Hive基础简介
Hive基础简介
一、为啥有Hive
MySQL:
处理不了大数据 & SQL语句简单—>
Hadoop:
HDFS【存储 & 需要Java能力和MR能力】+ MapReduce(MR)【处理数据 & 需要Java能力和MR能力】—>
HiveSQL:
分析处理大数据 & 语句简单
二、Hive基础考点概念
1、Hive是一个用于分析结构化数据和半结构化数据
的数据仓库系统。它建立在Hadoop之上。
2、它是一个类似SQL的查询工具,用于查询存储在HDFS和其他与Hadoop集成的文件系统中的数据。
3、Hive提供读取、写入和管理驻留在分布式存储中的大型数据集的功能。
4、它运行名为HQL(Hive查询语言)的类似SQL的查询,该HQL在内部默认自动转换为MapReduce , 可以更改为其他工具,例如Tez或Spark。
5、它是离线批处理 。
6、无需学习Java和Hadoop。
7、可扩展性、快、灵活
8、支持从序列化文件、文本文件、avro文件、orc文件、rc文件、Hbase表读取数据分析
9、Hive的元数据存在RDBMS里(例如MySQL),所以安装Hive之前要先安装RDBMS
10、Hive支持压缩功能
11、Hive支持Join联查功能
12、Hive支持索引来精准查询
13、Hive支持用户自定义函数可以自己写Java代码编写
三、Hive 适用、不适用情况
| 非适用 | 适用 |
|---|---|
| 关系型数据库 | 非关系型数据库 |
| 用于交易、事务处理 | 用于大批量分析 |
| 实时更新查询 | 离线批处理 |
| 低延迟、低吞吐量 | 高延迟、高吞吐量 |
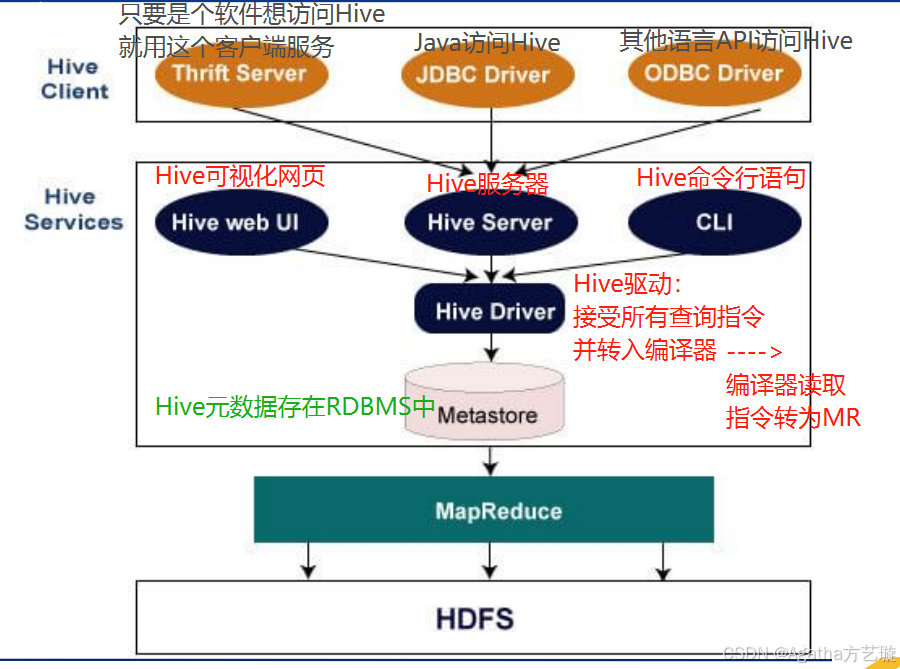
四、Hive架构