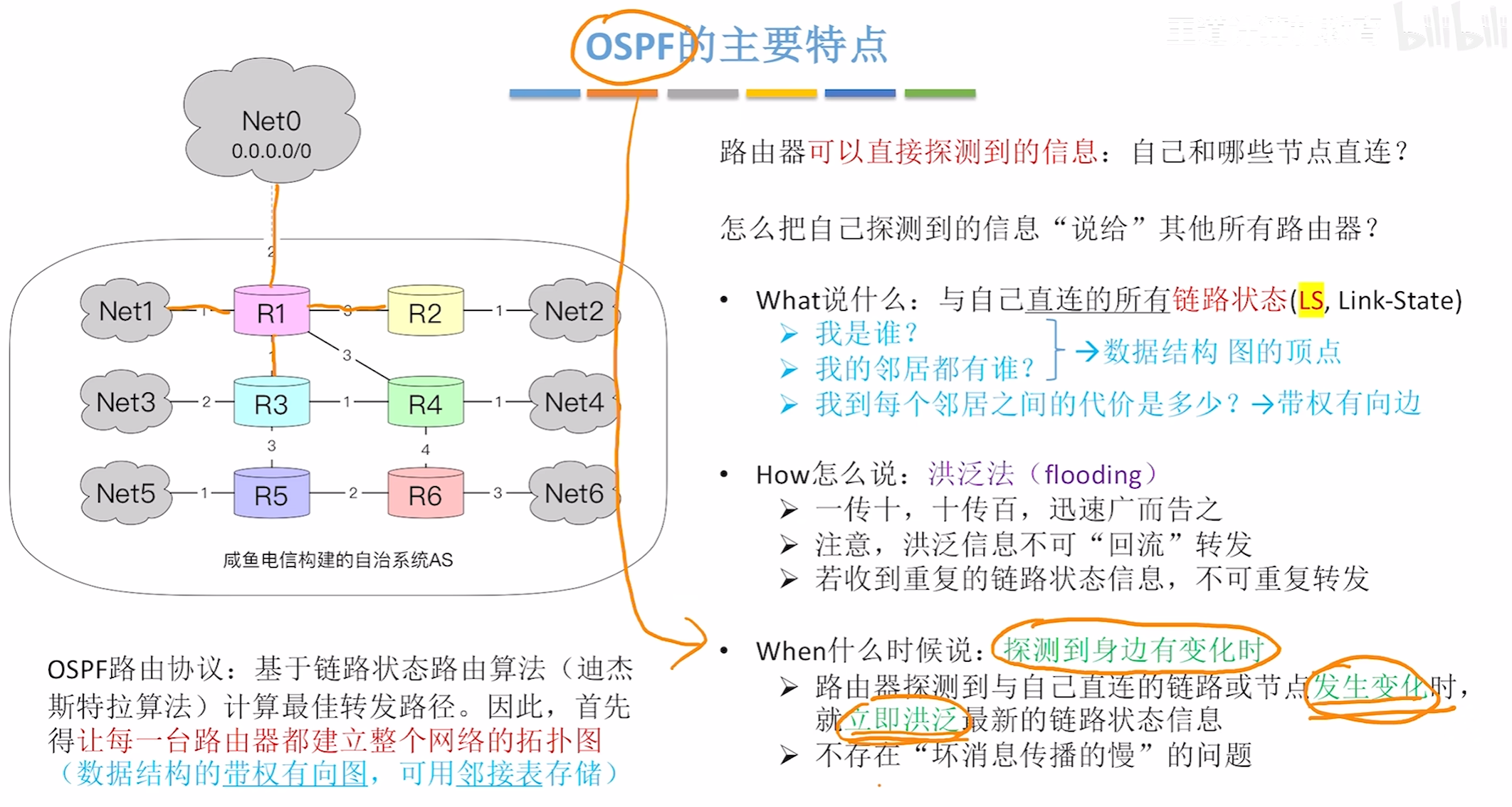
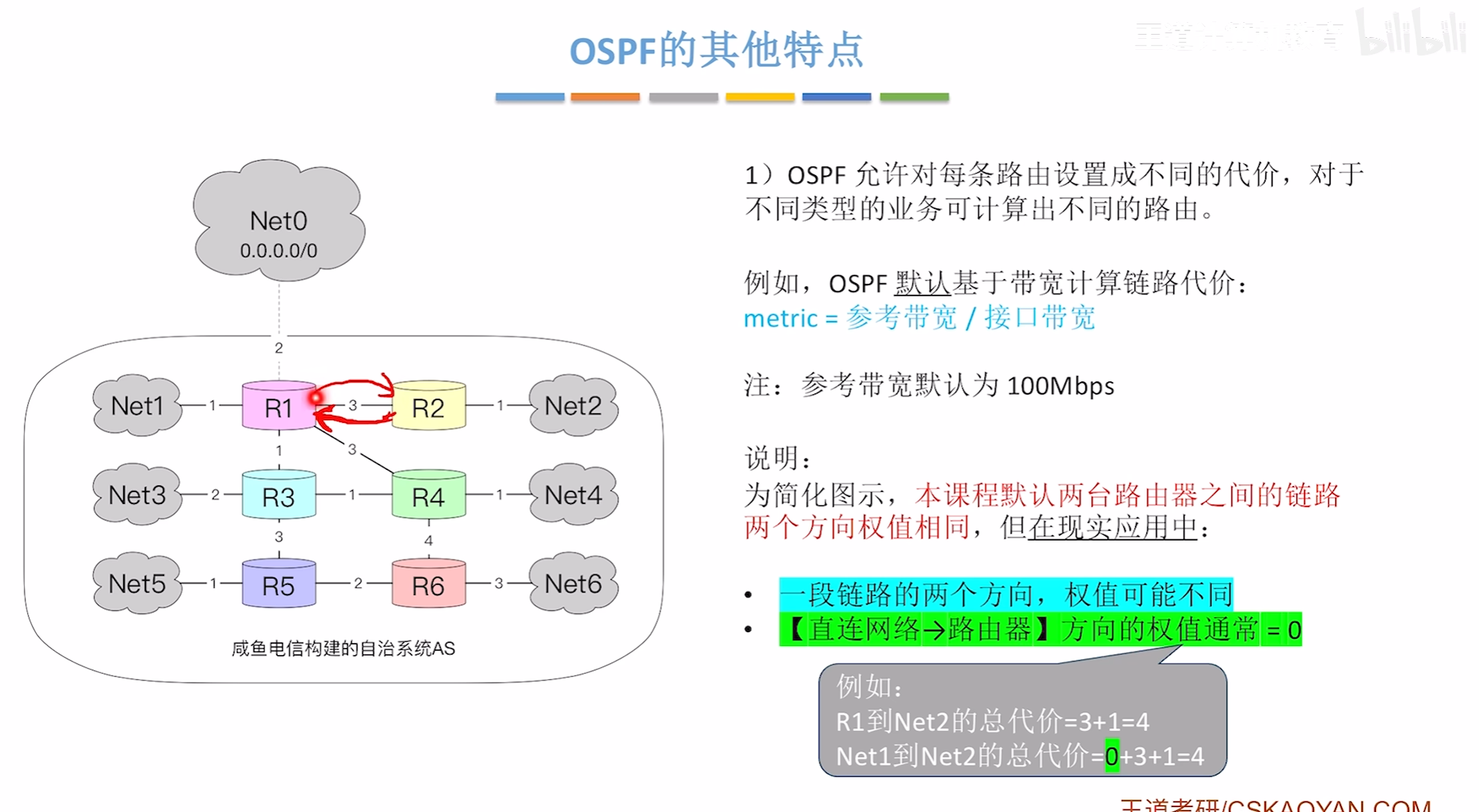
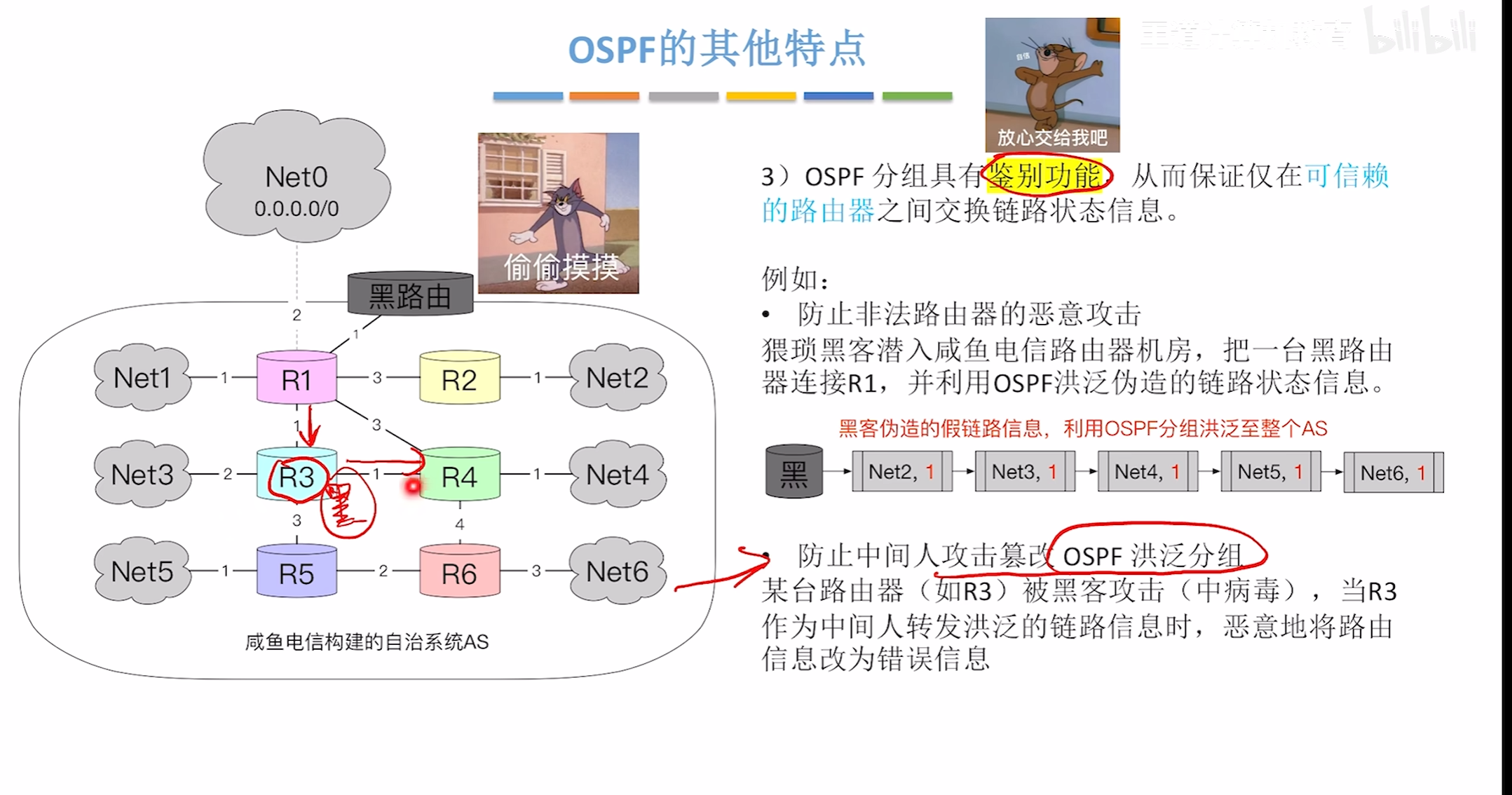
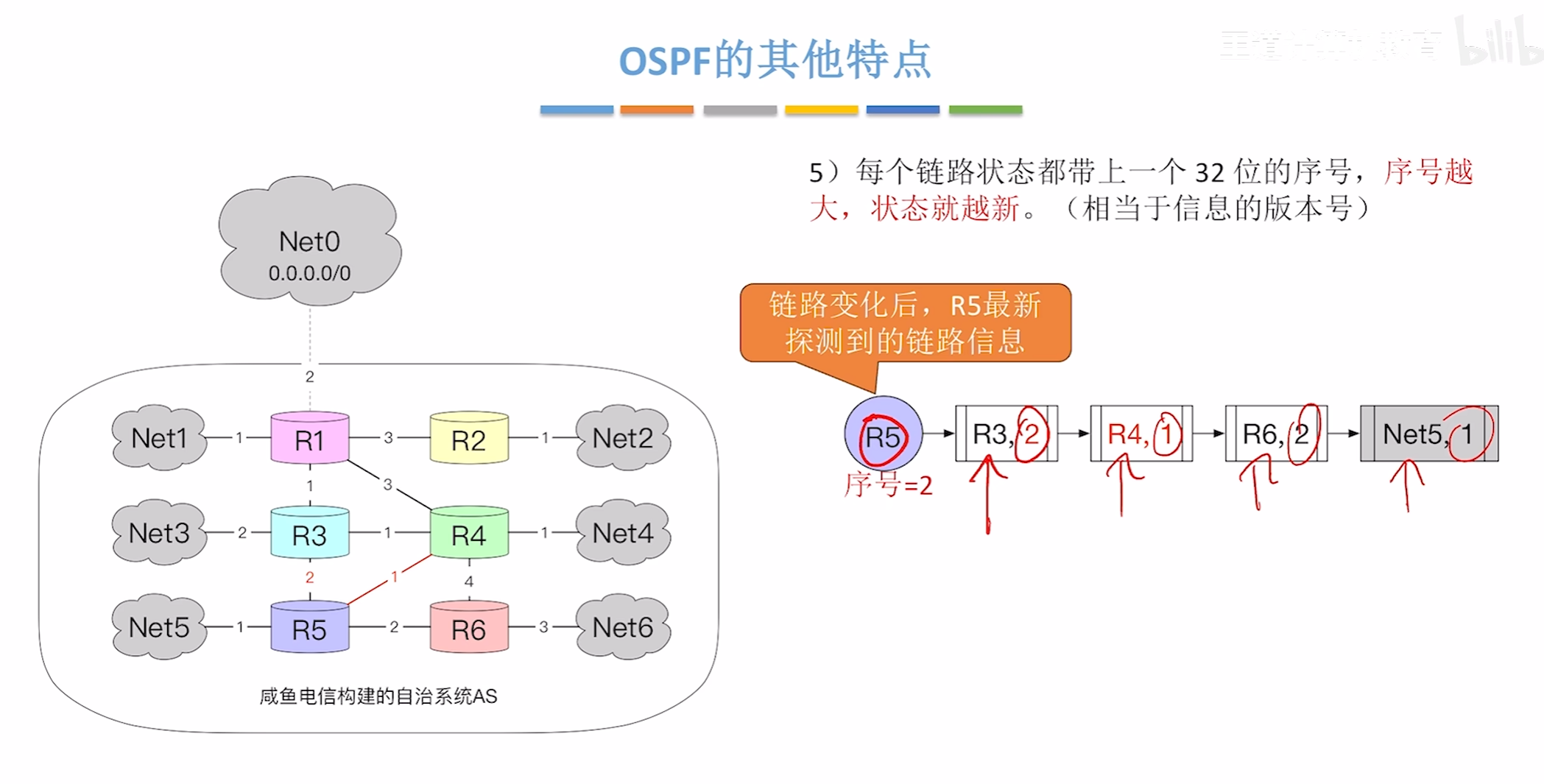
OSPF的主要特点
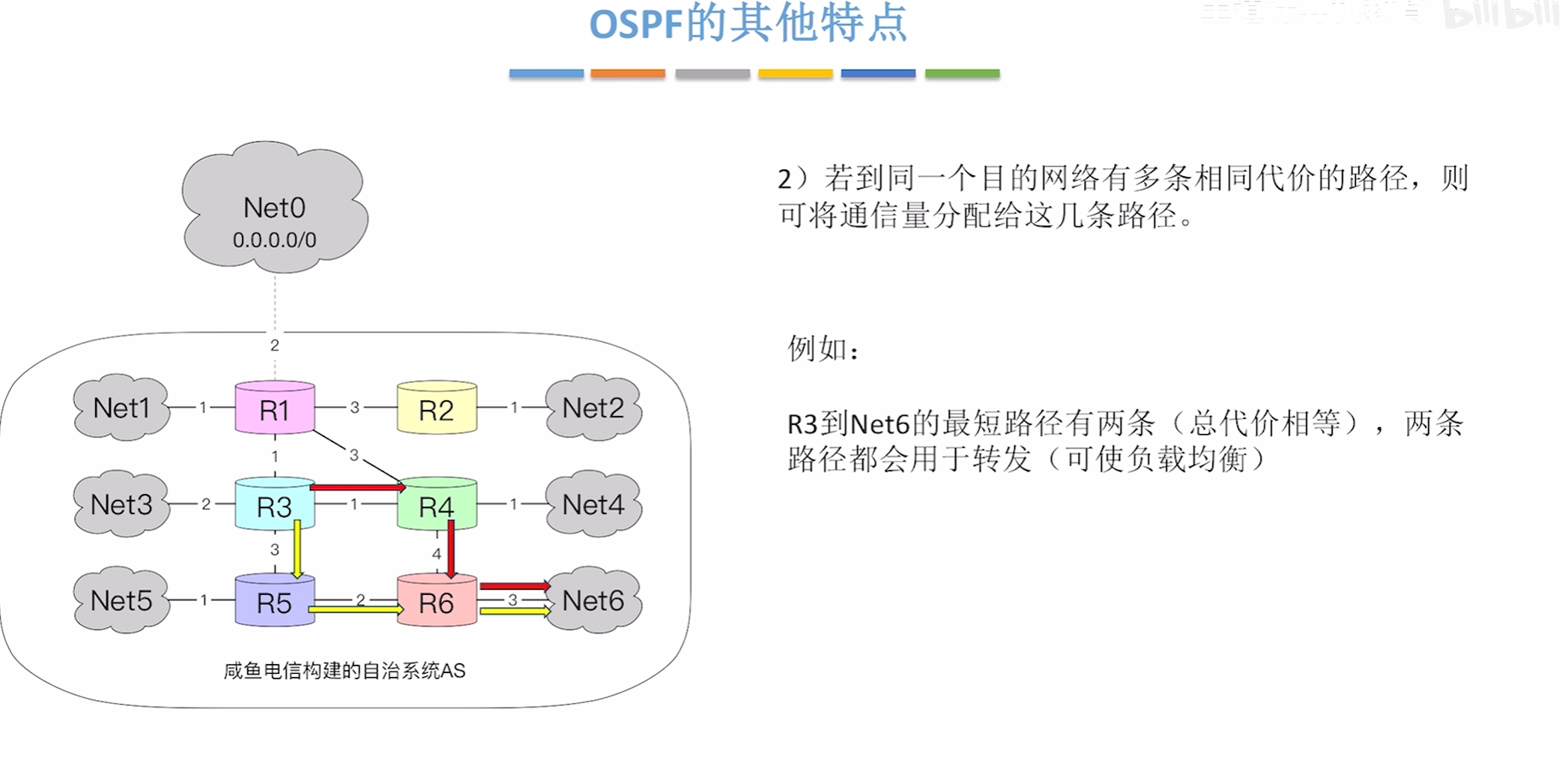


OSFP工作流程
OSPF区域的划分
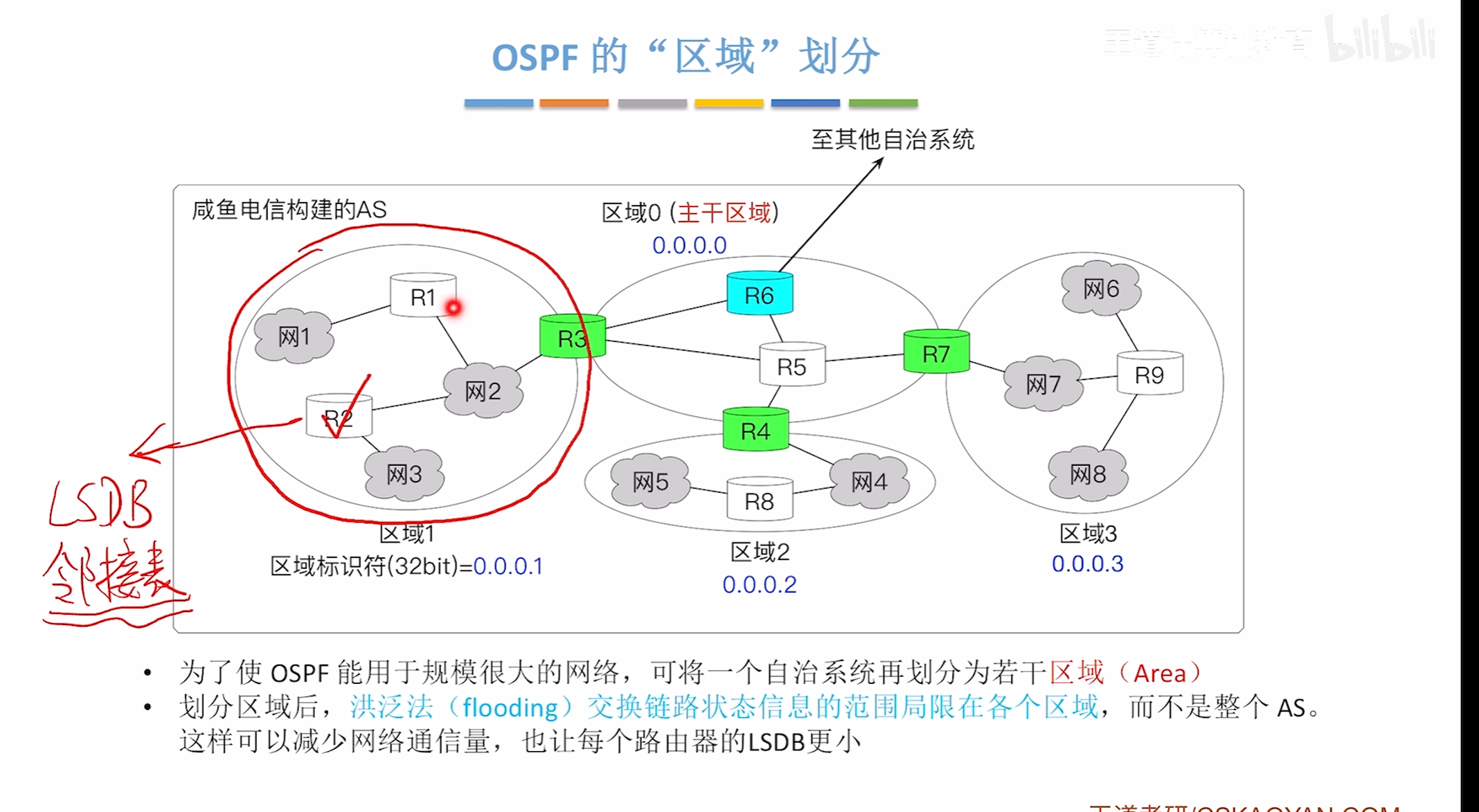
主干区域和非主干区域和区域边界路由器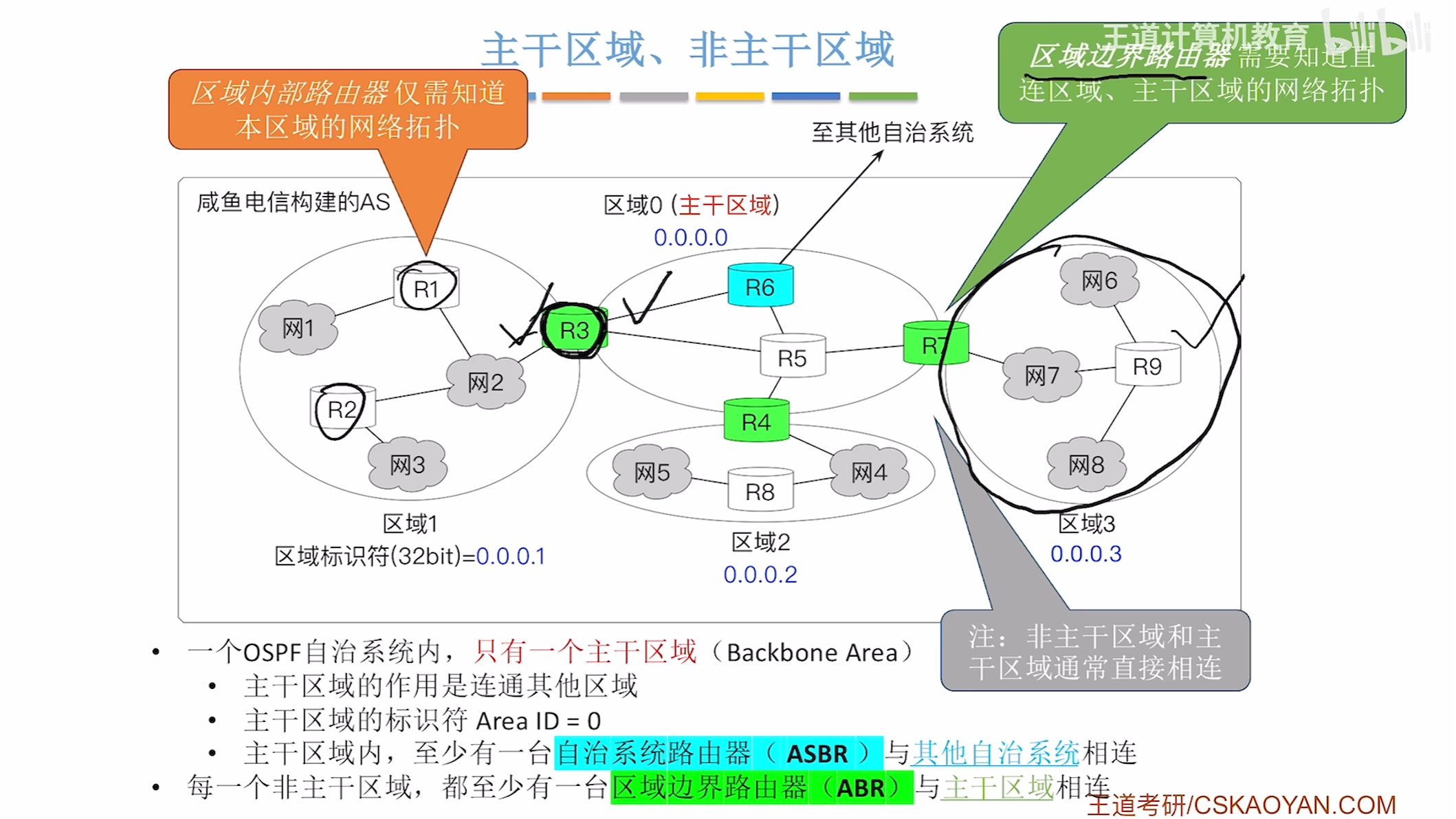
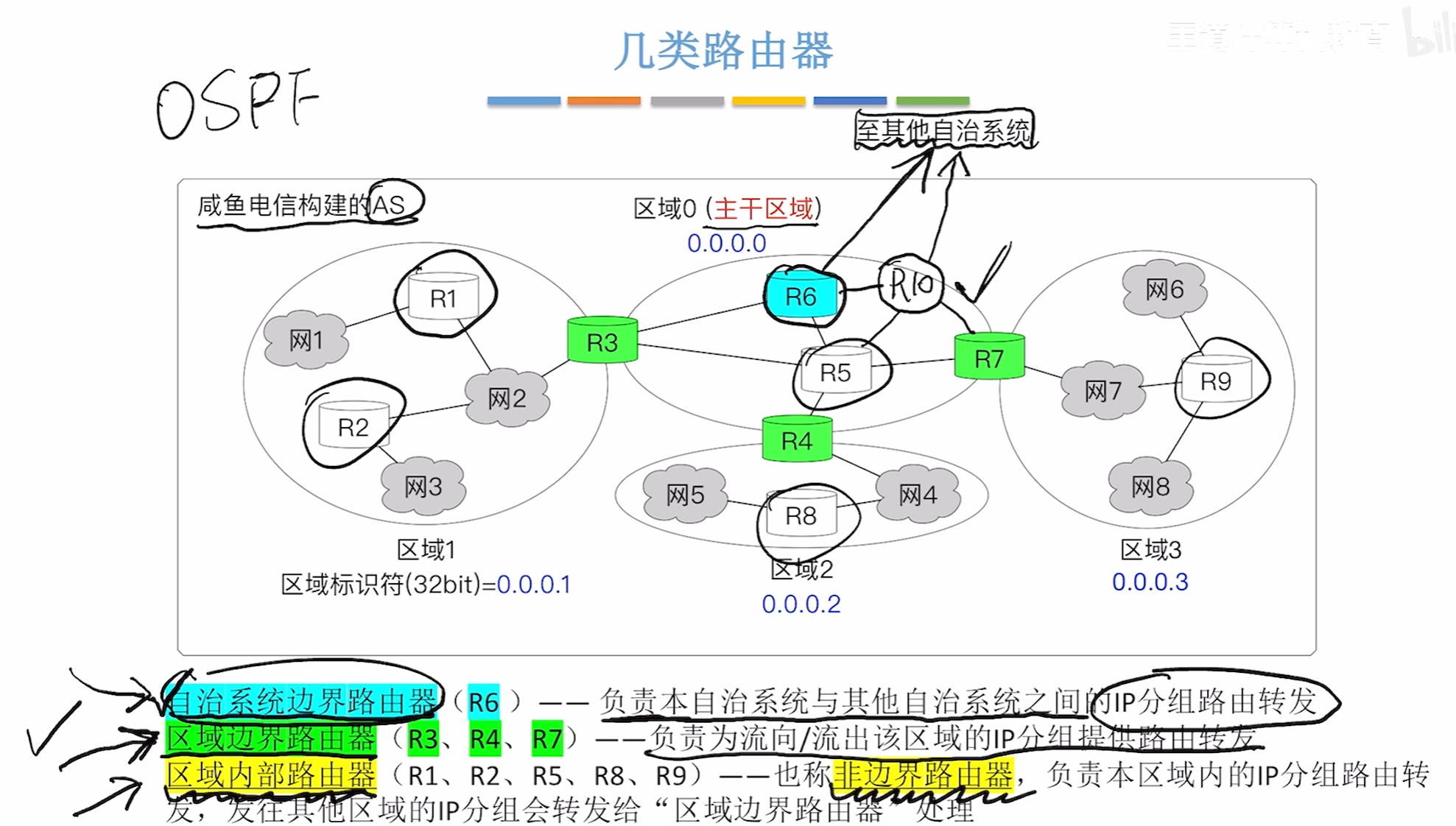
路由器类型
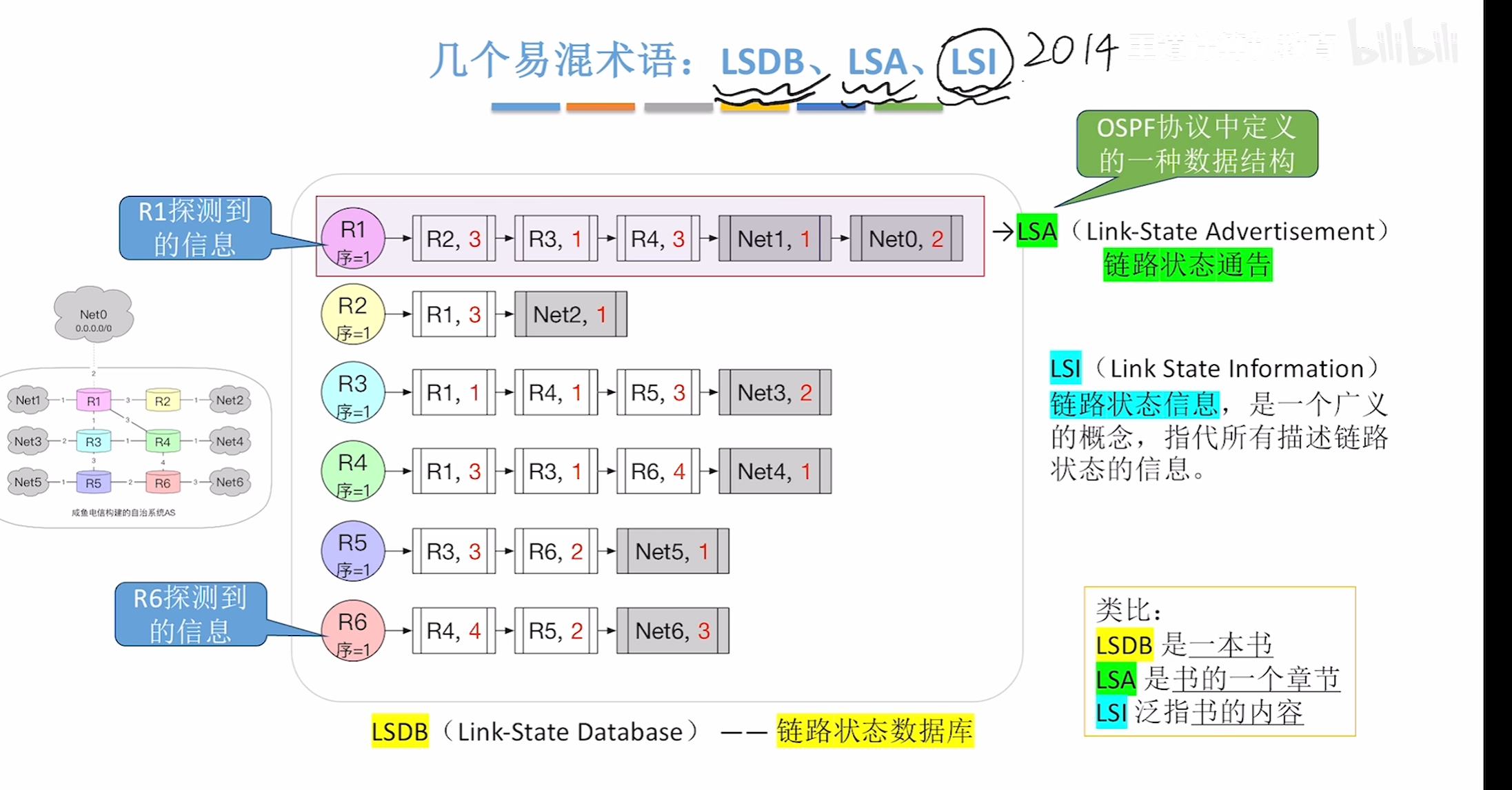
术语
OSPF协议分组类型
总结概括大概就是这样
1.新接入网络的路由器被看作为一个新同学,他被分配到了一个同桌,所以他和同桌会首先互相发送hello消息
2.接着当考试开始的时候,老同学会给新同学报告自己的信息,即自己还认识什么人,而新同学也会报告老同学自己的简要信息,即自己还认识什么人,即DD分组,发送LSA
3.接着新同学就会项同桌请求具体的认识那些同学,而老同学也会请求具体认识新同学的那些同学
4.接着新老同学都会告知与自己的相连的所有路由器,即自己认识的所有的人,我认识到了一群朋友,你们也认识一下,更新了全体的路由表,变成了一个全新的LSDB
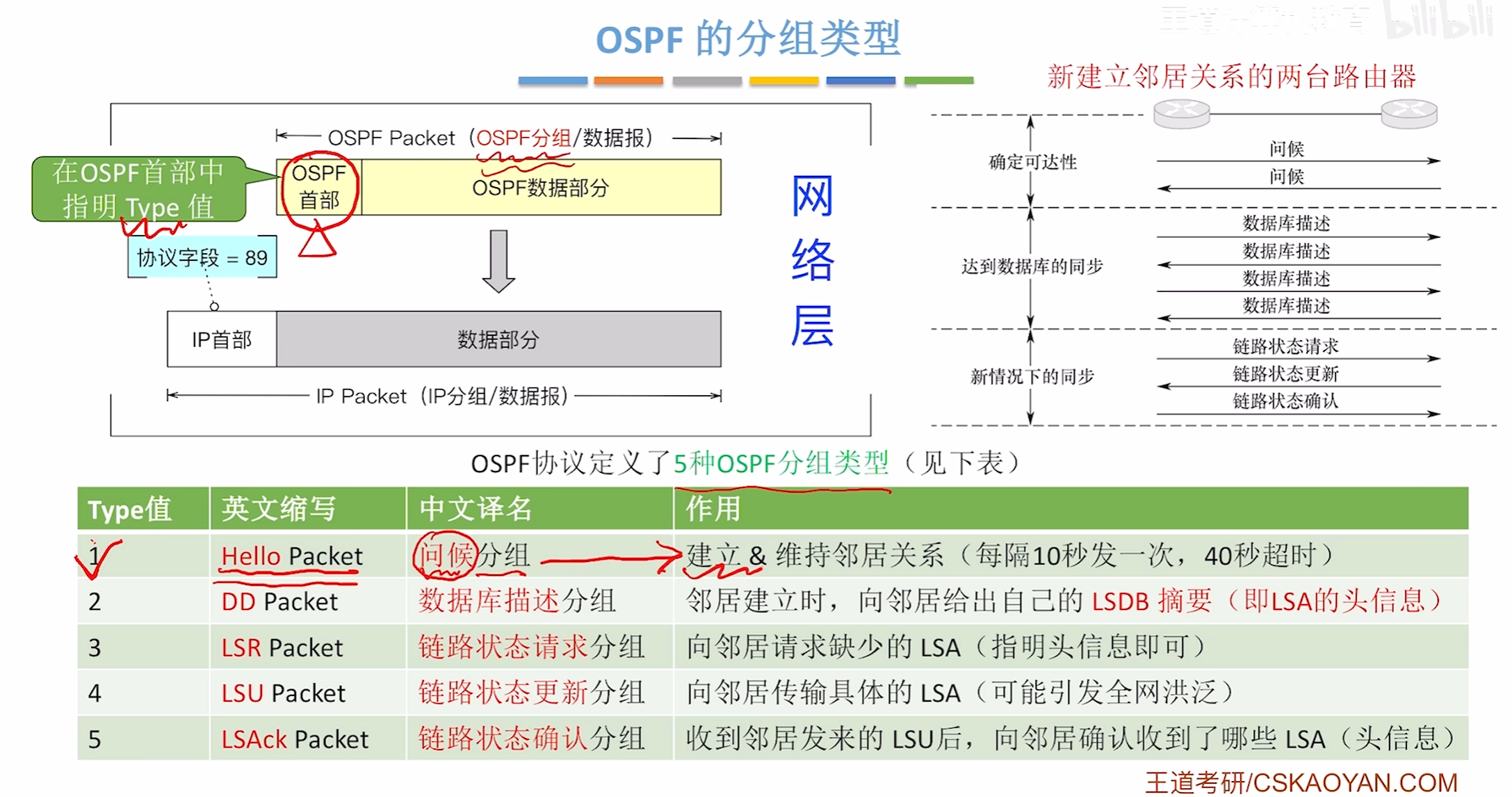
问候分组
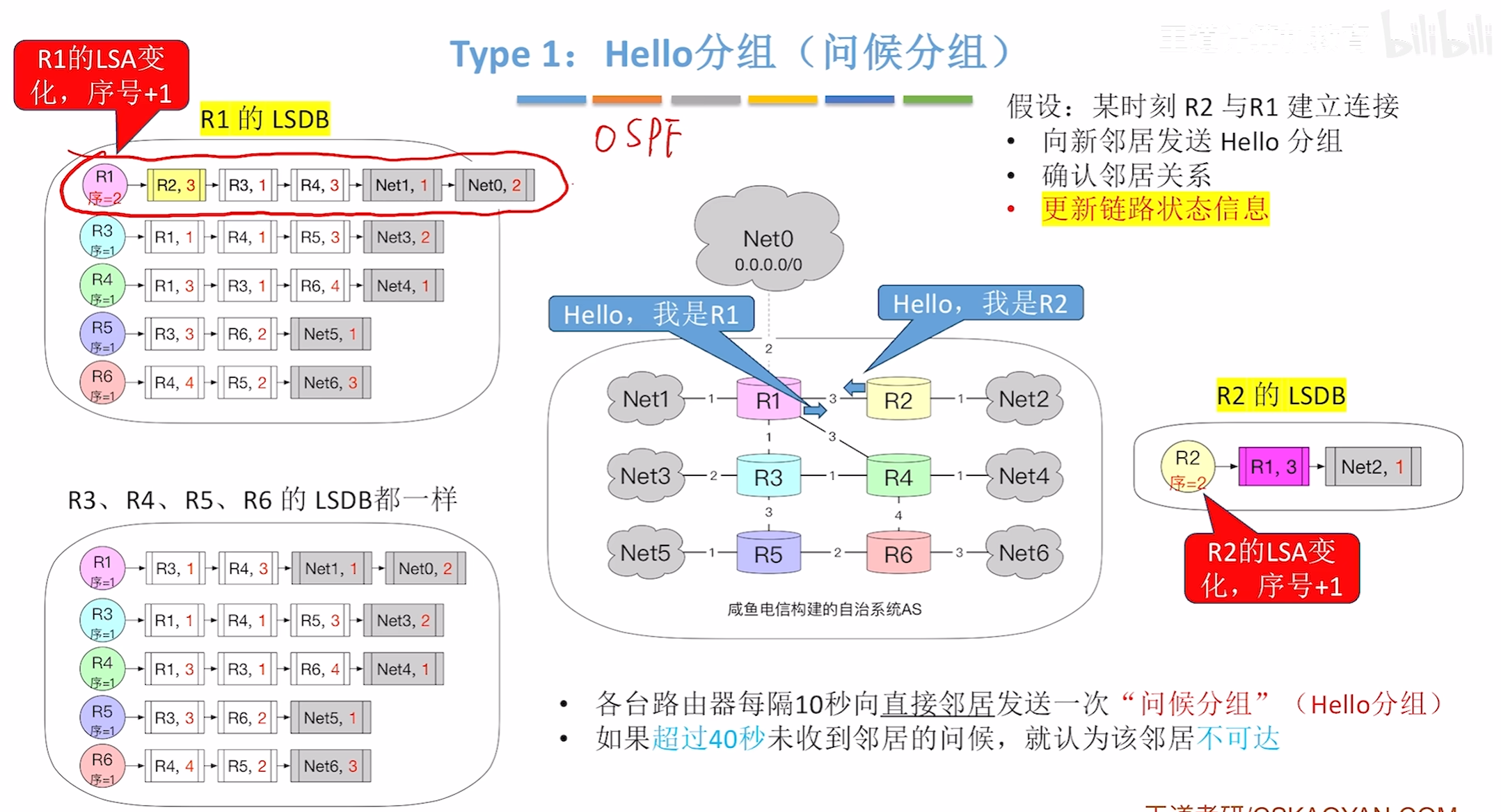
DD分组(数据库描述分组)
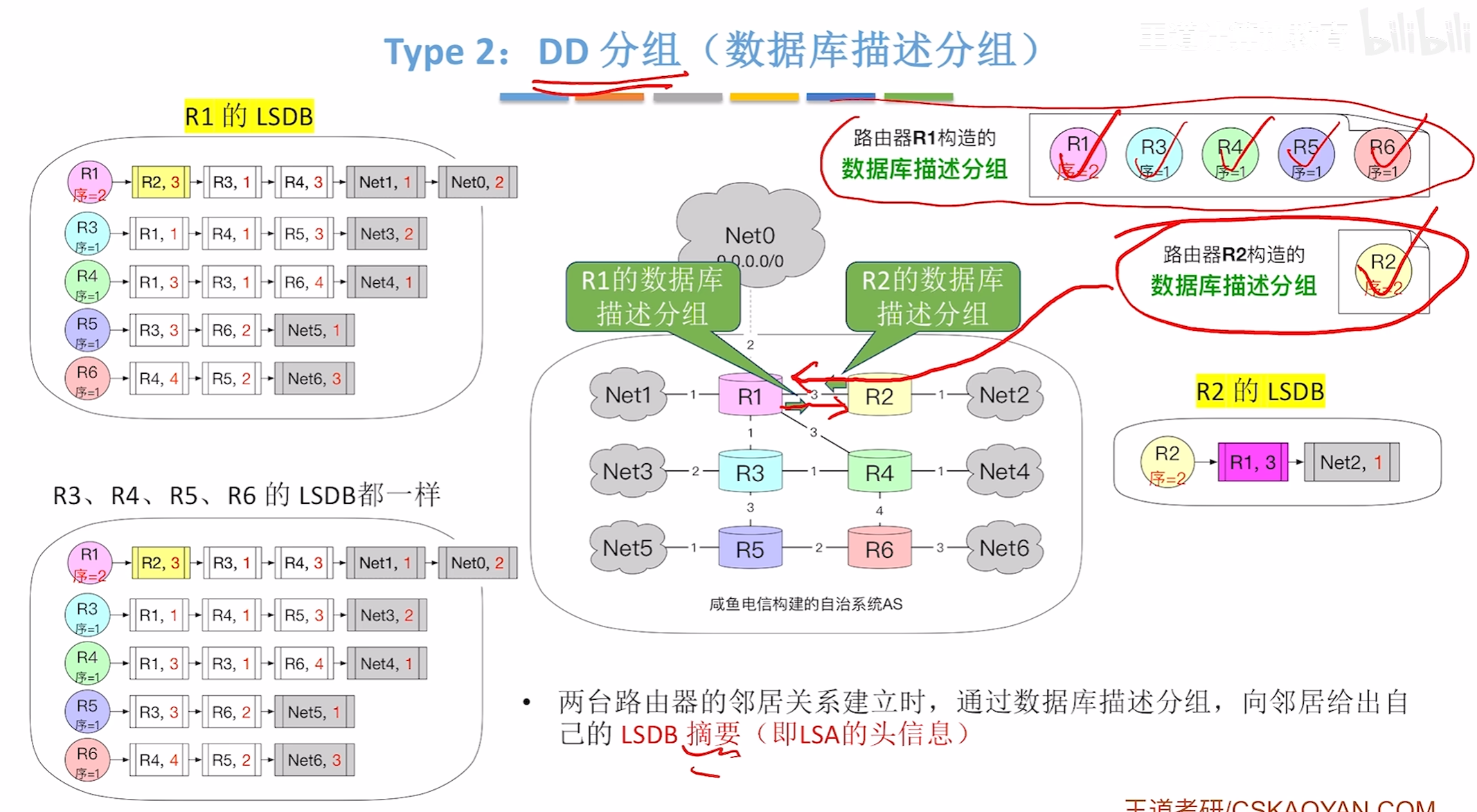
LSR分组(链路状态请求分组)
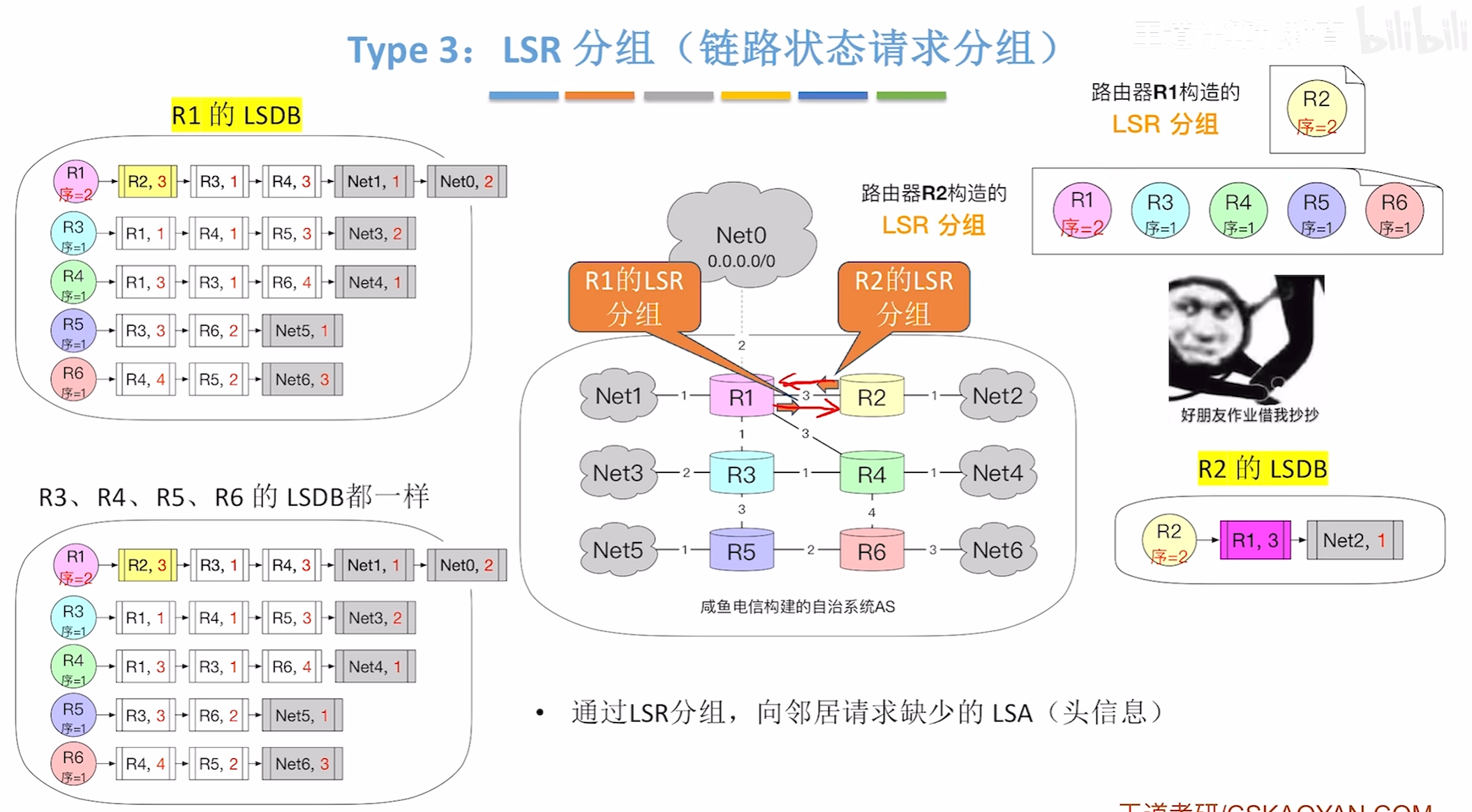
LSU分组(链路状态更新分组)
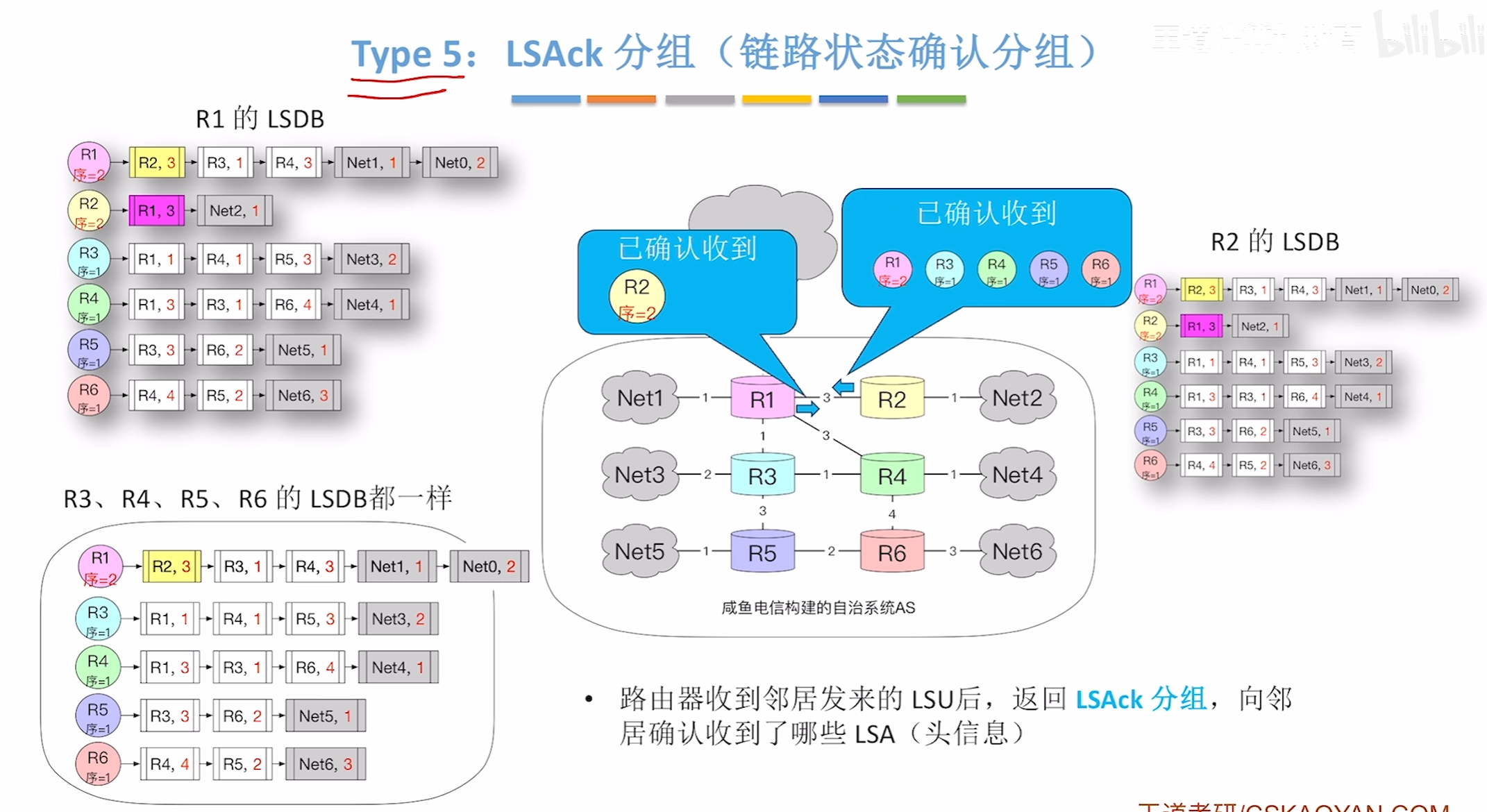
LSAck分组
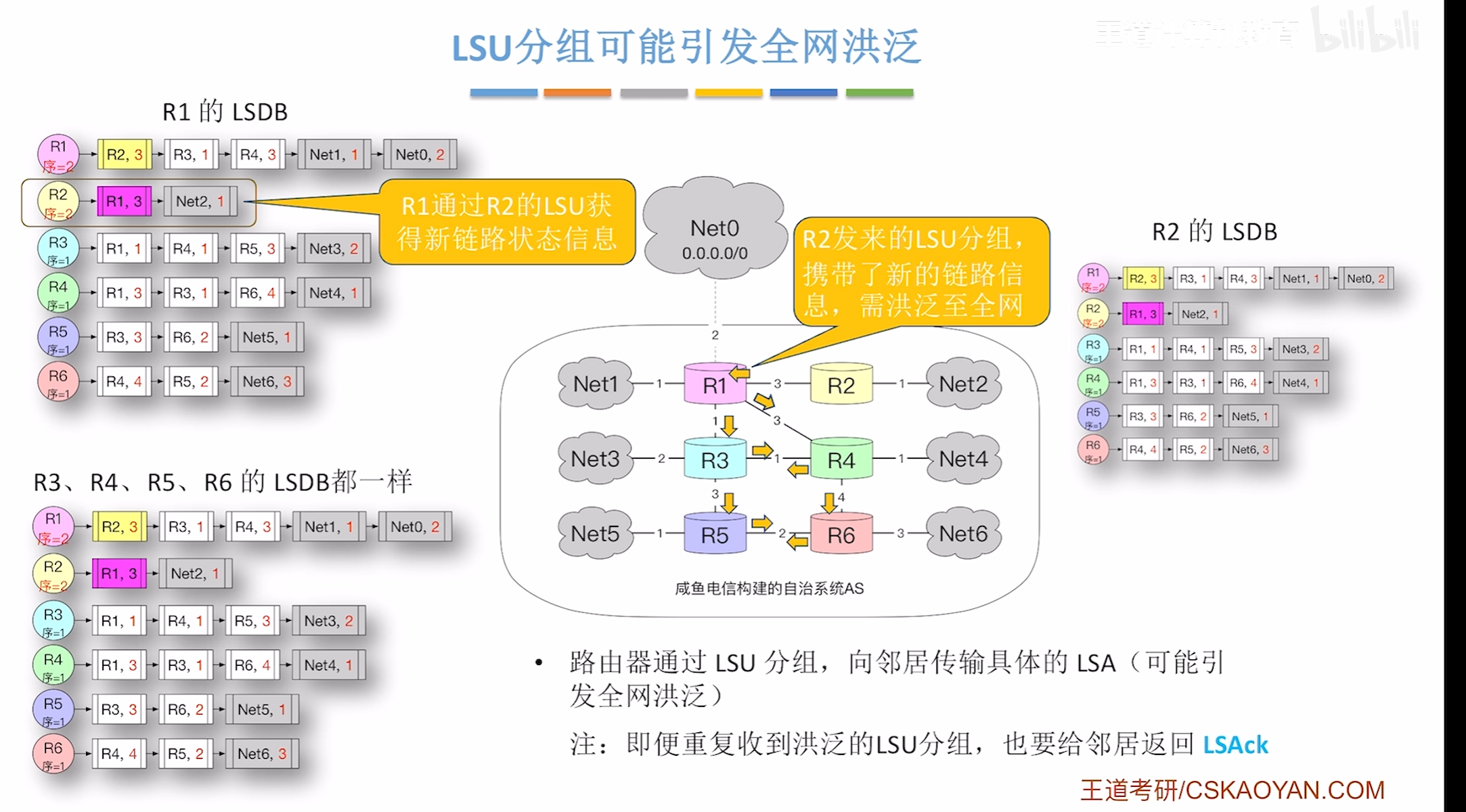
错题易错点
如何分析多余地址
您好,您提出的这个问题非常好,直击了路由聚合(Route Aggregation/Summarization)的核心要点和潜在风险。
将 `192.168.6.192/26` 和 `192.168.6.0/26` 进行聚合会引入多余的路由,是因为**聚合后产生的超网(Supernet)所覆盖的地址范围,比原始两个子网地址范围的总和要大,包含了原网络中并不存在的地址空间。**
下面我们通过详细的步骤来分析:
---
### 第一步:分析原始的两个地址块
1. **地址块 A: `192.168.6.0/26`**
* 子网掩码: `/26` 对应 `255.255.255.192`。
* 网络大小: 主机位有 `32 - 26 = 6` 位,总共 `2^6 = 64` 个地址。
* 地址范围: 从 `192.168.6.0` 到 `192.168.6.63`。
* 最后一个字节的二进制表示 (网络部分加粗): `**00**000000`2. **地址块 B: `192.168.6.192/26`**
* 子网掩码: `/26` 对应 `255.255.255.192`。
* 网络大小: 主机位有 `32 - 26 = 6` 位,总共 `2^6 = 64` 个地址。
* 地址范围: 从 `192.168.6.192` 到 `192.168.6.255`。
* 最后一个字节的二进制表示 (网络部分加粗): `**11**000000`### 第二步:进行路由聚合
路由聚合的目标是找到这两个网络地址的最长公共前缀。我们来比较它们的二进制形式:
* `192.168.6.0` -> `11000000.10101000.00000110.00000000`
* `192.168.6.192` -> `11000000.10101000.00000110.11000000`我们从左到右比较,发现前24位 (`11000000.10101000.00000110`) 是完全相同的。在第25位它们出现了不同(一个是0,一个是1)。
因此,最长的公共前缀是24位。
聚合后的路由就是:**`192.168.6.0/24`**。
### 第三步:分析聚合后的地址块
* **聚合路由: `192.168.6.0/24`**
* 子网掩码: `/24` 对应 `255.255.255.0`。
* 网络大小: 主机位有 `32 - 24 = 8` 位,总共 `2^8 = 256` 个地址。
* **地址范围**: 从 `192.168.6.0` 到 `192.168.6.255`。### 第四步:对比并找出“多余”部分(问题的关键)
现在我们来对比一下:
* **我们原本拥有的地址范围**:
* `192.168.6.0` - `192.168.6.63` (地址块A)
* `192.168.6.192` - `192.168.6.255` (地址块B)* **我们聚合后通告的地址范围**:
* `192.168.6.0` - `192.168.6.255` (聚合路由)**结论很明显:** 聚合后的路由 `192.168.6.0/24` 额外包含了两个我们实际上并**不拥有**的地址块:
1. **`192.168.6.64/26`** (范围: `192.168.6.64` - `192.168.6.127`)
2. **`192.168.6.128/26`** (范围: `192.168.6.128` - `192.168.6.191`)这两个地址块就是所谓的“**多余路由**”或“**引入的空洞**”。
### 为什么这会成为一个问题?
当你的路由器向外界通告(宣告)“所有去往 `192.168.6.0/24` 的流量请发给我”时:
* 如果一个数据包的目的地址是 `192.168.6.50`,它属于块A,没有问题,可以正确送达。
* 如果一个数据包的目的地址是 `192.168.6.200`,它属于块B,也没有问题,可以正确送达。
* **但是**,如果一个数据包的目的地址是 `192.168.6.100`,这个地址并不在块A或块B中。外部路由器会根据你的聚合路由把这个包发给你,但你的网络内部并没有这个地址的目的地,最终这个数据包会被丢弃。这种情况被称为“**路由黑洞** (Routing Black Hole)”。### 什么时候聚合是合适的?
只有当你要聚合的地址块是**连续且完整的**时候,才不会引入多余路由。例如,如果你拥有以下**所有四个** `/26` 的子网:
* `192.168.6.0/26`
* `192.168.6.64/26`
* `192.168.6.128/26`
* `192.168.6.192/26`这四个子网合在一起,正好完整地覆盖了 `192.168.6.0` 到 `192.168.6.255` 的全部地址。在这种情况下,将它们聚合成 `192.168.6.0/24` 就是一个完美、无损的操作。
**总结:** 路由聚合的本质是用一条路由条目来代表多条更具体的路由,以减小路由表的规模。但如果被聚合的子网之间存在“空隙”,那么聚合后的超网就会包含这些“空隙”,从而形成不精确的、可能导致流量黑洞的多余路由。
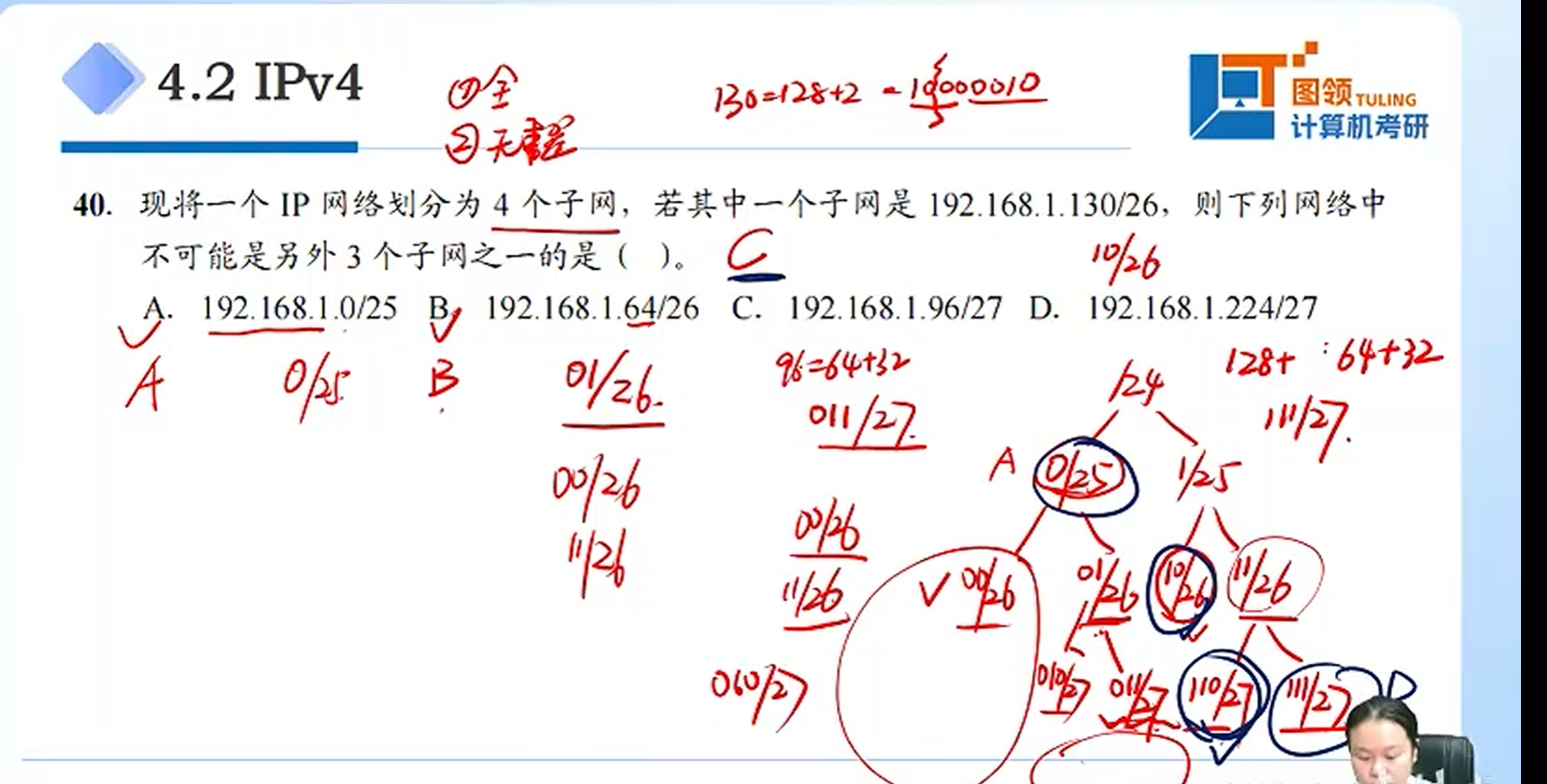
子网划分重点例题
即当该子网划分出来的时候能够向上合并,然后覆盖整个网络
A:此时位置在树中的0/25位置,那么我们只需要再划分110/27 111/27就可以实现全覆盖
即110/27 与 111/27可以合并成一个 11/26 然后11/26 与10/26可以合并成一个1/25然后 1/25 又可以和0/25聚合成一个/24 一个完整的子网
B:和A同理
接下来判断C为何不可以
当我们选择C时,他位于011/27 如果想要实现全覆盖那么它还需要 010/27 00/26 11/26这三个子网,这样子就会出现总计五个子网
那么为什么不能将1/25和0/25划分进来呢
因为子网划分还有一个重要的因素是,无重叠
1