【大模型应用开发 5.LlamaIndex知识管理与信息检索】
见老友的意义就是你垂头丧气的时候,他还记得你当年意气风发的样子。
—— 25.8.18
——————————————————————
秋招投了简历,所以一直没有跟进,现在把这些内容完善起来,留了很多草稿箱,现在一点点补回来,希望大家都能顺利!
一、大语言模型开发框架的价值
SDK:Software Development Kit,它是一组软件工具和资源的集合,旨在帮助开发者创建、测试、部署和维护应用程序或软件。
所有开发框架(SDK)的核心价值,都是降低开发、维护成本。
大语言模型开发框架的价值,是让开发者可以更方便地开发基于大语言模型的应用。主要提供以下帮助:
① 第三方能力抽象。比如 LLM、向量数据库、搜索接口等
② 常用工具、方案封装
③ 底层实现封装。比如流式接口、超时重连、异步与并行等
好的开发框架,需要具备以下特点:
① 可靠性、鲁棒性高
② 可维护性高
③ 可扩展性高
④ 学习成本低
举些通俗的例子:
- 与外部功能解依赖
- 比如可以随意更换 LLM 而不用大量重构代码
- 更换三方工具也同理
- 经常变的部分要在外部维护而不是放在代码里
- 比如 Prompt 模板
- 各种环境下都适用
- 比如线程安全
- 方便调试和测试
- 至少要能感觉到用了比不用方便
- 合法的输入不会引发框架内部的报错
什么是 SDK? 什么是 SDK?- SDK 详解 - AWS
SDK 和 API 的区别是什么? SDK 与 API — 开发人员工具之间的区别 — AWS
二、依赖SDK,四行代码搭建简易RAG系统
1.下载依赖
# pip install --upgrade llama-index
# pip install llama-index-llms-dashscope
# pip install llama-index-llms-openai-like
# pip install llama-index-embeddings-dashscope清华源下载:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple
2.RAG系统搭建
LlamaIndex默认Embedding模型是 OpenAIEmbedding(model="text-embedding-ada-002")
Settings.llm:是 LlamaIndex 框架的全局大语言模型(LLM)配置项,用于指定框架默认使用的大语言模型。通过修改它,可以替换 LlamaIndex 内置的默认 LLM(如 OpenAI),使其使用自定义模型。
OpenAILike():是 LlamaIndex 中用于集成兼容 OpenAI API 格式的第三方大模型的类(如通义千问、DeepSeek 等,这些模型的 API 接口格式与 OpenAI 兼容)。通过它可以将非 OpenAI 的模型接入 LlamaIndex,复用 OpenAI 风格的调用逻辑。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
model | str | 是 | 模型名称(如 "qwen-max"、"gpt-3.5-turbo" 等)。 |
api_base | str | 是 | API 服务基础地址(如阿里云 DashScope 的兼容地址)。 |
api_key | str | 是 | 访问 API 的密钥(通常从环境变量获取)。 |
is_chat_model | bool | 否 | 是否为聊天模型(默认True,适用于对话类模型)。 |
temperature | float | 否 | 生成文本的随机性(范围 0~1,默认 0.7,值越高输出越多样)。 |
max_tokens | int | 否 | 生成文本的最大 tokens 数量(默认根据模型限制自动调整)。 |
api_version | str | 否 | API 版本(部分服务需要指定,如 OpenAI 的 "2023-05-15")。 |
DashScope():用于集成阿里云 DashScope(百炼)服务的大语言模型,简化 DashScope API 调用。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
model_name | DashScopeGenerationModels | 是 | 模型名称枚举(如DashScopeGenerationModels.QWEN_MAX)。 |
api_key | str | 是 | DashScope API 密钥(需从环境变量或直接传入)。 |
temperature | float | 否 | 生成随机性参数(默认 0.7)。 |
max_tokens | int | 否 | 最大生成 tokens 数(默认模型默认值)。 |
top_p | float | 否 | 核采样参数(控制输出多样性,默认 0.95)。 |
streaming | bool | 否 | 是否启用流式输出(默认False)。 |
DashScopeGenerationModels:是 LlamaIndex 中用于枚举阿里云 DashScope 服务支持的生成式模型名称的类(枚举类)。它包含预定义的模型标识符(如 QWEN_MAX)。
os.getenv():Python os 模块的函数,用于从操作系统的环境变量中获取指定键(环境变量名)对应的值。若指定的环境变量不存在,可返回自定义默认值(默认返回 None)。常用于读取系统配置、敏感信息(如 API 密钥)等,避免硬编码。
| 参数名 | 类型 | 说明 | 默认值 |
|---|---|---|---|
key | str | 必需参数,要获取的环境变量的名称(键),区分大小写(取决于操作系统)。 | 无 |
default | 任意类型 | 可选参数,当环境变量 key 不存在时返回的值。默认返回 None。 | None |
Settings.embed_model:是 LlamaIndex 框架的全局嵌入模型配置项,用于指定框架默认使用的文本嵌入模型(将文本转换为向量的模型)。
DashScopeEmbedding():用于集成阿里云 DashScope 的文本嵌入模型,生成文本向量。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
model_name | DashScopeTextEmbeddingModels | 是 | 嵌入模型名称枚举(如DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1)。 |
api_key | str | 是 | DashScope API 密钥。 |
embed_batch_size | int | 否 | 批量嵌入的文本数量(默认 32,控制效率)。 |
dimension | int | 否 | 嵌入向量维度(默认由模型自动指定,如 text-embedding-v1 为 768 维)。 |
DashScopeTextEmbeddingModels:是 LlamaIndex 中用于枚举阿里云 DashScope 服务支持的文本嵌入模型名称的类(枚举类)。
documents:是一个存储从本地目录读取的文档对象的列表,每个元素是 LlamaIndex 的 Document 对象(包含文档文本内容和元数据)。
SimpleDirectoryReader():从本地目录读取文档(支持多种格式如 txt、pdf 等),生成可用于索引的文档对象。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
input_dir | str | 是 | 文档所在目录路径(如 "./data")。 |
recursive | bool | 否 | 是否递归读取子目录(默认False)。 |
exclude_hidden | bool | 否 | 是否排除隐藏文件 / 目录(默认True)。 |
required_exts | list[str] | 否 | 仅读取指定扩展名的文件(如[".txt", ".pdf"],默认无限制)。 |
file_metadata | callable | 否 | 自定义文件元数据的函数(输入文件路径,返回元数据字典)。 |
load_data():SimpleDirectoryReader 类的核心方法,用于实际执行文档加载操作。它会根据 SimpleDirectoryReader 初始化时配置的目录路径、文件过滤器、加载规则等,读取指定目录中的文件并转换为 LlamaIndex 可处理的 Document 对象列表。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
show_progress | bool | False | 是否在加载文档过程中显示进度条。设置为 True 时会展示加载进度,方便跟踪大目录或多个文件的加载状态。 |
index:是 LlamaIndex 的向量存储索引对象,由文档内容转换而来。它将 documents 中的文本分割为片段、生成向量,并存储在向量数据库中,支持后续基于向量相似性的快速检索。
VectorStoreIndex.from_documents():从文档列表创建向量存储索引(核心方法),用于后续检索和问答。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
documents | list[Document] | 是 | 文档对象列表(由SimpleDirectoryReader.load_data()返回)。 |
embed_model | BaseEmbedding | 否 | 嵌入模型(默认使用Settings.embed_model)。 |
service_context | ServiceContext | 否 | 服务上下文(包含 LLM、嵌入模型等配置,默认自动创建)。 |
show_progress | bool | 否 | 是否显示文档处理进度条(默认False)。 |
vector_store | VectorStore | 否 | 自定义向量存储(默认使用内存向量存储)。 |
VectorStoreIndex.from_documents().strorage_context.persist():LlamaIndex 中 StorageContext 类的核心方法,其主要作用是将存储上下文(StorageContext)中管理的所有数据持久化到磁盘,实现索引数据的本地保存。
| 参数名 | 类型 | 说明 | 默认值 |
|---|---|---|---|
persist_dir | str | 可选,指定持久化存储的目录路径(若不指定,默认使用当前目录下的 ./storage)。 | "./storage" |
query_engine:是 LlamaIndex 的查询引擎对象,由索引 index 转换而来。它封装了 “检索相关文档→生成回答” 的完整逻辑,接收用户查询并返回基于索引文档的回答。
index.as_query_engine():将向量索引转换为查询引擎,用于执行自然语言查询。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
similarity_top_k | int | 否 | 检索时返回的最相似文档数量(默认 2,值越高召回率越高但速度可能变慢)。 |
temperature | float | 否 | 生成回答的随机性(默认 0.0,适合事实性问答)。 |
streaming | bool | 否 | 是否启用流式输出(默认False,流式输出可实时返回结果)。 |
response_mode | str | 否 | 回答生成模式(如 "compact" 简洁模式、"tree_summarize" 树状总结,默认 "compact")。 |
response:是 query_engine.query() 方法返回的查询结果对象,包含针对用户问题的回答内容(如文本回答、来源文档引用等)。
query_engine.query():通过查询引擎执行自然语言查询,返回回答结果。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
str_or_query_bundle | str / QueryBundle | 是 | 查询文本(字符串)或查询对象(包含查询文本和元数据)。 |
streaming | bool | 否 | 是否强制流式输出(覆盖as_query_engine的配置,默认None)。 |
retrieval_kwargs | dict | 否 | 检索参数(如{"similarity_top_k": 5},覆盖查询引擎默认配置)。 |
# 导入操作系统交互模块,用于读取环境变量(如API密钥)
import os
# 导入LlamaIndex的全局配置类,用于统一设置框架的核心组件(模型、嵌入等)
from llama_index.core import Settings
# 导入兼容OpenAI API格式的第三方大语言模型集成类
# 用于接入API格式与OpenAI兼容的模型(如通义千问、DeepSeek等)
from llama_index.llms.openai_like import OpenAILike
# 导入阿里云DashScope(百炼)服务的大语言模型相关类
# DashScope:原生集成DashScope服务的LLM类
# DashScopeGenerationModels:枚举类,包含DashScope支持的生成式模型名称(避免拼写错误)
from llama_index.llms.dashscope import DashScope, DashScopeGenerationModels
# 导入阿里云DashScope服务的文本嵌入模型相关类
# DashScopeEmbedding:集成DashScope文本嵌入模型的类(用于将文本转换为向量)
# DashScopeTextEmbeddingModels:枚举类,包含DashScope支持的嵌入模型名称
from llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModels# 导入LlamaIndex的核心索引和文档读取类
# VectorStoreIndex:用于从文档构建向量存储索引(核心组件,支持向量检索)
# SimpleDirectoryReader:用于批量读取本地目录中的文档(支持多种格式:TXT、PDF等)
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader# LlamaIndex默认使用的大模型被替换为百炼
# Settings.llm = OpenAILike(
# model="qwen-max",
# api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
# api_key=os.getenv("DASHSCOPE_API_KEY"),
# is_chat_model=True
# )Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))# LlamaIndex默认使用的Embedding模型被替换为百炼的Embedding模型
Settings.embed_model = DashScopeEmbedding(# model_name="text-embedding-v1"model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1,api_key=os.getenv("DASHSCOPE_API_KEY")
)# RAG系统搭建
documents = SimpleDirectoryReader("./data").load_data()# 内存存储索引
index = VectorStoreIndex.from_documents(documents)# LlmaIndex的持久化索引
# index = VectorStoreIndex.from_documents(documents).strorage_context.persist("向量数据库存储路径")
query_engine = index.as_query_engine()
response = query_engine.query("deepseek v3有多少参数?")
print(response)
三、LlamaIndex介绍
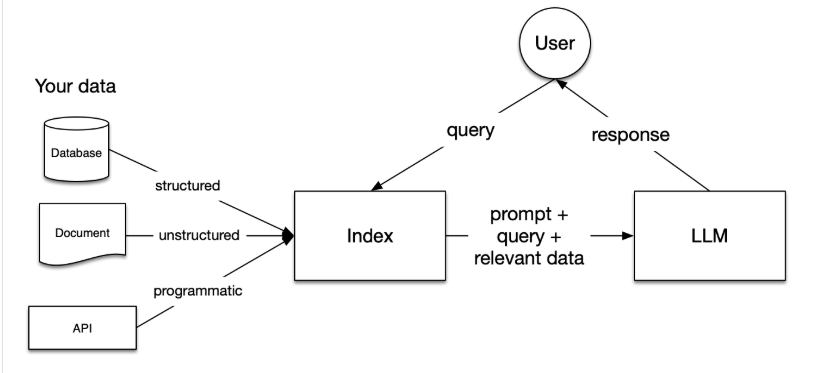
LlamaIndex 是一个为开发「知识增强」的大语言模型应用的框架(也就是 SDK)。Github 链接:https://github.com/run-llama
-
Python 文档地址:LlamaIndex - LlamaIndex
-
Python API 接口文档:API Reference - LlamaIndex
知识增强:泛指任何在私有或特定领域数据基础上应用大语言模型的情况。例如:
-
Question-Answering Chatbots (也就是 RAG)
-
Document Understanding and Extraction (文档理解与信息抽取)
-
Autonomous Agents that can perform research and take actions (智能体应用)
-
Workflow orchestrating single and multi-agent (编排单个或多个智能体形成工作流)
⭐LlamaIndex的核心模块
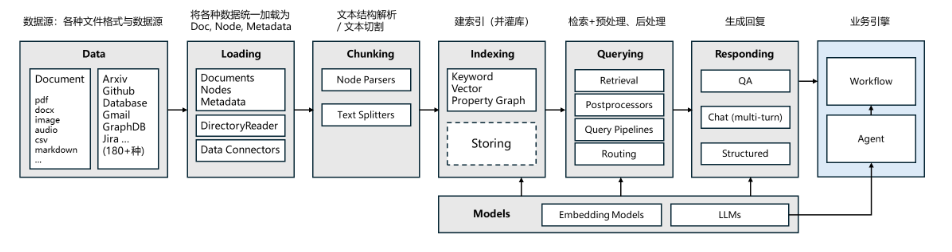
Ⅰ、核心模块作用
① Data 数据层
作用:接入多样数据源,为流程提供原始素材,涵盖文件(ArXiv/CSV 等)、图数据库(GraphDB/Neo4j)等 180 + 格式,统一为 LlamaIndex 可处理的 Document 结构。
定位:流程起点,决定 “用什么数据构建应用”。
② Loading 文档加载
作用:将分散数据源整合为 Documents 、Nodes ,通过 DirectoryReader 等工具批量读取文件,或用 Data Connectors 对接外部系统,完成数据初步聚合。
定位:数据层与解析层的桥梁,解决 “数据怎么读”。
核心函数:SimpleDirectoryReader()(批量加载目录文件)
| 参数名 | 类型 | 说明 | 示例值 |
|---|---|---|---|
input_dir | str | 必选,要加载的文件目录路径 | "./data/docs" |
file_extractor | dict | 可选,指定文件扩展名与解析器映射(覆盖默认解析) | {".pdf": PDFReader()} |
recursive | bool | 可选,是否递归加载子目录文件,默认 False | True |
required_exts | List[str] | 可选,限制仅加载指定扩展名文件,过滤无关内容 | [".txt", ".md"] |
SimpleDirectoryReader().load_data():SimpleDirectoryReader 是 llama_index 库中用于加载目录文件数据的核心工具类,其 load_data() 方法的主要作用是:读取指定目录(或特定文件列表)中的文件内容,自动解析多种格式(如 txt、pdf、docx 等),并将内容转换为 llama_index 可处理的 Document 对象列表,为后续的索引构建、检索增强生成(RAG)等任务提供基础数据。
# 1. 加载模块
from llama_index.core import SimpleDirectoryReader# 2. 配置参数,加载目录
documents = SimpleDirectoryReader(input_dir="./data/reports", # 加载指定目录required_exts=[".pdf"], # 仅加载PDF文件recursive=True # 递归子目录
).load_data()# 3. 输出结果:documents 是 Document 列表,可用于后续分块/索引
print(f"加载 {len(documents)} 个文档")③ Chunking 文本结构解析/分块
作用:拆分长文本为语义连贯的小片段(Node ),通过 Node Parsers (通用解析)或 Text Splitters (精细控制),适配模型输入长度、优化检索精度,决定 “文本怎么切”。
核心函数:TokenSplitter()(按 Token 数分块,常用文本拆分器)
| 参数名 | 类型 | 说明 | 示例值 |
|---|---|---|---|
chunk_size | int | 必选,每个分块的最大 Token 数(需适配模型上下文长度) | 512 |
chunk_overlap | int | 可选,分块间重叠 Token 数(避免语义割裂),默认 0 | 64 |
model_name | str | 可选,指定模型名称(用于精确计算 Token,如 gpt-3.5-turbo ) |
|
# 1. 加载工具 + 假设已加载 documents(来自 Loading 模块)
from llama_index.text_splitter import TokenSplitter
from llama_index.core import Document# 2. 初始化分块器
splitter = TokenSplitter(chunk_size=512, chunk_overlap=64,model_name="qwen-max" # 用通义千问模型规则计算 Token
)# 3. 分块:遍历文档,拆分为 Node
nodes = []
for doc in documents:doc_nodes = splitter.split_document(doc) # 按规则拆分单个文档nodes.extend(doc_nodes)# 4. 输出结果:nodes 是分块后的 Node 列表,可用于构建索引
print(f"文档拆分完成,共 {len(nodes)} 个 Node")④ Indexing 建模与索引
作用:为分块后的 Node 构建索引,支持关键词索引(快速文本匹配)、向量索引(Vector Store ,语义相似性检索)、属性图(Property Graph ,关联数据关系),核心解决 “数据怎么存、怎么高效查”。
核心函数:VectorStoreIndex()(构建向量索引,最常用)
| 参数名 | 类型 | 说明 | 示例值 |
|---|---|---|---|
nodes | List[Node] | 必选,分块后的 Node 列表(来自 Chunking 模块) | nodes(变量名) |
embed_model | str/BaseEmbedding | 可选,指定 Embedding 模型(如 "text-embedding-ada-002" 或自定义实例) | "dashscope-text-embedding" |
vector_store | BaseVectorStore | 可选,指定向量存储(如 Chroma / FAISS ),默认内存存储 | ChromaVectorStore() |
# 1. 加载工具 + 假设已生成 nodes(来自 Chunking 模块)
from llama_index.core import VectorStoreIndex
from llama_index.embeddings.dashscope import DashScopeEmbedding# 2. 配置 Embedding 模型(以 DashScope 为例)
embed_model = DashScopeEmbedding(model_name="dashscope-text-embedding-v1", # 阿里云嵌入模型api_key=os.getenv("DASHSCOPE_API_KEY") # 从环境变量读密钥
)# 3. 构建向量索引
index = VectorStoreIndex.from_nodes(nodes=nodes, # 分块后的 Node 列表embed_model=embed_model # 用指定模型生成向量
)# 4. 输出结果:index 是可检索的向量索引,支持 query_engine 调用
query_engine = index.as_query_engine()⑤ Querying 检索与预处理
作用:接收用户查询,通过 Retrievers (检索器)召回相关 Node ,结合 Postprocessors (后处理,如过滤、排序)、Query Pipelines (多检索器路由),输出 “与查询最相关的内容”,解决 “用户问什么,怎么找答案”。
核心函数:Retriever(检索器,以 VectorIndexRetriever 为例) + QueryEngine(编排检索 + 后处理)
VectorIndexRetriever():(向量检索器)
| 参数名 | 类型 | 说明 | 示例值 |
|---|---|---|---|
index | VectorStoreIndex | 必选,已构建的向量索引(来自 Indexing 模块) | index(变量名) |
similarity_top_k | int | 可选,召回 Top-K 个最相关 Node,默认 2 | 5 |
vector_store_query_mode | str | 可选,向量检索模式(如 "default" / "sparse" ) | "default" |
QueryEngine 检索 + 后处理:
# 1. 加载工具 + 假设已构建 index(来自 Indexing 模块)
from llama_index.core import VectorIndexRetriever, QueryEngine# 2. 初始化检索器
retriever = VectorIndexRetriever(index=index, # 关联向量索引similarity_top_k=3 # 召回最相关的 3 个 Node
)# 3. 构建 QueryEngine(串联检索 + 后处理)
query_engine = QueryEngine(retriever=retriever,# 可选:添加后处理(如 KeywordNodePostprocessor 过滤无关 Node)# postprocessors=[KeywordNodePostprocessor(keywords=["LLM"])]
)# 4. 执行查询
response = query_engine.query("LlamaIndex 分块策略有哪些?")# 5. 输出结果:response 包含模型回答、引用 Node 等
print("回答:", response.response)
print("引用 Node 数量:", len(response.source_nodes))⑥ Responding 生成与响应
作用:调用 LLMs (大模型),基于检索结果生成回答,支持单轮 QA(问答)、多轮 Chat(对话),还可输出 Structured (结构化数据,如表格 / JSON ),解决 “答案怎么生成”。
核心函数:LLM 调用(以 OpenAI 模型为例,或框架适配的 DashScope ) + Response 格式化
OpenAI初始化参数:
| 参数名 | 类型 | 说明 | 示例值 |
|---|---|---|---|
model | str | 必选,模型名称(如 "gpt-3.5-turbo" / "qwen-max" ) | "gpt-3.5-turbo" |
api_key | str | 必选,模型 API 密钥(从环境变量或配置读取) | os.getenv("OPENAI_API_KEY") |
temperature | float | 可选,生成随机性(0 最确定,1 最随机),默认 0.7 | 0.5 |
# 1. 加载工具 + 假设已构建 query_engine(来自 Querying 模块)
from llama_index.llms.openai import OpenAI# 2. 配置 LLM(替换默认模型,以 OpenAI 为例)
llm = OpenAI(model="gpt-3.5-turbo",api_key=os.getenv("OPENAI_API_KEY"),temperature=0.5
)# 3. 替换 QueryEngine 的 LLM(若需自定义生成逻辑)
query_engine.llm = llm# 4. 执行查询,生成回答
response = query_engine.query("LlamaIndex 怎么实现长文本分块?")# 5. 输出结构化响应(以多轮对话为例)
if response.response_mode == "chat":for msg in response.messages:print(f"[{msg.role}]: {msg.content}")
else:print("回答:", response.response)⑦ Models 模型支撑层
作用:提供 Embedding Models (文本转向量,支撑向量检索)、LLMs (大模型,生成回答),是 “语义理解、内容生成” 的核心依赖,决定 “用什么模型干活”。
⑧ 业务引擎 Workflow / Agent
作用:衔接 LlamaIndex 能力与业务场景,通过 Workflow 编排问答流程(如 “检索→回答→触发工单”),或用 Agent 实现复杂任务(多工具调用、决策逻辑),解决 “技术能力怎么落地业务”。
核心模式:通过 Workflow 编排流程,或用 Agent 实现自主决策(以框架 ReActAgent 为例)
| 核心能力 | 说明 | 示例场景 |
|---|---|---|
tools | 传入工具列表(如 QueryEngineTool 封装问答能力、APITool 调用外部接口) | tools=[query_engine_tool] |
llm | 关联大模型(如 OpenAI / DashScope ),驱动 Agent 决策 | llm=OpenAI(...) |
system_prompt | 自定义 Agent 系统指令(如 “作为业务助手,优先用文档回答”) | "严格遵循文档内容回答问题" |
# 1. 加载工具 + 假设已构建 query_engine(问答能力)
from llama_index.agent import ReActAgent, QueryEngineTool# 2. 封装问答工具
qa_tool = QueryEngineTool.from_defaults(query_engine=query_engine,name="LLM_QA_Tool",description="回答与 LlamaIndex 文档相关的问题"
)# 3. 初始化 Agent(关联模型+工具)
agent = ReActAgent(tools=[qa_tool],llm=OpenAI(model="gpt-3.5-turbo"),system_prompt="作为业务助手,先查文档回答,若需工单则输出 `CREATE_TICKET: 内容`"
)# 4. 模拟用户查询
user_query = "LlamaIndex 分块失败怎么排查?若解决不了,生成工单"
response = agent.chat(user_query)# 5. 解析 Agent 输出(判断是否触发工单)
if "CREATE_TICKET:" in response.content:ticket_content = response.content.split("CREATE_TICKET: ")[1]print(f"触发工单:{ticket_content} → 调用工单系统 API...")
else:print("Agent 回答:", response.content)⑨ 运行流程
LlamaIndex 核心流程
├─ 1. Loading(文档加载)
│ ├─ 工具:SimpleDirectoryReader(批量读取目录内文件,支持多格式)
│ └─ 输出:Documents(LlamaIndex 标准文档对象列表,含原始文本/元数据)
├─ 2. Chunking(文本分块)
│ ├─ 工具:TokenSplitter(按 Token 数拆分文本,适配模型上下文)
│ └─ 输出:Nodes(语义完整的文本块,含分块内容/位置信息)
├─ 3. Indexing(向量索引构建)
│ ├─ 工具:VectorStoreIndex(将 Nodes 转化为向量并存储,支持快速检索)
│ └─ 输出:Index(可检索的向量索引对象,关联向量数据库/内存存储)
├─ 4. Querying(检索与预处理)
│ ├─ 工具:Retriever(召回相关 Node) + QueryEngine(后处理,如过滤/排序)
│ └─ 输出:相关 Node(与用户查询语义匹配的 Top-K 节点列表)
├─ 5. Responding(回答生成)
│ ├─ 工具:LLM(如 OpenAI/DashScope 大模型,负责内容生成)
│ └─ 输出:用户可见响应(QA 单轮回答、Chat 多轮对话、结构化数据等)
└─ 6. 业务引擎(流程编排) ├─ 工具:Agent/Workflow(编排问答逻辑、调用外部工具、决策流程) └─ 输出:业务动作(直接回答、触发工单、调用 API 等场景化结果) 安装 LlamaIndex
清华源:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple llama-index
三、数据加载(Loading)
1.加载本地数据
SimpleDirectoryReader 是一个简单的本地文件加载器。它会遍历指定目录,并根据文件扩展名自动加载文件(文本内容)。
支持的文件类型:
.csv- comma-separated values.docx- Microsoft Word.epub- EPUB ebook format.hwp- Hangul Word Processor.ipynb- Jupyter Notebook.jpeg,.jpg- JPEG image.mbox- MBOX email archive.md- Markdown.mp3,.mp4- audio and video.pdf- Portable Document Format.png- Portable Network Graphics.ppt,.pptm,.pptx- Microsoft PowerPoint
代码示例
data:接收需要展示或处理的目标数据,但在不同函数中对数据类型和用途有具体限定:
- 在
show_json(data)中:data是待格式化为 JSON 风格展示的数据,支持 4 种类型:- JSON 字符串(如
'{"name":"test","value":123}'),需先反序列化为 Python 对象; - Python 字典 / 列表(原生可序列化数据),可直接格式化输出;
- Pydantic
BaseModel子类实例(如自定义数据模型对象),需先通过data.dict()转为字典再序列化。
- JSON 字符串(如
- 在
show_list_obj(data)中:data是待批量展示的对象列表,必须为 Python 列表类型(否则抛ValueError),函数会遍历列表中每个元素,调用show_json逐个格式化展示。
isinstance():判断一个对象是否属于指定的类型(或指定类型的子类),返回布尔值(True/False)。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
object | 任意对象 | 是 | 需要判断类型的目标对象(如变量、实例、容器等) |
classinfo | 类型 / 类型元组 | 是 | 用于匹配的类型(可传入单个类型,或多个类型组成的元组,满足任一类型即返回True) |
obj:临时变量,作用是存储 JSON 字符串反序列化后的 Python 原生对象:
当输入的 data 是 JSON 格式字符串(如 '{"page":1,"content":"test"}')时,通过 json.loads(data) 将字符串解析为 Python 字典或列表(具体类型由 JSON 字符串结构决定),解析后的结果赋值给 obj,后续再通过 json.dumps(obj, ...) 将 obj 格式化为带缩进、支持中文的 JSON 字符串并打印,实现可读性更强的展示效果。
json.loads():json标准库的函数,用于将JSON 格式的字符串(str类型)反序列化为 Python 原生数据类型(如dict、list、int等),是 “字符串转 Python 对象” 的核心工具。
注意与json.load()区分:json.load()用于读取JSON 文件对象(如open("data.json"))并反序列化,而loads()处理的是内存中的字符串。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
s | str | 是 | 待反序列化的 JSON 格式字符串(需符合 JSON 语法规范,如键必须用双引号) |
cls | 类 | 否 | 自定义 JSON 解码器(需继承json.JSONDecoder),用于处理特殊数据类型(如datetime) |
object_hook | 函数 | 否 | 反序列化后对生成的 Python 对象(如dict)进行自定义加工的函数 |
object_pairs_hook | 函数 | 否 | 对 JSON 键值对列表进行自定义处理的函数(优先级高于object_hook) |
parse_float | 函数 | 否 | 自定义解析 JSON 浮点数的函数(默认转为 Pythonfloat) |
parse_int | 函数 | 否 | 自定义解析 JSON 整数的函数(默认转为 Pythonint) |
parse_constant | 函数 | 否 | 自定义解析 JSON 常量(NaN、Infinity、-Infinity)的函数 |
json.dumps():json 标准库函数,用于将Python 原生可序列化对象(如dict、list、str、int等)序列化为JSON 格式的字符串。支持通过参数控制输出格式(如缩进、中文显示),是 “Python 对象→JSON 字符串” 的核心工具。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
obj | 可序列化对象 | 是 | 待序列化的 Python 对象(需为 JSON 支持类型,不支持set、datetime等非原生类型,需自定义处理) |
indent | int/str | 否 | 控制 JSON 字符串缩进格式(int表示空格数,str表示自定义缩进符,默认无缩进) |
ensure_ascii | bool | 否 | 是否将非 ASCII 字符(如中文、特殊符号)转义为\uXXXX格式(False保留原字符,True转义) |
cls | 类 | 否 | 自定义 JSON 编码器(需继承json.JSONEncoder),用于处理非原生可序列化对象 |
sort_keys | bool | 否 | 是否按 JSON 键的字母顺序对键值对排序(默认False) |
separators | 元组 | 否 | 自定义分隔符(格式为(item_sep, key_sep),默认(', ', ': '),用于压缩 JSON 体积) |
default | 函数 | 否 | 序列化非原生对象时的默认处理函数(接收待处理对象,返回可序列化格式) |
type():获取目标对象的精确类型(返回类型对象,不考虑继承关系)。
| 参数名 | 类型 | 是否必填 | 说明(分两种用法) |
|---|---|---|---|
object | 任意对象 | 是(单参数用法) | 获取目标对象的精确类型(如type(123)返回<class 'int'>) |
.dict():将 Pydantic 模型实例转换为 Python 原生dict(字典)。支持灵活筛选字段(包含 / 排除指定字段、过滤默认值等),是 Pydantic 模型序列化的核心工具。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
include | 集合 / 函数 | 否 | 指定需保留的字段(集合格式为字段名集合,函数格式需返回布尔值判断是否保留) |
exclude | 集合 / 函数 | 否 | 指定需排除的字段(规则同include,优先级高于include) |
by_alias | bool | 否 | 是否使用字段定义时的alias(别名)作为字典的键(默认False,用字段本名) |
exclude_unset | bool | 否 | 是否排除未显式赋值的字段(默认False,保留默认值字段) |
exclude_defaults | bool | 否 | 是否排除值等于字段默认值的字段(默认False,保留默认值字段) |
exclude_none | bool | 否 | 是否排除值为None的字段(默认False,保留None值字段) |
exclude_obj | 任意对象 | 否 | 自定义排除逻辑的辅助对象(需配合exclude函数使用,较少用) |
ValueError():Python 内置异常类,用于创建 “值错误” 异常实例。当函数 / 操作接收的参数类型正确但值不符合合法范围 / 逻辑要求时抛出(区别于TypeError,TypeError针对类型不匹配),常用于主动校验输入合法性并反馈错误原因。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
msg | str | 否 | 异常的描述信息(用于说明错误原因,便于调试和用户理解) |
args | 元组 | 否 | 异常的位置参数(若未指定msg,args的第一个元素会作为默认错误信息) |
SimpleDirectoryReader():llama-index(知识索引库)的文档读取类构造函数,用于创建 “目录级文档读取器” 实例。支持批量读取指定目录下的多种格式文档(如 PDF、TXT、DOCX、Markdown 等),自动处理文档解析,是构建本地知识库时加载文档的核心工具。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
input_dir | str/List[str] | 是 | 待读取的目录路径(可传入单个目录字符串,或多个目录组成的列表) |
recursive | bool | 否 | 是否递归读取子目录(True递归遍历所有子目录,False仅读取当前目录,默认False) |
required_exts | List[str] | 否 | 仅读取指定后缀的文件(格式为[".后缀1", ".后缀2"],默认读取所有支持格式) |
exclude_hidden | bool | 否 | 是否排除隐藏文件 / 目录(如 Linux 下以.开头的文件,Windows 下隐藏属性文件,默认True) |
file_metadata | 函数 | 否 | 自定义元数据生成函数(接收文件对象,返回字典格式的元数据,如文件大小、修改时间) |
num_workers | int | 否 | 多线程读取的 worker 数量(用于加速批量文档读取,默认1即单线程,设为0禁用多线程) |
encoding | str | 否 | 文本文件的编码格式(如"utf-8"、"gbk",默认自动检测) |
SimpleDirectoryReader().load_data():SimpleDirectoryReader 实例的核心读取方法,用于执行实际的文档加载操作。将input_dir目录下符合条件的文档解析为llama-index的Document对象列表(List[Document]),每个Document包含文档文本内容和元数据,是后续构建索引的基础数据。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
show_progress | bool | 否 | 是否显示文档读取进度条(批量读取大量文档时便于查看进度,默认False) |
docs | List[Document] | 否 | 初始文档列表(用于在已有文档基础上追加新读取的文档,默认None即仅返回新读取文档) |
collect_metadata | bool | 否 | 是否收集文档元数据(如文件路径、格式等,默认True) |
SimpleDirectoryReader().load_data().text:llama_index 文档对象的属性,作用是获取第一个文档的纯文本内容
SimpleDirectoryReader().load_data().json():列表中单个Document对象的json()方法,将Document实例直接序列化为JSON 格式字符串,无需先通过.dict()转字典,支持格式化输出。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
indent | int/str | 否 | 控制 JSON 字符串缩进格式(同json.dumps(),默认无缩进) |
ensure_ascii | bool | 否 | 是否转义非 ASCII 字符(False保留原字符,True转义,默认False) |
by_alias | bool | 否 | 是否使用字段别名作为 JSON 键(同.dict(),默认False) |
exclude_unset | bool | 否 | 是否排除未显式赋值的字段(同.dict(),默认False) |
exclude_defaults | bool | 否 | 是否排除值为默认值的字段(同.dict(),默认False) |
exclude_none | bool | 否 | 是否排除值为None的字段(同.dict(),默认False) |
# 导入Python标准库json,用于处理JSON格式数据(如将Python字典序列化為JSON字符串,或从JSON字符串反序列化为Python字典)
import json# 从pydantic库的v1版本导入BaseModel类
# pydantic是数据验证库,BaseModel是定义数据模型的基础类,可通过继承它定义强类型数据结构,自动实现字段类型检查、数据验证和序列化/反序列化
from pydantic.v1 import BaseModel# 从llama_index(知识索引构建库)的核心模块导入SimpleDirectoryReader类
# SimpleDirectoryReader用于批量读取指定目录下的各类文档文件(如PDF、TXT、DOCX等),是构建知识库时加载文档的常用工具
from llama_index.core import SimpleDirectoryReaderdef show_json(data):"""用于展示json数据"""if isinstance(data, str):obj = json.loads(data)print(json.dumps(obj, indent=4, ensure_ascii=False))elif isinstance(data, dict) or isinstance(data, list):print(json.dumps(data, indent=4, ensure_ascii=False))elif issubclass(type(data), BaseModel):print(json.dumps(data.dict(), indent=4, ensure_ascii=False))def show_list_obj(data):"""用于展示一组对象"""if isinstance(data, list):for item in data:show_json(item)else:raise ValueError("Input is not a list")reader = SimpleDirectoryReader(input_dir="./data", # 目标目录recursive=False, # 是否递归遍历子目录required_exts=[".pdf"] # (可选)只读取指定后缀的文件
)
documents = reader.load_data()print(documents[0].text)
show_json(documents[0].json())
注意:对图像、视频、语音类文件,默认不会自动提取其中文字。如需提取,参考下面介绍的
Data Connectors。
默认的 PDFReader 效果并不理想,我们可以更换文件加载器
LlamaParse
首先,登录并从 https://cloud.llamaindex.ai ↗ 注册并获取 api-key 。
清华源安装:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple llama-cloud-services
api_key:用于访问 Llama Cloud 服务(这里特指 LlamaParse 解析服务)的身份验证密钥。
os.getenv():Python 标准库 os 模块中的函数,用于从系统环境变量中读取指定键对应的值,常用于获取敏感配置(如 API 密钥、数据库密码等),避免将密钥硬编码到代码中,提高安全性。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
key | str | 是 | 环境变量的名称(如 "LLAMA_CLOUD_API_KEY")。 |
default | Any | 否 | 当环境变量不存在时返回的默认值,默认值为 None(如 default="N/A" 表示不存在时返回 "N/A")。 |
parser:初始化后的文档解析器对象(这里是LlamaParse类型)。
LlamaParse():Llama Cloud(LlamaIndex 官方云端服务)提供的高级文档解析类,专门用于处理复杂格式的文档(以 PDF 为主,也支持 docx、pptx 等),核心优势是能精准保留文档中的结构化信息(如表格、公式、多级标题、图片描述等),并将其转换为规整的文本格式(如 Markdown 或纯文本)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
api_key | str | 是 | Llama Cloud 的 API 密钥,用于验证身份并调用云端解析服务。可直接传入字符串,或通过环境变量 LLAMA_CLOUD_API_KEY 读取(推荐后者,避免硬编码)。 |
result_type | str | 否 | 解析后输出的文本格式,可选值: - "markdown"(默认):保留结构化信息(表格、标题等),转为 Markdown 格式;- "text":转为纯文本,丢弃复杂排版结构。 |
parsing_instruction | str | 否 | 自定义解析指令,用于指导云端模型如何处理文档(例如 “将所有表格转为 Markdown 表格”“忽略页眉页脚”),支持自然语言描述,进一步优化解析效果。 |
verbose | bool | 否 | 是否打印解析过程的详细日志(如 “正在上传文件”“解析完成”),默认 False。 |
skip_pages | list[int] | 否 | 需要跳过解析的页码列表(页码从 1 开始,如 [1, 5] 表示跳过第 1 页和第 5 页),默认不跳过任何页。 |
page_numbers | list[int] | 否 | 仅解析指定的页码列表(与 skip_pages 互斥,如 [2, 3, 4] 表示只解析第 2-4 页),默认解析所有页。 |
file_type | str | 否 | 手动指定文件类型(如 "pdf"“docx”),默认自动识别文件扩展名。 |
file_extractor:文件扩展名与解析器的映射字典。
documents:解析后的文档对象列表(Document类型的集合)。
SimpleDirectoryReader():LlamaIndex 提供的文档加载工具,用于批量读取指定目录中的文件(支持多种格式,如 txt、pdf、docx 等),并将文件内容转换为 Document 对象(包含文本内容和元数据),是连接本地文件与 LlamaIndex 索引系统的常用工具。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
input_dir | str | 是 | 待加载文件的目录路径(如 "./data")。 |
glob | str | 否 | 文件匹配模式(如 "*.pdf" 只加载 PDF 文件),默认加载目录中所有支持的文件。 |
recursive | bool | 否 | 是否递归加载子目录中的文件,默认 True。 |
required_exts | list[str] | 否 | 强制要求的文件扩展名列表(如 [".txt", ".pdf"]),不符合的文件会被过滤。 |
num_files_limit | int | 否 | 限制加载的文件数量(如 10 表示最多加载 10 个文件),默认无限制。 |
file_extractor | dict[str, Any] | 否 | 文件扩展名与解析器的映射(如 {".pdf": LlamaParse()}),指定不同类型文件的解析工具,默认使用内置解析器。 |
exclude_hidden | bool | 否 | 是否排除隐藏文件(如以 . 开头的文件),默认 True。 |
SimpleDirectoryReader().load_data():SimpleDirectoryReader 是 LlamaIndex 的文档加载类,实例化后调用 load_data() 方法可执行实际的文件加载与解析操作,最终返回一个包含 Document 对象的列表。这些 Document 对象封装了文件的文本内容和元数据(如文件路径、名称等),是后续构建索引、进行检索的基础数据单元。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
show_progress | bool | 否 | 是否显示加载进度条(适用于大量文件场景),默认 False。 |
num_workers | int | 否 | 多线程加载的 worker 数量(用于加速批量文件加载),默认 1(单线程)。 |
.text:Document 类的实例(LlamaIndex 中封装文档数据的核心类),text 是该实例的属性,用于存储文档的核心文本内容。
# 在系统环境变量里配置 LLAMA_CLOUD_API_KEY=XXXimport os
'''
llama_cloud_services:是 LlamaIndex 官方提供的云端服务 Python 包,封装了与 Llama Cloud(LlamaIndex 的云端服务平台)交互的工具,主要用于调用云端的高级文档解析、处理能力。
LlamaParse:是该包中的核心类,用于调用 Llama Cloud 的云端文档解析服务。它专门处理复杂格式的文档(如 PDF、docx、pptx 等),能精准识别并保留文档中的结构化信息(如表格、公式、多级标题、图片描述等),并将其转换为 Markdown 或纯文本格式。
'''
from llama_cloud_services import LlamaParse'''
llama_index.core:是 LlamaIndex 的核心包,包含了构建索引、加载文档、处理数据、执行查询等核心功能的基础组件,是整个 LlamaIndex 框架的 “引擎”。
SimpleDirectoryReader:是该包中的文档加载类,用于批量读取本地目录中的文件(支持 txt、pdf、docx 等多种格式)。它的核心作用是遍历指定目录,根据配置的规则(如文件类型过滤、解析器选择)加载文件,并将文件内容传递给解析工具(如LlamaParse),最终转换为 LlamaIndex 可处理的Document对象(包含文本内容和元数据)。
'''
from llama_index.core import SimpleDirectoryReaderapi_key = os.getenv("LLAMA_CLOUD_API_KEY")# set up parser
parser = LlamaParse(api_key = api_key,result_type="markdown" # "markdown" and "text" are available)
file_extractor = {".pdf": parser}documents = SimpleDirectoryReader(input_dir="./data", required_exts=[".pdf"], file_extractor=file_extractor).load_data()
print(documents[0].text)

2.Data Connectors
用于处理更丰富的数据类型,并将其读取为 Document 的形式。
例如:直接读取网页
清华源安装:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple llama-index-readers-web
documents:SimpleWebPageReader 加载网页内容后返回的文档对象列表(Document 类型的集合)。
每个 Document 对象包含从网页中提取的核心信息:
.text:网页的文本内容(若html_to_text=True则为纯文本,否则为原始 HTML);.metadata:网页的元数据(如网页 URL、标题、抓取时间等)。
SimpleWebPageReader():LlamaIndex 提供的网页内容加载类,用于抓取指定 URL 的网页内容,并将其转换为结构化的 Document 对象。核心功能是处理网页 HTML 内容,支持将 HTML 转为纯文本(便于后续处理),适用于从网页爬取数据并接入 LlamaIndex 索引系统。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
html_to_text | bool | 否 | 是否将网页 HTML 转换为纯文本(去除标签、保留文字内容)。 - True:返回纯文本(推荐用于索引构建);- False:保留原始 HTML 格式(含标签)。默认值: False。 |
timeout | int | 否 | 网页请求超时时间(单位:秒),超过该时间未响应则放弃抓取。默认值:10 秒。 |
headers | dict | 否 | 发送 HTTP 请求时的自定义请求头(如模拟浏览器身份),例如 {"User-Agent": "Mozilla/5.0"}。默认使用简单 headers。 |
verify_ssl | bool | 否 | 是否验证 SSL 证书(用于 HTTPS 网页)。False 可跳过证书验证(不推荐生产环境),默认 True。 |
load_data():SimpleWebPageReader 类的核心方法,用于执行实际的网页内容抓取与解析,接收网页 URL 列表,返回包含网页内容的 Document 对象列表(即 documents)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
urls | list[str] | 是 | 待抓取的网页 URL 列表,例如 ["https://example.com", "https://llamaindex.ai"]。每个 URL 对应一个网页,最终生成一个 Document 对象。 |
verbose | bool | 否 | 是否打印抓取过程日志(如 “正在抓取 URL: xxx”“抓取成功”),默认 False。 |
from llama_index.readers.web import SimpleWebPageReaderdocuments = SimpleWebPageReader(html_to_text=True).load_data(["网页地址"]
)print(documents[0].text)其他Data Connectors
内置的文件加载器:LlamaIndex Readers Integration: File
连接三方服务的数据加载器,例如数据库:模块指南 - LlamaIndex
更多加载器可以在 LlamaHub 上找到:Llama Hub
四、文本切分与解析(Chunking)
为方便检索,我们通常把 Document 切分为 Node。
在 LlamaIndex 中,Node 被定义为一个文本的「chunk」。
1.使用TextSplitters对文本做切分
例如:TokenTextSplitter按指定token数切分文本
data:作为函数的输入源
obj:仅在 show_json() 函数内部使用的临时变量,存储 json.loads() 解析 JSON 字符串后得到的Python 原生对象(通常是字典 dict 或列表 list)。
isinstance():判断一个对象是否属于指定的类型(或类型元组),返回布尔值 True/False,是代码中 “类型分支判断” 的核心工具。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
object | 任意对象 | 是 | 需要判断类型的目标对象(如代码中的 data)。 |
classinfo | 类型 / 类型元组 | 是 | 待匹配的类型(如 str、dict),或多个类型组成的元组(如 (dict, list))。 |
json.loads():将 JSON 格式字符串解析为 Python 原生数据结构(如字典 dict、列表 list),实现 “JSON 字符串 → Python 对象” 的转换。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
s | str | 是 | 待解析的 JSON 格式字符串(如代码中 isinstance(data, str) 时的 data)。 |
cls | 类 | 否 | 自定义解析类(用于处理特殊 JSON 类型,如日期),默认 None。 |
object_hook | 函数 | 否 | 自定义函数,用于将 JSON 对象(解析后的 dict)转换为自定义对象,默认 None。 |
parse_float | 函数 | 否 | 自定义函数,用于处理 JSON 中的浮点数,默认 float。 |
parse_int | 函数 | 否 | 自定义函数,用于处理 JSON 中的整数,默认 int。 |
json.dumps():将 Python 原生数据结构(如 dict、list)转换为 JSON 格式字符串,并支持格式化输出(如缩进、中文显示),实现 “Python 对象 → JSON 字符串” 的转换。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
obj | dict/list 等 | 是 | 待转换为 JSON 字符串的 Python 对象(如代码中的 obj、data)。 |
indent | int/None | 否 | JSON 字符串的缩进空格数(如 4 表示缩进 4 个空格,增强可读性),默认 None(无缩进)。 |
ensure_ascii | bool | 否 | 是否强制将非 ASCII 字符(如中文)转为 Unicode 转义符(\uXXXX):- False:保留中文等原字符;- True:转为转义符。默认 True,代码中设为 False 以正常显示中文。 |
cls | 类 | 否 | 自定义序列化类(用于处理 Python 特殊类型,如 datetime),默认 None。 |
sort_keys | bool | 否 | 是否按字典的键(key)排序输出,默认 False。 |
issubclass():判断一个类(class)是否是另一个类(或类元组)的子类,返回布尔值 True/False
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
cls | 类 | 是 | 需要判断的 “子类候选”。 |
classinfo | 类 / 类型元组 | 是 | 待匹配的 “父类”(,或多个父类组成的元组。 |
type():获取一个对象的类型(返回该对象所属的类),或创建新的类(较少用)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
object | 任意对象 | 是 | 需要获取类型的目标对象(如代码中的 data)。 |
data.dict():将 OpenAI.BaseModel 子类的实例(如 data)转换为 Python 字典,键为模型的字段名,值为字段对应的取值,实现 “结构化模型实例 → 字典” 的转换,便于后续 JSON 序列化。
documents:SimpleWebPageReader 加载网页内容后返回的 **Document 对象列表 **
每个 Document 对象封装了从目标网页(代码中为 https://edu.guangjuke.com/tx/)提取的信息:
.text:网页纯文本内容(因html_to_text=True,已去除 HTML 标签);.metadata:网页元数据(如 URL、抓取时间、网页标题等)。
是后续文档分割(TokenTextSplitter)的输入源。
SimpleWebPageReader():LlamaIndex 用于抓取网页内容的核心类,能自动请求目标 URL、解析网页 HTML,并根据配置转换为纯文本或保留 HTML 格式,最终返回 Document 对象列表。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
html_to_text | bool | 否 | 是否将网页 HTML 转换为纯文本(去除 <div>、<p> 等标签):- True:返回纯文本;- False:保留原始 HTML。默认 False,代码中设为 True 便于后续分割。 |
timeout | int | 否 | 网页请求超时时间(单位:秒),超过时间未响应则放弃抓取,默认 10 秒。 |
headers | dict | 否 | 自定义 HTTP 请求头(如模拟浏览器身份,避免被反爬),例如 {"User-Agent": "Mozilla/5.0"},默认使用简单 headers。 |
verify_ssl | bool | 否 | 是否验证 HTTPS 网页的 SSL 证书,False 可跳过验证(不推荐生产环境),默认 True。 |
SimpleWebPageReader().load_data():SimpleWebPageReader 实例的核心执行方法,接收网页 URL 列表,触发网页抓取、解析流程,最终返回 Document 对象列表
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
urls | list[str] | 是 | 待抓取的网页 URL 列表(如代码中的 ["https://edu.guangjuke.com/tx/"]),每个 URL 对应一个 Document。 |
verbose | bool | 否 | 是否打印抓取日志(如 “正在抓取 URL: xxx”“抓取成功”),默认 False。 |
node_parser:TokenTextSplitter 类的实例,即 “文档分割器对象”,专门用于将 Document 按 Token 数量分割为更小的 Node 单元。
TokenTextSplitter():LlamaIndex 按 Token 数量分割文档的核心类(区别于按字符数分割),能确保分割后的 Node 符合大模型的 Token 长度限制(如 512 Token),避免后续嵌入或生成时超限。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
chunk_size | int | 否 | 每个 Node 的最大 Token 数(即 “片段长度”),默认 1024,代码中设为 512。 |
chunk_overlap | int | 否 | 相邻 Node 之间的重叠 Token 数(用于保留上下文连贯性,避免分割丢失语义),默认 200,代码中保持默认。 |
tokenizer | 函数 / 类 | 否 | 自定义 Token 计算器(如使用 OpenAI 的 tiktoken 或 Hugging Face Tokenizer),默认使用 LlamaIndex 内置 Tokenizer。 |
separator | str | 否 | 分割时的文本分隔符(如 "\n\n" 按段落分割),默认优先按 Token 数分割,分隔符辅助优化语义完整性。 |
nodes:每个 Node 是 Document 分割后的 “子片段”,保留了原文档的部分文本和关联元数据(如所属 Document 的 ID、片段位置),适合后续生成嵌入向量、构建精细索引。
.get_nodes_from_documents():TokenTextSplitter 实例的核心执行方法,接收 Document 对象列表,按实例配置的规则(chunk_size、chunk_overlap)将 Document 分割为 Node 对象列表
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
documents | list[Document] | 是 | 待分割的 Document 对象列表(如代码中的 documents)。 |
show_progress | bool | 否 | 是否显示分割进度条(适用于大量文档场景),默认 False,代码中保持默认。 |
num_workers | int | 否 | 多线程分割的 worker 数量(用于加速批量分割),默认 1(单线程)。 |
node.json():将 Node 对象转换为 JSON 格式字符串,包含 Node 的所有属性(如 text 文本内容、metadata 元数据、node_id 唯一标识等),便于后续 JSON 格式化展示
import jsonfrom llama_index.readers.web import SimpleWebPageReader
from llama_index.core import Document
from llama_index.core.node_parser import TokenTextSplitter
from openai import BaseModeldef show_json(data):"""用于展示json数据"""if isinstance(data, str):obj = json.loads(data)print(json.dumps(obj, indent=4, ensure_ascii=False))elif isinstance(data, dict) or isinstance(data, list):print(json.dumps(data, indent=4, ensure_ascii=False))elif issubclass(type(data), BaseModel):print(json.dumps(data.dict(), indent=4, ensure_ascii=False))documents = SimpleWebPageReader(html_to_text=True).load_data(["https://edu.guangjuke.com/tx/"]
)node_parser = TokenTextSplitter(chunk_size=512, # 每个 chunk 的最大长度chunk_overlap=200 # chunk 之间重叠长度
)nodes = node_parser.get_nodes_from_documents(documents, show_progress=False
)show_json(nodes[1].json())
show_json(nodes[2].json())LlamaIndex 提供了丰富的 TextSplitter,例如:
- SentenceSplitter:在切分指定长度的 chunk 同时尽量保证句子边界不被切断;
Sentence splitter - LlamaIndex
- CodeSplitter:根据 AST(编译器的抽象句法树)切分代码,保证代码功能片段完整;
Code - LlamaIndex
- SemanticSplitterNodeParser:根据语义相关性对将文本切分为片段。
Semantic splitter - LlamaIndex
2.使用NodeParser对有结构的文档做解析
例如:HTMLNodeParser解析 HTML 文档
documents:SimpleWebPageReader 加载网页后返回的 Document 对象列表
SimpleWebPageReader():LlamaIndex 用于抓取网页内容的核心类,能自动请求目标 URL、解析网页 HTML,并根据配置转换为纯文本或保留 HTML 格式,最终返回 Document 对象列表。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
html_to_text | bool | 否 | 是否将网页 HTML 转换为纯文本(去除 <div>、<p> 等标签):- True:返回纯文本;- False:保留原始 HTML。默认 False,代码中设为 True 便于后续分割。 |
timeout | int | 否 | 网页请求超时时间(单位:秒),超过时间未响应则放弃抓取,默认 10 秒。 |
headers | dict | 否 | 自定义 HTTP 请求头(如模拟浏览器身份,避免被反爬),例如 {"User-Agent": "Mozilla/5.0"},默认使用简单 headers。 |
verify_ssl | bool | 否 | 是否验证 HTTPS 网页的 SSL 证书,False 可跳过验证(不推荐生产环境),默认 True。 |
SimpleWebPageReader().load_data():SimpleWebPageReader 实例的核心执行方法,接收网页 URL 列表,触发网页抓取、解析流程,最终返回 Document 对象列表
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
urls | list[str] | 是 | 待抓取的网页 URL 列表(如代码中的 ["https://edu.guangjuke.com/tx/"]),每个 URL 对应一个 Document。 |
verbose | bool | 否 | 是否打印抓取日志(如 “正在抓取 URL: xxx”“抓取成功”),默认 False。 |
parser:HTMLNodeParser 类的实例,即 “HTML 标签解析器对象”,专门用于从 HTML 格式的 Document 中按指定 HTML 标签提取内容并分割为 Node。
HTMLNodeParser(): HTML 文档专用节点解析器,核心作用是从 HTML 格式的文档中,按指定的 HTML 标签(如 <span>、<p>、<h1> 等)提取结构化内容,并将原始文档拆分为带有 HTML 语义的 “节点(Node)”。
| 参数名 | 参数类型 | 默认值 | 是否必填 | 参数说明 |
|---|---|---|---|---|
tags | List[str] | ["p", "h1", "h2", "h3", "h4", "h5", "h6", "li", "b", "i", "u", "section"] | 否 | 指定需要从 HTML 中提取内容的标签列表,只有这些标签内的文本会被解析为节点内容(如示例中 tags=["span"] 表示仅提取 <span> 标签内的内容)。 |
include_metadata | bool | True | 否 | 控制是否为解析出的节点添加元数据(如节点对应的 HTML 标签名、在原始文档中的位置等),便于后续追踪节点来源。 |
exclude_tags | Optional[List[str]] | None | 否 | 指定需要排除的 HTML 标签列表,即使该标签在 tags 中,也会跳过解析(优先级高于 tags)。例如 exclude_tags=["b"] 会忽略所有 <b> 标签内容。 |
strip_whitespace | bool | True | 否 | 控制是否自动去除解析出的文本内容中的多余空白字符(如连续空格、换行符),让文本更整洁。 |
base_url | Optional[str] | None | 否 | 若 HTML 文档中包含相对 URL(如 /img/logo.png),可通过该参数指定基础 URL(如 https://edu.guangjuke.com),用于将相对 URL 转换为绝对 URL 并添加到节点元数据中。 |
use_async | bool | False | 否 | 控制是否使用异步方式解析 HTML 内容(主要用于批量处理大量 HTML 文档时提升效率,单文档场景下差异不明显)。 |
与普通文本分割器(如 TokenTextSplitter)不同,它会保留 HTML 的标签语义(例如 “标题标签 <h1> 的内容”“段落标签 <p> 的内容”),而非简单按字符 / Token 分割,适用于需要从网页、HTML 文件中提取结构化信息(如标题、段落、列表、特定标签内容)的场景。
nodes:parser.get_nodes_from_documents() 的返回值,是 Node 对象列表(LlamaIndex 最小索引单元)。
parser.get_nodes_from_documents():TokenTextSplitter 实例的核心执行方法,接收 Document 对象列表,按实例配置的规则(chunk_size、chunk_overlap)将 Document 分割为 Node 对象列表
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
documents | list[Document] | 是 | 待分割的 Document 对象列表(如代码中的 documents)。 |
show_progress | bool | 否 | 是否显示分割进度条(适用于大量文档场景),默认 False,代码中保持默认。 |
num_workers | int | 否 | 多线程分割的 worker 数量(用于加速批量分割),默认 1(单线程)。 |
node.text:Node 对象的核心属性,存储从 HTML 标签中提取的纯文本内容(不含 HTML 标签)。
from llama_index.core.node_parser import HTMLNodeParser
from llama_index.readers.web import SimpleWebPageReaderdocuments = SimpleWebPageReader(html_to_text=False).load_data(["你想解析的网页文档"]
)# 默认解析 ["p", "h1", "h2", "h3", "h4", "h5", "h6", "li", "b", "i", "u", "section"]
parser = HTMLNodeParser(tags=["span"]) # 可以自定义解析哪些标签
nodes = parser.get_nodes_from_documents(documents)for node in nodes:print(node.text+"\n")更多的 NodeParser 包括 MarkdownNodeParse,JSONNodeParser等等。
五、索引(Indexing)与检索(Retrieval)
基础概念:在「检索」相关的上下文中,「索引」即index, 通常是指为了实现快速检索而设计的特定「数据结构」。
1.向量检索
Ⅰ、VectorStoreIndex:
DashScope_API_KEY:阿里云 DashScope 服务的 API 密钥。该密钥用于身份验证,使程序能够访问 DashScope 提供的嵌入模型(Embedding Model)等服务。通过os.getenv("DASHSCOPE_API_KEY")从环境变量中读取,避免了硬编码密钥的安全风险。
os.get_env():Python 标准库os中的函数,用于获取环境变量的值。常用于读取配置(如 API 密钥、数据库地址等,避免硬编码)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
key | str | 环境变量的名称(如 "OPENAI_API_KEY") | 是 |
default | 任意类型 | 若环境变量不存在时返回的默认值(默认 None) | 否 |
Settings.embed_model:LlamaIndex 框架的全局配置项,用于指定默认的文本嵌入模型。代码中将其设置为DashScopeEmbedding实例,意味着后续所有需要将文本转换为向量(嵌入)的操作,都会使用阿里云 DashScope 提供的嵌入模型来完成。
DashScopeEmbedding():阿里云 DashScope SDK 中的嵌入模型类,用于将文本转换为向量表示(嵌入)。支持多种 DashScope 提供的嵌入模型(如 text-embedding-v1)。
documents:存储从本地文件加载的原始文档数据的列表。通过SimpleDirectoryReader读取./data目录下的所有.pdf文件,并通过load_data()方法将文件内容解析为 LlamaIndex 的Document对象(每个对象包含文件文本内容和元数据,如文件名、路径等),最终保存在documents变量中。
SimpleDirectoryReader():LangChain 中的文档读取器类,用于从本地目录中批量读取文件(支持多种格式,如 txt、pdf、docx 等),返回Document对象列表。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
input_dir | str | 要读取的目录路径 | 是 |
glob | str | 文件匹配模式(如 "*.txt" 筛选 txt 文件) | 否 |
recursive | bool | 是否递归读取子目录中的文件(默认 False) | 否 |
required_exts | List[str] | 必须包含的文件扩展名(如 [".pdf"]) | 否 |
file_metadata | Callable | 自定义函数,用于为每个文件添加元数据 | 否 |
SimpleDirectoryReader().load_data():SimpleDirectoryReader类的方法,执行实际的文件读取操作,返回包含目录中所有文件内容的Document对象列表。
node_parser:文本分割器实例(这里是TokenTextSplitter),用于将原始文档分割为更小的 “节点”(Node)。
TokenTextSplitter():LangChain 中的文本分割器类,按 token(令牌)数量分割文本(而非字符数),避免分割语义完整的短语,适用于需要精确控制分割粒度的场景(如大语言模型的上下文窗口限制)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
chunk_size | int | 每个分割块的最大 token 数(如 512) | 是 |
chunk_overlap | int | 相邻分割块的重叠 token 数(如 100,用于保持上下文连贯性) | 否(默认 0) |
encoding_name | str | 用于计算 token 的编码方式(如 "cl100k_base",对应 GPT 模型) | 否(默认 "gpt2") |
separator | str | 分割文本时使用的分隔符(如 "\n\n") | 否 |
nodes:经node_parser分割后得到的 “节点” 列表。每个节点(Node)是原始文档的一个子片段,包含分割后的文本内容、对应的元数据(如来源文档信息)等。
.get_nodes_from_documents():LangChain 的DocumentTransformer或索引工具类,用于将原始文档(Document对象)转换为带有元数据的节点(Node对象),方便后续分割、存储和检索。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
documents | List[Document] | 原始文档列表(LangChain 的 Document 对象) | 是 |
text_splitter | TextSplitter | 文本分割器(如TokenTextSplitter),用于将文档分割为节点 | 否(若不分割则整文档为一个节点) |
include_metadata | bool | 是否在节点中保留原始文档的元数据 | 否(默认 True) |
VectorStoreIndex():LangChain 中的向量存储索引类,用于构建和管理基于向量的索引,将文档向量与向量数据库关联,支持快速检索。通常通过文档节点和嵌入模型初始化。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
nodes | List[Node] | 要构建索引的节点列表(通常来自.get_nodes_from_documents()) | 是 |
embedding | Embeddings | 嵌入模型(如DashScopeEmbedding),用于生成向量 | 否(若向量存储已包含嵌入则可省略) |
vector_store | VectorStore | 向量数据库实例(如Chroma、FAISS) | 否(默认使用内存向量存储) |
service_context | ServiceContext | 服务上下文,包含嵌入模型、LLM 等配置 | 否 |
vector_retriever:向量检索器对象,由VectorStoreIndex通过as_retriever()方法转换而来。
index.as_retriever():将向量索引(如VectorStoreIndex)转换为检索器(Retriever)对象,以便直接使用retrieve()方法进行检索。通常用于将索引与检索逻辑解耦,简化调用流程。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
search_type | str | 检索类型,如 "similarity"(相似度检索)、"mmr"(最大边际相关性)等 | 否 |
search_kwargs | dict | 检索参数,如k(返回数量)、filter(过滤条件)等,随search_type变化 | 否 |
results:检索结果的列表。
vector_retriever.retrieve():向量检索器的核心方法,用于根据输入的查询文本,从向量数据库中检索出与查询最相关的文档 / 数据(基于向量相似度匹配)。通常用于 RAG(检索增强生成)等场景。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
query | str | 检索的查询文本 | 是 |
k | int | 要返回的最相关结果数量(默认通常为 4 或 5) | 否 |
filter | dict | 检索时的过滤条件(如按元数据筛选) | 否 |
score_threshold | float | 相似度分数阈值,仅返回高于该值的结果 | 否 |
import os
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.core.node_parser import TokenTextSplitter, SentenceSplitter
from llama_index.embeddings.dashscope import DashScopeEmbedding# 配置DashScope 密钥
DashScope_API_KEY = os.getenv("DASHSCOPE_API_KEY")# 配置全局嵌入模型为DashScope模型
Settings.embed_model = DashScopeEmbedding(api_key=DashScope_API_KEY)# 加载 pdf 文档
documents = SimpleDirectoryReader("./data",required_exts=[".pdf"],
).load_data()# 定义 Node Parser
node_parser = TokenTextSplitter(chunk_size=512, chunk_overlap=200)# 切分文档
nodes = node_parser.get_nodes_from_documents(documents)# 构建 index,默认是在内存中
index = VectorStoreIndex(nodes)# 另外一种实现方式
# index = VectorStoreIndex.from_documents(documents=documents, transformations=[SentenceSplitter(chunk_size=512)])# 写入本地文件
# index.storage_context.persist(persist_dir="./doc_emb")# 获取 retriever
vector_retriever = index.as_retriever(similarity_top_k=2 # 返回2个结果
)# 检索
results = vector_retriever.retrieve("deepseek v3数学能力怎么样?")print(results[0].text)
Ⅱ、Qdrant
清华源下载Qdrant向量数据库:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple vector-stores-qdrant
DashScope_API_KEY:调用阿里云 DashScope 服务(提供嵌入模型等 AI 能力)的 API 密钥,用于身份验证和服务调用权限验证,从环境变量中获取。
os.getenv():Python 标准库os模块中的函数,用于获取环境变量的值,常用于安全存储 API 密钥等敏感信息(避免硬编码)。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
key | str | 环境变量的名称(如 "DASHSCOPE_API_KEY") | 无(必填) |
default | 任意类型 | 若环境变量不存在时返回的默认值 | None |
Settings.embed_model:LlamaIndex 全局配置的嵌入模型,此处设置为基于 DashScope 的嵌入模型,用于将文本转换为向量表示(便于后续向量检索)。
DashScopeEmbedding():LlamaIndex 中用于加载阿里云 DashScope 嵌入模型的类,负责将文本转换为向量表示(用于后续向量检索),支持调用 DashScope 平台提供的多种嵌入模型(如 text-embedding-v2 等)。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
api_key | str | 访问 DashScope 服务的 API 密钥,用于身份验证 | 无(必填) |
model_name | str | 嵌入模型名称,如 "text-embedding-v2"、"text-embedding-v1" 等 | "text-embedding-v2" |
dimensions | int | 向量维度(部分模型支持自定义) | 无(由模型默认决定) |
timeout | int | 接口调用超时时间(秒) | 60 |
**kwargs | - | 其他可选参数(如请求头等) | 无 |
documents:通过SimpleDirectoryReader从./data目录加载的 PDF 文档集合,包含了需要处理和检索的原始文档数据。
SimpleDirectoryReader():LlamaIndex 中的文档读取器类,用于从指定目录加载多种格式的文档(如 PDF、TXT、Markdown 等),支持过滤特定文件类型。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
input_dir | str | 文档所在的目录路径(如 "./data") | 无(必填) |
required_exts | list[str] | 仅加载指定扩展名的文件(如 [".pdf"]) | None(加载所有支持的格式) |
recursive | bool | 是否递归加载子目录中的文件 | False |
exclude_hidden | bool | 是否排除隐藏文件(如以 "." 开头的文件) | True |
filename_as_id | bool | 是否用文件名作为文档 ID | False |
file_metadata | Callable | 自定义函数,用于提取文件元数据(如创建时间) | None |
SimpleDirectoryReader().load_data():SimpleDirectoryReader实例的方法,执行文档加载操作,返回解析后的文档对象列表(每个对象包含文本内容和元数据)。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
show_progress | bool | 是否显示加载进度条 | False |
node_parser:文档分割器,此处为TokenTextSplitter,用于将原始文档按指定规则(chunk_size=512表示每个片段的 token 数量,chunk_overlap=200表示片段间的重叠 token 数量)分割成更小的文本片段。
TokenTextSplitter():LlamaIndex 中的文本分割器类,按 token 数量分割文档(而非字符数),避免因文本长度过长导致向量表示不准确,适用于需要精确控制片段长度的场景。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
chunk_size | int | 每个文本片段的最大 token 数 | 1024 |
chunk_overlap | int | 相邻片段的重叠 token 数(用于保持上下文连贯性) | 200 |
tokenizer | Callable | 自定义 tokenizer 函数(如 GPT2 的 tokenizer) | 默认使用llama_index.core.utils中的 tokenizer |
separator | str | 分割文本时使用的分隔符(如 "\n\n") | " " |
nodes:经node_parser分割后得到的文档片段集合,每个元素是一个独立的文本节点(便于后续单独处理和向量存储)。
node_parser.get_nodes_from_documents():文本分割器(如TokenTextSplitter)的方法,将原始文档(documents)按分割规则切分为多个Node对象(包含文本片段、元数据和索引信息),便于后续单独处理和向量存储。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
documents | list[Document] | 原始文档列表(由SimpleDirectoryReader加载) | 无(必填) |
show_progress | bool | 是否显示分割进度条 | False |
client:Qdrant 向量数据库的客户端实例,此处通过location=":memory:"配置为内存模式(数据仅在运行时存在,不持久化到磁盘)。
QdrantClient():Qdrant 向量数据库的客户端类,用于连接 Qdrant 服务(支持本地内存模式、本地磁盘模式或远程服务),提供向量存储、检索等操作的接口。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
location | str | 连接方式:":memory:"(内存模式)、本地路径(磁盘模式)或 "http://host:port"(远程服务) | 无(必填,或用host和port替代) |
host | str | 远程 Qdrant 服务的主机地址(与location二选一) | None |
port | int | 远程 Qdrant 服务的端口(与host配合使用) | 6333 |
api_key | str | 访问远程 Qdrant 服务的 API 密钥(若启用认证) | None |
timeout | int | 连接超时时间(秒) | 5 |
collection_name:Qdrant 向量数据库中存储向量数据的集合(类似数据库中的 "表")的名称,此处为 "demo"。
collection:在 Qdrant 中创建的具体集合对象,包含向量配置(size=1536表示向量维度为 1536,distance=Distance.COSINE表示使用余弦距离计算向量相似度)。
client.create_collection():Qdrant 客户端的方法,在 Qdrant 中创建一个集合(类似数据库中的 "表"),用于存储向量数据,需指定向量维度和相似度计算方式。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
collection_name | str | 集合名称(如 "demo") | 无(必填) |
vectors_config | VectorParams | 向量配置:size(维度)和distance(相似度算法,如 COSINE、EUCLID) | 无(必填) |
shard_number | int | 集合的分片数量(用于分布式存储) | 1 |
replication_factor | int | 副本数量(用于高可用) | 1 |
on_disk_payload | bool | 是否将元数据存储在磁盘(而非内存) | False |
vector_store:LlamaIndex 与 Qdrant 向量数据库交互的向量存储对象,关联了 Qdrant 客户端和指定的集合名称,用于管理向量的存储和检索。
QdrantVectorStore():LlamaIndex 中与 Qdrant 向量数据库对接的向量存储类,将 LlamaIndex 的向量操作(如存储、检索)转换为 Qdrant 客户端的 API 调用,实现向量数据的管理。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
client | QdrantClient | 已初始化的 Qdrant 客户端实例 | 无(必填) |
collection_name | str | 要操作的 Qdrant 集合名称 | 无(必填) |
vector_name | str | 向量字段的名称(若集合中有多个向量字段) | "vector" |
metadata_payload_key | str | 元数据在 Qdrant 中的存储键名 | "metadata" |
storage_context:存储上下文,用于管理索引的存储配置,此处通过关联vector_store指定了向量数据的存储位置(Qdrant 数据库)。
StorageContext.from_defaults():LlamaIndex 中创建存储上下文的方法,用于统一管理索引的存储配置(如向量存储、文档存储、索引存储等),使索引与存储系统关联。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
vector_store | VectorStore | 向量存储实例(如QdrantVectorStore) | None(使用默认内存存储) |
docstore | DocStore | 文档存储实例(用于存储原始文档) | None(使用默认内存存储) |
index_store | IndexStore | 索引存储实例(用于存储索引结构) | None(使用默认内存存储) |
graph_store | GraphStore | 图存储实例(用于知识图谱,可选) | None |
index:向量存储索引,基于分割后的nodes和storage_context创建,是连接文档片段与向量存储的核心组件,提供向量检索的基础能力。
VectorStoreIndex():LlamaIndex 中的向量存储索引类,是连接文档片段(nodes)与向量存储(vector_store)的核心组件,负责将文本片段转换为向量并存储,同时提供向量检索的基础能力。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
nodes | list[Node] | 经分割后的文档片段列表 | 无(必填,或通过documents参数传入原始文档) |
storage_context | StorageContext | 存储上下文(指定向量存储位置) | 无(必填,或自动创建默认存储) |
embed_model | BaseEmbedding | 嵌入模型(用于将文本转换为向量) | 全局配置的Settings.embed_model |
show_progress | bool | 是否显示索引创建进度条 | False |
vector_retriever:从索引中检索相关文档的检索器,similarity_top_k=1表示仅返回与查询最相似的 1 个文档片段。
index.as_retriever():VectorStoreIndex实例的方法,将索引转换为检索器(Retriever),用于根据查询文本从向量存储中检索最相似的文档片段。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
similarity_top_k | int | 返回与查询最相似的前 k 个文档片段 | 2 |
filter | Optional[MetadataFilters] | 元数据过滤条件(如仅检索特定来源的文档) | None |
vector_store_query_mode | str | 向量检索模式(如 "default"、"sparse" 等) | "default" |
alpha | float | 混合检索中稠密向量与稀疏向量的权重(0~1) | 0.7 |
results:检索结果集合,是vector_retriever针对查询 "deepseek v3 数学能力怎么样" 返回的最相关文档片段,此处因similarity_top_k=1而包含 1 个结果。
vector_retriever.retrieve():检索器(Retriever)的方法,接收查询文本,通过向量相似度计算从向量存储中检索并返回最相关的文档片段。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
str_or_query_bundle | Union[str, QueryBundle] | 查询文本(或封装了查询信息的QueryBundle对象) | 无(必填) |
import osfrom llama_index.core.indices.vector_store.base import VectorStoreIndex
from llama_index.embeddings.dashscope import DashScopeEmbedding
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core import StorageContextfrom qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distancefrom llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.core.node_parser import TokenTextSplitter, SentenceSplitter# 配置DashScope 密钥
DashScope_API_KEY = os.getenv("DASHSCOPE_API_KEY")# 配置全局嵌入模型为DashScope模型
Settings.embed_model = DashScopeEmbedding(api_key=DashScope_API_KEY)# 加载 pdf 文档
documents = SimpleDirectoryReader("./data",required_exts=[".pdf"],
).load_data()# 定义 Node Parser
node_parser = TokenTextSplitter(chunk_size=512, chunk_overlap=200)# 切分文档
nodes = node_parser.get_nodes_from_documents(documents)client = QdrantClient(location=":memory:")
collection_name = "demo"
collection = client.create_collection(collection_name=collection_name,vectors_config=VectorParams(size=1536, distance=Distance.COSINE)
)vector_store = QdrantVectorStore(client=client, collection_name=collection_name)
# storage: 指定存储空间
storage_context = StorageContext.from_defaults(vector_store=vector_store)# 创建 index:通过 Storage Context 关联到自定义的 Vector Store
index = VectorStoreIndex(nodes, storage_context=storage_context)# 获取 retriever
vector_retriever = index.as_retriever(similarity_top_k=1)# 检索
results = vector_retriever.retrieve("deepseek v3数学能力怎么样")print(results[0])2.更多索引与检索方式
LlamaIndex 内置了丰富的检索机制,例如:
Ⅰ、关键字检索
- BM25Retriever:基于 tokenizer 实现的 BM25 经典检索算法
- KeywordTableGPTRetriever:使用 GPT 提取检索关键字
- KeywordTableSimpleRetriever:使用正则表达式提取检索关键字
- KeywordTableRAKERetriever:使用RAKE算法提取检索关键字(有语言限制)
Ⅱ、RAG-Fusion
QueryFusionRetriever
Ⅲ、其他
还支持 KnowledgeGraph、SQL、Text-to-SQL 等等
3.检索后重排序处理
LlamaIndex 的 Node Postprocessors 提供了一系列检索后处理模块。
例如:我们可以用不同模型对检索后的 Nodes 做重排序
vector_retriever:从索引中检索相关文档的检索器,similarity_top_k=5表示返回与查询最相似的 5 个文档片段。
index.as_retriever():VectorStoreIndex实例的方法,将索引转换为检索器(Retriever),用于根据查询文本从向量存储中检索最相似的文档片段。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
similarity_top_k | int | 返回与查询最相似的前 k 个文档片段 | 2 |
filter | Optional[MetadataFilters] | 元数据过滤条件(如仅检索特定来源的文档) | None |
vector_store_query_mode | str | 向量检索模式(如 "default"、"sparse" 等) | "default" |
alpha | float | 混合检索中稠密向量与稀疏向量的权重(0~1) | 0.7 |
nodes:检索结果集合,是vector_retriever针对查询 "deepseek v3 有多少参数?" 返回的最相关文档片段,此处因similarity_top_k=5而包含 5 个结果。
vector_retriever.retrieve():检索器(Retriever)的方法,接收查询文本,通过向量相似度计算从向量存储中检索并返回最相关的文档片段。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
str_or_query_bundle | Union[str, QueryBundle] | 查询文本(或封装了查询信息的QueryBundle对象) | 无(必填) |
enumerate():Python 内置函数,用于将一个可迭代对象(如列表、元组、字符串等)转换为一个枚举对象,同时返回元素的索引和对应的值,常用于循环中便捷地获取元素位置和内容。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
iterable | 可迭代对象(如 list、tuple、str 等) | 需要进行枚举的对象,函数会遍历该对象并生成索引 - 值对 | 无(必填) |
start | int | 指定索引的起始值(即第一个元素的索引) | 0 |
# 检索后处理# 获取 retriever
vector_retriever = index.as_retriever(similarity_top_k=5)# 检索
nodes = vector_retriever.retrieve("deepseek v3有多少参数?")for i, node in enumerate(nodes):print(f"[{i}] {node.text}\n")六、生成回复(QA & Chat)
1.单轮回答(Query Engine)
qa_engine:查询引擎(Query Engine)实例,是 LlamaIndex 中用于处理用户查询并生成自然语言回答的核心组件。
它通过index.as_query_engine()从向量索引(index)创建,内部会整合「检索」和「生成」两个核心步骤:
- 首先根据用户查询从向量存储中检索相关文档片段(依赖索引的检索能力);
- 然后将检索到的信息作为上下文,调用大语言模型生成符合自然语言的回答。
当参数streaming=True时,qa_engine会变为流式查询引擎,支持将回答内容分块逐步返回(而非一次性返回完整结果),适合需要实时展示回答过程的场景。
index.as_query_engine():LlamaIndex 中VectorStoreIndex实例的方法,用于创建一个查询引擎(Query Engine)。查询引擎是连接检索与生成的核心组件,会先根据用户查询从向量索引中检索相关文档片段,再调用大语言模型(LLM)基于检索到的信息生成自然语言回答,实现 “检索增强生成(RAG)” 功能。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
streaming | bool | 是否启用流式输出(回答内容分块逐步返回) | False |
similarity_top_k | int | 检索时返回的最相关文档片段数量(影响回答的上下文丰富度) | 2 |
llm | BaseLLM | 指定用于生成回答的大语言模型,若不指定则使用全局配置的Settings.llm | None(默认使用全局 LLM) |
system_prompt | str | 自定义系统提示词(指导 LLM 生成回答的规则,如语气、格式等) | 内置默认提示词 |
filter | Optional[MetadataFilters] | 检索时的元数据过滤条件(如仅使用特定来源的文档) | None |
vector_store_query_mode | str | 向量检索模式(如 "default" 稠密检索、"sparse" 稀疏检索、"hybrid" 混合检索等) | "default" |
alpha | float | 混合检索中稠密向量与稀疏向量的权重(0~1,仅在vector_store_query_mode="hybrid"时生效) | 0.7 |
response_mode | str | 回答生成模式(如 "compact" 简洁模式、"tree_summarize" 树状总结模式等) | "compact" |
response:查询引擎处理查询后返回的结果对象,包含了针对用户问题的回答内容。
- 在非流式模式(
streaming=False,默认)下,response是一个包含完整回答的对象,直接打印(print(response))即可输出全部内容; - 在流式模式(
streaming=True)下,response是一个流式响应对象,需通过response.print_response_stream()方法逐段输出回答(类似聊天机器人的实时打字效果),此时回答内容会分批次返回,而非一次性生成完整结果。
qa_engine.query():查询引擎(qa_engine)的核心方法,用于接收用户的查询文本,执行检索与生成流程,并返回最终的回答结果对象(Response)。在非流式模式下返回完整回答,在流式模式下返回可迭代的流式响应对象。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
str_or_query_bundle | Union[str, QueryBundle] | 用户的查询内容,可为字符串(直接输入问题)或QueryBundle对象(封装了查询文本及向量等信息) | 无(必填) |
response.print_response_stream():流式响应对象(Response)的方法,仅在streaming=True模式下有效,用于将流式生成的回答内容逐段打印输出(类似实时打字效果),提升交互体验。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
delay | float | 每段内容输出的延迟时间(秒),控制打印速度 | 0.0(无延迟,即时打印) |
end | str | 每段内容末尾添加的字符(如换行符\n) | ""(空字符,连续打印) |
# 单轮回答(Query Engine)
qa_engine = index.as_query_engine()
response = qa_engine.query("deepseek v3数学能力怎么样?")print(response)# 流式输出
qa_engine = index.as_query_engine(streaming=True)
response = qa_engine.query("deepseek v3数学能力怎么样?")
response.print_response_stream()2.多轮回答(Chat Engine)
chat_engine:聊天引擎(Chat Engine)实例,由向量索引(index)通过index.as_chat_engine()创建,是 LlamaIndex 中用于处理多轮对话的核心组件。
与单轮查询引擎(qa_engine)不同,它能自动维护对话历史(上下文),在生成回答时会结合用户当前查询和之前的对话内容,支持连续交互(如追问、上下文关联的问题)。其内部同样基于 “检索增强生成(RAG)” 逻辑,先检索相关文档,再结合对话历史生成回答。
index.as_chat_engine():LlamaIndex 中VectorStoreIndex实例的方法,用于创建聊天引擎(Chat Engine)。聊天引擎是支持多轮对话的核心组件,能够自动维护对话历史(上下文),在生成回答时结合当前查询和历史对话内容,实现连续交互(如追问、上下文关联的问题)。其底层仍基于 “检索增强生成(RAG)” 逻辑,先从索引中检索相关文档,再结合对话历史生成回答。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
streaming | bool | 是否启用流式输出(回答内容分块逐步返回) | False |
llm | BaseLLM | 指定用于生成回答的大语言模型,不指定则使用全局配置的Settings.llm | None(默认使用全局 LLM) |
system_prompt | str | 自定义系统提示词(指导 LLM 生成回答的规则,如 “需结合上下文”“语气简洁” 等) | 内置默认提示词(如 “你是一个基于文档的聊天助手,需结合对话历史回答问题”) |
chat_mode | str | 聊天模式,决定对话历史的处理方式,常用值: - "condense_question":将历史对话压缩为一个问题后检索 - "context":直接将历史对话作为上下文传入 LLM - "simple":不压缩历史,直接拼接 | "condense_question" |
similarity_top_k | int | 检索时返回的最相关文档片段数量 | 2 |
filter | Optional[MetadataFilters] | 检索时的元数据过滤条件(如仅使用特定来源的文档) | None |
response:聊天引擎单轮对话的结果对象,由chat_engine.chat()方法返回,包含针对当前查询的回答内容。
由于chat_engine会维护对话历史,response的生成不仅依赖当前查询,还会参考之前的对话上下文(如用户上一轮的问题和引擎的回答)。打印response时会输出完整的自然语言回答,同时可能包含与回答相关的元数据(如检索到的源文档信息)。
chat_engine.chat():聊天引擎(chat_engine)的核心方法,用于处理单轮对话查询。接收用户当前的问题,结合历史对话上下文(自动维护)执行检索与生成流程,返回包含完整回答的响应对象,并更新聊天引擎内部的对话历史,为下一轮对话提供上下文。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
str_or_query_bundle | Union[str, QueryBundle] | 用户的查询内容,可为字符串(直接输入问题,如 "deepseek v3 有多少参数?")或QueryBundle对象(封装了查询文本及向量等信息) | 无(必填) |
streaming_response:聊天引擎流式对话的结果对象,由chat_engine.stream_chat()方法返回,仅用于流式输出场景。
与非流式的response不同,它不直接返回完整回答,而是提供一个可迭代的生成器,支持将回答内容分块(token 或短句)逐步返回,适合需要实时展示回答过程的场景(如聊天界面的 “打字效果”)。
chat_engine.stream_chat():聊天引擎的流式对话方法,功能与chat()类似,但返回流式响应对象。适用于需要实时展示回答过程的场景(如聊天界面的 “打字效果”),回答内容会分块(token 或短句)逐步生成,而非一次性返回完整结果。调用后会更新聊天引擎的对话历史。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
str_or_query_bundle | Union[str, QueryBundle] | 用户的查询内容,同chat()方法 | 无(必填) |
streaming_response.response_gen:流式响应对象中包含的生成器(generator),用于迭代获取流式输出的每个文本片段(token 或短句)。
通过for token in streaming_response.response_gen循环,可以逐段获取并打印回答内容,配合end=""和flush=True参数可实现连续、实时的输出效果,模拟人类打字的渐进式展示过程。
# 多轮回答(Chat Engine)
chat_engine = index.as_chat_engine()
response = chat_engine.chat("deepseek v3数学能力怎么样?")
print(response)response = chat_engine.chat("deepseek v3有多少参数?")
print(response)# 流式输出
chat_engine = index.as_chat_engine()
streaming_response = chat_engine.stream_chat("deepseek v3数学能力怎么样?")
# streaming_response.print_response_stream()
for token in streaming_response.response_gen:print(token, end="", flush=True)七、底层接口:Prompt、LLM与Embedding
1.Prompt模板
prompt:是PromptTemplate类的实例,代表一个单文本提示模板。它通过PromptTemplate("写一个关于{topic}的笑话")创建,包含一个带变量占位符{topic}的模板字符串,用于动态生成针对特定主题的笑话提示。
- 模板中
{topic}是变量占位符,可通过.format(topic="小明")方法传入具体值(如 “小明”),生成具体提示文本(如 “写一个关于小明的笑话”)。 - 作用:标准化提示词的结构,方便动态替换内容,适用于单轮、简单的文本生成场景。
PromptTemplate():用于创建文本提示模板的类,定义了包含变量占位符的模板字符串和对应的输入变量,方便动态填充内容生成具体提示词。例如,可定义模板"请解释{concept}的含义",再通过变量concept动态传入 “向量检索” 生成具体提示。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
template | str | 包含变量占位符的模板字符串(变量用{variable_name}表示) | 无(必填) |
input_variables | List[str] | 模板中所有变量的名称列表(需与template中的占位符对应) | 无(必填) |
validate_template | bool | 是否验证模板字符串与输入变量的一致性(如变量是否缺失) | True |
.format():提示模板(PromptTemplate)或字符串的方法,用于将输入变量填充到模板的占位符中,生成具体的提示文本。例如,template.format(concept="向量检索")会将模板中的{concept}替换为 “向量检索”。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
*args | 任意类型 | 按位置传递的变量值(与模板中变量的顺序对应) | 无(可选,与**kwargs二选一) |
** kwargs | 键值对 | 按名称传递的变量值(键需与模板中的变量名一致) | 无(可选,与*args二选一) |
chat_text_qa_msgs:是一个包含ChatMessage对象的列表,用于定义ChatPromptTemplate的消息结构。列表中包含两条消息:
第一条是MessageRole.SYSTEM(系统角色)的消息,内容为"你叫{name},你必须根据用户提供的上下文回答问题。",定义了助手的名称和行为规则;
第二条是MessageRole.USER(用户角色)的消息,内容包含{context}(已知上下文)和{question}(用户问题),定义了用户输入的格式。
- 作用:通过角色区分和变量占位符,结构化多轮对话的模板框架,作为
ChatPromptTemplate的核心输入,确保对话提示的规范性和可扩展性。
ChatMessage():表示单条聊天消息的类,用于构建对话历史。每条消息包含发送者角色(如系统、用户、助手)和具体内容,是多轮对话中上下文传递的基本单元。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
role | str | 消息发送者的角色,常用值: - "system":系统提示(指导助手行为) - "user":用户输入 - "assistant":助手的回答 | 无(必填) |
content | str | 消息的具体内容(文本) | 无(必填) |
additional_kwargs | Dict[str, Any] | 额外的元数据(如消息 ID、时间戳等,可选) | {} |
text_qa_template:是ChatPromptTemplate类的实例,代表一个多轮对话提示模板。它通过ChatPromptTemplate(chat_text_qa_msgs)创建,基于chat_text_qa_msgs列表中定义的多条聊天消息结构,用于构建问答场景的提示模板。
- 包含
{name}(系统角色名称)、{context}(上下文信息)、{question}(用户问题)三个变量占位符,可通过.format()方法传入具体值,生成完整的对话提示。 - 作用:标准化多轮对话的结构(包含系统提示、用户输入等角色区分),适用于需要明确角色和上下文的问答场景(如检索增强生成中的回答生成环节)。
ChatPromptTemplate():用于创建聊天场景提示模板的类,由多个ChatMessage对象组成,专门用于构建多轮对话的提示结构。例如,可包含一条 “system” 消息(系统提示)、多条 “user” 消息(用户历史问题)和 “assistant” 消息(助手历史回答),形成完整的对话上下文模板。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
messages | List[ChatMessage] | 组成提示模板的消息列表(每条为ChatMessage对象,包含角色和内容模板) | 无(必填) |
input_variables | List[str] | 所有消息模板中用到的变量名称列表(需与消息中的占位符对应) | 自动从messages中提取(可选) |
validate_template | bool | 是否验证消息模板与输入变量的一致性 | True |
from llama_index.core import PromptTemplateprompt = PromptTemplate("写一个关于{topic}的笑话")print(prompt.format(topic="小明"))# ChatPromptTemplate 定义多轮消息模板
from llama_index.core.llms import ChatMessage, MessageRole
from llama_index.core import ChatPromptTemplatechat_text_qa_msgs = [ChatMessage(role=MessageRole.SYSTEM,content="你叫{name},你必须根据用户提供的上下文回答问题。",),ChatMessage(role=MessageRole.USER,content=("已知上下文:\n" \"{context}\n\n" \"问题:{question}")),
]
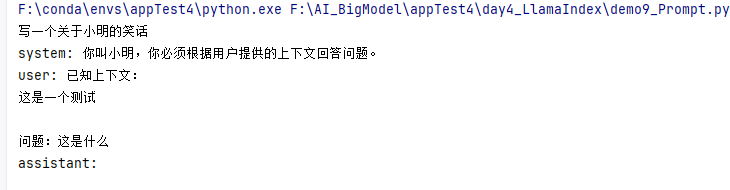
text_qa_template = ChatPromptTemplate(chat_text_qa_msgs)print(text_qa_template.format(name="小明",context="这是一个测试",question="这是什么")
)
2.语言模型
Ⅰ、配置模型
llm:llm 是 DashScope 类的实例,代表一个通过阿里云 DashScope 平台调用的大语言模型(LLM)客户端。它的作用是连接并使用 DashScope 提供的大语言模型服务
DashScope():LlamaIndex 中用于集成阿里云 DashScope 平台大语言模型(LLM)的类,用于创建一个大语言模型客户端实例。通过该实例可以调用 DashScope 提供的各类大语言模型(如 DeepSeek、Qwen 等)进行文本生成、问答、逻辑推理等任务,是连接 LlamaIndex 与 DashScope LLM 服务的核心接口。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
model_name | str | 指定要使用的 DashScope 平台模型名称,如 "deepseek-r1"(DeepSeek 系列模型)、"qwen-plus"(通义千问系列模型)、"llama3-8b-instruct"(Llama3 系列模型)等 | 无(必填,需根据 DashScope 支持的模型列表选择) |
api_key | str | 访问 DashScope 服务的 API 密钥,用于身份验证和权限校验,通常从环境变量获取(如os.getenv("DASHSCOPE_API_KEY")) | 无(必填,否则无法调用服务) |
temperature | float | 控制模型生成内容的随机性:值越高(0~2),生成结果越灵活多样;值越低,结果越确定、集中 | 0.7 |
max_tokens | int | 模型生成文本的最大 token 数量限制(防止生成内容过长) | 1024 |
top_p | float | 核采样参数,控制生成时选择 token 的范围(0~1):值越小,选择的 token 越集中于高概率词;值越大,包含的低概率词越多 | 1.0 |
top_k | int | 生成时仅从概率最高的前 k 个 token 中选择(控制多样性的另一种方式) | 50 |
timeout | int | 模型调用的超时时间(秒),超过该时间未返回结果则终止请求 | 60 |
streaming | bool | 是否启用流式输出(生成内容分块逐步返回,适用于实时展示场景) | False |
**kwargs | - | 其他可选参数(如自定义请求头、模型特定参数等,需参考 DashScope 官方 API 文档) | 无 |
import osfrom llama_index.llms.dashscope import DashScopellm = DashScope(model_name="deepseek-r1",api_key=os.getenv("DASHSCOPE_API_KEY"),temperature=1.5
)Ⅱ、全局配置
Settings.llm:LlamaIndex 核心配置类(Settings)中的全局大语言模型(LLM)属性,用于指定整个项目中默认使用的大语言模型,实现 “一次配置、全局复用”。
LlamaIndex 的各类组件(如查询引擎 QueryEngine、聊天引擎 ChatEngine、提示模板生成等)在需要生成自然语言(如回答问题、总结文本)时,会默认调用 Settings.llm 配置的模型,无需在每个组件中重复初始化和传入 LLM 参数,大幅简化代码并保证全局模型一致性。
DashScope():LlamaIndex 中用于集成阿里云 DashScope 平台大语言模型(LLM)的类,用于创建一个大语言模型客户端实例。通过该实例可以调用 DashScope 提供的各类大语言模型(如 DeepSeek、Qwen 等)进行文本生成、问答、逻辑推理等任务,是连接 LlamaIndex 与 DashScope LLM 服务的核心接口。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
model_name | str | 指定要使用的 DashScope 平台模型名称,如 "deepseek-r1"(DeepSeek 系列模型)、"qwen-plus"(通义千问系列模型)、"llama3-8b-instruct"(Llama3 系列模型)等 | 无(必填,需根据 DashScope 支持的模型列表选择) |
api_key | str | 访问 DashScope 服务的 API 密钥,用于身份验证和权限校验,通常从环境变量获取(如os.getenv("DASHSCOPE_API_KEY")) | 无(必填,否则无法调用服务) |
temperature | float | 控制模型生成内容的随机性:值越高(0~2),生成结果越灵活多样;值越低,结果越确定、集中 | 0.7 |
max_tokens | int | 模型生成文本的最大 token 数量限制(防止生成内容过长) | 1024 |
top_p | float | 核采样参数,控制生成时选择 token 的范围(0~1):值越小,选择的 token 越集中于高概率词;值越大,包含的低概率词越多 | 1.0 |
top_k | int | 生成时仅从概率最高的前 k 个 token 中选择(控制多样性的另一种方式) | 50 |
timeout | int | 模型调用的超时时间(秒),超过该时间未返回结果则终止请求 | 60 |
streaming | bool | 是否启用流式输出(生成内容分块逐步返回,适用于实时展示场景) | False |
**kwargs | - | 其他可选参数(如自定义请求头、模型特定参数等,需参考 DashScope 官方 API 文档) | 无 |
# 设置全局使用的语言模型
from llama_index.llms.dashscope import DashScope
from llama_index.core import SettingsSettings.llm = DashScope()3.Embedding模型
Ⅰ、配置模型
embedding_model:DashScopeEmbedding 类的实例,代表一个基于阿里云 DashScope 平台的文本嵌入模型客户端。其核心作用是将文本(如文档片段、查询语句等)转换为高维向量表示(即 “嵌入向量”),这些向量能够捕捉文本的语义信息,是实现向量检索(通过计算向量相似度匹配相关文本)的基础。
DashScopeEmbedding():LlamaIndex 中用于集成阿里云 DashScope 平台嵌入模型的类,用于创建文本嵌入模型(Embedding Model)实例。其核心功能是将文本(如文档片段、查询语句)转换为高维向量表示(Embedding),这些向量能捕捉文本的语义信息,是向量检索(通过计算向量相似度匹配相关文本)的基础,广泛用于检索增强生成(RAG)等场景。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
api_key | str | 访问 DashScope 服务的 API 密钥,用于身份验证和权限校验,通常从环境变量获取(如os.getenv("DASHSCOPE_API_KEY")) | 无(必填,否则无法调用服务) |
model_name | str | 指定要使用的 DashScope 嵌入模型名称,如 "text-embedding-v2"(通用文本嵌入模型)、"text-embedding-v1"(旧版本模型)等,不同模型的向量维度和语义捕捉能力可能不同 | "text-embedding-v2" |
dimensions | int | 生成向量的维度(部分模型支持自定义,如指定为 256、512 等),若不指定则使用模型默认维度(如 "text-embedding-v2" 默认维度为 1536) | None(使用模型默认维度) |
timeout | int | 模型调用的超时时间(秒),超过该时间未返回向量则终止请求 | 60 |
**kwargs | - | 其他可选参数(如自定义请求头、模型特定参数等,需参考 DashScope 官方 API 文档) | 无 |
from llama_index.embeddings.dashscope import DashScopeEmbeddingembedding_model = DashScopeEmbedding(api_key=os.getenv("DASHSCOPE_API_KEY"))
Ⅱ、全局配置
Settings.embed_model:LlamaIndex 核心配置类(Settings)中的全局嵌入模型属性,用于指定整个项目中默认使用的文本嵌入模型(Embedding Model),实现文本到向量转换的 “全局统一配置”。
在 LlamaIndex 中,将文本(如文档片段、用户查询)转换为向量(Embedding)是实现向量检索的基础步骤。Settings.embed_model 定义了全局默认使用的嵌入模型,所有需要进行文本向量化的操作(如:
- 将分割后的文档片段(
nodes)转换为向量并存储到向量数据库; - 将用户的查询文本转换为向量,用于匹配相似的文档向量;
)都会自动使用该配置的模型,无需在每个组件中重复指定,既简化代码又保证了向量生成逻辑的一致性。
DashScopeEmbedding():LlamaIndex 中用于集成阿里云 DashScope 平台嵌入模型的类,用于创建文本嵌入模型(Embedding Model)实例。其核心功能是将文本(如文档片段、查询语句)转换为高维向量表示(Embedding),这些向量能捕捉文本的语义信息,是向量检索(通过计算向量相似度匹配相关文本)的基础,广泛用于检索增强生成(RAG)等场景。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
api_key | str | 访问 DashScope 服务的 API 密钥,用于身份验证和权限校验,通常从环境变量获取(如os.getenv("DASHSCOPE_API_KEY")) | 无(必填,否则无法调用服务) |
model_name | str | 指定要使用的 DashScope 嵌入模型名称,如 "text-embedding-v2"(通用文本嵌入模型)、"text-embedding-v1"(旧版本模型)等,不同模型的向量维度和语义捕捉能力可能不同 | "text-embedding-v2" |
dimensions | int | 生成向量的维度(部分模型支持自定义,如指定为 256、512 等),若不指定则使用模型默认维度(如 "text-embedding-v2" 默认维度为 1536) | None(使用模型默认维度) |
timeout | int | 模型调用的超时时间(秒),超过该时间未返回向量则终止请求 | 60 |
**kwargs | - | 其他可选参数(如自定义请求头、模型特定参数等,需参考 DashScope 官方 API 文档) | 无 |
# 设置全局使用的嵌入模型from llama_index.embeddings.dashscope import DashScopeEmbedding
from llama_index.core import Settings# 全局设定
Settings.embed_model = DashScopeEmbedding()Ⅲ、链接DeepSeek
清华源下载:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple llama-index-llms-deepseek
DeepSeek():LlamaIndex 框架中适配 DeepSeek 大语言模型的类构造函数,用于初始化一个 DeepSeek 模型实例。该实例封装了与 DeepSeek 模型 API 交互的逻辑,通过配置模型名称、API 密钥、生成参数等,建立代码与 DeepSeek 模型的连接,为后续调用模型生成文本(如对话、创作、问答)提供基础。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
model | str | 是 | 指定要使用的 DeepSeek 模型版本,例如 "deepseek-chat"(对话模型)、"deepseek-coder"(代码模型)等,需与 DeepSeek 官方提供的模型名称一致 |
api_key | str | 是 | DeepSeek 平台的 API 密钥,用于身份验证(确保有权限调用模型 API),通常从环境变量或安全配置中获取,避免硬编码 |
temperature | float | 否 | 控制模型输出的随机性(范围通常为 0~2):值越大,输出越灵活多样;值越小,输出越确定保守(默认一般为 0.7,代码中曾设为 1.5 以增强创意性) |
max_tokens | int | 否 | 模型单次生成文本的最大 Token 数(限制输出长度),默认值由模型类型决定,需根据需求调整(如长文本生成可设为 2048) |
context_window | int | 否 | 模型支持的上下文窗口大小(即单次输入的最大 Token 数),默认匹配所选模型的原生上下文长度,无需手动修改 |
base_url | str | 否 | 自定义 DeepSeek 模型 API 的请求地址(默认使用 DeepSeek 官方 API 地址,私有部署场景下需修改) |
timeout | int | 否 | API 调用的超时时间(单位:秒),默认一般为 30 秒,避免因网络问题导致长期阻塞 |
stream | bool | 否 | 初始化时是否默认启用流式输出(默认 False,即一次性返回完整结果;设为 True 时需配合流式处理逻辑) |
llm:DeepSeek 类实例(LlamaIndex 适配的 DeepSeek 大语言模型对象),用于调用 DeepSeek 大语言模型的核心对象,承载了模型的配置信息和调用能力,是连接代码与 DeepSeek 模型 API 的桥梁。
response:大语言模型生成的响应结果(通常为字符串或 LlamaIndex 封装的响应对象,核心内容是文本)
llm.complete():DeepSeek 模型实例(即 llm)的核心方法,用于向初始化后的 DeepSeek 模型发送文本请求(Prompt),并获取模型生成的完整文本响应。适用于 “单轮输入 - 单轮输出” 的场景(如生成笑话、总结文本、回答简单问题),是直接调用模型生成内容的主要方式。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
prompt | str | 是 | 用户的文本需求(提示词),即模型需要处理的输入内容,例如 "写个笑话"、"总结以下文本:..." 等 |
stop | List[str]/str | 否 | 模型生成文本的 “停止符”:当模型生成内容中包含停止符时,会立即停止生成。可传入单个字符串(如 "。")或多个字符串组成的列表(如 ["END", "###"]),默认无停止符 |
stream | bool | 否 | 是否启用流式输出(默认 False):False 时一次性返回完整生成结果;True 时返回生成器,逐段返回文本(适合长文本生成,提升交互体验) |
max_tokens | int | 否 | 单次生成的最大 Token 数(优先级高于初始化 DeepSeek() 时的 max_tokens,可针对当前请求单独调整) |
temperature | float | 否 | 当前请求的输出随机性(优先级高于初始化 DeepSeek() 时的 temperature,可针对当前请求单独调整,如生成严谨内容时设为 0.2) |
additional_kwargs | dict | 否 | 额外的 API 请求参数(如自定义模型生成的其他配置,需与 DeepSeek API 文档中的可选参数匹配,一般场景下无需设置) |
import os
from llama_index.llms.deepseek import DeepSeekllm = DeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"), temperature=1.5)response = llm.complete("写个笑话")
print(response)Ⅳ、配置全局DeepSeek模型
Settings.llm:LlamaIndex 核心配置类(Settings)中的全局大语言模型(LLM)属性,用于指定整个项目中默认使用的大语言模型,实现 “一次配置、全局复用”。
LlamaIndex 的各类组件(如查询引擎 QueryEngine、聊天引擎 ChatEngine、提示模板生成等)在需要生成自然语言(如回答问题、总结文本)时,会默认调用 Settings.llm 配置的模型,无需在每个组件中重复初始化和传入 LLM 参数,大幅简化代码并保证全局模型一致性。
DeepSeek():LlamaIndex 框架中适配 DeepSeek 大语言模型的类构造函数,用于初始化一个 DeepSeek 模型实例。该实例封装了与 DeepSeek 模型 API 交互的逻辑,通过配置模型名称、API 密钥、生成参数等,建立代码与 DeepSeek 模型的连接,为后续调用模型生成文本(如对话、创作、问答)提供基础。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
model | str | 是 | 指定要使用的 DeepSeek 模型版本,例如 "deepseek-chat"(对话模型)、"deepseek-coder"(代码模型)等,需与 DeepSeek 官方提供的模型名称一致 |
api_key | str | 是 | DeepSeek 平台的 API 密钥,用于身份验证(确保有权限调用模型 API),通常从环境变量或安全配置中获取,避免硬编码 |
temperature | float | 否 | 控制模型输出的随机性(范围通常为 0~2):值越大,输出越灵活多样;值越小,输出越确定保守(默认一般为 0.7,代码中曾设为 1.5 以增强创意性) |
max_tokens | int | 否 | 模型单次生成文本的最大 Token 数(限制输出长度),默认值由模型类型决定,需根据需求调整(如长文本生成可设为 2048) |
context_window | int | 否 | 模型支持的上下文窗口大小(即单次输入的最大 Token 数),默认匹配所选模型的原生上下文长度,无需手动修改 |
base_url | str | 否 | 自定义 DeepSeek 模型 API 的请求地址(默认使用 DeepSeek 官方 API 地址,私有部署场景下需修改) |
timeout | int | 否 | API 调用的超时时间(单位:秒),默认一般为 30 秒,避免因网络问题导致长期阻塞 |
stream | bool | 否 | 初始化时是否默认启用流式输出(默认 False,即一次性返回完整结果;设为 True 时需配合流式处理逻辑) |
from llama_index.core import SettingsSettings.llm = DeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"), temperature=1.5)八、基于LlamaIndex实现一个功能较完整的RAG系统
1.功能要求
- 加载指定目录的文件
- 支持 RAG-Fusion
- 使用 Qdrant 向量数据库,并持久化到本地
- 支持检索后排序
- 支持多轮对话
2.代码实现
Ⅰ、Qdrant客户端搭建
EMBEDDING_DIM:嵌入向量的维度大小。此处定义为 1536,对应代码中使用的文本嵌入模型(DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1)生成的向量维度,用于指定 Qdrant 集合中存储的向量长度。
COLLECTION_NAME:Qdrant 向量数据库中 "集合"(collection)的名称。集合类似于数据库中的 "表",用于存储同一类别的向量数据,此处名称为 "full_demo",用于标识当前场景下的向量集合。
PATH:Qdrant 数据库文件在本地的存储路径。此处设置为 "./qdrant_db",表示向量数据会持久化存储在当前目录下的 "qdrant_db" 文件夹中。
client:Qdrant 向量数据库的客户端对象。通过QdrantClient(path=PATH)初始化,用于与本地 Qdrant 数据库交互(如创建集合、删除集合、读写向量等操作)。
QdrantClient():Qdrant 向量数据库的客户端类,用于连接 Qdrant 服务(支持内存模式、本地磁盘模式或远程服务),提供向量存储、检索、集合管理等操作的接口,是与 Qdrant 数据库交互的核心入口。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
host | str | "localhost" | Qdrant 服务的主机地址(如远程服务器 IP 或域名)。 |
port | int | 6333 | Qdrant 服务的 HTTP 端口。 |
grpc_port | int | 6334 | Qdrant 服务的 gRPC 端口(用于高效的二进制通信)。 |
https | bool | False | 是否使用 HTTPS 协议连接(True 启用加密通信)。 |
api_key | Optional[str] | None | 访问 Qdrant 服务的 API 密钥(用于身份验证,若服务开启了密钥验证)。 |
path | Optional[str] | None | 本地嵌入式 Qdrant 实例的数据存储路径(若使用本地模式,而非远程服务)。 |
timeout | Optional[float] | 5.0 | 单次请求的超时时间(单位:秒)。 |
prefix | str | "" | 服务路径前缀(用于反向代理场景,如 /qdrant)。 |
grpc_options | Optional[dict] | None | gRPC 连接的额外配置(如 grpc.max_receive_message_length 等)。 |
skip_init_check | bool | False | 是否跳过客户端初始化时与服务的连接检查(True 则不验证服务可用性)。 |
connection_pool_size | int | 10 | HTTP 连接池的大小(控制并发连接数量)。 |
EMBEDDING_DIM = 1536
COLLECTION_NAME = "full_demo"
PATH = "./qdrant_db"client = QdrantClient(path=PATH)Ⅱ、指定全局llm与嵌入模型
Settings.transformations:LlamaIndex 全局配置中定义的文档转换方式。此处设置为[SentenceSplitter(...)],表示会将加载的文档按指定规则(chunk_size=512,chunk_overlap=200)分割成更小的文本片段(chunk),便于后续嵌入和检索。
SentenceSplitter():LlamaIndex 中的文本分割器类,按句子边界分割文档(优先使用标点、换行等自然分隔符),尽量保证每个片段的语义完整性,适用于对上下文连贯性要求较高的场景(如长文档理解)。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
chunk_size | int | 每个文本片段的最大字符数(而非 token 数) | 1024 |
chunk_overlap | int | 相邻片段的重叠字符数(保持上下文关联) | 200 |
separator | str | 分割文本时的主要分隔符(如 "\n\n" 表示按段落分割) | "\n\n" |
paragraph_separator | str | 段落级分隔符 | "\n\n\n" |
secondary_separator | str | 次要分隔符(如句子间的 ".") | ". " |
# 2. 指定全局文档处理的 Ingestion Pipeline
Settings.transformations = [SentenceSplitter(chunk_size=512, chunk_overlap=200)]
Ⅲ、加载本地文档
documents:从本地目录加载的原始文档集合。通过SimpleDirectoryReader加载指定路径下的文件(如文本、PDF 等),存储为 LlamaIndex 的Document对象列表,是后续处理的原始数据。
SimpleDirectoryReader():LlamaIndex 中的文档读取器类,用于从指定目录批量加载多种格式的文档(如 PDF、TXT、Markdown、Word 等),支持过滤特定文件类型和递归读取子目录。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
input_dir | str | 文档所在的目录路径(如 "./docs") | 无(必填) |
required_exts | List[str] | 仅加载指定扩展名的文件(如 [".pdf", ".txt"]) | None(加载所有支持的格式) |
recursive | bool | 是否递归加载子目录中的文件 | False |
exclude_hidden | bool | 是否排除隐藏文件(如以 "." 开头的文件) | True |
filename_as_id | bool | 是否用文件名作为文档的唯一 ID | False |
file_metadata | Callable | 自定义函数,用于提取文件元数据(如创建时间、作者) | None |
# 3. 加载本地文档
documents = SimpleDirectoryReader(r"F:\AI_BigModel\appTest4\day4_LlamaIndex\data").load_data()Ⅳ、创建collection
client:Qdrant 向量数据库的客户端对象。通过QdrantClient(path=PATH)初始化,用于与本地 Qdrant 数据库交互(如创建集合、删除集合、读写向量等操作)。
client.collection_exists():Qdrant 客户端的方法,用于检查指定名称的集合(collection)是否已存在于 Qdrant 数据库中,返回布尔值(True表示存在,False表示不存在)。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
collection_name | str | 要检查的集合名称(如 "my_docs") | 无(必填) |
client.delete_collection():Qdrant 客户端的方法,用于删除 Qdrant 数据库中指定名称的集合及其中的所有数据(包括向量和元数据),操作不可逆。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
collection_name | str | 要删除的集合名称 | 无(必填) |
client.create_collection():Qdrant 客户端的方法,在 Qdrant 数据库中创建一个新集合(类似数据库中的 “表”),用于存储向量数据,需指定向量维度和相似度计算方式。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
collection_name | str | 新集合的名称 | 无(必填) |
vectors_config | VectorParams | 向量配置:size(维度,如 1536)和distance(相似度算法,如Distance.COSINE) | 无(必填) |
shard_number | int | 集合的分片数量(用于分布式存储) | 1 |
replication_factor | int | 副本数量(用于高可用) | 1 |
on_disk_payload | bool | 是否将元数据存储在磁盘(而非内存) | False |
VectorParams():Qdrant 向量数据库客户端(qdrant_client)中用于定义向量集合(Collection)核心配置的类,主要用于指定向量的维度、相似度计算方式等关键属性。当创建 Qdrant 集合时,必须通过 VectorParams 明确向量的基本规则,以确保后续向量的存储、检索和相似度计算能够正确执行。
Distance.COSINE:余弦相似度(常用于文本嵌入,衡量向量..方向的一致性
Distance.EUCLID:欧氏距离(衡量向量空间中两点的直线距离);
Distance.DOT:点积(衡量向量的相似度和幅度);
其他:如 MANHATTAN(曼哈顿距离)、HAMMING(汉明距离)等。
| 参数名称 | 类型 | 是否必填 | 描述 | 默认值 |
|---|---|---|---|---|
size | int | 是 | 向量的维度(长度),例如文本嵌入模型生成的 1536 维向量需指定 size=1536。 | 无 |
distance | Distance(枚举类型) | 是 | 向量相似度的计算方式,Qdrant 支持多种距离度量。 | 无 |
on_disk | bool | 否 | 指定向量是否存储在磁盘上(而非内存)。设置为 True 可节省内存,适合大规模数据。 | False |
quantization_config | QuantizationConfig(可选) | 否 | 向量量化配置,用于通过降低向量精度减少存储和计算成本(如 scalar 量化、product 量化等)。 | None |
# 4. 创建 collection
if client.collection_exists(collection_name=COLLECTION_NAME):client.delete_collection(collection_name=COLLECTION_NAME)client.create_collection(collection_name=COLLECTION_NAME,vectors_config=VectorParams(size=EMBEDDING_DIM, distance=Distance.COSINE)
)Ⅴ、创建向量数据库
vector_store:连接 Qdrant 数据库的向量存储对象。通过QdrantVectorStore初始化,关联 Qdrant 客户端(client)和指定集合(COLLECTION_NAME),负责将文档片段的嵌入向量存储到 Qdrant,并提供向量检索能力。
QdrantVectorStore():LlamaIndex 中与 Qdrant 向量数据库对接的向量存储类,将 LlamaIndex 的向量操作(如存储、检索、删除)转换为 Qdrant 客户端的 API 调用,实现向量数据的管理。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
client | QdrantClient | 已初始化的 Qdrant 客户端实例 | 无(必填) |
collection_name | str | 要操作的 Qdrant 集合名称 | 无(必填) |
vector_name | str | 向量字段在集合中的名称(若集合有多个向量字段) | "vector" |
metadata_payload_key | str | 元数据在 Qdrant 中的存储键名 | "metadata" |
# 5. 创建 Vector Store
vector_store = QdrantVectorStore(client=client, collection_name=COLLECTION_NAME)Ⅵ、向量索引构建
storage_context:LlamaIndex 中的存储上下文对象。通过StorageContext.from_defaults(vector_store=vector_store)创建,用于统一管理与存储相关的组件(此处主要关联向量存储vector_store),是构建索引的必要参数。
StorageContext.from_defaults():LlamaIndex 中创建存储上下文的方法,用于统一管理索引的存储配置(如向量存储、文档存储、索引存储等),使索引与底层存储系统(如 Qdrant、本地文件)关联。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
vector_store | VectorStore | 向量存储实例(如QdrantVectorStore) | None(使用默认内存存储) |
docstore | DocStore | 文档存储实例(用于存储原始文档) | None(使用默认内存存储) |
index_store | IndexStore | 索引存储实例(用于存储索引结构) | None(使用默认内存存储) |
graph_store | GraphStore | 图存储实例(用于知识图谱,可选) | None |
index:向量存储索引对象。通过VectorStoreIndex.from_documents创建,基于加载的文档(documents)和存储上下文(storage_context)构建,封装了文档片段的嵌入向量和检索逻辑,是后续查询的核心组件。
VectorStoreIndex.from_documents():LlamaIndex 中从原始文档直接创建向量存储索引的便捷方法,内部自动完成文档分割、向量化、存储等流程,无需手动处理nodes和storage_context。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
documents | List[Document] | 无默认值 | 必需参数,输入的原始文档列表,每个元素为 Document 对象(包含文本内容和元数据)。 |
storage_context | Optional[StorageContext] | None | 存储上下文对象,用于指定向量数据的存储位置(如 Qdrant、Chroma 等向量数据库)。若为 None,默认使用内存存储。你的代码中通过该参数指定了 vector_store,即向量存储目的地。 |
service_context | Optional[ServiceContext] | None | 服务上下文,包含嵌入模型(embed_model)、LLM、文本分割器等配置。若为 None,使用全局默认配置(Settings)。 |
transformations | Optional[List[BaseTransformation]] | None | 文档转换管道,通常包含文本分割器(如 SentenceSplitter),用于将原始文档拆分为短片段。你的代码中通过该参数指定了 SentenceSplitter(chunk_size=512, chunk_overlap=200),控制文档分割的粒度和重叠度。 |
show_progress | bool | False | 是否显示文档处理(分割、向量生成)的进度条。 |
embed_model | Optional[BaseEmbedding] | None | 用于生成文本向量的嵌入模型,若指定,会覆盖 service_context 中的配置。 |
nodes | Optional[List[BaseNode]] | None | 预分割的节点列表(BaseNode)。若提供,将跳过 transformations 步骤,直接使用这些节点生成索引。 |
index_id | Optional[str] | None | 索引的唯一标识 ID,用于后续通过 VectorStoreIndex.load_index_from_storage() 加载索引。 |
use_async | bool | False | 是否使用异步方式处理文档(如异步生成向量),适合大规模文档场景以提升效率。 |
store_nodes_override | Optional[bool] | None | 是否强制将节点存储到 DocumentStore,若为 None,则根据 storage_context 自动决定。 |
# 6. 指定 Vector Store 的 Storage 用于 index
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context, transformations=[SentenceSplitter(chunk_size=512, chunk_overlap=200)]
)Ⅶ、重排序模型
reranker:基于大语言模型的重排序器。通过LLMRerank(top_n=2)初始化,用于对检索到的初始结果按 "与查询的相关性" 重新排序,并保留前 2 个最相关的结果,提升检索精度。
LLMRerank():LlamaIndex 中的重排序器类,使用大语言模型(LLM)对初始检索结果进行重新排序,根据文本与查询的语义相关性调整顺序,提升检索精度(尤其适用于初始结果噪音较多的场景)。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
llm | BaseLLM | 用于重排序的大语言模型 | 无(必填) |
top_n | int | 重排序后保留的最相关结果数量 | 5 |
prompt_template | PromptTemplate | 用于重排序的提示模板(指导 LLM 判断相关性) | 内置默认模板 |
sp:相似度后处理器。通过SimilarityPostprocessor(similarity_cutoff=0.5)创建,用于过滤检索结果中相似度评分低于 0.5 的文档片段,去除不相关的结果。
SimilarityPostprocessor():LlamaIndex 中的后处理器类,对检索结果进行过滤,仅保留相似度分数高于阈值的文档片段,去除低相关性结果,减少噪音。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
similarity_cutoff | float | 相似度阈值(0~1),高于该值的结果才保留 | 0.7 |
top_n | int | 最多保留的结果数量(即使全部高于阈值) | None(无限制) |
# 7. 定义检索后排序模型
reranker = LLMRerank(top_n=2)
# 最终打分低于0.5的文档被过滤掉
sp = SimilarityPostprocessor(similarity_cutoff=0.5)Ⅷ、定义混合检索器
fusion_retriever:查询融合检索器。通过QueryFusionRetriever初始化,会基于原始查询生成多个相关子查询,融合多个子查询的检索结果以提升召回率,此处配置为从index中检索前 5 个结果,生成 3 个相关子查询。
QueryFusionRetriever():LlamaIndex 中的融合检索器类,将多个检索器(如不同向量存储的检索器、不同参数的检索器)的结果融合,通过 LLM 生成多个扩展查询,再聚合所有结果,提升检索的召回率和鲁棒性。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
base_retriever | BaseRetriever | 无默认值(必需) | 基础检索器(如 VectorIndexRetriever、BM25Retriever 等),用于执行单个查询的检索操作。 |
llm | Optional[LLM] | None | 用于生成查询变体的大语言模型。若为 None,则使用全局默认配置(Settings.llm)。 |
num_queries | int | 4 | 生成的查询变体数量(包括原始查询时,总检索次数为 num_queries)。 |
fusion_mode | str | "reciprocal_rank" | 结果融合策略,可选值: - "reciprocal_rank":基于 reciprocal rank 算法(常用,强调高排名结果);- "score":基于检索分数加权融合;- "relative_score":基于相对分数融合。 |
query_gen_prompt | Optional[PromptTemplate] | None | 生成查询变体的提示模板。若为 None,使用默认模板(指导 LLM 生成与原始查询语义相关的变体)。 |
use_original_query | bool | True | 是否将原始查询包含在检索中(True 则总检索次数为 num_queries,包含原始查询;False 则仅用生成的变体)。 |
similarity_top_k | Optional[int] | None | 最终返回的_top_k_个结果(若为 None,则使用基础检索器的 similarity_top_k)。 |
verbose | bool | False | 是否输出详细日志(如生成的查询变体、融合过程等)。 |
max_tokens | Optional[int] | None | 生成查询变体时的最大 Token 限制(若为 None,使用 LLM 的默认限制)。 |
index.as_retriever():VectorStoreIndex实例的方法,将索引转换为检索器(Retriever),用于根据查询文本从向量存储中检索最相似的文档片段。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
similarity_top_k | int | 4 | 检索时返回的最相关结果数量(top_k),例如 5 表示返回前 5 个最相似的节点。 |
vector_store_query_mode | str | "default" | 向量查询模式,控制检索算法,可选值: - "default":默认稠密向量相似性检索;- "sparse":稀疏向量检索(如 BM25);- "hybrid":混合检索(稠密 + 稀疏向量,需配合 alpha 参数);- "mmr":最大边际相关性检索(减少结果冗余)。 |
alpha | float | 0.5 | 混合检索(vector_store_query_mode="hybrid")时的权重参数,范围 [0,1]:- alpha=1:仅用稠密向量;- alpha=0:仅用稀疏向量;- 中间值:两者加权融合。 |
filters | Optional[MetadataFilters] | None | 元数据过滤器,用于根据文档元数据(如 source、date、category 等)筛选检索结果。例如过滤出 “来源为 PDF” 的文档。 |
node_ids | Optional[List[str]] | None | 限定检索的节点 ID 列表,仅从指定 ID 的节点中检索结果(用于精确控制范围)。 |
use_async | bool | False | 是否使用异步方式执行检索(True 则通过 async_retrieve 异步调用,适合高并发场景)。 |
verbose | bool | False | 是否输出检索过程的详细日志(如检索分数、过滤条件等),便于调试。 |
retriever_mode | str | "default" | 检索器模式(部分索引类型支持),例如 "embedding"(基于嵌入向量)、"keyword"(基于关键词)等,具体取决于索引实现。 |
score_threshold | Optional[float] | None | 检索结果的分数阈值,仅返回分数高于该值的节点(过滤低相关度结果,需向量存储支持分数输出)。 |
# 8. 定义 RAG Fusion 检索器
fusion_retriever = QueryFusionRetriever([index.as_retriever()],similarity_top_k=5, # 检索召回 top k 结果num_queries=3, # 生成 query 数use_async=False,# query_gen_prompt="", # 可以自定义 query 生成的 prompt 模板
)Ⅸ、单轮对话
query_engine:单轮查询引擎。通过RetrieverQueryEngine.from_args创建,以fusion_retriever为检索器,应用sp(过滤低相似度结果)和reranker(重排序)处理结果,最终通过response_synthesizer生成回答(此处使用REFINE模式优化回答),用于处理单轮用户查询。
RetrieverQueryEngine.from_args():LlamaIndex 中从检索器快速创建查询引擎的方法,将检索器(retriever)与大语言模型(llm)结合,实现 “检索 + 生成” 的问答功能,无需手动配置复杂流程。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
retriever | BaseRetriever | 无默认值(必需) | 检索器实例(如 VectorIndexRetriever、QueryFusionRetriever 等),负责根据查询检索相关文档。 |
response_synthesizer | Optional[ResponseSynthesizer] | None | 响应合成器实例,负责将检索结果生成为回答。若为 None,则通过 get_response_synthesizer() 自动创建默认合成器。 |
llm | Optional[LLM] | None | 用于生成回答的大语言模型,仅在未指定 response_synthesizer 时有效(会传递给默认合成器)。 |
text_qa_template | Optional[PromptTemplate] | None | 问答提示模板,仅在未指定 response_synthesizer 时有效(传递给默认合成器)。 |
refine_template | Optional[PromptTemplate] | None | 优化提示模板,仅在未指定 response_synthesizer 时有效(传递给默认合成器)。 |
response_mode | str | "compact" | 响应生成模式,仅在未指定 response_synthesizer 时有效(传递给默认合成器)。 |
node_postprocessors | Optional[List[BaseNodePostprocessor]] | None | 节点后处理器列表,用于对检索到的节点(Node)进行二次处理(如过滤低相关度节点、按时间排序等)。常见后处理器:SimilarityPostprocessor(按分数过滤)、MetadataReplacementPostprocessor(替换元数据占位符)。 |
verbose | bool | False | 是否输出查询引擎的详细日志(如检索过程、合成过程等)。 |
use_async | bool | False | 是否使用异步方式执行查询(True 则通过 async_query 异步调用)。 |
streaming | bool | False | 是否支持流式输出回答(需响应合成器也开启 streaming)。 |
service_context | Optional[ServiceContext] | None | 服务上下文,包含 LLM 等配置,优先级低于直接传入的 llm 参数。 |
get_response_synthesizer():LlamaIndex 中用于创建 响应合成器(ResponseSynthesizer) 的工具函数。响应合成器的核心作用是:接收检索器返回的相关文档片段(Node),结合用户的原始查询,通过大语言模型(LLM)生成最终的自然语言回答。它负责整合检索结果、处理上下文逻辑、生成连贯回答,还可支持引用来源、多轮优化等高级功能,是 RAG 系统中 “生成” 环节的核心组件。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
llm | Optional[LLM] | None | 用于生成回答的大语言模型。若为 None,使用全局默认配置(Settings.llm)。 |
text_qa_template | Optional[PromptTemplate] | None | 问答提示模板,定义 LLM 整合检索结果生成回答的指令(如 “基于以下文档回答问题:{context} 问题:{query}”)。若为 None,使用默认模板。 |
refine_template | Optional[PromptTemplate] | None | 优化提示模板,用于 “refine 模式”(逐步优化回答),定义如何基于新文档片段迭代优化已有回答。若为 None,使用默认模板。 |
response_mode | str | "compact" | 响应生成模式,控制回答合成逻辑,可选值: - "compact":将所有文档合并为单一上下文生成回答(默认);- "refine":逐步加入文档片段,迭代优化回答;- "tree_summarize":先总结每个文档,再合并总结生成最终回答;- "no_text":仅返回检索结果,不生成回答。 |
use_async | bool | False | 是否使用异步方式生成回答(True 则通过异步 LLM 调用提升效率)。 |
verbose | bool | False | 是否输出合成过程的详细日志(如提示词内容、中间结果等)。 |
streaming | bool | False | 是否支持流式输出回答(True 则返回 StreamingResponse,可实时获取生成的 token)。 |
output_cls | Optional[type] | None | 输出结果的类型(如自定义 Pydantic 模型),用于强制 LLM 按指定格式生成结构化回答。 |
summary_template | Optional[PromptTemplate] | None | 摘要提示模板,用于 “tree_summarize 模式” 中总结单个文档片段。 |
service_context | Optional[ServiceContext] | None | 服务上下文,包含 LLM、嵌入模型等配置,优先级低于直接传入的 llm 参数。 |
# 9. 构建单轮 query engine
query_engine = RetrieverQueryEngine.from_args(fusion_retriever,node_postprocessors=[sp,reranker],response_synthesizer=get_response_synthesizer(response_mode = ResponseMode.REFINE)
)Ⅹ、多轮对话
chat_engine:对话引擎。通过CondenseQuestionChatEngine.from_defaults创建,基于query_engine扩展多轮对话能力,会将历史对话浓缩为新的查询(结合上下文),再调用query_engine生成回答,支持连续多轮交互。
CondenseQuestionChatEngine.from_defaults():LlamaIndex 中创建 “压缩问题” 聊天引擎的方法,适用于多轮对话场景。其核心逻辑是:将用户当前查询与历史对话压缩为一个独立问题,再基于该问题检索相关文档并生成回答,避免历史对话过长导致的冗余。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
retriever | BaseRetriever | 用于检索相关文档的检索器 | 无(必填) |
llm | BaseLLM | 用于压缩问题和生成回答的大语言模型 | 全局配置的Settings.llm |
condense_question_prompt | PromptTemplate | 用于压缩问题的提示模板(将历史对话 + 当前查询转为单轮问题) | 内置默认模板 |
chat_history | List[ChatMessage] | 初始对话历史(可选) | [](空历史) |
streaming | bool | 是否启用流式输出 | False |
question:用户输入的查询问题。通过input("User:")获取,是对话交互中用户提出的具体问题。
str.strip():Python 字符串的方法,用于去除字符串首尾的指定字符(默认去除空格、换行符\n、制表符\t等空白字符),返回处理后的新字符串(原字符串不变)。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
chars | str | 要去除的字符集合(如"@#"表示去除首尾的@和#) | 所有空白字符(' \t\n\r\f\v') |
response:AI 对用户问题的回答结果。通过chat_engine.chat(question)生成,包含基于检索到的文档信息和大语言模型生成的最终回答内容。
chat_engine.chat():聊天引擎(ChatEngine)的核心方法,处理单轮对话查询。接收用户当前问题,结合历史对话上下文(自动维护)执行检索与生成流程,返回包含完整回答的响应对象,并更新内部对话历史。
| 参数名 | 类型 | 描述 | 默认值 |
|---|---|---|---|
str_or_query_bundle | Union[str, QueryBundle] | 用户的查询内容(字符串或封装的查询对象) | 无(必填) |
client.close():Qdrant 客户端的方法,用于关闭与 Qdrant 服务的连接(释放网络资源),主要用于非内存模式(如远程服务或本地磁盘模式)。
# 10. 对话引擎
chat_engine = CondenseQuestionChatEngine.from_defaults(query_engine=query_engine,# condense_question_prompt="" # 可以自定义 chat message prompt 模板
)# 测试多轮对话
# User: deepseek v3模型核心架构是什么?
# User: 每次激活多少参数while True:question=input("User:")if question.strip() == "":breakresponse = chat_engine.chat(question)print(f"AI: {response}")# AI: DeepSeek-V3的核心架构基于Transformer框架,并具有多头潜在注意力(MLA)和DeepSeekMoE的特点,以实现高效的推理和经济的训练。此外,它还采用了多令牌预测(MTP)训练目标来提升在评估基准上的整体表现。
# AI: DeepSeek V3每次激活370亿个参数。client.close()3.代码运行流程
RAG系统整体流程
├─ 1. 环境准备与依赖导入
│ ├─ 导入系统库:os(环境变量操作)
│ ├─ 导入向量数据库库:qdrant_client(Qdrant客户端、VectorParams/ Distance配置)
│ └─ 导入LlamaIndex核心库:
│ ├─ 索引/文档处理:VectorStoreIndex、SimpleDirectoryReader、IngestionPipeline
│ ├─ 向量存储适配:QdrantVectorStore
│ ├─ 文档分块:SentenceSplitter
│ ├─ 响应生成:get_response_synthesizer、ResponseMode
│ ├─ 存储上下文:StorageContext
│ ├─ 后处理:LLMRerank、SimilarityPostprocessor
│ ├─ 检索器:QueryFusionRetriever
│ ├─ 查询/对话引擎:RetrieverQueryEngine、CondenseQuestionChatEngine
│ └─ 模型适配:DashScope(LLM)、DashScopeEmbedding(嵌入模型)
│
├─ 2. 全局参数与基础配置
│ ├─ 固定参数定义:
│ │ ├─ EMBEDDING_DIM=1536(嵌入向量维度,匹配TEXT_EMBEDDING_V1模型)
│ │ ├─ COLLECTION_NAME="full_demo"(Qdrant集合名称)
│ │ └─ PATH="./qdrant_db"(Qdrant本地存储路径)
│ ├─ 初始化Qdrant客户端:client = QdrantClient(path=PATH)
│ └─ 全局模型配置(LlamaIndex Settings):
│ ├─ Settings.llm:DashScope模型(QWEN_MAX,从环境变量取API_KEY)
│ ├─ Settings.embed_model:DashScope嵌入模型(TEXT_EMBEDDING_V1)
│ └─ Settings.transformations:文档分块规则(SentenceSplitter,chunk_size=512,chunk_overlap=200)
│
├─ 3. 文档加载与预处理
│ ├─ 加载本地文档:SimpleDirectoryReader读取指定路径(F:\AI_BigModel\...\data)下的文档
│ └─ 文档预处理:自动应用Settings.transformations中的SentenceSplitter分块(无需额外调用,后续索引构建时自动触发)
│
├─ 4. Qdrant向量数据库初始化
│ ├─ 检查并清理旧集合:若COLLECTION_NAME已存在,调用client.delete_collection删除
│ └─ 创建新集合:
│ ├─ 集合名称:COLLECTION_NAME
│ └─ 向量配置:VectorParams(size=EMBEDDING_DIM,distance=Distance.COSINE(余弦相似度))
│
├─ 5. 向量存储与索引构建
│ ├─ 创建Qdrant向量存储:vector_store = QdrantVectorStore(client=client, collection_name=COLLECTION_NAME)
│ ├─ 构建存储上下文:storage_context = StorageContext.from_defaults(vector_store=vector_store)
│ └─ 从文档创建索引:VectorStoreIndex.from_documents(documents, storage_context=storage_context)
│ └─ 内部逻辑:文档分块 → 嵌入模型生成向量 → 向量写入Qdrant集合
│
├─ 6. 检索与后处理策略配置
│ ├─ 后处理组件:
│ │ ├─ SimilarityPostprocessor:过滤相似度低于0.5的文档块
│ │ └─ LLMRerank:对检索结果重排序,保留Top 2相关文档
│ └─ 检索器配置(Query Fusion检索器):
│ ├─ 基础检索器列表:[index.as_retriever()](基于上述构建的VectorStoreIndex)
│ ├─ 检索参数:similarity_top_k=5(单次检索召回Top 5结果)
│ ├─ Query生成数量:num_queries=3(生成3个相关Query增强检索覆盖度)
│ └─ 异步设置:use_async=False(同步执行检索)
│
├─ 7. 查询引擎与对话引擎构建
│ ├─ 单轮查询引擎(RetrieverQueryEngine):
│ │ ├─ 核心检索器:fusion_retriever(Query Fusion检索器)
│ │ ├─ 后处理链:[SimilarityPostprocessor → LLMRerank](先过滤低相似度,再重排序)
│ │ └─ 响应生成器:get_response_synthesizer(响应模式=ResponseMode.REFINE,逐步优化回答)
│ └─ 多轮对话引擎(CondenseQuestionChatEngine):
│ ├─ 基础查询引擎:上述单轮查询引擎
│ └─ 核心功能:将多轮对话历史浓缩为单轮Query,适配检索逻辑
│
├─ 8. 多轮对话交互(循环执行)
│ ├─ 输入处理:循环接收用户输入(input("User:")),若输入为空则退出循环
│ ├─ 对话请求:调用chat_engine.chat(question)生成AI响应
│ ├─ 结果输出:打印AI响应(print(f"AI: {response}"))
│ └─ 终止条件:用户输入空字符串时退出循环
│
└─ 9. 资源释放└─ 关闭Qdrant客户端:client.close()4.整体代码
import osfrom qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, DistanceEMBEDDING_DIM = 1536
COLLECTION_NAME = "full_demo"
PATH = "./qdrant_db"client = QdrantClient(path=PATH)# ————————————————————————————————————————————————————————————————from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, get_response_synthesizer
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.response_synthesizers import ResponseMode
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core import Settings
from llama_index.core import StorageContext
from llama_index.core.postprocessor import LLMRerank, SimilarityPostprocessor
from llama_index.core.retrievers import QueryFusionRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.chat_engine import CondenseQuestionChatEngine
from llama_index.llms.dashscope import DashScope, DashScopeGenerationModels
from llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModels# 1. 指定全局llm与embedding模型
Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX,api_key=os.getenv("DASHSCOPE_API_KEY"))
Settings.embed_model = DashScopeEmbedding(model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1)# 2. 指定全局文档处理的 Ingestion Pipeline
Settings.transformations = [SentenceSplitter(chunk_size=512, chunk_overlap=200)]# 3. 加载本地文档
documents = SimpleDirectoryReader(r"F:\AI_BigModel\appTest4\day4_LlamaIndex\data").load_data()if client.collection_exists(collection_name=COLLECTION_NAME):client.delete_collection(collection_name=COLLECTION_NAME)# 4. 创建 collection
client.create_collection(collection_name=COLLECTION_NAME,vectors_config=VectorParams(size=EMBEDDING_DIM, distance=Distance.COSINE)
)# 5. 创建 Vector Store
vector_store = QdrantVectorStore(client=client, collection_name=COLLECTION_NAME)# 6. 指定 Vector Store 的 Storage 用于 index
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context
)# 7. 定义检索后排序模型
reranker = LLMRerank(top_n=2)
# 最终打分低于0.5的文档被过滤掉
sp = SimilarityPostprocessor(similarity_cutoff=0.5)# 8. 定义 RAG Fusion 检索器
fusion_retriever = QueryFusionRetriever([index.as_retriever()],similarity_top_k=5, # 检索召回 top k 结果num_queries=3, # 生成 query 数use_async=False,# query_gen_prompt="", # 可以自定义 query 生成的 prompt 模板
)# 9. 构建单轮 query engine
query_engine = RetrieverQueryEngine.from_args(fusion_retriever,node_postprocessors=[sp,reranker],response_synthesizer=get_response_synthesizer(response_mode = ResponseMode.REFINE)
)# 10. 对话引擎
chat_engine = CondenseQuestionChatEngine.from_defaults(query_engine=query_engine,# condense_question_prompt="" # 可以自定义 chat message prompt 模板
)# 测试多轮对话
# User: deepseek v3模型核心架构是什么?
# User: 每次激活多少参数while True:question=input("User:")if question.strip() == "":breakresponse = chat_engine.chat(question)print(f"AI: {response}")# AI: DeepSeek-V3的核心架构基于Transformer框架,并具有多头潜在注意力(MLA)和DeepSeekMoE的特点,以实现高效的推理和经济的训练。此外,它还采用了多令牌预测(MTP)训练目标来提升在评估基准上的整体表现。
# AI: DeepSeek V3每次激活370亿个参数。client.close()

九、Text2SQL / NL2SQL / NL2Chart / ChatBI
1.基本介绍
Text2SQL 是一种将自然语言转换为SQL查询语句的技术。
意义:让每个人都能像对话一样查询数据库,获取所需信息,而不必学习SQL语法。
2.典型应用场景
-
业务分析师的数据自助服务
-
智能BI与数据可视化
-
客服与内部数据库查询
-
跨部门数据协作与分享
-
运营数据分析与决策支持
3.Text2SQL核心能力与挑战
成熟Text2SQL的关键能力:
| 核心能力 | 说明 | 技术挑战 |
|---|---|---|
| 语义理解 | 理解用户真正的查询意图 | 处理歧义、上下文推断 |
| 数据库结构感知 | 了解表结构、字段关系 | 自动映射字段与实体 |
| 复杂查询构建 | 支持多表连接、聚合等 | 子查询、嵌套逻辑转换 |
| 上下文记忆 | 理解多轮对话中的指代 | 维护查询状态 |
| 错误处理 | 识别并修正错误输入 | 模糊匹配、容错机制 |
4.实现Text2SQL的技术架构
-
架构一:基于Workflow工作流方案
-
架构二:基于LangChain的数据库链方案
-
架构三:企业级解决方案
-
Vanna(开源):Vanna.AI - Personalized AI SQL Agent
-
阿里云(商业):
-
如何使用基于大语言模型LLM的NL2SQL_云原生数据库 PolarDB(PolarDB)-阿里云帮助中心
-
如何使用自然语言生成智能图表_云原生数据库 PolarDB(PolarDB)-阿里云帮助中心
-
-
腾讯云(商业):腾讯云 BI ChatBI 产品介绍_腾讯云如何使用基于大语言模型LLM的NL2SQL_云原生数据库 PolarDB(PolarDB)-阿里云帮助中心
-