AWS TechFest 2025: 智能体企业级开发流程、Strands Agents
Agent Enterprise Development Process(智能体企业级开发流程)
这是指企业在构建和部署 AI智能体(Agent) 时所遵循的一套系统化流程。与传统应用的开发相比,智能体的开发更强调自主性、环境交互能力和多工具集成。流程通常包括:
- 需求分析:确定企业需要什么样的智能体(客服、业务助手、流程自动化等)。
- 设计与开发:定义智能体的角色、目标和与外部系统的接口方式。
- 测试与迭代:模拟场景进行测试,确保智能体能按预期执行。
- 部署与监控:将智能体运行在安全、可扩展的环境中,并持续监控性能与行为。
- 治理与合规:确保智能体的行为符合公司政策和法律法规。
Traditional application developers are now shifting to agent developers(传统应用开发者正转型为智能体开发者)
过去,开发者主要构建的是“固定逻辑”的应用程序(例如Web应用或移动App)。而现在,随着 大语言模型和AI代理技术 的发展,开发者的角色正在转变:
- 传统开发者:编写业务逻辑代码,控制用户输入和输出。
- 智能体开发者:更多是编排和引导AI模型,为其提供工具调用、知识库和上下文管理,让AI自主完成复杂任务。
这种转型意味着开发者不仅要懂编程,还要理解AI模型的能力、局限性和治理机制。
Agent Developer(智能体开发者)
智能体开发者的职责包括:
- 设计智能体的 目标和角色。
- 编写提示(prompt)和上下文逻辑,引导AI输出符合业务需求的结果。
- 集成API、数据库和企业系统,让智能体能调用外部工具。
- 持续优化智能体的效果,例如减少“幻觉”(hallucination)、提高准确性和可解释性。
Agent Tool Integration(智能体工具集成)
智能体不是孤立的,而是需要和各种 工具与系统 集成:
- 内部工具:CRM、ERP、HR系统。
- 外部工具:搜索引擎、支付系统、第三方API。
- AI工具:向量数据库、知识库、模型调用接口。
通过工具集成,智能体才能真正完成复杂任务(如“查询库存→计算价格→生成报价”)。
Build a secure and scalable infrastructure for AI agents(为AI智能体构建安全且可扩展的基础设施)
企业级智能体需要一个安全可靠的平台来运行:
- 安全性:数据隐私保护、身份验证、防止越权访问。
- 可扩展性:支持同时运行成千上万个智能体,并能应对峰值流量。
- 弹性架构:利用云原生和微服务架构,保证智能体能快速部署和升级。
Agent Governance(智能体治理)
治理是企业应用智能体时的核心问题。包括:
- 身份认证(Authentication):确认是哪个智能体在发出请求。
- 访问授权(Authorization):智能体能访问哪些应用、工具和数据,避免越权。
- 合规与审计:记录和审查智能体的操作,确保其遵循法律法规和公司政策。
Observability: Monitoring(可观测性与监控)
智能体不像传统应用那样完全可预测,因此必须建立强大的监控体系:
- 日志记录:保存智能体的输入、输出、调用的工具。
- 性能监控:响应时间、成功率、错误率。
- 行为分析:是否出现幻觉、不当内容或异常操作。
- 可视化工具:帮助运维和开发人员实时追踪智能体状态。
Agent End-user(智能体终端用户)
最终使用智能体的可能是:
- 企业员工:内部使用,例如市场人员用AI助手生成方案。
- 客户:外部使用,例如智能客服。
- 混合场景:B2B 或 B2C 应用,智能体协助企业与客户交互。
智能体需要通过良好的用户体验(UX)设计,让用户信任并愿意长期使用。
一、How to transit to Agentic AI(如何过渡到 Agentic AI)
Agentic AI 指的是具备更高自主性和决策能力的智能体(Agentic = Agency + AI)。它不仅能被动回答或执行任务,还能主动制定计划、发现问题、调用工具并执行行动。要从传统AI或早期的“AI Agent”过渡到 Agentic AI,需要以下几个步骤:
-
明确应用场景与价值目标
-
传统AI多用于单一任务(如客服问答、推荐系统)。
-
过渡到Agentic AI时,需要确定它能在业务中承担“代理人角色”,例如:
- 主动监控供应链异常并提出解决方案。
- 主动为客户安排差旅并实时调整航班和酒店预订。
-
-
强化上下文理解与长期记忆能力
- 传统AI往往是“无记忆”的,对话结束后无法延续。
- Agentic AI需要持久记忆(long-term memory),能够学习用户历史偏好、企业规则和环境变化。
-
增强工具调用与多系统集成
- 传统AI只给出答案。
- Agentic AI要能调用外部工具(API、数据库、应用系统),实现从“说”到“做”的跃迁。
- 例如:不仅告诉你航班延误,还能直接帮你改签。
-
引入自主决策和任务分解机制
-
Agentic AI需要有规划(Planning)与执行(Execution)的循环:
- 先制定行动计划 → 调用工具执行 → 评估结果 → 调整下一步。
-
这类似人类的思考与行动闭环。
-
-
搭建企业级安全与治理框架
- 确保智能体的决策在可控范围内,避免“越权”。
- 建立访问控制(哪些数据可用)、日志审计(谁做了什么)、合规管理(符合法律法规)。
-
逐步试点与规模化部署
- 先在单一流程中引入Agentic AI,测试其效果与风险。
- 再扩展到跨部门、多业务场景,最终形成大规模应用。
二、What are the challenges and characteristics of transitioning from traditional AI Agent to Agentic AI(从传统AI Agent过渡到Agentic AI的挑战与特征)
挑战(Challenges):
-
自主性带来的不确定性
- Agentic AI具备自主规划能力,但这意味着它可能采取“意料之外”的路径。
- 挑战在于如何确保其行动可控、可审计。
-
数据与工具权限管理
- Agentic AI需要调用更多外部系统,如果权限控制不严,可能导致数据泄露或误操作。
-
技术复杂性提高
- 需要多模态理解(文字、语音、图像)、长期记忆、推理能力以及复杂的工具编排。
- 这对开发者的技能要求远高于传统AI Agent。
-
可观测性与调试难度
- 传统AI只生成输出,结果较容易追踪。
- Agentic AI涉及计划、工具调用和多步推理,调试和监控的难度大大增加。
-
伦理与合规风险
- 自主性越强,越容易出现伦理风险(如做出歧视性决定、错误行动)。
- 需要更严格的AI治理框架。
特征(Characteristics):
-
主动性(Proactivity)
- 从被动回答问题 → 主动发现问题、提出行动。
-
自主决策(Autonomy)
- 传统AI依赖用户指令,而Agentic AI能自主设定行动计划。
-
工具调用能力(Tool-augmented)
- 不仅生成语言,还能调用外部工具完成任务。
-
多步推理与任务分解(Reasoning & Planning)
- 能把复杂任务分解成多个步骤,并逐步执行。
-
长期记忆与上下文管理(Memory & Context Awareness)
- 能记住过去的交互,维持长期一致性。
-
可扩展性与适应性(Scalability & Adaptability)
- 随着环境和任务的变化,Agentic AI能自我调整。
Strands Agents 是一个开源的 SDK(软件开发工具包),它采用 模型驱动(model-driven) 的方式来构建和运行 AI 智能体(Agent),只需要几行代码即可完成。
Strands 的设计目标是 从简单到复杂的智能体场景都能适用,并且可以 从本地开发快速扩展到生产环境部署。目前,AWS 内部已经有多个团队在生产环境中使用 Strands 构建智能体,包括 Amazon Q Developer、AWS Glue 和 VPC Reachability Analyzer。现在,我们很高兴能把 Strands 开源,让开发者也能基于它来构建自己的 AI 智能体。
为什么选择 Strands?
相比于一些需要开发者定义复杂工作流(workflow)的智能体框架,Strands 做了极大的简化:
- 它充分利用了 最先进模型的能力 —— 让模型自己来进行 规划(plan)、推理链条(chain of thought)、调用工具(call tools)、自我反思(reflect)。
- 开发者只需要在代码中 定义一个提示(prompt)和一个工具列表,就能快速构建智能体。
- 然后可以 在本地测试,再一键 部署到云端。
Strands 的名字来自 DNA 的双链,寓意它将智能体的 两大核心要素 连接在一起:
- 模型(Model)
- 工具(Tools)
Strands 借助模型的高级推理能力,既能规划智能体的下一步行动,也能负责调用外部工具来完成执行。
高级功能与定制
对于更复杂的智能体应用场景,Strands 也允许开发者进行高度定制:
- 可以定义 工具的选择策略(如何选择合适的工具)。
- 可以定制 上下文(context)的管理方式。
- 可以指定 会话状态和记忆(session state & memory) 存储在哪里。
- 甚至可以构建 多智能体(multi-agent)应用,让多个 Agent 协同完成任务。
Strands 的运行环境非常灵活:
-
可以运行在任何地方(本地、云端、容器环境等)。
-
支持任何具备推理和工具调用能力的模型,包括:
- Amazon Bedrock
- Anthropic
- Ollama
- Meta
- 以及通过 LiteLLM 接入的其他模型供应商。
开源与社区
Strands Agents 是一个 开放社区项目,目前已经有多家企业参与支持与贡献,包括:
- Accenture
- Anthropic
- Langfuse
- mem0.ai
- Meta
- PwC
- Ragas.io
- Tavily
例如:
- Anthropic 已经贡献了 Strands 对其 API 的支持。
- Meta 贡献了 Strands 对 Llama 模型(通过 Llama API)的支持。
任何人都可以通过 GitHub 加入 Strands Agents 的开发与使用。
👉 总结一句话:
Strands Agents 是一个轻量但强大的 AI Agent 开发工具,让开发者无需复杂的工作流设计,就能借助先进模型的推理与工具调用能力,快速构建并部署智能体。
我主要负责 Amazon Q Developer 的工作,这是一个基于生成式AI的 软件开发助手。
我和我的团队在 2023年初 就开始尝试构建 AI 智能体(Agent),大概也是 ReAct(Reasoning and Acting,推理与行动) 这篇科学论文发表的时间。
这篇论文证明了大语言模型(LLM)不仅能对话,还能 进行推理、制定计划,并在环境中采取行动。
举个例子:
- 模型可以推理出“要完成这个任务需要调用某个 API”。
- 然后,它还能自动生成这个 API 所需的输入参数。
于是我们意识到,大语言模型可以被当作 智能体 来完成各种任务,包括复杂的软件开发和运维故障排查。
早期的挑战
在那个时候,大语言模型并不是为了扮演智能体而训练的:
-
它们主要被训练来进行自然语言对话。
-
如果要让模型具备推理和行动能力,需要:
- 复杂的提示词设计(prompt instructions),告诉模型该如何使用工具。
- 解析器(parsers),用来读取和处理模型的输出结果。
- 编排逻辑(orchestration logic),协调模型的推理和工具调用流程。
甚至让模型可靠地生成 语法正确的 JSON 都是一个难题!
为了原型设计和部署智能体,我们依赖了很多复杂的智能体框架(framework libraries),它们提供了“支架”和“编排能力”,确保智能体在早期模型的支持下还能完成任务。
但即便有了这些框架,我们也常常需要 几个月的时间 调试和微调,才能让一个智能体达到生产级别。
模型能力的进步
后来,我们看到大语言模型在能力上的 巨大飞跃:
- 它们的 推理能力 更强了。
- 它们能更好地 调用工具完成任务。
这意味着:
- 我们不再需要复杂的编排逻辑来“弥补模型的不足”。
- 模型自身就能承担规划和工具调用的核心任务。
甚至有些我们之前依赖的框架,反而成了“阻碍”,因为它们限制了我们充分利用最新模型的能力。
虽然模型本身进步很快,但框架带来的复杂性让我们依旧无法更快地开发和迭代智能体,生产化落地仍然需要数月时间。
为什么要开发 Strands Agents
于是,我们开始为 Q Developer 团队构建 Strands Agents,目标就是 去掉这些不必要的复杂性。
通过依赖最新大模型的原生能力(推理 + 工具使用):
- 智能体的开发周期大幅缩短。
- 用户体验也更好。
对比:
- 以前:从原型到生产环境,可能要花几个月。
- 现在:用 Strands,只需要 几天到几周 就能上线一个新的智能体。
👉 总结一句话:
最初我们需要复杂的框架来“弥补模型不足”;但随着大模型本身能力提升,我们意识到可以直接依靠模型本身,构建更高效的智能体。于是我们打造了 Strands Agents,大幅缩短开发周期,让 Q Developer 的团队能够快速交付生产级智能体。
Strands Agents 的核心概念
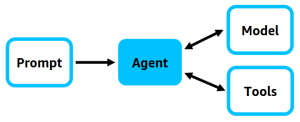
在 Strands Agents 中,最简单的智能体(Agent)定义可以归结为三个核心要素:
- 模型(Model)
- 工具(Tools)
- 提示词(Prompt)
一个智能体就是这三者的组合。
- 模型提供推理和生成能力。
- 工具扩展模型的功能,帮助它与外部世界交互。
- 提示词定义了智能体要完成的任务。
智能体利用这三部分,往往能够 自主地 完成任务。
这些任务可以非常多样,比如:
- 回答问题
- 生成代码
- 规划旅行
- 优化投资组合
在 模型驱动(model-driven)方法中,智能体依靠模型动态地决定下一步该怎么做,并调用相应工具,直到完成任务。
如何在 Strands Agents SDK 中定义一个 Agent
要创建一个智能体,只需要在代码里定义 模型、工具和提示词。
1. 模型(Model)
Strands 提供了灵活的模型支持:
- Amazon Bedrock(支持工具调用和流式输出的模型)
- Anthropic 的 Claude(通过 Anthropic API)
- Meta 的 Llama(通过 Llama API)
- Ollama(本地开发使用)
- 其他模型提供商(例如 OpenAI,通过 LiteLLM 接入)
- 开发者还可以在 Strands 中定义自己的自定义模型提供者。
2. 工具(Tools)
工具让智能体具备行动能力。
-
你可以使用成千上万的 Model Context Protocol (MCP) 服务器,作为智能体的工具。
-
Strands 自带 20+ 内置示例工具,例如:
- 文件操作工具
- API 请求工具
- 与 AWS API 交互的工具
-
你也可以把任意 Python 函数注册成工具,只需要加上
@tool装饰器即可。
3. 提示词(Prompt)
提示词告诉智能体它的任务是什么:
- 例如:“请回答用户提出的问题”。
- 还可以提供 系统提示词(system prompt),用来规定智能体的总体行为和风格。
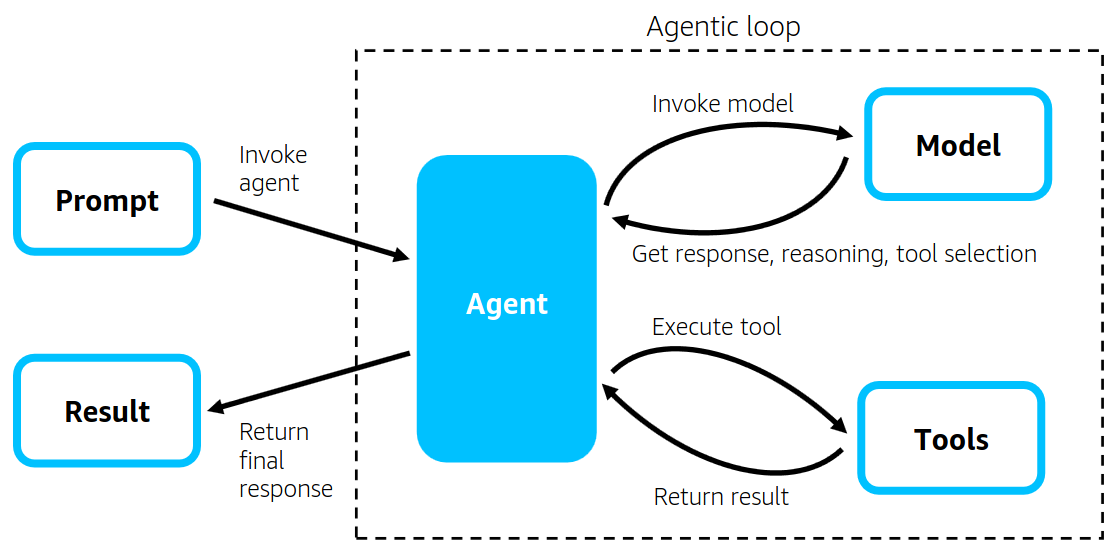
智能体循环(Agentic Loop)
智能体通过一个不断循环的过程(agentic loop)与模型和工具交互,直到任务完成。
-
在每一轮循环中:
-
Strands 将提示词、上下文、工具描述传给模型。
-
模型会:
- 直接生成自然语言回答给终端用户;
- 规划任务步骤;
- 反思先前的操作;
- 选择一个或多个工具来调用。
-
如果模型选择了工具,Strands 会负责执行该工具,并把结果反馈给模型。
-
当模型判断任务完成时,Strands 返回最终结果。
-
这个循环机制充分利用了现代大语言模型的能力(推理、规划、工具使用),是 Strands 的核心。
工具在模型驱动方法中的作用
在 Strands 中,工具不仅仅是“扩展功能”,更是 定制智能体行为的关键。
它们可以:
- 从知识库中检索文档
- 调用外部 API
- 执行 Python 逻辑
- 返回静态指令作为模型的额外提示
通过这些工具,可以实现复杂的应用场景。Strands 提供了一些特别有代表性的工具:
1. Retrieve Tool(检索工具)
-
使用 Amazon Bedrock Knowledge Bases 实现语义搜索。
-
不仅能检索文档,还能帮助模型规划和推理。
-
例如:AWS 内部某个智能体有 6000+ 工具可供选择。
- 直接让模型在 6000 个工具里选,几乎不可能成功。
- 解决方案:用检索工具先从 6000 个工具里筛选出最相关的几个,再让模型挑选。
-
开发者也可以把大量工具描述存在知识库里,让模型通过检索工具找到当前任务需要的工具子集。
2. Thinking Tool(思考工具)
- 让模型在多个循环中进行深度分析和自我反思。
- 把“深度思考”抽象成一个工具,使模型能判断何时需要进入更深入的分析过程。
3. 多智能体工具(Multi-agent Tools)
- 包括工作流(workflow)、图(graph)、群体(swarm)等模式。
- 当任务复杂时,Strands 能够调度多个智能体协作完成任务。
- 通过把子智能体和多智能体协作抽象成工具,模型可以自己决定何时需要调用工作流或群体协作。
- Strands 未来还会支持 Agent2Agent (A2A) 协议,以增强多智能体应用。
👉 总结:
在 Strands Agents 中,一个智能体就是 模型 + 工具 + 提示词。
通过 agentic loop,模型能自主推理和规划任务,并在合适的时机调用工具完成工作。工具不仅扩展了模型的能力,还让复杂任务(文档检索、深度思考、多智能体协作)变得可实现。Strands 的核心价值在于,它利用了大语言模型的原生推理与工具使用能力,把复杂的智能体开发简化为一种灵活、可扩展的 模型驱动方法。
Strands Agents 入门示例
这部分的核心是:通过 Strands Agents SDK 来构建一个 AI Agent(智能体)。示例场景是:创建一个“命名助手”,帮助为开源项目起名字,同时检查相关域名和 GitHub 组织名是否可用。
示例背景
在计算机科学领域,“命名”一直被认为是一件很难的事情。对于开源项目,如何起一个合适的名字更是难题。
因此,在本示例里,我们利用 Strands 构建了一个 命名 AI Agent,它不仅能提出名字建议,还能自动检查:
- 域名是否已经被注册
- GitHub 组织名是否已经被占用
代码讲解(agent.py)
1. 导入依赖
from strands import Agent
from strands.tools.mcp import MCPClient
from strands_tools import http_request
from mcp import stdio_client, StdioServerParameters
Agent:核心类,用于定义和运行智能体。MCPClient:连接 MCP 协议的客户端。MCP(Model Context Protocol)用于智能体与工具之间的通信。http_request:预置的工具,可以发起 HTTP 请求(例如请求 GitHub API)。stdio_client:通过标准输入输出运行 MCP 服务。
2. 定义系统提示(System Prompt)
NAMING_SYSTEM_PROMPT = """
You are an assistant that helps to name open source projects.When providing open source project name suggestions, always provide
one or more available domain names and one or more available GitHub
organization names that could be used for the project.Before providing your suggestions, use your tools to validate
that the domain names are not already registered and that the GitHub
organization names are not already used.
"""
-
这是一个自然语言的系统指令,告诉智能体它的任务:
- 帮助起开源项目的名字。
- 必须附带至少一个可用的域名和 GitHub 组织名。
- 在提供建议前,要用工具检查可用性。
3. 加载域名检查工具
domain_name_tools = MCPClient(lambda: stdio_client(StdioServerParameters(command="uvx", args=["fastdomaincheck-mcp-server"])
))
- 这里通过 MCPClient 加载了一个叫 fastdomaincheck-mcp-server 的工具,专门用于检查域名是否可用。
4. GitHub 名称检查工具
github_tools = [http_request]
- 使用内置的
http_request工具,向 GitHub API 发起请求,检查组织名是否可用。
5. 定义并运行命名智能体
with domain_name_tools:tools = domain_name_tools.list_tools_sync() + github_toolsnaming_agent = Agent(system_prompt=NAMING_SYSTEM_PROMPT,tools=tools)naming_agent("I need to name an open source project for building AI agents.")
- 将 域名工具 + GitHub 工具 组合,交给
Agent使用。 - 最后,执行智能体,输入的用户任务是:
“我需要为一个构建 AI Agents 的开源项目起名字。”
运行环境要求
要运行这个智能体,你需要:
- GitHub 个人访问令牌(GITHUB_TOKEN) → 用来调用 GitHub API 检查组织名。
- AWS Bedrock 模型访问权限(Anthropic Claude 3.7 Sonnet,区域 us-west-2)。
- 本地已配置 AWS 凭证。
运行步骤
pip install strands-agents strands-agents-tools
python -u agent.py
执行后,输出类似:
Based on my checks, here are some name suggestions for your
open source AI agent building project:## Project Name Suggestions:1. **Strands Agents**
- Available domain: strandsagents.com
- Available GitHub organization: strands-agents
也就是说,它会生成项目名 + 对应可用域名 + 可用 GitHub 组织名。
快速上手配置(MCP Server)
Strands 还提供了 MCP 服务器,可以直接接入任何 MCP 兼容的开发工具(例如 Q Developer CLI 或 Cline)。
配置示例:
{"mcpServers": {"strands": {"command": "uvx","args": ["strands-agents-mcp-server"]}}
}
这样,你就能在命令行开发工具中直接调用 Strands Agents 的功能。
✅ 总结:
通过 Strands Agents SDK,你可以非常快速地构建一个智能体:
- 用系统提示定义任务逻辑;
- 接入 MCP 工具检查外部资源(如域名、GitHub);
- 用 LLM 驱动整个任务流程。
这个例子展示了 Strands 如何把 模型、工具、提示 组合在一起,形成一个能自主执行任务的 AI Agent。
核心思想
Strands 的设计理念之一就是:智能体(Agent)不仅仅停留在实验阶段,而是要真正在生产环境中运行。
为此,Strands Agents 项目提供了一整套 部署工具包(deployment toolkit),里面包含了参考实现(reference implementations),帮助开发者把智能体顺利推向生产。
支持多种生产架构
Strands 很灵活,支持不同的应用场景:
- 对话型智能体(conversational agents)
- 事件触发型智能体(triggered by events)
- 定时任务型智能体(run on a schedule)
- 持续运行型智能体(run continuously)
你可以选择两种主要部署方式:
- 单体架构(monolith):智能体循环(agentic loop)和工具执行在同一个环境里运行。
- 微服务架构(microservices):智能体循环和工具执行分开,分别运行在不同服务里。
AWS 内部使用 Strands 时,采用了 四种典型架构模式。
架构模式一:本地运行(Local Client Architecture)
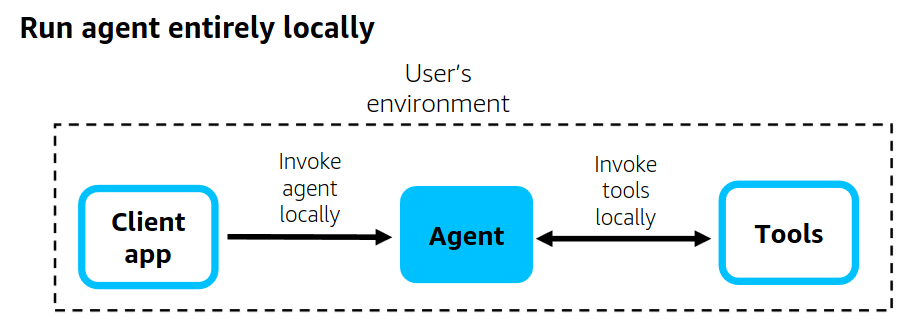
- Strands 完全在用户本地环境中运行,通过一个客户端应用。
- GitHub 上的命令行示例(CLI AI 助手)就是这种模式。
- 特点:适合开发测试、个人使用,不依赖云端部署。
架构模式二:API 部署(Run Agent Behind an API)
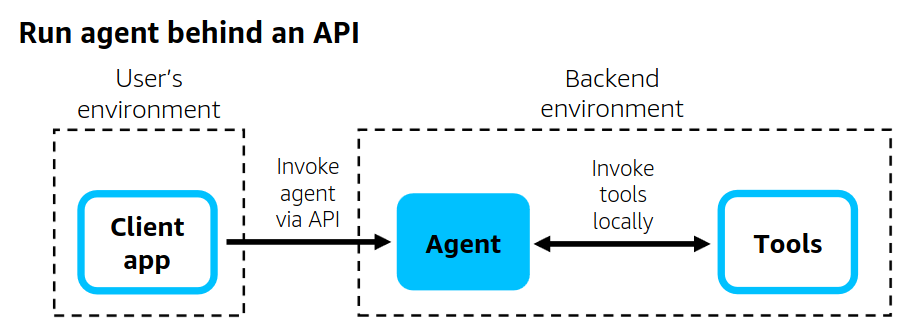
- 将智能体和工具一起部署在一个 API 服务 后端。
- 通过 API 对外提供智能体能力。
- 官方已提供参考实现,支持在 AWS 上用 Lambda、Fargate、EC2 部署。
- 特点:适合 SaaS 或面向外部用户的服务。
架构模式三:分离式架构(Run Tools in Isolated Backend)

-
将智能体循环和工具执行分离,分别运行在不同环境:
- 智能体循环运行在容器(如 Fargate)
- 工具运行在 隔离的后端环境(如 Lambda 函数)
-
智能体通过 API 调用工具,形成一个 松耦合架构。
-
特点:安全性高、扩展性强,方便对工具独立维护和伸缩。
架构模式四:混合控制(Run a Mix of Tools)

-
采用 return-of-control 模式:客户端负责运行一部分工具。
-
架构特点:
- 部分工具运行在后端环境(例如 API 服务)。
- 另一部分工具运行在客户端本地,由客户端直接调用。
-
特点:灵活性强,能结合本地和远端工具的优势。
生产可观测性(Observability)
无论选择哪种架构,**可观测性(Observability)**都是关键:
-
需要清楚了解智能体在生产环境中的运行情况、性能和问题。
-
Strands 提供了监控工具:
- Agent trajectories:记录智能体的执行轨迹(每一步的动作)。
- Metrics:性能指标。
- OpenTelemetry (OTEL):用于收集和输出遥测数据,兼容所有支持 OTEL 的后端。
-
分布式追踪(Distributed Tracing):支持跨组件跟踪请求,帮助排查复杂架构中的问题,形成完整的智能体会话视图。
✅ 总结
在生产环境中部署 Strands Agents,可以有多种方式:
- 本地运行(适合个人和开发)
- API 部署(适合对外提供服务)
- 智能体与工具分离(提升安全和扩展性)
- 本地+远端混合模式(兼顾灵活性和性能)
而在实际部署时,必须重视 监控和可观测性,通过 OTEL 进行分布式追踪,才能保证系统的可靠运行。
Amazon Bedrock AgentCore 简介
AgentCore 是 Amazon Bedrock 提供的一整套 核心运行框架,帮助企业在生产环境中快速、安全、可扩展地部署 AI Agent。
它包含了从运行时、内存管理、安全身份认证,到工具接入、代码执行、网页交互和可观测性等 关键能力模块。
换句话说,AgentCore 就像是 企业级 AI Agent 的基础设施和操作系统,把构建和运维 Agent 所需的核心功能都打包在一起。
核心组成部分
-
Runtime(运行时)
- Agent 运行的核心环境,负责调度模型、工具和任务。
- 类似于一个虚拟机或容器,确保 Agent 在企业环境里稳定执行。
-
Memory(记忆系统)
- 提供 上下文记忆管理,让 Agent 记住对话历史、用户偏好和任务进展。
- 支持长期记忆和短期记忆,使智能体能够实现 情境感知(Context-aware)。
- 例如:Agent 在处理客户服务时,可以记住客户的身份、之前的问题和未完成的任务。
-
Identity(身份管理)
- 提供 安全、集中化的访问控制。
- 管理 Agent 的认证与授权,确保 Agent 在调用工具或访问数据时有正确的权限。
- 这对企业环境至关重要,可以防止敏感信息泄露或越权访问。
-
Gateway(网关)
- 负责 构建、部署和连接工具与智能体。
- 可以把不同的 API、外部系统、数据库、甚至其他 Agent 都集成进来,形成一个 生态网络。
- 相当于 Agent 与外部世界交互的“高速通道”。
-
Code Interpreter(代码解释器)
-
让 Agent 能够 安全地编写和执行代码。
-
常见场景包括:
- 数据分析(运行 Python/R 脚本)
- 自动化运维(执行 Bash/SQL)
- 生成并运行小型程序解决复杂任务
-
同时包含沙箱机制,确保执行过程安全,不影响生产系统。
-
-
Browser(浏览器运行时)
-
提供 基于云的快速、安全浏览器环境,让 Agent 能够与网站交互。
-
用途包括:
- 自动收集网络信息(如新闻、价格、技术文档)
- 填写表单、进行网页操作
-
与传统爬虫不同,这里是 Agent 自主决策并操作网页。
-
-
Observability(可观测性)
-
提供 全方位监控和调试能力:
- Trace(追踪):跟踪 Agent 的每个执行步骤
- Debug(调试):快速定位错误或性能瓶颈
- Monitor(监控):持续观测 Agent 在生产中的表现
-
这对企业非常重要,可以帮助团队理解 Agent 的行为逻辑,提升透明度和可控性。
-
✅ 总结
Amazon Bedrock AgentCore 提供了企业部署 AI Agent 所需的一切核心能力:
- 运行时环境(Runtime)
- 记忆管理(Memory)
- 安全认证(Identity)
- 工具与Agent连接网关(Gateway)
- 安全代码执行(Code Interpreter)
- 网页交互能力(Browser)
- 监控与调试(Observability)
这让企业能够快速、安全、规模化地构建 具备记忆、推理、交互和可控性的 AI Agent。