通义万相wan2.2视频模型的基础模型与安装应用详解
Wan2.2 是阿里巴巴于 2025 年 7 月 28 日开源的电影级视频生成模型。Wan2.2 在视频扩散模型中引入了混合专家(MoE)架构,将去噪过程分离,高噪阶段关注整体布局,低噪阶段完善细节。
本节内容所涉及模型见文末网盘,可直接转存及下载。
1 模型简介
1.1 模型特点
(1)有效的 MoE 架构:引入混合专家 (MoE) 架构,通过使用专门的强大专家模型将去噪过程跨时间步长分离,这扩大了整体模型容量,同时保持了相同的计算成本。
在Wan2.2 中,A14B系列模型采用了针对扩散模型去噪过程量身定制的双专家设计:一个是高噪声专家 (high-noise expert),用于生成的早期阶段,专注于整体布局;一个是低噪声专家 (low-noise expert),用于生成的后期阶段,负责精炼视频细节。每个专家模型拥有约14B参数,使得总参数量达到27B,但由于每一步只激活14B参数,因此推理计算量和GPU显存占用几乎保持不变(注意:5B模型没有采用双模型设计)。
两个专家之间的切换点由信噪比(SNR)决定,这是一个随着降噪步数的增加而单调递减的指标。在降噪过程的开始阶段,降噪步数很大,噪声水平高,因此信噪比处于其最小值。在此阶段,高噪声专家被激活。我们定义了一个阈值步数,它所对应的信噪比值为最小信噪比的一半,当降噪步数小于阈值步数时,模型便切换到低噪声专家 (low-noise expert)。
(2)电影级美学:Wan2.2 融合了精心策划的美学数据,并配有详细的照明、构图、对比度、色调等标签。这允许更精确和可控的电影风格生成,有助于创建具有可定制审美偏好的视频。
(3)复杂运动生成:与 Wan2.1 相比,Wan2.2 使用更大的数据进行训练,图像增加了 +65.6%,视频增加了 +83.2%。这种扩展显着增强了模型在运动、语义和美学等多个维度上的泛化,在所有开源和闭源模型中实现了 TOP 性能。
(4)高效高清混合 TI2V:Wan2.2使用先进的 Wan2.2-VAE 构建的 5B 模型,该模型实现16×16×4的压缩比。该型号支持以 720P 分辨率和 24fps 生成文本到视频和图像到视频,也可以在 4090 等消费级显卡上运行。它是目前最快的 720P@24fps 模型之一,能够同时服务于工业和学术部门。
1.2 模型分类
(1)万相2.2-文生视频-A14B:文生视频-A14B 模型支持生成时长为5秒、分辨率为480P和720P的视频。
(2)万相2.2-图生视频-A14B:图生视频-A14B模型是一款专为图生视频设计的模型,支持480P和720P两种分辨率。将静态图像转换为动态视频,保持内容一致性和流畅的动态过程。
(3)万相2.2-图/文生视频-5B:混合版模型,同时支持文本转视频和图像转视频,单个模型满足两个核心任务需求。
本节内容将对comfy-org官方发布的适配comfyui使用的wan2.2模型,由于本地显存有限,仅使用Wan2.2 TI2V 5B混合模型进行测试。
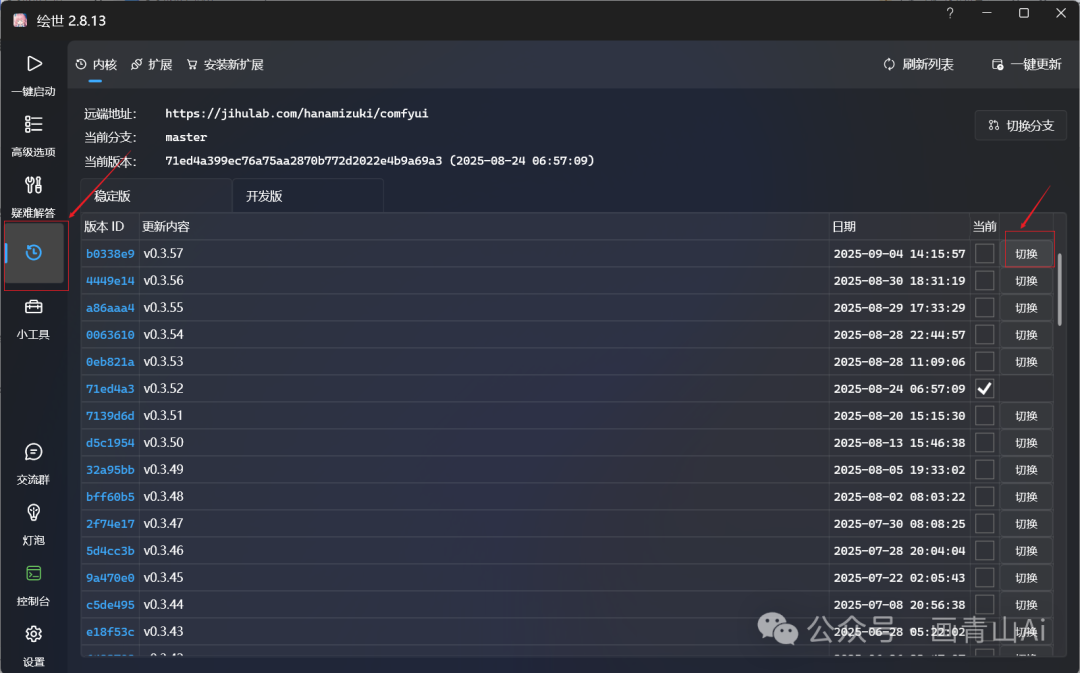
学习准备:下载comfyui整合包,并将内核版本更新至最新稳定版本。
2 comfy org官方版本模型与工作流
适配comfyui的wan2.2系列模型包括comfy org官方发布的模型及社区发布的kijai版本模型、GGUF版本模型等。下文内容为comfy org官方发布的wan2.2适配模型及工作流应用。
2.1 Wan2.2混合模型(5B版本)
2.1.1 Wan2.2混合模型(5B版本)
wan2.2_ti2v_5B_fp16.safetensors
模型下载地址(需科学上网):
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/diffusion_models
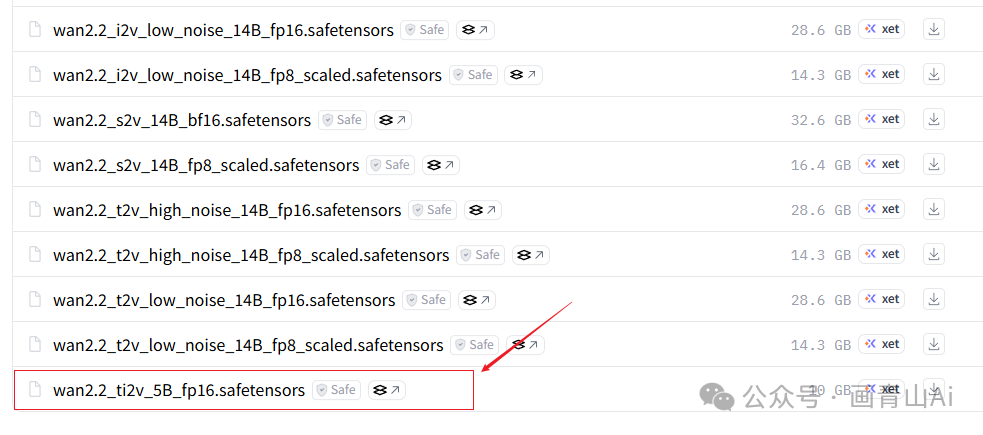
模型安装位置:..\ComfyUI\models\diffusion_models
2.1.2 VAE模型
wan2.2_vae.safetensors
模型下载地址(需科学上网):
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/vae
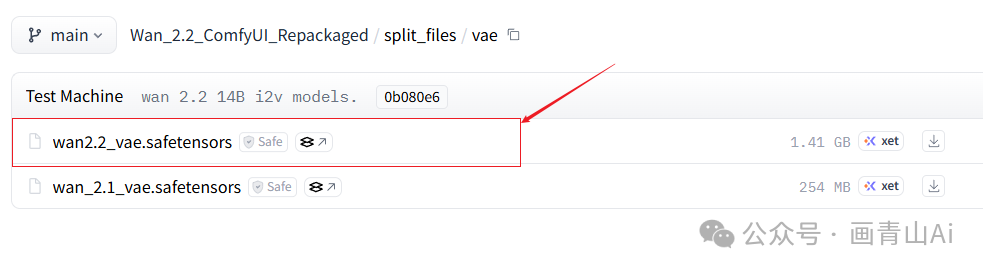
模型安装位置:..\comfyui\models\vae
(注:该VAE为wan2.2混合版5B模型使用,14B模型使用的仍是wan_2.1_VAE.safetensors)
2.1.3 Text Encoder文本编码器
umt5_xxl_fp8_e4m3fn_scaled.safetensors
模型下载地址(需科学上网):
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders

注:该模型与wan2.1共用,如wan2.1已下载则无需重复下载。
2.1.4 工作流
comfyui范本--视频生成--Wan 2.2 5B Video Generation工作流
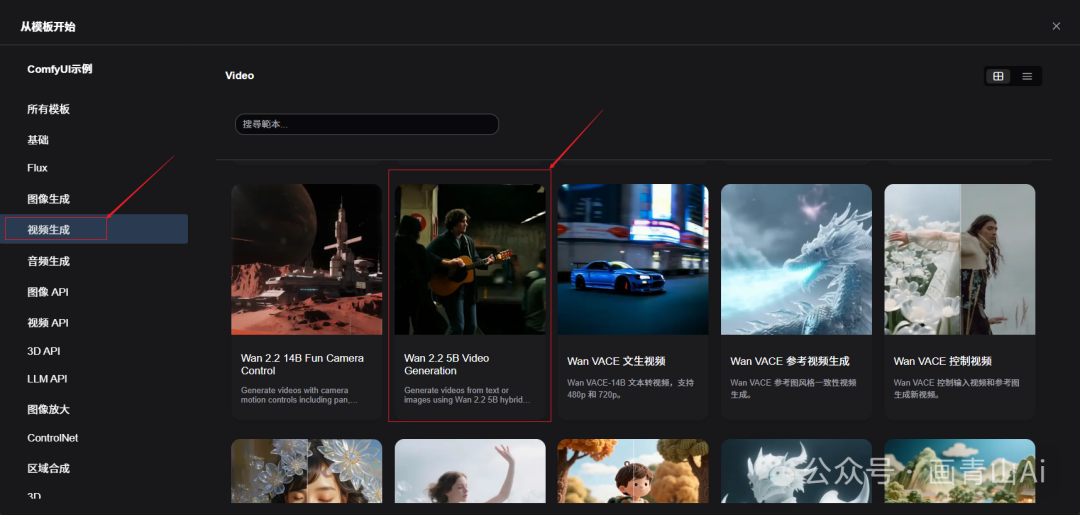
wan2.2_ti2v_5B_fp16.safetensors模型加载与wan2.1类似,仅需加载5B单一模型。文生图工作流如下:
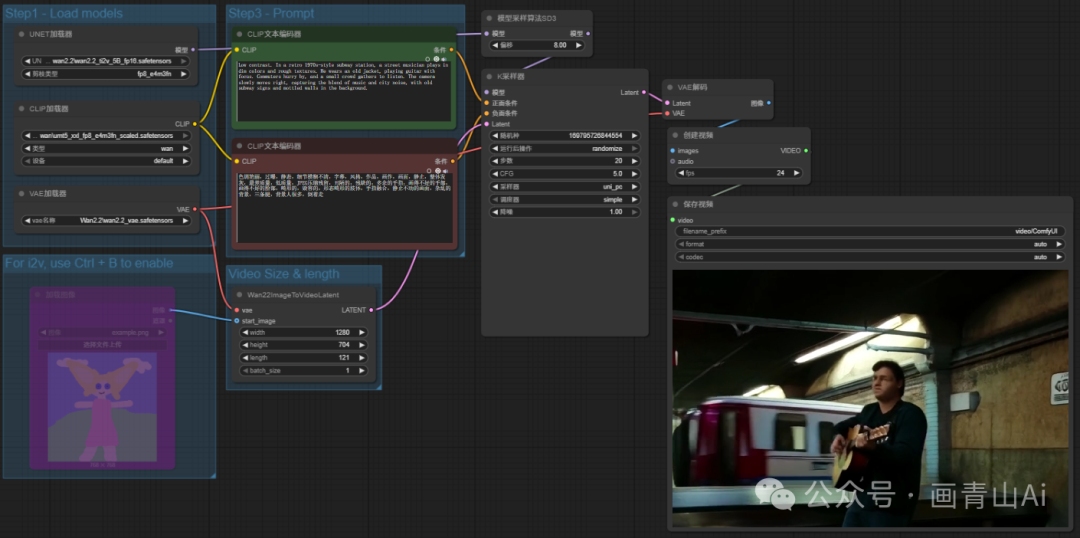
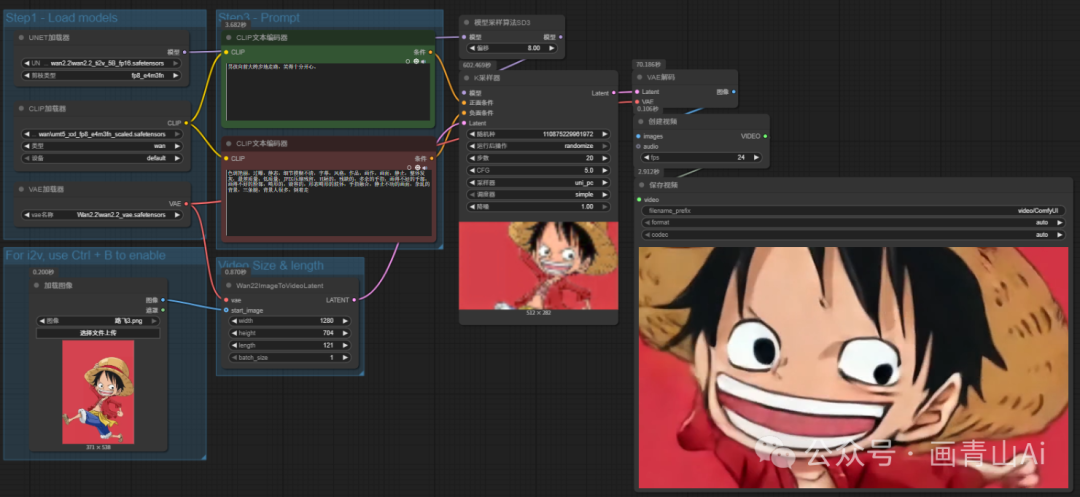
图生图工作流仅需将工作流中忽略的“加载图像”重新启用即可:
2.2 Wan2.2 14B T2V(14B文生视频)
2.2.1 Wan2.2 14B T2V模型
上文已经介绍,wan2.2模型的14B版本分为高噪声模型和低噪声模型两个版本,需要同时下载,另外14B版本不同噪声级模型又都分为FP16和FP8版本模型,可根据电脑配置情况灵活选择。
模型下载地址(需科学上网):
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/diffusion_models
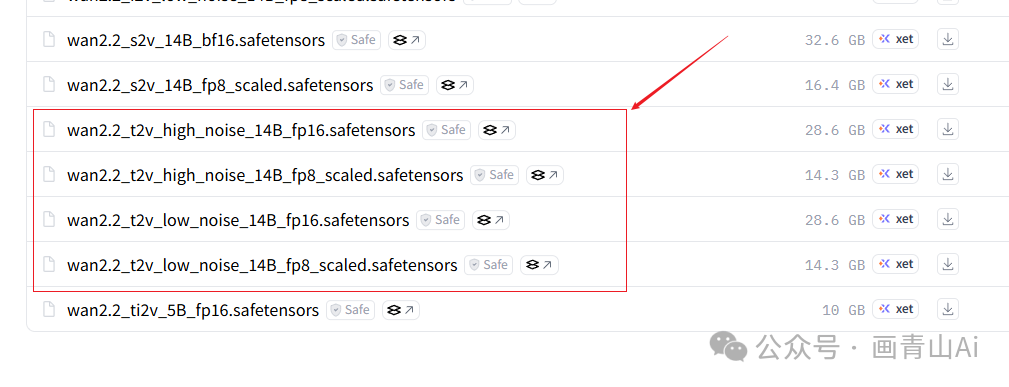
模型安装位置:..\ComfyUI\models\diffusion_models
注意高噪声版和低噪声版都要下载,且fp版本需一致。
2.2.2 VAE模型
14B版本模型工作流中所使用的VAE模型仍是wan2.1版本的VAE模型,这点和5B混合模型专用VAE模型不一致,需要特别注意。
下载地址:
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae

文件存放目录:..\comfyui\models\vae
2.2.3 Text Encoder文本编码器
umt5_xxl_fp8_e4m3fn_scaled.safetensors
模型下载地址(需科学上网):
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders
注:该模型与wan2.1共用,如wan2.1已下载则无需重复下载。
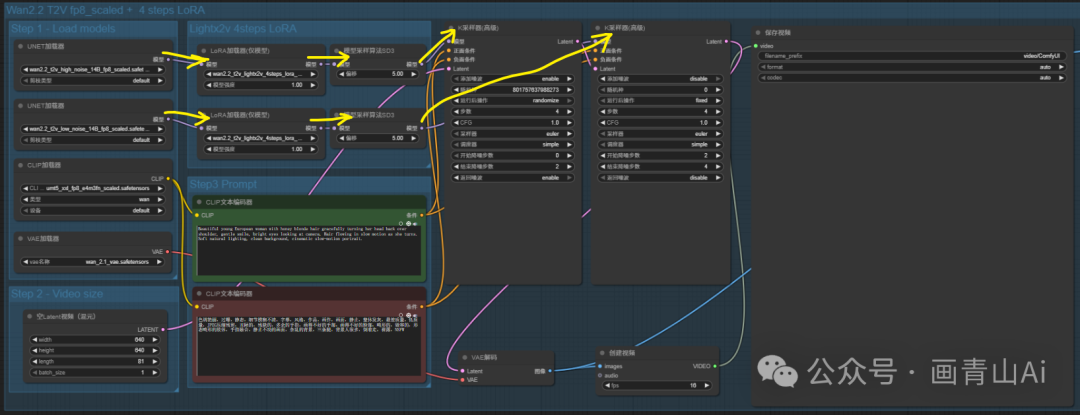
2.2.4 加速lora模型(lightx2v_4steps_lora)
模型下载地址(需科学上网):
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/loras
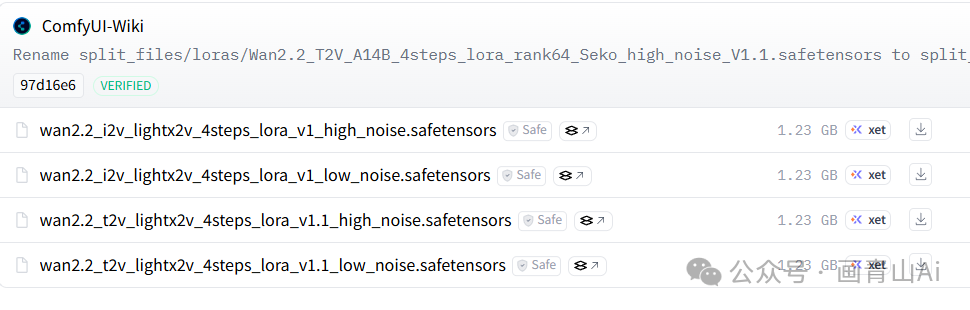
模型安装目录:..\comfyui\models\loras
高噪声和低噪声模型加载器后均需链接对应版本的加速lora模型(14B I2V模型对应lora理同,下文不再重复描述)。
2.2.5 工作流
共经过两次采样,需要两个K处理器串联,先高噪声模型采样再低噪声模型采样。
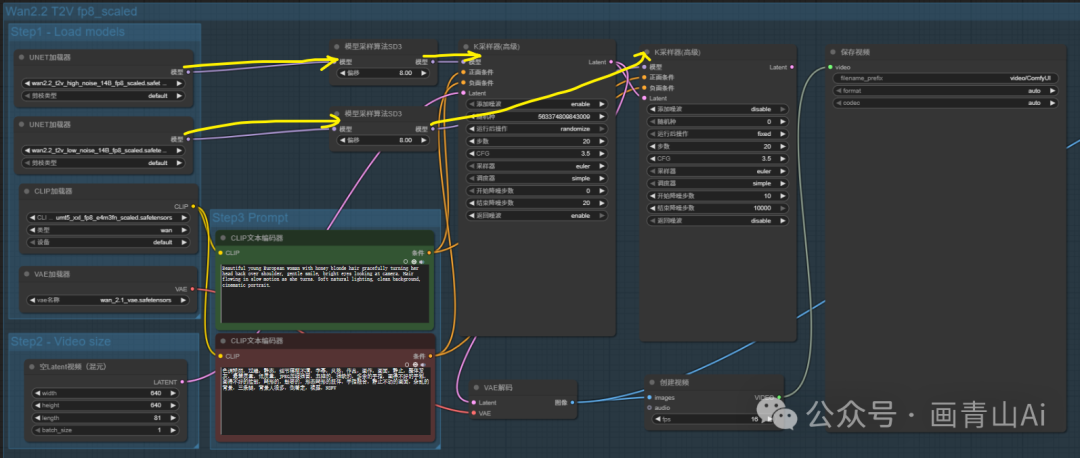
第一个加载扩散模型(Load Diffusion Model) 节点加载高噪声模型 wan2.2_t2v_high_noise_14B_fp8/fp16_scaled.safetensors;第二个“加载扩散模型” 节点加载低噪声模型wan2.2_t2v_low_noise_14B_fp8/fp16_scaled.safetensors 。
加载加速lora工作流:
2.3 Wan2.2 14B I2V(14B图生视频)
2.3.1 Wan2.2 14B I2V模型
与14B文生视频模型一样,14B版wan2.2图生视频模型也分为高噪声模型和低噪声模型两个版本,需要同时下载,另外14B版本不同噪声级模型又都分为FP16和FP8版本模型,可根据电脑配置情况灵活选择。
模型下载地址(需科学上网):
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/diffusion_models
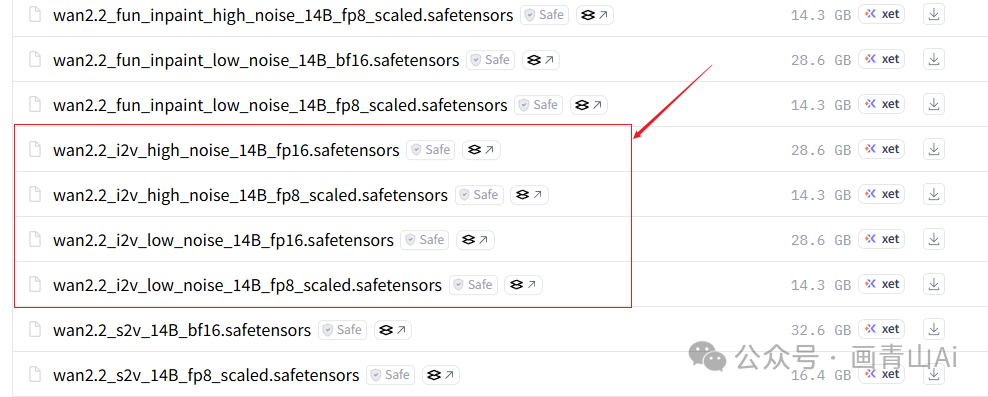
模型安装位置:..\ComfyUI\models\diffusion_models
注意高噪声版和低噪声版都要下载,且fp版本需一致。
2.3.2 VAE模型
14B版本模型工作流中所使用的VAE模型是wan2.1版本的VAE模型。
下载地址:
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae
文件存放目录:..\comfyui\models\vae
2.3.3 Text Encoder文本编码器
umt5_xxl_fp8_e4m3fn_scaled.safetensors
模型下载地址(需科学上网):
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders
注:该模型与wan2.1共用,如wan2.1已下载则无需重复下载。
2.3.4 工作流
第一个加载扩散模型(Load Diffusion Model) 节点加载高噪声模型 wan2.2_i2v_high_noise_14B_fp8/fp16_scaled.safetensors;第二个“加载扩散模型” 节点加载低噪声模型wan2.2_i2v_low_noise_14B_fp8/fp16_scaled.safetensors 。
图像输入使用“Wan图像到视频”节点
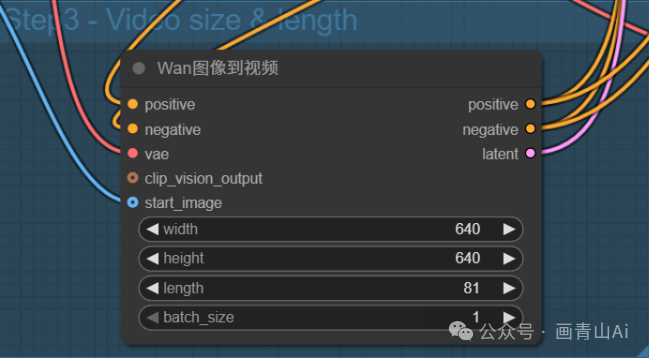
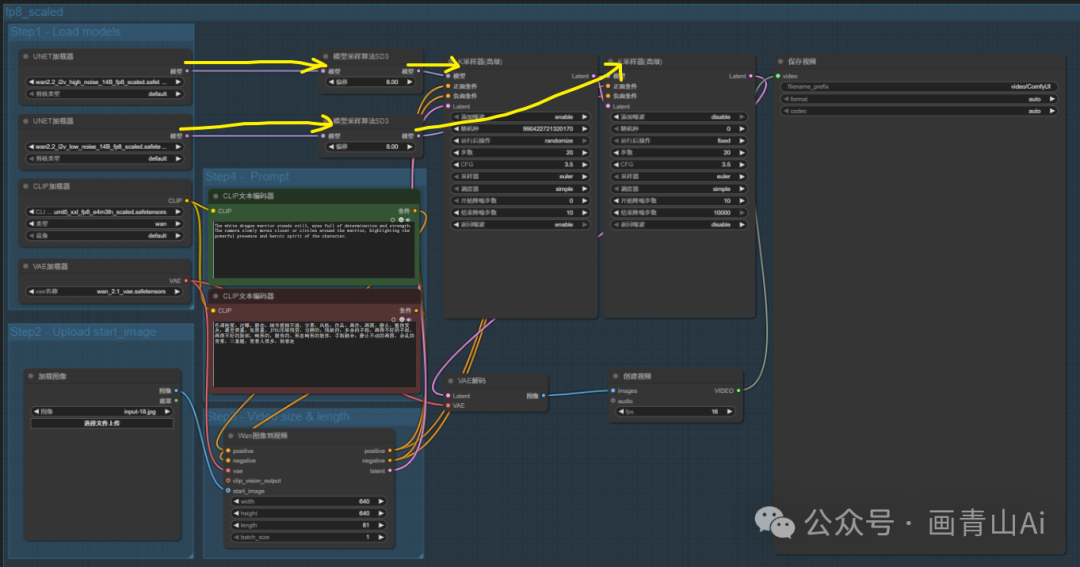
添加加速lora模型后工作流:
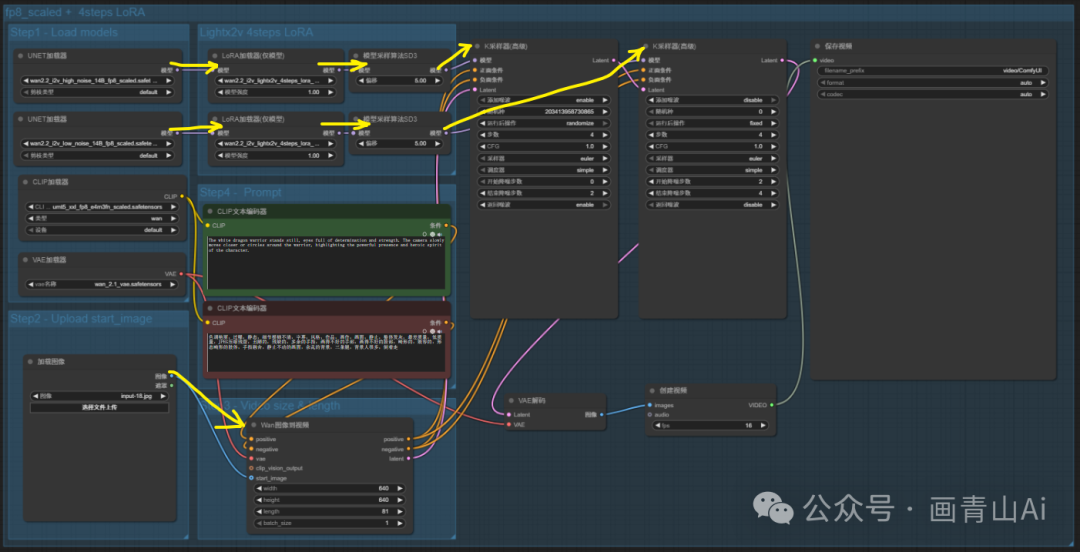
2.4 Wan2.2 14B FLF2V首尾帧视频
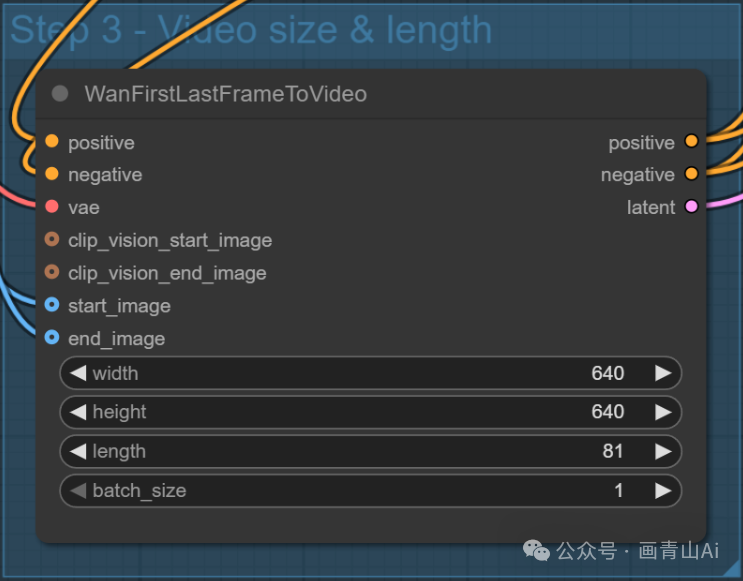
与wan2.1模型不同,wan2.2首尾帧视频无需使用专用的首尾帧视频模型,使用的模型仍是14B图生视频模型。
首、尾帧图像输入“WanFirstLastFrameToVideo”节点连入工作流。
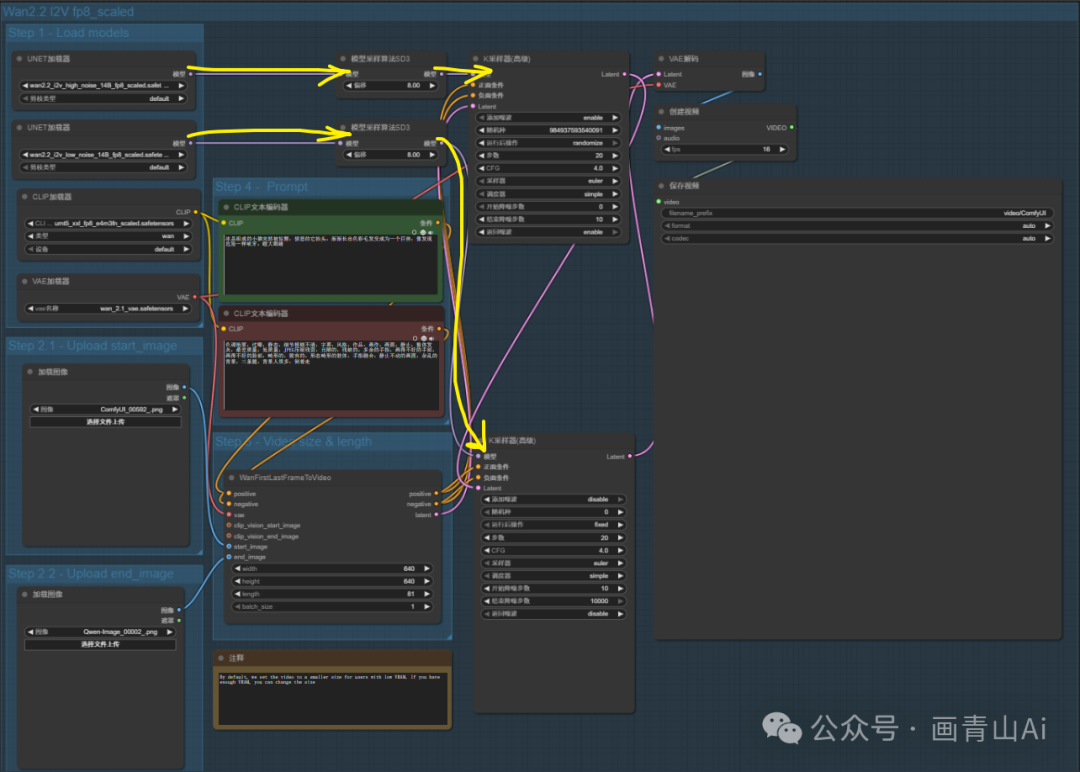
添加加速lora工作流:
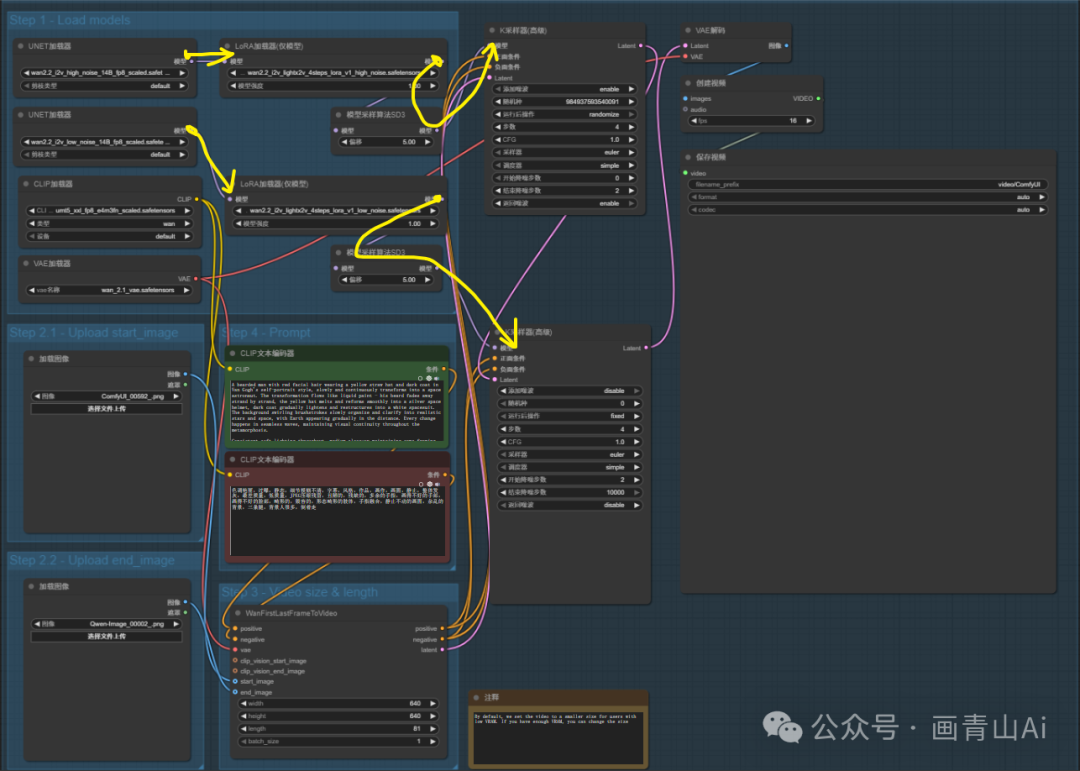
3 Wan2.2 模型--kijai版本
3.1 kijai插件安装
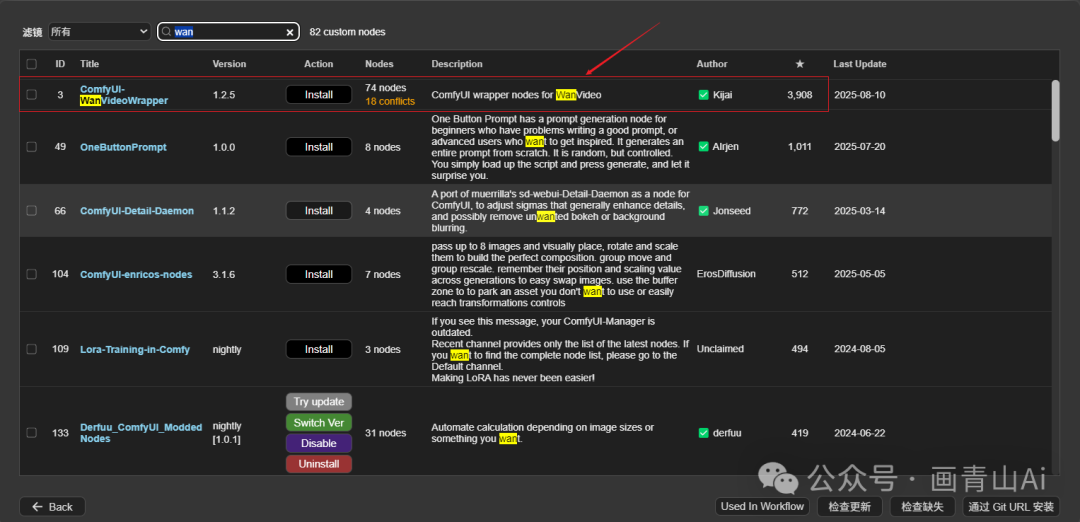
kiji模型适配wan 2.2模型的插件是WanVideoWrapper
插件地址:https://github.com/kijai/ComfyUI-WanVideoWrapper
wanvideowrapper可以通过管理器直接进行安装。
git安装方式:
git clone https://github.com/kijai/ComfyUI-WanVideoWrapper
3.2 模型安装
3.2.1 wan2.2 模型下载
kiji发布的模型地址:
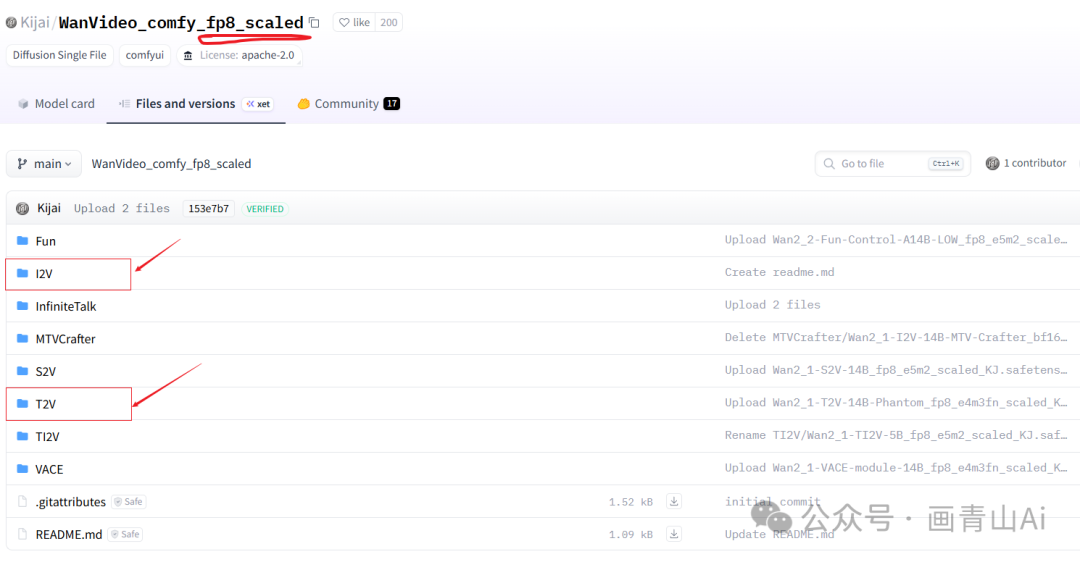
标准版本:https://huggingface.co/Kijai/WanVideo_comfy/tree/main
fp8版本:https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled/tree/main
本文以fp8版本模型的安装为例进行演示,下载页面如下:
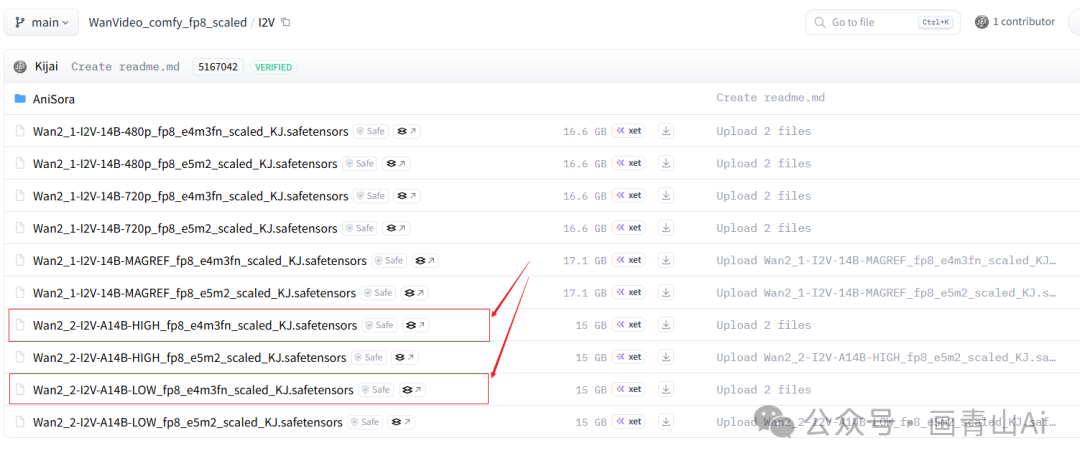
进入后选择适合电脑显存的版本即可,模型安装位置也是:
..\ComfyUI\models\diffusion_models
3.2.2VAE模型及text_encoders模型
kijai版本模型与工作流需要下载kijai版本的VAE模型、text_encoders模型,上述模型均在kijai模型标准版本的发布页中,拉到下载页面的最下方,见下图示例。
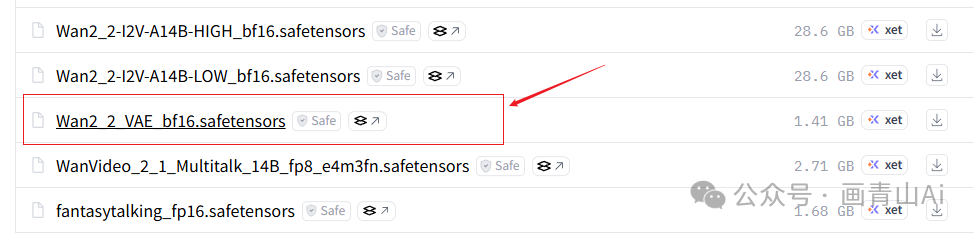
VAE模型文件存放目录:..\comfyui\models\vae

text_encoders文件存放目录:..\comfyui\models\text_encoders
text_encoders模型与wan2.1共用,如已下载则无需重复安装。
3.3 示例工作流
kiji版本的示例工作流在WanVideoWrapper插件的安装目录中,地址如下:
..\comfyui\custom_nodes\ComfyUI-WanVideoWrapper\example_workflows
注意:将WanVideoWrapper插件更新至最新版本。
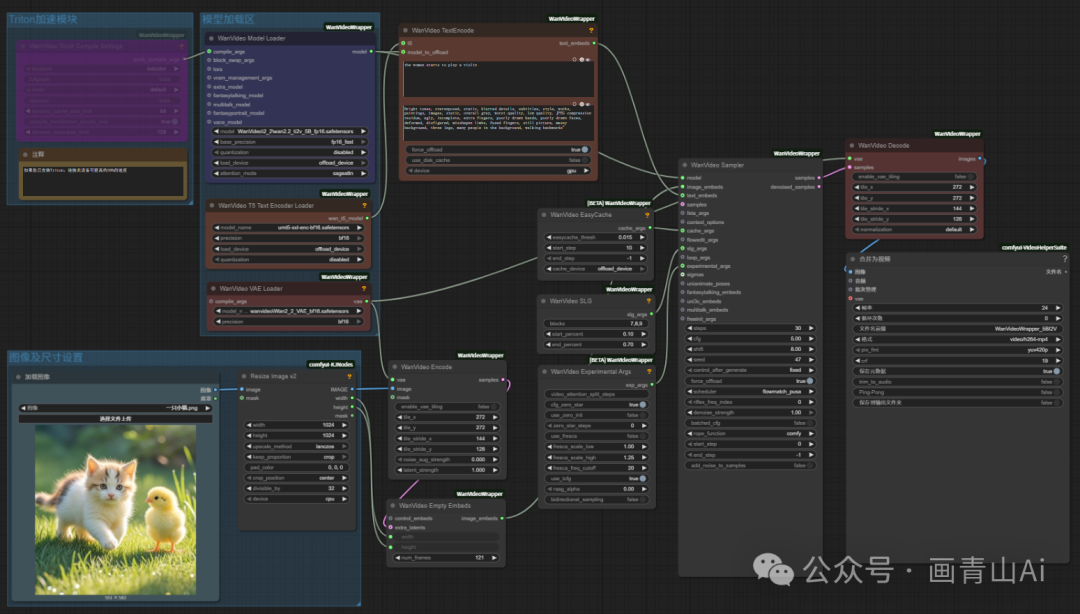
(1)wan2.2 5B混合模型基础工作流(kijai版本模型)--按分区整理后工作流如下:
(2)wan2.2 14B模型基础工作流(kijai版本模型)--按功能分区整理后工作流如下:

几个节点的作用说明:
WanVideo Block Swap(Wan 视频块交换)节点是一款针对视频生成 / 处理场景设计的功能节点,核心作用是通过跨视频帧的特征块交换,实现视频内容的风格融合、动态元素替换或帧间特征重组,常用于提升视频生成的多样性、修复帧间一致性问题,或创造特殊视觉效果。
Create CFG Schedule Float List(创建 CFG 调度浮点列表)节点是用于自定义 AI 图像 / 视频生成过程中CFG(Classifier-Free Guidance,无分类器引导)参数调度的核心工具节点。其核心作用是生成一份浮点数值列表,定义 CFG 强度在生成过程的不同步骤中如何动态变化 —— 从而实现对 “遵循提示词准确性” 与 “创作自由度” 平衡的精细化阶段控制。
4 wan2.2 模型--GGUF版本
4.1 插件安装
使用GGUF版本模型,需要安装comfyui-GGUF插件
插件地址:https://github.com/city96/ComfyUI-GGUF
可以通过gitclone方式安装,安装地址:
gitclonehttps://github.com/city96/ComfyUI-GGUF
也可以通过管理器安装,搜索GGUF,安装作者为city96的comfyui-gguf即可。
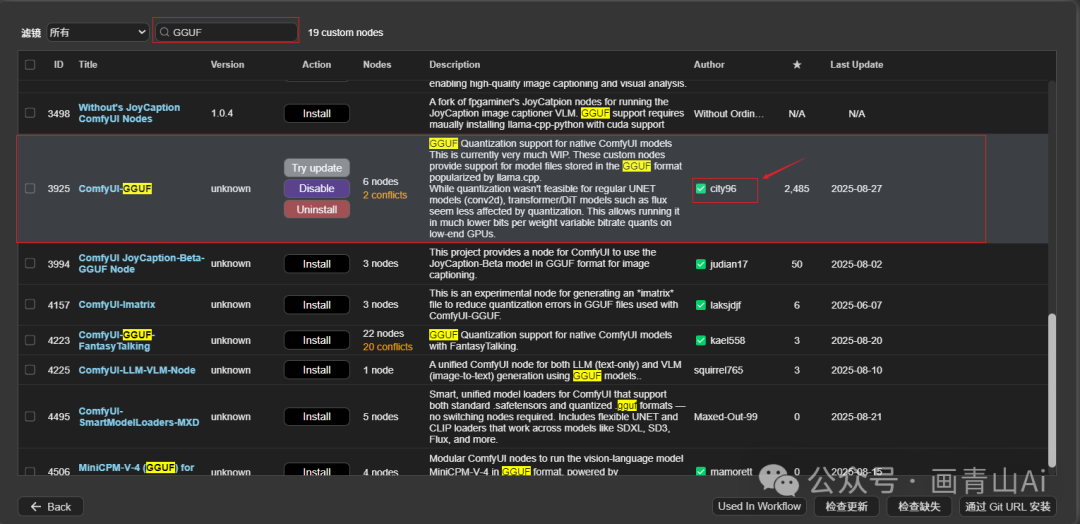
4.2 wan2.2-gguf模型
comfyorg官方推荐了作者bullerwins和作者QuantStack制作的GGFU版本模型,地址如下,大家自行选择下载即可。
(1)bullerwins版本地址如下:
14B图生视频模型:
https://huggingface.co/bullerwins/Wan2.2-I2V-A14B-GGUF/tree/main
14B文生视频模型:
https://huggingface.co/bullerwins/Wan2.2-T2V-A14B-GGUF/tree/main
(2)QuantStack版本地址如下:
https://huggingface.co/collections/QuantStack/wan22-ggufs-6887ec891bdea453a35b95f3
GGUF量化板模型划分为Q2~Q8多个子版本模型,根据电脑显存配置选择Q?版本即可,模型安装位置:..\ComfyUI\models\unet
4.3 工作流应用
使用GGUF量化模型参考官方模型基础工作流,仅需要把“UNET加载器”替换成GGUF插件对应的加载器“Unet Loader(GGUF)”,并选择对应的GGUF版本模型即可。
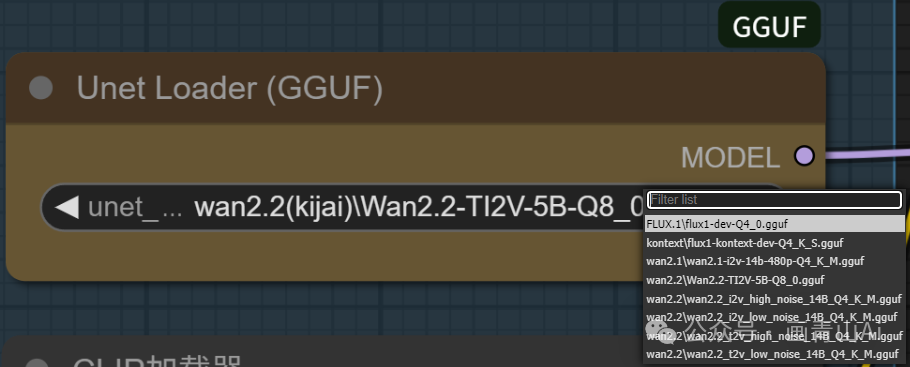
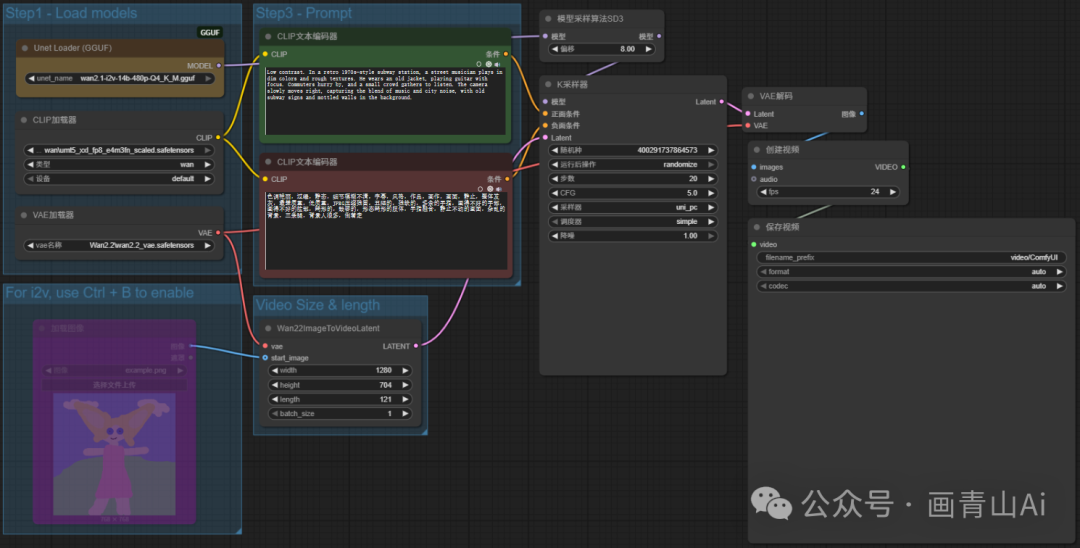
5 网盘地址
本节内容涉及模型网盘地址:https://pan.quark.cn/s/bceae7a6b71c
模型文件已进行整理,网盘内包含工作流获取方式,适合不方便科学上网的的小伙伴下载使用。模型文件数量较多且尺寸较大,为避免下载中断等问题,可先转存再下载。
欢迎正在学习comfyui等ai技术的伙伴V加 huaqs123 进入学习小组。在这里大家共同学习comfyui的基础知识、最新模型与工作流、行业前沿信息等,也可以讨论comfyui商业落地的思路与方向。 欢迎感兴趣的小伙伴,群共享资料会分享博主自用的comfyui整合包(已安装超全节点与必备模型)、基础学习资料、高级工作流等资源……
致敬每一位在路上的学习者,你我共勉!Ai技术发展迅速,学习comfyUI是紧跟时代的第一步,促进商业落地并创造价值才是学习的实际目标。

——画青山Ai学习专栏———————————————————————————————
零基础学Webui:
https://blog.csdn.net/vip_zgx888/category_13020854.html
Comfyui基础学习与实操:
https://blog.csdn.net/vip_zgx888/category_13006170.html
comfyui功能精进与探索:
https://blog.csdn.net/vip_zgx888/category_13005478.html
系列专栏持续更新中,欢迎订阅关注,共同学习,共同进步!