【Linux】 进程控制
Linux 进程控制
1.进程的创建
fork()-进程分裂(兵分两路)
什么是fork函数?
fork函数是Linux中一个重要的函数,它用于创建一个新的进程,被创建的新进程被称为子进程,创建新进程的原进程被称为父进程.
#include <unistd.h> //fork函数存在unistd.h库中pid_t fork(void);
- pid_t:在Linux系统中表示进程ID的关键数据类型.**父进程中返回的值是子进程的PID(进程ID),子进程中返回的是0.**因此我们可以根据返回值确定父子进程.
#include <stdio.h>
#include <unistd.h>
int main(){pid_t pid = fork();if(pid < 0){printf("create child process failed!\n");}else if(pid > 0){printf("this is a parent process\n");}else{printf("this is a parent process\n");}return 0;
}
this is a parent process
this is a child process
//两者的顺序不确定!
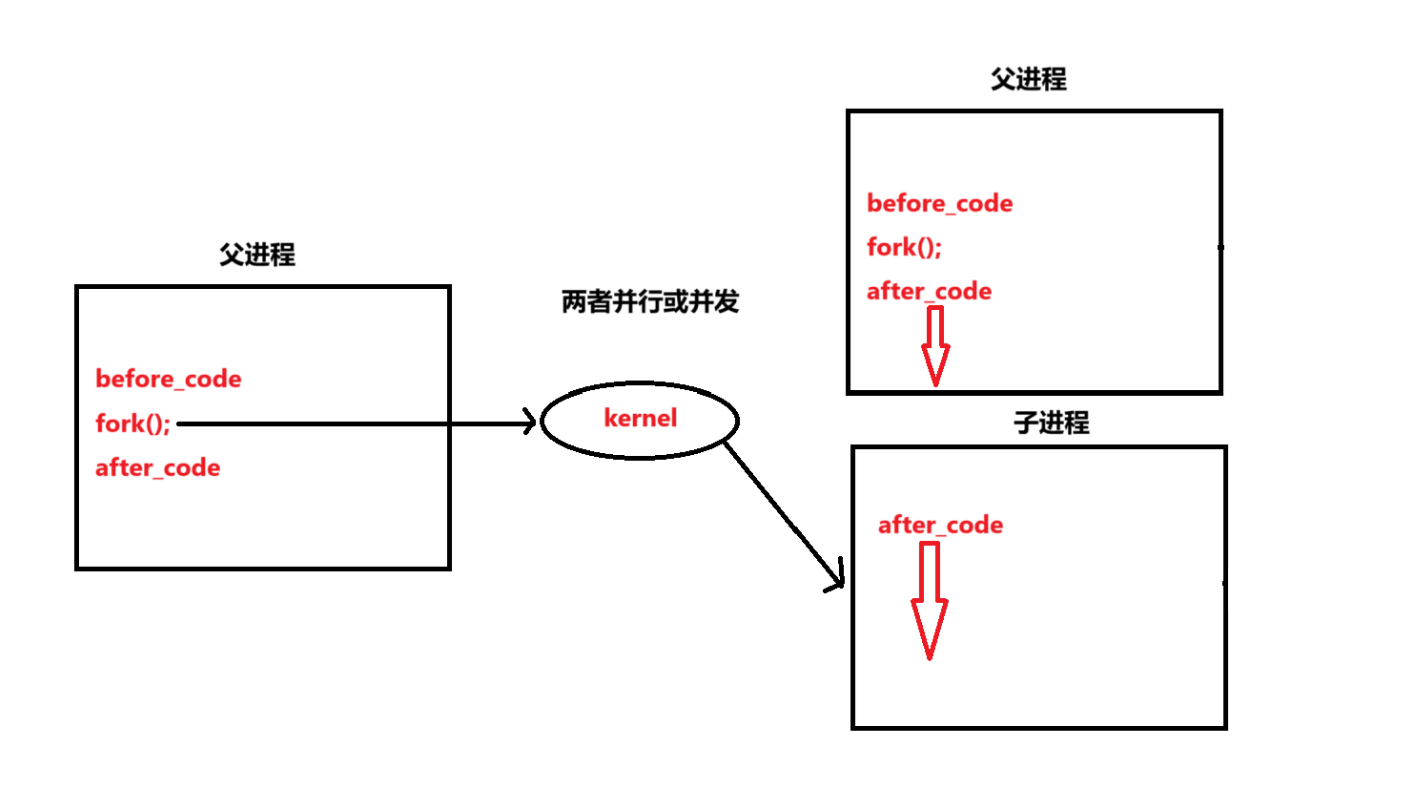
进程调用fork的过程与细节
当进程调用fork函数后,从用户态转换到进程态,进入内核空间中开始执行fork代码,过程如下:
-
分配新的内存块和内核数据结构给子进程.
-
将父进程的部分数据结构内容拷贝给子进程.
-
添加子进程到进程列表中.
-
fork返回,开始调度器调用.
执行点: 子进程从
fork()调用返回处开始执行,而不是从程序的开头。因为它复制了父进程的执行状态(包括程序计数器)。进程ID不同: 子进程的ID与父进程ID不同,但是子进程的PPID是父进程的ID
fork的特性—写时复制:
这是现代操作系统实现 fork() 的关键优化。调用 fork() 时,操作系统不会立即复制父进程的整个地址空间(代码、数据、堆、栈等)。相反,它让父子进程共享相同的物理内存页(页表)。只有当其中一个进程(父或子)试图修改某个内存页时,操作系统才会为该进程复制该页。这大大提高了 fork() 的效率,避免了不必要的内存拷贝开销。
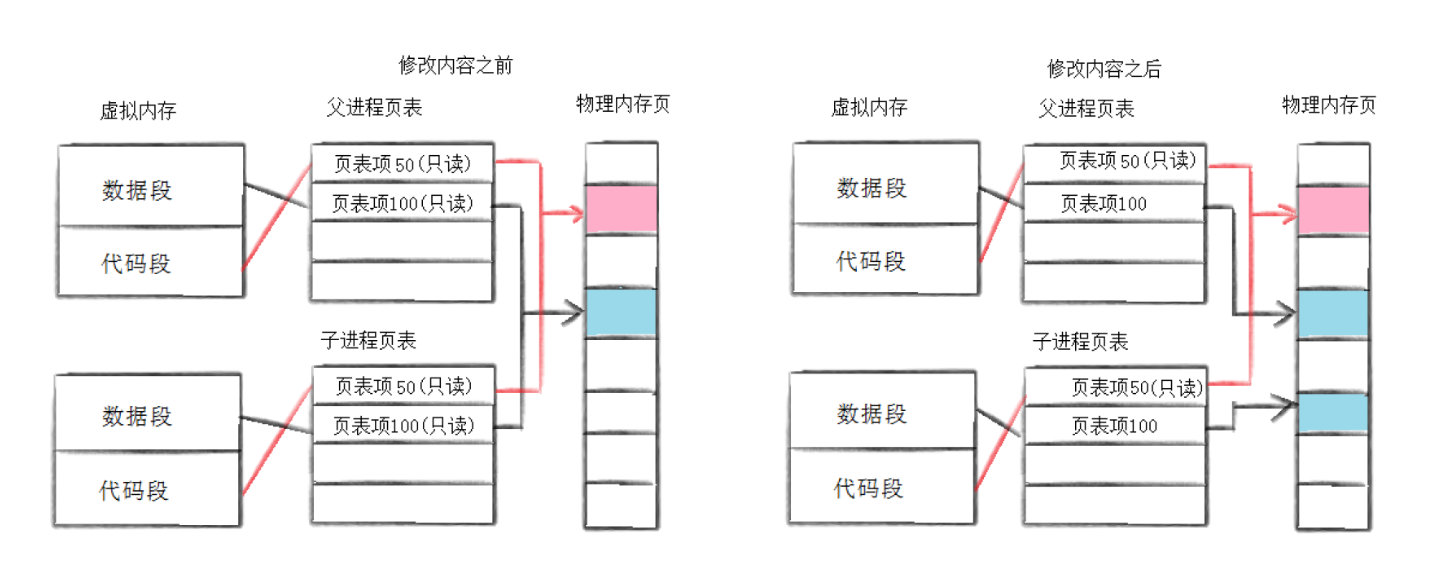
当子进程被创建,所有的数据都将是只读的,如果是父进程要修改数据,那么系统会为父进程找一块内存,存放修改的数据,并将页表对应的物理地址改为新的内存所在,而子进程原指向的内存数据将被设置为可改;如果是子进程要修改数据,那么系统会为子进程进程找一块内存,存放修改的数据,并将页表对应的物理地址改为新的内存所在,而父进程原指向的内存数据将被设置为可改.
进程创建的意义
- 程序执行: 运行新程序的基本方式。
- 并发: 创建多个进程可以同时执行多个任务(多进程并发)。
- 模块化: 将大型程序分解为独立的进程,提高健壮性(一个进程崩溃不影响其他进程)和可维护性。
- 利用多核: 操作系统可以将不同进程调度到不同CPU核心上运行,充分利用多核处理器。
- 服务/守护进程: 系统服务和守护进程通常由
init或systemd等进程在启动时创建。
需要注意的点
- 资源消耗: 创建进程比创建线程开销大,因为需要独立的地址空间和内核数据结构。
- 通信: 进程间通信需要专门的机制(IPC),如管道、消息队列、共享内存、套接字等,因为它们的地址空间是隔离的。
- 僵尸进程: 如果父进程没有调用
wait()/waitpid()回收已终止的子进程,子进程会变成“僵尸进程”,占用系统资源(主要是进程表项)。 - 孤儿进程: 如果父进程在子进程结束前终止,子进程会成为“孤儿进程”,通常会被
init进程(PID 1)接管,init会负责回收它们。 fork()炸弹::(){ :|:& };:是一个经典的fork炸弹代码(Bash shell),它会无限递归地调用fork()创建子进程,迅速耗尽系统资源导致宕机。这说明了无节制创建进程的危险性。
- fork调用失败的原因:
- 系统中有太多的进程.
- 实际用户的进程数超过了限制.
2.进程的终止
进程的终止大概分为两种情况:
- 正常终止.
- 返回值正常.
- 返回值异常.
- 异常终止.
一、正常终止:
1.从main函数返回.
这是最常见,最标准的正常的进程终止方式.
int main() {// ... 执行各种操作 ...return 0; // 或者 return 一个非零值
}
-
当
main函数运行到return语句时,它通常会将返回值返回给父进程(通常是shell). -
这个返回值被称为退出状态码 (Exit Status).可以使用
echo $?查看进程的退出码 -
惯例:
return 0;: 表示进程成功执行并顺利完成任务.return 非零值;: 表示进程在执行过程中遇到了某种预料之中的错误或异常情况(例如,文件未找到、参数错误等)。这个非零值可以由程序员自己定义,用来区分不同的错误类型.
2.调用exit()函数
exit() 是一个标准库函数(在 stdlib.h 中声明),它可以在程序的任何地方被调用,用来立即终止整个进程.
#include <stdlib.h>void some_function() {// ... 检查到某个严重错误 ...printf("发生致命错误,程序无法继续!\n");exit(1); // 立即终止进程,并返回状态码 1
}
- 关键行为:
- 它会执行一系列清理操作:调用
atexit()或on_exit()注册的函数、刷新并关闭所有打开的标准 I/O 流(比如stdout的缓冲区会被清空,确保所有printf的内容都显示出来. - 然后,它会调用
_exit()系统调用,将控制权交还给内核.
- 它会执行一系列清理操作:调用
exit(status)中的status参数同样是退出状态码,会被传递给父进程.
3.调用_exit()函数
_exit() 是一个内核级的系统调用(在 unistd.h 中声明).同样可以在进程中任何位置被调用,并且终止整个进程.
#include <unistd.h>void critical_section() {pid_t pid = fork();if (pid == 0) { // 子进程// ..._exit(0); // 子进程直接退出,不执行任何清理}// ... 父进程 ...
}
- 适用场景:
- 在
fork()之后,子进程通常会调用_exit()。因为子进程继承了父进程的 I/O 缓冲区,如果子进程调用exit(),可能会导致缓冲区内容被重复输出. - 需要尽快终止,且不关心数据是否完整保存的特殊情况.
- 在
三者的一些区别:
-
return与exit()、_exit()的区别:不难发现,
return语句在各个函数中都有存在,不同功能的函数用于返回不同的值,当在函数中运用return时,结束的只有使用return的函数本身,并不会结束整个进程.反之,exit()与_exit()在任何位置被调用都会终止整个进程. -
exit()与_exit()的区别_exit()不会执行任何清理工作。它不会调用atexit注册的函数,也不会刷新 I/O 缓冲区。它会立即终止进程,将资源直接交还给内核。
二、异常终止
这是指进程因为接收到一个无法处理的致命信号,或者遇到内部无法恢复的错误,从而被迫非自愿地中断执行。
接收到终止信号 (Signal)
Linux 通过信号机制来处理异步事件。很多信号的默认行为就是终止进程.
-
SIGINT (Interrupt):通常由用户在终端按下
Ctrl+C产生。表示“中断”,请求进程停止. -
SIGQUIT (Quit):通常由
Ctrl+\产生。不仅终止进程,还会生成一个core dump文件,用于事后调试. -
SIGTERM (Terminate):这是一个通用的、礼貌的终止信号。
kill命令默认发送的就是这个信号。它告诉进程:“请你尽快终止”,进程可以捕获这个信号并进行一些清理工作再退出. -
SIGKILL (Kill):这是“必杀令”,信号编号为 9。
kill -9发送的就是它。这个信号不能被进程捕获、忽略或阻塞。内核会立即终止目标进程,不给它任何机会做清理。这是最后的手段. -
SIGSEGV (Segment Fault):当进程试图访问一个它无权访问的内存地址时(比如访问空指针、数组越界),由内核发送.
-
SIGFPE (Floating-Point Exception):发生致命的算术错误,比如除以零.
-
当一个进程因为一个信号而终止时,它的退出状态码会是一个大于 128 的特殊值,通常是
128 + 信号编号。例如,被 SIGKILL (编号9) 杀死的进程,其退出状态码是128 + 9 = 137.
三、查看C语言中的一些错误信息
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
int main(){int count = 0; for(count = 0; count < 200;count++){printf("error[%d] -> %s\n", count, strerror(count));}return 0;}3.进程等待
一、进程终止后的状态:僵尸进程 (Zombie Process)
一个进程终止后,它不会立即从系统中消失。内核会保留它的一些关键信息(如进程ID、退出状态码、资源使用情况等)在一个叫做进程表 (Process Table) 的地方.
-
此时,这个进程就进入了僵尸状态 (Zombie)。它已经死了(不占用CPU),但它的“尸体”(在进程表中的条目)还在.
-
目的: 保留这些信息是为了让其父进程能够“收尸”。父进程可以通过调用
wait()或waitpid()系统调用来获取子进程的退出状态码,并告诉内核:“我已经知道我儿子是怎么死的了,它的尸体可以清理掉了”. -
**僵尸进程的危害:**如果父进程没有调用
wait()或waitpid(),那么子进程的僵尸状态会一直存在,白白占用进程表中的一个条目。如果大量产生僵尸进程,最终可能导致进程表被占满,系统无法创建新的进程,从而导致内存泄漏的问题. -
如何解决:
- 父进程正确调用
wait()/waitpid(). - 如果父进程先于子进程退出,子进程会成为“孤儿”,并被
init进程(PID为1)领养。init进程会自动回收所有它领养的僵尸子进程. - 在多进程编程中,使用信号处理机制,在父进程中捕获 SIGCHLD 信号(子进程终止时会发送此信号),然后在信号处理函数中调用 waitpid()。
- 父进程正确调用
所以,我们可以得出进程等待的必要性:
- 了解子进程的运行情况,包括运行的正确与否、退出与否、结果正确与否.
- 防止僵尸进程的生成,从而导致内存泄漏,减少孤儿进程的生成.
二、进程等待函数
1.wait():最简单的等待
wait() 是一个阻塞式的、最基础的等待函数,位于sys/wait.h库中。wait()不会特别地去等待某一个子进程,它就像一位在校门口等待所有孩子放学的家长,不在乎是哪个孩子先出来,只要有任何一个孩子出来了,他就领走,然后回家。我们来看函数形式:
#include <sys/wait.h>
pid_t wait(int* wstatus);
wstatus:wait() 唯一的参数,也是理解进程等待的关键。它是一个 “输出参数”,也就是说,你传一个整型变量的地址给它,当函数返回时,操作系统会把子进程的终止状态信息“填充”到这个变量里.若是不关系子进程的运行状态,可以设置为NULL.
pid_t返回值:等待成功则返回等待到的子进程的PID,等待失败则返回-1.
案例如下:
#include <stdio.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdlib.h>
void RunChild(){printf("i am a child, pid = %d, ppid = %d\n", getpid(), getppid());return;
}int main(){pid_t id = fork();if(id < 0){printf("create child process failed!\n");return 0;}//父进程if(id > 0){pid_t ret = wait(NULL);if(ret != -1){printf("wait success, pid = %d\n", ret);}else{printf("filed success\n");}sleep(5);}else{//子进程RunChild();exit(0);//关闭子进程}return 0;
}
i am a child, pid = 17093, ppid = 17092
wait success, pid = 17093
2.wiatpid():更强大、更灵活的等待
waitpid() 是 wait() 的超集(wait()是waitpid()的子集),提供了更精细的控制。waitpid可以单独等待某个进程,也可像wait()一样等待任意一个进程,它就像一位可以指定等待某个特定孩子、可以在校门口边玩手机边等(非阻塞)、并且还能关心孩子其他状态的“全能家长”.
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int* wstatus, int options);
-
pid_t pid:指定等待目标pid > 0: 只等待进程ID(PID)与 pid 值完全相等的那个子进程.pid == -1: 等待任何一个子进程(等同于wait()).pid == 0: 等待同一个进程组中的任何一个子进程.pid < -1: 等待指定进程组(组ID为pid的绝对值)中的任何一个子进程.(暂时不探讨)
-
int *wstatus:与wait完全相同这个参数的含义、内部位结构、以及解析它的宏,都与 wait() 中的 wstatus 完全一致。
-
options:这个参数通过“按位或”(|)操作符,可以组合多个选项来改变waitpid的行为。-
0: 表示没有任何特殊选项,此时 waitpid 会阻塞。 -
WNOHANG: (最常用) 将 waitpid 从阻塞调用变为非阻塞调用。如果调用时没有子进程结束,它不会等待,而是会立刻返回 0。 -
WUNTRACED: 除了关心子进程的“终止”状态,还关心它是否被“暂停”(stopped)。如果子进程被暂停了,waitpid 也会返回。这时可以用以下宏来判断:WIFSTOPPED(status): 判断子进程是否是暂停状态。WSTOPSIG(status): 如果子进程是暂停的,返回导致它暂停的信号编号。
-
WCONTINUED: 与WUNTRACED对应,关心被暂停的子进程是否已“恢复运行”。如果恢复了,waitpid也会返回,此时WIFCONTINUED(status)宏会返回真。
-
-
返回值 :
pid_t-
成功时:
-
> 0: 返回状态发生变化的那个子进程的PID。 -
= 0: 仅当使用了 WNOHANG 选项,并且当前没有子进程结束时,才会返回0。 -
失败时: 返回 -1。
-
| 特性 | wait() | waitpid() |
|---|---|---|
| 等待目标 | 任何一个子进程 | 可指定特定PID、特定进程组或任何子进程 |
| 阻塞行为 | 总是阻塞 | 默认阻塞,但可通过 WNOHANG 变为非阻塞 |
| 功能范围 | 只能处理子进程的终止 | 除了终止,还能处理子进程的暂停和继续 |
| 灵活性 | 低,简单易用 | 高,功能强大,控制精细 |
| 适用场景 | 简单的程序,或者只需要等待一个子进程的场合 | 几乎所有需要精细管理子进程的严肃程序,如网络服务器、操作系统Shell等 |
关于wstatus的两个宏函数
WIFEXITED(status):若为正常终止的子进程状态,则返回真.(查看子进程是否正常终止)WEXITSTATUS(status):若WIFEXITED(status)非零,则提取子进程的退出码.
3.wstatus详细探讨
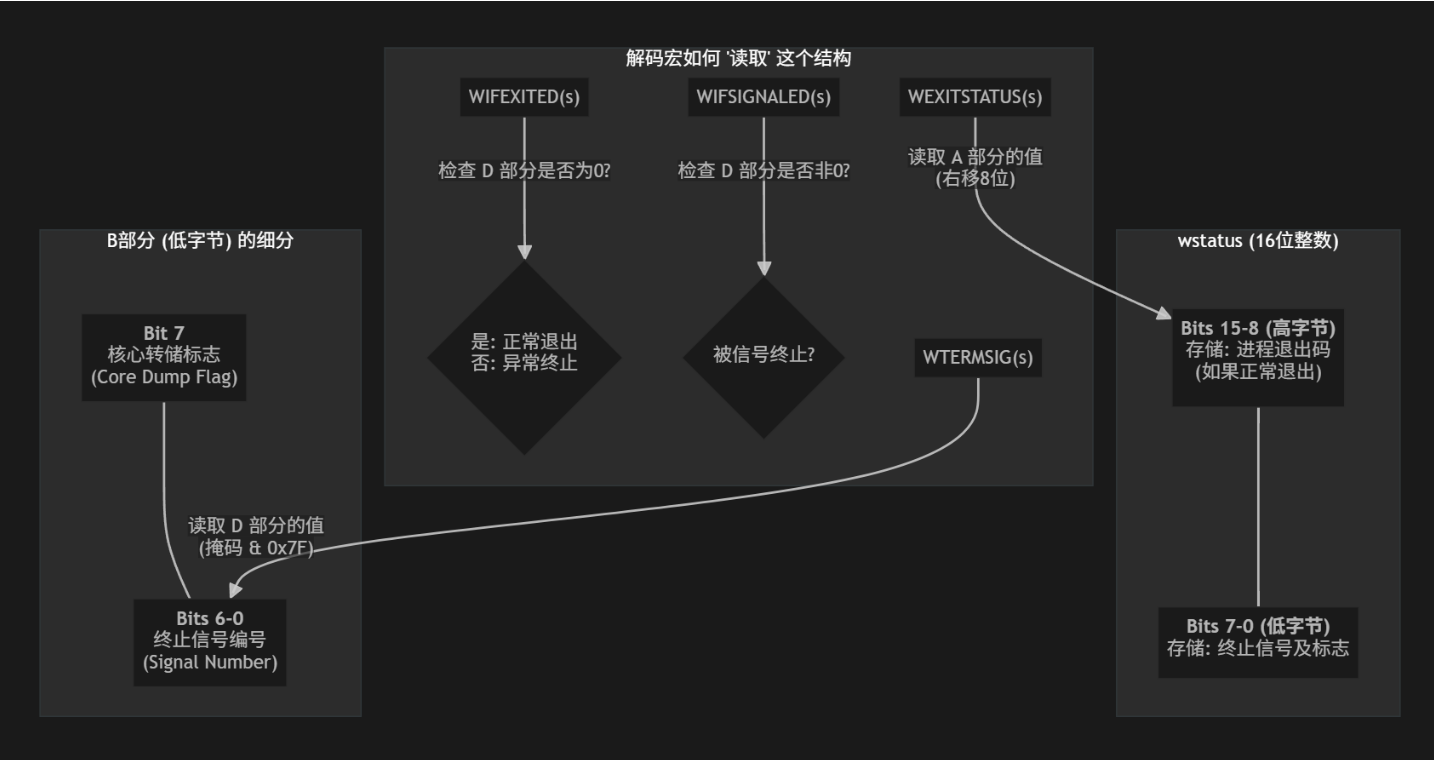
对于wstatus,它并非只是一个简单的整数,而是一个被划分区域的整数,被称为状态字,32个比特位被划为几个区域,每个区域存放着不同的0和1,其次,一个标准的wstatus其实只有16个比特位是存放数字的,结构大致如下:
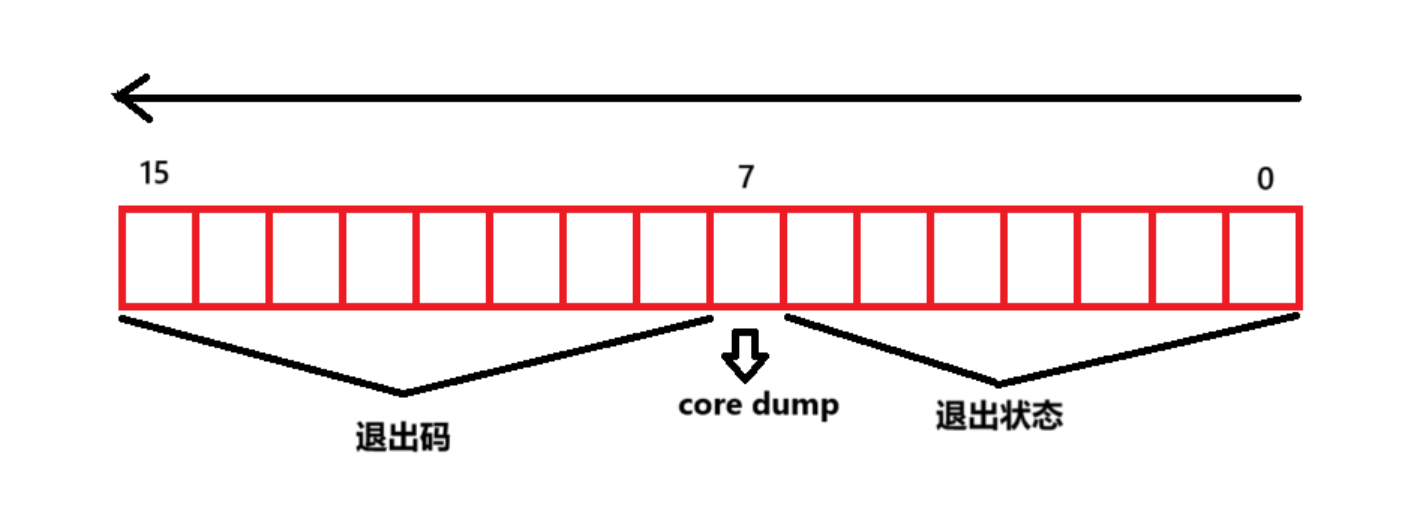
- 低7位 (Bits 0-6): 如果进程是被一个信号杀死的,这里存储的就是那个信号的编号。比如,SIGKILL 是 9,SIGSEGV(段错误)是 11。如果进程是正常退出的,这部分全为0。
- 第7位 (Bit 7): 这是一个标志位,如果进程是因为信号而死,并且还生成了一个core dump文件(用于事后调试的内存快照),这一位就会被置为1。
- 高8位 (Bits 8-15): 如果进程是正常退出的(调用 exit() 或从 main 返回),这里存储的就是它的退出码(0 到 255)。
综合实例:
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>int main(){pid_t pid = fork();if(pid == -1) printf("create child process failed\n");else if(pid == 0){//子进程int cnt = 5;while(cnt){printf("I am a child process, pid = %d, ppid = %d\n", getpid(), getppid());cnt--;sleep(1);}exit(11);//随便定一个退出码}else if(pid > 0){//父进程int ChildStatus = 0;while(1){pid_t ret = waitpid(pid, &ChildStatus, WNOHANG);//非阻塞等待模式if(ret > 0){//捕捉到了子进程if(WIFEXITED(ChildStatus))//是否正常退出{printf("子进程正常退出,退出码:%d\n", WEXITSTATUS(ChildStatus));}else{printf("子进程非正常退出\n");}break;}else if(ret < 0){printf("等待失败\n");break;}else{//ret = 0printf("子进程在忙~\n");sleep(1);}}}return 0;
}
子进程在忙~
I am a child process, pid = 21331, ppid = 21330
子进程在忙~
I am a child process, pid = 21331, ppid = 21330
子进程在忙~
I am a child process, pid = 21331, ppid = 21330
子进程在忙~
I am a child process, pid = 21331, ppid = 21330
子进程在忙~
I am a child process, pid = 21331, ppid = 21330
子进程在忙~
子进程正常退出,退出码:11
三、非阻塞式轮询
- 你按下开始键。
- 然后,你走开去看会儿电视。
- 但你心里惦记着午餐,所以你每隔30秒就跑回厨房,瞥一眼微波炉的屏幕。
- 第一次瞥:还剩 2:30。你心想:“哦,还在热。” 然后马上回去继续看电视。
- 第二次瞥:还剩 2:00。你心想:“行,继续。” 又回去看电视了。
- …
- 第六次瞥:屏幕显示 0:00。你心想:“好了!” 于是你停止看电视,拿出午餐。
- 这就是非阻塞式轮询。我们来拆解这个行为:
1.非阻塞 (Non-blocking): 你“瞥一眼”微波炉的行为是非阻塞的。你不需要一直盯着它,你看一眼,立刻就得到了“还在运行”或“已经完成”的状态,然后你就可以立刻离开,去做别的事情(看电视)。你的主任务(生活)没有被卡住。
2.轮询 (Polling): 你主动地、重复地跑回去检查状态的行为,就是轮询。你在一个循环中,不断地去查询“你好了吗?你好了吗?你好了吗?”。
我们根据代码解释一下:
现在,把这个比喻和你之前的代码对应起来:
-
父进程就是那个想吃午餐又想看电视的你。
-
子进程就是那个正在工作的微波炉。
-
waitpid(pid, &ChildStatus, WNOHANG) 就是你“瞥一眼”的动作。WNOHANG保证了这一瞥是非阻塞的。
-
如果返回 0,等于你看到倒计时还没结束。
-
如果返回 > 0,等于你看到倒计时变成了0:00。
-
while(1) 循环就是你“每隔一段时间就跑回去检查”的这个轮询行为。
-
sleep(1) 就是你在两次检查之间“看会儿电视”的时间。这是为了避免你过于频繁地检查(比如每毫秒就跑去看一次),那样会把自己累死(耗尽CPU资源)。
总结一下:
非阻塞式轮询,本质上是一种“我不会傻等你,但我会时不时地主动去问你好了没有,在问的间隙我还能干点别的”的工作模式。
它赋予了程序在等待期间执行其他任务的能力,代价是需要自己写循环逻辑来不断查询,并且会消耗一定的CPU资源。
4.进程程序替换
一、程序替换的意义
**什么是进程替换?**我们上面提到过我们的fork()函数创建子进程,子进程会继续往下执行父进程程序里面写好的代码.当我们想要子进程执行一个新的程序的时候(main函数进入),我们可以使用一个程序来替代我们的子进程.这就是程序替换.这个“程序替换”的动作,在编程层面对应的就是 exec 家族的系统调用(如 execl, execv, execve 等)。
程序替换的意义
程序替换的意义在于将“创建新进程”和“执行新程序”这两个行为解耦(分开),从而赋予程序员在两者之间的“空隙”里做准备工作的能力,这带来了无与伦比的灵活性和强大的功能组合.
二、exec家族
下面我们先以一段代码开头:
#include <stdio.h>
#include <unistd.h>int main(){pid_t id = fork();if(id < 0){printf("进程创建失败\n");return 1;}if(id == 0){sleep(2);printf("程序替换开始!\n");execl("/usr/bin/ls", "ls", "-a", "-l", NULL);printf("子进程替换成ls程序成功\n");}else{printf("父进程等待子进程中\n");waitpid(id, NULL, 0);printf("等待子进程成功\n");sleep(2);printf("父进程执行结束\n");}return 0;
}
父进程等待子进程中
程序替换开始!
total 44
drwxrwxr-x 2 xj xj 4096 Jul 4 09:48 .
drwxrwxr-x 16 xj xj 4096 Jul 3 10:45 ..
-rw-rw-r-- 1 xj xj 0 Jul 3 11:14 log.txt
-rw-rw-r-- 1 xj xj 65 Jul 3 10:52 Makefile
-rwxrwxr-x 1 xj xj 8392 Jul 4 09:48 myfile
-rw-rw-r-- 1 xj xj 535 Jul 4 09:48 myfile.c
-rwxrwxr-x 1 xj xj 8296 Jul 3 10:54 test1
-rw-rw-r-- 1 xj xj 176 Jul 4 09:32 test1.c
等待子进程成功
父进程执行结束
上面的代码中,我们将子进程替换成了ls命令,执行了ls -a -l.我们使用了execl这一个命令,下面我们来仔细介绍一下exec家族.
在编程层面,实现程序替换的正是 exec 函数家族。它们都是系统调用,一旦调用成功,当前进程的内存空间就会被新程序完全覆盖,并从新程序的入口点(main 函数)开始执行。
正因如此,一个调用成功的 exec 函数,永远不会返回。因为调用它的那个旧程序,在它成功的那一刻就已经“灰飞烟灭”了。如果 exec 返回了,那只说明一件事:调用出错了!
[!WARNING]
若是这些函数替换程序失败则返回
-1
exec 家族的函数命名非常有规律,我们可以通过字母后缀轻松地理解它们的用法:
-
l (list): 参数以参数列表(一个接一个的字符串)的形式传递。
-
v (vector): 参数以一个字符串指针数组(char *argv[])的形式传递。
-
p (path): 函数会自动在 PATH 环境变量指定的目录中搜索要执行的程序。
-
e (environment): 允许你手动传入一个自定义的环境变量数组给新程序。
下面这张表格可以帮助您理清它们之间的关系:
| 函数名 | 参数形式 | 自动搜索PATH | 自定义环境变量 |
|---|---|---|---|
| execl | 参数列表 (l) | 否 | 否 |
| execlp | 参数列表 (l) | 是 § | 否 |
| execle | 参数列表 (l) | 否 | 是 (e) |
| execv | 指针数组 (v) | 否 | 否 |
| execvp | 指针数组 (v) | 是 § | 否 |
| execvpe | 指针数组 (v) | 是 § | 是 (e) |
最常用的是 execlp 和 execvp,因为它们最方便,能像我们在 Shell 里一样直接执行命令而不用写完整路径。下面我们仔细解释一下,l、v、p、e的含义.
如上面的写的样例代码:
execl("/usr/bin/ls", "ls", "-a", "-l", NULL);
这种就是l模式的传参模式,/usr/bin/ls为程序所在的位置,ls为需要替换的程序,-a、-l为程序的参数,NULL为命令行参数列表的结束符(告知程序命令行到此结束)
char* args[] = {"ls","-a","-l",NULL
}
execv("/usr/bin/ls", args);
如上,我们可以将命令集中在一个字符串数组中,我们使用execv函数,直接将表示命令的字符串数组传入其中即可,可以达到同样的效果.注意:数组必须要以NULL结尾.
同时我们可以发现,在我们的bash命令行中,我们可以直接输入ls -a -l系统可以直接输出我们想要的内容,系统也从来不问我们这个命令在那里,这是为什么呢?很简单,因为系统会从我们的环境变量中直接寻找我们的命令.那么,我们可以实现同样的效果嘛?当然可以,我们只需要使用后面带有p(PATH)的exec指令即可.
execlp("ls", "ls", "-a", "-l", NULL);
char* args[] = {"ls","-a","-l",NULL
}
execv("ls", args);
他们的效果是一样的,但是execvp、execlp比前面的函数更见方便.
对于e(environment)选项,如execle、execvpe,它允许用户自定义传入环境变量的配置,但是要注意的是:当我们自己传入了自定义的环境配置之后,子进程将不再继承父进程的环境变量,传入的环境变量将完全覆盖继承父进程的环境变量.
三、替换的本质
上面一直在说进程替换,但是替换的究竟是什么呢?
核心思想:”灵魂“互换,而非”肉体“重生
首先,我们必须建立一个颠覆直觉的认知:程序替换,并不是创建一个新进程。
我们可以把一个正在运行的进程想象成一个拥有独立身份的“躯体”。它有自己的身份ID(PID)、社会关系(父进程PPID)、以及它所拥有的资源(如内存空间、打开的文件等)。而程序,则是寄宿于这个躯体内的“灵魂”,它本质上是一系列将要被CPU执行的指令和数据。程序替换 (exec) 的本质,就是在不改变进程“躯体”和身份的前提下,将它体内的“旧灵魂”(旧程序)彻底清除,然后换上一个全新的“灵魂”(新程序)。
这个过程完成后,进程的PID不会改变,但它执行的代码、使用的数据,已经完完全全是新程序的了。

程序的替换,实则是一场身体灵魂的交换,就像武侠小说里面的夺舍,皮囊还是原来的皮囊,灵魂却已经不在了.
-
被替换的 (红色部分):exec 的核心是彻底替换进程的内存空间。旧程序的代码、全局变量、堆栈等都会被新程序的内容所取代。这是程序的灵魂.
-
**保留的 (绿色部分):**进程在操作系统内核中的“身份”和“上下文”被完整保留了下来。其中,文件描述符的保留至关重要。这意味着,由父进程打开的文件、建立的管道或网络连接,在子进程
exec之后依然有效。这些是程序的躯壳.
四、fork()、exec()、waitpid()联合应用
上面的这三个函数在进程的控制中是联合使用的,他们的不分家的,每个函数各施其职,才能保证程序的稳定运行.我们使用一张图来展示这三个函数对程序的控制流程.
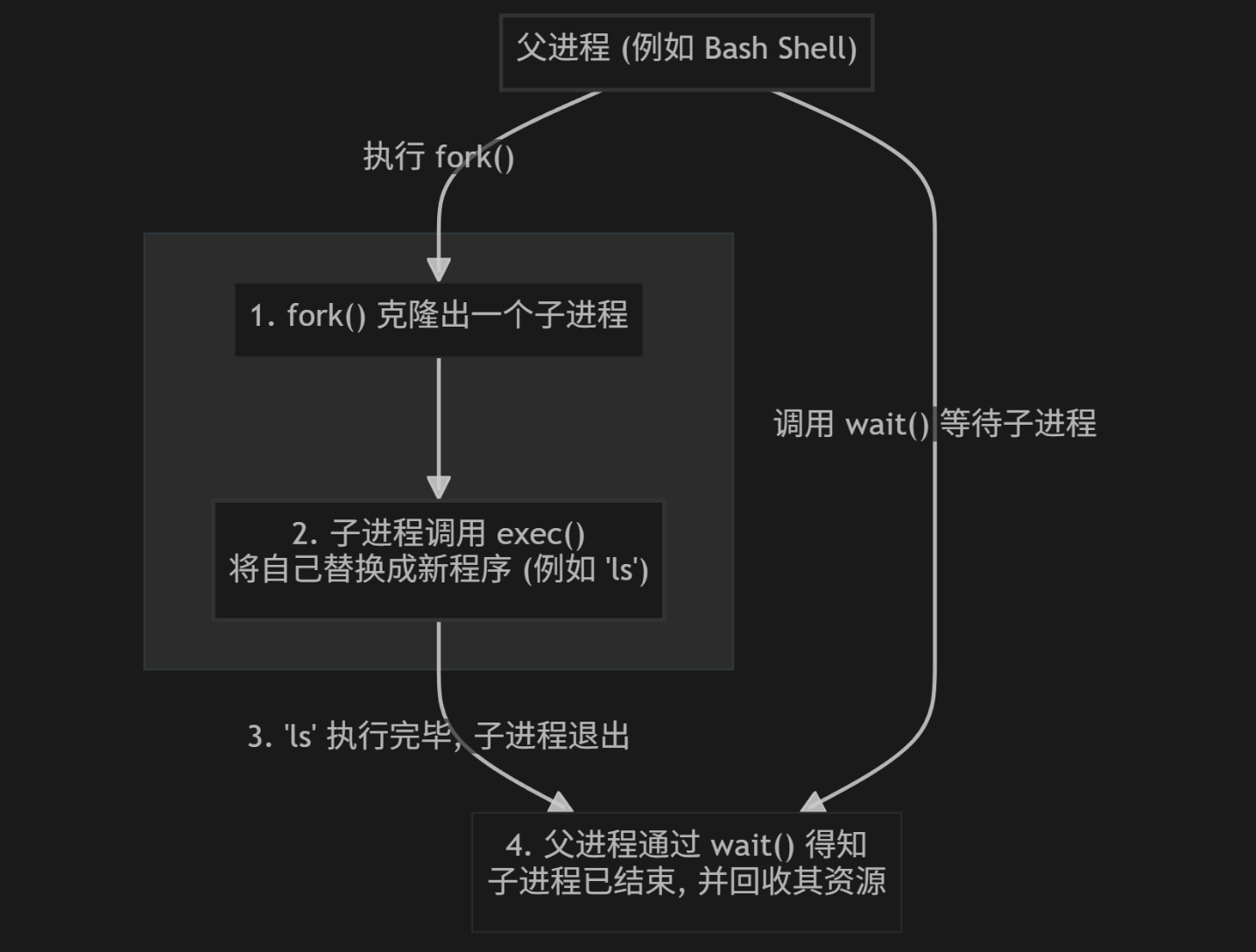
-
fork()- 复制分身:父进程调用 fork(),操作系统会复制一个与父进程几乎一模一样的子进程。这个子进程是父进程的“一次性消耗品”,专门用来执行 exec。 -
exec()- 灵魂互换:在 fork() 成功后,子进程立刻调用 exec 函数,用新程序的“灵魂”替换掉自己从父进程那里继承来的“灵魂”。 -
wait()- 回收资源:父进程则可以通过 wait() 或 waitpid() 函数来等待子进程执行结束,并回收其占用的资源,从而避免产生僵尸进程。
五、程序替换之执行自己的程序
上面我们演示了使用程序替换执行了ls命令,既然说的是:进程程序替换,那我们写的程序运行的时候也是一个进程,那我们当然也可以将子进程替换成我们写好的程序.让我们开始!
#include <stdio.h>
#include <unistd.h>int main(){pid_t id = fork();if(id < 0){printf("进程创建失败\n");return 1;}if(id == 0){sleep(2);printf("程序替换开始!\n");execl("./OtherExe", "OtherExe", "-a", "-l", "b", NULL);printf("子进程替换成ls程序成功\n");}else{printf("父进程等待子进程中\n");waitpid(id, NULL, 0);printf("等待子进程成功\n");sleep(2);printf("父进程执行结束\n");}return 0;
}
#include <stdio.h>
int main(int argc, char* argv[]){int i = 0;printf("This is argv:\n");for(i = 0; argv[i]; i++){printf("argv[%d] = %s\n", i, argv[i]);} return 0;}
父进程等待子进程中
程序替换开始!
This is argv:
argv[0] = OtherExe
argv[1] = -a
argv[2] = -l
argv[3] = b
等待子进程成功
父进程执行结束
所以,我们一个软件可以有多个.exe文件,我们可以通过一个主程序,但用到某些模块的时候,我们可以通过进程程序替换的方式来调用他们.这样我们的程序也就更加的有条理.
5.简单模拟实现shell
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>#include <sys/wait.h>
#include <fcntl.h>#define MAX_LINE 1024 // 输入命令的最大长度
#define MAX_ARGS 128 // 命令参数最大数量
#define HISTORY_SIZE 100 // 历史命令最大条数char *history[HISTORY_SIZE]; // 用于存储历史命令
int history_count = 0; // 当前历史命令数量// 添加命令到历史记录
void add_history(const char *cmd) {if (history_count < HISTORY_SIZE) {history[history_count++] = strdup(cmd);}
}// 显示历史命令
void show_history() {for (int i = 0; i < history_count; ++i) {printf("%d %s\n", i + 1, history[i]);}
}// 解析命令,支持管道、重定向、后台执行
int parse_command(char *line, char **args, int *background, char **infile, char **outfile, int *is_pipe, char **pipe_cmd) {*background = 0; // 是否后台执行*infile = NULL; // 输入重定向文件*outfile = NULL; // 输出重定向文件*is_pipe = 0; // 是否有管道*pipe_cmd = NULL;// 管道右侧命令int argc = 0; // 参数计数char *token = strtok(line, " "); // 按空格分割命令while (token) {if (strcmp(token, "&") == 0) { // 后台执行符号*background = 1;} else if (strcmp(token, ">") == 0) { // 输出重定向token = strtok(NULL, " ");if (token) *outfile = token;} else if (strcmp(token, "<") == 0) { // 输入重定向token = strtok(NULL, " ");if (token) *infile = token;} else if (strcmp(token, "|") == 0) { // 管道*is_pipe = 1;token = strtok(NULL, ""); // 剩下的全是管道命令if (token) *pipe_cmd = token;break;} else {args[argc++] = token; // 普通参数}token = strtok(NULL, " ");}args[argc] = NULL; // 参数数组以NULL结尾return argc;
}// 执行普通命令,支持重定向和后台
void execute_command(char **args, int background, char *infile, char *outfile) {pid_t pid = fork(); // 创建子进程if (pid == 0) {// 子进程if (infile) { // 输入重定向int fd = open(infile, O_RDONLY);if (fd < 0) { perror("open infile"); exit(1); }dup2(fd, STDIN_FILENO); // 替换标准输入close(fd);}if (outfile) { // 输出重定向int fd = open(outfile, O_WRONLY | O_CREAT | O_TRUNC, 0644);if (fd < 0) { perror("open outfile"); exit(1); }dup2(fd, STDOUT_FILENO); // 替换标准输出close(fd);}execvp(args[0], args); // 执行命令perror("execvp"); // execvp失败exit(1);} else if (pid > 0) {// 父进程if (!background) {waitpid(pid, NULL, 0); // 前台等待子进程结束} else {printf("[后台] 进程PID: %d\n", pid); // 后台运行}} else {perror("fork"); // 创建进程失败}
}// 执行管道命令
void execute_pipe(char **args, char *pipe_cmd, int background) {int pipefd[2];pipe(pipefd); // 创建管道pid_t pid1 = fork();if (pid1 == 0) {// 左侧命令(写端)dup2(pipefd[1], STDOUT_FILENO); // 标准输出重定向到管道写端close(pipefd[0]);close(pipefd[1]);execvp(args[0], args);perror("execvp");exit(1);}pid_t pid2 = fork();if (pid2 == 0) {// 右侧命令(读端)char *pipe_args[MAX_ARGS];int dummy_bg; char *infile = NULL, *outfile = NULL, *dummy_pipe = NULL;parse_command(pipe_cmd, pipe_args, &dummy_bg, &infile, &outfile, &dummy_bg, &dummy_pipe);dup2(pipefd[0], STDIN_FILENO); // 标准输入重定向到管道读端close(pipefd[1]);close(pipefd[0]);execvp(pipe_args[0], pipe_args);perror("execvp");exit(1);}close(pipefd[0]);close(pipefd[1]);if (!background) {waitpid(pid1, NULL, 0); // 等待左侧命令结束waitpid(pid2, NULL, 0); // 等待右侧命令结束} else {printf("[后台] 管道进程PID: %d, %d\n", pid1, pid2);}
}int main() {char line[MAX_LINE]; // 存储用户输入while (1) {printf("myshell> "); // 提示符if (!fgets(line, sizeof(line), stdin)) break; // 读取输入line[strcspn(line, "\n")] = 0; // 去除换行符if (strlen(line) == 0) continue; // 空行跳过add_history(line); // 加入历史char *args[MAX_ARGS];int background;char *infile, *outfile, *pipe_cmd;int is_pipe;int argc = parse_command(line, args, &background, &infile, &outfile, &is_pipe, &pipe_cmd); // 解析命令if (argc == 0) continue;// 内置命令处理if (strcmp(args[0], "exit") == 0) break; // 退出shellif (strcmp(args[0], "cd") == 0) {if (args[1]) chdir(args[1]); // 切换目录else chdir(getenv("HOME")); // 默认主目录continue;}if (strcmp(args[0], "history") == 0) {show_history(); // 显示历史continue;}if (is_pipe) {execute_pipe(args, pipe_cmd, background); // 执行管道} else {execute_command(args, background, infile, outfile); // 执行普通命令}}return 0;
} // 程序结束