机器学习中的损失函数是什么
在机器学习中,损失函数(Loss Function) 是衡量模型预测结果与真实值之间差异的核心工具。它的作用是 量化模型的“错误程度”,并指导模型通过优化算法(如梯度下降)不断调整参数以减少这种差异。
1. 为什么需要损失函数?
- 问题:模型的预测结果(如分类概率、回归值)可能与真实标签不一致。
- 解决方法:定义一个数学函数,计算这种不一致的程度(即“损失”),并让模型通过优化算法最小化这个损失。
2. 常见损失函数的类型
(1) 均方误差(Mean Squared Error, MSE)
适用场景:回归任务(预测连续数值,如房价、温度)。
公式:
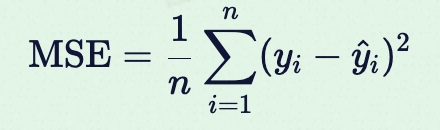
- yi: 真实值(如实际房价)
- y^i: 模型预测值(如预测房价)
- n: 样本数量
特点:
- 对异常值敏感(平方放大误差)。
- 适合目标变量是连续值的问题。
(2) 交叉熵损失(Cross-Entropy Loss)
适用场景:分类任务(预测离散类别,如图像分类、文本情感分析)。
公式(二分类):
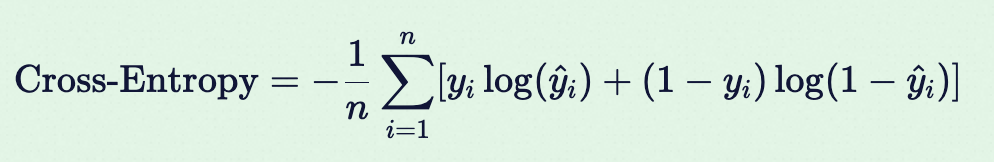
- yi∈{0,1}yi∈{0,1}: 真实类别(如是否是猫)
- y^i∈[0,1]y^i∈[0,1]: 模型预测的概率(如预测是猫的概率为 0.9)
多分类公式:
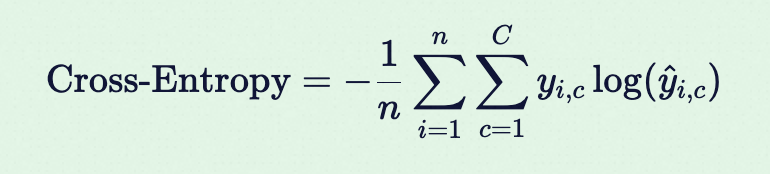
- C: 类别数量(如 10 个数字类别)
特点:
- 鼓励模型对正确类别输出高概率,对错误类别输出低概率。
- 常与 Softmax 激活函数配合使用(将 logits 转换为概率分布)。
3. 损失函数的作用
量化误差:
- 通过数值(如 0.12、0.05)直观反映模型的预测效果。
- 误差越小,模型越接近真实值。
指导优化:
- 损失函数是优化算法(如梯度下降)的目标函数。
- 通过计算损失对模型参数的梯度,调整参数以最小化损失。
评估模型性能:
- 训练过程中监控损失值,判断模型是否收敛或过拟合。
- 例如:训练损失下降但验证损失上升 → 可能过拟合
4. 示例对比
回归任务(MSE)
- 问题:预测房价。
- 模型预测:y^=300,000(预测房价)
- 真实值:y=280,000(实际房价)
- 损失:(300,000−280,000)2=4×109(300,000−280,000)2=4×109(误差平方)
分类任务(交叉熵损失)
- 问题:判断图片是否是猫。
- 模型预测:y^=0.9(预测是猫的概率)
- 真实值:y=1(实际是猫)
- 损失:−log(0.9)≈0.105(误差较小)
5. 总结
- 一句话:
损失函数是模型“学习”的指南针,通过量化预测与真实值的差异,驱动模型不断优化参数,最终提高预测准确性。