Next系统总结学习(一)
下面我按题号逐条 详细 解释并给出示例与最佳实践。为便于阅读,我会同时给出关键代码片段(伪代码/实用例子),并指出常见坑与解决方案。
1. 你是如何理解服务端渲染(SSR)的?它的核心工作流程是怎样的?
理解(简要):
服务端渲染(SSR,Server-Side Rendering)指在服务器端执行前端应用的渲染逻辑,生成完整或部分 HTML,然后把该 HTML 返回给浏览器。浏览器收到的不是空的 div#root,而是可见的、有语义的 HTML 内容,之后再下载并执行前端 JS,把页面“接管”(hydrate)成为可交互的单页应用(SPA)。
核心工作流程(高层):
- 浏览器发出 HTTP 请求(GET /path)。
- 服务器接收请求,基于请求 URL 做路由匹配(找到对应页面组件/路由)。
- 服务器执行与该路由相关的数据获取(同步或异步),得到初始数据/state。
- 服务器把组件渲染成 HTML 字符串(或流式输出部分 HTML)。
- 服务器把 HTML + 初始序列化状态(例如
window.__INITIAL_STATE__)和指向客户端脚本的<script>一并返回。 - 浏览器解析 HTML(首屏内容可见),并开始并行加载 JS/CSS/资源。
- 客户端 JS 执行,读取服务器注入的初始状态并进行 hydration,装配事件处理器,页面变得可交互。
关键点: 渲染过程发生在服务器端,渲染结果携带初始数据发送到客户端;客户端只做挂载/复用而不是从零开始渲染整棵树。
2. 为什么需要服务端渲染?它主要解决了客户端渲染(CSR)的哪些问题?
主要原因 / 优势:
- 首屏体验(首字节到可见内容更快):用户能更早看到内容,感知速度提升,特别是慢网或低端设备上。
- 搜索引擎优化(SEO):搜索引擎爬虫和社交抓取器能够直接读取 HTML 内容(meta、open graph),提高索引与分享预览质量。
- 更好的社交卡片与预览:分享到社交平台时,抓取器获取的是完整 HTML meta,而非依赖 JS 才生成的内容。
- 可访问性 & 无 JS 场景降级:在 JavaScript 被禁用或异常情况下,用户仍能看到内容(至少部分内容)。
- 首屏可渲染时间(TTI/First Contentful Paint)优化:服务器返回 HTML,浏览器可以立即渲染,而 CSR 需要下载并执行大量 JS 才能产生可见内容。
- 可控的资源优先级:服务器端可以内联关键 CSS、预加载关键脚本资源,优化渲染路径。
CSR 的痛点(SSR 主要解决或缓和):
- CSR 初始请求通常返回空 HTML,需要下载大包 JS 才能渲染,导致首屏慢。
- SEO 问题:早期或部分爬虫难以执行 JS(现在好多能执行,但仍有限制)。
- “白屏”或“闪烁”(FOUC)问题,尤其在慢网络或 CPU 较弱设备上明显。
- 社交抓取/预览无法拿到动态内容(除非额外处理)。
权衡:
SSR 提升体验但带来更高的后端复杂度、构建和部署复杂性、缓存策略需求、以及处理服务器上同步/并发渲染时的资源占用问题(CPU / 内存 / IO)。是否使用 SSR 取决于产品需求(SEO、首屏体验)与工程成本。
3. 什么是“同构(Isomorphic)/通用(Universal)”代码?在 SSR 中为何重要?
定义:
“同构/通用”代码指同一套 JavaScript 代码能够在 服务器端和客户端 两个环境中运行 —— 例如,业务组件、路由定义、数据获取逻辑复用在服务器渲染和客户端渲染中。
在 SSR 中的重要性:
- 代码复用:同一套组件既用于服务器渲染也用于客户端 hydration,减少重复实现和维护成本。
- 一致性:保证服务器渲染时生成的 UI 与客户端渲染/交互时的 UI 一致(避免 “内容不一致” 的 React 警告)。
- 统一路由与数据获取机制:同构路由可以在服务器上匹配并加载数据、在客户端复用同样的路由逻辑做客户端导航。
- 开发效率:开发者只需关注一套逻辑,易于测试与维护。
注意点:
同构代码必须 避免直接依赖浏览器全局对象(window, document, localStorage 等),或对这类依赖做运行时判断/延迟调用(见第6点)。此外,模块分包(server/client bundles)与构建配置需要支持不同目标的打包。
4. 请描述一次完整的 SSR 请求生命周期,从浏览器发出请求到页面可交互
下面给出一个较完整、带步骤的生命周期(包含常见中间环节与优化点):
-
DNS/TCP/TLS/CDN(前置层)
- 浏览器解析 DNS、建立 TCP/TLS 连接(若启用 CDN,CDN 会先命中或回源)。
-
请求到达边缘或应用服务器
- CDN 缓存判断命中:若命中直接返回缓存 HTML(最快)。否则请求到应用服务器或 Serverless 函数。
-
服务器/边缘路由匹配
- 服务端用与客户端同构的路由逻辑匹配请求 URL,决定要渲染哪个页面/组件树。
-
数据加载(服务器上)
- 执行路由对应的数据加载器(同步或异步),读取 DB、调用后端 API、做鉴权等。
- 可使用并行/复合请求并设超时与降级策略(避免无限等待)。
-
渲染到 HTML(server-render)
- 将 React/Vue 等组件树渲染成 HTML 字符串或流,并在适当位置注入初始序列化状态(“脱水”)。
- 可采用流式渲染:先把 shell(静态骨架)返回,随后逐步发送组件 HTML,缩短 Time-to-first-byte(TTFB)。
-
插入资源引用
- 在返回 HTML 中包含
<link rel="stylesheet">、<script src="client.js" defer>、预加载/预取 hint 等。
- 在返回 HTML 中包含
-
HTTP 响应
- 服务器将 HTML 发回浏览器(做 gzip/br/HTTP2 等压缩),并可配合缓存头(Cache-Control、ETag、Surrogate-Key)缓存策略。
-
浏览器解析 HTML
- 浏览器构建 DOM / CSSOM,页面可见(首屏已显示)。此时仍未绑定 JS 事件。
-
资源并行加载
- 浏览器下载 JS、CSS、图片等资源(如果
<script>使用defer或 module,则先解析后执行)。
- 浏览器下载 JS、CSS、图片等资源(如果
-
客户端 JS 执行与 Hydration(注水)
- 客户端脚本读取服务器注入的初始 state(如
window.__INITIAL_STATE__),运行客户端入口,执行hydrate()或hydrateRoot(),将事件处理器挂到已存在的 DOM 上,进行 DOM 比对(reconciliation)。
- 客户端脚本读取服务器注入的初始 state(如
-
页面可交互
- hydration 完成后,路由跳转、事件处理等全部生效;此时页面被完全“接管”成 SPA。
-
后续导航(客户端路由)
- 之后的导航可在客户端完成(局部更新、客户端数据 fetch),避免再次 SSR(除非需要新页面的 SSR)。
失败/降级场景:
- 数据加载失败 -> 可返回错误页面或返回带错误提示的 HTML(并在客户端 retry)。
- Hydration 报错 -> 浏览器可能会重新完全渲染客户端(client-side render fallback),或显示不交互的页面。
- 超时 -> 可设定渲染超时,返回部分 HTML(骨架)并标注 JS 在客户端补全。
5. SSR 应用的“服务端入口”(Server Entry)和“客户端入口”(Client Entry)有何不同?
Server Entry(服务器入口)特点:
- 运行环境:Node.js / serverless / edge runtime(无浏览器 DOM)。
- 目标:导出用于服务器渲染的接口(例如接受 URL -> 返回 HTML 字符串 / 流的函数)。
- 不应包含浏览器专属 API 的直接使用(或者要做保护判断)。
- 打包目标通常是
target: node,保留require、不需要 polyfill 浏览器 API,通常要剔除客户端依赖(CSS-in-JS 有时需要特定处理以抽取样式)。 - 可以直接访问服务器资源(数据库、文件系统、环境变量、后端 API)。
Client Entry(客户端入口)特点:
- 运行环境:浏览器(有 DOM、window、document)。
- 目标:在加载时读取服务器注入的状态,执行
hydrate()或hydrateRoot(),并启动客户端路由、事件绑定、热更新(开发时)。 - 包含浏览器 polyfills、第三方客户端库(analytics、service worker 注册等)。
- 通常被 code-splitting(按路由拆包)以减小初始下载体积。
不同点(对比表):
- 运行时:Server->Node;Client->Browser
- 包含内容:Server->渲染逻辑、数据加载器;Client->事件处理、交互逻辑、路由器、持久化。
- 构建目标:Server->server bundle(体积可小但包含渲染需要);Client->浏览器 bundle(要优化大小)
- 生命周期:Server->一次 HTTP 请求到响应;Client->页面首载后长期驻留与导航
6. 在服务端执行前端代码时,遇到 window 或 document 等浏览器特有对象不存在应如何处理?
核心策略:避免直接在模块顶层使用浏览器 API;在运行时判断或延迟在客户端执行。
常见做法(按安全与优先级):
- 运行时判断(最简单):
const isBrowser = typeof window !== 'undefined';if (isBrowser) {// 浏览器独有逻辑
}
-
把浏览器副作用放到生命周期里(React)
- 把 DOM 相关操作放在
useEffect(只在客户端运行),而不是render或getInitialProps:
- 把 DOM 相关操作放在
useEffect(() => {// 这个只会在客户端执行const el = document.getElementById('x');
}, []);
-
条件/动态导入(code-splitting)
- 延迟加载依赖浏览器的模块(
import()):
- 延迟加载依赖浏览器的模块(
if (typeof window !== 'undefined') {import('some-dom-lib').then(lib => { lib.doSomething(); });
}
-
抽象平台差异为“环境适配器”
- 用
platform的抽象接口封装(server 与 client 提供不同实现),依赖注入。
- 用
-
SSR-safe 组件
- 对需要浏览器 API 的组件,在 SSR 时返回占位(skeleton),在客户端 mount 后再真正渲染。
function MapComponent() {const [mounted, setMounted] = useState(false);useEffect(()=> setMounted(true), []);if (!mounted) return <div className="map-placeholder" />;return <RealMap/>; // uses window.google.maps
}
-
模拟 DOM(不推荐)
- 在某些场景(测试或特殊库)可以用
jsdom在 Node 上提供document、window。但实际生产 SSR 中尽量避免这样做(性能/兼容/不可控)。
- 在某些场景(测试或特殊库)可以用
-
安全的第三方库选择
- 选那些支持 SSR 的库(说明中标注
ssr: true或有服务端兼容实现)。
- 选那些支持 SSR 的库(说明中标注
7. Node.js 在 SSR 架构中扮演了什么角色?
Node.js 作为服务器端 JavaScript 运行时,承担下列职责:
- 运行 SSR 渲染代码:执行 React/Vue/Svelte 等框架的服务器渲染 API(
renderToString、renderToPipeableStream等)。 - 提供 HTTP 服务:作为应用服务器(或在 serverless 中作为运行时)接收请求、路由、返回 HTML。
- 与后端服务/数据库交互:在渲染前获取数据、做鉴权、调用微服务、缓存等。
- 文件与静态资源管理:读取模板、发放静态资源、构建时处理。
- 缓存策略实现:在内存、Redis、CDN 回源层配合做页面/片段缓存。
- 流式输出与性能优化:通过流(streaming)把 HTML 分块发送给客户端,缩短首屏时间。
- 中间件支持:整合日志、监控、错误上报、安全中间件(CSP、XSS 防护)等。
- 运行时多样化:可以部署为长驻服务(传统 Node 服务器),也可打包为 serverless 函数或中转到 Edge Runtime(Cloudflare Workers、Deno、V8 isolates 等),不同环境会影响渲染模型与性能。
补充: 随着 Edge/Worker 平台兴起,有些 SSR 工作可以在更靠近用户的边缘节点完成(更低延迟),但这些运行时可能不能访问本地文件系统,也对 API 有限制(短执行时间、不同的 Node API)。
8. SSR 中的路由同构是如何实现的?
目标:服务器和客户端使用相同的路由定义与匹配逻辑,服务器用于匹配并提前加载对应页面的数据,客户端用于后续导航与局部更新。
实现方法(常用模式):
-
定义一份“路由表/路由配置”
- 把路由及其对应组件、数据加载器、meta 信息写成共享配置(例如
routes.js),这个文件既被 ServerEntry 使用,也被 ClientEntry 使用。
- 把路由及其对应组件、数据加载器、meta 信息写成共享配置(例如
// routes.js (示例)
export default [{ path: '/', component: Home, loader: homeLoader },{ path: '/post/:id', component: Post, loader: postLoader },
];
-
服务器端用路由匹配库(matchRoutes)找到匹配项并运行 loader
- 在服务器接收到
/post/123时,用相同的匹配算法取得要渲染的组件和它的 loader,然后在渲染前调用 loader 获取所需数据并注入(脱水)。
- 在服务器接收到
import { matchRoutes } from 'react-router';
const matches = matchRoutes(routes, req.url);
await Promise.all(matches.map(m => m.route.loader && m.route.loader({params: m.params})));
-
客户端使用同一套路由定义做导航与懒加载
- 客户端 hydration 后,路由库(如 React Router、Vue Router)根据同样的配置处理
pushState导航、懒加载组件及其数据获取(可以使用 prefetch)。
- 客户端 hydration 后,路由库(如 React Router、Vue Router)根据同样的配置处理
-
错误/重定向/404 的统一处理
- 路由的重定向或 404 处理应在服务器端和客户端一致(例如 loader 抛出
redirect或notFound,服务器根据异常返回 302/404)。
- 路由的重定向或 404 处理应在服务器端和客户端一致(例如 loader 抛出
-
路由级数据预取与缓存
- Server loader 的结果被序列化到 HTML(脱水),客户端路由在首次渲染时复用这些数据而不重复请求(减少重复请求)。
注意事项:
- 匹配逻辑和参数解析必须保持完全一致。
- 要考虑 SSR 中同步/异步数据加载的超时、缓存与错误策略。
- 对于文件系统路由(如 Next.js / Nuxt),构建工具会自动生成可同构的路由映射。
9. 什么是“脱水”(Dehydration)和“注水”(Hydration)?
脱水(Dehydration):
指服务器在渲染后将运行时生成的数据/状态序列化并注入到 HTML 中,通常通过一个 <script> 标签把初始状态写到 window.__INITIAL_STATE__(或类似命名)。这样客户端在加载时可以读取这份预置状态,而无需在 hydration 时重新向后端拉取同样的数据。
注水(Hydration):
客户端读取服务器注入的 HTML 以及脱水的状态,然后运行框架的 hydration API(如 React 的 hydrateRoot)来复用服务端生成的 DOM,仅挂上事件监听并完成虚拟 DOM 的首次比对,使页面变得可交互。
示例(简化):
服务器输出:
<div id="root">...rendered html...</div>
<script>window.__INITIAL_STATE__ = {/* safe-serialized data */}</script>
<script src="/client.js" defer></script>
客户端:
const state = window.__INITIAL_STATE__;
hydrateRoot(document.getElementById('root'), <App initialState={state} />);
关键问题与实践:
- 安全: 直接把 JSON 用
JSON.stringify插入 HTML 可能导致 XSS(若数据含</script>)。应用serialize-javascript或对特殊字符做转义来避免注入攻击。 - 大小: 注入的数据会增加 HTML 大小,需避免传输过多不必要的数据(只传必要 state)。
- 一致性: 注入的状态必须与服务端渲染使用的状态一致,否则 hydration 会失败或产生警告。
- 部分/渐进注水(Partial/Progressive Hydration):先进的策略是只 hydrate 首屏或重要交互组件,延迟或按需 hydrate 其它部分,节省 CPU 并提升交互速度。
10. SSR 对你的开发模式和心智模型提出了哪些新的要求?
需要建立的新心智模型和开发习惯:
-
分清“渲染环境”与“运行环境”
- 明确哪些代码可在服务器运行、哪些代码只能在浏览器执行(DOM 操作、浏览器 API、window 事件等)。
-
数据获取需可在服务器端运行
- 设计数据加载器(loaders、getServerSideProps、asyncData 等)能够在服务器执行并返回脱水数据;并考虑网络故障、超时与降级。
-
更强的错误/边界意识
- 服务器渲染中的报错会影响 HTTP 响应,因此需要完善的错误边界、超时与降级策略。要在服务端和客户端都处理错误情形(并统一展示)。
-
缓存与性能思维
- 需要设计页面/片段缓存策略(CDN/边缘/内存缓存),理解何时可以缓存和何时需要动态渲染(用户特定内容不能缓存)。
-
安全意识
- 序列化初始状态时注意 XSS,防止敏感数据在 HTML 中泄露(例如不要把用户密码或秘密放进注入的 state)。
-
构建与部署复杂度
- 要管理双重构建产物(server bundle & client bundle),理解 target 配置、tree-shaking、代码分割、CI/CD 流程的差异。
-
调试技巧
- 需要同时会在服务器端和浏览器端调试渲染问题(server logs、stack traces、source map 配置、SSR-specific breakpoints)。
-
测试策略
- 引入服务器渲染测试(例如用
renderToString或 headless 环境测试输出 HTML),以及客户端 hydration 后的集成测试(确保一致性)。
- 引入服务器渲染测试(例如用
-
渐进增强与 UX 考虑
- 设计能在无 JS 或部分 JS 场景下也能提供合理体验的页面(骨架、链接可用、表单能工作等)。
-
路由/状态统一思维
- 将路由与数据获取看成可以在服务端与客户端共同驱动的流程,保证接口和约定一致。
总结性的建议:
- 开始时把 SSR 作为优化手段(针对首屏和 SEO 的热点页面做 SSR),而非整个站点一次性 SSR 化。
- 采用渐进式策略(先实现服务端渲染 + 基本脱水/注水,再优化流式渲染、缓存、部分 hydration)。
- 选择一个 SSR 友好的框架或工具(例如 Next.js、Nuxt、Remix、Sapper 等)可以大幅减少样板工作并提供成熟的约定。
附:常见代码示例(简洁版)
服务器端(伪 Node + React 18 流式)
// server.js (node)
import express from 'express';
import { renderToPipeableStream } from 'react-dom/server';
import App from './App';
import { matchAndLoadData } from './ssr-utils'; // route match + loadersconst app = express();app.get('*', async (req, res) => {const initialState = await matchAndLoadData(req.url); // 服务器拉数据let didError = false;const stream = renderToPipeableStream(<App url={req.url} initialState={initialState} />,{onShellReady() {res.statusCode = didError ? 500 : 200;res.setHeader('Content-Type', 'text/html; charset=utf-8');res.write('<!doctype html><div id="root">');stream.pipe(res);res.write('</div>');// 安全序列化初始状态res.write(`<script>window.__INITIAL_STATE__ = ${serialize(initialState)};</script>`);res.write('<script src="/client.js" defer></script>');res.end();},onError(err) { didError = true; console.error(err); }});
});
客户端入口(hydrate)
// client.js
import { hydrateRoot } from 'react-dom/client';
import App from './App';const initialState = window.__INITIAL_STATE__ || {};
hydrateRoot(document.getElementById('root'), <App initialState={initialState} />);
避免 window/document 在 SSR 中报错
// safeDom.js
export const isBrowser = typeof window !== 'undefined';
export function getWindowLocation() {return isBrowser ? window.location : { pathname: '/' };
}
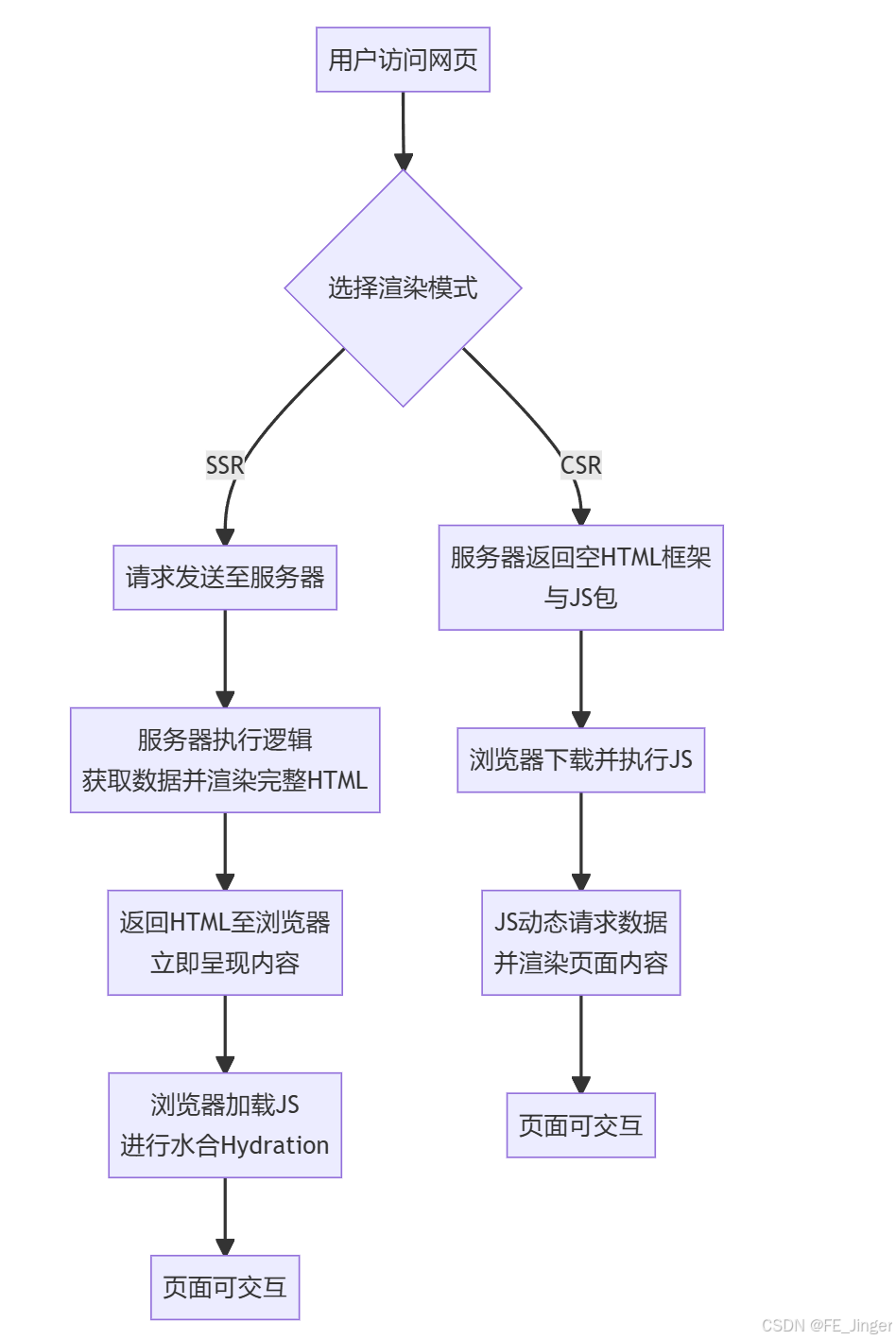
你提出了关于前端渲染策略的一系列核心问题,它们确实是现代Web开发中架构选型的关键。下面我将为你逐一详细解答,并配以图表辅助说明。
📊 SSR 与 CSR 核心对比
要直观理解服务器端渲染(SSR)和客户端渲染(CSR)的根本区别,它们的工作流程对比是最好的方式。下图清晰地展示了从用户请求到页面最终可交互的完整过程:
此流程决定了它们各自的特性:
| 特性维度 | 服务器端渲染 (SSR) | 客户端渲染 (CSR) |
|---|---|---|
| 渲染地点 | 服务器 | 浏览器 |
| 首屏加载速度 | 通常较快 用户能更快看到内容 | 可能较慢 需等待JS下载、执行和数据加载,期间可能白屏 |
| SEO友好性 | 天然友好 搜索引擎可直接抓取完整HTML内容 | 不友好 初始HTML内容为空,依赖JS执行,不利于爬虫抓取 |
| 服务器压力 | 较大 每次请求都需服务器渲染页面 | 较小 服务器主要提供静态文件和API接口 |
| 开发复杂度 | 相对较高 需处理服务端和客户端环境差异、水合等 | 相对较低 更纯粹的前端开发体验 |
| 交互体验 | 首屏后若需更新内容,可能需整页刷新 | 切换页面体验流畅 仅需局部更新,无需整页刷新 |
🫛 12. SSR和SSG(静态站点生成)有何区别?应如何做技术选型?
SSR 和 SSG 都属于预渲染策略,关键区别在于渲染时机:
- SSR (Server-Side Rendering):动态渲染。在用户请求时,服务器动态获取数据、渲染HTML并返回。适合内容频繁变更或个性化极强的页面(如新闻详情页、用户主页)。
- SSG (Static Site Generation):静态生成。在项目构建时,提前将数据和模板生成静态HTML文件。适合内容稳定的页面(如博客、文档、官网)。
技术选型建议:
- 选择 SSG:若内容相对固定,追求极致性能、低服务器成本和高安全性(如技术博客、企业官网、产品文档)。
- 选择 SSR:若内容动态性强,需要个性化数据或实时更新(如电商首页、社交平台、新闻门户)。
🖼️ 13. 什么是预渲染 (Prerendering)?它和SSR/SSG有什么关系?
- 预渲染是一个广义概念,指在浏览器呈现页面之前,提前生成好HTML内容的过程。它主要为了解决CSR首屏慢和SEO差的问题。
- SSR 和 SSG 是预渲染的两种具体实现方案:
- SSG 是构建时预渲染。
- SSR 是运行时(请求时)预渲染。
🎯 14. 在什么场景下,SSR是最佳选择?什么场景下SSG更优?
这个选择很大程度上取决于你内容的动态化程度和更新频率。下图基于这两个维度提供了一个直观的选型指南:
quadrantCharttitle SSR与SSG技术选型指南x-axis "低动态性" --> "高动态性"y-axis "低更新频率" --> "高更新频率""用户仪表盘(高动态/实时)": [0.85, 0.9]"新闻门户(高动态/频繁)": [0.8, 0.7]"电商首页(混合)": [0.65, 0.6]"商品详情页(混合)": [0.6, 0.5]"企业官网(静态/稳定)": [0.2, 0.1]"技术博客(静态/稳定)": [0.15, 0.2]"产品文档(静态/稳定)": [0.1, 0.3]
如图所示,SSG 是静态内容王者,非常适合企业官网、技术博客、产品文档等内容稳定、无需用户鉴权的场景。它能提供最快的加载速度(CDN分发)、更高的安全性和更低的服务器成本。
而 SSR 则擅长处理动态内容优先的场景,例如:
- SEO依赖型页面:新闻文章、电商商品列表页,需要被搜索引擎收录。
- 重度依赖实时数据的页面:股票行情、赛事比分。
- 高度个性化的页面:社交媒体信息流、用户个人中心。
📈 15. 结合核心Web指标,分析SSR和CSR在性能表现上的差异
Core Web Vitals 是谷歌衡量用户体验的关键指标,SSR和CSR的表现差异显著:
| 核心指标 | 说明 | SSR 表现 | CSR 表现 |
|---|---|---|---|
| LCP 最大内容绘制 | 测量加载性能。感知页面主要内容加载所需的时间。 | 通常较好。 服务器返回的HTML包含内容,LCP时间更短。 | 通常较差。 需等待JS bundle加载执行后才会渲染内容。 |
| FID 首次输入延迟 | 测量交互性。用户首次与页面交互到浏览器响应的时间。 | 可能较差。 在水合过程完成前,页面无法响应交互。 | 通常较好。 一旦JS加载完成,交互响应迅速。 |
| CLS 累积布局偏移 | 测量视觉稳定性。页面生命周期内意外布局偏移的程度。 | 通常较好。 内容一次渲染到位,布局偏移较少。 | 可能较差。 异步加载内容可能导致元素突然插入,造成偏移。 |
SSR在LCP和CLS上通常有优势,但在FID上可能表现不佳(在水合完成前,页面看似可见却无法交互)。CSR则相反,其FID可能在JS加载后表现良好,但LCP和CLS通常是短板。
🔄 16. 你了解ISR(增量静态再生)或DPR(分布式持久渲染)吗?
它们是现代框架(如Next.js)提供的混合渲染方案,旨在结合SSG和SSR的优点:
-
ISR (Incremental Static Regeneration):
- 解决问题:SSG无法处理动态数据,而SSR服务器压力大。
- 原理:在SSG基础上,允许静态页面在构建后按需重新生成。你可以为页面设置一个重新验证时间(
revalidate),过期后,下一个请求会在后台重新生成新页面,用户先看到旧页面,生成完后再更新缓存。 - 场景:商品详情页、博客文章页等数据可能变化但不需极端实时性的场景。
-
DPR 并非通用标准术语,其思想与ISR类似。
🤝 17. 混合渲染 (Hybrid Rendering) 是什么概念?
混合渲染指在同一个Web应用中,根据不同页面的需求,混合使用SSR、SSG和CSR等多种渲染策略。
- Next.js等框架支持此概念。例如:
- 营销首页(
/)使用 SSG,预生成静态文件以实现极速加载。 - 博客文章页(
/posts/[id])使用 ISR,增量更新。 - 用户个人资料页(
/profile)使用 SSR,提供个性化实时内容。 - 管理后台(
/admin/*)使用 CSR,提供丰富的交互体验。
- 营销首页(
- 这样做可以在性能、新鲜度和开发成本之间取得最佳平衡。
💼 18. 对于一个重交互、数据实时性要求高的后台管理系统,适合使用SSR吗?为什么?
通常不适合,更推荐使用CSR(或SSG+CSR)。
原因如下:
- 极重的交互性:后台系统操作频繁,CSR在首次加载后,后续交互无需整页刷新,体验极其流畅。若使用SSR,每个交互都可能请求服务器渲染,反而会牺牲响应速度。
- 实时数据需求:数据需实时拉取和展示,CSR可通过API按需获取和局部更新,比SSR整页渲染更高效。
- 通常无SEO需求:后台系统是权限内应用,无需被搜索引擎收录,SSR的SEO优势在此场景无意义。
- 开发体验与性能:CSR架构前后端分离更彻底,开发效率高。且所有渲染在客户端进行,极大减轻了服务器压力。
更优方案:对这类系统,可采用 CSR + SSG 的混合模式。登录页可静态化(SSG),主应用使用CSR。同时利用代码分割、懒加载等技术优化首屏加载速度。