2025时序数据库选型,以IoTDB为主从架构基因到AI赋能来解析
> 💡 原创经验总结,禁止AI洗稿!转载需授权
> 声明:本文所有观点均基于多个领域的真实项目落地经验总结,数据说话,拒绝空谈!
目录
引言:你的数据库,能应对时序数据的“四重考验”吗?
一、维度一:架构基因 —— 从根源看懂谁是“天选之子”
二、维度二:数据全生命周期管理 —— 从边缘到云端,成本与效率的博弈
2.1 端云协同:IoTDB的“杀手锏”
2.2 数据模型:树状结构 vs 关系表
三、维度三:性能剖析 —— 成本敏感型场景下的终极对决
四、维度四:AI与开发者生态 —— 决胜未来的软实力
4.1 AI 原生集成:从“被动调用”到“主动赋能”
4.2 大数据生态与查询语言
结论:2025年,你的场景该如何选型?
引言:你的数据库,能应对时序数据的“四重考验”吗?
智慧工厂里,上万个传感器每秒并发写入;新能源车队中,PB级的电池数据需存储数年备查;金融市场上,高频交易数据要求微秒级延迟响应。这些场景的背后,是时序数据的四大典型特征,也是对所有TSDB的“灵魂拷问”:

(1)极高的写入并发:能否撑住百万测点持续不断的数据轰炸?
(2)强时间关联性查询:能否在毫秒内完成对任意时间范围的聚合分析?
(3)海量数据的生命周期管理:能否用最低成本存储数年的“冷”数据,同时保证“热”数据的高效访问?
(4)乱序与高基数挑战:能否从容应对工业场景中常见的网络延迟(数据乱序)和爆炸式增长的设备标签(高基数)?
无法完美回答这四个问题的TSDB,终将在未来的数据浪潮中掉队。带着这些问题,我们来审视三位主流选手:
(1)Apache IoTDB:为工业物联网(IIoT)海量数据而生的国产原生分布式架构。
(2)InfluxDB:市场领先的通用型监控与时序应用标杆。
(3)QuestDB:以SQL为核心并兼容PostgreSQL协议的高性能时序架构。
一、维度一:架构基因 —— 从根源看懂谁是“天选之子”
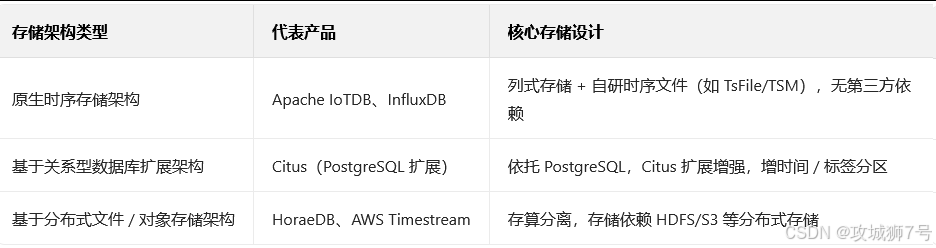
数据库的底层架构,是其能力的上限。我们可以将TSDB分为三类,其基因决定了它们各自的命运。

深度分析:
(1)原生时序,为何是工业场景的首选? 以 Apache IoTDB 为代表的原生架构,是真正为解决上述“四重考验”而生的。它采用列式存储和自研的时序文件格式(TsFile),天然适合做时间范围的聚合查询和高倍率压缩。更重要的是,它摒弃了传统数据库沉重的事务管理,通过顺乱序数据分离引擎(IoTLSM) 等设计,从根源上解决了工业场景中常见的乱序数据写入难题。这种“专病专治”的设计,使其在处理海量工业数据时,展现出体系化的优势。
(2)InfluxDB 同样属于原生阵营,其 TSM存储引擎 非常高效,但在开源版本的分布式能力和对工业数据模型的亲和度上,与IoTDB的设计思路有所不同。
(3)QuestDB 的“SQL原生”路线,通过兼容PostgreSQL线协议,极大地降低了开发者的学习成本,其性能表现令人印象深刻。但这种设计也意味着它必须在SQL的框架内进行优化,对于工业领域一些特有的数据模型(如层级结构),表达能力会受到一定限制。
结论:对于需要管理大规模、长周期、且数据特性复杂的工业物联网场景,原生时序架构无疑是根正苗红的“天选之子”。
二、维度二:数据全生命周期管理 —— 从边缘到云端,成本与效率的博弈
现代物联网应用,数据链路横跨“端-边-云”,高效管理整个链路是降本增效的关键。
2.1 端云协同:IoTDB的“杀手锏”
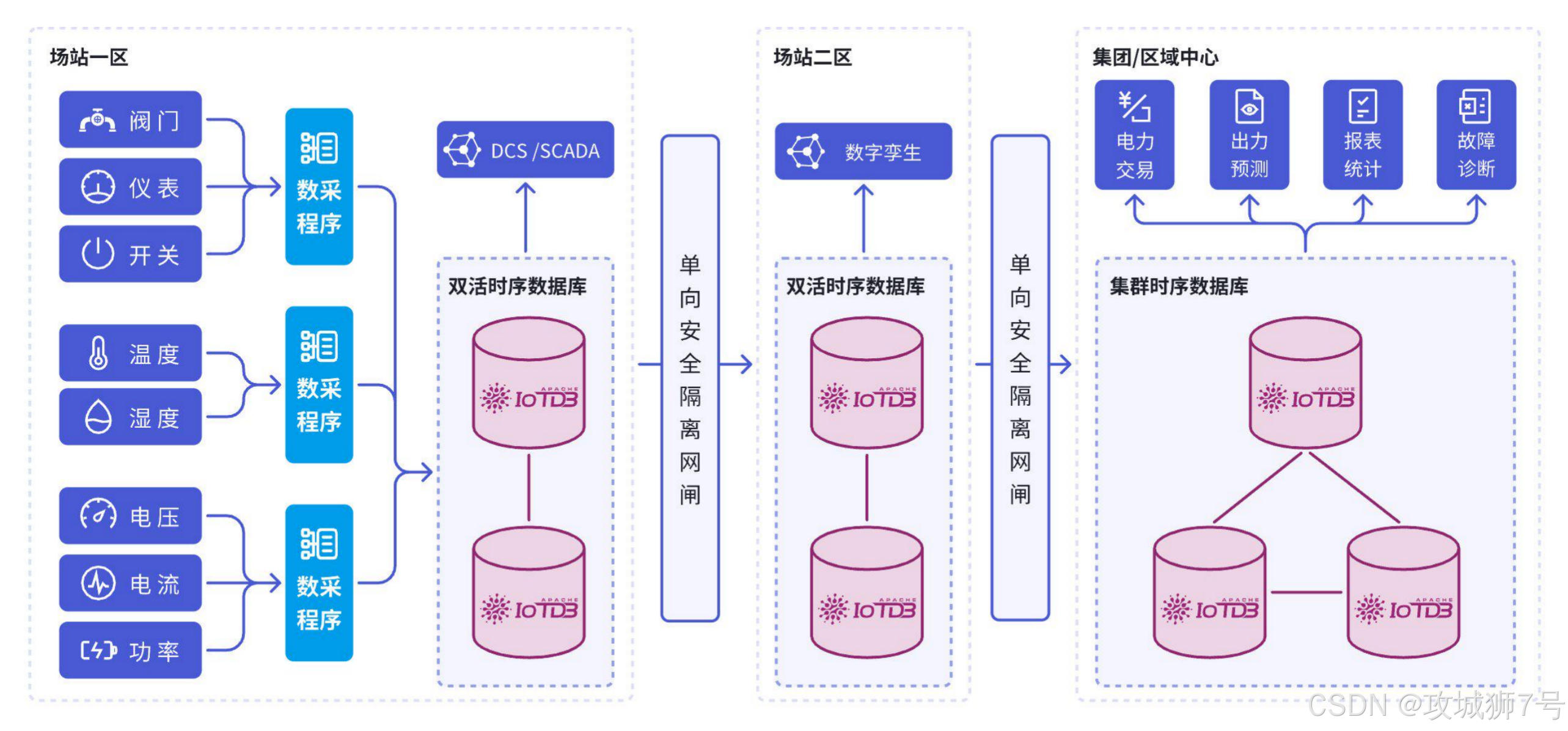
这是 Apache IoTDB 的绝对主场。它原生提供了轻量级的边缘端版本和强大的端云同步(Data Sync)工具。你可以在边缘网关上部署一个IoTDB实例(仅需几十MB内存)进行本地数据缓存和预聚合,再通过内置工具,将压缩后的 `TsFile` 文件高效、断点续传地同步至云端。这套机制是为弱网络、高延迟的工业环境“量身定制”的,能极大降低带宽成本和云端写入压力。
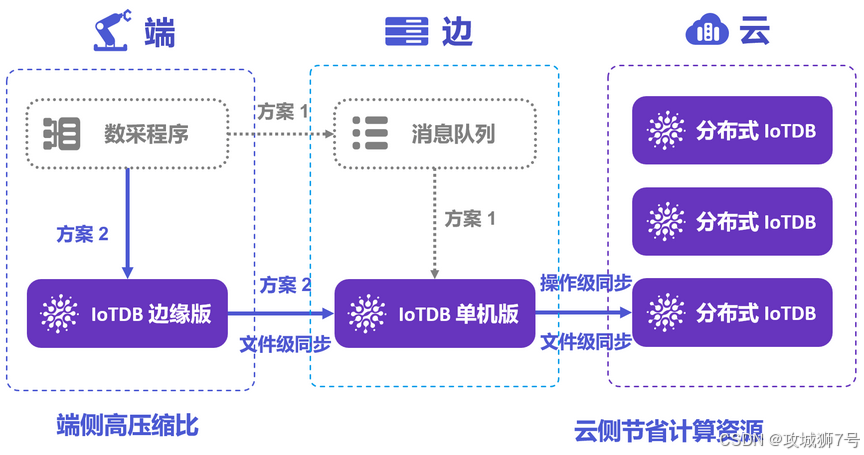
相比之下,InfluxDB 依赖 Telegraf,QuestDB 则更侧重于云端部署,它们在端侧的原生数据管理和复杂同步策略上,都不如 IoTDB 体系化。
2.2 数据模型:树状结构 vs 关系表
(1)IoTDB 的树状模型 (`root.group.device.sensor`) 与工业设备的物理层级结构天然同构。你可以像管理文件目录一样管理设备测点,例如`root.发电集团.风电场A.风机01.温度`。这种模型让数据组织非常直观,查询(如`select * from root.发电集团.风电场A.*`)也极为便利。
(2)InfluxDB 的 Tag-Value模型 在处理多维度的监控指标时极为灵活。
(3)QuestDB 采用标准的关系模型,数据存储在表中。这对于习惯SQL的开发者非常友好,但在表达复杂的设备层级关系时,可能需要设计额外的关联表,增加了复杂性。
三、维度三:性能剖析 —— 成本敏感型场景下的终极对决
我们来看一组更贴近真实业务的对比,特别是关注存储成本,这往往是长期运营中最敏感的部分。
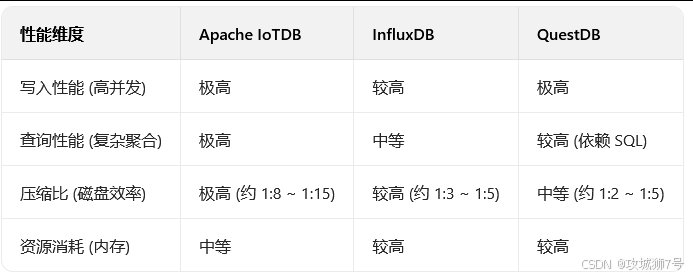
深度分析与案例:
(1)写入与查询:三者在高并发写入上都表现优异。但在复杂聚合查询(如计算一个集团下所有风场每小时的平均发电量)方面,IoTDB 凭借其专为时序设计的存储格式和查询引擎,通常表现更佳。
(2)压缩比(成本关键):这是 IoTDB 的“断层式”优势。其自研的 `TsFile` 格式,结合了Delta编码、RLE、GORILLA等多种针对不同数据类型的最优压缩算法,实现了极致的压缩比。其中一个真实案例:某智能电网项目中,1TB的原始数据,在使用IoTDB压缩后仅需80GB,节省了超过90%的磁盘成本!对于需要按法规长期保存数据(如3-5年)的工业场景,这每年可以节省数十万甚至上百万的存储费用。
代码示例:IoTDB原生的极致性能体验 (Java)
为了追求极致性能,许多工业级应用会选择Java。下面的代码展示了IoTDB如何通过`Tablet`实现超高性能的批量写入。
// 生产环境推荐使用连接池高效管理会话SessionPool pool = new SessionPool.Builder().host("127.0.0.1").port(6667).user("root").password("root").maxSize(3).build();// 1. 定义设备与测点结构 (Schema),甚至可以为每个测点指定最高效的压缩编码List<MeasurementSchema> schemaList = new ArrayList<>();schemaList.add(new MeasurementSchema("temperature", TSDataType.DOUBLE, TSEncoding.GORILLA));schemaList.add(new MeasurementSchema("status", TSDataType.BOOLEAN, TSEncoding.PLAIN));// 2. 创建Tablet,一个内存中的高效数据块,用于批量操作Tablet tablet = new Tablet("root.factory.workshop1.device01", schemaList, 100);// 3. 在客户端内存中高效填充数据long timestamp = System.currentTimeMillis();for (long row = 0; row < 100; row++) {int rowIndex = tablet.rowSize++;tablet.addTimestamp(rowIndex, timestamp + row);tablet.addValue("temperature", rowIndex, ThreadLocalRandom.current().nextDouble(20, 30));tablet.addValue("status", rowIndex, row % 2 == 0);}// 4. 一次网络请求,将整个Tablet写入数据库,性能远超逐条写入pool.insertTablet(tablet);System.out.println("Tablet 写入成功!");pool.close();代码解读:这种“客户端缓存、一次批量写入”的模式,正是IoTDB针对物联网“高并发、高吞吐”特性设计的精髓,也是其实现超高性能写入的核心秘密。
四、维度四:AI与开发者生态 —— 决胜未来的软实力
4.1 AI 原生集成:从“被动调用”到“主动赋能”
当其他数据库还在讨论如何被AI调用时,IoTDB已经通过 AINode 和 时序大模型,将AI能力内嵌到了数据库内核中。
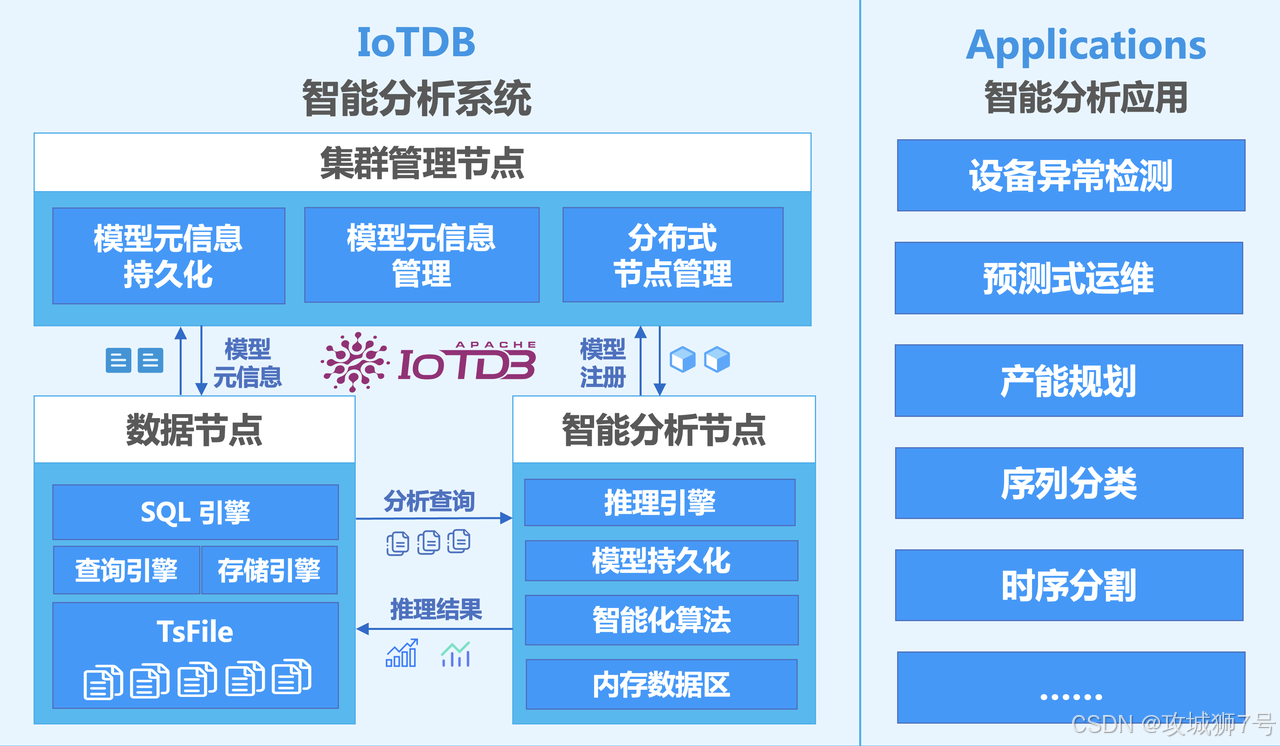
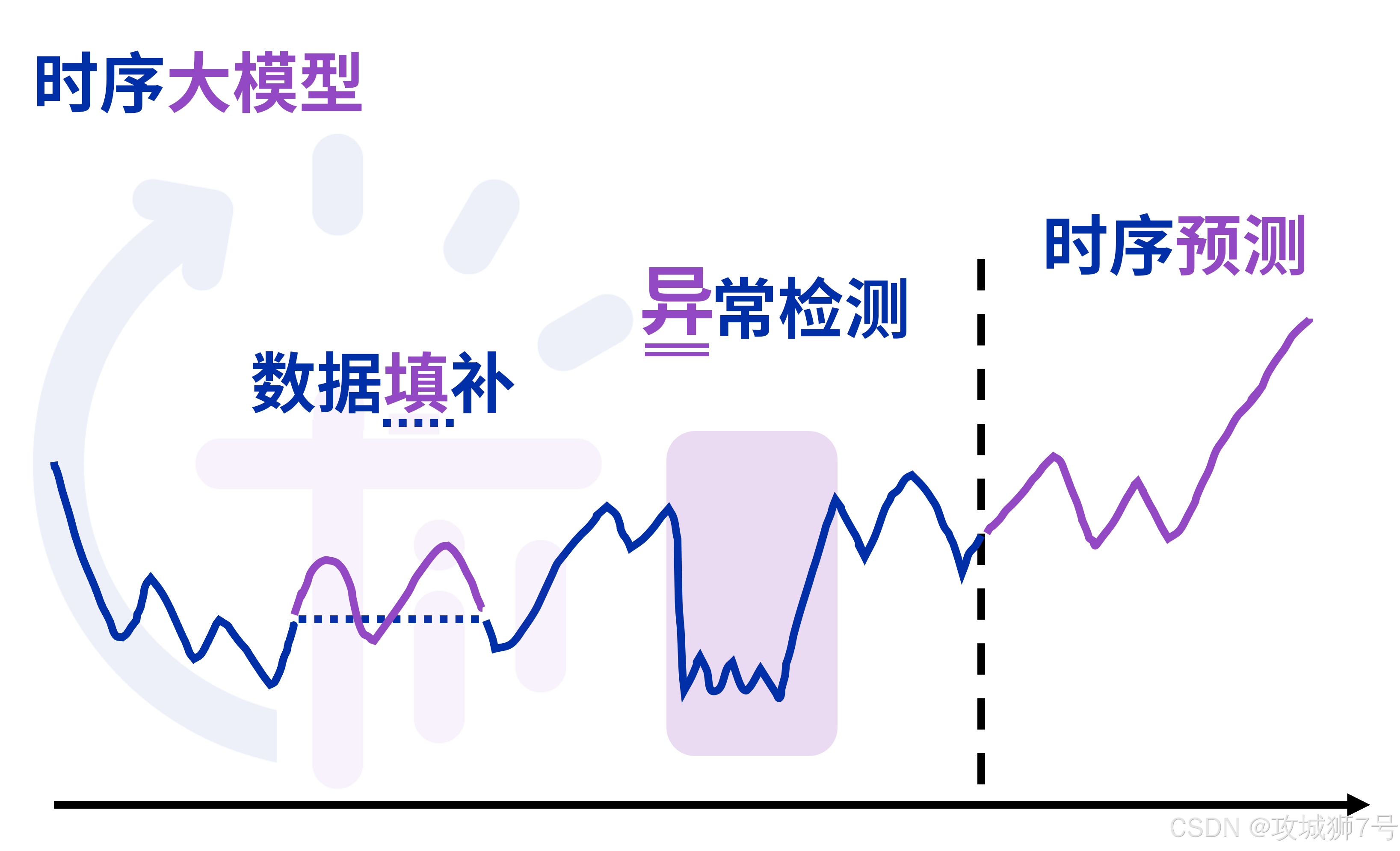
(1)超越MCP:除了支持MCP协议让LLM能用自然语言查询数据,IoTDB更进一步。
(2)内置AINode:你可以将训练好的时序模型(如清华自研的Timer-XL)部署在AINode中。
(3)SQL调用AI:最酷的是,你可以直接用SQL来调用这些模型进行预测或异常检测!
-- 使用内置的时序大模型,预测未来24个点的温度SELECT PREDICT(temperature, 24) FROM root.factory.workshop1.device01这种设计,让AI从一个外部工具,变成了数据库的原生能力,极大地简化了AI应用的开发和部署。
4.2 大数据生态与查询语言
(1)作为Apache基金会的顶级项目,IoTDB 与 Spark、Flink、Hadoop 等大数据生态无缝集成,提供了原生Connector,方便构建“采-存-算-用”一体化的数据平台。
(2)IoTDB 和 QuestDB 都提供了对开发者最友好的类 SQL 查询语言,学习成本极低。而 InfluxDB 的 Flux 语言功能强大,但也需要专门的学习过程。
结论:2025年,你的场景该如何选型?
如果你的战场在工业互联网、车联网、智慧能源等领域,面临着海量设备、长期存储、边云协同和高昂成本的挑战,那么 Apache IoTDB 无疑是你的首选。它在架构、成本、生态和AI集成上的体系化优势,是专门为应对这些挑战而设计的。
如果你的核心诉-求是极致的写入性能和数据导入速度,并且业务以标准SQL查询为主,特别是在金融高频交易或日志分析场景,那么 QuestDB 的性能优势会非常突出。
如果你需要快速启动一个中小型监控或通用IoT项目,希望拥有成熟的社区和丰富的第三方工具支持,InfluxDB 依然是一个强大而稳健的“万金油”选项。
时序数据库的选型没有“银弹”,但通过理解不同产品背后的设计哲学,我们可以找到最匹配自己业务需求的那一把“钥匙”。
> 👉 下载 Apache IoTDB 开源版体验:`https://iotdb.apache.org/zh/Download/`
> 👉 企业级支持与更强功能: `https://timecho.com`
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!