Linux:malloc背后的实现细节
目录
- 前言
- 一、先搞懂基础:程序的内存布局(关键前提!)
- 二、malloc的核心实现步骤(4层架构拆解)
- 第1层:用户调用 → 标准库处理(glibc的malloc.c)
- 第2层:堆内存池管理(ptmalloc2的核心)
- 关键数据结构:Chunk(内存块)
- 空闲内存管理:Bins(内存池桶)
- 分配过程详解(以小块内存为例):
- 第3层:向操作系统申请内存(系统调用层)
- 第4层:物理内存映射(操作系统视角)
- 三、深度解析:关键问题与优化技巧
- 问题1:内存碎片如何解决?
- 问题2:多线程安全如何实现?
- 问题3:性能瓶颈在哪?
- 四、动手实验:验证malloc行为
- 五、其他malloc实现对比(扩展知识)
- 六、malloc的完整生命周期
前言
作为C/C++中最基础的动态内存分配函数,malloc看似简单(void* malloc(size_t size)),但其背后涉及操作系统、内存管理、性能优化等多层复杂机制。作为新手,理解这些细节能帮你避免内存泄漏、碎片化等常见问题。
历史:glibc 早期基于 dlmalloc,后来引入了 ptmalloc2,增加了多线程支持
一、先搞懂基础:程序的内存布局(关键前提!)
在深入malloc前,必须理解程序运行时的内存布局。一个进程的内存通常分为5个区域:
高地址 |-----------------|| 栈(Stack) | ← 局部变量、函数调用(向下增长)|-----------------|| ... | ← 未分配区域|-----------------|| 堆(Heap) | ← 动态内存分配(向上增长) ← malloc管理的区域|-----------------|| 未初始化数据(BSS)| ← 全局/静态变量(初始为0)|-----------------|| 初始化数据(Data)| ← 全局/静态变量(有初始值)|-----------------|| 代码段(Text) | ← 程序指令
低地址 |-----------------|
- 堆(Heap):
malloc申请的内存就来自这里。堆的顶部由brk指针标记,操作系统通过brk/sbrk系统调用移动该指针来扩展堆。- 主线程的堆(main arena)通常来自
brk。 - 其他线程的堆(thread arena)通常来自
mmap,不与主线程堆相邻。
- 主线程的堆(main arena)通常来自
- 关键区别:
- 栈内存:自动管理(函数结束自动释放)
- 堆内存:手动管理(需
malloc/free)
✅ 新手提示:
malloc本质是向操作系统申请一块堆内存,并维护这块内存的元数据(大小、状态等)。它不是直接操作物理内存,而是管理操作系统分配的虚拟内存。
二、malloc的核心实现步骤(4层架构拆解)
malloc的实现可分为4层,从用户调用到最终获取物理内存:
第1层:用户调用 → 标准库处理(glibc的malloc.c)
当调用malloc(100)时:
- 对齐处理:
- 内存地址需按系统字长对齐(x86_64通常是16字节对齐)。
- 实际请求大小 =
100 + 对齐填充→ 例如100字节会被调整为112字节(16×7)。
- 大小分类:
- 小块内存(< 128KB):走堆内存池(避免频繁系统调用)
- 大块内存(≥ 128KB):直接用
mmap映射匿名页(避免堆碎片)
// glibc源码简化逻辑(malloc.c)
void* malloc(size_t bytes) {size_t req = bytes;if (req + MALLOC_ALIGN_MASK < req) /* 检查溢出 */ return NULL;req = aligned_size(req); // 对齐处理(如100→112)if (req <= MAX_SMALL_REQUEST) // 小块内存(<128KB)return allocate_from_heap_pool(req);else // 大块内存return mmap_anonymous_page(req);
}
第2层:堆内存池管理(ptmalloc2的核心)
这是malloc最复杂的部分!glibc使用ptmalloc2实现,核心思想是将堆分成多个"内存池",用链表管理空闲块。
关键数据结构:Chunk(内存块)
- 每个内存块(无论空闲/已用)都包含头部(Header),存储元数据:
| 头部 (8/16字节) | 用户数据区 | 末尾 (可选) |-
头部内容(以64位系统为例):
struct malloc_chunk {size_t prev_size; // 前一个chunk的大小(仅当前chunk空闲时有效)size_t size; // 当前chunk大小 + 标志位(最低3位:IS_MMAPPED, NON_MAIN_ARENA, PREV_INUSE)struct malloc_chunk* fd; // 空闲时:指向下一个空闲chunk(用于链表)struct malloc_chunk* bk; // 空闲时:指向前一个空闲chunk };PREV_INUSE(通常值为0x1)- 含义:前一个 chunk 是否正在使用中。
- 如果为
0:表示前一个 chunk 是空闲的(可以在释放时合并)。 - 如果为
1:表示前一个 chunk 已被分配,不可合并。
- 如果为
- 位置:
size & 0x1
🧠 作用:是实现
ptmalloc合并相邻空闲块 的重要机制。当一个 chunk 被释放时,会检查前后邻居,如果它们未被使用,就进行合并,防止内存碎片化。IS_MMAPPED(通常值为0x2)- 含义:当前 chunk 是否由
mmap分配。- 如果为
1:表示 chunk 不是从堆中分配,而是通过mmap单独映射的一段内存。 mmap分配的内存块在释放时不合并也不保留在 Arena 中,而是直接munmap。
- 如果为
- 位置:
size & 0x2
🧠 作用:大块内存请求(如超过
M_MMAP_THRESHOLD,默认 128KB)会直接用mmap,而不是从 Arena 中分配。这样可以减少堆碎片化。NON_MAIN_ARENA(通常值为0x4)- 含义:当前 chunk 是否属于非主 Arena(即线程私有 Arena)。
- 为
1:表示该 chunk 来源于非主 Arena,意味着是在多线程环境下创建的。 - 为
0:表示来自主 Arena(程序默认只有一个主 Arena,用于主线程)。
- 为
- 位置:
size & 0x4
- 含义:前一个 chunk 是否正在使用中。
-
size字段的技巧:
实际大小 =size & ~0x7(清除最低3位标志),例如size=0x71→ 实际大小112字节。
-
空闲内存管理:Bins(内存池桶)
ptmalloc2将空闲chunk按大小分类存储在Bins中,类似"分类垃圾桶":
| Bin类型 | 管理大小范围 | 特点 | 适用场景 |
|---|---|---|---|
| Fast Bins | 16~80字节 | LIFO单链表,不合并空闲块 | 超小对象(如int) |
| Unsorted Bin | 所有大小 | 新释放的chunk先放这里 | 临时中转站 |
| Small Bins | 16~512字节 | 62个双向循环链表(每个大小固定) | 小对象(如struct) |
| Large Bins | >512字节 | 63个双向链表(每个链表管理一个范围) | 大对象(如数组) |
分配过程详解(以小块内存为例):
- 检查Fast Bins:
- 若请求16~80字节,直接从对应Fast Bin的链表头取一个chunk(O(1)时间)。
- Fast Bin不合并空闲块 → 速度快但可能浪费内存。
- 检查Unsorted Bin:
- 若Fast Bin无匹配,遍历Unsorted Bin:
- 若chunk大小正好匹配 → 直接返回
- 若大于请求 → 切割chunk(剩余部分放回Unsorted Bin)
- 若Fast Bin无匹配,遍历Unsorted Bin:
- 检查Small/Large Bins:
- 按大小找到对应Bin,取第一个可用chunk(最佳适应策略)。
- 系统扩容:
- 若所有Bin都无足够内存 → 向操作系统申请新内存(见第3层)。
💡 关键优化:
- 切割(Splitting):若分配的chunk比请求大,剩余部分放回Unsorted Bin。
- 合并(Coalescing):
free时检查相邻chunk是否空闲,合并成大块减少碎片。
第3层:向操作系统申请内存(系统调用层)
当内存池不足时,ptmalloc2通过两种系统调用扩展堆:
| 系统调用 | 原理 | 适用场景 | 特点 |
|---|---|---|---|
sbrk | 移动堆顶指针brk,扩展堆区域 | 小/中等请求(<128KB) | 快,但可能产生外部碎片 |
mmap | 直接映射匿名内存页(不经过堆) | 大请求(≥128KB) | 避免碎片,但系统调用开销大 |
sbrk工作流程:void* new_heap = sbrk(increment); // increment = 新增字节数 if (new_heap == (void*)-1) /* 失败 */ ; // 将新内存划分为chunk,加入Unsorted Bin- 为什么大内存用mmap?
避免堆碎片:mmap分配的内存独立于堆,free时直接munmap归还系统,不会留下碎片。
第4层:物理内存映射(操作系统视角)
- 用户看到的"内存"是虚拟内存,操作系统通过页表映射到物理内存。
- 当首次访问
malloc返回的指针时,触发缺页异常 → 内核分配物理页帧(Page Frame)。 - 写时复制(Copy-on-Write):多个进程共享同一物理页(如fork后),直到写入时才复制。
三、深度解析:关键问题与优化技巧
问题1:内存碎片如何解决?
- 内部碎片:
- 原因:对齐填充 + chunk头部占用(如申请1字节,实际分配16字节)。
- 解决:ptmalloc2对小对象使用Fast Bins(固定大小池),减少浪费。
- 外部碎片:
- 原因:频繁
malloc/free导致空闲内存分散。 - 解决:
- 合并(Coalescing):
free时检查前后chunk是否空闲,合并成大块。 - 内存池(Arenas):多线程下每个线程有独立内存池(避免锁竞争),减少碎片化。
- 合并(Coalescing):
- 原因:频繁
问题2:多线程安全如何实现?
🔀 多线程下的 Arena (竞技场)机制,为了减少锁竞争,ptmalloc2 引入了 多 arena(分配区) 的概念:
-
Main Arena:主线程首次 malloc 时创建。
-
Thread Arena:新线程首次 malloc 时,glibc 会为其分配一个独立的 arena(堆 + 空闲链表)。
-
并发分配:不同线程使用不同 arena 时,可以并行 malloc/free,互不加锁。
-
Arena 数量上限:
- 32 位系统:
2 × CPU 核数 - 64 位系统:
8 × CPU 核数
- 32 位系统:
-
超过上限:新线程会复用已有 arena,需要加锁,可能阻塞等待。
-
Arena 的大小:在 glibc ptmalloc2 中,Arena 并不是一个固定大小的“内存块”,而是一个管理结构 + 若干堆段(heap segment) 的组合。不过,glibc 在创建新的 heap segment 时有一个默认的分配粒度:
-
32 位系统:每个新 heap segment 默认 1 MB
-
64 位系统:每个新 heap segment 默认 64 MB ,所以在64位主机上,你的多线程程序可能并没有申请多少内存,但是top看到的进程虚拟内存占用却很大,即Arena 数量 * 64MB。
注意:这是单个 heap segment 的初始大小,不是整个 Arena 的上限。Arena 可以随着分配需求增长,追加更多 heap segment。
-
如何获取 Arena 大小你可以通过几种方式查看进程中 Arena 的数量和分布:
-
pmap
pmap -x <pid>- 观察
heap段(brk 分配)和以mmap方式分配的匿名映射段(通常是 thread arena)。 - 统计符合 Arena 粒度的段数,就能估算 Arena 数量。
- 观察
-
mallinfo / mallinfo2(glibc 提供的 API)
- 可以查看总分配内存、空闲内存等,但不会直接告诉你 Arena 数量。
- 结合
MALLOC_ARENA_MAX环境变量,可以推测 Arena 的分布。
-
gdb 调试
- 在调试时查看
main_arena和其他malloc_state结构体,可以直接看到 Arena 链表。
- 在调试时查看
-
-
-
malloc 内部如何操作 Arena:glibc 的 malloc 在多线程下的分配流程大致如下:
-
选择 Arena
- 每个线程第一次 malloc 时,会尝试绑定一个空闲的 Arena(
malloc_state)。 - 如果没有空闲 Arena 且未达到
MALLOC_ARENA_MAX限制,就创建一个新的 Arena(通过mmap分配 heap segment)。 - 如果达到上限,就复用已有 Arena,需要加锁。
- 每个线程第一次 malloc 时,会尝试绑定一个空闲的 Arena(
-
Arena 内部分配
- Arena 内部维护多个 bin(空闲块链表),按大小分类:
- fast bins(小块,释放时不立即合并)
- small bins / large bins(按块大小分组)
- unsorted bin(刚释放的块)
- malloc 会先在对应 bin 中找可用块,如果找不到,就从 top chunk(Arena 顶部的空闲区域)切割。
- 如果 top chunk 不够,就扩展 heap segment(
sbrk或mmap)。
- Arena 内部维护多个 bin(空闲块链表),按大小分类:
-
释放内存
- free 会把块放回对应 bin,有时会触发合并(coalescing)。
- 对于大块(mmap 分配的),free 会直接调用
munmap归还给内核。
-
🔒 线程安全与锁
- 每个 arena 有自己的互斥锁(
mutex),分配/释放时需要锁定该 arena。 - 全局还有一个
list_lock,用于保护 arena 链表的修改。 - 分配流程:
- 线程先看自己是否已有绑定的 arena。
- 如果没有,就在 arena 链表中找一个未加锁的 arena。
- 找不到就阻塞等待,直到有可用的 arena。
🛠 实际行为示例,假设一个进程有 1 主线程 + 2 个工作线程:
- 主线程 malloc:使用 main arena,通过
brk扩展堆。 - 线程 A malloc:glibc 创建一个新的 thread arena,通过
mmap分配 1MB 对齐的堆段。 - 线程 B malloc:同样创建自己的 thread arena。
- 并发分配:A、B、主线程各自操作自己的 arena,无需互相等待。
- arena 用尽:如果线程数超过 arena 上限,就会出现多个线程共享 arena,需要加锁,性能下降。
📊性能与调优
- 优点:多 arena 减少锁竞争,提高多线程 malloc/free 性能。
- 缺点:可能导致内存碎片化,因为每个 arena 都有自己的空闲块。
- 调优手段:
- 环境变量
MALLOC_ARENA_MAX控制 arena 数量。 - 使用
jemalloc、tcmalloc等替代分配器,优化多线程性能。
- 环境变量
多线程下 malloc 的高性能秘诀在于 per-thread arena 机制,它让不同线程在不同堆上并行分配内存,减少锁竞争。但这也带来内存碎片化的风险。理解这一点,对于调优高并发 C/C++ 程序的内存性能非常关键。
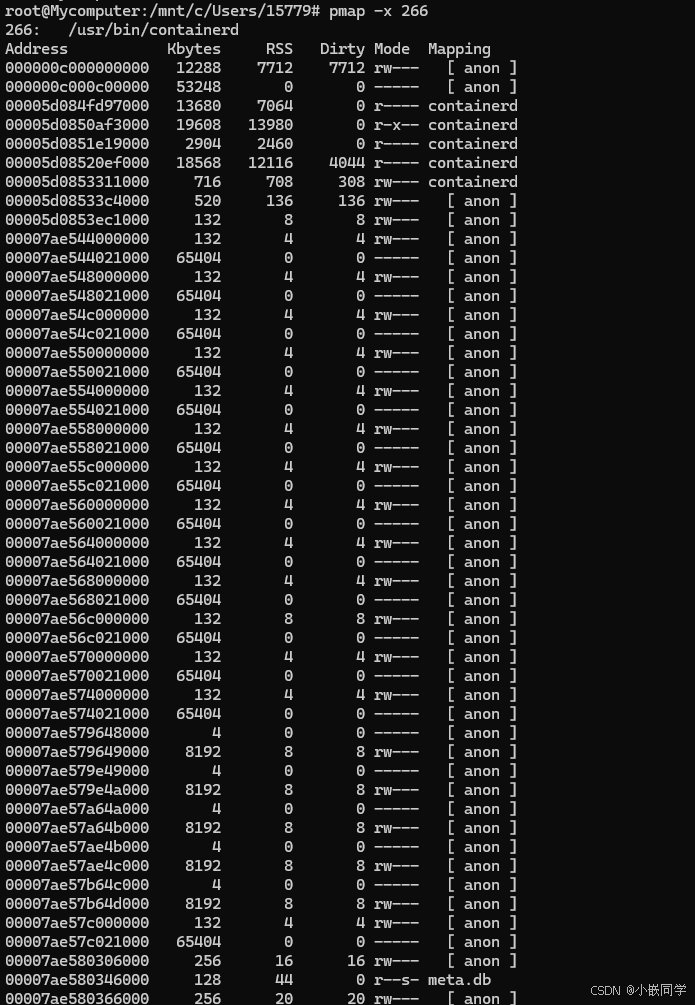
1️⃣ 先看整体结构:pmap -x 输出的每一行是一个虚拟内存映射区(VMA),包括:
- Address:起始虚拟地址
- Kbytes:映射大小
- RSS:实际驻留物理内存(已分配的页)
- Dirty:脏页大小(被写过)
- Mode:权限(r=读,w=写,x=执行,s=共享,-=无)
- Mapping:映射来源(文件名、[anon]、[stack] 等)
2️⃣ 识别 Arena 对应的匿名映射:在 glibc 多线程 malloc 中:
- main_arena(主线程)通常来自
brk扩展的 heap(会显示为[heap],但这里可能被优化掉或合并显示)。 - thread_arena(其他线程)通常通过
mmap分配匿名内存段([ anon ]),大小接近 64MB(64 位系统默认 heap segment 粒度)。
在你的输出中,这些模式很明显:
00007ae544000000 132 4 4 rw--- [ anon ]
00007ae544021000 65404 0 0 ----- [ anon ]
- 第一行 132 KB 可读写(rw—),紧接着一大段 65404 KB(约 63.9 MB)不可访问(-----)。
- 这对组合就是一个 Arena 的 heap segment:前面 132 KB 是已映射的堆头部(包含 Arena header、bins、已分配 chunk),后面 64MB 预留但未映射(延迟分配,按需触发缺页)。
你会发现这种 132K + 65404K 的组合重复出现多次(00007ae548000000、00007ae54c000000、00007ae550000000…),说明这个进程有多个 thread_arena。
3️⃣ 为什么是 132K?
- 132 KB ≈ 128 KB + 一点元数据空间。
- 这是 glibc 在新建 heap segment 时的初始映射量(只映射一小部分,后续按需映射更多页)。
- 64MB 是整个 heap segment 的保留虚拟地址空间(mmap 预留,但不立即分配物理页)。
4️⃣ 结合 Arena 机制理解
- 每个线程第一次 malloc 时,如果没有绑定 Arena,就会创建一个新的 Arena(通过 mmap 分配一个 heap segment)。
- 你的输出中有十几个这样的 64MB 区域,说明 containerd 进程里有很多线程各自持有 Arena。
- 这些 Arena 内部会有 fast bins / small bins / large bins / unsorted bin 等结构,管理该 Arena 的空闲块。
- 当线程 malloc 时,会优先在自己绑定的 Arena 中找空闲块,减少锁竞争。
5️⃣ 其他值得注意的映射
- 很多
8192K、8448K、8704K的[ anon ]段,可能是 mmap 分配的大对象(≥128KB)或其他缓存区。 .so文件(libc.so.6、ld-linux-x86-64.so.2)是共享库映射。[ stack ]是线程栈。meta.db是一个内存映射文件(r–s- 表示只读共享映射)。
6️⃣ 总结: pmap 输出里
- 132K + 65404K 的成对
[ anon ]段 = glibc thread_arena 的 heap segment(64MB 粒度)。 - 出现多次 → 多线程 + 多 Arena。
- 这正是我们之前说的 per-thread arena 机制的直接证据。
- Arena 内部再细分为 fast bins / unsorted bin / small bins / large bins,malloc/free 都在这些结构里操作。
问题3:性能瓶颈在哪?
| 操作 | 时间复杂度 | 优化手段 |
|---|---|---|
| 小内存分配 | O(1) | Fast Bins + 线程私有Arena |
| 大内存分配 | O(n) | Large Bins + mmap直接映射 |
| 内存释放 | O(1)~O(n) | 延迟合并(放入Unsorted Bin) |
| 首次分配 | O(n) | 预分配内存池(避免频繁系统调用) |
⚡ 性能对比:
- Fast Bin分配:~5ns(L1缓存速度)
- Large Bin分配:~50ns(需遍历链表)
mmap分配:~1000ns(系统调用开销)
四、动手实验:验证malloc行为
观察chunk头部(Linux环境)
#include <malloc.h>
#include <stdio.h>int main() {void* p = malloc(100); // 申请100字节size_t* header = (size_t*)((char*)p - 2*sizeof(size_t));printf("Chunk size: 0x%zx (实际大小: %zu)\n", header[1], header[1] & ~0x7);free(p);return 0;
}
输出示例:
Chunk size: 0x71 (实际大小: 112)
→ 100字节被对齐为112字节(16×7),0x71的二进制...01110001中最低3位001表示PREV_INUSE=1。
五、其他malloc实现对比(扩展知识)
| 实现 | 特点 | 适用场景 |
|---|---|---|
| ptmalloc2 | glibc默认,多线程支持好 | 通用Linux应用 |
| jemalloc | 降低碎片化(Facebook用),多级缓存 | 高并发服务(如Redis) |
| tcmalloc | 超低延迟(Google用),线程缓存+中心堆 | 高性能服务器(如MySQL) |
| mimalloc | 新一代设计,低碎片+低延迟 | 嵌入式/实时系统 |
✅ 新手建议:
- 优先用glibc的
malloc(足够通用)- 遇到性能问题再考虑jemalloc/tcmalloc(需重新编译程序)
六、malloc的完整生命周期
💡 核心思想:
malloc是内存资源的"银行"——它向操作系统"批发"内存,再"零售"给用户,通过精细化的分类管理(Bins)和优化策略(对齐、合并、线程池)平衡速度与空间效率。