【论文阅读】自我进化的AI智能体综述
论文链接:https://arxiv.org/pdf/2508.07407
【AI 进化新物种:自演化智能体正在诞生】
还在手动调 Prompt?新一代 AI 已经“自己升级自己”!格拉斯哥等 8 所顶尖高校联合发布的《自演化 AI 智能体全景综述》透露:AI 正从“训练完就冻结”的 MOP 时代,走向终身成长的 MASE 时代——像生物一样在环境中持续变异、适应、变强。
作者提出“自演化三定律”:①安全第一,任何升级不破坏稳定;②性能不减,新技能必须≥旧能力;③自主进化,无需人类写死规则。基于这一框架,他们系统梳理了 200+ 前沿研究:单智能体如何自己改 Prompt、优化记忆、甚至“发明”工具;多智能体怎样像公司一样自动重组架构、精简沟通;医疗、金融、编程等垂直场景又为何需要“专属进化策略”。
更重磅的是,团队开源了首个 MASE 框架 EvoAgentX,把“写代码→跑任务→给反馈→再进化”全过程打包成一条命令,开发者只需准备需求,智能体便会夜以继日地自我迭代。
报告也拉响警报:自演化带来失控、滥用的风险,亟需动态审计与法规配套。未来,AI 将不再只是“工具”,而是能“活、学、长”的数字生命。
自我进化的AI智能体综述
连接基础模型和终身智能体系统的新范式
金源方*1,彭艳文*2,张希*1,王英旭3,易新浩1,张贵斌4,许怡5,吴斌6,刘思伟7,李子豪1,任兆春8,Nikos Aletras2,王希2,周汉5,孟再桥1
1格拉斯哥大学,2谢菲尔德大学,3阿联酋人工智能大学,4新加坡国立大学,5剑桥大学,伦敦大学学院,7阿伯丁大学,8莱顿大学
*同等贡献者,通讯作者
大型语言模型(LLM)的最新进展引发了人们对能够解决复杂现实世界任务的AI智能体的兴趣。然而,大多数现有的智能体系统依赖于部署后保持静态的手工配置,限制了它们适应动态和演变环境的能力。为了解决这一局限性,最近的研究探索了智能体进化技术,旨在根据交互数据和环境影响自动增强智能体系统。这一新兴方向为自我进化的AI智能体奠定了基础,它们连接了基础模型的静态能力与终身智能体系统所需的持续适应性。在本调查中,我们全面回顾了自我进化智能体系统的现有技术。具体来说,我们首先介绍了一个统一的框架,该框架抽象了自我进化智能体系统设计背后的反馈循环。该框架突出了四个关键组件:系统输入,智能体系统,环境,和优化器,作为理解和比较不同策略的基础。基于这个框架,我们系统地回顾了一系列针对智能体系统不同组件的自我进化技术,包括基础模型、智能体提示、内存、工具、工作流程以及智能体之间的通信机制。我们还研究了为生物医学、编程和金融等专门领域开发的特定领域进化策略,在这些领域,智能体行为和优化目标与领域约束紧密耦合。此外,我们专门讨论了自我进化智能体系统的评估、安全和伦理考虑,这对于确保其有效性和可靠性至关重要。本调查旨在为研究人员和从业者提供对自我进化AI智能体的系统理解,为开发更具适应性、自主性和终身智能体系统奠定基础。
O Github: https://github.com/EvoAgentX/Awesome- Self- Evolving- Agents
1简介
大型语言模型(LLM)的最新进展显著推动了人工智能(AI)的发展。由于在大规模预训练、监督微调和强化学习方面的进展,LLM在规划、推理和自然语言理解(Zhao等人,2023年;Grattafiori等人,2024年;Yang等人,2025a年;Guo等人,2025年)方面表现出色。这些进步激发了人们对基于LLM的智能体(AI智能体的一个子类,其中LLM作为决策/策略模块)的兴趣(Wang等人,2024c年;Luo等人,2025a年),这些是自主系统,它们利用LLM作为核心推理组件,在开放式、现实世界的环境中理解输入、规划行动和生成输出(Wang等人,2024c年;Xi等人,2025年;Luo等人,2025a年)。典型的AI智能体由几个组件组成,使其能够以自主的方式执行复杂、目标导向的任务。基础模型(例如LLM)是核心,负责解释目标、制定计划并执行行动。为了支持这些能力,集成了感知(Shridhar等人,2021年;Zheng等人,2024年)、规划(Yao等人,2023a- b年;Besta等人,2024年)、记忆(Modarressi等人,2023年;Zhong等人,2024年)和工具(Schick等人,2023年;Gou等人,2024年;Liu等人,2025g年)等附加模块,以帮助智能体感知输入、分解任务、保留上下文信息以及与工具交互(Wang等人,2024c年)。
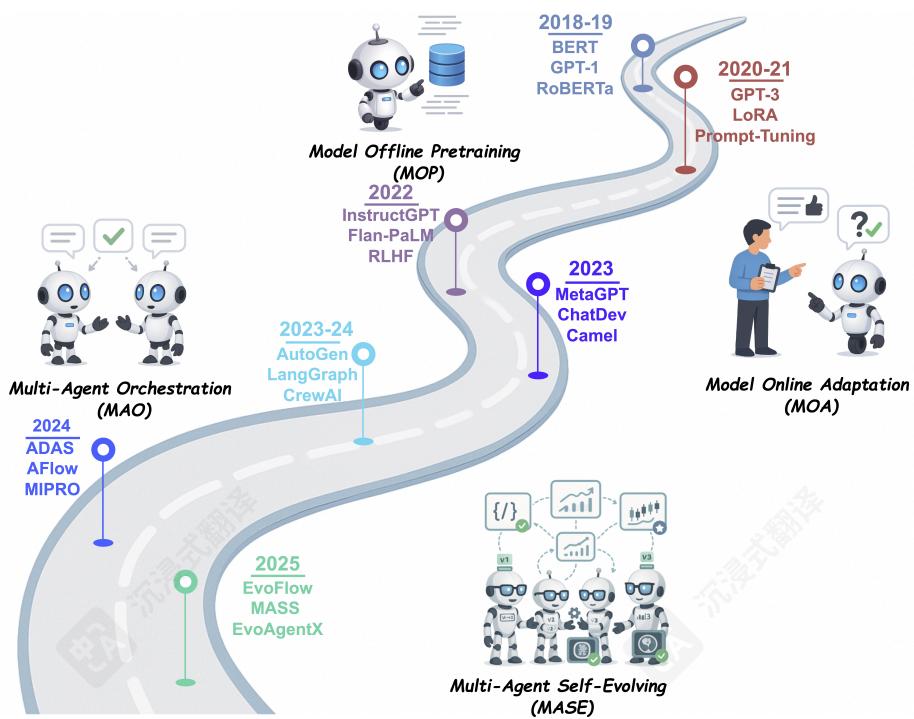
图1 以LLM为中心的学习正在从单纯地从静态数据中学习,发展到与动态环境交互,并最终朝着通过多智能体协作和自我进化实现终身学习方向发展。
虽然单智能体系统在各种任务中表现出强大的泛化和适应性,但它们在动态和复杂环境中往往难以进行任务专业化和协调(Wu等人,2024a年;Qian等人,2024年)。这些限制导致了多智能体系统(MAS)的发展(Hong等人,2024年;Guo等人,2024c年;Zhou等人,2025a年),其中多个智能体合作解决复杂问题。与单智能体系统相比,MAS实现了功能专业化,每个智能体都设计用于特定的子任务或专业领域。此外,智能体可以交互、交换信息并协调其行为以实现共同目标。这种合作使系统能够处理单个智能体能力范围之外的任务,同时模拟更现实、动态和交互的环境。基于LLM的智能体系统已成功应用于广泛的现实世界任务,从代码生成(Jiang等人,2024年)、科学研究(Lu等人,2024a年)、网页导航(Lai等人,2024a年),到生物医学(Kim等人,2024年)和金融(Tian等人,2025年)等特定领域的应用。
尽管智能体系统取得了显著进展,但大多数智能体系统,无论是单智能体还是多智能体,仍然严重依赖手动设计的配置。一旦部署,这些系统通常会保持静态架构和固定功能。然而,现实世界环境是动态且不断演变的,例如用户意图会变化,任务需求会改变,外部工具或信息来源可能会随时间变化。例如,一个用于客户服务的智能体可能需要处理新推出的产品、更新的公司政策或用户不熟悉的意图。类似地,一个科学研究助手可能需要整合新发表算法或集成新型分析工具。在这种情况下,手动重新配置智能体系统既耗时又费力,且难以扩展。
这些挑战推动了近期探索新的范式自我进化AI智能体,这是一种新型智能体系统,能够自主适应和持续自我改进,将基础模型与终身学习智能体系统相结合。
定义
自我进化的AI代理是自主系统,通过与环境交互,持续系统地优化其内部组件,旨在适应不断变化的任务、环境和资源,同时保持安全并提升性能。
受艾萨克·阿西莫夫的机器人三定律1,我们提出了一套指导原则,用于AI代理的安全有效自我进化:
自我进化的AI代理三大定律
I. 忍耐(安全适应)自我进化的AI代理在任何修改过程中必须保持安全和稳定性;II. 卓越(性能保持)根据第一定律,自我进化的AI代理必须保持或提升现有任务性能;III. 进化(自主进化)遵循第一和第二定律,自我进化的AI代理必须能够自主优化“他们在应对变化的任务或环境以及资源的情况下调整内部组件的功能和结构。」
我们将自我进化的AI智能体的出现视为LLM系统发展过程中更广泛范式转变的一部分。这种转变涵盖从早期的模型离线预训练(MOP)和模型在线适应(MOA),到较新的多智能体编排(MAO)趋势,最终到多智能体自我进化(MASE)。如图1和表1所总结的,每个范式都建立在之前的基础上,从静态、冻结的基础模型发展到完全自主、自我进化的智能体系统。
-
MOP(模型离线预训练)。初始阶段专注于在大型静态语料库上预训练基础模型,然后以固定、冻结的状态部署它们,不再进行进一步适配。
-
MOA(在线模型自适应)。基于MOP,本阶段引入了部署后的自适应,其中基础模型可以通过监督微调、低秩适配器(Pfeiffer等人,2021;Hu等人,2022),或人类反馈强化学习(RLHF)(Ouyang等人,2022),使用标签、评分或指令提示进行更新。
-
MAO(多智能体编排)。超越单一基础模型,此阶段协调多个LLM智能体,通过消息交换或辩论提示(LI等人,2024g;张等人,2025h),无需修改底层模型参数即可解决复杂任务。
-
MASE(多智能体自进化)。最后,MASE引入了一个终身自进化循环,其中智能体群体根据环境反馈和元奖励持续优化其提示、记忆、工具使用策略甚至交互模式(Novikov等人,2025;张等人,2025i)。
从MOP到MASE的转变代表了基于LLM系统的开发中的根本性转变,从静态、手动配置的架构转变为能够响应不断变化的需求和环境而进化的自适应、数据驱动系统。自进化AI智能体将基础模型的静态能力与终身智能体系统所需的持续适应性相结合,为更自主、更具弹性和可持续性的AI提供了一条路径。
尽管自我进化的AI代理代表着未来AI系统的一项雄心勃勃的愿景,但实现这一级别的自主性仍然是一个长期目标。当前的系统仍然远未展现出安全、稳健和开放式自我进化的全部所需能力。在实践中,当前向这一愿景的进展是通过代理进化和优化技术实现的,这些技术为使代理系统能够基于交互数据和环境反馈迭代地优化其组件提供了实用手段,从而提高了它们在现实世界任务中的有效性。最近的研究探索了该领域的几个关键方向。一条研究路线专注于增强底层的LLM本身,以改进核心能力,例如规划(Qiao等人,2024年)、推理(Zelikman等人,2022年;Tong等人,2024年)和工具使用(Feng等人,2025a)。另一条研究路线针对代理系统中辅助组件的优化,包括提示(Xu等人,2022年;Prasad等人,2023年;Yang等人,2024a;Wang等人,2025i)、工具(Yuan等人,2025b;Qu等人,2025年),
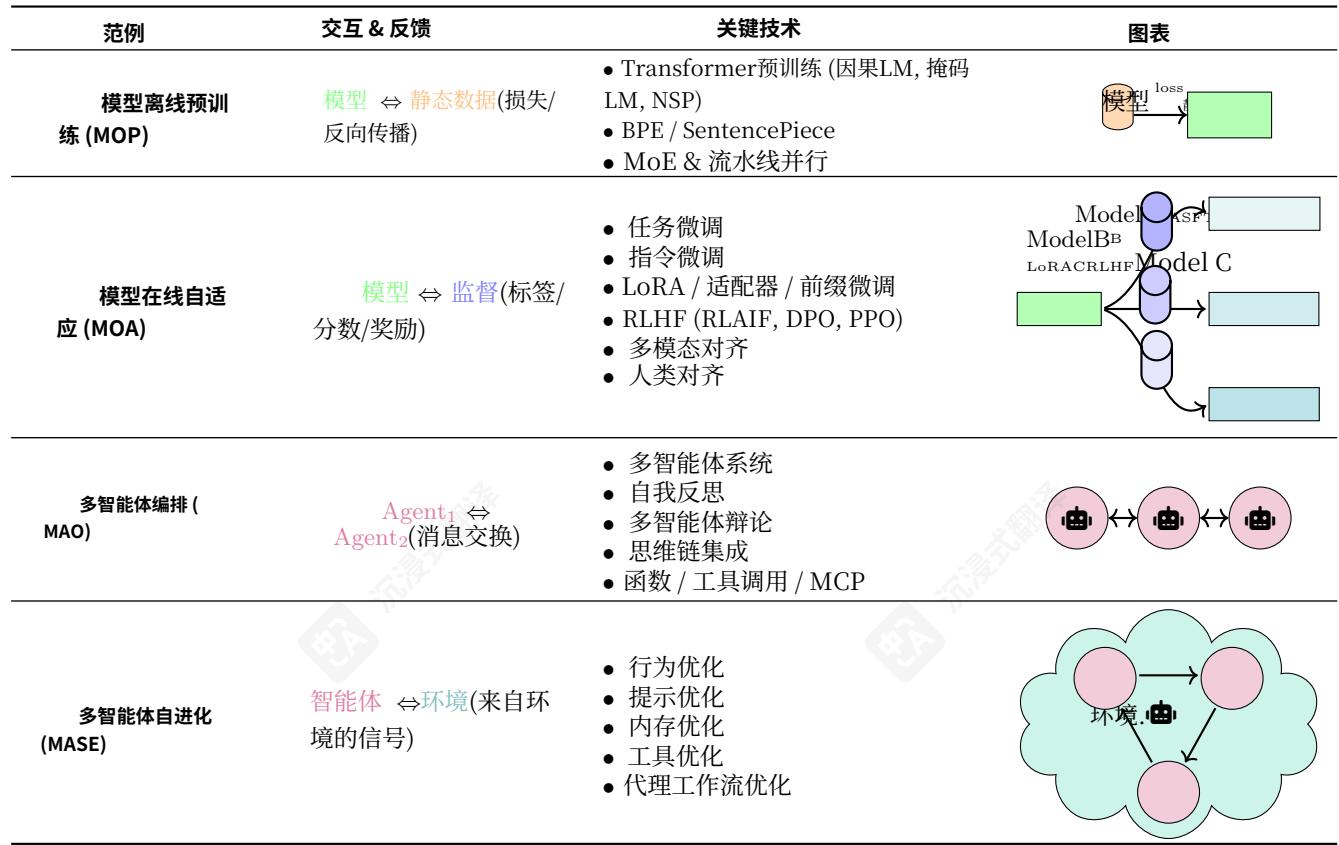
Table1四种以LLM为中心的学习范式比较—模型离线预训练(MOP)、模型在线适应(MOA)、多代理编排(MAO)和多代理自进化(MASE),突出每种范式的交互与反馈机制、核心技术以及说明性图表,以追踪从静态模型训练到动态、自主代理进化的过程。
记忆(Zhong等人。,2024;Lee等人。,2024d),以及等等,允许代理更好地泛化到新任务和动态环境。此外,在多代理系统中,最近的研究调查了代理拓扑和通信协议的优化(Bo等人。,2024;Chen等人。,2025h;Zhang等人。,2025j;Zhou等人。,2025a),旨在识别最适合当前任务的代理结构,并提高代理之间的协调和信息共享。
现有的关于AI代理的调查要么侧重于代理架构和功能的总体介绍(Wang等人,2024c;Guo等人,2024c;Xi等人,2025;Luo等人,2025a;Liu等人,2025a,d),要么针对特定组件,如规划(Huang等人,2024b)、内存(Zhang等人,2024d)、协作机制(Tran等人,2025)和评估(Yehudai等人,2025)。其他调查研究了代理的特定领域应用,如操作系统代理(Hu等人,2025b)和医疗保健代理(Sulis等人,2023)。虽然这些调查为代理系统的各个方面提供了宝贵的见解,但代理自进化和持续适应的最新进展尚未得到充分覆盖,这与代理在终身、自主AI系统开发中的核心能力相对应。这为寻求全面理解支撑自适应和自进化代理系统的新学习范式的研究人员和从业者留下了一个关键空白。
为了弥合这一差距,本调查提供了针对使智能体能够基于交互数据和环境影响进行进化和自我改进的技术的专注和系统性综述。具体而言,我们引入了一个统一的框架,该框架抽象了自进化智能体系统设计背后的反馈循环。该框架确定了四个核心组件:系统输入、智能体系统、环境和优化器,突出了智能体系统的进化循环。基于此框架,我们系统地考察了针对智能体系统不同组件的多种进化和优化技术,包括LLM、提示、内存、工具、工作流拓扑和通信机制。此外,我们还研究了为专业领域开发的特定领域进化策略。此外,我们还专门讨论了自进化智能体系统的评估、安全和伦理考量
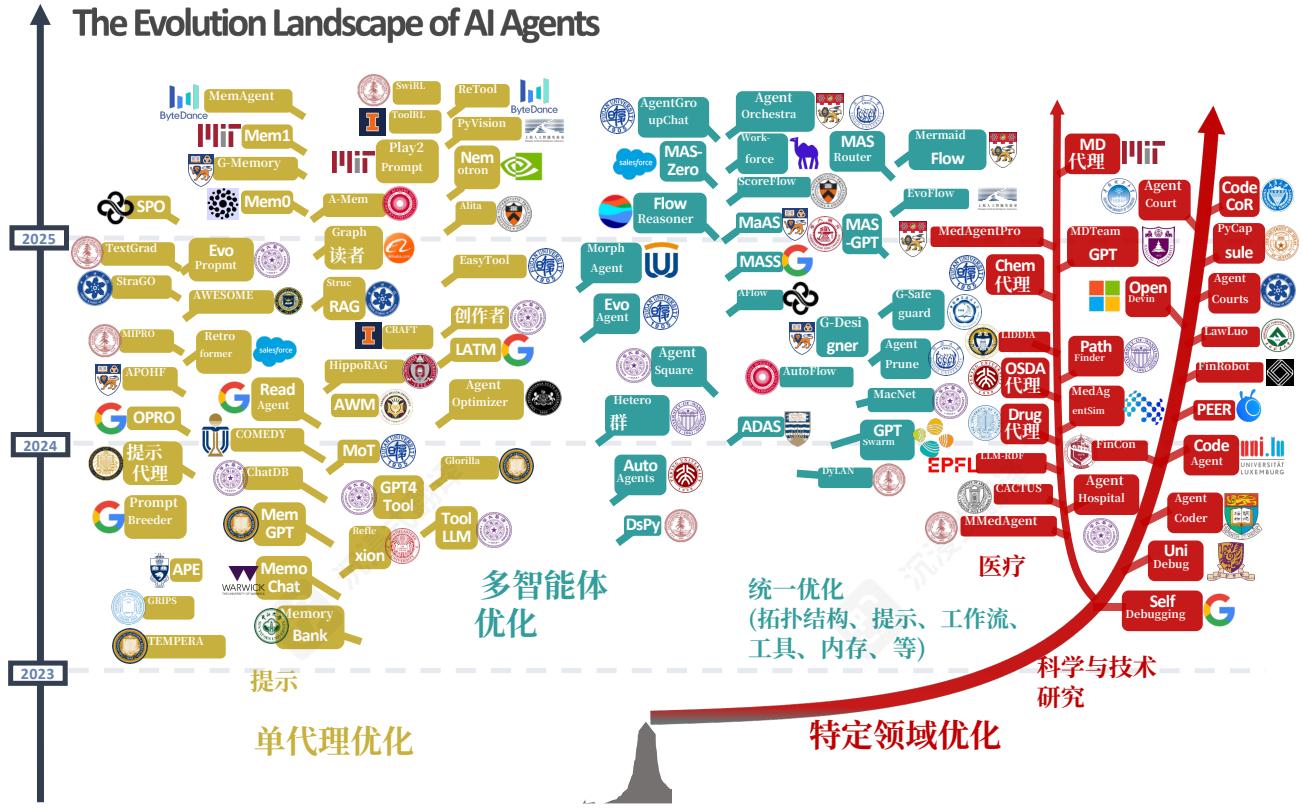
图2 AI代理进化和优化技术的视觉分类法,分为三个主要方向:单代理优化、多代理优化和特定领域优化。树状结构展示了这些方法从2023年到2025年的发展,包括每个分支中的代表性方法。
系统,这些系统对于确保其有效性和可靠性至关重要。作为一项并行工作,Gao等人(2025b)调查了围绕三个基础维度组织的自进化代理:进化什么、何时进化以及如何进化。尽管它们的分类法提供了有价值的见解,但我们的调查旨在提供一个更全面和整合的视角,即统一的框架,关于构建终身自进化代理系统的机制和挑战。
本调查旨在对自进化代理系统的现有技术进行全面和系统的综述,从而为研究人员和从业者提供有关开发更有效和可持续代理系统的宝贵见解和指南。图2展示了单代理、多代理和特定领域优化中现有代理进化策略的视觉分类法,突出了每个方向中的代表性方法。我们的主要贡献如下:
- 我们形式化定义了自我进化的AI代理的三大定律并将以LLM为中心的学习范式从静态预训练映射到完全自主、终身自我进化的代理系统。- 我们引入了一个统一的框架概念,该框架抽象了自我进化代理系统背后的反馈循环,并为系统地理解和比较不同的进化和优化方法提供了基础。- 我们对单代理、多代理和特定领域设置中的现有进化和优化技术进行了系统性综述。- 我们提供了关于自我进化代理系统的评估、安全和伦理考虑的全面综述,强调了它们在确保这些系统的有效性、安全性和负责任部署中的关键作用。- 我们识别了关键开放挑战并概述了有前景的研究方向,旨在促进未来的探索和推进更自适应、自主和自我进化的开发自主系统。
本调查的其余部分按以下方式组织。第2节介绍了人工智能代理和多智能体系统的初步知识,包括它们的定义、关键组件、代表性架构以及自主和自我进化智能体系统的更广泛愿景。第3节介绍了一种统一的智能体进化方法的概念框架,概述了关键要素,如系统输入、进化目标、代理结构和优化器。第4节专注于单智能体系统的优化。它讨论了几个关键方面,如推理策略的优化、提示的制定、记忆机制和工具的使用。第5节专注于多智能体系统,并回顾了优化代理工作流程、拓扑结构和智能体间通信策略的方法。第6节重点介绍了特定领域的智能体优化技术和应用,而第7节讨论了评估智能体系统的评估方法和基准。第8节介绍了智能体进化和优化领域的现有挑战,并概述了一些有前景的未来研究方向。最后,我们在第9节总结本调查。
2人工智能代理系统的基础
为了清晰地理解代理的进化和优化,本节概述了现有的AI代理系统。我们从介绍单代理系统开始,在2.1节中,概述了它们的定义和核心组件。然后,我们在2.2节转向多代理系统(MAS),重点介绍它们的动机、结构范式和协作机制。最后,我们在2.3节提出了终身、自我进化的代理系统的愿景。
2.1人工智能代理
人工智能代理是指能够感知其输入、推理目标并与环境交互以完成任务的自主系统(Luo等人,2025a)。在本节中,我们关注单代理系统,它们是人工智能代理研究的基础。虽然我们的目标在这里只是提供一个简要概述,但读者可以参考现有的综述以获取关于人工智能代理架构和能力的更全面讨论(Guo等人,2024c;AI等人,2025;Luo等人,2025a;Liu等人,2025a)。
一个AI代理通常由多个组件组成,这些组件协同工作以实现自主决策和执行。代理的核心组件是基础模型,最常见的是LLM2,它作为中央推理引擎,负责解释指令、生成计划并产生可操作的响应。此外,还有一些支持模块可以增强代理在复杂和动态环境中的能力:
(1)感知模块。感知模块负责从环境中获取和解释信息(Lietal.,2024f)。这包括处理文本输入、音频信号、视频帧或其他类似感官的数据,以构建适合推理的表示。
(2)规划模块。规划模块使代理能够将复杂任务分解为可操作的子任务或操作序列,并在多个步骤中指导其执行(Huangetal.,2024b)。这个过程促进了分层推理,并确保任务的一致性完成。最简单的规划形式涉及线性任务分解,其中问题被分解为多个中间步骤,而LLM按照这些步骤来解决该问题。这由诸如思维链提示(Weietal.,2022)等方法exemplified。除了静态规划之外,更动态的方法在选代循环中交错规划和执行。例如,ReAct(Yaoetal.,2023b)框架结合了推理和行动,允许代理根据实时反馈修改其计划。除了线性规划之外,一些方法采用分支策略,其中每一步都可能引出多个可能的延续。代表性例子是Tree-of-Thought(Yaoetal.,2023a)和Graph-of-Thought(Bestaetal.,2024),这些方法使代理能够探索多个推理路径。
(3)内存模块。内存模块使智能体能够保持和回忆过去的经验,从而实现情境感知推理和长期一致性。广义上,记忆可以分为短期记忆和长期记忆。短期记忆通常存储在交互过程中生成的上下文和交互。
当前任务的执行。一旦任务完成,短期记忆将被清除。相比之下,长期记忆会持续存在,并可能存储积累的知识、过去的经验或跨任务的可重用信息。为了访问相关的长期记忆,许多智能体系统采用检索增强生成(RAG)模块(张等人,2024d),其中智能体从内存中检索相关信息,并将其整合到LLM的输入上下文中。设计一个有效的内存模块涉及多个挑战,包括如何构建内存表示、何时以及存储什么、如何高效地检索相关信息以及如何将其整合到推理过程中曾等人(2024a)。关于AI智能体中内存机制的更全面综述,我们建议读者参考张等人(2024d)的调查。
(4)工具使用。使用外部工具的能力是AI代理在现实场景中有效运行的关键因素。虽然大型语言模型在语言理解和生成方面功能强大,但它们的能力本质上受限于静态知识和推理能力。通过使用外部工具,代理可以扩展其功能范围,使其能够更好地与现实世界环境交互。典型工具包括网络搜索引擎(Li等人。,2025g),代码解释器或执行环境(Islam等人。,2024),以及浏览器自动化框架(Muller和Zunič,2024)。工具使用组件的设计通常涉及选择工具、构建特定于工具的输入、调用API调用,并将工具输出集成回推理过程。
2.2多智能体系统
虽然单智能体系统在各种任务中已展现出强大的能力,但许多现实世界的任务需要专业化和协调,这些需求超出了单个智能体的能力范围。这一局限性推动了多智能体系统(MAS)的发展,后者模拟了生物和社会系统中存在的分布式智能。
MAS是正式定义为在共享环境中交互的自主代理集合,以实现单个代理能力范围之外的目标。与仅依赖个体推理和能力的单代理系统不同,MAS通过不同代理之间的结构化协调和协作来聚焦于实现集体智能(Tran等人,2025)。实现这种协调的一个基本机制是代理拓扑的概念,即定义代理如何在系统中连接和通信的结构配置。拓扑决定了代理之间的信息流和协作策略,直接影响任务的分配和执行。因此,MAS通常实现为一个多代理工作流,其中系统的拓扑编排代理之间的交互以完成复杂、共享的目标。关键洞察在于,当多个代理通过此类工作流协作时,系统的整体性能可以超过系统内所有代理个体能力的总和(Lin等人,2025;Luo等人,2025a)。
MAS相比于单智能体系统具有几个显著的优点。首先,MAS可以将复杂任务分解为可管理的子任务,并将其分配给专门的智能体,这有助于提高整体性能(Krishnan,2025;Sarkar和Sarkar,2025)。这种方法类似于人类的组织协作,使MAS能够处理单个智能体能力范围之外的任务。其次,MAS支持并行执行,允许多个智能体同时工作以完成任务。此功能对于时间敏感的应用特别有利,因为它大大加速了问题解决过程(Zhang等人,2025k;Liu等人,2025a;Li等人,2025h)。第三,MAS的去中心化特性增强了鲁棒性:当一个智能体失败时,其他智能体可以动态重新分配任务并弥补故障,确保优雅降级而不是系统完全崩溃(Huang等人,2024a;Yang等人,2025b)。第四,MAS提供了内在的可扩展性,因为新的智能体可以无缝集成,而无需重新设计整个系统(Han等人,2024;Chen等人,2025g)。最后,辩论和迭代改进等协作机制使MAS能够通过利用智能体之间的不同观点和批判性评估来生成更具创新性和可靠性的解决方案(Guo等人,2024c;Lin等人,2025)。CAMEL和AutoGen等框架通过提供模块化架构、角色扮演模式和自动化编排功能进一步简化了MAS的开发,从而减少了工程开销(Li等人,2023a;Wu等人,2024a)。
2.2.1系统架构
MAS的架构设计从根本上决定了智能体如何组织、协调和执行任务。这些结构范围从严格的等级制度到灵活的点对点网络,每种结构都体现了关于控制、自主性和协作的不同哲学。
(1)分层结构。这些系统采用静态分层组织,通常是线性或基于树的,其中任务被明确分解并按顺序分配给特定代理。例如,MetaGPT(Hong等人。,2024)引入标准操作程序(SOPs)来简化软件开发,而HALO(Hou等人。2025)结合了蒙特卡洛树搜索来提高推理性能。这种高度定制化的方法提供了模块化、开发简便和领域特定优化,使其在软件开发、医学、科学研究和社会科学(Zheng等人。,2023b;Park等人。,2023;Qian等人。,2024;Li等人。,2024c;Cheng等人。,2025)中很普遍。
(2)集中式结构。这种架构遵循管理-跟随范式,其中中央代理或高级协调员处理规划、任务分解和委派,而从属代理执行分配的子任务。这种设计有效地平衡了全局规划与特定任务执行(Fourney等人。,2024;Roucher等人。,2025;CAMEL-AI,2025)。然而,中央节点会创建性能瓶颈,并引入单点故障漏洞,从而削弱系统鲁棒性(Ko等人。,2025)。
(3)分布式结构。在这种架构中,智能体作为对等节点在分布式网络中协作,广泛应用于世界模拟应用。缺乏中心控制可防止单点故障——任何节点的损坏都不会使整个系统瘫痪,消除了瓶颈并增强了鲁棒性(Lu等人,2024b;Yang等人,2025b)。然而,这给信息同步、数据安全和协作成本增加带来了挑战(Ko等人,2025)。最近的研究探索了区块链技术来解决这些协调挑战(Geren等人,2024;Yang等人,2025d)。
2.2.2通信机制
MAS的有效性在很大程度上取决于智能体如何交换信息和协调行动。MAS中的通信方法已从简单的消息传递发展到平衡表达性、效率和互操作性的复杂协议。
(1)结构化输出。这种方法采用JSON(Li等人,2024c;Chen等人,2025g),XML(Zhang等人,2025b;Kong等人,2025),和可执行代码(Roucher等人,2025)进行智能体间通信。显式的结构和明确定义的参数确保了高机器可读性和可解释性,而标准化格式促进了跨平台协作(Chen等人,2025g)。这些特性使结构化通信成为需要精确性和效率的应用的理想选择,例如问题解决和推理任务。紧凑的信息表示进一步提高了计算效率(Wang等人,2024h)。
(2)自然语言。自然语言交流保留了丰富的上下文和语义细节,使其特别适合创意任务、世界模拟和创意写作场景(刘等人,2025a)。这种表达性能够实现细致的交互,捕捉微妙的意义和意图。然而,它也带来了包括歧义、潜在的误解以及与结构化格式相比执行效率降低等挑战(郭等人,2024c;杨等人,2025c;孔等人,2025)。
(3)标准化协议。最近的进展引入了专门设计的协议,旨在标准化MAS通信,创建更具包容性和互操作性的智能体生态系统:A2A(LLC和贡献者)通过结构化的点对点任务委托模型标准化横向通信,使智能体能够协作处理复杂、长时间运行的任务,同时保持执行透明度。ANP(张和贡献者)通过具有内置去中心化身份(DID)和动态协议协商的分层架构,为去中心化的“智能体互联网”实现安全、开放的横向通信。MCP(PBC和贡献者)通过统一的客户端-服务器接口标准化单个智能体与外部工具或数据资源之间的纵向通信。Agora(Marro和贡献者)作为横向通信的元协议,使智能体能够动态协商和演变其通信方法,在灵活的自然语言和高效的结构化程序之间无缝切换。
2.3终身化、自我进化的智能体系统愿景
2.3 终身化、自我进化的智能体系统愿景从模型离线预训练(MOP)通过模型在线适应(MOA)和多智能体编排(MAO)的轨迹已稳步降低了基于LLM的系统中的手动配置程度。然而,即使是最先进的多智能体框架今天也常常依赖于手工制作的流程、固定的通信协议和人类策划的工具链(Talebirad和Nadiri,2023;赵等,2024;罗等,2025a;陈等,2025)。这些静态元素限制了适应性,使得智能体难以在动态、开放的环境中长期维持性能,因为需求、资源和目标会随着时间的推移而演变。
多智能体自我进化(MASE)系统的涌现范式通过在部署和持续改进之间形成闭环来解决这些局限性。在一个MASE系统中,一组智能体被配置为能够自主优化它们的提示、记忆、工具使用策略,甚至它们的交互拓扑——在环境反馈和高层次的元奖励(Novikov等人,2025;Zhang等人,2025i)的指导下。这种持续优化过程使智能体不仅能够适应一次,而且能够在其生命周期内根据不断变化的任务、领域和运营约束进行进化。
终身化、自我进化的智能体系统旨在通过将持续改进循环嵌入到架构的核心来克服这些约束。在自我进化人工智能智能体的三大定律——忍耐(安全适应)、卓越(性能保持)和进化(自主优化)——的指导下,这些系统被设计为:
(I)在运行过程中监控自身性能和安全状况;(II)通过受控的增量更新来保留或增强能力;(III)根据不断变化的任务、环境和资源,自主调整提示、记忆结构、工具使用策略,甚至跨代理拓扑结构。
与其要求人类设计师手工设计每一种交互模式,一个终身自我进化的系统可以生成、评估和优化自身的代理配置,从而在环境反馈、元级推理和结构适应之间形成闭环。这使代理从静态执行者转变为持续学习、协同进化的运营生态系统中的参与者。
这一愿景具有深远的影响。在科学发现中,自我进化的代理生态系统可以自动生成假设、设计实验并迭代研究工作流程。在软件工程中,它们可以协同进化开发管道,随着新工具的出现而集成。在人类- AI协作中,它们可以学习个人偏好并持续个性化交互风格。超越数字领域,此类系统可以通过机器人、物联网设备和物理- 数字基础设施与物理世界交互,感知环境变化、采取行动,并将现实世界反馈纳入其进化闭环。通过将代理视为可重构的计算实体,能够自我进化、协调和长期适应,MASE为可扩展、可持续和值得信赖的AI提供了一条路径——这种AI不仅被训练一次,而是能够生存、学习和持久。
3MASE的概念框架
3 MASE 的概念框架为了全面概述自进化智能体系统,我们提出一个高级概念框架,该框架抽象和总结了智能体进化和优化方法设计和实现背后的关键要素。该框架为大多数现有优化方法提供了一个抽象但可推广的视角,从而能够全面理解该领域并促进不同方法之间的比较分析。
3.1自进化过程概述
3.1 自进化过程概述我们首先概述了智能体系统中的自进化过程,在实践中通常通过迭代优化来实现。在这个过程中,智能体系统根据从性能评估和环境交互中获得的反馈信号进行迭代更新。如图3所示,该过程以任务规范开始,这可能包括高级描述、输入数据、上下文信息或具体示例。这些元素构成了系统输入,它们定义了问题
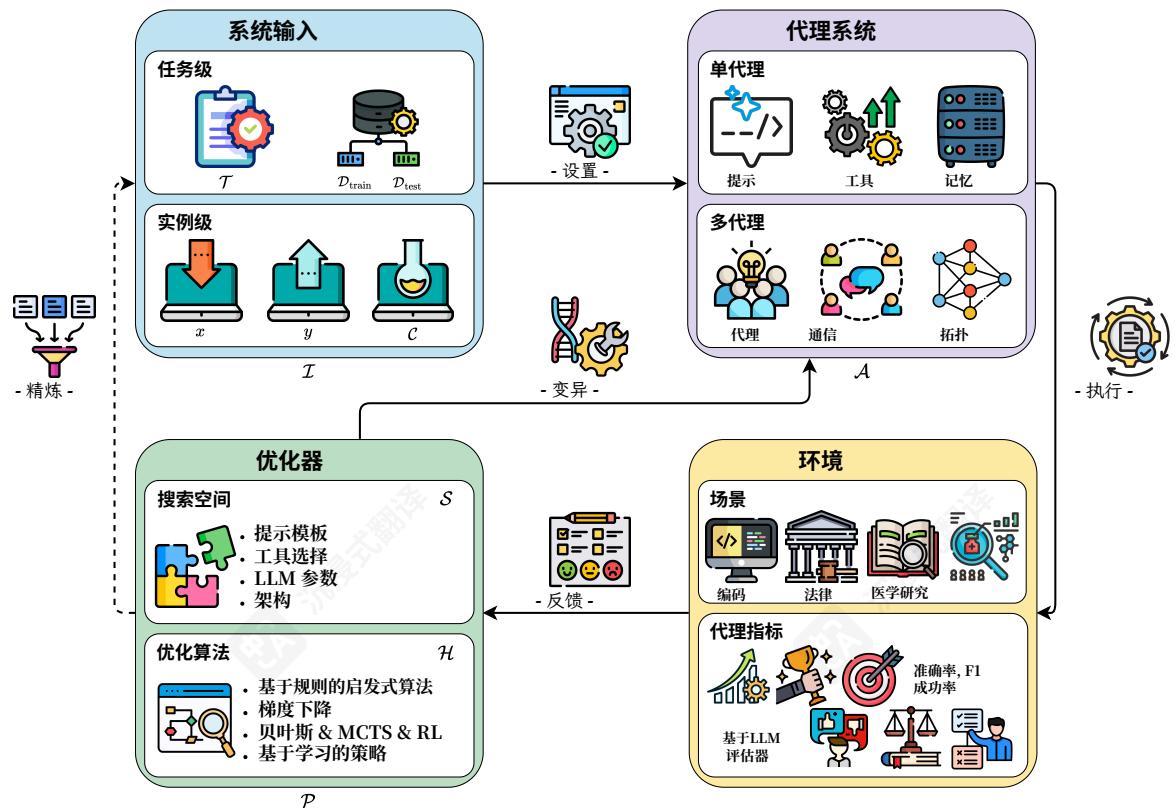
图3 智能体系统中自我进化过程的框架概念。该过程形成一个包含四个组件的迭代优化循环:系统输入、智能体系统、环境和优化器。系统输入定义任务设置(例如,任务级或实例级)。智能体系统(以单智能体或多智能体形式)执行指定任务。环境(根据不同场景)通过代理指标提供反馈。优化器通过定义的搜索空间和优化算法更新智能体系统,直到达到性能目标。
的设置。该智能体系统,无论是遵循单智能体还是多智能体架构,都被部署到环境中。环境提供了操作上下文并生成反馈信号,这些信号来自预定义的评估指标,用于衡量系统的有效性并指导后续优化。基于环境的反馈,优化器应用特定的算法和策略来更新智能体系统,例如调整LLM参数、修改提示或改进系统的结构。在某些情况下,优化器还可以通过合成训练示例来改进系统输入,以增强现有数据集,从而扩展后续优化周期可用的数据。更新后的智能体系统然后被重新部署到环境中,启动下一次迭代。这个过程形成了一个迭代、封闭的反馈循环,其中智能体系统在多次迭代中逐步被精炼和优化。当达到预定义的性能阈值或满足收敛标准时,循环终止。基于MASE的概念框架,EvoAgentX是第一个应用这种自进化智能体过程的开源框架,旨在自动化智能体系统的生成、执行、评估和优化(Wang等人,2025i)。
在上述概述的基础上,智能体优化过程中有四个关键组件:系统输入、智能体系统、环境和优化器。在下文中,我们将介绍每个组件,突出它们在优化框架中的各自作用、特征和交互。
3.2 系统输入
系统输入指的是提供给优化过程的上下文信息和数据。形式上,我们将系统输入的集合表示为 I\mathcal{I}I ,它可能由一个或多个指定任务要求、约束和可用数据的元素组成。这些输入定义了代理系统的问题描述,并确定了优化的范围。根据场景的不同, I\mathcal{I}I 可以采取不同的形式:
-
任务级优化。现有研究中最常见的设置专注于提高代理系统在特定任务上的整体性能。在这种情况下,系统输入 I\mathcal{I}I 可能包括一个任务描述 T\mathcal{T}T 和一个训练数据集 Dtrain\mathcal{D}_{\mathrm{train}}Dtrain 用于训练或验证: I={T,Dtrain}\mathcal{I} = \{\mathcal{T}, \mathcal{D}_{\mathrm{train}}\}I={T,Dtrain} 。还可以包含一个单独的测试数据集 Dtest\mathcal{D}_{\mathrm{test}}Dtest 来评估优化后的代理的性能。在某些场景中,任务特定的标记数据,即 Dtrain\mathcal{D}_{\mathrm{train}}Dtrain ,可能不可用。为了在这样的设置中启用优化,最近的方法(Huang等人,2025;Zhao等人,2025a;Liu等人,2025b)提出动态合成训练示例,通常通过基于LLM的数据生成,以创建一个替代数据集进行迭代改进。
-
实例级优化。近期研究也探索了一种更细粒度的设置,其中目标是提高代理系统在特定示例上的性能(Sun等人,2024a;Novikov等人,2025)。在这种情况下,系统输入可能由一个输入-输出对 (x,y)(x, y)(x,y) ,以及可选的上下文信息 C\mathcal{C}C ,即, I={x,y,C}\mathcal{I} = \{x, y, \mathcal{C}\}I={x,y,C} 。
3.3 代理系统
代理系统是反馈循环中受优化的核心组件。它定义了代理在给定输入下的决策过程和功能。形式上,我们将代理系统表示为 A\mathcal{A}A ,它可能由单个代理或一组协作代理组成。代理系统 A\mathcal{A}A 可以进一步分解为几个组件,例如底层LLM、提示策略、内存模块、工具使用策略等。优化方法可能根据预期范围针对其中一个或多个这些组件。在大多数现有工作中,优化是在 A\mathcal{A}A 的单个组件上进行的,例如微调LLM以增强推理和规划能力(Zelikman等人,2022;Tong等人,2024;Lai等人,2024b),或调整提示并选择合适的工具以提高特定任务的性能,而不修改LLM本身(Yang等人,2024a;Yuan等人,2025b)。此外,近期研究还探索了使用 A\mathcal{A}A 对多个组件进行联合优化。例如,在单代理系统中,一些方法联合优化LLM和提示策略,以更好地使模型行为与任务要求保持一致(Soylu等人,2024)。在多代理系统中,现有研究已经探索了提示和代理间拓扑结构的联合优化,以提高整体效果(Zhang等人,2025j;Zhou等人,2025a)。
3.4 环境
环境是智能体系统运行和生成输出的外部背景
具体而言,智能体系统通过与环境感知其输入、执行动作并接收相应的结果进行交互。根据任务的不同,环境可以是基准数据集,也可以是完整的动态、真实世界环境(Liu et al., 2023a)。例如,在代码生成任务中,环境可能包括编译器、解释器和测试用例等代码执行和验证组件。在科学研究中,它可能由文献数据库、仿真平台或实验室设备组成。
除了提供操作背景外,环境在生成用于告知和指导优化过程的反馈信号方面也起着至关重要的作用。这些信号通常源自量化代理系统有效性的评估指标。在大多数情况下,此类指标是特定于任务的,例如准确率、F1值或成功率,它们为性能提供了定量度量。然而,在缺乏标记数据或真实标签的情况下,通常采用基于LLM的评估器来估计性能(Yehudai等人,2025年)。这些评估器可以通过评估正确性、相关性、连贯性或与任务指令的一致性等方面来生成代理指标或提供文本反馈。关于不同应用中评估策略的更详细讨论,请参见第7节。
3.5 优化器
优化器 (P)(P)(P) 是自进化反馈循环的核心组件,负责根据环境中的性能反馈来优化代理系统 A\mathcal{A}A 。它们的目的是通过专门的算法和策略,搜索在给定评估指标下性能最佳的代理配置。形式上,这可以表示为:
A∗=argmaxA∈SO(A;I),(1) \mathcal{A}^{*} = \underset {\mathcal{A} \in \mathcal{S}}{\arg \max} \mathcal{O}(\mathcal{A}; \mathcal{I}), \tag{1} A∗=A∈SargmaxO(A;I),(1)
其中 SSS 表示配置的搜索空间, O(A;I)∈R\mathcal{O}(A; \mathcal{I}) \in \mathbb{R}O(A;I)∈R 是将 A\mathcal{A}A 在给定系统输入 I\mathcal{I}I 上的性能映射到标量分数的评估函数,而 A∗\mathcal{A}^{*}A∗ 表示最优的代理配置。
优化器通常由两个核心组件定义:(1) 搜索空间 (S)(S)(S) :这定义了可以探索和优化的智能体配置集。 SSS 的粒度取决于受优化的智能体系统的哪些部分,范围从智能体提示或工具选择策略到连续的LLM参数或架构结构。(2) 优化算法 (H)(\mathcal{H})(H) :这指定了用于探索 SSS 并选择或生成候选配置的策略。它可以包括基于规则的启发式算法、梯度下降、贝叶斯优化、蒙特卡洛树搜索(MCTS)、强化学习、进化策略或基于学习的策略。共同,这对 (S,H)(S, \mathcal{H})(S,H) 定义了优化器的行为,并决定了它如何有效地适应智能体系统以获得更好的性能。
在以下部分,我们介绍了三种不同设置中的典型优化器:单智能体系统(第4节),多智能体系统(第5节),和特定领域的智能体系统(第6节)。每种设置都表现出不同的特征和挑战,导致优化器设计和实现的不同
在单智能体优化中,重点是通过调整大型语言模型参数,提示、记忆机制或工具使用策略来提高单个智能体的性能。相比之下,多智能体优化将范围扩展到不仅优化单个智能体,还包括其结构设计、通信协议和协作能力。特定领域的智能体优化提出了额外的挑战,优化器必须考虑特定领域特有的需求和约束,从而导致定制化的优化器设计。图5提供了这些优化设置和代表性方法的全面分层分类。5。
4 单智能体优化
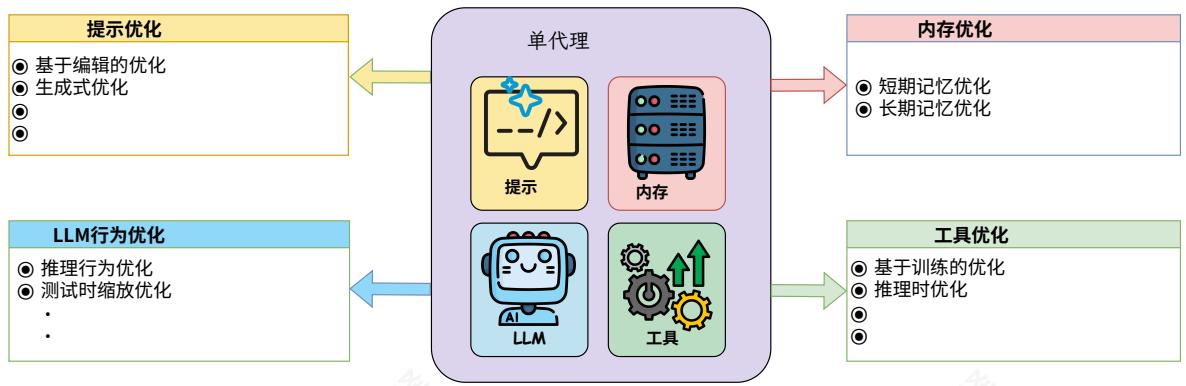
图4 单智能体优化方法概述,按智能体系统中的目标组件分类:提示、记忆和工具。
单智能体优化专注于提高单个智能体系统的性能。根据之前引入的优化反馈循环,关键挑战在于设计用于更新系统的优化器。这涉及识别要优化的智能体系统的特定组件(即搜索空间)、确定要增强的特定能力,并选择适当的优化策略以有效实现这些改进(即优化算法)。
在本节中,我们根据智能体系统中目标组件,组织了单智能体优化方法,因为这决定了搜索空间的结构和优化方法的选择。具体而言,我们关注四个主要类别:(1)LLM行为优化,旨在通过参数调整或测试时扩展技术来提高LLM的推理和规划能力;(2)提示优化,专注于调整提示以引导LLM生成更准确和任务相关的输出;(3)内存优化,旨在增强智能体存储、检索和推理历史信息或外部知识的能力;(4)工具优化,专注于增强智能体有效利用现有工具,或自主创建或配置新工具以完成复杂任务的能力。图4显示了单智能体优化方法的主要类别。
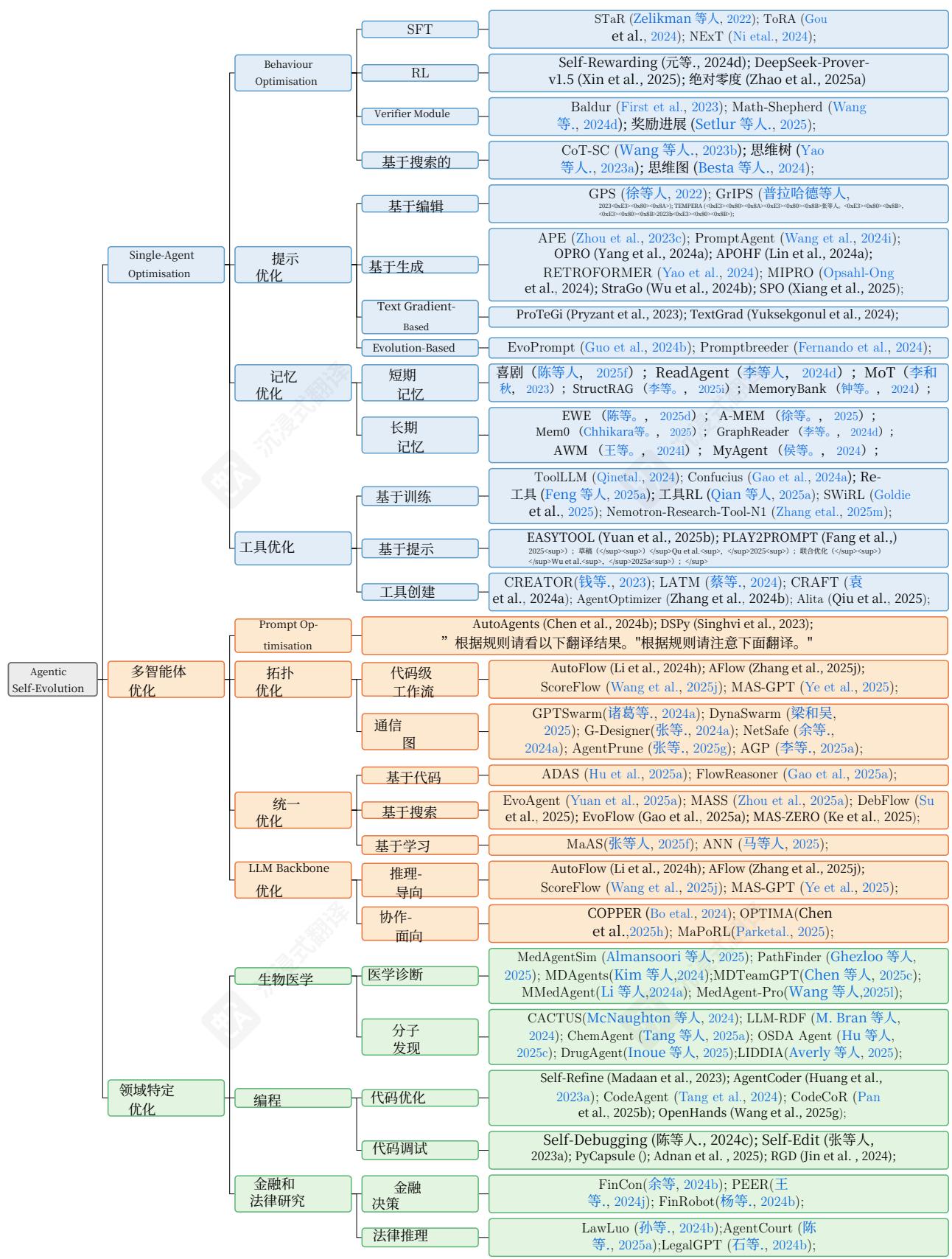
图5一种全面的层次分类法,涵盖单智能体、多智能体和特定领域优化类别,并附有代表性工作的说明。
4.1LLM行为优化
4.1 LLM 行为优化骨干 LLM 为单智能体系统奠定基础,作为负责规划、推理和任务执行的主要组件。因此,增强 LLM 的规划和推理能力是提高智能体系统整体有效性的核心。近期在这一方向上的努力大致分为两类:(1) 基于训练的方法,直接更新模型的参数以提升推理能力和任务性能;(2) 推理时方法,旨在在不修改其参数的情况下改进 LLM 在推理时的行为。在下文中,我们将回顾和总结这两类中的代表性方法。
4.1.1基于训练的行为优化
尽管LLM已展现出强大的语言能力(Zhao等人。,2023),近期研究(Wu等人。,2024c)指出了一个显著差距,即LLM在自然语言流畅性和复杂推理能力之间的差距。这种差异限制了基于LLM的智能体在需要多步推理和复杂决策的任务中的有效性。为解决这一问题,近期工作探索了面向推理的训练方法,使用监督微调(SFT)和强化学习(RL)帮助模型系统地评估和优化其响应。
有监督微调。有监督微调的核心思想是使用包含详细推理步骤的标注数据来训练代理,使模型能够学习从输入问题,通过中间推理过程,到最终答案的完整映射。这种方法通常依赖于精心构建的推理轨迹,这些轨迹通常可以由(1)代理在执行过程中生成的rollout和(2)更强的教师代理产生的演示来构建。通过模仿这些轨迹,代理获得了在结构化方式下进行逐步推理的能力。STaR(Zelikman et al.,2022)提出了一种选代微调程序,其中模型在它正确解决的实例上进行训练,并改进不正确的轨迹以生成更好的轨迹。基于这个想法,NExT(Nietal.,2024)使用通过单元测试正确性过滤的自我生成轨迹来自我进化用于程序修复任务的代理。类似地,Deepseek- Prover(Xinetal.,2024)通过迭代地用验证过的证明来训练策略模型,逐步进化代理,使其能够为定理证明任务生成越来越精确的正式证明。另一条工作路线是在数学(Gouetal.,2024;Yinetal.,2024)和科学(Maetal.,2024)等领域的专有LLM生成的轨迹上有监督地微调代理。除了代理能力之外,Minetal.(2024);Huang et al.(2024c);Labs(2025)基于由OpenAiol(Jaech et al.,2024)生成的轨迹来训练模型,以复制其思考能力,旨在进一步提高代理主干的推理能力。
强化学习。RL将推理视为一个序列决策过程,其中模型因产生正确或高质量的推理路径而获得奖励。其中一种策略是基于偏好的优化,使用从各种来源生成的偏好对(例如测试用例性能、最终结果的正确性或训练好的过程奖励模型(PRMs)的伪标签(Hui等人,2024;Min等人,2024;Jiao等人,2024;Liu等人,2025f)应用DPO(Rafailov等人,2023)。Yuan等人(2024d)进一步介绍了一个自进化框架,其中策略模型使用自己的判断来迭代地改进其推理能力。类似地,AgentQ(Putta等人,2024)结合了MCTS指导搜索和自我批评机制,通过DPO迭代地改进Web环境中代理的决策,利用成功和失败的轨迹。在另一条工作线中,Tulu3(Lambert等人,2024)在数学和指令跟随任务中应用具有可验证奖励的强化学习,而无需任何学习到的奖励模型。值得注意的是,DeepSeek- Rt(Guo等人,2025)进一步证明了在存在真实验证的情况下,纯强化学习的可行性,使用组相对策略优化(Shao等人,2024)。基于这一方向,Xin等人(2025)将这一想法扩展到通过结合来自证明助手反馈的强化学习来增强DeepSeek- Prover。Liu等人(2025e)进一步探索了多模态环境中的自进化训练,通过引入MSTAR(一个利用强化学习克服性能饱和并通过迭代自改进增强推理能力的框架)来实现。除了在固定数据集中使用可验证奖励之外,Absolute Zero(Zhao等人,2025a)训练了一个单一模型,该模型在任务提议者和求解者角色之间交替,通过生成和解决自己的问题进行自进化。类似地,R- Zero(Huang等人,2025)采用了一种双模式框架,其中挑战者生成针对求解者当前能力的定制任务,使两者能够在没有外部监督的情况下迭代地进化。
4.1.2测试时行为优化
随着训练资源变得越来越受限,并且基于API的模型无法进行微调,推理时的计算量(test- time compute)作为解决方案出现了,它通过使模型能够在推理期间改进或扩展其推理能力来解决这些限制而无需额外的训练。通过增加推理预算,模型能够“思考得更久”。
扩展测试时能力可以通过两种主要策略实现。第一种涉及通过结合外部反馈来指导推理,这有助于模型改进其响应。第二种策略侧重于使用更高效的采样算法生成多个候选输出。随后是一个选择过程,其中验证器识别最合适的输出。值得注意的是,这两种方法实际上密切相关。前者用于指导生成的反馈可以自然地作为后者的验证器。
基于反馈的策略。一种自然的方法是根据模型生成输出的质量来调整其行为。该过程通常依赖于验证器的反馈,验证器提供精确或估计的分数来指导模型。我们将反馈分为两种类型。结果级反馈根据最终输出提供一个分数或信号,而不管推理步骤的数量。对于可以轻松访问真实值的任务,验证器可以作为外部工具实现以提供准确的反馈。例如,CodeT(Chen等人,2023)和LEVER(Ni等人,2023)利用编译器执行生成的代码并对照测试用例验证其正确性。START(Li等人,2025c)和CoRT(Li等人,2025b)采用基于提示的工具调用来增强长CoT推理。类似地,Baldur(First等人,2023)利用证明助手的错误消息来进一步修复LLM生成的错误证明。然而,对于大多数任务,真实值在推理时并不总是可用。因此,更通用的方法是为验证器训练一个模型,该验证器为每个候选响应分配分数(Liu等人,2024a,2025c),允许它们根据预测质量进行排序。然而,这种形式的反馈相对稀疏,因为它只评估最终输出。相比之下,步骤级反馈评估生成过程中的每个中间步骤,提供更细粒度的监督。仅依赖结果反馈往往会导致不忠实推理问题(Turpin等人,2023),其中不正确的推理链仍可能导致正确最终答案。为了解决这个问题,最近的工作(Wang等人,2024d;Jiao等人,2024;Setlur等人,2025)越来越关注训练过程奖励模型以检测和纠正推理过程中的错误,通常比使用结果级反馈带来更好的改进。
基于搜索的策略。复杂推理任务通常允许多条有效路径通向正确解。基于搜索的方法利用这一特性,并行探索多个候选推理轨迹,使模型能更好地导航解空间。借助评价模型,已开发出多种搜索策略来指导解码过程。例如,CoT- SC(王等,2023b)采用最佳N中择一方法:它生成多条推理路径,并基于多数投票选择最终答案。DBS(朱等,2024)提出结合步进级反馈使用波束搜索来优化中间推理步骤,而CoRe(朱等,2023)和思维树(姚等,2023a)明确将推理过程建模为树状结构,使用蒙特卡洛树搜索(MCST)在搜索中平衡探索与利用。思维森林(Bi等,2025)进一步推广这一思路,使多棵树能独立决策,并应用稀疏激活机制从最相关的树中过滤和选择输出。除基于树的方法外,其他方法也探索了推理的替代结构形式。思维图(Besta等,2024)将中间思考组织为图中的节点,并应用基于图的操作来支持灵活推理和信息流。思维缓冲(杨等,2024c)引入动态记忆缓冲区在推理过程中存储和实例化元级思考。
4.2提示优化
4.2 提示优化在单代理系统中,提示词在定义代理的目标、行为和特定任务策略方面起着至关重要的作用。它们通常包含指令、说明性演示和上下文信息,以指导底层LLM生成适当的输出。然而,众所周知,LLM对提示词高度敏感;措辞、格式或词序的微小变化都可能导致LLM的行为和输出发生重大变化(Loya等人、2023;Zhou等人、2024b)。这种敏感性使得
设计鲁棒且可推广的AI代理系统变得困难,从而推动了提示词优化技术的开发,以自动搜索高质量的提示词。提示词优化方法可以根据用于导航提示词空间并识别提升模型性能的高质量提示词的策略进行分类。在本节中,我们回顾和总结了四种代表性类别:基于编辑的方法、生成方法、基于文本梯度的方法和进化方法。
4.2.1基于编辑的提示优化
早期的提示优化尝试主要关注基于编辑的方法,这些方法通过预定义的编辑操作迭代地优化人类编写的提示,例如标记插入、删除或替换(Prasad et al.,2023; Pan et al., 2024a; Lu et al., 2024c; Zhang et al.,2023b; Zhou et al., 2023a;Agarwalet al., 2024)。这些方法将提示优化视为在提示空间上的局部搜索问题,旨在逐步提高提示质量,同时保留原始指令的核心语义。例如,GRIPS(Prasad et al.,2023)将指令拆分为短语,并应用短语级别的编辑操作:删除、交换、释义和添加,以逐步提高提示质量。Plum(Pan et al.,2024a)通过结合元启发式策略,如模拟退火、变异和交叉,扩展了GRIPS。TEMPERA(Zhang et al.,2023b)进一步将编辑过程建模为一个强化学习问题,训练一个策略模型以高效地执行不同的编辑技术来构建与查询相关的提示。
4.2.2生成式提示优化
与对提示进行局部修改的编辑式方法不同,生成式方法利用大语言模型(LLMs)迭代生成全新的提示,这些提示基于基础提示和各种优化信号。与局部修改相比,生成式方法可以探索更广泛的提示空间,并产生更多样化且语义丰富的候选者。
提示生成过程通常由各种优化信号驱动,这些信号引导大语言模型(LLMs)生成改进的提示。这些信号可能包括预定义的重写规则(Xu等人,2022;Zhou等人,2024a)、输入- 输出示例(Zhou等人,2023c;Xu等人,2024b)以及数据集或程序描述(Opsahl- Ong等人,2024)。额外的指导可以来自先前的提示及其评估分数(Yang等人,2024a)、指定任务目标和约束的元提示(Ye等人,2023;Hsieh等人,2024;Wang等人,2024i;Xiang等人,2025),以及指示预期变化方向的信号(Fernando等人,2024;Guo等人,2024b;Opsahl- Ong等人,2024)。此外,一些方法还利用成功和失败的示例来突出显示有效的或问题的提示模式(Wu等人,2024b;Yao等人,2024)。例如,ORPO(Yang等人,2024a)通过提示大语言模型(LLMs)使用先前生成的候选者和它们的评估分数来生成新的指令。StraGo(Wu等人,2024b)利用成功和失败案例的见解来识别获得高质量提示的关键因素。优化信号可以进一步集成到高级搜索策略中,例如吉布斯采样(Xu等人,2024b)、蒙特卡洛树搜索(MCTS)(Wang等人,2024i)、贝叶斯优化(Opsahl- Ong等人,2024;Lin等人,2024b;Hu等人,2024;Schneider等人,2025;Wan等人,2025),以及基于神经 bandit的方法(Lin等人,2024b;Shi等人,2024a;Lin等人,2024a)。这些搜索策略能够更高效和可扩展地探索提示空间。例如,PromptAgent(Wang等人,2024i)将提示优化制定为一个战略规划问题,并利用蒙特卡洛树搜索(MCTS)来有效地导航专家级的提示空间。MIPRO(Opsahl- Ong等人,2024)采用贝叶斯优化来高效地搜索指令候选者和少量演示的最佳组合。
虽然大多数生成式方法使用冻结的大型语言模型来生成新提示,但最近的研究探索了使用强化学习来训练一个策略模型用于提示生成(Deng等人,2022;Sun等人,2024a;Yao等人,2024;Wang等人,2025k)。例如,Retroformer(Yao等人,2024)训练一个策略模型,通过总结先前失败案例的根本原因来迭代地优化提示。
4.2.3基于文本梯度的提示优化
除了直接编辑和生成提示外,近期的研究工作探索了使用文本渐变来指导提示优化(Pryzant等人,2023;Yuksekgonul等人,2024;Wang等人,2024;Austin和Chartoek,2024;Yuksekgonul等人,2025;Tang等人,2025;Zhang等人,2025i)。这些方法借鉴了神经网络中的基于梯度的学习,但不是计算模型参数上的数值梯度,而是生成自然语言反馈,称为“文本渐变”,以指导如何更新提示以优化给定目标。一旦获得文本渐变,提示就会根据反馈进行更新。此类方法的关键组件在于文本渐变是如何生成的,以及它们是如何随后用于更新提示的。例如,ProTeGi(Przyzant等人,2023)通过批评当前提示来生成文本渐变。随后,它在梯度的相反语义方向上向一辑提示。这种“梯度下降”步骤由波束搜索和bandit选择过程指导,以及高效地找到最佳提示。类似地,TextGrad(Yuksekgonul等人,2024;Yuksekgonul等人,2025)将这一思想推广到复合AI系统的更广泛框架。它将文本反馈视为一种“自动微分”形式,并使用LLM生成的建议来迭代改进提示。代码或其他符号变量等组件。另一项工作(Zhou等人,2024c)提出了代理符号学习,这是一个以数据为中心的框架。它将语言代理建模为符号网络,并使它们能够通过符号的back- propagation和梯度下降类似物来自主优化它们的提示、工具和工作流程。近期的研究(Wu等人,2025c)还探索了复合AI系统中的提示优化,其目标是在异构组件和参数集上自动优化配置,例如模型参数、提示、模型选择选择和超参数。
模型参数,而是生成自然语言反馈,称为“文本渐变”,以指导如何更新提示以优化给定目标。一旦获得文本渐变,提示就会根据反馈进行更新。此类方法的关键组件在于文本渐变是如何生成的,以及它们是如何随后用于更新提示的。例如,ProTeGi(Pryzant等人,2023)通过批评当前提示来生成文本渐变。随后,它在梯度的相反语义方向上编辑提示。这种“梯度下降”步骤由波束搜索和bandit选择过程指导,以高效地找到最佳提示。类似地,TextGrad(Yuksekgonul等人,2024;Yuksekgonul等人,2025)将这一思想推广到复合AI系统的更广泛框架。它将文本反馈视为一种“自动微分”形式,并使用LLM生成的建议来迭代改进提示、代码或其他符号变量等组件。另一项工作(Zhou等人,2024c)提出了代理符号学习,这是一个以数据为中心的框架,它将语言代理建模为符号网络,并使它们能够通过符号的back- propagation和梯度下降类似物来自主优化它们的提示、工具和工作流程。近期的研究(Wu等人,2025c)还探索了复合AI系统中的提示优化,其目标是在异构组件和参数集上自动优化配置,例如模型参数、提示、模型选择选择和超参数。
4.2.4进化式提示优化
除了上述优化技术之外,进化算法也被探索作为一种灵活且有效的方法用于提示优化(Guo等人,2024b;Fernando等人,2024)。这些方法将提示优化视为一个进化过程,维护一个候选提示的种群,通过突变、交叉和选择等进化算子进行迭代优化。例如,EvoPrompt(Guo等人,2024b)利用了两种广泛使用的进化算法:遗传算法(GA)和差分进化(DE),来指导优化过程以找到高性能的提示。它将核心进化操作,即突变和交叉,适应到提示优化环境中,通过组合两个父提示的片段并引入对特定元素的随机变化来生成新的候选提示。类似地,Promptbreeder(Fernando等人,2024)也迭代地突变任务提示种群以进化这些提示。一个关键特性是其使用突变提示,这些是指定任务提示在突变过程中应如何修改的指令。这些突变提示可以是预定义的,也可以由LLM本身动态生成,从而实现灵活且自适应的机制来指导提示进化。
4.3内存优化
内存对于使智能体能够进行推理、适应并在长时间任务中有效运行至关重要。然而,智能体经常面临由于上下文窗口受限和遗忘而产生的限制,这可能导致上下文漂移和幻觉(刘等人。,2024b;张等人。,2024c,d)。这些限制推动了人们对内存优化的日益关注,以使智能体能够在动态环境中表现出可泛化和一致的行为。在本调查中,我们关注推理时内存策略,这些策略在不修改模型参数的情况下提高了内存利用率。与训练时技术(如微调或知识编辑(曹等人。,2021;米切尔等人。,2022))不同,推理时方法在推理过程中动态决定要保留、检索和丢弃的内容。
我们将现有方法分为两个优化目标:短期记忆,它侧重于在活动上下文中保持连贯性,以及长期记忆,它支持跨会话的持久检索。这种以优化为导向的视角将重点从静态内存格式(例如,内部与外部)转移到动态内存控制,强调内存如何被调度、更新和重用以支持决策。在以下小节中,我们将介绍每个类别中的代表性方法,强调它们对推理保真度和在长时程环境中的有效性的影响。
4.3.1短期记忆优化
短期记忆优化专注于管理LLM工作内存(刘等人,2024b)中有限的上下文信息。这通常包括最近的对话回合、中间推理轨迹以及来自即时上下文的任务相关内容。随着上下文的扩展,内存需求显著增加,使得在固定的上下文窗口中保留所有信息变得不切实际。为了解决这个问题,已经提出了各种技术来压缩、总结或选择性地保留关键信息(张
et al., 2024d; 王等人, 2025d)。常见的策略包括总结、选择性保留、稀疏注意力和动态上下文过滤。例如, 王等人(2025d)提出了递归总结, 以增量地构建紧凑且全面的记忆表示, 从而在整个扩展交互过程中保持一致的响应。MemoChat(陆等人, 2023)维护从对话历史中派生的对话级记忆, 以支持连贯和个性化的交互。COMEDY(陈等人, 2025f)和ReadAgent(李等人, 2024d)进一步将提取或压缩的记忆轨迹纳入生成过程, 允许代理在长时间对话或文档中保持上下文。除了总结之外, 其他方法动态调整上下文或检索中间状态轨迹, 以促进多跳推理。例如, MoT(李和邱, 2023)和StructRAG(李等人, 2025i)检索自生成或结构化记忆来指导中间步骤。MemoryBank(钟等人, 2024),受艾宾浩斯遗忘曲线(Murre和Dros, 2015)的启发, 分层总结事件并根据时效性和相关性更新记忆。Reflexion(Shinn等人, 2023)使代理能够反思任务反馈并存储情景见解, 从而随着时间的推移促进自我改进。
这些方法显著提高了局部一致性和上下文效率。然而, 仅靠短期记忆不足以在会话之间保留知识或在长期范围内实现泛化, 这突出了对补充性长期记忆机制的需求。
4.3.2 长期记忆优化
长期记忆优化通过提供持久且可扩展的存储来缓解短上下文窗口的限制, 该存储范围超出了语言模型的即时输入范围。它使智能体能够在会话之间保留和检索事实知识、任务历史记录、用户偏好和交互轨迹(Du等人, 2025),从而支持长期内的连贯推理和决策。该领域的一个关键目标是在管理日益复杂和扩展的记忆空间的同时, 保持记忆存储与推理过程之间的清晰分离(张等人, 2024d)。外部记忆可以是结构化的, 也可以是组织成元组、数据库或知识图等结构化格式(曾等人, 2024b),并且可以涵盖广泛的数据源和概念。
长期记忆优化的关键范式之一是检索增强生成(RAG), 它通过检索将相关的外部记忆融入推理过程(Wang et al., 2023a; Efeoglu and Paschke, 2024; Gao et al., 2025c)。例如, EWE(Chen et al., 2025d)为语言模型增加了一个显式的工作记忆, 该记忆动态地持有检索到的段落的潜在表示, 专注于在每次解码步骤中结合静态记忆条目。相比之下, A- MEM(Xu et al., 2025)通过动态索引和链接构建相互连接的知识网络, 使智能体能够形成演变的记忆。另一个突出的方向涉及智能体检索, 其中智能体自主决定何时以及检索什么, 以及轨迹级记忆, 它利用过去的交互来指导未来的行为。支持技术如高效索引、记忆剪枝和压缩进一步增强了可扩展性(Zheng et al., 2023a; Alizadeh et al., 2024)。例如, Wang et al. (2024e) 提出了一种基于RAG范式的轻量级遗忘学习框架。通过改变用于检索的外部知识库, 系统可以在不修改底层LLM的情况下模拟遗忘效应。类似地, Xu et al. (2025) 引入了一个自演进的记忆系统, 该系统在无需依赖预定义操作的情况下维护长期记忆。除了检索策略和记忆控制机制之外, 记忆本身的结构和编码也显著影响系统性能。基于向量的记忆系统在密集潜在空间中编码记忆, 并支持快速、动态访问。例如, MemGPT (Packer et al., 2023)、NeuroCache (Safaya and Yuret, 2024)、G- Memory (Zhang et al., 2025e) 和 AWESOME (Cao and Wang, 2024) 能够跨任务整合和重用。Mem0 (Chhikara et al., 2025) 进一步引入了一个面向生产、以记忆为中心的架构, 用于连续提取和检索。其他方法从生物或符号系统中获得灵感, 以提高可解释性。HippoRAG (Gutierrez et al., 2024) 通过轻量级知识图谱实现了启发式海马体的索引。GraphReader (Li et al., 2024d) 和 Mem08 (Chhikara et al., 2025) 使用基于图的结构来捕获对话依赖关系并指导检索。在符号领域, 像ChatDB (Hu et al., 2023) 这样的系统在结构化数据库上发出SQL查询, 而 Wang et al. (2024f) 引入了一个神经符号框架, 该框架以自然和符号形式存储事实和规则, 支持精确推理和记忆跟踪。
近期研究也强调了推理过程中记忆控制机制的重要性(Zou等人, 2024; Chen等人, 2025d), 这些机制决定了要存储、更新或丢弃什么、何时以及如何存储记忆(Jin等人, 2025)。
例如,MATTER (Lee 等人,2024b) 动态地从多个异构记忆源中选择相关片段以支持问答,而 AWM (Wang 等人,2024l) 则在在线和离线设置中实现连续的记忆更新。MyAgent (Hou 等人,2024) 为智能体赋予了记忆感知的召回机制以支持生成,解决了LLMs 在时间认知上的局限性。MemoryBank (Zhong 等人,2024) 提出了一种受认知启发的更新策略,其中定期回顾过去的知识可以减轻遗忘并增强长期记忆。强化学习和优先级策略也被用于指导记忆动态 (Zhou 等人,2025b; Yan 等人,2025; Long 等人,2025)。例如,MEM1 (Zhou 等人,2025c) 利用强化学习来维持一个不断演变的内部记忆状态,选择性地整合新信息同时丢弃不相关内容。A- MEM (Xu 等人,2025) 提出了一种自主组织、更新和修剪记忆的智能体记忆架构。MrSteve (Park 等人,2024) 结合了情景“什么- 在哪里- 何时”记忆来分层结构化长期知识,实现目标导向的规划和任务执行。这些方法使智能体能够主动管理记忆并补充短期机制。同时,MIRIX (Wang 和 Chen,2025) 引入了一个在协作环境中具有六种专用记忆类型的智能体记忆系统,实现了协调检索并在长时程任务中达到最先进性能,而 Agent KB (Tang 等人,2025b) 利用一个共享知识库和师生双阶段检索机制来在智能体之间转移跨领域问题解决策略和执行经验,通过分层战略指导和改进显著提升性能。
4.4 工具优化
工具是智能体系统中的关键组件,作为接口使智能体能够感知和与现实世界交互。它们提供对外部信息源、结构化数据库、计算资源和API的访问,从而增强智能体解决复杂现实问题的能力(Patil et al.,2024; Yang etal.,2023; Guoetal.,2024d)。因此,工具使用已成为人工智能智能体的核心能力,特别是对于需要外部知识和多步推理的任务。然而,仅仅向智能体暴露工具是不够的。有效的工具使用要求智能体识别何时以及如何调用正确的工具,解释工具输出,并将其整合到多步推理中。因此,最近的研究集中在工具优化上,旨在增强智能体智能高效使用工具的能力。
现有的工具优化研究主要分为两个互补的方向。第一个方向已被更广泛地探索,专注于增强智能体与工具交互的能力。这是通过不同的方法实现的,包括训练策略、提示技术和推理算法,旨在提高智能体理解、选择和有效执行工具的能力。第二个方向则较新且仍在发展中,专注于通过修改现有工具或创建与目标任务功能需求更匹配的新工具来优化工具本身。
4.4.1 基于训练的工具优化
基于训练的工具优化旨在通过学习更新底层LLM的参数来提升代理使用工具的能力。这种方法的动机源于LLM仅在纯文本生成任务上进行预训练,而没有接触过工具使用或交互式执行。因此,它们缺乏对如何调用外部工具和解释工具输出的内在理解。基于训练的方法旨在通过明确教导LLM如何与工具交互,将工具使用能力直接嵌入代理的内部策略中,从而解决这一局限性。
工具优化的监督微调。这项工作中的早期努力依赖于监督微调 (SFT),它通过在高质量的工具使用轨迹上训练LLM 来明确展示工具应如何调用和集成到任务执行中 (Schick 等人,2023; Du 等人,2024;Liu 等人,2025g; Wang 等人,2025e).这些方法的核心重点在于收集高质量的工具使用轨迹,这些轨迹通常由输入查询、中间推理步骤、工具调用和最终答案组成。这些轨迹作为明确的监督信号,指导代理学习如何规划工具使用、执行调用并将结果整合到其推理过程中。例如,ToolLLM (Qin 等人,2024) 和 GPT4Tools (Yang 等人,2023) 利用更强大的 LLM 来生成指令和相应的工具使用轨迹。受人类学习过程的启发,STE (Wang 等人,2024a) 引入模拟的试错交互来收集工具使用示例,而 TOOLEVO (Chen 等人,
2025b)采用MCTS来实现更主动的探索并收集更高质量的轨迹。T3- Agent(Gao等人,2025d)进一步将这一范式扩展到多模态环境,通过引入数据合成管道来生成和验证高质量的多模态工具使用轨迹,用于微调视觉- 语言模型。
此外,最近的研究工作(Yao等人。,2025)表明,即使先进的LLM在多轮交互中的工具使用也面临挑战,尤其是在这些交互涉及复杂的函数调用、长期依赖关系或请求缺失信息时。为了在多轮工具调用上生成高质量的训练轨迹,Magnet(Yin等人。,2025)提出从工具中合成一系列查询和可执行函数调用,并利用图来构建一个可靠的多轮查询。BUTTON(Chen等人。,2025e)通过一个两阶段过程生成合成组合指令微调数据,其中自底向上的阶段组合原子任务来构建指令,自顶向下的阶段采用多智能体系统来模拟用户、助手和工具以生成轨迹数据。为了实现更真实的数据生成,APIGen- MT(Prabhakar等人。,2025)提出一个两阶段框架,首先生成工具调用序列,然后通过模拟人机交互将其转换为完整的多轮交互轨迹。
一旦收集了工具使用轨迹,它们就通过标准的语言建模目标来微调LLM,使模型能够学习工具调用和集成功的成功模式。除了这种常见范式之外,一些研究还探索了更高级的训练策略,以进一步提高工具使用能力。例如,Confucius(Gao等人,2024a)引入了一种由易到难的课程学习范式,逐步向模型展示越来越复杂的工具使用场景。Gorilla(Patil等人,2024)提出将文档检索器集成到训练管道中,允许代理通过将工具使用与检索到的文档相结合来动态适应不断发展的工具集。
工具优化的强化学习。虽然监督微调已被证明对教代理使用工具很有效,但其性能通常受限于训练数据的质量和覆盖范围低质量的轨迹会导致性能提升减弱。此外,在有限的数据集上进行微调可能会阻碍泛化,尤其是在代理在推理时遇到未见过的工具或任务配置时。为了解决这些限制,最近的研究转向强化学习(RL)作为工具使用的替代优化范式。通过使代理能够通过交互和反馈进行学习,RL促进了更具适应性和鲁棒性的工具使用策略的开发。这种方法在最近的工作中显示出有希望的结果,例如ReTool(Feng等人,2025a)和Nemotron- Research- Tool- N1(Tool- N1)(Zhang等人,2025m),它们都展示了如何在交互环境中通过轻量级监督来获得更具泛化性的工具使用能力。Tool- Star(Dong等人,2025a)通过结合可扩展的工具集成数据合成和两阶段训练框架来增强基于RL的工具使用,以改进自主多工具协作推理。SPORT(Li等人,2025d)通过逐步偏好优化将基于RL的工具优化扩展到多模态设置,使代理能够自行合成任务、探索和验证工具使用而无需人工注释。在这些基础之上,进一步的研究集中于改进用于工具使用的RL算法,包括ARPO(Dong等人,2025b),它通过基于的自适应滚动机制和逐步优势归因来平衡长期推理和多轮工具交互,以及设计更有效的奖励函数(Qian等人,2025a)以及利用合成数据生成和过滤来增强训练稳定性和效率(Goldie等人,2025)。
4.4.2推理时工具优化
除了基于训练的方法外,另一条研究思路专注于在推理过程中增强工具使用能力,而无需修改大型语言模型(LLM)参数。这些方法通常通过优化提示中的工具相关上下文信息,或在测试时通过结构化推理引导代理的决策过程来运作。在此范式内,主要有两个方向:(1)基于提示的方法,该方法通过改进工具文档或指令的表示来促进对工具的更好理解和利用;(2)基于推理的方法,该方法利用测试时的推理策略,如蒙特卡洛树搜索(MCTS)和其他基于树的算法,以在推理过程中实现更有效的工具探索和选择。
基于提示的工具优化。工具相关信息通常通过提示中的工具文档提供给代理。这些文档描述了工具的功能、潜在用途和调用格式,帮助代理理解如何与外部工具交互以解决复杂任务。因此,提示中的工具文档是代理及其可用工具之间至关重要的桥梁,直接
影响工具使用决策的质量。最近的努力集中于优化文档的呈现方式,通过重构源文档或通过交互式反馈进行完善(Qu et al., 2025)。例如,EASYTOOL (Yuan et al., 2025b) 将不同工具文档转换为统一、简洁的指令,使它们更容易被LLM使用。相比之下,DRAFT (Qu et al., 2025) 和 PLAY2PROMPT (Fang et al., 2025) 等方法从人类的试错过程获得灵感,引入交互式框架,根据反馈迭代完善工具文档。
在这些方法之外,一个更近期的方向探索了工具文档和提供给LLM代理的指令的联合优化。例如,Wu等人(2025a)提出了一种优化框架,该框架同时细化代理的提示指令和工具描述,统称为上下文,以增强它们的交互。优化的上下文已被证明可以减少计算开销并提高工具使用效率,突出了上下文设计在有效推理时间工具优化中的重要性。
基于推理的工具优化。测试时的推理和规划技术已显示出在AI代理中提高工具使用能力的强大潜力。早期工作,如ToolLLM (Qin等人,2024)已验证了ReAct (Yao等人,2023b)框架在工具使用场景中的有效性,并进一步提出了一种深度优先树搜索算法,该算法使代理能够快速回溯到最后一个成功状态,而不是从头开始重新启动,这显著提高了效率。ToolChain (Zhuang等人,2024)通过采用成本函数来估计给定分支的未来成本,引入了一种更高效的基于树的搜索算法。这允许代理尽早修剪低价值路径,并避免传统MCTS常见的低效扩展。类似地,Tool- Planner (Liu等人,2025h)将具有相似功能的手工工具聚类为工具包,并利用基于树的规划方法从这些工具包中快速重新选择和调整工具。MCP- Zero (Fei等人,2025)引入了一个主动代理框架,该框架使LLM能够自主识别能力差距并按需请求工具。
4.4.3工具功能性优化
在优化代理行为之外,另一条互补的工作线专注于修改或生成工具本身,以更好地支持特定任务的推理和执行。受人类不断开发工具以满足任务需求的实践启发,这些方法旨在通过将工具集适配到任务来扩展代理的动作空间,而不是将任务适配到固定的工具集(Wang等人,2024k)。例如,CREATOR (Qian等人,2023)和LATM (Cai等人,2024)引入生成新任务的工具文档和可执行代码的框架。CRAFT (Yuan等人,2024a)利用先前任务中的可重用代码片段为未见过的场景创建新工具。AgentOptimiser (Zhang等人,2024b)将工具和函数视为可学习的权重,允许代理使用基于LLM的更新迭代地优化它们。一项更近期的作品Alita (Qiu等人,2025),将工具创建扩展为多组件程序(MCP)格式,增强了可重用性和环境管理。此外,CLOVA (Gao等人,2024b)引入了一个闭环视觉助手框架,包含推理、反思和学习阶段,能够根据人类反馈持续调整视觉工具。
5多智能体优化
多智能体工作流定义了多个智能体如何通过结构化拓扑和交互模式协作解决复杂任务。该领域经历了根本性转变:从手动设计的智能体架构,研究人员明确指定协作模式和通信协议,到能够自动发现有效协作策略的自进化系统。这种进化将工作流设计重新定义为在三个相互关联的空间上的搜索问题:可能的智能体拓扑结构的结构空间、智能体角色和指令的语义空间,以及LLM主干的能能力空间。最近的方法使用各种优化技术探索这些空间,从进化算法到强化学习,每种方法在平衡多个优化目标(例如,准确性、效率和安全性)方面都提供了不同的权衡。
本节追踪了多智能体工作流优化在四个关键维度上的进展。我们的起点是手动设计的范例,这些范例确立了基础原则。从那里,我们考虑了提示级优化,它在不固定的拓扑结构中细化智能体行为。随后
地址拓扑优化,它专注于发现多个智能体为完成给定任务而最有效的架构。我们还讨论了综合方法,这些方法同时考虑多个优化空间,以集成方式联合优化提示、拓扑和其他系统参数。此外,我们研究了LLM骨干优化,它通过有针对性的训练增强智能体自身的根本推理和协作能力。通过这个视角,我们展示了该领域如何逐步扩展其对多智能体系统中构成可搜索和可优化参数的理解,从智能体指令和通信结构到底层模型的核心能力。图6提供了多智能体工作流优化在其核心要素和关键维度上的概述。
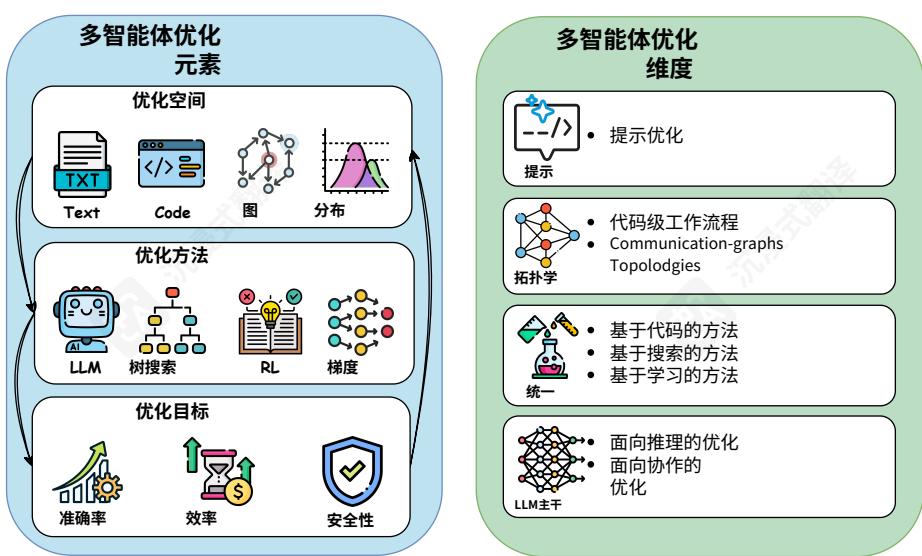
图6多智能体系统优化方法概述,左侧为核心优化元素(空间、方法和目标),右侧为优化维度(提示、拓扑、统一和LLM主干)。
5.1手动设计的多智能体系统
手动设计的流程构成了多智能体协作研究的基础。这些架构将研究人员关于任务分解、智能体能力和协调机制的理解编码为明确的交互模式。通过研究这些手工制作的范例,我们可以理解指导智能体协作的设计原则以及塑造系统架构的工程考虑。
并行流程。并行流程采用并发执行,然后进行集体决策。最简单形式涉及多个独立智能体并行生成解决方案,然后通过多数投票选择最终输出。实证研究表明,使用小型LLM的并行生成可以匹敌甚至优于单个大型LLM(Verga等人,2024;Wang等人,2025a)。多层聚合进一步降低了误差界限并提高了鲁棒性(Zhang等人,2025d)。最近的扩展集成了动态任务图和异步线程,以实现近线性扩展并降低决策延迟(Yu等人,2025;Gu等人,2025;Wang等人,2025c)。然而,虽然计算吞吐量可以水平扩展,但管理协调和一致性的工程成本呈指数级增长。
分层工作流。当子任务表现出严格的上下文依赖关系时,分层(张等人。,2024c;钱等人。,2024)工作流提供了一个结构化的替代方案。这些框架将代理组织成多级自上而下结构或顺序管道。系统在层之间分解任务,每一层负责不同的子任务。这种设计在复杂的以目标驱动的任务中表现出色,例如深度研究和代码生成(洪等人。,2024;张等人。,2025n)。然而,其固定的拓扑结构限制了适应性,尤其是在面对动态目标或资源限制时。
多智能体辩论。为了平衡准确性与可解释性,研究人员开发了辩论范式,其中智能体通过对抗性谈判仲裁循环来讨论和纠正推理错误。早期
工作探索了对称辩论机制(Li等人,2024g)。更近期的研究通过引入角色不对称性、可调节的辩论强度和以说服力为导向的策略扩展了这一框架(Yin等人,2023;Liang等人,2024;Khan等人,2024;Chang,2024)。此外,置信度门控辩论策略表明,仅在单个模型表现出低置信度时触发多智能体辩论可以显著降低推理成本而不影响性能(Eo等人,2025)。
尽管手动设计的流程和结构化多智能体范式取得了成功,但最近的实证研究表明,具有精心设计的提示的单个大型LLM可以在多个推理基准上匹配复杂多智能体讨论框架的性能(Pan等人,2025a).这一发现,加上手工制作多智能体流程的高实现和维护成本(Li等人,2024h;张等人,2025j),推动了自进化多智能体系统的发展,这些系统可以自动学习、适应和随着时间的推移重新构建其工作流程,而不是依赖于固定的架构和静态的协调协议。
5.2自进化多智能体系统
手动设计多智能体流程的高工程成本和有限的适应性促使人们转向自动化、自进化的系统。这些系统可以通过根据性能反馈调整其提示、拓扑结构和协作策略来自动设计、评估和细化智能体工作流程。它们不依赖于硬编码的配置,而是将工作流优化视为一个搜索问题,系统在可能的配置空间中探索和优化。搜索空间涵盖多个层次,从局部提示到全局拓扑结构。
为了有效地导航搜索空间,已经引入了各种搜索算法。这些方法从强化学习、蒙特卡洛树搜索和能够实现高效探索的生成模型,到提供强大搜索能力的进化算子。此外,优化目标已从提高性能扩展到平衡多维目标,包括任务精度、计算效率和安全性。这种演变表明,随着搜索能力的进步,核心挑战已从寻找最优解转变为在动态多智能体环境中定义最优性意味着什么。
5.2.1多智能体提示优化
5.2.1多智能体提示优化实现这种自进化的一种有前景的方向是通过提示优化,其中提示定义了智能体的角色及其相应的任务指令。最近的方法将这些提示编码的配置视为一个形式化的搜索空间,用于系统性的改进。事实上,多智能体工作流中的提示优化通常基于第4.2节中讨论的单智能体技术,但将其扩展到协调多个智能体和任务依赖。例如,DSPy (Singhvi等人。,2023)断言引入了运行时自进化,其中搜索空间包括来自管道模块的可能中间输出,使用断言驱动的回溯,并提供明确的反馈来指导LLM自我纠正违反程序性约束的输出。AutoAgents(Chen等人。,2024b)将提示优化从单智能体环境扩展到整个多智能体团队配置,通过专门的元智能体之间的结构化对话,优化专业智能体角色和执行计划。
5.2.2拓扑优化
拓扑优化代表了多智能体系统设计中的一个范式转变:它不再将通信结构视为固定约束,而是将拓扑本身视为一个强大的优化目标。这一见解源于一个基本观察——即使最好的提示也无法弥补糟糕的架构选择。通过以表示为中心的视角来看,现有工作可以划分为两个互补的类别:程序/代码级工作流拓扑和通信图拓扑;这种分类突出了什么正在被优化——拓扑的选择表示。这不仅标志着技术进步,更是一种概念上的转变——媒介(拓扑)与信息(提示)同等重要。
代码级工作流。将工作流表示为可执行程序或带类型的代码图,使代理协调显式且可验证,支持组合式重用和自动检查。AutoFlow(Li等人。,2024h)将搜索空间设置为自然语言程序(CoRE)并训练一个使用强化
学习训练的生成器LLM,支持微调和上下文使用。与AutoFlow相比,AFlow(Zhang等人。,2025j)用带类型的可重用算子替换NL程序空间以形成代码图;蒙特卡洛树搜索结合LLM指导扩展和软概率选择,比在CoRE上的强化学习提供更结构化、样本效率更高的设计空间探索。超越这些离散搜索方案,ScoreFlow(Wang等人。,2025j)将代码表示提升到连续空间,并应用基于梯度的优化(Score- DPO,一种结合定量反馈的直接偏好优化变体)来改进工作流生成器。这解决了RL/MCTS内在的探索低效问题,并支持任务级自适应工作流生成。与基于搜索的优化正交,MAS- GPT(Ye等人。,2025)在一个以一致性为导向的语料库(跨文档和文档内一致性)上进行监督微调,以便单次推理旨在生成一个完整的可执行MAS代码库,以单次效率换取更广泛的搜索覆盖范围,并更依赖数据质量。
通信图拓扑。与代码级程序不同,此行将工作流视为一个多智能体通信图,其连接是优化目标(刘等人。2025i)。GPTSwarm(诸葛等人。,2024a)将其搜索空间定义为智能体计算图内的连接,它将此离散空间放松为连续的边概率,并采用强化学习来学习最佳连接方案。基于GPTSwarm,DynaSwarm(梁和吴,2025)将搜索空间从单个优化图扩展到一组图结构,采用Actor- Critic(A2C)优化和轻量级图选择器进行每个实例的拓扑选择,解决了关键观察结果:不同的查询需要不同的图结构以获得最佳性能。G- Designer(张等人。,2024a)采用变分图自动编码器直接生成任务自适应通信图,调节结构复杂性以平衡质量和标记成本。MermaidFlow(郑等人。,2025)将拓扑表示为具有静态验证的、类型的声明性图,并通过安全约束的进化算子仅探索语义有效的区域。
超越静态图合成,一些方法在执行过程中动态调节通信图。DyLAN(刘等人。,2023b)将搜索空间视为跨层的主动代理,并带有提前停止时间轴;它通过LLM排序器剪枝低价值代理,并使用传播- 聚合- 选择进行自动团队优化,使用代理重要性分数。Captain Agent(宋等人。,2024)将搜索空间定义为特定子任务的代理和工具集(检索、过滤,并在需要时生成);嵌套的组对话和反思在现场迭代优化团队组成,而不是从头开始合成固定图。Flow(牛等人。,2025)通过动态调整AOV图结构,与DyLAN的剪枝和Captain Agent的团队重组形成对比:它通过并行性/依赖性指标选择初始图,然后通过工作流优化和子任务重新分配在线细化它,以最小的协调成本实现模块化并发。
与图合成正交,剪枝方法通过移除冗余或风险较高的通信来优化,同时保留必要的协作。AgentPrune(张等人,2025g)将搜索空间视为一个时空通信图,其中对话内(空间)和对话间(时间)的边都是剪枝目标;它采用可训练的低秩引导图掩码,通过一次性剪枝识别并消除冗余通信,优化令牌经济性。基于此剪枝范式,AGP(自适应图剪枝)(李等人,2025a)将搜索空间扩展到包括代理数量(硬剪枝)和通信边(软剪枝)。它采用两阶段训练策略,在每项任务的基础上联合优化这些维度,动态确定代理的最优数量及其连接,以生成特定任务的拓扑结构。虽然上述方法剪枝以提高效率和适应性,但G- Safeguard(王等人,2025f)应用剪枝来保障安全——它以通信边为搜索空间,使用GNN标记风险节点,并使用确定性规则在模型驱动的阈值下切断外向边,以防御对抗性攻击。相关地,NetSafe(余等人,2024a)总结拓扑安全风险,并提出基于图的检测和干预原则,作为补充的安全视角。
5.2.3统一优化
统一优化源于一个关键洞察:提示词和拓扑结构并非独立的设计选择,而是智能体系统中深度相互关联的方面(Zhou等人,2025a)。精心设计的提示词在糟糕的通信结构中无法有效运行,而优雅的拓扑结构在糟糕的
指导下智能体。这种相互关联推动了该领域沿着三条不同的技术路径发展:基于代码的统一、结构化优化方法和学习驱动架构。每种方法都从独特的角度应对联合优化挑战,揭示了效率与性能之间的不同权衡。
基于代码的方法。最直接的综合优化方法将代码视为提示和拓扑结构的通用表示。ADAS(胡等人。,2025a)通过其Meta Agent Search框架开创了这种方法,将提示、工作流和工具使用表示为Python代码,以实现迭代代理生成和评估。这种以代码为中心的观点允许自然协同进化,修改代理逻辑本质上会影响指令和结构方面。FlowReasoner(高等人。,2025a)通过专注于查询级适应推进了基于代码的范式,为每个查询生成一个MAS,而不是为每个任务生成。在从DeepSeek- R1中提炼推理能力后,它采用GRPO并结合外部执行反馈来增强其元代理,优化性能和效率。这些方法共同表明,代码为联合优化提供了一个灵活的基础,尽管适应的粒度不同。
基于搜索的方法。与通过代码依赖隐式协同进化不同,另一条研究路线开发用于协调提示和拓扑设计的显式机制。EvoAgent(袁等人。,2025a)将搜索空间定义为文本代理设置(角色、技能、提示),并采用具有突变、交叉和选择算子的进化算法来生成多样化的代理种群。与隐式基于代码的协同进化相比,EvoAgent显式地进化配置级特征,而不是合成程序。相对于EvoAgent的文本中心配置搜索,EvoFlow(高等人。,2025a)同样采用进化搜索,但针对操作符- 节点工作流图。它引入了预定义的复合操作符(例如CoT、辩论),并使用带有标签选择的操作符库来约束突变/交叉,从而缩小搜索空间。EvoFlow进一步将LLM选择视为决策变量,以平衡性能和成本;多样性感知选择保留了种群多样性,而多目标适应度驱动成本- 性能帕累托优化。
与进化搜索互补,MASS(Zhou等人,2025a)提出了一种三阶段、条件耦合优化框架:它首先局部调整每个智能体的提示,然后在一个剪枝空间中搜索工作流拓扑,最后在选定的拓扑上执行全局提示优化;该过程交替进行而不是完全解耦,作为联合优化的实用近似。最近,DebFlow(Su等人,2025)将搜索空间表示为操作节点的工作流图,并采用多智能体辩论进行优化。在执行失败的反思指导下,它避免了穷举搜索,同时在自动化智能体设计中开创了辩论机制。这些结构化方法以一定的灵活性为代价,换取了更具针对性的优化策略。基于操作节点表示,MAS- ZERO(Ke等人,2025)将统一优化视为纯粹推理时的搜索,通过可解性引导的精炼迭代重构智能体团队和任务分解,而无需任何梯度更新或离线训练。
基于学习的方案。最新一波研究将复杂的学习范式应用于联合优化提示和工作流拓扑。MaAS(张等人,2025f)从优化单个架构转向学习智能体超网——多智能体系统的概率分布。其控制器网络使用蒙特卡洛和文本梯度优化对查询特定架构进行采样,以显著降低推理成本实现了卓越性能。ANN(马等人,2025)将多智能体协作概念化为分层神经网络,其中每一层形成专门的智能体团队。它采用两阶段优化过程:正向任务分解和反向文本梯度精炼。这种方法联合进化智能体角色、提示和层间拓扑,使训练后能够适应新任务。
5.2.4LLMBackbone优化
智能体背后的LLM主干的演变是多智能体演变的一个关键方面,特别是智能体如何通过交互提升其合作或推理能力。
面向推理的优化。一项突出工作专注于通过多智能体协作增强骨干LLM的推理能力。例如,多智能体微调(Subramaniam等人。,2025)利用从多智能体辩论中采样的高质量合作轨迹进行监督微调,实现(1)智能体角色的特定专业化以及(2)底层骨干模型的推理能力提升。类似地,Sirius(Zhao等人。,2025c)和MALT(Motwani等人。,2024)采用自我博弈来
收集高质量合作轨迹并在各自的智能体协作框架中训练智能体。虽然两种方法都在一定程度上利用了失败轨迹,但它们在方法上有所不同:Sirius完全依赖SFT,通过自我纠正将错误轨迹集成到训练数据集中,而MALT采用DPO,自然地利用负样本。这些方法为多智能体系统中的自我改进潜力提供了早期证据,尽管它们主要应用于相对简单的环境(例如,多智能体辩论或“生成器- 验证器- 回答者”系统)。未来,MaPoRL(Park等人。,2025)引入任务特定奖励塑形,通过强化学习明确激励智能体间的通信与合作。MARFT(Liao等人。,2025)在传统多智能体强化学习(MARL)和基于LLM的多智能体强化微调之间建立了全面桥梁。在此基础上,MARTI(Liao等人。,2025)提出了一种更可定制的强化多智能体微调框架,支持智能体结构和奖励函数的灵活设计。实证结果表明,在合作训练期间,LLM骨干在合作能力方面表现出显著改进。
面向协作的优化。超越推理,一个较小的工作重点在于增强多智能体系统内的沟通和协作能力。核心假设是LLM智能体并非天生有效的团队成员,其协作沟通能力需要针对性训练。一个早期例子是COPPER(Bo等人。,2024),该研究采用PPO训练一个共享反射器,为多智能体协作轨迹生成高质量、角色感知的个性化反思。OPTIMA(Chen等人。,2025h)更直接地针对多智能体系统中的沟通效率(通过token使用和沟通可读性衡量)并探索通过SFT、DPO和混合方法实现有效性- 效率权衡。它报告在需要密集信息交换的任务上,通过不到 10%10\%10% 的token成本实现了2. 性能提升,这生动地展示了扩展智能体协作能力的潜力。此外,MaPoRL(Park等人。,2025)认为,现行的即用型LLM提示范式和仅依赖其固有协作能力的做法值得质疑
相反,它在多智能体辩论框架内引入了精心设计的强化学习信号,以明确地引出协作行为,鼓励智能体更频繁、更高质量地进行通信。
6特定领域优化
虽然之前的章节主要关注通用领域设置中的智能体优化和进化技术,但特定领域的智能体系统引入了独特的挑战,需要定制的优化策略。这些领域,如生物医学(Almansoori等人,2025),编程(Tang等人,2024),科学研究(Pu等人,2025),游戏(Belle等人,2025),计算机使用(Sun等人,2025),以及金融与法律研究,通常具有专门的任务结构、特定领域的知识库、不同的数据模式以及操作约束。这些因素会显著影响智能体的设计、优化和进化在本节中,我们调查了特定领域智能体优化和进化的最新进展,重点介绍了为满足每个领域的独特需求而开发的有效技术。
6.1生物医学领域的特定领域优化
在生物医学领域,代理优化专注于使代理行为与真实世界临床环境的过程和运营要求相一致。最近的研究表明,特定领域的代理设计在两个关键应用领域(医疗诊断(Donner- Banzhoff,2018;Almansooriet al.,2025;Zhuang et al.,2025)和分子发现(M.Bran et al.,2024;Inoue et al.,2025))中是有效的。在接下来的部分中,我们将考察这两个领域中具有代表性的代理优化策略。
6.1.1医疗诊断
医学诊断需要根据临床症状、病史和诊断检验结果等临床信息来确定患者的状况(Kononenko,2001;Donner- Banzhoff,2018)。近年来,越来越多的研究探索了自主代理在这一背景下的应用,使系统能够自动进行诊断对话、提出澄清问题并生成可能的诊断假设(Li et al.,2024c;Chen et al.,2025i;Zuoet al.,2025;Ghezloo et al.,2025)。这些代理通常在不确定条件下运行,
根据不完整或模糊的患者信息做出决策(Chen etal., 2025i)。诊断过程通常涉及多轮交互,代理通过后续查询来获取缺失信息(Chenet al., 2025i)。此外,为了支持稳健的临床推理,代理通常需要整合外部知识库或与专业的医疗工具交互以进行信息检索和循证推理(Feng et al., 2025b; Fallahpour et al., 2025)。
考虑到这些特定领域的需求,最近的研究主要集中在开发专门针对医学诊断优化的代理架构(Li 等人,2024a;Almansoori 等人,2025;Ghezloo 等人,2025;Wang 等人,2025l).一个有前景的研究方向是多代理系统,这些系统在模拟医学诊断中涉及的复杂性和多步骤推理方面显示出强大的潜力。这些方法可以大致分为两类:基于模拟和协作设计。基于模拟的系统旨在通过为代理分配特定角色并在模拟的医疗环境中进行交互来重现真实的临床环境,使它们能够学习诊断策略。例如,MedAgentSim(Almansoori 等人,2025)引入了一个自演进的模拟框架,该框架集成了经验回放、思维链集成和基于CLIP的语义记忆来支持诊断推理。PathFinder(Ghezloo 等人,2025)通过协调多个代理来模拟专家诊断工作流程,以对吉像素级医学图像进行组织病理学分析。相比之下,协作多代理系统侧重于代理之间的集体决策和协作。例如,MDAgents(Kim 等人,2024)使多个代理能够自适应协作,其中一名调解代理负责整合不同的建议并在需要时咨询外部知识源。MDTeamGPT(Chen 等人,2025c)将这种范例扩展到多学科咨询,通过反思讨论机制支持自演进的、基于团队的诊断过程。
另一个关于诊断代理优化的工作重点是工具集成和多模态推理。例如,MMedAgent(李等人。,2024a)通过在不同模态中动态地整合专业医疗工具来解决现有多模态LLM的泛化局限性。为了提高临床可靠性,MedAgent- Pro(王等人。,2025l)引入了基于既定临床标准的诊断规划,并通过特定任务的工具代理整合多模态证据。与固定的代理架构不同,最近的工作探索了更灵活的设计,这些设计可以根据诊断性能进行调整。例如,庄等人。(2025)提出了一种基于图的代理框架,其中推理过程使用来自诊断结果的反馈进行持续调整。这些方法突出了专业化、多模态和交互式推理作为开发医疗诊断中基于代理系统的关键原则。
6.1.2分子发现和符号推理
6.1.2 分子发现和符号推理生物医学领域的分子发现需要在化学结构、反应路径和药理学约束上进行精确的符号推理(Bilodeau等人。,2022;Makke 和 Chawla,2024;M.Bran 等人。,2024)。为了支持分子发现,最近基于代理的系统引入了定制技术,例如整合化学分析工具、增强知识保留的记忆以及实现多代理协作(McNaughton等人。,2024;Inoue 等人。,2025)。一种关键方法是特定领域的工具集成,这允许代理通过与可执行的化学操作交互来进行化学推理。例如,CACTUS(McNaughton等人。,2024)为代理配备了化学信息学工具,如 RDKit(Landrum,2013)以确保生成化学上有效的输出。通过将推理基于特定领域的工具集,CACTUS比没有工具集的代理实现了显著更好的性能。类似地,LLM- RDF(M.Bran等人。,2024)通过协调负责特定任务的专用代理来自动化化学合成,每个代理都配备了相应的工具,用于文献挖掘、合成规划或反应优化。
另一项突出的研究方向利用了内存增强推理(Hu 等人,2025c;Inoue 等人,2025),其中智能体通过记录先前间题是如何被解决的来从先验经验中学习。ChemAgent(Tang 等人,2025a)将复杂的化学任务分解成更小的子任务,这些子任务存储在一个结构化的内存模块中,从而实现高效的检索和优化。OSDA Agent(Hu 等人,2025c)通过引入一个自我反思机制来扩展这种方法,其中失败的分子提议被抽象为结构化的内存更新,这些更新为未来的决策提供信息并加以增强。同时,多智能体协调提供了额外的优势。DrugAgent(Inoue 等人,2025)引入了一种协调器架构,该架构集成了基于机器学习的预测器、生物医学知识图谱和文献搜索智能体的证据。它采用Chain- of- Thought和ReAct(Yao 等人,2023b)框架来支持可解释的多源
推理。LIDDIA(Averly等人,2025)通过分配模块化角色(即推理者、执行者、评估者和内存)来推广这种设计,这些角色共同模拟了药物化学中的迭代工作流程,并促进了多目标分子评估。
6.2领域特定优化编程
6.2领域特定优化编程在编程领域,代理优化专注于使代理行为与既定软件工程工作流的过程和操作要求相一致。近期研究表明,领域特定代理设计在两个关键应用领域(代码优化(Rashed等人,2024;Tang等人,2024;Pan等人,2025b)和代码调试(Lee等人,2024a;Puvvadi等人,2025;Adnan等人,2025))中非常有效。在接下来的部分中,我们将探讨这两个领域中具有代表性的代理优化策略。
6.2.1代码优化
6.2.1代码优化代码优化涉及在保持其原始功能的同时,迭代改进代码质量、结构和正确性(Yang等人,2024d;He等人,2025;Islam等人,2025)。近期研究越来越多地调查支持该任务领域特定优化的基于代理的系统,重点关注自我改进、协作工作流以及与编程工具的集成(Madaan等人,2023;Tang等人,2024;Rahman等人,2025)。这些系统旨在模拟人工参与迭代优化过程,强制执行软件工程最佳实践,并确保代码在整个迭代开发周期中保持健壮、可读和可维护。一种关键的优化策略涉及自我反馈机制,其中代理批评和修订自己的输出。例如,Self- Refine(Madaan等人,2023)引入了一个轻量级框架,其中语言模型对其自己的输出生成自然语言反馈,并随后相应地修订代码。类似地,CodeCriticBench(Zhang等人,2025a)提出了一个综合基准,旨在评估大型语言模型的自我批评和优化能力,其中代理被评估其通过结构化自然语言反馈识别、解释和修订代码缺陷的能力。LLM- Surgeon(van der Ouderaa等人,2023)提出了一种系统框架,其中语言模型诊断其代码输出中的结构和语义问题,并根据学习到的修复模式应用有针对性的编辑,从而在保持功能的同时优化代码质量。这些方法消除了特定任务再训练的需求,为代码质量提供了持续改进。
另一种研究探索了经验驱动学习,其中智能体通过依赖内存增强的推理来提高其问题解决能力,系统地记录和重用先前遇到的任务的解决方案(Wang等人,2025g;Tang等人,2024;Pan等人,2025b)。例如,AgentCoder(Huang等人,2023a)和CodeAgent(Tang等人,2024)通过为单个智能体分配专门角色(如编码器、审查者和测试者)来模拟协作开发工作流程,通过结构化对话周期迭代改进代码。这些系统支持集体评估和修订,促进角色专业化和审议性决策。此外,工具增强型框架(如CodeCoR(Pan等人,2025b)和OpenHands(Wang等人,2025g))结合外部工具和模块化智能体交互,以促进动态代码修剪、补丁生成和上下文感知优化。VFlow(Wei等人,2025b)将Verilog代码生成任务的工作流优化问题重新表述为在具有代码表示的LLM节点图上的搜索任务,采用协同进化与经验增强蒙特卡洛树搜索(CEPE- MCTS)算法。这些发展突出了迭代反馈、模块化设计和交互式推理作为构建自适应智能体系统以进行代码优化的基本原则。
6.2.2代码调试
6.2.2代码调试代码调试呈现复杂的挑战,需要精确的故障定位、执行感知推理和迭代修正。这些能力通常在通用大语言模型(Puvvadi等人,2025;Mannadiar和Vangheluwe,2010)中缺失。为应对这些挑战,领域特定优化专注于将代理角色和工作流程与人类调试实践中观察到的结构化推理模式和工具使用进行对齐。一个关键策略是利用运行时反馈来促进自我修正。例如,自我调试(Chen等人,2024c)和自我编辑(Zhang等人,2023a)通过将执行跟踪纳入调试过程,体现了这种方法。这些代理通过内部循环的故障识别、基于自然语言的推理和有针对性的代码修订来运行,实现无需外部监督的自主调试。
近期研究探索了专门为支持调试工作流程的多阶段结构而设计的模块化代理架构。例如,PyCapsule(Adnan等人,2025)引入了程序员代理和执行代理之间的职责分离,从而区分代码生成和语义验证。更高级的系统,包括自我协作(Dong等人,2024)和RGD(Jin等人,2024),采用协作管道,其中代理被分配专门角色,如测试员、审查员或反馈分析员,镜像专业调试实践。此外,FixAgent(Lee等人,2024a)通过分层代理激活扩展了这一范式,根据错误复杂性和所需分析深度动态调度不同代理。
6.3 金融与法律研究中的领域特定优化
在金融和法律领域,代理优化专注于根据领域特定工作流的程序和运营需求,定制多代理架构,推理策略和工具集成(Sun等人,2024b;He等人,2024;Li等人,2025f)。近期研究表明,此类领域特定设计在两个关键应用领域——金融决策(Li等人,2023c;Yu等人,2024b;Wang等人,2024j)和法律推理(DiMartino等人,2023;Chen等人,2025a),的有效性,其中模块化设计、协作交互和基于规则的推理对于可靠性能至关重要。在下文中,我们将考察这两个领域中的代表性代理优化策略。
6.3.1 金融决策
金融决策要求代理在不确定和快速变化的环境下运行,对波动的市场动态进行推理,并整合异构信息源,如数值指标、新闻情绪和专家知识(Li等人,2023c;Sarin等人,2024;Chudziak和Waver,2025)。为应对这些领域特定需求,近期研究专注于开发针对金融环境程序和认知需求的多代理架构(Fatemi和Hu,2024;Luo等人,2025a)。一项关键策略涉及概念和协作代理设计。例如,FinCon(Yu等人,2024b)提出了一种基于大型语言模型的综合多代理系统,采用概念语言强化和领域自适应微调来增强动态市场的决策稳定性和策略一致性。PEER(Wang等人,2024j)通过包含专家、检索器和控制器角色的模块化代理架构扩展了这一范式,这些代理在统一调优机制下交互,以平衡任务专业化与通用适应性。FinRobot(Yang等人,2024b)通过整合外部工具进行模型基础推理,进一步推进了这一研究方向,使代理能够将高级策略与可执行的金融模型和实时数据流连接起来。
另一个关于金融决策代理优化的工作重点在于情感分析和报告(Xing,2025;Tian等人,2025;Raza等人,2025)。异构LLM代理架构(Xing,2025)通过结合专门的情感模块与基于规则的验证器来增强金融报告的鲁棒性,以确保符合特定领域的指南。类似地,基于模板的报告框架(Tian等人,2025)将报告生成分解为代理驱动的检索、验证和合成阶段,通过现实世界的反馈实现迭代优化。这些方法展示了自进化多代理系统在复杂金融环境中提供可靠、可解释和上下文感知决策支持的可能性。
6.3.2 法律推理
法律推理需要代理机构解释结构化的法律规则,分析特定案例的证据,并生成与机构法规和司法标准一致的输出(徐和Ju,2023;袁等,2024c;蒋和杨,2025)。为了应对这些特定领域的需求,最近的研究探索了针对法律环境程序性和解释性要求的定制化多代理系统(DiMartino等,2023;胡和舒,2023;陈等,2025a)。一个重要的方向是模拟司法过程并支持结构化论证的合作代理框架。例如,LawLuo(孙等,2024b)引入了一种协同运行的多代理架构,其中法律代理机构被分配了专门的角色,如文件起草、法律论证生成和合规性验证,所有这些都在中央控制器的监督下运行,以确保程序一致性和法律正确性。多代理司法模拟(DiMartino等,2023)和AgentCourt(陈等,2025a)将这一范式扩展到模拟对抗性审判程序,使代理机构能够参与基于角色的互动,模拟现实世界的法庭动态。在
特别是,AgentCourt包含了通过反思性自我博弈来完善其策略的自我进化律师代理机构,从而提高了辩论质量并增强了程序真实性。
另一项工作重点在于结构化法律推理和领域相关的可解释性。LegalGPT(石等人。,2024b)在多智能体系统中集成了法律思维链框架,通过可解释和规则一致的步骤指导法律推理。类似地,AgentsCourt(何等人。,2024)结合了法庭辩论模拟和法律知识增强,使智能体能够基于成文规则和案例先例进行司法决策。这些方法突出了规则基础、模块化角色设计和协作推理在开发强大、透明和具有法律可靠性的智能体系统中的重要性。
7评估
7.1 基于基准的评估7.1.1 工具和API驱动的代理工具增强型代理的评估基于其调用外部API和函数以解决超出其内在知识范围问题的能力。ToolBench (Xu 等人,2023)、API- Bank (Li等人,2023b)、MetaTool (Huang等人,2023b) 和 ToolQA (Zhuang等人,2023) 定义了需要使用工具的任务,并评估API调用的正确性和效率。许多此类评估使用模拟API或沙盒环境,在测量任务成功的同时评估交互效率早期研究表明,代理往往过拟合特定的工具模式,对先前未见过的API泛化能力有限。为解决此限制,最近的基准如GTA (Wang等人,2024b) 和 AppWorld (Trivedi等人,2024) 引入了更现实的多步骤任务,要求跨多个工具进行规划和协调,同时更强调面向过程的评估指标。这一趋势反映了更广泛的转向更丰富、推理感知的评估,不仅评估最终结果,也评估决策过程的质量。
7.1 基于基准的评估
7.1.1工具和API驱动的代理
工具增强型代理的评估基于其调用外部API和函数以解决超出其内在知识范围问题的能力。ToolBench (Xu 等人,2023)、API- Bank (Li等人,2023b)、MetaTool (Huang等人,2023b) 和 ToolQA (Zhuang等人,2023) 定义了需要使用工具的任务,并评估API调用的正确性和效率,许多此类评估使用模拟API或沙盒环境,在测量任务成功的同时评估交互效率
早期研究表明,代理往往过拟合特定的工具模式,对先前未见过的API泛化能力有限。为解决此限制,最近的基准如GTA (Wang等人,2024b) 和 AppWorld (Trivedi等人,2024) 引入了更现实的多步骤任务,要求跨多个工具进行规划和协调,同时更强调面向过程的评估指标。这一趋势反映了更广泛的转向更丰富、推理感知的评估,不仅评估最终结果,也评估决策过程的质量。
7.1.2网络导航和浏览代理
7.1.2 网络导航和浏览代理网络代理通过其与网站交互、提取信息和完成现实世界在线任务的能力进行评估。浏览竞赛(Wei等人,2025a)、MM- BrowseComp(Li等人,2025e)、WebArena(Zhou等人,2023b)、视觉WebArena(Koh等人,2024)、WebCanvas(Pan等人,2024b)、WebWalker(Wu等人,2025b)和AgentBench(Liu等人,2023a)等基准测试逐步提高了基于网络的评估的真实性和多样性,涵盖了模拟和实时环境。这些基准测试测试导航能力、对界面变化的适应性和文本与视觉信息的整合。最近的工作结合了中间指标(例如,子目标完成)和鲁棒性评估,但由于网络动态变化的特性,可重复性和泛化仍然具有挑战性。
7.1.3多智能体协作与通才
7.1.3 多智能体协作与通才随着代理变得更加通用,新的基准测试针对多代理协调和跨领域能力。MultiAgentBench (Zhu 等人,2025) 和 SwarmBench (Ruan 等人,2025) 评估 LLM 代理之间的协作、竞争和去中心化协调,既评估任务完成情况,也评估沟通和策略的质量。通用基准测试如 GAIA (Mialon 等人,2023) 和 AgentBench (Liu
等。, 2023a) 测试在不同环境中的适应性,从网页导航到编码和数据库查询。近期工作,Wang 等人。(2025b) 进一步探索 GAIA 基准测试,分析代理系统的效率- 效果权衡,提出了高效代理,一个在显著降低运营成本的同时实现竞争性性能的框架。这些评估突出了跨异构任务聚合指标、窄场景过拟合风险以及需要统一、全面的排行榜的挑战。
7.1.4 GUI和多模态环境代理
GUI和多模态基准挑战代理在结合文本和视觉输入的丰富、交互式环境中运行。Mobile- Bench (Deng等人。, 2024), AndroidWorld (Rawles 等人。, 2024), CRAB (Xu 等人。, 2024a), GUI- World (Chen 等人。, 2024a), 和 OSWorld (Xie 等人。, 2024) 模拟现实的应用程序和操作系统,需要复杂的动作序列。任务通常结合自然语言理解、视觉感知和API调用。评估测量任务成功、状态管理、感知准确性和对GUI变化的适应能力。然而,GUI环境的多样性使得标准化和可重复性变得困难,代理在面对界面变化时仍然很脆弱。
7.1.5 特定领域任务代理
特定领域的基准在编码(SWE- bench (Jimenez等人。, 2024)),数据科学(DataSciBench (Zhang等人。, 2025c)),企业生产力(WorkBench (Styles 等人。, 2024)),和科学研究(OpenAGI (Ge 等人。, 2023)),SUPER (Begin等人。, 2024) 评估集成规划、工具使用和遵守领域规范的专门能力。例如,SWE- bench 评估代码编辑代理在真实的GitHub存储库上,而 AgentClinic (Schmidgall 等人。, 2024) 和 MMedAgent (Li等人。, 2024a) 测试临床环境中的多模态推理。评估标准已从二元成功指标扩展到涵盖测试通过率、政策遵守和符合特定领域约束的指标。尽管取得了这些进展,但指标定义的不一致和泛化方面的持续差距仍然是重大挑战。
7.2 基于LLM的评估
7.2.1 LLM作为裁判
LLM作为裁判范式是指利用大型语言模型来评估人工智能系统生成的输出质量,例如文本、代码或对话式响应,通过结构化提示(Arabzadeh等人,2024;Li等人,2024b;Qian等人,2025b)。这种方法作为一种可扩展且经济高效的替代方案,引起了人们对传统评估方法的关注,包括人工判断和自动指标(例如BLEU、ROUGE),这些方法往往无法捕捉语义深度或连贯性(Arabzadeh等人,2024)。LLM裁判通常以两种模式运行:点式评估(Ruan等人,2024),其中输出直接根据事实性和有用性等标准进行评分,以及成对比较,其中两个输出进行比较,并选择更优的输出并给出理由(Li等人,2024b;Zhao等人,2025b)。
近期研究表明,基于LLM的评估可以与人类判断相关联,在某些情况下达到标注者间一致性水平(Arabzadeh等人,2024)。然而,这些方法对提示设计敏感,容易受到细微指令变化引入的偏差影响(Arabzadeh等人,2024;Zhao等人,2025b)。此外,单步、输出导向的评估可能会忽略多步过程中的推理深度(Zhuge等人,2024b;Wang等人,2025b)。为解决这些局限性,已提出改进方案,包括多智能体协商框架(如CollabEval(Qian等人,2025b))和结构化元评估基准,用于校准和提升LLM裁判的可靠性(Li等人,2024b;Zhao等人,2025b)。
7.2.2 智能体作为裁判
Agent- as- a- Judge 框架通过采用能够进行多步推理、状态管理和工具使用的完整代理系统,扩展了基于LLM 的评估,用于评判其他 AI 代理(Zhuge 等人,2024b;Zhao 等人,2025b;Qian 等人,2025b)。与传统LLM 评判员不同,后者仅关注最终输出,代理评判员评估整个推理轨迹,捕捉决策过程和中间动作(Zhuge 等人,2024b)。例如,Zhuge 等人(2024b)应用了一种代理评判员
到 DevAI 代码生成代理基准。该框架集成了专门模块来分析中间产物、构建推理图并验证分层需求,从而使得评估结果与传统基于大型语言模型的(LLM)方法相比更贴近人类专家判断。代理裁判还带来了显著的效率提升,相对于人工审查减少了评估时间和成本(Zhuge 等人,2024b;Zhao 等人,2025b)。
然而,实施代理作为法官的方法论增加了额外的复杂性,并提出了在代码生成以外的领域推广的挑战。当前研究寻求提高适应性并简化跨更广泛人工智能任务的部署(赵等,2025b;钱等,2025b)。
7.3 安全、对齐和终身自进化代理的鲁棒性
在自进化人工智能代理的三大定律的背景下,坚持,在任何修改期间维护安全和稳定性,是所有其他形式适应的主要约束。对于终身、自进化代理系统,安全不是一次性的认证,而是一个持续的要求:从提示更新到拓扑变化,每一步进化都必须评估意外或恶意行为。这需要连续、粒度和可扩展的评估协议,确保代理在长期适应过程中保持对齐。
最近的工作引入了多种评估范式。以风险为中心的基准,如 AGENTHARM (安德里尤申科等,2025) 测量代理遵守显式恶意多步请求的倾向——需要连贯的工具使用来执行欺诈或网络犯罪等有害目标,表明即使是领先的LLM也可以通过最少的提示被诱导进行复杂的不安全行为。特定领域的探测,如 RedCode (郭等,2024a) (代码安全) 和 MobileSafetyBench (李等,2024c) (移动控制) 在真实、沙盒环境中对代理进行压力测试。行为探测,如 MACH- AVELLI (潘等,2023) 探索代理在奖励优化下是否发展出不道德、追求权力的策略,突出了坚持和卓越之间的相互作用,安全的适应不应降低核心任务能力。
元评估方法,例如 AGENT- AS- A- JUDGE (诸葛等人,2024b)、AGENTEVAL (阿卜杜勒- 扎德等人,2024),以及 R- JUDGE (袁等人,2024b) - 将 LLM 代理自身定位为评估者或安全监控员,提供可扩展的监督,但也暴露了当前“风险意识”的局限性。这些研究强调了安全的多维性,其中仅准确性是不够的;过度依赖正确性指标可能会掩盖认知风险和系统性偏差(李等人,2025j)。例如 SAFELAVYBENCH (曹等人,2025) 进一步表明,即使是最先进的模型也难以满足既定的法律原则,这反映了在具有开放性规范的领域中难以将一致性编码的困难。
尽管取得了这些进展,但大多数当前评估都是基于快照的,在单个时间点评估代理。对于 MASE 系统,安全评估本身必须变得动态——随着系统的演变持续监控、诊断和纠正行为。开发纵向的、具有进化感知的基准,以跟踪代理生态系统整个生命周期中的安全、一致性和鲁棒性,仍然是一个开放且紧迫的挑战。
8 挑战与未来方向
尽管取得了快速进展,但 AI 代理的进化和优化仍然面临根本性障碍。这些挑战与自我进化 AI 代理的三大定律紧密相关,需要得到解决以实现终身代理系统的愿景。我们相应地归纳了关键的开问题。
8.1 挑战
8.1.1 坚持——安全适应
(1) 安全、法规和一致性。大多数优化流程优先考虑任务指标而非安全约束,忽视了意外行为、隐私泄露和目标不一致等风险。不断演变的智能体的动态特性破坏了现有的法律框架(例如,欧盟人工智能法案、通用数据保护条例),这些框架假设静态模型和固定的决策逻辑。这要求新的、适应演变的审计机制、可证明安全的沙盒以及能够跟踪和约束智能体自我导向进化路径的法律协议。
许可证、可证明安全的沙盒以及能够跟踪和约束智能体自我导向进化路径的法律协议。
(2) 奖励建模和优化不稳定性。用于中间推理步骤的学习到的奖励模型通常受到数据集稀缺、监督噪声和反馈不一致的影响,导致代理行为不稳定或发散。稳定性是安全的核心:输入或更新规则中的微小扰动都可能破坏正在发展的工作流程的可信度。
8.1.2 Excel - 性能保留
(1) 在科学和特定领域场景中的评估。在生物医学或法律等领域,可靠的基准真理往往缺失或有争议,这使构建用于优化的可信反馈信号变得复杂。
(2) 在多智能体优化中平衡效率和效果。大规模多智能体优化可以提高任务性能,但会带来显著的计算成本、延迟和不稳定性。设计明确权衡效果与效率的方法仍然是未决。
(3) 优化提示和拓扑结构的可迁移性。优化的提示或代理拓扑结构通常很脆弱,在具有不同推理能力的LLM主干上表现出较差的泛化能力。这削弱了在生产环境中的可扩展性和可重用性。
8.1.3 进化 - 自主优化
(1) 多模态和空间环境中的优化。大多数优化算法仅处理文本,而现实世界的智能体必须处理多模态输入并在空间关联或连续环境中进行推理。这需要内部世界模型和感知-时间推理。
(2) 工具使用和创造。当前方法通常假设固定的工具集,忽略了智能体与工具的自主发现、适应和共同进化。
8.2 未来方向
展望未来,这些局限性指出了许多有前景的研究方向。我们强调几个方向,并将它们与它们在 MOP →\rightarrow→ MOA →\rightarrow→ MAO →\rightarrow→ MASE 范式转变中的作用联系起来。
(1) 用于完全自主自我进化的模拟环境 (MASE)。开发开放式的交互式模拟平台,让智能体可以迭代交互、接收反馈,并通过闭环优化改进提示、记忆、工具和工作流程。
(2) 推进工具使用和创建 (MAO →\rightarrow→ MASE)。超越静态工具调用,转向能够自适应选择、组合或创建工具的智能体。结合强化学习和反馈驱动策略,并配备稳健的评估流程。
(3) 现实世界评估和基准测试 (跨阶段)。创建反映现实世界复杂性的基准和协议,支持基于交互和纵向的评估,并与长期改进信号保持一致。
(4) 多智能体系统优化中的有效性与效率权衡 (MAO)。设计优化算法,联合建模性能和资源约束,使多智能体系统在严格的延迟、成本或能源预算下部署。
(5) 面向科学和专门应用的领域感知进化 (MASE)。针对科学、医学、法律或教育中的领域特定约束,定制进化方法,整合异构知识源、定制评估标准和监管合规性。
Outlook. 解决这些挑战将需要优化管道,这些管道不仅需要高性能和领域自适应,还需要安全、符合法规并自我维持。将这些解决方案嵌入到 MOP →\rightarrow→ MOA →\rightarrow→ MAO →\rightarrow→ MASE 轨迹中,并以自我进化人工智能代理的三大定律为基础,为真正实现终身、自主代理系统提供了清晰的道路——这些系统可以在其整个运行生命周期中持续存在、表现出色并不断进化。
9结论
在本调查中,我们全面概述了自我进化AI代理这一新兴范式,该范式连接了基础模型的静态能力与终身代理系统所需的持续适应性。我们将这一进化过程置于一个统一的四阶段轨迹中,从模型离线预训练(MOP)和模型在线适应(MOA),通过多代理编排(MAO),最终到多代理自我进化(MASE),突出了从静态、人工配置模型到动态、自主生态系统的渐进转变。
为了形式化这一过渡,我们引入了一个概念框架,该框架抽象了智能体进化的底层反馈循环,包含四个关键组件:输入、智能体系统、目标和优化器,这些组件共同决定了智能体如何通过与环境的持续交互来改进。在此基础上,我们系统地回顾了智能体组件的优化技术、特定领域的策略以及构建自适应和弹性智能体系统至关重要的评估方法。
我们还提出了自我进化的AI智能体的三大定律,忍耐(安全适应)、卓越(性能保持)和进化(自主进化),作为指导原则,以确保终身自我改进保持安全、有效和一致。这些定律不仅仅是原则,而是实际的设计约束,确保通往自主的道路始终与安全、性能和适应性保持一致。它们是MASE范式的护栏,指导研究从狭隘的单次优化转向持续、开放式的自我改进。
展望未来,忍耐、卓越和进化的能力将决定智能体在动态、真实世界环境中的表现,无论是在科学发现、软件工程还是人机协作中。实现这一点将需要突破可扩展优化算法、终身评估协议、异构智能体环境中的安全协调机制以及适应未知领域的机制。
我们希望这项调查既能作为参考点,又能作为行动号召,以构建一个自我进化的AI智能体生态系统,这些智能体不仅执行任务,而且能够生存、学习和持续存在。通过将技术创新与原则性自我进化相结合,我们可以为真正自主、坚韧和值得信赖的终身智能体系统铺平道路。
致谢
我们感谢郭舒宇为智能体优化早期探索和文献综述所做的宝贵贡献。
参考文献
Muntasir Adnan, Zhiwei Xu, and Carlos CN Kuhn. Large language model guided self- debugging code generation. arXiv preprint arXiv:2502.02928, 2025. Eshaan Agarwal, Joykirti Singh, Vivek Dani, Raghav Magarine, Tanuja Ganu, and Akshay Namid. Promptwizard: Task- aware prompt optimization framework. arXiv preprint arXiv:2405.18369, 2024. Keivan Alizadeh, Seyed- Iman Mirzadeh, Dmitry Belenko, S. Khatamifard, Minsik Cho, Carlo C. del Mundo, Mohammad Bastegari, and Mohdad Farajtabar. LLM in a flash: Efficient large language model inference with limited memory. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12562- 12584, 2024. Mohammad Almansoori, Komal Kumar, and Hisham Cholakkal. Self- evolving multi- agent simulations for realistic clinical interactions. arXiv preprint arXiv:2503.22678, 2025. Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, J. Zico Kolter, Matt Fredrikson, Yarin Gal, and Xander Davies. AgentHarm: A benchmark for measuring harmfulness of LLM agents. In The Thirteenth International Conference on Learning Representations, 2025. Negar Arabzadeh, Julia Kiseleva, Qingyun Wu, Chi Wang, Ahmed Awadallah, Victor Dibia, Adam Fourney, and Charles Clarke. Towards better human- agent alignment: Assessing task utility in llm- powered applications. arXiv preprint arXiv:2402.09015, 2024.
Derek Austin and Elliott Chartock. GRAD- SUM: Leveraging gradient summarization for optimal prompt engineering. arXiv preprint arXiv:2407.12865, 2024.
Reza Averly, Frazier N Baker, and Xia Ning. LIDDIA: Language- based intelligent drug discovery agent. arXiv preprint arXiv:2502.13959, 2025.
Nikolas Belle, Dakota Barnes, Alfonso Amayuelas, Ivan Bercovich, Xin Eric Wang, and William Wang. Agents of change: Self- evolving llm agents for strategic planning. arXiv preprint arXiv:2506.04651, 2025.
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI conference on artificial intelligence, pages 17682- 17690, 2024.
Zhenni Bi, Kai Han, Chuanjian Liu, Yehui Tang, and Yunke Wang. Forest- of- thought: Scaling test- time compute for enhancing LLM reasoning. In Forty- second International Conference on Machine Learning, 2025.
Camille Bilodeau, Wengong Jin, Tommi Jaakkola, Regina Barzilay, and Klavs F Jensen. Generative models for molecular discovery: Recent advances and challenges. Wiley Interdisciplinary Reviews: Computational Molecular Science, 12(5): e1608, 2022.
Xiaohe Bo, Zeyu Zhang, Quanyu Dai, Xueyang Feng, Lei Wang, Rui Li, Xu Chen, and Ji- Rong Wen. Reflective multi- agent collaboration based on large language models. Advances in Neural Information Processing Systems, 37: 138595- 138631, 2024.
Ben Bogin, Kejuan Yang, Shashank Gupta, Kyle Richardson, Erin Bransom, Peter Clark, Ashish Sabharwal, and Tushar Khot. SUPER: evaluating agents on setting up and executing tasks from research repositories. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 12622- 12645, 2024.
Tianle Cai, Xuezhi Wang, Tengyu Ma, Xinyun Chen, and Denny Zhou. Large language models as tool makers. In The Twelfth International Conference on Learning Representations, 2024.
CAMEL- AI. Workforce — camel- ai documentation. https://docs.camel- ai.org/key_modules/workforce, 2025. Accessed: 2025- 08- 09.
Chuxue Cao, Han Zhu, Jiaming Ji, Qichao Sun, Zhenghao Zhu, Yinyu Wu, Josef Dai, Yaodong Yang, Sirui Han, and Yi- Ke Guo. SafeLawBench: Towards safe alignment of large language models. In Findings of the Association for Computational Linguistics, pages 14015- 14048, 2025.
Nicola De Cao, Wilker Aziz, and Ivan Titov. Editing factual knowledge in language models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6491- 6506, 2021.
Shuyang Cao and Lu Wang. AWESOME: GPU memory- constrained long document summarization using memory mechanism and global salient content. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5925- 5941, 2024.
Edward Y Chang. Sorcrasynth: Multi- llm reasoning with conditional statistics. arXiv preprint arXiv:2402.06634, 2024.
GaoWei Chang and Agent Network Protocol Contributors. Agent Network Protocol (ANP). https://github.com/agent- network- protocol/AgentNetworkProtocol. MIT License, accessed 2025- 07- 31.
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian- Guang Lou, and Weizhu Chen. CodeT: Code generation with generated tests. In The Eleventh International Conference on Learning Representations, 2023.
Dongping Chen, Yue Huang, Siyuan Wu, Jingyu Tang, Huichi Zhou, Qihui Zhang, Zhigang He, Yilin Bai, Chujie Gao, Liuyi Chen, et al. GUI- world: A video benchmark and dataset for multimodal GUI- oriented understanding. In The Thirteenth International Conference on Learning Representations, 2024a.
Guangyao Chen, Siwei Dong, Yu Shu, Ge Zhang, Jaward Sesay, Borje Karlsson, Jie Fu, and Yemin Shi. AutoAgents: A framework for automatic agent generation. In Proceedings of the Thirty- Third International Joint Conference on Artificial Intelligence, pages 22- 30, 2024b.
Guhong Chen, Liyang Fan, Zihan Gong, Nan Xie, Zixuan Li, Ziqiang Liu, Chengming Li, Qiang Qu, Hamid Alinejad- Rokny, Shiwen Ni, and Min Yang. AgentCourt: Simulating court with adversarial evolvable lawyer agents. In Findings of the Association for Computational Linguistics, pages 5850- 5865. Association for Computational Linguistics, 2025a.
Guoxin Chen, Zhong Zhang, Xin Cong, Fangda Guo, Yesai Wu, Yankai Lin, Wenzheng Feng, and Yasheng Wang. Learning evolving tools for large language models. In The Thirteenth International Conference on Learning Representations, 2025b.
Kai Chen, Xinfeng Li, Tianpei Yang, Hewei Wang, Wei Dong, and Yang Gao. MDTeamGPT: A self- evolving llm- based multi- agent framework for multi- disciplinary team medical consultation. arXiv preprint arXiv:2503.13856, 2025c.
Mingda Chen, Yang Li, Karthik Padthe, Rulin Shao, Alicia Yi Sun, Luke Zettlemoyer, Gargi Ghosh, and Wen- tau Yih. Improving factuality with explicit working memory. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11199- 11213, 2025d.
Mingyang Chen, Haoze Sun, Tianpeng Li, Fan Yang, Hao Liang, KeerLu, Bin CUI, Wentao Zhang, Zenan Zhou, and Weipeng Chen. Facilitating multi- turn function calling for LLMs via compositional instruction tuning. In The Thirteenth International Conference on Learning Representations, 2025e.
Nuo Chen, Hongguang Li, Jianhui Chang, Juhua Huang, Baoyuan Wang, and Jia Li. Compress to impress: Unleashing the potential of compressive memory in real- world long- term conversations. In Proceedings of the 31st International Conference on Computational Linguistics, pages 755- 773, 2025f.
Weize Chen, Ziming You, Ran Li, Yitong Guan, Chen Qian, Chenyang Zhao, Cheng Yang, Ruobing Xie, Zhiyuan Liu, and Maosong Sun. Internet of agents: Weaving a web of heterogeneous agents for collaborative intelligence. In The Thirteenth International Conference on Learning Representations, 2025g.
Weize Chen, Jiarui Yuan, Chen Qian, Cheng Yang, Zhiyuan Liu, and Maosong Sun. Optima: Optimizing effectiveness and efficiency for llm- based multi- agent system. In Findings of the Association for Computational Linguistics, pages 11534- 11557. Association for Computational Linguistics, 2025h.
Xi Chen, Huahui Yi, Mingke You, WeiZhi Liu, Li Wang, Hairui Li, Xue Zhang, Yingman Guo, Lei Fan, Gang Chen, et al. Enhancing diagnostic capability with multi- agents conversational large language models. NPJ digital medicine, 8(1):159, 2025i.
Xinyun Chen, Maxwell Lin, Nathanael Scharli, and Denny Zhou. Teaching large language models to Self- Debug. In The Twelfth International Conference on Learning Representations, 2024c.
Yuyang Cheng, Yumiao Xu, Chaojia Yu, and Yong Zhao. HAWK: A hierarchical workflow framework for multi- agent collaboration. arXiv preprint arXiv:2507.04067, 2025.
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production- ready ai agents with scalable long- term memory. arXiv preprint arXiv:2504.19413, 2025.
Jaroslaw A Chudziak and Micha Wawer. ElliottAgents: a natural language- driven multi- agent system for stock market analysis and prediction. arXiv preprint arXiv:2507.03432, 2025.
Mingkai Deng, Jianyu Wang, Cheng- Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric P. Xing, and Zhiting Hu. RLPrompt: Optimizing discrete text prompts with reinforcement learning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3369- 3391, 2022.
Shihan Deng, Weikai Xu, Hongda Sun, Wei Liu, Tao Tan, Jianfeng Liu, Ang Li, Jian Luan, Bin Wang, Rui Yan, and Shuo Shang. Mobile- Bench: An evaluation benchmark for llm- based mobile agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8813- 8831, 2024.
Beniamino Di Martino, Antonio Esposito, and Luigi Colucci Cante. Multi agents simulation of justice trials to support control management and reduction of civil trials duration. Journal of Ambient Intelligence and Humanized Computing, 14(4):3645- 3657, 2023.
Guanting Dong, Yifei Chen, Xiaoxi Li, Jiajie Jin, Hongjin Qian, Yutao Zhu, Hangyu Mao, Guorui Zhou, Zhicheng Dou, and Ji- Rong Wen. Tool- Star: Empowering llm- brained multi- tool reasoner via reinforcement learning. arXiv preprint arXiv:2505.16410, 2025a.
Guanting Dong, Hangya Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jianchen Du, Haiyang Wang, Fuzheng Zhang, et al. Agentice reinforced policy optimization. arXiv preprint arXiv:2507.19849, 2025b.
Yihong Dong, Xue Jiang, Zhi Jin, and Ge Li. Self- collaboration code generation via chatgpt. ACM Transactions on Software Engineering and Methodology, 33(7):1- 38, 2024.
Norbert Donner- Banzhoff. Solving the diagnostic challenge: a patient- centered approach. The Annals of Family Medicine, 16(4):353- 358, 2018.
Yiming Du, Wenyu Huang, Danna Zheng, Zhaowei Wang, Sebastien Montella, Mirella Lapata, Kam- Fai Wong, and Jeff Z Pan. Rethinking memory in ai: Taxonomy, operations, topics, and future directions. arXiv preprint arXiv:2505.00675, 2025.
Yu Du, Fangyun Wei, and Hongyang Zhang. AnyTool: Self- reflective, hierarchical agents for large- scale API calls. In Forty- first International Conference on Machine Learning, 2024.
Sefika Efeoglu and Adrian Paschke. Retrieval- augmented generation- based relation extraction. arXiv preprint arXiv:2404.13397, 2024.
Sugyeong Eo, Hyeonseok Moon, Evelyn Hayoon Zi, Chanjun Park, and Heuiseok Lim. Debate only when necessary: Adaptive multiagent collaboration for efficient llm reasoning. arXiv preprint arXiv:2504.05047, 2025.
Adibvafa Fallahpour, Jun Ma, Alif Munim, Hongwei Lyu, and Bo Wang. Medrax: Medical reasoning agent for chest x- ray. arXiv preprint arXiv:2502.02673, 2025.
Wei Fang, Yang Zhang, Kaizhi Qian, James Glass, and Yada Zhu. Play2prompt: Zero- shot tool instruction optimization for llm agents via tool play. arXiv preprint arXiv:2503.14432, 2025.
Sorouralsadat Fatemi and Yuheng Hu. Finvision: A multi- agent framework for stock market prediction. In Proceedings of the 5th ACM International Conference on AI in Finance, pages 582- 590, 2024.
Xiang Fei, Xiawu Zheng, and Hao Feng. MCP- Zero: Active tool discovery for autonomous llm agents. arXiv preprint arXiv:2506.01056, 2025.
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms. arXiv preprint arXiv:2504.11536, 2025a.
Jinghao Feng, Qiaoyu Zheng, Chaoyi Wu, Ziheng Zhao, Ya Zhang, Yanfeng Wang, and Weidi Xie. M3builder: A multi- agent system for automated machine learning in medical imaging. arXiv preprint arXiv:2502.20301, 2025b.
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktaschel. Promptbreeder: Self- referential self- improvement via prompt evolution. In Forty- first International Conference on Machine Learning, 2024.
Emily First, Markus N Rabe, Talia Ringer, and Yuriy Bruni. Baldur: Whole- proof generation and repair with large language models. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 1229- 1241, 2023.
Adam Fourney, Gagan Bansal, Hussein Mozanmar, Cheng Tan, Eduardo Salinas, Frederike Niedtner, Grace Proebsting, Griffin Bassman, Jack Gerrits, Jacob Alber, et al. Magentic- one: A generalist multi- agent system for solving complex tasks. arXiv preprint arXiv:2411.04468, 2024.
Hongcheng Gao, Yue Liu, Yufei He, Longxu Dou, Chao Du, Zhijie Deng, Bryan Hooi, Min Lin, and Tianyu Pang. FlowReasoner: Reinforcing query- level meta- agents. arXiv preprint arXiv:2504.15257, 2025a.
Huan- ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, et al. A survey of self- evolving agents: On path to artificial super intelligence. arXiv preprint arXiv:2507.21046, 2025b.
Shen Gao, Zhengliang Shi, Minghang Zhu, Bowen Fang, Xin Xin, Pengjie Ren, Zhumin Chen, Jun Ma, and Zhaochun Ren. Confucius: Iterative tool learning from introspection feedback by easy- to- difficult curriculum. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 18030- 18038, 2024a.
Yunfan Gao, Yun Xiong, Yijie Zhong, Yuxi Bi, Ming Xue, and Haofen Wang. Synergizing RAG and reasoning: A systematic review. arXiv preprint arXiv:2504.15909, 2025c.
Zhi Gao, Yuntao Du, Xintong Zhang, Xiaojian Ma, Wenjuan Han, Song- Chun Zhu, and Qing Li. CLOVA: A closed- loop visual assistant with tool usage and update. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13258- 13268. IEEE, 2024b.
Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaojian Ma, Tao Yuan, Yue Fan, Yuwei Wu, Yunde Jia, Song- Chun Zhu, and Qing Li. Multi- modal agent tuning: Building a vlm- driven agent for efficient tool usage. In The Thirteenth International Conference on Learning Representations, 2025d.
Yingqiang Ge, Wenyue Hua, Kai Mei, Juntao Tan, Shuyuan Xu, Zelong Li, Yongfeng Zhang, et al. OpenAGI: When llm meets domain experts. Advances in Neural Information Processing Systems, 36:5539- 5568, 2023.
Caleb Geren, Amanda Board, Gaby G. Dagher, Tim Andersen, and Jun Zhuang. Blockchain for large language model security and safety: A holisticsurvey. SIGKDD Explorations, 26(2):1- 20, 2024.
Fatemeh Ghezloo, Mehmet Saygin Seyfioglu, Rustin Soraki, Wisdom O Ikezogwo, Beibin Li, Tejoram Vivekanandan, Joann G Elmore, Ranjay Krishna, and Linda Shapiro. Pathfinder: A multi- modal multi- agent system for medical diagnostic decision- making applied to histopathology. arXiv preprint arXiv:2502.08916, 2025.
Anna Goldie, Azalia Mirhoseini, Hao Zhou, Irene Cai, and Christopher D.Manning Manning. Synthetic data generation & multi- step RL for reasoning & tool use. arXiv preprint arXiv:2504.04736, 2025.
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Minlie Huang, Nan Duan, and Weizhu Chen. ToRA: A tool- integrated reasoning agent for mathematical problem solving. In The Twelfth International Conference on Learning Representations, 2024.
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
Zhouhong Gu, Xiaoxuan Zhu, Yin Cai, Hao Shen, Xingzhou Chen, Qingyi Wang, Jialin Li, Xiaoran Shi, Haoran Guo, Wenxuan Huang, et al. AgentGroupChat- V2: Divide- and- conquer is what llm- based multi- agent system need. arXiv preprint arXiv:2506.15451, 2025.
Chengquan Guo, Xun Liu, Chulin Xie, Andy Zhou, Yi Zeng, Zinan Lin, Dawn Song, and Bo Li. Redcode: Risky code execution and generation benchmark for code agents. Advances in Neural Information Processing Systems, 37: 106190- 106236, 2024a.
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek- R1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. EvoPrompt: Connecting llms with evolutionary algorithms yields powerful prompt optimizers. In The Twelfth International Conference on Learning Representations, 2024b.
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi- agents: A survey of progress and challenges. In Proceedings of the Thirty- Third International Joint Conference on Artificial Intelligence, pages 8048- 8057, 2024c.
Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, and Yang Liu. StableToolBench: Towards stable large- scale benchmarking on tool learning of large language models. In Findings of the Association for Computational Linguistics, pages 11143- 11156, 2024d.
Bernal Jimenez Gutierrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. HippoRAG: Neurobiologically inspired long- term memory for large language models. In Advances in Neural Information Processing Systems, 2024.
Shanshan Han, Qifan Zhang, Yuhang Yao, Weizhao Jin, and Zhaozhuo Xu. LLM multi- agent systems: Challenges and open problems. arXiv preprint arXiv:2402.03578, 2024.
Junda He, Christoph Treude, and David Lo. LLM- based multi- agent systems for software engineering: Literature review, vision, and the road ahead. ACM Transactions on Software Engineering and Methodology, 34(5):1- 30, 2025.
Zhitao He, Pengfei Cao, Chenhao Wang, Zhuoran Jin, Yubo Chen, Jiexin Xu, Huaijun Li, Xiaojian Jiang, Kang Liu, and Jun Zhao. AgentsCourt: Building judicial decision- making agents with court debate simulation and legal knowledge augmentation. arXiv preprint arXiv:2403.02959, 2024.
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta programming for A multi- agent collaborative framework. In The Twelfth International Conference on Learning Representations, 2024.
Yuki Hou, Haruki Tamoto, and Homei Miyashita. “my agent understands me better”: Integrating dynamic human- like memory recall and consolidation in llm- based agents. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, CHI '24, page 1- 7. ACM, May 2024.
Zhipeng Hou, Junyi Tang, and Yipeng Wang. Halo: Hierarchical autonomous logic- oriented orchestration for multi- agent llm systems. arXiv preprint arXiv:2505.13516, 2025.
Cho- Jui Hsieh, Si Si, Felix X. Yu, and Inderjit S. Dhillon. Automatic engineering of long prompts. In Findings of the Association for Computational Linguistics, pages 10672- 10685, 2024.
Chenxu Hu, Jie Fu, Chenzhuang Du, Simian Luo, Junbo Zhao, and Hang Zhao. ChatDB: Augmenting llms with databases as their symbolic memory. arXiv preprint arXiv:2306.03901, 2023. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low- rank adaptation of large language models. In The Tenth International Conference on Learning Representations, 2022. Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems. In The Thirteenth International Conference on Learning Representations, 2025a.Wenyang Hu, Yao Shu, Zongmin Yu, Zhaoxuan Wu, Xiaoqiang Lin, Zhongxiang Dai, See- Kiong Ng, and Bryan Kian Hsiang Low. Localized zeroth- order prompt optimization. Advances in Neural Information Processing Systems, 37:86309- 86345, 2024. Xueyu Hu, Tao Xiong, Biao Yi, Zishu Wei, Huixuan Xiao, Yurun Chen, Jiasheng Ye, Meiling Tao, Xiangxin Zhou, Ziyu Zhao, et al. OS agents: A survey on mllm- based agents for computer, phone and browser use. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7436- 7465, 2025b.Zhaolin Hu, Yixiao Zhou, Zhongan Wang, Xin Li, Weimin Yang, Hehe Fan, and Yi Yang. Osda agent: Leveraging large language models for de novo design of organic structure directing agents. In The Thirteenth International Conference on Learning Representations, 2025c.Zhiting Hu and Tianmin Shu. Language models, agent models, and world models: The law for machine reasoning and planning. arXiv preprint arXiv:2312.05230, 2023. Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R- Zero: Self- evolving reasoning llm from zero data. arXiv preprint arXiv:2508.05004, 2025. Dong Huang, Jie M Zhang, Michael Luck, Qingwen Bu, Yuhao Qing, and Heming Cui. AgentCoder: Multi- agent- based code generation with iterative testing and optimisation. arXiv preprint arXiv:2312.13010, 2023a.Jen- tse Huang, Jiaxu Zhou, Tailin Jin, Xuhui Zhou, Zixi Chen, Wenxuan Wang, Youliang Yuan, Michael R Lyu, and Maarten Sap. On the resilience of llm- based multi- agent collaboration with faulty agents. arXiv preprint arXiv:2408.00989, 2024a.Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. Understanding the planning of llm agents: A survey. arXiv preprint arXiv:2402.02716, 2024b.Yue Huang, Jiawen Shi, Yuan Li, Chenrui Fan, Siyuan Wu, Qihui Zhang, Yixin Liu, Pan Zhou, Yao Wan, Neil Zhenqiang Gong, et al. Metatool benchmark for large language models: Deciding whether to use tools and which to use. arXiv preprint arXiv:2310.03128, 2023b.Zhen Huang, Haoyang Zou, Xuefeng Li, Yixiu Liu, Yuxiang Zheng, Ethan Chern, Shijie Xia, Yiwei Qin, Weizhe Yuan, and Pengfei Liu. O1 replication journey- part 2: Surpassing o1- preview through simple distillation, big progress or bitter lesson? arXiv preprint arXiv:2411.16489, 2024c.Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5- coder technical report. arXiv preprint arXiv:2409.12186, 2024. Yoshitaka Inoue, Tianqi Song, Xinling Wang, Augustin Luna, and Tianfan Fu. Drugagent: Multi- agent large language model- based reasoning for drug- target interaction prediction. In ICLR 2025 Workshop on Machine Learning for Genomics Explorations, 2025. Md. Ashraful Islam, Mohammed Eunus Ali, and Md. Rizwan Parvez. MapCoder: Multi- agent code generation for competitive problem solving. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 4912- 4944, 2024. Md. Ashraful Islam, Mohammed Eunus Ali, and Md. Rizwan Parvez. CodeSim: Multi- agent code generation and problem solving through simulation- driven planning and debugging. In Findings of the Association for Computational Linguistics: NAACL, 2025. Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El- Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. CoRR, 2024. Cong Jiang and Xiaolei Yang. Agentsbench: A multi- agent llm simulation framework for legal judgment prediction. Systems, 13(8):641, 2025.
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. A survey on large language models for code generation. arXiv preprint arXiv:2406.00515, 2024.
Fangkai Jiao, Chengwei Qin, Zhengyuan Liu, Nancy F. Chen, and Shafiq Joty. Learning planning- based reasoning by trajectories collection and process reward synthesizing. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 334- 350, 2024.
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. SWE- bench: Can language models resolve real- world github issues? In The Twelfth International Conference on Learning Representations, 2024.
Haolin Jin, Zechao Sun, and Huaming Chen. RGD: Multi- LLM based agent debugger via refinement and generation guidance. In 2024 IEEE International Conference on Agents (ICA), pages 136- 141. IEEE, 2024.
Mingyu Jin, Weidi Luo, Stao Cheng, Xinyi Wang, Wenyue Hua, Ruxixiang Yang, William Yang Wang, and Yongfeng Zhang. Disentangling memory and reasoning ability in large language models. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1681- 1701, 2025.
Zixuan Ke, Austin Xu, Yifei Ming, Xuan- Phi Nguyen, Caiming Xiong, and Shafiq Joty. MAS- ZERO: Designing multi- agent systems with zero supervision. arXiv preprint arXiv:2505.14996, 2025.
Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R. Bowman, Tim Rocktäschel, and Ethan Perez. Debating with more persuasive llms leads to more truthful answers. In Forty- first International Conference on Machine Learning, 2024.
Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik S Chan, Xuhai Xu, Daniel McDuff, Hyeonhoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae W Park. MDAgents: An adaptive collaboration of llms for medical decision- making. Advances in Neural Information Processing Systems, 37:79410- 79452, 2024.
Ronny Ko, Jiseong Jeong, Shuyuan Zheng, Chuan Xiao, Tae- Wan Kim, Makoto Onizuka, and Won- Yong Shin. Seven security challenges that must be solved in cross- domain multi- agent llm systems. arXiv preprint arXiv:2505.23847, 2025.
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po- Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 881- 905, 2024.
Dezhang Kong, Shi Lin, Zhenhua Xu, Zhebo Wang, Minghao Li, Yufeng Li, Yilun Zhang, Hujin Peng, Zeyang Sha, Yuyuan Li, Changting Lin, Xun Wang, Xuan Liu, Ningyu Zhang, Chaochao Chen, Muhammad Khurram Khan, and Meng Han. A survey of llm- driven ai agent communication: Protocols, security risks, and defense countermeasures, 2025.
Igor Kononenko. Machine learning for medical diagnosis: history, state of the art and perspective. Artificial Intelligence in Medicine, 23(1):89- 109, 2001. ISSN 0933- 3657. doi: https://doi.org/10.1016/S0933- 3657(01)00077- X.
Naveen Krishnan. Advancing multi- agent systems through model context protocol: Architecture, implementation, and applications. arXiv preprint arXiv:2504.21030, 2025.
Bespoke Labs. Bespoke- stratos: The unreasonable effectiveness of reasoning distillation. www.bespokelabs.ai/blog/bespoke- stratos- the- unreasonable- effectiveness- of- reasoning- distillation, 2025. Accessed: 2025- 01- 22.
Hanyu Lai, Xiao Liu, Iat Long Iong, Shuntian Yao, Yuxuan Chen, Pengbo Shen, Hao Yu, Hanchen Zhang, Xiaohan Zhang, Yuxiao Dong, and Jie Tang. AutoWebGLM: A large language model- based web navigating agent. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5295- 5306. ACM, 2024a.
Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng, and Jiaya Jia. Step- DPO: Step- wise preference optimization for long- chain reasoning of llms. arXiv preprint arXiv:2406.18629, 2024b.
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post- training. arXiv preprint arXiv:2411.15124, 2024.
Greg Landrum. Rdkit documentation. Release, 1(1- 79):4, 2013.
Cheryl Lee, Chunqiu Steven Xia, Longji Yang, Jen- tse Huang, Zhouruixin Zhu, Lingming Zhang, and Michael R Lyu. A unified debugging approach via llm- based multi- agent synergy. arXiv preprint arXiv:2404.17153, 2024a.
Dongkyu Lee, Chandana Satya Prakash, Jack FitzGerald, and Jens Lehmann. MATTER: memory- augmented transformer using heterogeneous knowledge sources. In Findings of the Association for Computational Linguistics, pages 16110- 16121, 2024b.
Juyong Lee, Dongyoon Hahm, June Suk Choi, W Bradley Knox, and Kimin Lee. MobileSafetyBench: Evaluating safety of autonomous agents in mobile device control. arXiv preprint arXiv:2410.17520, 2024c.
Kuang- Huei Lee, Xinyun Chen, Hiroki Furuta, John F. Canny, and Ian Fischer. A human- inspired reading agent with gist memory of very long contexts. In Forty- first International Conference on Machine Learning, 2024d.
Hui Yi Leong and Yuqing Wu. DynaSwarm: Dynamically graph structure selection for llm- based multi- agent system. arXiv preprint arXiv:2507.23261, 2025.
Binxu Li, Tiankai Yan, Yuanting Pan, Jie Luo, Ruiyang Ji, Jiayuan Ding, Zhe Xu, Shilong Liu, Hayyu Dong, Zihao Lin, et al. MMedAgent: Learning to use medical tools with multi- modal agent. arXiv preprint arXiv:2407.02403, 2024a.
Boyi Li, Zhonghan Zhao, Der- Horng Lee, and Gaoang Wang. Adaptive graph pruning for multi- agent communication. arXiv preprint arXiv:2506.02951, 2025a.
Chengpeng Li, Zhengyang Tang, Ziniu Li, Mingfeng Xue, Keqin Bao, Tian Ding, Ruoyu Sun, Benyou Wang, Xiang Wang, Junyang Lin, et al. CoRT: Code- integrated reasoning within thinking. arXiv preprint arXiv:2506.09820, 2025b.
Chengpeng Li, Mingfeng Xue, Zhenru Zhang, Jiaxi Yang, Beichen Zhang, Xiang Wang, Bowen Yu, Binyuan Hui, Junyang Lin, and Dayiheng Liu. START: Self- taught reasoner with tools. arXiv preprint arXiv:2503.04625, 2025c.
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for “mind” exploration of large language model society. In Thirty- seventh Conference on Neural Information Processing Systems, 2023a.
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. LLMs- as- Judges: a comprehensive survey on llm- based evaluation methods. arXiv preprint arXiv:2412.05579, 2024b.
Junkai Li, Yunghwei Lai, Weitao Li, Jingyi Ren, Meng Zhang, Xinhui Kang, Siyu Wang, Peng Li, Ya- Qin Zhang, Weizhi Ma, et al. Agent hospital: A simulacrum of hospital with evolvable medical agents. arXiv preprint arXiv:2405.02957, 2024c.
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API- Bank: A comprehensive benchmark for tool- augmented llms. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3102- 3115, 2023b.
Pengxiang Li, Zhi Gao, Bofei Zhang, Yapeng Mi, Xiaojian Ma, Chenrui Shi, Tao Yuan, Yuwei Wu, Yunde Jia, Song- Chun Zhu, et al. Iterative tool usage exploration for multimodal agents via step- wise preference tuning. arXiv preprint arXiv:2504.21561, 2025d.
Shilong Li, Yancheng He, Hangyu Guo, Xingyuan Bu, Ge Bai, Jie Liu, Jiaheng Liu, Xingwei Qu, Yangguang Li, Wanli Ouyang, Wenbo Su, and Bo Zheng. GraphReader: Building graph- based agent to enhance long- context abilities of large language models. In Findings of the Association for Computational Linguistics: EMNLP, pages 12758- 12786, 2024d.
Shilong Li, Xingyuan Bu, Wenjie Wang, Jiaheng Liu, Jun Dong, Haoyang He, Hao Lu, Haozhe Zhang, Chenchen Jing, Zhen Li, et al. MM- BrowseComp: A comprehensive benchmark for multimodal browsing agents. arXiv preprint arXiv:2508.13186, 2024e.
Xiangyu Li, Yawen Zeng, Xiaofen Xing, Jin Xu, and Xiangmin Xu. HedgeAgents: A balanced- aware multi- agent financial trading system. In Companion Proceedings of the ACM on Web Conference 2025, pages 296- 305, 2025f.
Xiaonan Li and Xipeng Qiu. MoT: Memory- of- thought enables chatgpt to self- improve. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6354- 6374, 2023.
Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yutao Zhu, Yongkang Wu, Ji- Rong Wen, and Zhicheng Dou. WebThinker: Empowering large reasoning models with deep research capability. arXiv preprint arXiv:2504.21776, 2025g.
Xin Sky Li, Qizhi Chu, Yubin Chen, Yang Liu, Yaoqi Liu, Zekai Yu, Weize Chen, Chen Qian, Chuan Shi, and Cheng Yang. GraphTeam: Facilitating large language model- based graph analysis via multi- agent collaboration. arXiv preprint arXiv:2410.18032, 2024e.
Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. A survey on llm- based multi- agent systems: workflow, infrastructure, and challenges. Vicinagearth, 1(1):9, 2024f.
Yang Li, Yangyang Yu, Haohang Li, Zhi Chen, and Khaldoun Khashanah. TradingGPT: Multi- agent system with layered memory and distinct characters for enhanced financial trading performance. arXiv preprint arXiv:2309.03736, 2023c.
Yaoru Li, Shunyu Liu, Tongya Zheng, and Mingli Song. Parallelized planning- acting for efficient LLM- based multi- agent systems. arXiv preprint arXiv:2503.03505, 2025h.
Yunxuan Li, Yibing Du, Jiageng Zhang, Le Hou, Peter Grabowski, Yeqing Li, and Eugene Ie. Improving multi- agent debate with sparse communication topology. In Findings of the Association for Computational Linguistics: EMNLP, pages 7281- 7294. Association for Computational Linguistics, 2024g.
Zelong Li, Shuyuan Xu, Kai Mei, Wenyue Hua, Balaji Rama, Om Raheja, Hao Wang, He Zhu, and Yongfeng Zhang. AutoFlow: Automated workflow generation for large language model agents. arXiv preprint arXiv:2407.12821, 2024h.
Zhuoqun Li, Xuanang Chen, Haiyang Yu, Hongyu Lin, Yaojie Lu, Qiaoyu Yang, Fei Huang, Xianpei Han, Le Sun, and Yongbin Li. StructRAG: Boosting knowledge intensive reasoning of llms via inference- time hybrid information structurization. In The Thirteenth International Conference on Learning Representations, 2025i.
Zihao Li, Weiwei Yi, and Jiahong Chen. Accuracy paradox in large language models: Regulating hallucination risks in generative ai. arXiv preprint, 2025j.
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinking in large language models through multi- agen debate. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17889- 17904, 2024.
Junwei Liao, Muning Wen, Jun Wang, and Weinan Zhang. MARFT: Multi- agent reinforcement fine- tuning. arXiv preprint arXiv:2504.16129, 2025.
Xiaoqiang Lin, Zhongxiang Dai, Arun Verma, See- Kiong Ng, Patrick Jaillet, and Bryan Kian Hsiang Low. Prompt optimization with human feedback. arXiv preprint arXiv:2405.17346, 2024a.
Xiaoqiang Lin, Zhaoxuan Wu, Zhongxiang Dai, Wenyang Hu, Yao Shu, See- Kiong Ng, Patrick Jaillet, and Bryan Kian Hsiang Low. Use your INSTINCT: instruction optimization for llms using neural bandits coupled with transformers. In Forty- first International Conference on Machine Learning, 2024b.
Yi- Cheng Lin, Kang- Chieh Chen, Zhe- Yan Li, Tzu- Heng Wu, Tzu- Hsuan Wu, Kuan- Yu Chen, Hung- yi Lee, and Yun- Nung Chen. Creativity in llm- based multi- agent systems: A survey. arXiv preprint arXiv:2505.21116, 2025.
Bang Liu, Xinfeng Li, Jiayi Zhang, Jinlin Wang, Tanjin He, Sirui Hong, Hongzhang Liu, Shaokun Zhang, Kaitao Song, Kunlun Zhu, et al. Advances and challenges in foundation agents: From brain- inspired intelligence to evolutionary, collaborative, and safe systems. arXiv preprint arXiv:2504.01990, 2025a.
Bo Liu, Leon Guertler, Simon Yu, Zichen Liu, Penghui Qi, Daniel Balcells, Mickel Liu, Cheston Tan, Weiyan Shi, Min Lin, et al. SPIRAL: Self- play on zero- sum games incentivizes reasoning via multi- agent multi- turn reinforcement learning. arXiv preprint arXiv:2506.24119, 2025b.
Chris Yuhao Liu, Liang Zeng, Jiacai Liu, Rui Yan, Jujie He, Chaojie Wang, Shuicheng Yan, Yang Liu, and Yahui Zhou. Skywork- reward: Bag of tricks for reward modeling in llms. arXiv preprint arXiv:2410.18451, 2024a.
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxiang Zhang, Jiacheng Xu, et al. Skywork- reward- v2: Scaling preference data curation via human- ai synergy. arXiv preprint arXiv:2507.01352, 2025c.
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157- 173, 2024b.
Siwei Liu, Jinyuan Fang, Han Zhou, Yingxu Wang, and Zaiqiao Meng. SEW: Self- evolving agentic workflows for automated code generation. arXiv preprint arXiv:2505.16646, 2025d.
Wei Liu, Junlong Li, Xiwen Zhang, Fan Zhou, Yu Cheng, and Junxian He. Diving into self- evolving training for multimodal reasoning. In Forty- second International Conference on Machine Learning, 2025e.
Wei Liu, Ruochen Zhou, Yiyun Deng, Yuzhen Huang, Junting Liu, Yuntian Deng, Yizhe Zhang, and Junxian He. Learn to reason efficiently with adaptive length- based reward shaping. arXiv preprint arXiv:2505.15612, 2025f.
Weiwen Liu, Xu Huang, Xingshan Zeng, Xinlong Hao, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, Zezhong Wang, Yuxian Wang, Wu Ning, Yutai Hou, Bin Wang, Chuhan Wu, Xinzhi Wang, Yong Liu, Yasheng Wang, Duyu Tang, Dandan Tu, Lifeng Shang, Xin Jiang, Ruiming Tang, Defu Lian, Qun Liu, and
Enhong Chen. ToolACE: Winning the points of LLM function calling. In The Thirteenth International Conference on Learning Representations, 2025g.
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. AgentBench: Evaluating llms as agents. arXiv preprint arXiv:2308.03688, 2023a.
Yanming Liu, Xinyue Peng, Jiannan Cao, Shi Bo, Yuwei Zhang, Xuhong Zhang, Sheng Cheng, Xun Wang, Jianwei Yin, and Tianyu Du. Tool- Planner: Task planning with clusters across multiple tools. In The Thirteenth International Conference on Learning Representations, 2025h.
Yixin Liu, Guibin Zhang, Kun Wang, Shiyuan Li, and Shirui Pan. Graph- augmented large language model agents: Current progress and future prospects. arXiv preprint arXiv:2507.21407, 2025i.
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. Dynamic LLM- Agent network: An LLM- agent collaboration framework with agent team optimization. arXiv preprint arXiv:2310.02170, 2023b.
Google LLC and A2A Project Contributors. Agent2Agent (A2A) Protocol. https://github.com/a2aproject/A2A. Apache License 2.0, accessed 2025- 07- 31.
Lin Long, Yichen He, Wentao Ye, Yiyuan Pan, Yuan Lin, Hang Li, Junbo Zhao, and Wei Li. Seeing, listening, remembering, and reasoning: A multimodal agent with long- term memory. arXiv preprint arXiv:2508.09736, 2025.
Manikanta Loya, Divya Sinha, and Richard Futrell. Exploring the sensitivity of llms’ decision- making capabilities: Insights from prompt variations and hyperparameters. In Findings of the Association for Computational Linguistics: EMNLP, pages 3711- 3716, 2023.
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist: Towards fully automated open- ended scientific discovery. arXiv preprint arXiv:2408.06292, 2024a.
Junru Lu, Siyu An, Mingbao Lin, Gabriele Pergola, Yulan He, Di Yin, Xing Sun, and Yunsheng Wu. MemoChat: Tuning LLMs to use mems for consistent long- range open- domain conversation. arXiv preprint arXiv:2308.08239, 2023.
Siyuan Lu, Jiaqi Shao, Bing Luo, and Tao Lin. MorphAgent: Empowering agents through self- evolving profiles and decentralized collaboration. arXiv preprint arXiv:2410.19048, 2024b.
Yao Lu, Jiayi Wang, Raphael Tang, Sebastian Riedel, and Pontus Stenotorp. Strings from the library of babel: Random sampling as a strong baseline for prompt optimisation. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2221- 2231, 2024c.
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, et al. Large language model agent: A survey on methodology, applications and challenges. arXiv preprint arXiv:2505.21460, 2025a.
Yichen Luo, Yebo Feng, Jiahua Xu, Paolo Tasca, and Yang Liu. LLM- powered multi- agent system for automated crypto portfolio management. arXiv preprint arXiv:2501.00826, 2025b.
Andres M. Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D White, and Philippe Schwaller. Augmenting large language models with chemistry tools. Nature Machine Intelligence, 6(5):525- 535, 2024.
Xiaowen Ma, Chenyang Lin, Yao Zhang, Volker Tresp, and Yunpu Ma. Agentic neural networks: Self- evolving multi- agent systems via textual backpropagation. arXiv preprint arXiv:2506.09046, 2025.
Yubo Ma, Zhibin Gou, Junheng Hao, Ruochen Xu, Shuohang Wang, Liangming Pan, Yujiu Yang, Yixin Cao, and Aixin Sun. SciAgent: Tool- augmented language models for scientific reasoning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing 2024, pages 15701- 15736, 2024.
Annan Madaan, Niket Tandon, Prakhar Gupta, Skyler Halliman, Luyu Gao, Sarah Wiegrefe, Uri Alon, Nouna Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self- Refine: Iterative refinement with self- feedback. Advances in Neural Information Processing Systems, pages 46534- 46594, 2023.
Nour Makke and Sanjay Chawla. Interpretable scientific discovery with symbolic regression: a review. Artificial Intelligence Review, 57(1):2, 2024.
Raphael Mannadiar and Hans Vangheluwe. Debugging in domain- specific modelling. In International Conference on Software Language Engineering, pages 276- 285. Springer, 2010.
Samuele Marro and Agora Protocol Contributors. Agora Protocol (AGORA). https://agoraprotocol.org/. MIT License, accessed 2025- 07- 31.
Andrew D McNaughton, Gautham Krishna Sankar Ramalaxmi, Agustin Kruel, Carter R Knutson, Rohith A Varikoti, and Neeraj Kumar. Cactus: Chemistry agent connecting tool usage to science. ACS omega, 9(46):46563- 46573, 2024.
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: a benchmark for general ai assistants. In The Twelfth International Conference on Learning Representations, 2023.
Yingqian Min, Zhipeng Chen, Jinhao Jiang, Jie Chen, Jia Deng, Yiwen Hu, Yiru Tang, Jiapeng Wang, Xiaoxue Cheng, Huatong Song, et al. Imitate, explore, and self- improve: A reproduction report on slow- thinking reasoning systems. arXiv preprint arXiv:2412.09413, 2024.
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D. Manning. Fast model editing at scale. In The Tenth International Conference on Learning Representations, 2022.
Ali Modarressi, Ayyoub Imani, Mohsen Fayyaz, and Hinrich Schütze. RET- LLM: Towards a general read- write memory for large language models. arXiv preprint arXiv:2305.14322, 2023.
Sumeet Ramesh Motwani, Chandler Smith, Rocktim Jyoti Das, Rafael Rafailov, Ivan Laptev, Philip HS Torr, Fabio Pizzati, Ronald Clark, and Christian Schroeder de Witt. MALT: Improving reasoning with multi- agent llm training. arXiv preprint arXiv:2412.01928, 2024.
Jaap MJ Murre and Joeri Dros. Replication and analysis of ebbinghaus’ forgetting curve. PloS one, 10(7):e0120644, 2015.
Magnus Müller and Gregor Žunič. Browser use: Enable AI to control your browser, 2024. https://github.com/browser- use/browser- use.
Deepak Nathani, Lovish Madaan, Nicholas Roberts, Nikolay Bashlykov, Ajay Menon, Vincent Moens, Amar Budhiraja, Despoina Magka, Vladislav Vorotilov, Gaurav Chaurasia, et al. MLGym: A new framework and benchmark for advancing ai research agents. arXiv preprint arXiv:2502.14499, 2025.
Ansong Ni, Srini Iyer, Dragomir Radev, Veselin Stoyanov, Wen- tau Yih, Sida Wang, and Xi Victoria Lin. LEVER: Learning to verify language- to- code generation with execution. In International Conference on Machine Learning, pages 26106- 26128. PMLR, 2023.
Ansong Ni, Miltiadis Allamanis, Arman Cohan, Yinlin Deng, Kensen Shi, Charles Sutton, and Pengcheng Yin. NExT: Teaching large language models to reason about code execution. In Forty- first International Conference on Machine Learning, 2024.
Boye Niu, Yiliao Song, Kai Lian, Yifan Shen, Yu Yao, Kun Zhang, and Tongliang Liu. Flow: Modularized agentic workflow automation. In The Thirteenth International Conference on Learning Representations, 2025.
Alexander Novikov, Ngan Vu, Marvin Eisenberger, Emilien Dupont, Po- Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. AlphaEvolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131, 2025.
Krista Opsahl- Ong, Michael J. Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. Optimizing instructions and demonstrations for multi- stage language model programs. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9340- 9366, 2024.
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730- 27744, 2022.
Charles Packer, Vivian Fang, Shishir G Patil, Kevin Lin, Sarah Wooders, and Joseph E Gonzalez. MemGPT: Towards llms as operating systems. arXiv preprint arXiv:2310.08560, 2023.
Alexander Pan, Jun Shern Chan, Andy Zou, Nathaniel Li, Steven Basart, Thomas Woodside, Hanlin Zhang, Scott Emmons, and Dan Hendrycks. Do the rewards justify the means? measuring trade- offs between rewards and ethical behavior in the machiavelli benchmark. In International conference on machine learning, pages 26837- 26867. PMLR, 2023.
Melissa Z Pan, Mert Cemri, Lakshya A Agrawal, Shuyi Yang, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Kannan Ramchandran, Dan Klein, Joseph E. Gonzalez, Matei Zaharia, and Ion Stoica. Why do Multi- Agent systems fail? In ICLR 2025 Workshop on Building Trust in Language Models and Applications, 2025a.
Rui Pan, Shuo Xing, Shizhe Diao, Wenhe Sun, Xiang Liu, Kashun Shum, Jipeng Zhang, Renjie Pi, and Tong Zhang. Plum: Prompt learning using metaheuristics. In Findings of the Association for Computational Linguistics, pages 2177- 2197, 2024a.
Ruwei Pan, Hongyu Zhang, and Chao Liu. CodeCoR: An llm- based self- reflective multi- agent framework for code generation. arXiv preprint arXiv:2501.07811, 2025b.
Yichen Pan, Dehan Kong, Sida Zhou, Cheng Cui, Yifei Leng, Bing Jiang, Hangyu Liu, Yanyi Shang, Shuyan Zhou, Tongshuang Wu, et al. WebCanvas: Benchmarking web agents in online environments. arXiv preprint arXiv:2406.12373, 2024b.
Chanwoo Park, Seungju Han, Xingzhi Guo, Asuman E. Ozdaglar, Kaiqing Zhang, and Joo- Kyung Kim. MAPoRL: Multi- agent post- co- training for collaborative large language models with reinforcement learning. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 30215- 30248, 2025.
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology, pages 1- 22, 2023.
Junyeong Park, Junmo Cho, and Sungjin Ahn. MrSteve: Instruction- following agents in minecraft with what- where- when memory. arXiv preprint arXiv:2411.06736, 2024.
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive APIs. Advances in Neural Information Processing Systems, 37:126544- 126565, 2024.
Anthropic PBC and Model Context Protocol Contributors. Model Context Protocol (MCP). https://modelcontextprotocol.io/overview. MIT License, accessed 2025- 07- 31.
Jonas Pfeiffer, Aishwarya Kamath, Andreas Ruckle, Kyunghyun Cho, and Iryna Gurevych. AdapterFusion: Nondestructive task composition for transfer learning. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, pages 487- 503, 2021.
Akshara Prabhakar, Zuxin Liu, Ming Zhu, Jianguo Zhang, Tulika Awalgaonkar, Shiyu Wang, Zhiwei Liu, Haolin Chen, Thai Hoang, Juan Carlos Niebles, et al. APIGen- MT: Agentic pipeline for multi- turn data generation via simulated agent- human interplay. arXiv preprint arXiv:2504.03601, 2025.
Archiki Prasad, Peter Hase, Xiang Zhou, and Mohit Bansal. GRIPS: Gradient- free, edit- based instruction search for prompting large language models. In Andreas Vlachos and Isabelle Augenstein, editors, Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 3827- 3846, 2023.
Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with “gradient descent” and beam search. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7957- 7968, 2023.
Yingming Pu, Tao Lin, and Hongyu Chen. PiFlow: Principle- aware scientific discovery with multi- agent collaboration. arXiv preprint arXiv:2505.15047, 2025.
Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Garg, and Rafael Rafailov. Agent Q: Advanced reasoning and learning for autonomous ai agents. arXiv preprint arXiv:2408.07199, 2024.
Meghana Puvvadi, Sai Kumar Arava, Adarsh Santoria, Sesa Sai Prasanna Chennupati, and Harsha Vardhan Puvvadi. Coding agents: A comprehensive survey of automated aug fixing systems and benchmarks. In 2025 IEEE 14th International Conference on Communication Systems and Network Technologies (CSNT), pages 680- 686. IEEE, 2025.
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative agents for software development. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15174- 15186, 2024.
Cheng Qian, Chi Han, Yi R Fung, Yujia Qin, Zhiyuan Liu, and Heng Ji. CREATOR: Tool creation for disentangling abstract and concrete reasoning of large language models. In 2023 Findings of the Association for Computational Linguistics: EMNLP 2023, pages 6922- 6939. Association for Computational Linguistics (ACL), 2023.
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xusi Chen, Dilek Hakkani- Tur, Gokhan Tur, and Heng Ji. ToolRL: Reward is all tool learning needs. arXiv preprint arXiv:2504.13958, 2025a.
Yiyue Qian, Shinan Zhang, Yun Zhou, Haibo Ding, Diego Socolinsky, and Yi Zhang. Enhancing LLM- as- a- Judge via multi- agent collaboration. amazon.science, 2025b.
Shuofei Qiao, Runnan Fang, Ningyu Zhang, Yuqi Zhu, Xiang Chen, Shumin Deng, Yong Jiang, Pengjun Xie, Fei Huang, and Huajun Chen. Agent planning with world knowledge model. In Advances in Neural Information Processing Systems, 2024.
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real- world apis. In The Twelfth International Conference on Learning Representations, 2024.
Jiahao Qiu, Xuan Qi, Tongcheng Zhang, Xinzhe Juan, Jiancheng Guo, Yifu Lu, Yimin Wang, Zixin Yao, Qihan Ren, Xun Jiang, et al. Alita: Generalist agent enabling scalable agentic reasoning with minimal predefinition and maximal self- evolution. arXiv preprint arXiv:2505.20286, 2025.
Changle Qu, Sunhao Dai, Xiaochi Wei, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Jun Xu, and Ji- Rong Wen. From exploration to mastery: Enabling LLMs to master tools via self- driven interactions. In The Thirteenth International Conference on Learning Representations, 2025.
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Thirty- seventh Conference on Neural Information Processing Systems, 2023.
Asif Rahman, Veljko Cvetkovic, Kathleen Reece, Aidan Walters, Yasir Hassan, Aneesh Tummeti, Bryan Torres, Denise Cooney, Margaret Ellis, and Dimitrios S Nikolopoulos. MARCO: Multi- agent code optimization with real- time knowledge integration for high- performance computing. arXiv preprint arXiv:2505.03906, 2025.
Zeeshan Rasheed, Malik Abdul Sami, Kai- Kristian Kemell, Muhammad Waseem, Mika Saari, Kari Systa, and Pekka Abrahamsson. CodePori: Large- scale system for autonomous software development using multi- agent technology. arXiv preprint arXiv:2402.01411, 2024.
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell- Ajala, et al. AndroidWorld: A dynamic benchmarking environment for autonomous agents. arXiv preprint arXiv:2405.14573, 2024.
Shaina Raza, Ranjan Sapkota, Manoj Karkee, and Christos Emmanouilidis. TRiSM for agentic ai: A review of trust, risk, and security management in him- based agentic multi- agent systems. arXiv preprint arXiv:2506.04133, 2025.
Aymeric Roucher, Albert Villanova del Moral, Thomas Wolf, Leandro von Werra, and Erik Kaunismaki. “smolagents”: a smol library to build great agentic systems. https://github.com/huggingface/smolagents, 2025.
Kai Ruan, Xuan Wang, Jixiang Hong, Peng Wang, Yang Lin, and Hao Sun. Liveideabench: Evaluating llms’ divergent thinking for scientific idea generation with minimal context. arXiv preprint arXiv:2412.17596, 2024.
Kai Ruan, Mowen Huang, Ji- Rong Wen, and Hao Sun. Benchmarking LLMs’ swarm intelligence. arXiv preprint arXiv:2505.04364, 2025.
Ali Safaya and Deniz Yuret. Neurocache: Efficient vector retrieval for long- range language modeling. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 870- 883, 2024.
Saket Sarin, Sunil K Singh, Sudhakar Kumar, Shivam Goyal, Brij Bhooshan Gupta, Wadee Alhalabi, and Varsha Arya. Unleashing the power of multi- agent reinforcement learning for algorithmic trading in the digital financial frontier and enterprise information systems. Computers, Materials & Continua, 80(2), 2024.
Anjana Sarkar and Soumyendu Sarkar. Survey of LLM agent communication with mcp: A software design pattern centric review. arXiv preprint arXiv:2506.05364, 2025.
Timo Schick, Jane Dwivedi- Yu, Roberto Dessi, Roberta Raleanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. ToolFormer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36:68539- 68551, 2023.
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. Agent Clinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments. arXiv preprint arXiv:2405.07960, 2024.
Lennart Schneider, Martin Wistuba, Aaron Klein, Jacek Golebiowski, Giovanni Zappella, and Felice Antonio Merra. Hyperband- based bayesian optimization for black- box prompt selection. In Forty- second International Conference on Machine Learning, 2025.
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. Rewarding progress: Scaling automated process verifiers for LLM reasoning. In The Thirteenth International Conference on Learning Representations, 2025.
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
Chengshuai Shi, Kun Yang, Jing Yang, and Cong Shen. Best arm identification for prompt learning under a limited budget. arXiv preprint arXiv:2402.09723, 2024a.
Juanming Shi, Qinglang Guo, Yong Liao, and Shenglin Liang. Legalgpt: Legal chain of thought for the legal large language model multi- agent framework. In International Conference on Intelligent Computing, pages 25- 37. Springer, 2024b.
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36:8634- 8652, 2023.
Mohit Shridhar, Xingdi Yuan, Marc- Alexandre Cote, Yomatan Bisk, Adam Trischler, and Mathew J. Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning. In 9th International Conference on Learning Representations, 2021.
Arnav Singhvi, Manish Shetty, Shangyin Tan, Christopher Potts, Koushik Sen, Matei Zaharia, and Omar Khattab. Dspy assertions: Computational constraints for self- refining language model pipelines. arXiv preprint arXiv:2312.13382, 2023.
Linxin Song, Jiale Liu, Jieyu Zhang, Shaokun Zhang, Ao Luo, Shijian Wang, Qingyun Wu, and Chi Wang. Adaptive in- conversation team building for language model agents. arXiv preprint arXiv:2405.19425, 2024.
Dilara Soylu, Christopher Potts, and Omar Khattab. Fine- Tuning and Prompt Optimization: Two great steps that work better together. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10696- 10710, 2024.
Olly Styles, Sam Miller, Patricio Cerda- Mardini, Tanaya Guha, Victor Sanchez, and Bertie Vidgen. Workbench: a benchmark dataset for agents in a realistic workplace setting. arXiv preprint arXiv:2405.00823, 2024.
Jinwei Su, Yinghui Xia, Ronghua Shi, Jianhui Wang, Jianuo Huang, Yijin Wang, TIANYU SHI, Yang Jingsong, and Lewei He. DebFlow: Automating agent creation via agent debate. In ICML 2025 Workshop on Collaborative and Federated Agentic Workflows, 2025.
Vighnesh Subramaniam, Yilun Du, Joshua B Tenenbaum, Antonio Torralba, Shuang Li, and Igor Mordatch. Multiagent finetuning: Self improvement with diverse reasoning chains. arXiv preprint arXiv:2501.05707, 2025.
Emilio Sulis, Stefano Mariani, and Sara Montagna. A survey on agents applications in healthcare: Opportunities, challenges and trends. Computer Methods and Programs in Biomedicine, 236:107525, 2023.
Hao Sun, Alihan Hiyurik, and Mihaela van der Schaar. Query- Dependent prompt evaluation and optimization with offline inverse RL. In The Twelfth International Conference on Learning Representations, 2024a.
Jingyun Sun, Chengxiao Dai, Zhongze Luo, Yangbo Chang, and Yang Li. LawLuo: A Chinese law firm co- run by LLM agents. arXiv preprint arXiv:2407.16252, 2024b.
Zeyi Sun, Ziyu Liu, Yuhang Zang, Yuhang Cao, Xiaoyi Dong, Tong Wu, Dahua Lin, and Jiaqi Wang. SEAgent: Self- evolving computer use agent with autonomous learning from experience. arXiv preprint arXiv:2508.04700, 2025.
Yashar Talebirad and Amirhossein Nadiri. Multi- agent collaboration: Harnessing the power of intelligent llm agents. arXiv preprint arXiv:2306.03314, 2023.
Xiangru Tang, Tianyu Hu, Muyang Ye, Yanjun Shao, Xunjian Yin, Siru Ouyang, Wangchunshu Zhou, Pan Lu, Zhuosheng Zhang, Yilun Zhao, et al. ChemAgent: Self- updating memories in large language models improves chemical reasoning. In The Thirteenth International Conference on Learning Representations, 2025a.
Xiangru Tang, Tianrui Qin, Tianhao Peng, Ziyang Zhou, Daniel Shao, Tingting Du, Xinming Wei, Peng Xia, Fang Wu, He Zhu, et al. Agent kb: Leveraging cross- domain experience for agentic problem solving. arXiv preprint arXiv:2507.06229, 2025b.
Xinyu Tang, Xiaolei Wang, Wayne Xin Zhao, Siyuan Lu, Yaliang Li, and Ji- Rong Wen. Unleashing the potential of large language models as prompt optimizers: Analogical analysis with gradient- based model optimizers. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 25264- 25272, 2025c.
Xunzhu Tang, Kisub Kim, Yewei Song, Cedric Lothritz, Bei Li, Saad Ezzini, Haoye Tian, Jacques Klein, and Tegawendé F Bissyandé. CodeAgent: Autonomous communicative agents for code review. arXiv preprint arXiv:2402.02172, 2024. Yong- En Tian, Yu- Chien Tang, Kuang- Da Wang, An- Zi Yen, and Wen- Chih Peng. Template- based financial report generation in agentic and decomposed information retrieval. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2706- 2710. ACM, 2025. Yuxuan Tong, Xiwen Zhang, Rui Wang, Ruidong Wu, and Junxian He. DART- math: Difficulty- aware rejection tuning for mathematical problem- solving. In The Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024. Khanh- Tung Tran, Dung Dao, Minh- Duong Nguyen, Quoc- Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. Multi- Agent collaboration mechanisms: A survey of LLMs. arXiv preprint arXiv:2501.06322, 2025. Harsh Trivedi, Tushar Khot, Marelke Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. Appworld: A controllable world of apps and people for benchmarking interactive coding agents. arXiv preprint arXiv:2407.18991, 2024. Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don’t always say what they think: Unfaithful explanations in chain- of- thought prompting. In Thirty- seventh Conference on Neural Information Processing Systems, 2023. Tycho FA van der Ouderaa, Markus Nagel, Mart Van Baalen, Yuki M Asano, and Tijmen Blankevoort. The LLM surgeon. arXiv preprint arXiv:2312.17244, 2023. Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating llm generations with a panel of diverse models. arXiv preprint arXiv:2404.18796, 2024. Xingchen Wan, Han Zhou, Ruoxi Sun, and Sercan Ö. Arik. From few to many: Self- improving many- shot reasoners through iterative optimization and generation. In The Thirteenth International Conference on Learning Representations, 2025. Boshi Wang, Hao Fang, Jason Eisner, Benjamin Van Durme, and Yu Su. LLMs in the imaginarium: Tool learning through simulated trial and error. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10583- 10604, 2024a.Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open- ended embodied agent with large language models. Transactions on Machine Learning Research, 2023a.Jize Wang, Ma Zerun, Yining Li, Songyang Zhang, Cailian Chen, Kai Chen, and Xinyi Le. GTA: a benchmark for general tool agents. In The Thirty- eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024b.Junlin Wang, Jue WANG, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture- of- agents enhances large language model capabilities. In The Thirteenth International Conference on Learning Representations, 2025a.Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jitakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6): 186345, 2024c.Ningning Wang, Xavier Hu, Pai Liu, He Zhu, Yue Hou, Heyuan Huang, Shengyu Zhang, Jian Yang, Jiaheng Liu, Ge Zhang, Changwang Zhang, Jun Wang, Yuchen Eleanor Jiang, and Wangchunshu Zhou. Efficient agents: Building effective agents while reducing cost, 2025b.Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math- shepherd: Verify and reinforce llms step- by- step without human annotations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426- 9439, 2024d.Qian Wang, Tianyu Wang, Zhenheng Tang, Qinbin Li, Nuo Chen, Jingsheng Liang, and Bingsheng He. All it takes is one prompt: An autonomous LLM- MA system. In ICLR 2025 Workshop on Foundation Models in the Wild, 2025c.Qingyue Wang, Yanhe Fu, Yanan Cao, Shuai Wang, Zhiliang Tian, and Liang Ding. Recursively summarizing enables long- term dialogue memory in large language models. Neurocomputing, 639:130193, 2025d.Renxi Wang, Xudong Han, Lei Ji, Shu Wang, Timothy Baldwin, and Haonan Li. ToolGen: Unified tool retrieval and calling via generation. In The Thirteenth International Conference on Learning Representations, 2025e.
Shang Wang, Tianqing Zhu, Dayong Ye, and Wanlei Zhou. When machine unlearning meets retrieval- augmented generation (RAG): Keep secret or forget knowledge? arXiv preprint arXiv:2410.15267, 2024e.
Shilong Wang, Guibin Zhang, Miao Yu, Guancheng Wan, Fanci Meng, Chongye Guo, Kun Wang, and Yang Wang. G- Safeguard: A topology- guided security lens and treatment on llm- based multi- agent systems. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7261- 7276, 2025f.
Siyuan Wang, Zhongyu Wei, Yejin Choi, and Xiang Ren. Symbolic working memory enhances language models for complex rule application. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17583- 17604, 2024f.
Wenyi Wang, Hisham A Alyahya, Dylan R Ashley, Oleg Serikov, Dmitrii Khizbullin, Francesco Faccio, and Jürgen Schmidhuber. How to correctly do semantic backpropagation on language- based agentic systems. arXiv preprint arXiv:2412.03624, 2024g.
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better llm agents. In Forty- first International Conference on Machine Learning, 2024h.
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangyu Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, and et al. OpenHands: An open platform for AI software developers as generalist agents. In The Thirteenth International Conference on Learning Representations, 2025g.
Xinyuan Wang, Chenki Li, Zhen Wang, Fan Bai, Haotian Luo, Jiayou Zhang, Nebojsa Jojic, Eric P. Xing, and Zhiting Hu. PromptAgent: Strategic planning with language models enables expert- level prompt optimization. In The Twelfth International Conference on Learning Representations, 2024i.
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self- consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations, 2023b.
Yingxu Wang, Shiqi Fan, Mengzhu Wang, and Siwei Liu. Dynamically adaptive reasoning via LLM- guided mcts for efficient and context- aware KGQA. arXiv preprint arXiv:2508.00719, 2025h.
Yingxu Wang, Siwei Liu, Jinyuan Fang, and Zaiqiao Meng. EvoAgentX: An automated framework for evolving agentic workflows. arXiv preprint arXiv:2507.03616, 2025i.
Yinjie Wang, Ling Yang, Guohao Li, Mengdi Wang, and Bryon Aragam. ScoreFlow: Mastering llm agent workflows via score- based preference optimization. arXiv preprint arXiv:2502.04306, 2025j.
Yiying Wang, Xiaojing Li, Binzhu Wang, Yueyang Zhou, Yingru Lin, Han Ji, Hong Chen, Jinshi Zhang, Fei Yu, Zewei Zhao, et al. PEER: Expertizing domain- specific tasks with a multi- agent framework and tuning methods. arXiv preprint arXiv:2407.06985, 2024j.
Yu Wang and Xi Chen. MIRIX: Multi- agent memory system for llm- based agents. arXiv preprint arXiv:2507.07957, 2025.
Zhiruo Wang, Graham Neubig, and Daniel Fried. TroVE: Inducing verifiable and efficient toolboxes for solving programmatic tasks. In Forty- first International Conference on Machine Learning, 2024k.
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Lingfe Li, Zhengyuan Yang, Xing Jin, Kebin Yu, Minh Nhat Nguyen, Licheng Liu, et al. RAGEN: Understanding self- evolution in llm agents via multi- turn reinforcement learning. arXiv preprint arXiv:2504.20073, 2025k.
Ziyue Wang, Junde Wu, Chang Han Low, and Yaeming Jin. MedAgent- Pros: Towards multi- model evidence- based medical diagnosis via reasoning agentic workflow. arXiv preprint arXiv:2503.18968, 2025l.
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. In Forty- second International Conference on Machine Learning, 2024l.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain- of- Thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, 2022.
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. BrowseComp: A simple yet challenging benchmark for browsing agents. arXiv preprint arXiv:2504.12516, 2025a.
Yangbo Wei, Zhen Huang, Huang Li, Wei W Xing, Ting- Jung Lin, and Lei He. Vflow: Discovering optimal agentic workflows for verilog generation. arXiv preprint arXiv:2504.03723, 2025b.
Bin Wu, Edgar Meij, and Emine Yilmaz. A joint optimization framework for enhancing efficiency of tool utilization in LLM agents. In Findings of the Association for Computational Linguistics, ACL, pages 22361- 22373, 2025a.
Jialong Wu, Wenbiao Yin, Yong Jiang, Zhenglin Wang, Zekun Xi, Runnan Fang, Linhai Zhang, Yulan He, Deyu Zhou, Pengjun Xie, and Pei Huang. WebWalker: Benchmarking llms in web traversal. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10290- 10305, 2025b.
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next- gen llm applications via multi- agent conversations. In First Conference on Language Modeling, 2024a.
Shirley Wu, Parth Sarthi, Shyu Zhao, Aaron Lee, Herumb Shandilya, Adrian Mladenie Grobelnik, Narendra Choudhary, Eddie Huang, Kartlik Subbian, Linjun Zhang, et al. Optimas: Optimizing compound ai systems with globally aligned local rewards. arXiv preprint arXiv:2507.03041, 2025c.
Yurong Wu, Yan Gao, Bin Zhu, Zineng Zhou, Xiaodi Sun, Sheng Yang, Jian- Guang Lou, Zhiming Deng, and Linjun Yang. StraGo: Harnessing strategic guidance for prompt optimization. In Findings of the Association for Computational Linguistics: EMNLP, pages 10043- 10061, 2024b.
Zhaofeng Wu, Linlu Qiu, Alexis Ross, Ekin Akyurek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. Reasoning or reciting? exploring the capabilities and limitations of language models through counterfactual tasks. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1819- 1862, 2024c.
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changbao Jiang, Yicheng Zou, Xiangyang Liu, Zhangxue Yin, Shihan Dou, Rongxiang Weng, Wenjuan Qin, Yongyan Zheng, Xiping Qiu, Xuanjing Huang, Qi Zhang, and Tao Gui. The rise and potential of large language model based agents: a survey. Science China Information Sciences, 68(2), 2025.
Jinyu Xiang, Jiayi Zhang, Zhaoyang Yu, Fengwei Teng, Jinhao Tu, Xinbing Liang, Sirui Hong, Chenglin Wu, and Yuyu Luo. Self- supervised prompt optimization. arXiv preprint arXiv:2502.06853, 2025.
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open- ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040- 52094, 2024.
Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, and Xiaodan Liang. Deepseek- prover: Advancing theorem proving in llms through large- scale synthetic data. arXiv preprint arXiv:2405.14333, 2024.
Huajian Xin, Z.Z. Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, Wenjun Gao, Haowei Zhang, Qihao Zhu, Dejian Yang, Zhibin Gou, Z.F. Wu, Fuli Luo, and Chong Ruan. Deepseek- prover- v1.5: Harnessing proof assistant feedback for reinforcement learning and monte- carlo tree search. In The Thirteenth International Conference on Learning Representations, 2025.
Frank Xing. Designing heterogeneous LLM agents for financial sentiment analysis. ACM Transactions on Management Information Systems, 16(1):1- 24, 2025.
Hanwei Xu, Yujun Chen, Yulun Du, Nan Shao, Yanggang Wang, Haiyu Li, and Zhilin Yang. GPS: genetic prompt search for efficient few- shot learning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 8162- 8171, 2022.
Qiantong Xu, Fenglu Hong, Bo Li, Changran Hu, Zhengyu Chen, and Jian Zhang. On the tool manipulation capability of open- source large language models. arXiv preprint arXiv:2305.16504, 2023.
Tianqi Xu, Linyao Chen, Dai- Jie Wu, Yanjun Chen, Zecheng Zhang, Xiang Yao, Zhiqiang Xie, Yongchao Chen, Shilong Liu, Bochen Qian, et al. Crab: Cross- environment agent benchmark for multimodal language model agents. arXiv preprint arXiv:2407.01511, 2024a.
Tianwen Xu and Fengkui Ju. Multi- agent logic for reasoning about duties and powers in private law. In Proceedings of the Nineteenth International Conference on Artificial Intelligence and Law, pages 361- 370, 2023.
Weijia Xu, Andrzej Banburski, and Nebojsa Jojic. Reprompting: Automated chain- of- thought prompt inference through gibbs sampling. In Forty- first International Conference on Machine Learning, 2024b.
Wujiang Xu, Kai Mei, Hang Gao, Juntao Tan, Zujie Liang, and Yongfeng Zhang. A- MEM: Agentic memory for llm agents. arXiv preprint arXiv:2502.12110, 2025.
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Hinrich Schütze, Volker Tresp, and Yunpu Ma. Memory- R1: Enhancing large language model agents to manage and utilize memories via reinforcement learning. arXiv preprint arXiv:2508.19828, 2025.
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025a.
Chengrun Yang, Xuehli Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. In The Twelfth International Conference on Learning Representations, 2024a.
Hongyang Yang, Boyu Zhang, Neng Wang, Cheng Guo, Xiaoli Zhang, Likun Lin, Junlin Wang, Tianyu Zhou, Mao Guan, Runjia Zhang, et al. Pimrobot: an open- source ar agent platform for financial applications using large language models. arXiv preprint arXiv:2405.14767, 2024b.
Ling Yang, Zhaochen Yu, Tianjun Zhang, Shiyi Cao, Minkai Xu, Wentao Zhang, Joseph E. Gonzalez, and Bin CUI. Buffer of thoughts: Thought- augmented reasoning with large language models. In The Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024c.
Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, and Ying Shan. GPT4Tools: Teaching large language model to use tools via self instruction. In Advances in Neural Information Processing Systems, 2023.
Weiqing Yang, Hanbin Wang, Zhenghao Liu, Xinze Li, Yukun Yan, Shuo Wang, Yu Gu, Minghe Yu, Zhiyuan Liu, and Ge Yu. Enhancing the code debugging ability of llms via communicative agent based data refinement. CoRR, 2024d.
Yingxuan Yang, Huacan Chai, Shuai Shao, Yuanyi Song, Siyuan Qi, Renting Rui, and Weinan Zhang. AgentNet: Decentralized evolutionary coordination for llm- based multi- agent systems. arXiv preprint arXiv:2504.00587, 2025b.
Yingxuan Yang, Huacan Chai, Yuanyi Song, Siyuan Qi, Muning Wen, Ning Li, Junwei Liao, Haoyi Wu, Jianghao Lin, Gaowei Chang, et al. A survey of AI agent protocols. arXiv preprint arXiv:2504.16736, 2025c.
Yingxuan Yang, Qiuying Peng, Jun Wang, Ying Wen, and Weinan Zhang. Unlocking the potential of decentralized llm- based MAS: privacy preservation and monetization in collective intelligence. In Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, pages 2896- 2900, 2025d.
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems, 36: 11809- 11822, 2023a.
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, 2023b.
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R Narasimhan. τ\tauτ - bench: A benchmark for Tool- Agent- User interaction in real- world domains. In The Thirteenth International Conference on Learning Representations, 2025.
Weiran Yao, Shelby Heinecke, Juan Carlos Niebles, Zhiwei Liu, Yihao Feng, Le Xue, Rithesh R. N., Zeyuan Chen, Jianguo Zhang, Devansh Arpit, Ran Xu, Phil Mui, Huan Wang, Caiming Xiong, and Silvio Savarese. Retroformer: Retrospective large language agents with policy gradient optimization. In The Twelfth International Conference on Learning Representations, 2024.
Qinyuan Ye, Maxamed Axmed, Reid Pryzant, and Fereshte Khani. Prompt engineering a prompt engineer. arXiv preprint arXiv:2311.05661, 2023.
Rui Ye, Shuo Tang, Rui Ge, Yaxin Du, Zhenfei Yin, Siheng Chen, and Jing Shao. MAS- GPT: Training LLMs to build LLM- based multi- agent systems. arXiv preprint arXiv:2503.03686, 2025.
Asaf Yehudai, Lilach Eden, Alan Li, Guy Uziel, Yilun Zhao, Roy Bar- Haim, Arman Cohan, and Michal Shmueli- Scheuer. Survey on evaluation of LLM- based agents. arXiv preprint arXiv:2503.16416, 2025.
Fan Yin, Zifeng Wang, I Hsu, Jun Yan, Ke Jiang, Yanfei Chen, Jindong Gu, Long T Le, Kai- Wei Chang, Chen- Yu Lee, et al. Magnet: Multi- turn tool- use data synthesis and distillation via graph translation. arXiv preprint arXiv:2503.07826, 2025.
Shuo Yin, Weihao You, Zhilong Ji, Guoqiang Zhong, and Jinfeng Bai. MuMath- Code: Combining tool- use large language models with multi- perspective data augmentation for mathematical reasoning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4770- 4785, 2024.
Zhangyue Yin, Qiushi Sun, Cheng Chang, Qipeng Guo, Junqi Dai, Xuanjing Huang, and Xipeng Qiu. Exchange- of- Thought: Enhancing large language model capabilities through cross- model communication. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 15135- 15153, 2023.
Junwei Yu, Yepeng Ding, and Hiroyuki Sato. DynTaskMAS: A dynamic task graph- driven framework for asynchronous and parallel LLM- based multi- agent systems. arXiv preprint arXiv:2503.07675, 2025.
Miao Yu, Shilong Wang, Guibin Zhang, Junyuan Mao, Chenlong Yin, Qijiong Liu, Qingsong Wen, Kun Wang, and Yang Wang. NetSafe: Exploring the topological safety of multi- agent networks. arXiv preprint arXiv:2410.15686, 2024a.
Yangyang Yu, Zhiyuan Yao, Haohang Li, Zhiyang Deng, Yuechen Jiang, Yupeng Cao, Zhi Chen, Jordan Suchow, Zhenyu Cui, Rong Liu, et al. Fincon: A synthesized llm multi- agent system with conceptual verbal reinforcement for enhanced financial decision making. Advances in Neural Information Processing Systems, 37:137010- 137045, 2024b.
Lilian Yuan, Yangyi Chen, Xingyao Wang, Yi Fung, Hao Peng, and Heng Ji. CRAFT: Customizing LLMs by creating and retrieving from specialized toolsets. In The Twelfth International Conference on Learning Representations, 2024a.
Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Dongsheng Li, and Deqing Yang. EvoAgent: Towards automatic multi- agent generation via evolutionary algorithms. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 6192- 6217, 2025a.
Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Yongliang Shen, Kan Ren, Dongsheng Li, and Deqing Yang. EASYTOOL: enhancing llm- based agents with concise tool instruction. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 951- 972, 2025b.
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, et al. R- judge: Benchmarking safety risk awareness for llm agents. arXiv preprint arXiv:2401.10019, 2024b.
Weikang Yuan, Junjie Cao, Zhuoren Jiang, Yangyang Kang, Jun Lin, Kaisong Song, Pengwei Yan, Changlong Sun, Xiaozhong Liu, et al. Can large language models grasp legal theories? enhance legal reasoning with insights from multi- agent collaboration. arXiv preprint arXiv:2410.02507, 2024c.
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self- rewarding language models. In Forty- first International Conference on Machine Learning, 2024d.
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. Textgrad: Automatic “differentiation” via text. arXiv preprint arXiv:2406.07496, 2024.
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Pan Lu, Zhi Huang, Carlos Guestrin, and James Zou. Optimizing generative AI by backpropagating language model feedback. Nature, 639(8055):609- 616, 2025.
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. STaR: Bootstrapping reasoning with reasoning. In Advances in Neural Information Processing Systems, volume 35, pages 15476- 15488, 2022.
Ruihong Zeng, Jinyuan Fang, Siwei Liu, and Zaiqiao Meng. On the structural memory of llm agents. arXiv preprint arXiv:2412.15266, 2024a.
Ruihong Zeng, Jinyuan Fang, Siwei Liu, and Zaiqiao Meng. On the structural memory of llm agents. arXiv preprint arXiv:2412.15266, 2024b.
Alexander Zhang, Marcus Dong, Jiaheng Liu, Wei Zhang, Yejie Wang, Jian Yang, Ge Zhang, Tianyu Liu, Zhongyuan Peng, Yingshui Tan, et al. CodeCriticBench: A holistic code critique benchmark for large language models. arXiv preprint arXiv:0502.16614, 2025a.
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. AppAgent: Multimodal agents as smartphone users. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 70:1- 70:20. ACM, 2025b.
Dan Zhang, Sining Zhoubian, Min Cai, Fengzu Li, Lekang Yang, Wei Wang, Tianjiao Dong, Ziniu Hu, Jie Tang, and Yisong Yue. DataSciBench: An llm agent benchmark for data science. arXiv preprint arXiv:2502.13897, 2025c.
Enhao Zhang, Erkang Zhu, Gagan Bansal, Adam Fourney, Hussein Mozannar, and Jack Gerrits. Optimizing sequential multi- step tasks with parallel llm agents. arXiv preprint arXiv:2507.08944, 2025d.
Guibin Zhang, Yanwei Yue, Xiangguo Sun, Guancheng Wan, Miao Yu, Junfeng Fang, Kun Wang, Tianlong Chen, and Dawei Cheng. G- designer: Architecting multi- agent communication topologies via graph neural networks. arXiv preprint arXiv:2410.11782, 2024a.
Guibin Zhang, Muxin Fu, Guancheng Wan, Miao Yu, Kun Wang, and Shuicheng Yan. G- Memory: Tracing hierarchical memory for multi- agent systems. arXiv preprint arXiv:2506.07398, 2025e.
Guibin Zhang, Luyang Niu, Junfeng Fang, Kun Wang, LEI BAI, and Xiang Wang. Multi- agent architecture search via agentic supernet. In Forty- second International Conference on Machine Learning, 2025f.
Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jeffrey Xu Yu, and Tianlong Chen. Cut the crap: An economical communication pipeline for llm- based multi- agent systems. In The Thirteenth International Conference on Learning Representations, 2025g.
Hanglian Zhang, Zhiyao Cui, Ximun Wang, Qiaosheng Zhang, Zhen Wang, Dinghao Wu, and Shuyue Hu. If multi- agent debate is the answer, what is the question. arXiv preprint arXiv:2502.08788, 2025h.
Jenny Zhang, Shengran Hu, Cong Lu, Robert Lange, and Jeff Clune. Darwin godel machine: Open- ended evolution of self- improving agents. arXiv preprint arXiv:2505.22954, 2025i.
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xiong- Hui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. AFlow: Automating agentic workflow generation. In The Thirteenth International Conference on Learning Representations, 2025j.
Jun Zhang, Yuwei Yan, Junbo Yan, Zhiheng Zheng, Jinghua Piao, Depeng Jin, and Yong Li. A parallelized framework for simulating large- scale LLM agents with realistic environments and interactions. In Georg Rehm and Yunyao Li, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track), pages 1339- 1349, Vienna, Austria, July 2025k. Association for Computational Linguistics. ISBN 979- 8- 89176- 288- 6. doi: 10.18653/v1/2025. acl- industry.94.
Kechi Zhang, Zhuo Li, Jin Li, Ge Li, and Zhi Jin. Self- Edit: Fault- aware code editor for code generation. arXiv preprint arXiv:2305.04087, 2023a.
Peiyan Zhang, Haibo Jin, Leyang Hu, Xinnuo Li, Liying Kang, Man Luo, Yangqiu Song, and Haohan Wang. Revolve: Optimizing AI systems by tracking response evolution in textual optimization. In Forty- second International Conference on Machine Learning, 2025l.
Shaokun Zhang, Jieyu Zhang, Jiale Liu, Linxin Song, Chi Wang, Ranjay Krishna, and Qingyun Wu. Offline training of language model agents with functions as learnable weights. In Forty- first International Conference on Machine Learning, 2024b.
Shaokun Zhang, Yi Dong, Jieyu Zhang, Jan Kautz, Bryan Catanzaro, Andrew Tao, Qingyun Wu, Zhiding Yu, and Guilin Liu. Nematron- research- tool- n1: Tool- using language models with reinforced reasoning. arXiv preprint arXiv:2505.00024, 2025m.
Tianjun Zhang, Xuezhi Wang, Denny Zhou, Dale Schuurmans, and Joseph E. Gonzalez. TEMPERA: test- time prompt editing via reinforcement learning. In The Eleventh International Conference on Learning Representations, 2023b.
Wentao Zhang, Ce Cui, Yilei Zhao, Rui Hu, Yang Liu, Yahui Zhou, and Bo An. Agentorchestra: A hierarchical multi- agent framework for general- purpose task solving. arXiv preprint arXiv:2506.12508, 2025n.
Yusen Zhang, Ruoxi Sun, Yanfei Chen, Tomas Pfister, Rui Zhang, and Sercan Arik. Chain of agents: Large language models collaborating on long- context tasks. Advances in Neural Information Processing Systems, 37:132208- 132237, 2024c.
Zeyu Zhang, Quanyu Dai, Xiaobe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji- Rong Wen. A survey on the memory mechanism of large language model based agents. ACM Transactions on Information Systems, 2024d.
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong- Jin Liu, and Gao Huang. Expel: LLM agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 19632- 19642, 2024.
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute Zero: Reinforced self- play reasoning with zero data. arXiv preprint arXiv:2505.03335, 2025a.
Ruochen Zhao, Wenxuan Zhang, Yew Ken Chia, Weiwen Xu, Deli Zhao, and Lidong Bing. Auto- Arena: Automating LLM evaluations with agent peer battles and committee discussions. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4440- 4463, 2025b.
Wanjia Zhao, Mert Yuxsekgonul, Shirley Wu, and James Zou. SiriuS: Self- improving multi- agent systems via bootstrapped reasoning. arXiv preprint arXiv:2502.04780, 2025c.
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 1(2), 2023.
Chengqi Zheng, Jianda Chen, Yueming Lyu, Wen Zheng Terence Ng, Haopeng Zhang, Yew- Soon Ong, Ivor Tsang, and Haiyan Yin. Mermaidflow: Redefining agentic workflow generation via safety- constrained evolutionary programming. arXiv preprint arXiv:2505.22967, 2025.
Longtao Zheng, Rundong Wang, Ximrun Wang, and Bo An. Synapse: Trajectory- as- exemplar prompting with memory for computer control. In The Twelfth International Conference on Learning Representations, 2023a.
Sipeng Zheng, Jiazheng Liu, Yicheng Feng, and Zongqing Lu. Steve- Eye: Equipping llm- based embodied agents with visual perception in open worlds. In The Twelfth International Conference on Learning Representations, 2024.
Zhiling Zheng, Oufan Zhang, Ha L Nguyen, Nakul Rampal, Ali H Alawadhi, Zichao Rong, Teresa Head- Gordon, Christian Borgs, Jennifer T Chayes, and Omar M Yaghi. Chatgpt research group for optimizing the crystallinity of mofs and cofs. ACS Central Science, 9(11):2161- 2170, 2023b.
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanjin Wang. Memorybank: Enhancing large language models with long- term memory. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 19724- 19731, 2024.
Han Zhou, Xingchen Wan, Ivan Vulic, and Anna Korhonen. Survival of the most influential prompts: Efficient black- box prompt search via clustering and pruning. In Findings of the Association for Computational Linguistics: EMNLP, pages 13064- 13077, 2023a.
Han Zhou, Xingchen Wan, Yinhong Liu, Nigel Collier, Ivan Vulic, and Anna Korhonen. Fairer preferences elicit improved human- aligned large language model judgments. In Yaser Al- Onaizan, Mohit Bansal, and Yun- Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1241- 1252, Miami, Florida, USA, November 2024a. Association for Computational Linguistics.
Han Zhou, Xingchen Wan, Lev Proleev, Diana Mincu, Jilin Chen, Katherine A Heller, and Subhrajit Roy. Batch calibration: Rethinking calibration for in- context learning and prompt engineering. In The Twelfth International Conference on Learning Representations, 2024b.
Han Zhou, Xingchen Wan, Ruoxi Sun, Hamid Palangi, Shariq Iqbal, Ivan Vulić, Anna Korhonen, and Sercan Ö Arik. Multi- Agent design: Optimizing agents with better prompts and topologies. arXiv preprint arXiv:2502.02533, 2025a.
Huichi Zhou, Yihang Chen, Siyuan Guo, Xue Yan, Kin Hei Lee, Zihan Wang, Ka Yiu Lee, Guchun Zhang, Kun Shao, Linyi Yang, et al. Memento: Fine- tuning llm agents without fine- tuning llms. arXiv preprint arXiv:2508.16153, 2025b.
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854, 2023b.
Wangchunshu Zhou, Yixin Ou, Shengwei Ding, Long Li, Jialong Wu, Tiannan Wang, Jiamin Chen, Shuai Wang, Xiaohua Xu, Ningyu Zhang, et al. Symbolic learning enables self- evolving agents. arXiv preprint arXiv:2406.18532, 2024c.
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human- level prompt engineers. In The Eleventh International Conference on Learning Representations, 2023c.
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. MEM1: Learning to synergize memory and reasoning for efficient long- horizon agents. arXiv preprint arXiv:2506.15841, 2025c.
Kunlun Zhu, Hongyi Du, Zhaochen Hong, Xiaocheng Yang, Shuyi Guo, Zhe Wang, Zhenhailong Wang, Cheng Qian, Xiangru Tang, Heng Ji, et al. MultiAgentBench: Evaluating the collaboration and competition of llm agents. arXiv preprint arXiv:2505.01935, 2025.
Tinghui Zhu, Kai Zhang, Jian Xie, and Yu Su. Deductive beam search: Decoding deducible rationale for chain- of- thought reasoning. In First Conference on Language Modeling, 2024.
Xinyu Zhu, Junjie Wang, Lin Zhang, Yuxiang Zhang, Yongfeng Huang, Ruyi Gan, Jiaxing Zhang, and Yujiu Yang. Solving math word problems via cooperative reasoning induced language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics (ACL), 2023. Yangyang Zhuang, Wenjia Jiang, Jiayu Zhang, Ze Yang, Joey Tianyi Zhou, and Chi Zhang. Learning to be a doctor: Searching for effective medical agent architectures. arXiv preprint arXiv:2504.11301, 2025. Yuchen Zhuang, Yue Yu, Kuan Wang, Haotian Sun, and Chao Zhang. ToolQA: A dataset for LLM question answering with external tools. In Advances in Neural Information Processing Systems, 2023. Yuchen Zhuang, Xiang Chen, Tong Yu, Saayan Mitra, Victor Bursztyn, Ryan A Rossi, Somdeb Sarkhel, and Chao Zhang. Toolchain*: Efficient action space navigation in large language models with a* search. In The Twelfth International Conference on Learning Representations, 2024. Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. GPTSwarm: Language agents as optimizable graphs. In Forty- first International Conference on Machine Learning, 2024a. Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, et al. Agent- as- a- judge: Evaluate agents with agents. arXiv preprint arXiv:2410.10934, 2024b. Huhai Zou, Rongzhen Li, Tianhao Sun, Fei Wang, Tao Li, and Kai Liu. Cooperative scheduling and hierarchical memory model for multi- agent systems. In 2024 IEEE International Symposium on Product Compliance Engineering - Asia (ISPCE- ASIA), pages 1- 6, 2024. doi: 10.1109/ISPCE- ASIA64773.2024.10756271. Kaiwen Zuo, Yirui Jiang, Fan Mo, and Pietro Lio. KG4Diagnosis: A hierarchical multi- agent LLM framework with knowledge graph enhancement for medical diagnosis. In AAAI Bridge Program on AI for Medicine and Healthcare, pages 195- 204. PMLR, 2025.