深入剖析LLM:从原理到应用与挑战
在当今的科技浪潮中,大型语言模型(LLM,Large Language Model)无疑是最耀眼的明星之一。作为一名资深的计算机技术博主,今天就来和大家深入聊聊LLM。
一、LLM是什么
LLM是一种基于深度学习的自然语言处理技术,其核心在于通过深度神经网络,在大规模的文本数据上进行预训练。这些模型包含着数十亿甚至数千亿的参数,能够学习到丰富的语言知识和语言模式,从而具备强大的自然语言理解和生成能力。从简单的文本分类、命名实体识别,到复杂的机器翻译、对话生成,LLM都展现出了卓越的表现。
二、LLM的发展历程
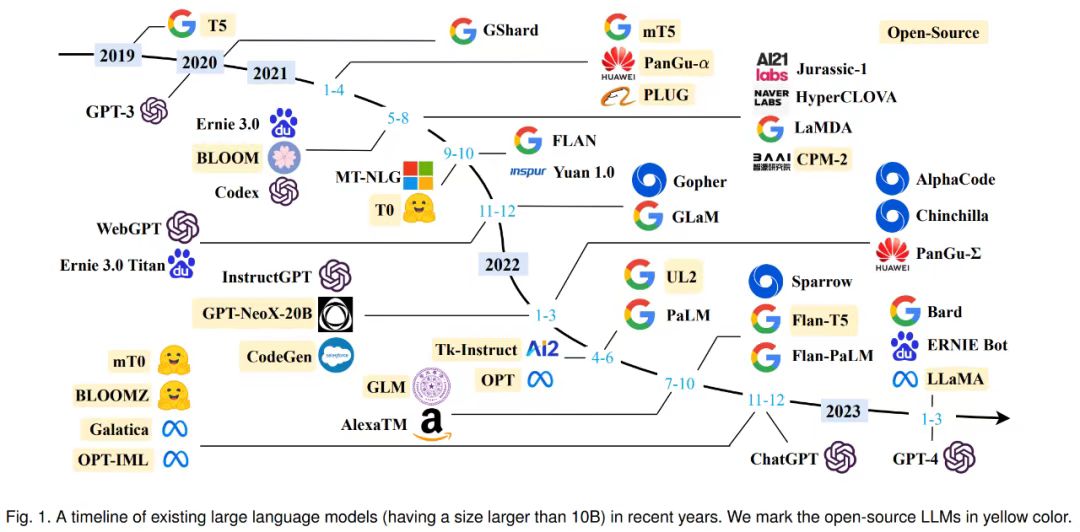
回顾LLM的发展,那是一段充满创新与突破的旅程。早期的自然语言处理基于简单的规则和统计方法,处理能力有限。直到20世纪90年代末至21世纪初,随着计算能力的提升和数据量的增加,神经网络开始在NLP领域广泛应用 。2017年,谷歌AI团队提出的Transformer模型是一个里程碑式的突破,它摒弃了传统的循环结构,采用自注意力机制来处理序列数据,大大提高了训练速度和对语境的敏感度,为后续的预训练模型发展奠定了基础。
2018年,谷歌发布BERT,采用双向训练方式,利用大量无标注文本预训练,在多种下游任务中性能显著提升;同年,OpenAI发布GPT-1,采用12个Transformer解码器进行无监督预训练,重点在于生成任务。此后,GPT系列不断进化,从GPT-2到GPT-3,再到后来的版本,参数量不断攀升,能力也越发强大。2023年更是被称为人工智能“元年”,各大科技公司纷纷推出自家LLM,如复旦大学的Moss、百度的文心一言、阿里巴巴的通义千问、谷歌的PaLM2等 ,形成了百花齐放的竞争态势。
三、LLM常见应用
1. 文本到文本:在文本摘要方面,能快速将冗长的报告压缩为简洁准确的摘要,帮助企业快速获取关键信息,提高决策效率;机器翻译中,能实现不同语言之间的自动转换,打破语言障碍,助力跨国企业的全球业务开展;问答平台里,凭借上下文感知算法,为用户提供准确的答案,如今许多企业的客服系统都引入了这一技术。
2. 语音转文本:在电话会议中,自动语音识别(ASR)系统能提供实时转录服务,生成可搜索和存档的文本记录;声控助手结合ASR和NLP,可执行各种命令,在仓库、零售等行业都有广泛应用,实现免提操作和更便捷的客户交互。
3. 图像转文本:像OCR技术可识别图像中的文字,领域LLM还能实现图像字幕生成、视觉内容自动标记、发票自动分类等功能,为企业处理图像相关业务提供便利。
4. 代码生成:在软件开发中,能预测并自动生成代码片段,加速开发周期,还能通过集成静态代码分析工具,帮助修复代码中的Bug,提高业务应用程序的效率和稳健性。
5. 聊天机器人:用于客户支持和交互式常见问题解答,通过在企业历史客户服务交互数据上的训练,能更准确地解决客户问题,还能执行潜在客户开发、自动追加销售等任务,降低人力成本。
6. 情绪分析:利用自然语言理解(NLU)识别语言中的情感倾向,企业将其集成到CRM系统中,可实时跟踪客户情绪,实现更有针对性的客户互动。
7. 数据清理:通过配置决策树或基于规则的系统,识别并纠正结构化数据中的错误条目,确保分析数据的可靠性,对企业战略规划和运营效率至关重要。
8. 异常检测:在欺诈检测、制造质量控制、市场趋势预测等领域,帮助企业预先识别和减轻风险。
四、LLM的优势与局限
优势
- 强大的语言处理能力:能够理解和生成非常自然流畅的文本,在多种自然语言处理任务中表现出色。
- 广泛的通用性:可以在没有针对特定任务进行大量训练的情况下,通过提示工程等方式,完成多种不同类型的任务,具有很强的迁移学习能力。
- 持续的技术优化:随着技术的发展,模型架构和训练技术不断改进,性能持续提升。
局限
- 知识实时性问题:其知识来源于训练数据,无法实时获取最新信息,对于一些时效性要求高的问题,可能给出过时的答案。
- 数据偏见和伦理问题:如果训练数据存在偏见,模型可能会生成带有偏见或误导性的内容,引发伦理争议。
- 高计算资源需求:训练和部署大规模的LLM需要强大的计算资源支持,这不仅成本高昂,还对硬件设备有较高要求。
五、LLM的未来展望
未来,LLM有望在多个方向取得进一步发展。一方面,模型规模可能会继续扩大,同时更加注重性能和效率的优化,以降低计算成本和资源消耗。另一方面,多模态处理将成为重要趋势,LLM将整合图像、音频等更多模态信息,从而在更复杂的场景中发挥作用。此外,随着LLM在各领域的深入应用,其在政策制定和决策支持方面也将扮演更重要的角色,但同时也需要加强对其社会影响的评估和监管 。
LLM作为人工智能领域的关键技术,已经深刻改变了我们与计算机交互以及处理信息的方式,未来也必将持续为我们带来更多的惊喜和变革。作为技术爱好者,让我们一起期待并见证它的发展吧!