人工智能学习:Transformer结构(编码器及其掩码张量)

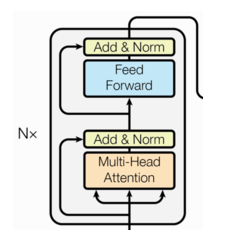
一、编码器介绍
由N个编码器层堆叠而成,每个编码器层由两个子层连接结构组成。
第一个子层连接结构包括一个多头自注意力子层和一个残差连接以及规范化层(层归一化)。
第二个子层连接结构包括一个前馈全连接子层和一个残差连接以及规范化层(层归一化)。
二、掩码张量
1、掩码张量介绍
掩码张量(Mask Tensor)是一种用于控制模型对输入数据的访问或处理方式的工具。它在深度学习中广泛应用,尤其是在处理变长序列(如自然语言处理中的句子)或需要忽略某些数据时。掩码张量通常是一个二进制张量(值为0或1)或下三角矩阵,用于指示哪些位置是有效的,哪些位置是无效的(需要被忽略)。
掩代表遮掩,码就是我们张量中的数值,它的尺寸不定,里面一般只有1和0的元素,代表位置被遮掩或者不被遮掩,至于是0位置被遮掩还是1位置被遮掩可以自定义,因此它的作用就是让另外一个张量中的一些数值被遮掩,也可以说被替换, 它的表现形式是一个张量。
2、掩码张量类型
Transformer 中常用的掩码张量主要分为以下两种类型:
-
Padding Mask(填充掩码)
- 作用:在处理变长序列时,输入序列通常会被填充到相同的长度(例如,使用 标记)。Padding Mask 用于屏蔽这些填充位置,确保注意力机制不会将注意力分配到这些无效位置。
- 场景:适用于编码器(Encoder)和解码器(Decoder)的输入序列。
- 实现:
- Padding Mask 是一个二进制张量,形状通常为 (batch_size, seq_len) 或 (batch_size, 1, 1, seq_len)(适配多头注意力机制)。
- 对于填充位置,掩码值为 False 或负无穷大(-inf);对于有效位置,掩码值为 True 或 1。
- 在注意力计算中,掩码会与注意力权重(scores)相加,填充位置的权重会被设置为负无穷大,softmax 后这些位置的注意力权重接近 0。
-
Look-Ahead Mask(前向掩码/因果掩码)
- 作用:在解码器(Decoder)中,生成序列时,模型在生成第 \(t\)$ 个词时只能依赖前 $\(t-1\) 个词。前向掩码用于屏蔽未来的词,防止模型“作弊”看到后续信息。