YOLOv8 TensorRT C++部署实战详解:从XMake构建到推理流水线
YOLOv8 TensorRT C++部署实战详解:从XMake构建到推理流水线
本项目已上传到GitHub https://github.com/Bayesianovich/yolov8-fire-smoke-detection,欢迎star⭐ ⭐ ⭐
项目概述
本项目是一个基于YOLOv8和TensorRT的高性能火灾烟雾检测系统,使用C++实现,具有以下特点:
- 实时检测性能:利用TensorRT GPU加速,实现高性能推理
- 智能双条件触发:只有同时检测到火和烟时才触发警报
- 现代化构建系统:使用XMake替代CMake,配置更简洁
- 内存高效管理:零拷贝内存管理和CUDA流异步处理
技术架构
核心组件
项目结构
├── main.cpp # 主应用程序
├── include/
│ └── yolov8_trt_demo.h # 检测器头文件
├── src/
│ └── yolov8_trt_demo.cpp # 检测器实现
├── xmake.lua # XMake构建配置
├── classes.txt # 类别标签文件
└── firesmokev1.engine # TensorRT引擎文件
关键依赖库
- TensorRT 8.6+: GPU推理加速引擎
- CUDA 12.1+: GPU并行计算平台
- cuDNN 8.9+: 深度学习GPU加速库
- OpenCV 4.8+: 计算机视觉处理库
XMake构建系统深度解析
为什么选择XMake而非CMake?
XMake相比CMake具有以下优势:
- 语法简洁:基于Lua的配置语言,学习成本更低
- 自动依赖管理:内置包管理系统
- 跨平台支持:统一的配置文件支持多平台
- 构建速度:增量编译和并行构建优化
XMake配置文件详解
1. 项目基础配置
-- 项目基本信息
set_project("yolov8_demo")
set_version("1.0.0")
set_languages("c++17")-- 构建模式配置
add_rules("mode.debug", "mode.release")
2. 路径变量管理
-- 集中管理依赖库路径
local tensorrt_root = "F:/TensorRT-8.6.1.6"
local cudnn_root = "F:/cudnn_64-8.9.0.131"
local cuda_root = "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.1"
local opencv_root = "F:/opencv_cpu_install"
3. 目标配置
target("yolov8_demo")set_kind("binary")-- 源文件配置add_files("main.cpp", "src/yolov8_trt_demo.cpp")-- 头文件包含add_includedirs("include",tensorrt_root .. "/include",cudnn_root .. "/include",cuda_root .. "/include",opencv_root .. "/include")-- 库文件链接add_linkdirs(tensorrt_root .. "/lib",cudnn_root .. "/lib/x64",cuda_root .. "/lib/x64",opencv_root .. "/lib")
4. 依赖库链接
-- TensorRT核心库
add_links("nvinfer", -- 推理引擎"nvinfer_plugin", -- 插件支持"nvonnxparser", -- ONNX解析"nvparsers" -- 其他格式解析
)-- CUDA运行时库
add_links("cudart", "cublas", "curand")-- cuDNN深度学习库
add_links("cudnn")-- OpenCV模块(版本相关)
add_links("opencv_core480","opencv_imgproc480", "opencv_imgcodecs480","opencv_highgui480","opencv_videoio480","opencv_video480","opencv_dnn480"
)
5. 自动化构建后处理
after_build(function (target)local targetdir = target:targetdir()-- 自动复制必要的DLL文件os.trycp(opencv_root .. "/bin/opencv_*.dll", targetdir)os.trycp(tensorrt_root .. "/lib/*.dll", targetdir)os.trycp(cuda_root .. "/bin/cudart64*.dll", targetdir)os.trycp(cudnn_root .. "/bin/*.dll", targetdir)-- 复制项目资源文件os.trycp("*.engine", targetdir)os.trycp("classes.txt", targetdir)
end)
常用构建命令
# 构建发布版本(推荐)
xmake build# 构建调试版本
xmake config --mode=debug
xmake build# 清理构建文件
xmake clean# 清理TensorRT引擎文件
xmake clean-engines# 运行程序
xmake run yolov8_demo# 显示项目信息
xmake info
YOLOv8 TensorRT检测器实现解析
核心类结构
class YOLOv8TRTDetector {
private:// TensorRT组件nvinfer1::IRuntime* runtime;nvinfer1::ICudaEngine* engine;nvinfer1::IExecutionContext* context;// 内存管理void* buffers[2]; // GPU输入输出缓冲区std::vector<float> prob; // CPU输出缓冲区cudaStream_t stream; // CUDA异步流// 模型参数float conf_threshold = 0.25f;float iou_threshold = 0.25f;int inputH = 640, inputW = 640;public:void initConfig(const std::string& engine_file, float conf_threshold, float iou_threshold);void detect(cv::Mat& frame, std::vector<DetectResult>& results);~YOLOv8TRTDetector();
};
检测结果结构
struct DetectResult {int class_id; // 类别ID (0=火, 1=烟)float conf; // 置信度cv::Rect box; // 边界框
};
推理数据流详解
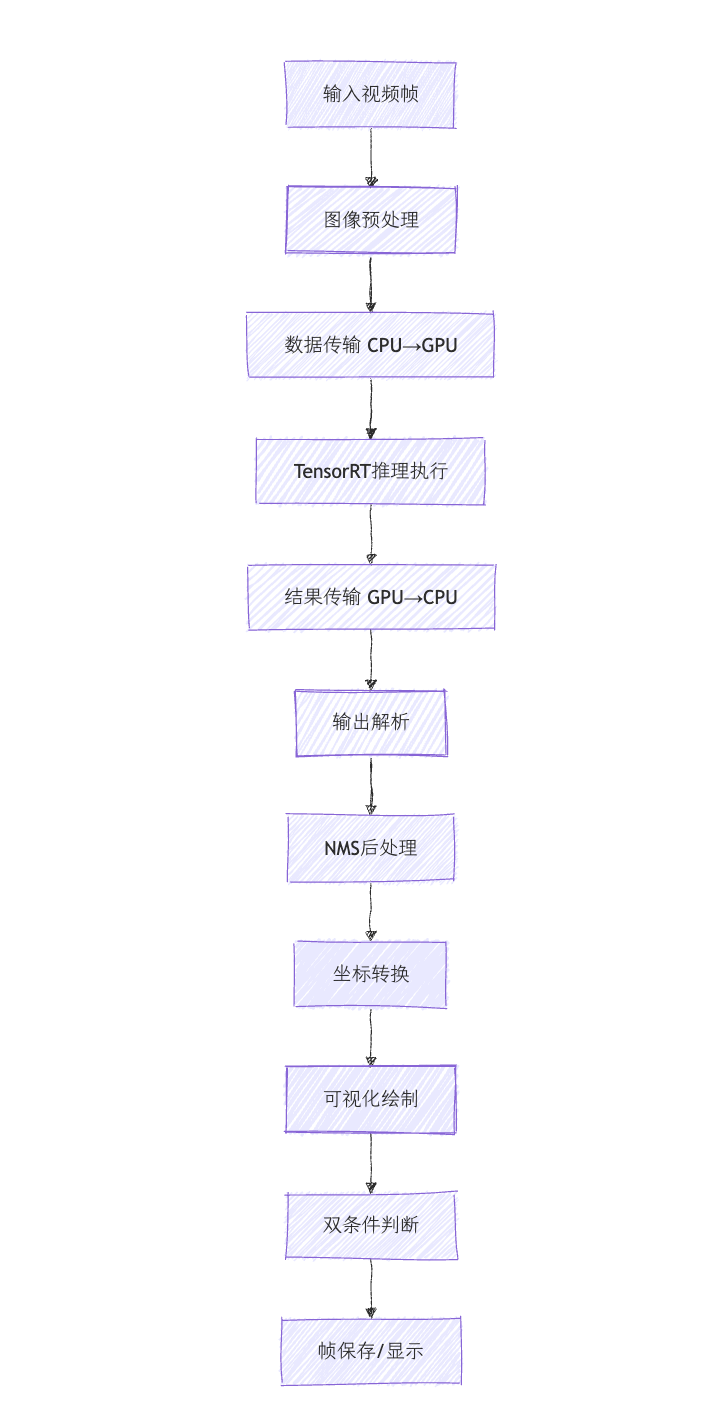
1. 图像预处理阶段
// 创建正方形画布(等比例缩放策略)
int max_side = std::max(original_h, original_w);
cv::Mat canvas = cv::Mat::zeros(max_side, max_side, CV_8UC3);// 将原图复制到左上角
cv::Rect roi(0, 0, original_w, original_h);
frame.copyTo(canvas(roi));// 使用OpenCV DNN进行预处理
cv::Mat tensor = cv::dnn::blobFromImage(canvas, // 输入图像1.0/255.0, // 归一化系数cv::Size(inputW, inputH), // 目标尺寸640x640cv::Scalar(0,0,0), // 均值true, // BGR转RGBfalse // 不裁剪
);
预处理步骤解析:
- 尺寸标准化:创建正方形画布,避免图像失真
- 像素归一化:将像素值从[0,255]归一化到[0,1]
- 通道重排:从HWC(高×宽×通道)转换为CHW格式
- 颜色空间转换:BGR转RGB以匹配模型训练数据
2. 异步数据传输
// CPU到GPU异步传输
cudaMemcpyAsync(buffers[0], // 目标GPU缓冲区tensor.ptr<float>(), // 源CPU数据inputH * inputW * 3 * sizeof(float), // 数据大小cudaMemcpyHostToDevice, // 传输方向stream // CUDA流
);
优势:
- 异步执行:CPU和GPU并行工作,提高效率
- 内存带宽优化:减少同步等待时间
- 流水线处理:多帧并行处理成为可能
3. TensorRT推理执行
// 执行推理
context->enqueueV2(buffers, stream, nullptr);
TensorRT优势:
- 图优化:自动优化网络结构
- 精度优化:支持FP16/INT8量化
- 内核融合:减少内存访问次数
- 动态形状:支持可变输入尺寸
4. 结果解析和NMS处理
// 解析检测结果 (格式: 1×6×8400)
cv::Mat detMat(output_feat, output_detbox, CV_32F, (float*)prob.data());
cv::Mat detMat_t = detMat.t(); // 转置为8400×6for (int i = 0; i < detMat_t.rows; ++i) {// 提取类别概率cv::Mat scores = detMat_t.row(i).colRange(4, output_feat);// 获取最高概率类别cv::Point classIdPoint;double max_class_score;cv::minMaxLoc(scores, 0, &max_class_score, 0, &classIdPoint);if (max_class_score > conf_threshold) {// 提取边界框坐标(中心点格式)float cx = detMat_t.at<float>(i, 0);float cy = detMat_t.at<float>(i, 1);float w = detMat_t.at<float>(i, 2);float h = detMat_t.at<float>(i, 3);// 转换为左上角坐标格式int left = static_cast<int>(cx - w / 2);int top = static_cast<int>(cy - h / 2);// 坐标映射回原图尺寸left = std::max(0, static_cast<int>(left * x_scale));top = std::max(0, static_cast<int>(top * y_scale));}
}
数据格式说明:
- 输出维度:1×6×8400
- 6个通道:[cx, cy, w, h, conf, class_prob…]
- 8400个候选框:来自3个不同尺度的特征图
5. NMS非极大值抑制
std::vector<int> nms_indices;
cv::dnn::NMSBoxes(boxes, // 候选框confidences, // 置信度conf_threshold, // 置信度阈值iou_threshold, // IoU阈值nms_indices // 输出保留的框索引
);
NMS算法原理:
- 置信度排序:按置信度降序排列候选框
- IoU计算:计算重叠度(Intersection over Union)
- 重叠抑制:移除IoU超过阈值的冗余框
- 最优保留:每个目标只保留最佳检测框
6. 坐标系转换
由于预处理时进行了等比例缩放和填充,需要将检测结果映射回原始图像坐标系:
// 计算缩放比例
float x_scale = canvas.cols / static_cast<float>(inputW);
float y_scale = canvas.rows / static_cast<float>(inputH);// 坐标转换并边界检查
left = std::max(0, static_cast<int>(left * x_scale));
top = std::max(0, static_cast<int>(top * y_scale));
width = std::min(static_cast<int>(width * x_scale), original_w - left);
height = std::min(static_cast<int>(height * y_scale), original_h - top);
主应用程序逻辑
核心业务流程
int main() {// 1. 初始化检测器auto detector = std::make_shared<YOLOv8TRTDetector>();detector->initConfig("firesmokev1.engine", 0.25f, 0.25f);// 2. 视频处理循环while (true) {cap.read(frame);detector->detect(frame, results);// 3. 双条件判断逻辑bool has_fire = false, has_smoke = false;for (const auto& result : results) {if (result.class_id == 0) has_fire = true; // 火if (result.class_id == 1) has_smoke = true; // 烟}// 4. 只有同时检测到火和烟才触发警报if (has_fire && has_smoke) {// 绘制警报框和保存帧drawAlertBox(frame, results);saveFrame(frame, frame_count);}}
}
智能双条件触发机制
// 双条件检查
if (has_fire && has_smoke) {// 绘制烟雾检测框(橙色)for (const auto& result : results) {if (result.class_id == 1) { // 只绘制烟雾cv::rectangle(frame, result.box, cv::Scalar(0, 165, 255), 3);std::string label = "SMOKE " + cv::format("%.2f", result.conf) + " [FIRE+SMOKE ALERT!]";}}// 保存警报帧std::string save_name = save_dir + "/frame_" + cv::format("%04d", frame_count) + ".jpg";cv::imwrite(save_name, frame);} else {// 显示正常状态cv::putText(frame, "Normal - No Fire+Smoke Condition", ...);
}
设计理念:
- 降低误报:单独的火或烟不触发警报
- 提高准确性:双重确认机制确保真实火灾
- 可视化清晰:不同状态有明确的视觉反馈
性能优化策略
1. 内存管理优化
// GPU内存预分配,避免运行时分配
cudaMalloc(&buffers[0], inputH * inputW * 3 * sizeof(float));
cudaMalloc(&buffers[1], output_feat * output_detbox * sizeof(float));// CPU缓冲区预分配
prob.resize(output_feat * output_detbox);
2. CUDA流异步处理
// 创建CUDA流
cudaStreamCreate(&stream);// 异步内存拷贝和推理
cudaMemcpyAsync(..., stream);
context->enqueueV2(buffers, stream, nullptr);
cudaMemcpyAsync(..., stream);// 同步等待完成
cudaStreamSynchronize(stream);
3. 内存带宽优化
- 零拷贝技术:直接在GPU上处理数据
- 内存池复用:避免频繁分配释放
- 数据预取:提前加载下一帧数据
4. FPS性能监测
int64 start = cv::getTickCount();
// ... 推理过程 ...
int64 end = cv::getTickCount();
float fps = cv::getTickFrequency() / (end - start);
cv::putText(frame, cv::format("FPS: %.2f", fps), ...);
部署建议和最佳实践
1. 环境配置
# 确保CUDA版本兼容
nvidia-smi # 检查CUDA版本# 验证TensorRT安装
ls $TRT_ROOT/lib/ # 检查库文件# 检查cuDNN版本
cat $CUDNN_ROOT/include/cudnn.h | grep CUDNN_MAJOR
2. 模型优化
// 推荐的TensorRT配置
builder->setMaxBatchSize(1);
config->setMaxWorkspaceSize(1 << 30); // 1GB
config->setFlag(BuilderFlag::kFP16); // 启用FP16
3. 错误处理
// 资源初始化验证
if (!runtime || !engine || !context) {std::cerr << "TensorRT初始化失败" << std::endl;exit(-1);
}// CUDA错误检查
#define CUDA_CHECK(call) \do { \cudaError_t err = call; \if (err != cudaSuccess) { \std::cerr << "CUDA错误: " << cudaGetErrorString(err) << std::endl; \exit(-1); \} \} while(0)
4. 生产环境建议
- 批处理优化:支持多帧并行推理
- 模型量化:使用INT8量化进一步加速
- 动态分辨率:根据硬件性能调整输入尺寸
- 多线程处理:分离推理和后处理线程
- 内存监控:定期检查GPU内存使用情况
总结
本项目展示了如何使用现代C++技术栈构建高性能的深度学习推理应用:
- XMake构建系统提供了比CMake更简洁的配置方式
- TensorRT优化引擎实现了GPU加速推理
- 智能双条件触发降低了火灾检测的误报率
- 异步内存管理保证了实时性能
- 完整的错误处理确保了系统稳定性
这个项目可以作为其他深度学习C++部署项目的参考模板,特别是在工业监控、安防系统等对实时性要求较高的应用场景中。
通过合理的架构设计和性能优化,我们成功实现了一个既高效又稳定的火灾烟雾检测系统,为实际应用提供了可靠的技术基础。
如果想要完整看代码,我已经上传到github
点击yolov8-fire-smoke-detection即可跳转,欢迎Star ⭐ ⭐ ⭐