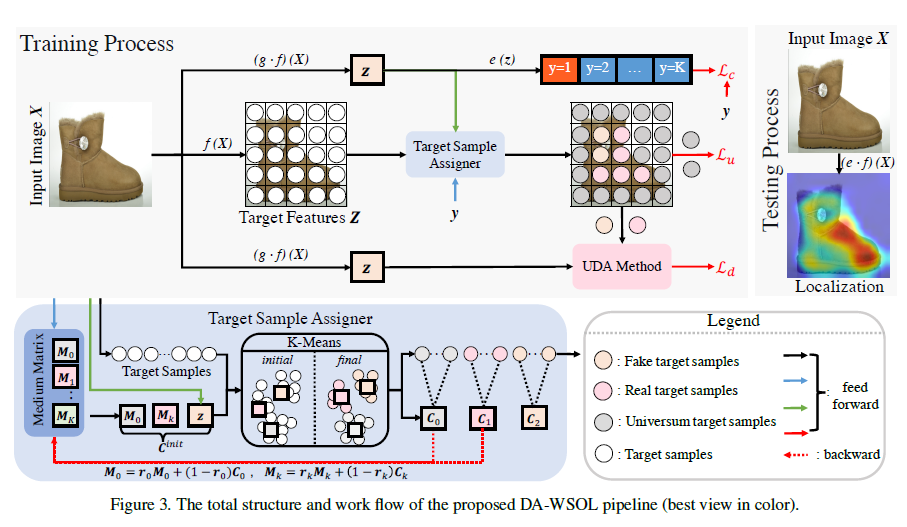
DA-WSOL
任务:
仅在image-level上进行分类训练,得到一个网络可以在图片上进行带标签的object localization
之前的模型:
WSOL使用CAM / grad-CAM进行定位
创新点:
将WSOL转变为一个Damain Adaption Task,source domain为image-level domain,target domain为pixel-level domain
模型主要结构:
特征向量:
pixel-level feature vector:
对输入的image 进行
特征提取,得到
,其中N为image的像素总数,即N = height * width
image-level feature vector:
对 进行
特征提取,得到
, 即整张image的特征向量
score:
对 和
都使用评价
可以得到其对应的得分
其中K为label总数
源域(source domain):
目标域(target domain):
其中M为image总数
target set(目标集):
分为三类,
:与source domain高度相关的sample,可以用作source sample的补充
:包含与source sample label无关的label,如background
:
target set smapling:
使用TSA(target sample assigner) 进行sample
定义一个cache matrix
其中 存放
的 anchor vector , 初始化为全0
存放
中 第k类标签所对应的anchor vector, 当遇到第一个image-level的label为k时,其image-level对应的特征向量为z,则
,其中
为随机扰动
步骤:
forward:
进行feature提取后,得到k-means的三个初始聚类中心:
,其中k为image对应的label
对image的所有pixel的feature vector进行聚类迭代,得到最后的聚类中心
此时聚类得到了所有pixel的target set label
backward:
对M进行更新,公式如下:
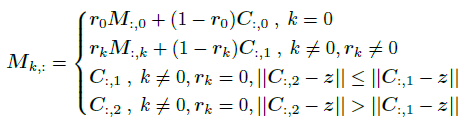
(等号左边应为),原论文此处应是一个错误
Loss:
第一项为task loss,即image-level的分类loss,使用cross-entropy loss
第二项为DAL(damain adaption loss),为source domain分布与target domain分布之间差异产生的loss
这里使用MMD(Maximum Mean Discrepancy)来计算
即
其中h为高斯核(gaussian kernel)
第三项为Universum loss,对未知标签的分类进行惩罚,这里采用feature-based 的L1正则化
即,来限制
的特征强度
Loss各项功能的解释:
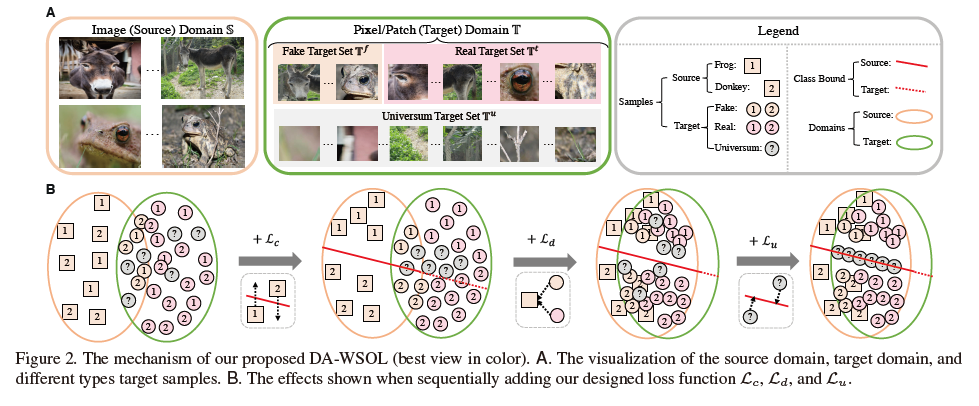
使模型能够正确分类
使源域和目标域接近相同
使模型能够处理未知分类
整个模型流程: