安装JUPYTERHUB - 不使用LINUX本地用户
安装JUPYTERHUB - 不使用LINUX本地用户
- 背景
- 步骤
- 下载和安装基础环境
- JUPYTERHUB
- ANACONDA
- 配置
- 启动JUPYTERHUB
- 生成JUPYTERHUB配置并使用
- LDAP配置
- 其他基础配置
- 个人服务启动环境配置和跳过LINUX用户验证
背景
在LINUX机器中安装JUPYTERHUB时,JUPYTERHUB本身会希望使用LINUX用户来进行用户登录,权限判断和目录使用等,我这里不使用LINUX用户,而是使用LDAP作为登录验证,使用ANACONDA作为用户自有PYTHON环境,使用上更加灵活
步骤
下载和安装基础环境
JUPYTERHUB
基础PYTHON环境还是要有的,官网提供了使用本地PYTHON安装JUPYTERHUB和使用CONDA环境安装JUPYTERHUB两种方式,我这里使用的是PYTHON直接安装,CONDA安装也是相同步骤可以完成,只不过CONDA安装JUPYTERHUB耗时会很长
我这里使用的最新版本的JUPYTERHUB,所以按照官网要求PYTHON版本也使用了3.8
# 如果没有安装npm,按照系统内核自行选择安装
# Debian系列:Debian、Ubuntu等
sudo apt-get install nodejs npm
# RedHat系列:Redhat、Centos、Fedora等
sudo yum install nodejs npm# 按照官网安装JUPYTERHUB
npm install -g configurable-http-proxy
python3 -m pip install jupyterhub
JUPYTERHUB-GIT
ANACONDA
使用ANACONDA或者MINICONDA都可以,我理解配置是相同的,如果是ANACONDA的话可以参考我的这篇文章LINUX安装ANACONDA,这个过程就是点点点我就不赘述了,唯一需要注意的是不需要使用默认环境(也就是不需要在命令行开头显示base标志),这样就能保证使用你本来想使用的PYTHON版本,而不被ANACONDA的基础PYTHON环境覆盖(最新版本的ANACONDA的PYTHON版本已经到了3.12)
不默认使用ANACONDA的base环境需要在~/.bashrc中添加一句标识
# 在~/.bashrc中添加标识
conda config --set auto_activate_base false# 生效
source ~/.bashrc# 重新连接服务器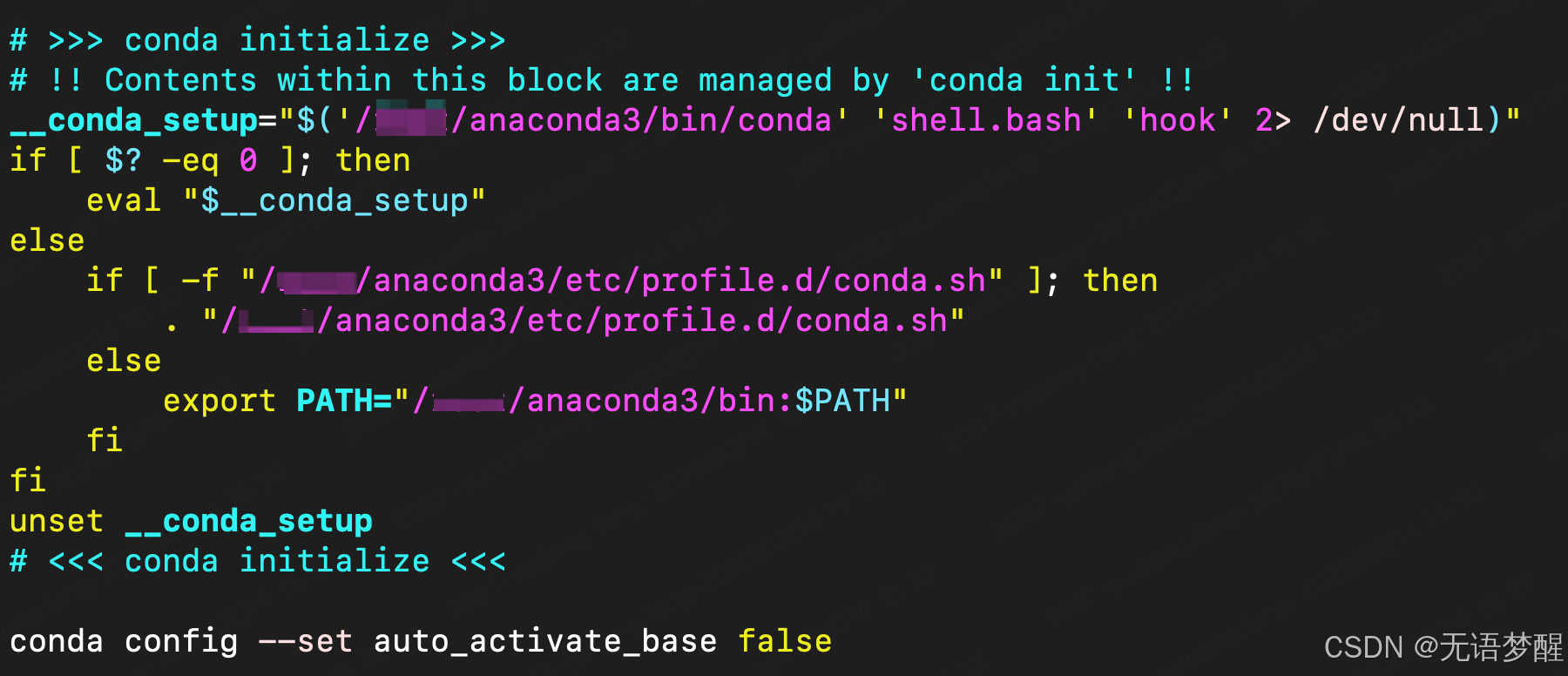
配置
启动JUPYTERHUB
接下来要频繁的执行该命令来调试无论是LDAP登录也好还是个人环境配置等
jupyterhub --debug
生成JUPYTERHUB配置并使用
# 生成配置文件,命令后可以跟随目录路径,省略路径的话,则直接在home/用户/目录中生成
jupyterhub --generate-config# 在~/.bashrc中添加配置文件路径
export JUPYTERHUB_CONFIG=/home/user/jupyterhub_conf.py# 生效
source ~/.bashrcLDAP配置
LDAP配置一般为企业配置,相关信息找对应的人问就好,基本属性如下
c.JupyterHub.authenticator_class = 'ldapauthenticator.LDAPAuthenticator'
# c.LDAPAuthenticator.create_system_users = False # 是否创建系统用户,通常设置为False# LDAP 服务器地址(LDAP:// 或 LDAPS://),自行修改
c.LDAPAuthenticator.server_address = 'ldap://XXXXXXXXXXXX'
c.LDAPAuthenticator.server_port = 389 # 默认 LDAP 端口 (389) / LDAPS (636)# 绑定用户(用于搜索用户信息)
c.LDAPAuthenticator.bind_dn_template = ["cn=XXXXX,dc=XXXXX,dc=XXXXX"
]
# # 或者,如果 LDAP 需要 Bind 用户身份认证,使用某一确认的只读账号密码
c.LDAPAuthenticator.bind_dn = 'cn=XXXXX,dc=XXXXX,dc=XXXXX'
c.LDAPAuthenticator.bind_password = 'XXXXX'c.LDAPAuthenticator.use_ssl = True # LDAPS
c.LDAPAuthenticator.allow_self_signed = True # 许自签名证书c.Authenticator.admin_users = {'admin'} # JupyterHub 管理员用户,LDAP的话可以指定对应的账号
c.Authenticator.allowed_users = set() # 允许所有通过 LDAP 认证的用户
c.Authenticator.allow_all = True如果仍然无法登录,可以使用ldapsearch验证一下LDAP相关配置是否正确,该命令会返回LDAP相关部分配置信息,如果失败则会提示Invalid credentials
# 如果没有安装的话需要手动安装一下,依然按照系统版本选择使用yum还是apt-get
yum install openldap-clients
# 使用提供的参数来替换网址,用户名,密码等相关信息即可
ldapsearch -x -H ldap://XXXXXXXXXX:389 -D "cn=USERNAME,dc=XXXXXX,dc=XXXXXX" -w 'PASSWORD' -b "dc=XXXXXX,dc=XXXXXX"
其他基础配置
在踩了很多坑之后认定以下参数可以参考,避免出现一些问题
c.JupyterHub.tornado_settings = {"xsrf_cookies": False
}
# 配置文件添加(不保证肯定解决此类问题,文件夹权限问题也可能导致此类问题)
c.Spawner.args = ['--allow-root']
个人服务启动环境配置和跳过LINUX用户验证
首先启动用户个人服务器验证器LocalProcessSpawner和SystemdSpawner均希望验证LINUX用户,所以如果不想使用LINUX用户的话验证上肯定会报错
jupyterhub home = pwd.getpwnam(self.user.name).pw_dirKeyError: "getpwnam(): name not found: 'XXXXX'"
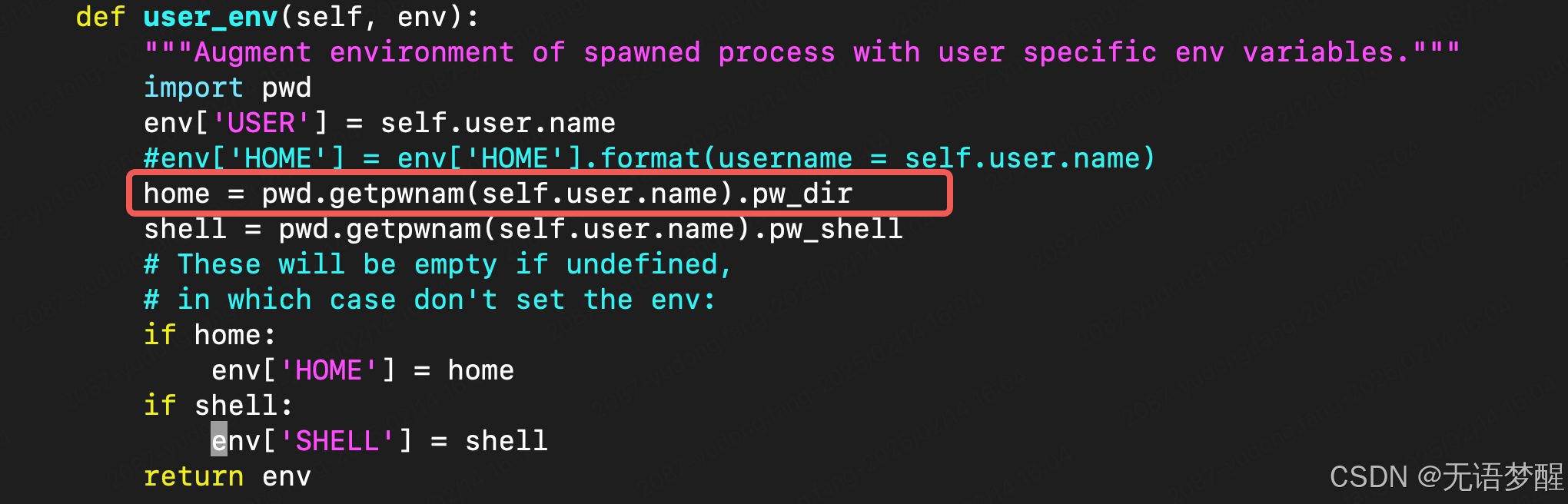
所以在配置文件中需要给出你想存储的用户目录位置,例如/data/jupyterhub/user,自己创建基础目录即可,需要给当前用户和其他用户的访问权限,像我就直接777了
# 例如给用户liyao授权
chmod -r 777 /data/jupyterhub/user/liyao
c.Spawner.notebook_dir = "/data/jupyterhub/user/{username}"
c.Spawner.args = ['--allow-root']
c.Spawner.environment = {'SHELL': '/bin/bash',
}而后就是需要自定义个人服务器启动脚本(所有的路径类信息均需要自己修改,没有默认值),保证用户登录可以使用指定的用户目录作为个人文件存储位置,那这里就涉及到三个点,先放脚本,然后再解释
custom_spawner.py
import os
import pwd
import subprocess
import shutil
from jupyterhub.spawner import LocalProcessSpawnerclass CustomCondaSpawner(LocalProcessSpawner):"""自定义 Spawner:- 允许 JUPYTERHUB 运行时不依赖 Linux 本地用户- 每个用户使用独立的 Anaconda 环境"""def user_env(self, env):"""设置环境变量"""# 获取登录的JUPYTERHUB用户名username = self.user.name # 用户独立的ANACONDA环境对应的绝对路径,需要自己修改CONDA_ENV_PATH = f"/anaconda3/envs/{username}"# 基础ANACONDA命令使用的绝对路径,需要自己修改CONDA_EXE = "/anaconda3/bin/conda"# 用户独立的ANACONDA环境对应的PYTHON的绝对路径,需要自己修改PYTHON_EXE = "/anaconda3/envs/" + username + "/bin/python"# 想要展示在JUPYTERHUB上的KERNEL环境名称IPYKERNEL_NAME = "python-kernel({" + username + "})"# 如果不存在则自动创建ANACONDA环境if not os.path.exists(CONDA_ENV_PATH):self.log.info(f"Creating Conda environment for {username}...")# 创建个人使用的PYTHON环境(ANACONDA环境)并在其中创建个人可用的IPYKERNEL,版本可以自己指定即可subprocess.run([CONDA_EXE, "create", "-n", username, "python=3.8", "-y"], check=True)# 有IPYKERNEL才能在JUPYTERHUB中有独立的个人环境空间subprocess.run([CONDA_EXE, "run", "-n", username, "pip", "install", "ipykernel"], check=True)# IPYKERNEL创建时不指定存储位置会创建在local中,这样在WEB页面上是无法看到的subprocess.run([PYTHON_EXE, "-m", "ipykernel", "install", "--prefix", CONDA_ENV_PATH, "--name", username,"--display-name", IPYKERNEL_NAME], check=True)# 设置环境变量env.update({'USER': username,'HOME': f"/data/jupyterhub/user/{username}", # 设置假的 home 目录,需要自己修改'SHELL': '/bin/bash','CONDA_DEFAULT_ENV': username,'CONDA_PREFIX': CONDA_ENV_PATH,'PATH': f"{CONDA_ENV_PATH}/bin:/anaconda3/bin:" + os.environ.get('PATH', ''),# 使得JUPYTER用户能够使用自己环境的IPYKERNEL,需要自己修改'JUPYTER_PATH': f"/anaconda3/envs/{username}/share/jupyter"})return envdef make_preexec_fn(self, name):"""创建用户目录"""home_dir = f"/data/jupyterhub/user/{name}"def preexec():os.makedirs(home_dir, exist_ok=True) # 自动创建目录os.chdir(home_dir)return preexec- 首次登录判定和使用指定的用户目录:得存储目录,所以首次登录如果没有得创建目录,并在配置文件中指定虚假的用户目录参数
- 首次启动判定和使用指定的用户环境:得有环境,所以首次登录的时候如果没有得创建环境和内核,并安装基础需求的PYTHON包,否则会出现可以正常启动JUPYTERHUB服务,但无法正常启动内核的问题
- 登录完成后可以使用指定的用户环境:得使用个人环境,所以得把虚拟环境的存储目录指定在对应用户的CONDA目录下
最后就是引用了,在生成的配置文件中,例如我的话就是/home/user/jupyterhub_conf.py中添加
import sys
import os# 添加 个人服务生成器 custom_spawner.py 所在的目录
sys.path.append('/home/user/jupyterhub') from custom_spawner import CustomCondaSpawner
c = get_config()
c.JupyterHub.spawner_class = CustomCondaSpawner