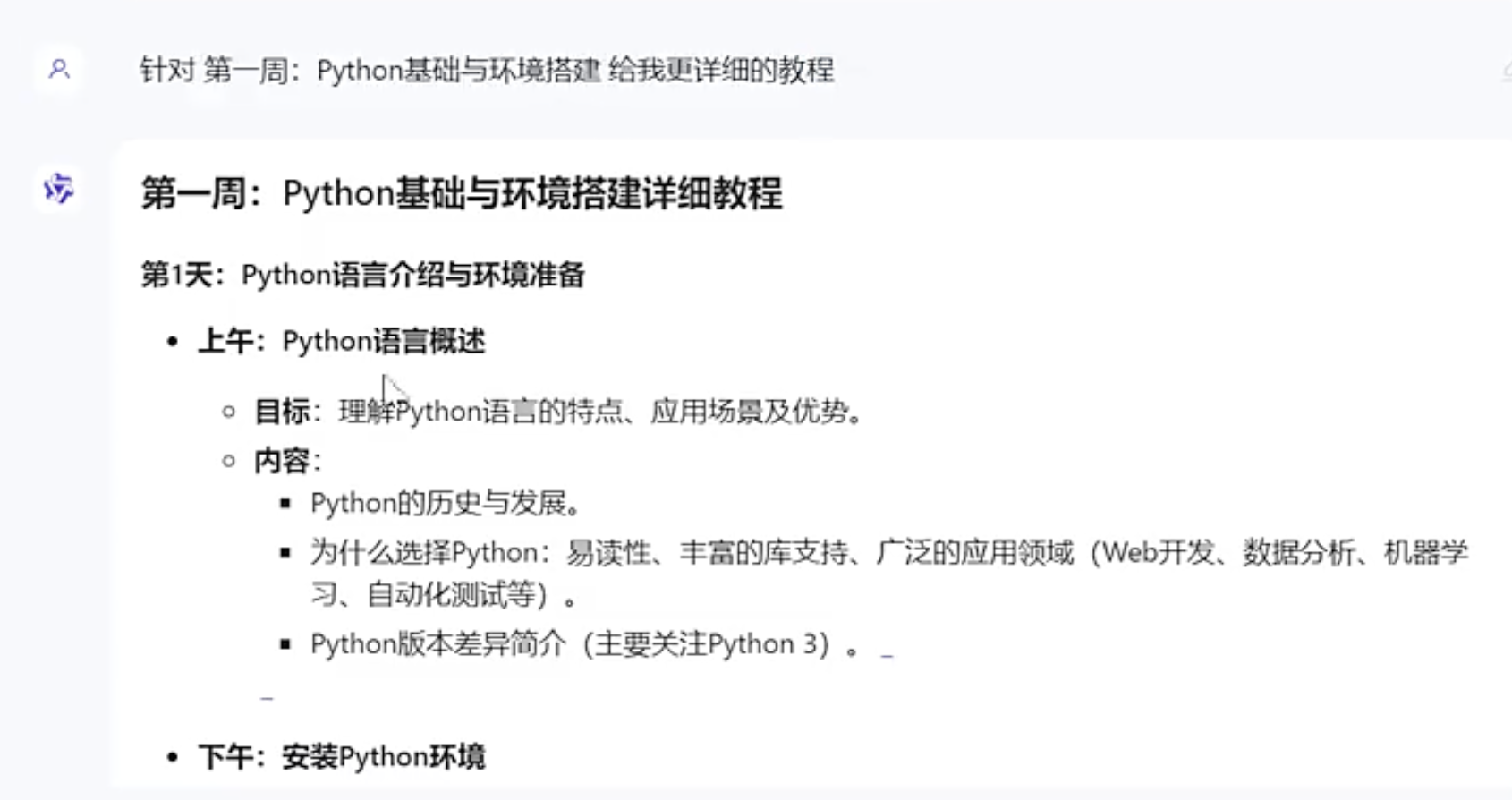
【P01_AI测试开发课程-导论】
一、前言
chatgpt刚流行时,是通过与AI对话模式,进行辅助提效
当下,则是结合AI做AI的应用开发(不去开发AI,只是使用)
本地运行大模型,对电脑配置要求:8G内存以上,4G独立显卡。或者是租云服务去部署大模型,几块钱一小时。大模型的开发,需要GPU、CPU、内存这些,几百万的硬件设备
二、概念介绍-模型-训练-微调
模型:算法+数据
大模型:很多算法+很多数据
三、AI大模型的必知必会术语
知识蒸馏:KD:基于已经训练好的模型,进行二次开发训练,这就是知识蒸馏
大语言模型:LLM:理解和生成人类自然语言
大性视觉模型:LVM:基于图片和视频等非文字类的处理,由计算机去理解和生成人类通过视觉上能看到的东西
多态大语言模型:MLLM:既能处理文本,也能处理语音、图片、视频等,多合一的推理能力
参数量:模型中的可训练变量,这些变量决定了模型的行为和性能。参数量是衡量模型规模的重要指标 B是billiom 十亿
Prompt(提示词):人类提供给大模型的文本内容,大模型基于这些提示内容,,推理人类期望的内容
推理(inference):已经训练好的大模型,生成并输出结果的过程
Token: 通常指文本或数据中的一个基本单元或符号,就是单词。你、好、世界、!。分解为token更容易被机器理解和处理。大模型处理中,tokenm越多,处理量越大。大模型收费是根据token进行收费的。主要是我们自己输入的内容
大模型幻觉: 大模型生成的内容,看似合理,但是又不准确或者虚构的信息,原因是因为尽管大模型可以生成符合语言结构的文本,但是他们不具备真正理解的能力,只是基于概率生成下一个词语。
四、大模型应用开发
传统应用具备可控性(可预知的),但是AI应用具备不可控性(不可预知性)

五、AI在测试中的应用
六、 AI对话
1、和AI对话,要定位AI的身份是什么,“专家”、“老师”、“朋友”
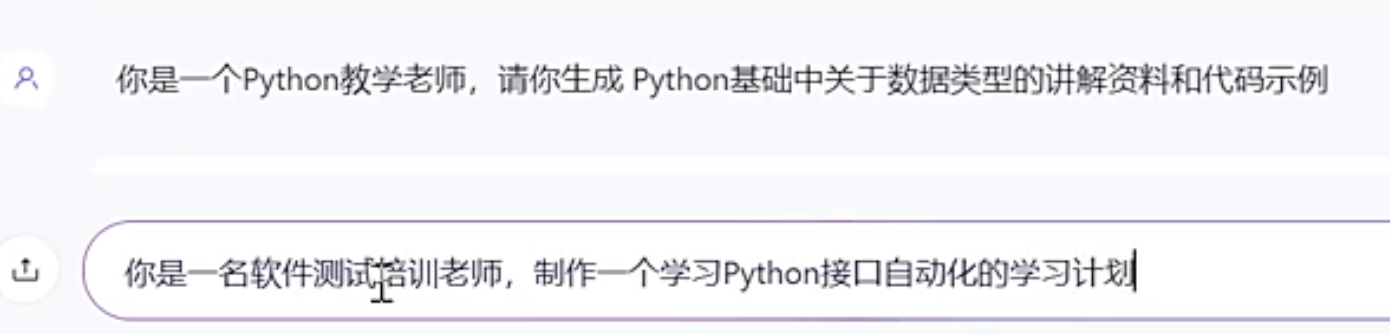
上下文