DEEP THINK WITH CONFIDENCE-Meta-基于置信度的深度思考

原文地址
摘要
大型语言模型(LLM)通过自我一致性和多数投票等测试时间缩放方法,在推理任务中显示出巨大的潜力。然而,这种方法经常导致精度回报递减和高计算开销。为了应对这些挑战,我们引入了深度自信思考(DeepConf),这是一种简单但强大的方法,可以提高推理效率和测试时的性能。DeepConf利用模型内部置信度信号,在生成过程中或生成后动态过滤掉低质量的推理痕迹。它不需要额外的模型训练或超参数调整,并且可以无缝地集成到现有的服务框架中。我们通过各种推理任务和最新的开源模型来评估DeepConf,包括Qwen 3和GPT-OSS系列。值得注意的是,在AIME 2025等具有挑战性的基准上,DeepConf@512实现了高达99.9%的准确率,与完全并行思维相比,生成的令牌减少了高达84.7%。
文章目录
- 摘要
- 1 INTRODUCTION
- 2 CONFIDENCE AS AN INDICATOR OF REASONING QUALITY
- 3 DEEP THINK WITH CONFIDENCE
- 3.1 CONFIDENCE MEASUREMENTS
- 3.2 OFFLINE THINKING WITH CONFIDENCE
- 3.3 ONLINE THINKING WITH CONFIDENCE
- 4 EXPERIMENTS
- 4.1 EXPERIMENTAL SETUP
- 4.2 OFFLINE EVALUATIONS
- 4.3 ONLINE EVALUATIONS
- 5 FUTURE WORK
1 INTRODUCTION
大型语言模型(LLM)已经显示出非凡的推理能力,特别是当配备了在测试时推理期间增强其性能的方法时。一种突出的技术是自我一致性,它对多条推理路径进行采样,并通过多数投票聚集最终答案(Wang等人,2023)。这种类型的方法,也称为并行思维,显著提高了推理精度,但会产生大量的计算开销:每个查询生成大量推理轨迹会线性地扩大推理开销,限制实际部署(薛等人,2023)。例如,在AIME 2025上使用标准多数投票将PASS@1的准确率从68%提高到82%,需要使用Qwen3-8B为每个问题增加511个额外的推理轨迹,消耗1亿个额外的令牌。此外,与多数投票并行的思维表现出回报递减–绩效往往随着踪迹数量的增加而饱和或下降(Chen等人,2024a)。一个关键的限制是,标准多数投票平等对待所有推理痕迹,忽略质量变化(Pal等人,2024;Wang等人,2025)。当低质量跟踪在投票过程中占据主导地位时,这可能会导致性能不佳。最近的工作利用下一个令牌分布统计来评估推理跟踪质量(Geng等人,2024;Fadeeva等人,2024;Kang等人,2025)。较高的预测置信度通常与较低的熵和减少的不确定性相关。通过聚合令牌级统计数据,如熵和置信度分数,现有方法计算整个跟踪的全局置信度度量,以识别和过滤低质量跟踪,以提高多数投票性能(Kang等人,2025)。
然而,全球信心指标在实践中存在几个局限性。首先,它们可能会掩盖局部推理步骤中的置信度波动,这可以为估计轨迹质量提供足够的信号。对跟踪中的整个令牌进行平均可以掩盖在特定中间步骤发生的关键推理故障。其次,全局置信度测量需要在计算之前生成完整的推理轨迹,这防止了低质量轨迹的提前停止。
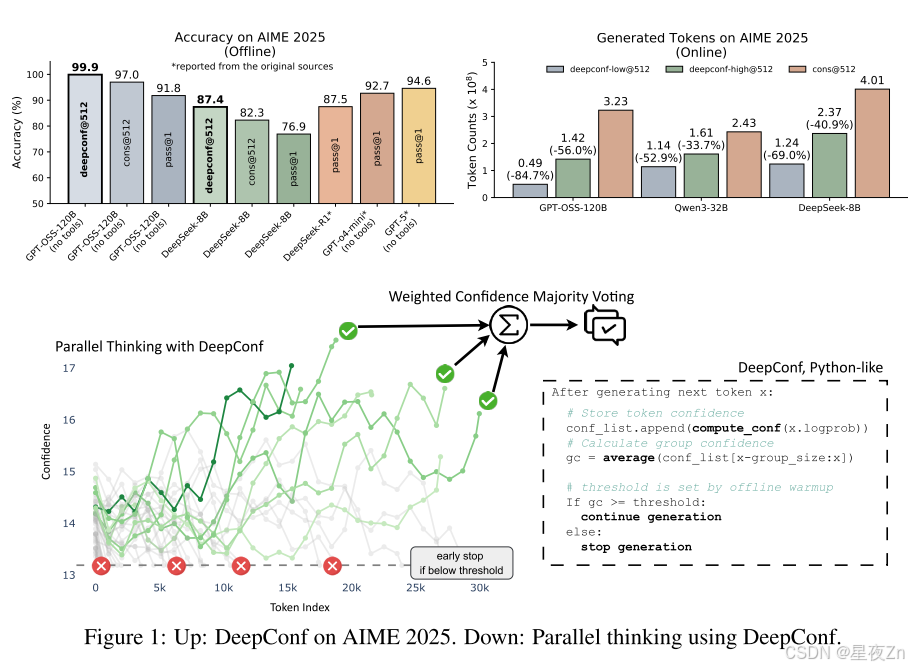
我们介绍了DeepConf,一种简单但有效的测试时间方法,它结合了并行思维和基于局部置信度测量的置信度过滤。DeepConf在离线和在线模式下运行,在生成过程中或生成后识别和丢弃低置信度推理痕迹。这种方法减少了不必要的令牌生成,同时保持或提高了最终答案的准确性。我们在多个推理基准(AIME 2024/2025、HMMT 2025、BRUMO25、GPQA-Diamond)和模型(DeepSeek-8B、Qwen3-8B/32B、GPT-OSS-20B/120B)上评估DeepConf。通过对每个设置平均重复次数的大量实验,我们证明了DeepConf获得了优越的推理性能,并且与标准多数投票相比,所需生成的令牌显著减少。在可以访问所有推理轨迹的离线模式下,DeepConf@512使用GPT-OSS-120B(无工具)在AIME 2025上达到99.9%的准确率,与CONS@512(多数投票)的97.0%和PASS@1的91.8%相比,饱和了这一基准。在具有实时生成控制的在线模式下,DeepConf在保持或超过准确性的同时,与标准并行思维相比,最高可减少84.7%的令牌生成。图1突出显示了我们的主要结果。
2 CONFIDENCE AS AN INDICATOR OF REASONING QUALITY
最近的工作表明,使用从模型的内部令牌分布导出的度量,可以有效地估计推理跟踪质量。(2025)。这些度量提供了模型固有的信号,用于区分高质量的推理轨迹和错误的推理轨迹,而不需要外部监督。令牌熵。给定语言模型在位置i处的预测令牌分布PI,令牌熵被定义为:
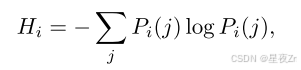
其中,PI(J)表示第j个词汇标记的概率。低熵表示具有较高模型确定性的峰值分布,而高熵表示预测中的不确定性。
Token Confidence. 我们将令牌置信度Ci定义为位置i处的前k个令牌的负平均对数概率:
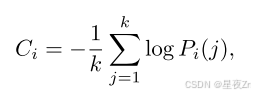
其中k表示所考虑的顶级令牌的数量。高置信度对应于峰值分布和更大的模型确定性,而低置信度表示令牌预测中的不确定性。
Average Trace Confidence. 令牌级指标需要聚合来评估整个推理痕迹。追随Kang等人的研究。(2025),我们使用平均跟踪置信度(也称为自信度)作为跟踪级别的质量衡量标准:
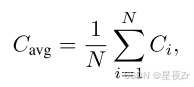
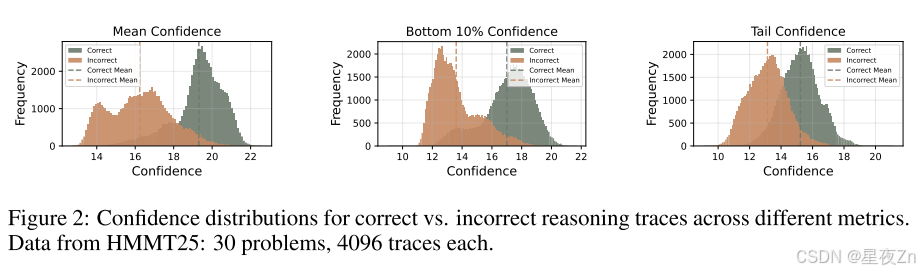
其中N是生成的令牌总数。如图2所示,平均跟踪置信度有效地区分正确和不正确的推理路径,值越高表示正确的可能性越大。尽管它是有效的,但平均跟踪置信度有显著的局限性。首先,全局聚合掩盖了中间推理失败:几个高置信度令牌可以掩盖大量低置信度片段,潜在地隐藏关键错误。其次,这种方法需要对质量评估进行完整的跟踪,防止过早终止低质量的生成并导致计算效率低下。
3 DEEP THINK WITH CONFIDENCE
在这一部分中,我们将介绍如何更有效地利用置信度度量来提高推理性能和思维效率。我们的目标是两个主要场景:线下和在线思维。离线思维通过评估和聚合来自完成的推理痕迹的信息来利用信心来提高推理性能。在线思维在令牌生成过程中结合了置信度,以实时提高推理性能和/或计算效率。
3.1 CONFIDENCE MEASUREMENTS
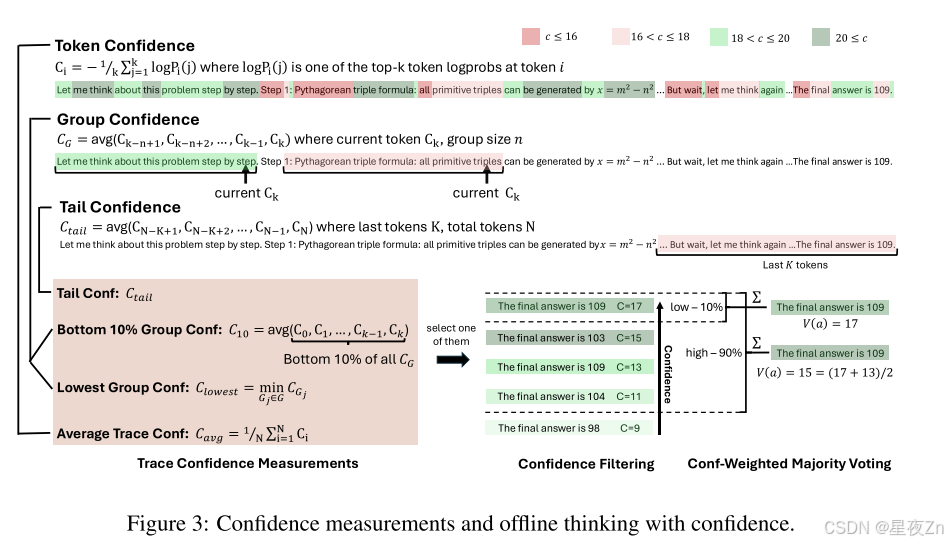
为了解决像自信这样的全局置信度度量的局限性,我们引入了几种替代的置信度度量,它们捕获了局部中间步骤质量,并提供了对推理痕迹的更细粒度的评估。
团体自信心。我们使用群体置信度来量化中间推理步骤的置信度。通过在推理轨迹的重叠跨度上平均标记置信度,群体置信度提供了更局部化和更平滑的信号。每个令牌与滑动窗口组Gi相关联,滑动窗口组Gi由具有重叠的相邻窗口的n个先前令牌(例如,n=1024或2048)组成。对于每个组GI,组信任度定义为:
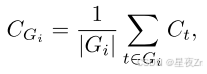 其中,|gi|是组gi中的令牌数。
其中,|gi|是组gi中的令牌数。
估计推理轨迹质量需要从群体置信度中聚合信号。我们观察到,跟踪可信度极低的中间步骤会显著影响最终解的正确性。例如,当在推理过程中,当置信度急剧下降时,使用重复的低置信度标记,如“等待”、“然而”和“再想一想”,就会扰乱推理流程,并导致后续错误。
Bottom 10% Group Confidence。为了捕捉极低置信度组的影响,我们提出了最低10%的组置信度,其中跟踪置信度由跟踪内最低10%的组置信度的平均值确定:
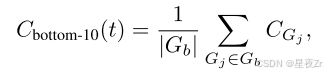
其中,GB是具有最低10%置信度分数的组的集合。经验上,我们发现10%有效地捕获了不同模型和数据集中最有问题的推理片段。
Lowest Group Confidence. 我们还考虑了最低群体置信度,它代表了推理轨迹中最不自信的群体的置信度–最低10%的群体置信度的特殊情况。此测量仅基于最低置信度组来评估跟踪质量:
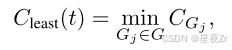
Tail Confidence. 除了基于组的度量之外,我们还提出了尾部置信度,它通过关注最后一部分来评估推理跟踪的可靠性。这一衡量标准的动机是观察到,推理质量通常会在长链思维的末端降级,而最后几步对于正确的结论至关重要。在数学推理中,最终答案和结论步骤尤其重要:尽管中间推理前景看好,但开始强劲但结束薄弱的轨迹可能会产生不正确的结果。尾部置信度尾部定义为:
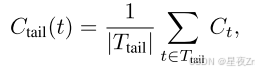
其中Tail表示固定数量的令牌(例如,2048)。图2比较了不同的置信度度量,说明与平均置信度方法相比,底部10%和尾部置信度度量都更好地分离不正确和正确的跟踪分布,这表明这些度量对于跟踪质量估计更有效。
3.2 OFFLINE THINKING WITH CONFIDENCE
我们现在描述如何应用各种置信度度量来提高离线设置下的推理性能。在离线思考中,每个问题的推理轨迹都已经生成,关键挑战是从多个轨迹中聚合信息,以更好地确定最终答案。虽然最近的工作提出了使用LLMS来总结和分析推理轨迹的先进方法,但我们专注于标准的多数投票方法。
Majority Voting. 在标准多数投票中,来自每个推理轨迹的最终答案对最终决定的贡献是平等的。设T是所有生成的轨迹的集合,对于每个t答案T,设∈(T)是从轨迹t中提取的答案串。每个候选答案a的投票计数为:
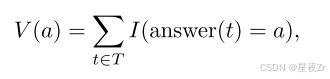
其中 I{⋅}I\{\cdot\}I{⋅} 是指示函数。最终答案通过最高票数选出:
a^=argmaxaV(a).\hat{a} = \arg \max_a V(a).a^=argamaxV(a).
置信度加权多数投票
不同于对每条推理轨迹的投票平等对待,我们根据相应轨迹的置信度对每个最终答案进行加权。对于每个候选答案 aaa,其总投票权重定义为:
V(a)=∑t∈TCt⋅I(answer(t)=a),V(a) = \sum_{t \in T} C_t \cdot I(\text{answer}(t) = a),V(a)=t∈T∑Ct⋅I(answer(t)=a),
其中 CtC_tCt 是从前文讨论的置信度度量方法中选取的轨迹级置信度。我们选择获得最高加权票数的答案。这种投票机制倾向于支持高置信度轨迹产生的答案,从而降低不确定或低质量推理结果的影响。
置信度过滤
除了加权多数投票外,我们还采用置信度过滤机制以集中关注高置信度的推理轨迹。该机制根据轨迹置信度分数筛选前 η\etaη% 的轨迹,确保只有最可靠的路径对最终答案产生贡献。我们为所有置信度度量提供两个选项:η=10%\eta = 10\%η=10% 和 η=90%\eta = 90\%η=90%。
选择前10%的方案侧重于最高置信度分数,适用于仅需少量可靠轨迹即可获得准确结果的情况。但过度依赖极少数量轨迹会因模型偏差而导致错误答案。选择前90%的方案提供了更平衡的策略,通过纳入更广泛的轨迹保持多样性并降低模型偏差。这在置信度分布趋于均匀时尤为重要,能确保替代推理路径得到充分考虑。图3展示了置信度度量的示意图及离线思考机制与置信度的协同工作原理。算法II提供了具体实现细节。
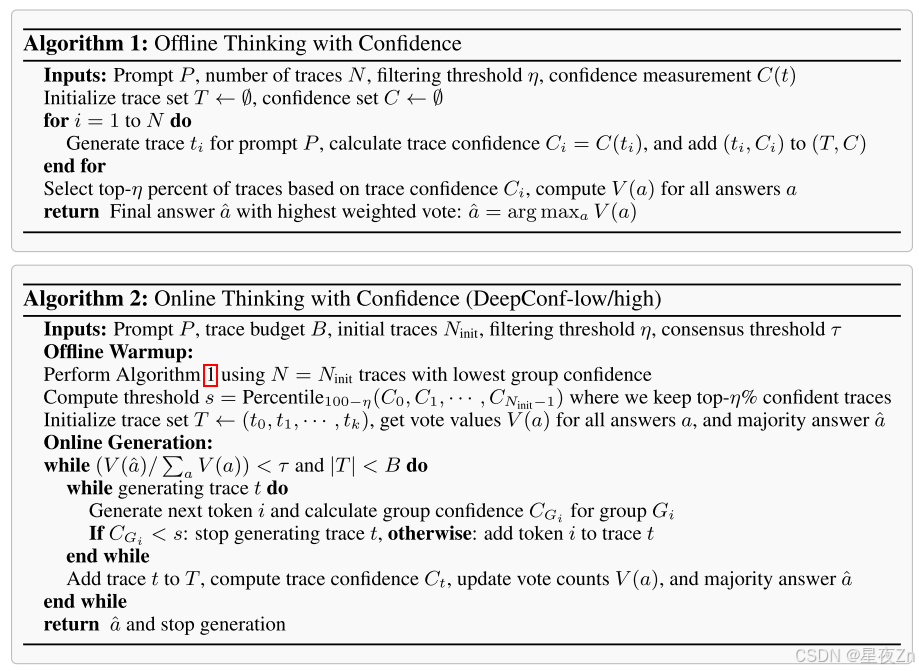
3.3 ONLINE THINKING WITH CONFIDENCE
在在线思考期间评估可信度,可以在生成过程中实时估计痕迹质量,从而动态终止不看好的痕迹。此方法在资源受限的环境中或需要快速响应时特别有用。在此在线设置中可以有效地应用最低组置信度度量。当令牌组置信度低于关键阈值时,我们可以停止跟踪生成,从而确保此类跟踪很可能在置信度过滤期间被排除。
我们提出DeepConf-low和DeepConf-high这两种基于最低组置信度的算法,它们能在在线思考过程中自适应地停止生成并调整轨迹预算。该方法包含两个主要组件:离线预热和自适应采样。
离线预热
DeepConf需要离线预热阶段来建立用于在线判定的停止阈值sss。对于每个新提示,我们生成NinitN_{\text{init}}Ninit条推理轨迹(例如Ninit=16N_{\text{init}} = 16Ninit=16)。停止阈值sss定义为:
s=Percentile100−η({Ct:t∈Twarmup}),s = \text{Percentile}_{100-\eta} (\{ C_t : t \in T_{\text{warmup}} \}),s=Percentile100−η({Ct:t∈Twarmup}),
其中TwarmupT_{\text{warmup}}Twarmup表示所有预热轨迹,CtC_tCt是轨迹ttt的置信度,η\etaη为预设保留比例。具体而言,DeepConf-low统一采用前η=10%\eta = 10\%η=10%(对应第90百分位数),DeepConf-high统一采用前η=90%\eta = 90\%η=90%(对应第10百分位数)。该阈值确保在线生成过程中,当轨迹置信度低于预热阶段最高置信度前η%\eta\%η%轨迹的水平时即终止生成。
自适应采样
在DeepConf中,我们采用跨所有方法的自适应采样机制,根据问题难度动态调整生成轨迹数量(Xue等[2023])。难度通过已生成轨迹的共识度评估,量化为多数投票权重V(a^)V(\hat{a})V(a^)与总投票权重∑aV(a)\sum_a V(a)∑aV(a)的比值:
β=V(a^)∑aV(a).\beta = \frac{V(\hat{a})}{\sum_a V(a)}.β=∑aV(a)V(a^).
其中τ\tauτ是预设共识阈值。当β<τ\beta < \tauβ<τ时,模型对当前问题未达成共识,继续生成轨迹直至达到固定轨迹预算BBB;否则立即停止轨迹生成,并基于现有轨迹确定最终答案。
由于采用最低组置信度机制,足够大的预热集能准确估计停止阈值sss——任何在线终止的轨迹其组置信度均低于sss,因而会被离线过滤器排除。因此在线过程近似模拟离线最低组置信度策略,且随着NinitN_{init}Ninit增大,其准确度逐渐逼近离线准确度(详见附录B.2)。图4展示了在线生成过程,算法2提供了具体实现细节。
4 EXPERIMENTS
4.1 EXPERIMENTAL SETUP
Models。我们评估了来自三个模型家族的五个开源推理LLM:DeepSeek8B1(Guo等人,2025)、Qwen3-8B、Qwen3-32B(Yang等人,2025a)、GPT-OSS-20B和GPTOSS-120B(OpenAI,2025)。这些模型以强大的数学推理和长期的思维链性能而被公认,在可重复性方面完全开源,并涵盖多个参数范围以测试稳健性。附录F提供了完整的生成超参数和提示模板。
基准。我们在五个具有挑战性的数据集上进行评估:AIME24(问题解决的艺术,2024a;b)、AIME25(问题解决的艺术,2025a;b)、BRUMO25(Bru,2025)、HMMT25(HMMT,2025)和GPQA(Rein等人,2024)。前四个是高难度的数学竞赛问题,而GPQA包括研究生级别的STEM推理任务。所有基准都被广泛采用在最近的顶级推理LLM的评估中(例如,Grok-4(Xai,2025),Qwen3(Yang等人,2025a),GPT-5(OpenAI,2025)),并出现在MathArena排行榜(Balunoviüc等人,2025)中。
基线。我们采用自我一致性(Wang等人,2023年),多数投票作为我们的主要基线。每个LLM对T条独立推理路径进行采样,并通过未加权多数投票选择最终答案,如SEC中形式化的。3.2.
实验设置。对于每个问题,我们通过预先生成一个由4,096个完整推理轨迹组成的池来建立一个通用的采样框架;该池作为离线和在线评估的基础。离线实验在每次运行时从该池中重新采样大小为K(例如,K=512)的工作集,并应用指定的投票方法。在线实验类似地对工作集进行重新采样,以通过提前停止来驱动即时生成;该池确保了跨方法的一致采样。
我们报告了四种关键方法:(I)PASS@1(单迹精度),(Ii)CONS@K(具有K个迹线的未加权多数投票准确率),(Iii)MEASure@K(置信度加权多数表决准确度),以及(Iv)MEASure+TOP-η%@K,它在应用加权多数表决之前保留样本工作集中按置信度最高的η%迹(我们使用η∈{10,90})。具体的置信度衡量标准因设置而异。我们还报告生成的令牌总数。所有指标都是独立运行的平均值,并带有新的重新采样;除非特别说明,否则会对所有生成的轨迹进行端到端的计数,而提前终止的轨迹只会贡献停止前生成的令牌。
对于在线评估,我们使用最低组置信度(等式)实例化DeepConf-Low和DeepConf-High6)具有2,048个令牌的重叠窗口。每个问题都以NINIT=16条用于离线预热的完整轨迹开始;然后我们设置特定于运行的停止阈值S=MINT∈Ttop Ct,其中Ttop包含置信度最高的百分位数轨迹(η=10用于深度会议低,η=90用于深度会议高;秒。3.3)。在生成过程中,提前终止当前群体置信度低于S的轨迹;通过信任度加权多数投票聚合完成的轨迹,并在达成共识≥τ或预算K时自适应地停止生成。
对于离线评估,我们对SEC的三个跟踪级别置信度定义进行了基准测试。3.1:(I)平均跟踪置信度(Eq.3)、(Ii)最低10%的群体置信度(等式5),以及(Iii)最后2,048个令牌的尾置信度(等式7)。对于每个指标,我们使用η{10,90}报告MEASure@K和MEASure+TOP-η∈%@K,其中每次运行时都会在采样工作集中重新计算TOP-η%截止值(3.2)。
4.2 OFFLINE EVALUATIONS
在表1中,我们在投票大小为K=512的五个数据集上提供了三个模型的离线结果。我们比较了以下方法:PASS@1=单轨迹精度;CONS@512=具有512个轨迹的未加权多数投票;Mean Conf@512=使用平均轨迹置信度(Eq.3);Bottom-10%Conf@512和Tail Conf@512=使用(I)最低10%重叠组信任度的平均值(等式)进行的信心加权多数投票5)和(Ii)最后2,048个令牌的平均置信度(等式7)。90%/10%子列表示置信度筛选中的保留率η:我们在投票前将最高η%的最高置信度跟踪保留在样本工作集中。例如,当K=512时,η=10%时,我们保留了大约51个轨迹用于投票。
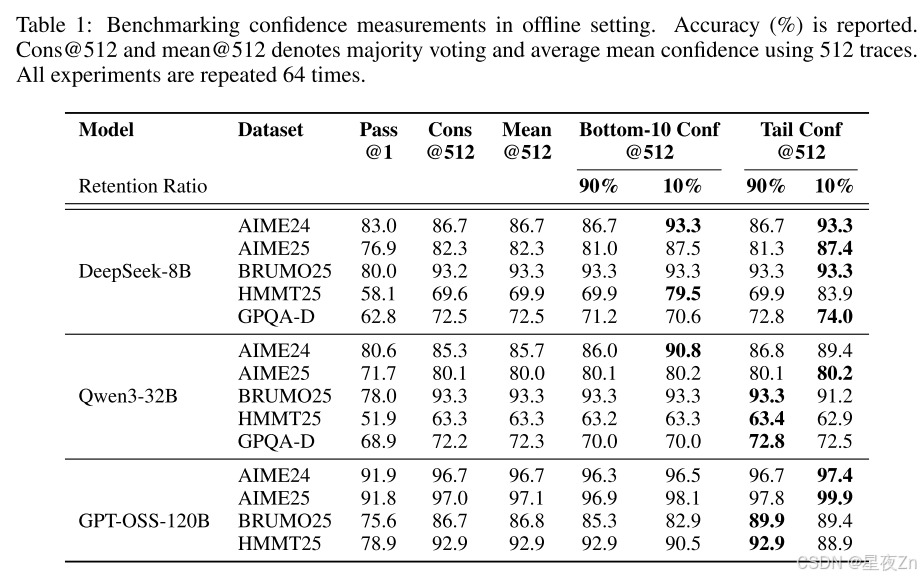
总体而言,在大多数设置中,信心感知加权和过滤始终优于标准多数投票(Cons@512)。η=10%的过滤效果最好,AIME25上的DeepSeek-8B(82.3%→87.4%)和AIME24上的Qwen3-32B(85.3%→90.8%)都有显著的改善,AIME25上的GPT-OSS-120B甚至达到99.9%。局部(Tail Conf和Bottom-10%)和全局(Average Trace Conf)置信度测量在识别有信心的踪迹方面都显示出令人振奋的结果。然而,过滤涉及到重要的权衡:虽然积极过滤(η=10%)在大多数情况下可以最大限度地提高精度,但有时会由于模型对错误问题过于自信而损害性能,就像GPT-OSS-120B所看到的那样。在这种情况下,保守过滤(η=90%)提供了更安全的选择。与PASS@1相比,在所有方法中都观察到了实质性的改进,证实了集合方法的价值。我们在附录B.4中提供了详细的置信度比较。
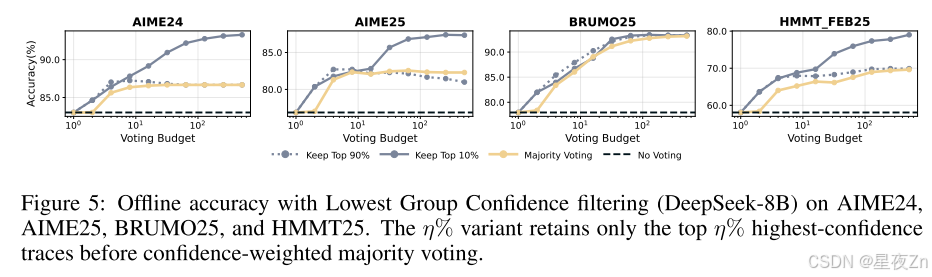
然后,我们证明了最低组置信度也是有效的。图5使用最低组置信度(等式)报告离线结果6)捕获每个踪迹内最不可信的令牌组(窗口大小2,048)。在每个采样的工作集内,我们保留最高η%的最高置信度跟踪,然后应用置信度加权多数投票。在使用DeepSeek-8B的AIME24、AIME25、BRUMO25和HMMT25中,保留最高η=10%的结果比多数投票获得的最佳准确率有一致的提高:+0.26%到+9.38%(平均+5.27%),比单一跟踪(或不投票)的准确率有很大提高(+10.26%到+20.94个百分点;平均+14.30%)。保守的η=90%设置符合或略高于所有四个数据集的最佳多数投票精度(+0.16%至+0.57%;平均+0.29),同时仍比单道精度(平均+9.31%)有很大改进。这些结果激发了在线变量:关注最不可信的部分可靠地识别出具有局部推理故障的痕迹,为离线过滤提供了强烈的信号,并在在线生成期间提供了一个自然停止的标准。除了这些结果之外,我们在附录B.3中去除了保留率η,并在附录C中提供了完整的脱机结果。
4.3 ONLINE EVALUATIONS
在这一部分中,我们通过改变预算K∈{32,,128,256,512}来评估在线算法的精度和成本之间的权衡,其中成本计算所有生成的标记,包括来自早期停止的跟踪的部分标记。遵循SEC。3.3.我们使用NINIT=16个轨迹执行预热,以设置使用最低组置信度(窗口大小2,048)的停止阈值S:我们按置信度将S设置在最高η%的预热轨迹上(η∈{10,90}),然后一旦其当前的组置信度降到S以下,就终止任何新的轨迹。在每个新的轨迹完成后,我们重新应用相同的阈值S进行过滤,以便该过程与最低组置信度过滤器的离线版本相匹配,同时节省了早期停止的轨迹的成本。我们考虑两个在线变量:DeepConf-Low(η=10%)和DeepConf-High(η=90%),它们将继续采样,直到达到共识≥τ(我们使用τ=0.95%)或预算上限K。我们比较了仅预算的变量(总是运行到上限K而不一致停止)和附录B.1中不同的τ值。
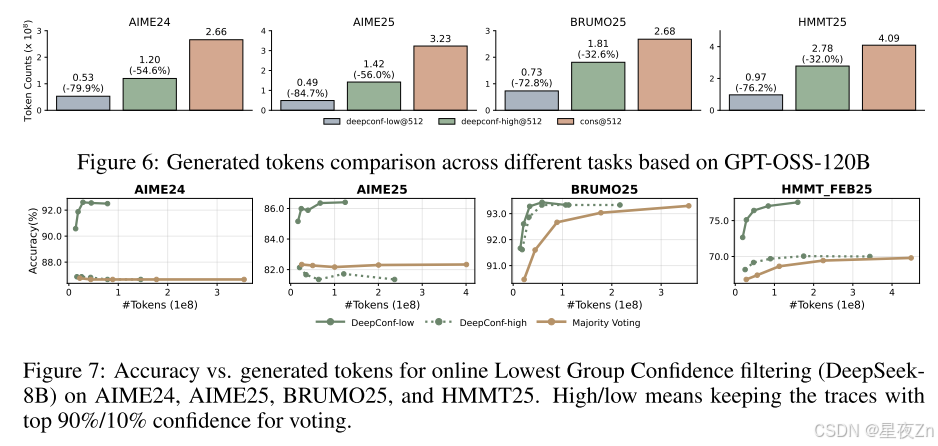
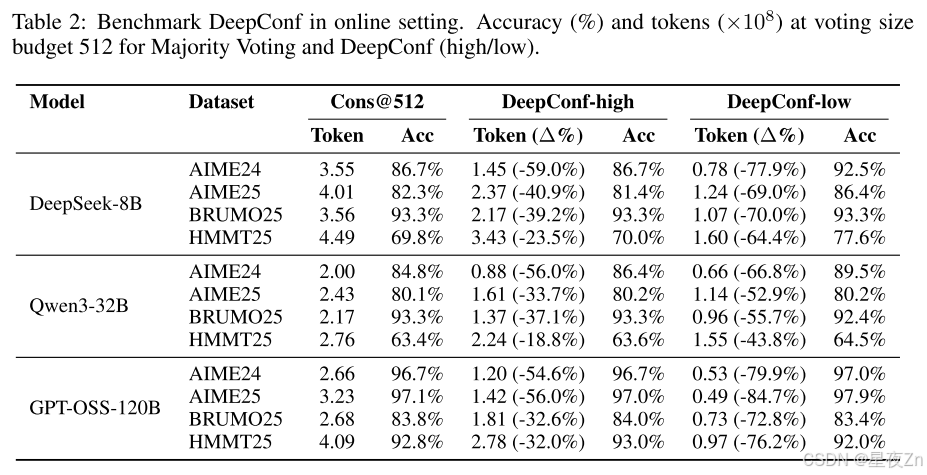
表2显示了在投票大小预算为K=512的DeepSeek-8B/Qwen3-32B/GPT-OSS-120B上DeepConf的自适应采样版本的性能。与多数投票基准相比,DeepConf-Low在AIME24/AIME25/BRUMO25/HMMT25中减少了43%-79%的令牌。虽然它在大多数情况下匹配或提高了精度(例如,DeepSeek-8B AIME24:+5.8%),但它在一些设置中经历了显著的精度下降(例如,Qwen3-32B BRUMO25:−0.9%)。更保守的DeepConf-HIGH在这些集合上节省了18%-59%的令牌,同时保持了几乎相同的精度,或者只会导致最小的性能下降。图6可视化了GPT-OSS-120B的令牌减少模式,说明了DeepConf如何在保持跨不同数学推理任务的竞争性准确性的同时实现大量的计算节省(即,高达85.8%)。
图7比较了DeepConf和DeepSeek-8B上的多数投票基线。DeepConf方法在保持同等精度的同时显示出明显的效率优势:与相同精度水平的多数投票基线相比,DeepConf-low实现了62.88%的平均令牌节省,DeepConf-High实现了47.67%的平均令牌节省。在性能方面,DeepConf的行为反映了离线设置:η=10%(低)过滤在大多数情况下产生最高的精度提升,尽管它有时可能会导致特定数据集的精度下降(例如,表2中HMMT25上的GPT-OSS-120B)。
这些结果支持我们的设计:使用最不可信的段来选通跟踪,为提前终止提供了强烈的本地信号,而自适应共识停止在不牺牲精度的情况下进一步压缩了令牌。此外,我们在附录B.2中提供了预热尺寸NINIT的消融,并在附录D中报告了完整的在线结果。
5 FUTURE WORK
我们相信,从这项工作中可以得出几个有希望的方向。首先,将DeepConf扩展到强化学习环境可以利用基于信心的提前停止来指导策略探索,并在培训期间提高样本效率。第二,解决模型在不正确的推理路径上表现出高度置信度的情况,这是我们在实验中观察到的一个关键限制。未来的工作还可以探索更稳健的置信度校准技术和不确定性量化方法,以更好地识别和缓解过度自信但错误的预测。
我们提出了DeepConf,这是一种简单而有效的方法,在集成投票场景中显著提高了推理性能和计算效率。通过在最先进的推理模型和具有挑战性的数据集上进行广泛的实验,DeepConf展示了显著的准确性改进,同时实现了有意义的令牌节省,在从8B到120B参数的模型范围内观察到了一致的好处。我们希望这种方法突出了测试时间压缩作为一种实用和可扩展的有效LLM推理解决方案的潜力。
以上内容全部使用机器翻译,如果存在错误,请在评论区留言。欢迎一起学习交流!
郑重声明:
- 本文内容为个人对相关文献的分析和解读,难免存在疏漏或偏差,欢迎批评指正;
- 本人尊重并致敬论文作者、编辑和审稿人的所有劳动成果,若感兴趣,请阅读原文并以原文信息为准;
- 本文仅供学术探讨和学习交流使用,不适也不宜作为任何权威结论的依据。
- 如有侵权,请联系我删除。xingyezn@163.com