ViT学习
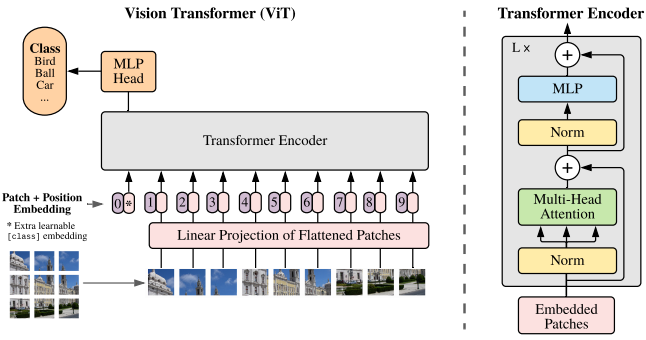
图像块嵌入(Patch Embeddings)
为了将Transformer应用到2D图像中,ViT将图像展平成2D的patches矩阵
,其中H、W分别为图像的height(高)和width(宽),C是原图像通道数,(P,P)是每个图像patch的分辨率,N为图像的patch数
。所以原图转化成了一组一维的patch序列。
的结果可能很大,Transformer不能直接处理高维的向量,因此我们定义一个可训练的权重矩阵
,把每个patch向量
映射到D维空间:
这一步就是Patch Embedding,把每一个patch向量映射到一个固定的维度中。
最终输入给Transformer的就是N个D维向量。整个过程类似于把文本的one-hot encoding映射为固定维度词嵌入的过程。
可学习的分类Token(Class Token)
在得到N个patch向量输入后,Transformer会输出N个向量,这样到底用哪一个来代表整张图像做分类呢?类似于NLP里BERT在句子最前面加一个[CLS]token专门用来承载整句话的语义,在ViT里,我们在patch序列的最前面手动添加一个可学习的嵌入向量。所以输入序列变成:
序列长度变为N+1。
这个一开始是随机初始化的,在自注意力机制中,class token会作为Query,和所有patch的Key/Value交互;它通过注意力权重从所有 patch 中获取信息,并在多层 Transformer 中不断更新,最终成为图像的全局语义表示。
在分类头中,我们便通过这个Class Token做分类任务。
位置嵌入(Position Embeddings)
Transformer的自注意力机制有一个特点:扰动不变性(Permutation-invariant),即如果我们打乱输入序列中token的顺序,self-attention本身不会知道顺序被打乱了。所以在Transformer中采用了固定位置编码。在ViT论文中,提供了四种方案:
1. 无位置嵌入:效果最差
2. 1D位置嵌入(1D-PE):把图像当作一维序列,每个位置分配一个可学习的向量
3. 2D位置嵌入(2D-PE):用图像块的二维坐标 (x,y) 来生成位置向量,更贴近图像的空间结构
4. 相对位置嵌入(RPE):考虑token与token之间相对关系
2/3/4方案效果相差不大,因为patch本身就包含了一部分局部空间结构信息。
Transformer Encoder
详见:Transformer
一个Transformer Encoder Block主要包含一个MSA(多头自注意力层)和一个MLP/FFN(多层感知机/Feed-forward network),MLP/FFN包含两个FC(全连接层)+中间的非线性激活函数GeLU。层内通过残差结构和层归一化层连接。
推理过程
1. 输入图像,划分patch:
2. 通过线性投影层映射到维度为D的嵌入空间,得到patch embedding序列:
每个向量长度为D
3. 加入class token,序列长变为N+1:
4. 加入位置嵌入,默认使用1D绝对位置嵌入:
5. 经过L层Transformer编码器
(1)多头注意力子层(MSA),所有token两两交互(多组权重矩阵):
(2)前馈网络子层(MLP):每个token独立通过两层全连接+GeLU激活:
(3)残差连接+LayerNorm:每个子层前先对输入做LayerNorm,再加上残差
重复L层后,得到最终序列表示
6. 分类
得到多层交互后的class token,此时该向量已融合全图信息,把送入分类头,输出每个类别的概率分布。
归纳偏置(Inductive Bias)与优化
归纳偏置:模型在设计时人为注入的先验知识,帮助它更快或更高效地学习。
CNN有以下特点:
1. 局部性(Locality):卷积核只在局部区域滑动,所以先关注小范围特征
2. 二维邻域结构 (2D neighborhood structure):卷积核在二维空间移动,天然利用了图像的二维网格结构
3. 平移等变性 (translation equivariance):输入图像发生平移,卷积后的特征图也会以同样的方式平移
以上特点使CNN在处理图像时已经帮模型带来了很多图像结构的认识。
而在ViT中唯一和图像局部相关的设计是一开始的patch划分。之后所有空间关系都要依靠训练学习出来。位置嵌入在初始化时也不知道任何2D空间结构,也是依靠训练逐渐学习的。换句话说,ViT几乎完全按照数据来学习图像结构;CNN则在网络结构里就内置了很多图像知识。
为了弥补ViT的归纳偏置不足,可以考虑 CNN+ViT 的混合方式。即不直接把原始图像切成 patch,而是先用CNN提取特征图;然后把CNN的特征图按照ViT的方式做处理。这样,CNN 已经做了局部感知和降采样,减少了 Transformer 的学习负担,同时ViT可以在CNN特征的基础上学习全局依赖。
微调
通常,我们在大型数据集上预训练 ViT,并对 (更小的) 下游任务进行微调。