自适应滤波器:Ch1 正交性原理->维纳-霍夫方程
维纳滤波器
维纳滤波器是自适应滤波器下的一类线性最优离散滤波器。有别于传统意义的滤波器设计,维纳滤波器一般用于复值随机过程,其滤波器的输出表征的是一种估计。
维纳滤波器一般采用FIR形式,如下所示:
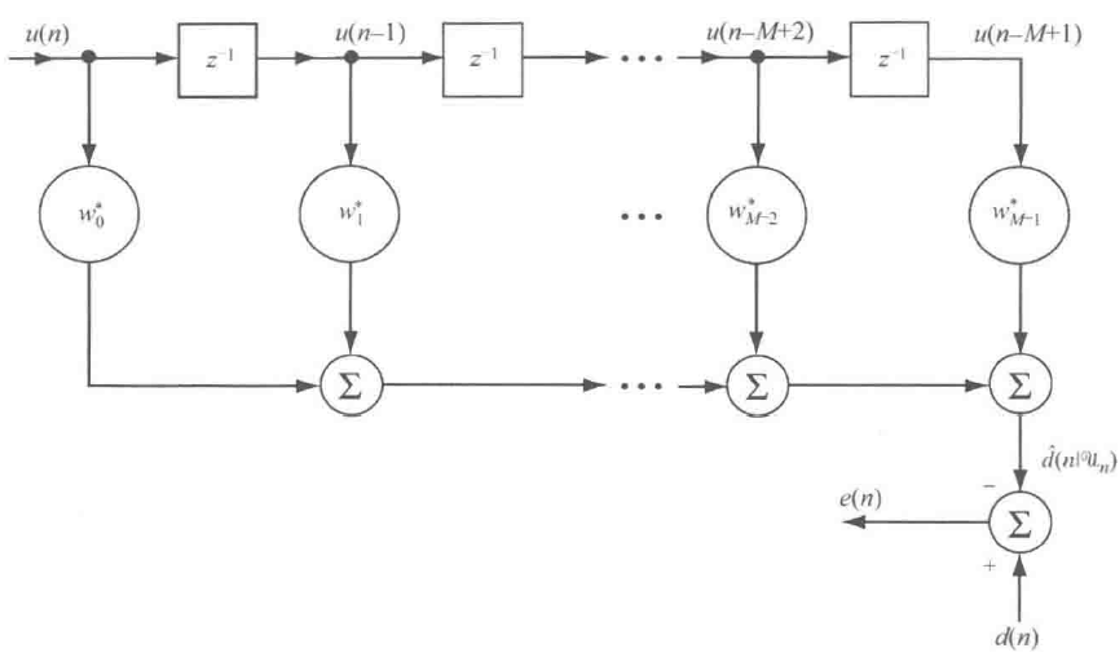
由上图可得,维纳滤波器的输出(是一个估计值)被定义为d^(n)\widehat{d}(n)d(n),也就是n时刻的估计。即
d^(n)=∑k=0M−1w∗k∗u(n−k)\widehat{d}(n) = \sum_{k = 0}^{M - 1}{{w^{*}}_{k}*u(n - k)}\ d(n)=k=0∑M−1w∗k∗u(n−k)
该滤波器具备
-
M级输入,u(n−k),k=0,1,2,3,…,M−1u(n - k),\ \ k = 0,1,2,3,\ldots,M - 1u(n−k), k=0,1,2,3,…,M−1
-
M级系数,w∗k,k=0,1,2,3,…,M−1{w^{*}}_{k},\ \ k = 0,1,2,3,\ldots,M - 1w∗k, k=0,1,2,3,…,M−1
-
输出d^(n)\widehat{d}(n)d(n),其上标^表示该值为估计输出(不带上标^的表示期望输出)。
估计误差被定义为期望输出与估计输出的差值,即
e(n)=d(n)−d^(n)e(n) = d(n) - \widehat{d}(n)e(n)=d(n)−d(n)
注意:
-
这里将FIR的级数限制为M,而不是无穷,是因为这里仅考虑有限的FIR结构
-
这里w∗k{w^{*}}_{k}w∗k的星号指的是共轭复数。这里的u(n−k)u(n - k)u(n−k)和w∗k{w^{*}}_{k}w∗k都是复数。
在滤波器优化设计过程中,可以考虑采用某种最小代价函数或者某个性能指标来衡量,一般有下列几种选择:
-
估计误差的均方值
-
估计误差绝对值的期望值
-
估计误差绝对值的三阶或高阶期望值
选项1在数学上更加容易处理,而且选择均方误差准则导致滤波器冲激响应未知系数代价函数的二阶相关性,同时该代价函数有一个独特的最小值能唯一的定义滤波器的统计优化设计。故维纳滤波器所用的代价函数是估计误差的均方值,即
J=E[e(n)∗e∗(n)]=E[∣e(n)∣2]J = E\lbrack e(n)*e^{*}(n)\rbrack = E\lbrack|e(n)|^{2}\rbrackJ=E[e(n)∗e∗(n)]=E[∣e(n)∣2]
上式中符号EEE表示期望(expectation)
而代价函数J的最小值,就是维纳滤波器的最优解。因此维纳滤波器的设计,就是求取代价函数J的最小值时的滤波器系数(LMMSE,线性最小均方误差估计器)。
关于维纳滤波器的最优解,下面将会从两个角度分别证明:一个是从正交性原理出发,另一个是从误差曲面出发。两者的结果是等价的,下面分别给出证明。
正交性原理
正交性原理->维纳-霍夫方程
将估计误差e(n)e(n)e(n)的表达式代入到代价函数J中后进一步得到
J=E[(d(n)−d^(n))∗(d∗(n)−d^∗(n))]=E[(d(n)−∑k=0M−1u(n−k)∗w∗k)∗(d∗(n)−∑i=0M−1u∗(n−i)∗wi)]{J = E\lbrack(d(n) - \widehat{d}(n))*(d^{*}(n) - {\widehat{d}}^{*}(n))\rbrack }{= E\left\lbrack \left( d(n) - \sum_{k = 0}^{M - 1}{u(n - k)*}{w^{*}}_{k} \right)*\left( d^{*}(n) - \sum_{i = 0}^{M - 1}{u^{*}(n - i)*}w_{i} \right) \right\rbrack}J=E[(d(n)−d(n))∗(d∗(n)−d∗(n))]=E[(d(n)−k=0∑M−1u(n−k)∗w∗k)∗(d∗(n)−i=0∑M−1u∗(n−i)∗wi)]
由于滤波器系数wkw_{k}wk和w∗k{w^{*}}_{k}w∗k是复数,它可以进一步的被表示为实数和虚数的和,即
wk=ak+j∗bkw_{k} = a_{k} + j*b_{k}wk=ak+j∗bk
w∗k=ak−j∗bk{w^{*}}_{k} = a_{k} - j*b_{k}w∗k=ak−j∗bk
定义梯度算子∇k\nabla_{k}∇k(即对第k个滤波器系数的实数部分和虚数部分分别求偏导),即
∇k=∂∂ak+j∂∂bk\nabla_{k} = \frac{\partial}{\partial a_{k}} + j\frac{\partial}{\partial b_{k}}∇k=∂ak∂+j∂bk∂
使得所有的梯度算子(k=0,1,…M-1)作用于J后都为0,也就是一阶导为0,可得最小J
∇kJ=∂J∂ak+j∂J∂bk=0\nabla_{k}J = \frac{\partial J}{\partial a_{k}} + j\frac{\partial J}{\partial b_{k}} = 0∇kJ=∂ak∂J+j∂bk∂J=0
下面详细计算梯度算子
∇kJ=∂J∂ak+j∂J∂bk=E[∂[e(n)∗e∗(n)]∂ak]+jE[∂[e(n)∗e∗(n)]∂bk]=E[∂e(n)∂ak∗e∗(n)+∂e∗(n)∂ak∗e(n)+j∂e(n)∂bk∗e∗(n)+j∂e∗(n)∂bk∗e(n)]{\nabla_{k}J = \frac{\partial J}{\partial a_{k}} + j\frac{\partial J}{\partial b_{k}} = E\left\lbrack \frac{\partial\left\lbrack e(n)*e^{*}(n) \right\rbrack}{\partial a_{k}} \right\rbrack + jE\left\lbrack \frac{\partial\left\lbrack e(n)*e^{*}(n) \right\rbrack}{\partial b_{k}} \right\rbrack }{= E\left\lbrack \frac{\partial e(n)}{\partial a_{k}}*e^{*}(n) + \frac{\partial e^{*}(n)}{\partial a_{k}}*e(n) + j\frac{\partial e(n)}{\partial b_{k}}*e^{*}(n) + j\frac{\partial e^{*}(n)}{\partial b_{k}}*e(n) \right\rbrack}∇kJ=∂ak∂J+j∂bk∂J=E[∂ak∂[e(n)∗e∗(n)]]+jE[∂bk∂[e(n)∗e∗(n)]]=E[∂ak∂e(n)∗e∗(n)+∂ak∂e∗(n)∗e(n)+j∂bk∂e(n)∗e∗(n)+j∂bk∂e∗(n)∗e(n)]
偏微分的计算过程都是类似的,下面将详细计算第一个部分,即
∂e(n)∂ak=∂(d(n)−d^(n))∂ak=−∂d^(n)∂ak=−∂(∑k=0M−1u(n−k)∗w∗k)∂ak=−∂(u(n−k)∗w∗k)∂ak=−∂(u(n−k)∗(ak−j∗bk))∂ak=−u(n−k){\frac{\partial e(n)}{\partial a_{k}} = \frac{\partial\left( d(n) - \widehat{d}(n) \right)}{\partial a_{k}} = - \frac{\partial\widehat{d}(n)}{\partial a_{k}} = - \frac{\partial\left( \sum_{k = 0}^{M - 1}{u(n - k)*{w^{*}}_{k}} \right)}{\partial a_{k}} = - \frac{\partial\left( u(n - k)*{w^{*}}_{k} \right)}{\partial a_{k}} }{= - \frac{\partial\left( u(n - k)*\left( a_{k} - j*b_{k} \right) \right)}{\partial a_{k}} }{= - u(n - k)}∂ak∂e(n)=∂ak∂(d(n)−d(n))=−∂ak∂d(n)=−∂ak∂(∑k=0M−1u(n−k)∗w∗k)=−∂ak∂(u(n−k)∗w∗k)=−∂ak∂(u(n−k)∗(ak−j∗bk))=−u(n−k)
同理可得下面所有的偏微分结果,如下
∂e(n)∂ak=−u(n−k)∂e(n)∂bk=j∗u(n−k)∂e∗(n)∂ak=−u∗(n−k)∂e∗(n)∂bk=−j∗u∗(n−k){\frac{\partial e(n)}{\partial a_{k}} = - u(n - k) }{\frac{\partial e(n)}{\partial b_{k}} = j*u(n - k) }{\frac{\partial e^{*}(n)}{\partial a_{k}} = - u^{*}(n - k) }{\frac{\partial e^{*}(n)}{\partial b_{k}} = - j*u^{*}(n - k)}∂ak∂e(n)=−u(n−k)∂bk∂e(n)=j∗u(n−k)∂ak∂e∗(n)=−u∗(n−k)∂bk∂e∗(n)=−j∗u∗(n−k)
将这四个偏微分结果全都代入,可得
∇kJ=E[−u(n−k)∗e∗(n)−u∗(n−k)∗e(n)−u(n−k)∗e∗(n)+u∗(n−k)∗e(n)]=E[−u(n−k)∗e∗(n)−u(n−k)∗e∗(n)]=−2∗E[u(n−k)∗e∗(n)]{\nabla_{k}J = E\left\lbrack - u(n - k)*e^{*}(n) - u^{*}(n - k)*e(n) - u(n - k)*e^{*}(n) + u^{*}(n - k)*e(n) \right\rbrack }{= E\left\lbrack - u(n - k)*e^{*}(n) - u(n - k)*e^{*}(n) \right\rbrack }{= - 2*E\left\lbrack u(n - k)*e^{*}(n) \right\rbrack }∇kJ=E[−u(n−k)∗e∗(n)−u∗(n−k)∗e(n)−u(n−k)∗e∗(n)+u∗(n−k)∗e(n)]=E[−u(n−k)∗e∗(n)−u(n−k)∗e∗(n)]=−2∗E[u(n−k)∗e∗(n)]
重新整理一下得到
∇kJ=−2∗E[u(n−k)∗e∗(n)]\nabla_{k}J = - 2*E\left\lbrack u(n - k)*e^{*}(n) \right\rbrack∇kJ=−2∗E[u(n−k)∗e∗(n)]
当滤波器工作在最优条件下时,J将达到最小值,此时:
-
最优条件时 ∇kJ\nabla_{k}J∇kJ 应当为0.
-
最优条件时滤波器输出的估计值 d^(n)\widehat{d}(n)d(n)
被重新定义为最优估计d^0(n){\widehat{d}}_{0}(n)d0(n),下标0代表最优解。 -
最优条件时估计误差 e(n)e(n)e(n) 也被重新定义为最优估计误差e0(n)e_{0}(n)e0(n)
,下标0代表最优解。
e(n)=d(n)−d^(n)→J最小d(n)−d^0(n)=e0(n)e(n) = d(n) - \widehat{d}(n)\overset{J最小}{\rightarrow}d(n) - {\widehat{d}}_{0}(n) = e_{0}(n)e(n)=d(n)−d(n)→J最小d(n)−d0(n)=e0(n)
因此当滤波器工作在最优条件时可得正交性原理,即
E[u(n−k)∗e∗0(n)]=0,k=0,1,2,3,……M−1E\left\lbrack u(n - k)*{e^{*}}_{0}(n) \right\rbrack = 0,k = 0,1,2,3,\ldots\ldots M - 1E[u(n−k)∗e∗0(n)]=0,k=0,1,2,3,……M−1
正交性原理:
使得滤波器工作在最优解,或者使得代价函数J获得最小值的充要条件是:在n时刻的估计误差e(n)e(n)e(n)正交与滤波器的任意一个输入u(n−k),k=0,1,2,3,…M−1u(n - k),\ \ k = 0,1,2,3,\ldots M - 1u(n−k), k=0,1,2,3,…M−1
进一步查看滤波器输出的估计值d^(n)\widehat{d}(n)d(n)与估计误差e(n)e(n)e(n)的相关特性:
E[d^(n)∗e∗(n)]=E[∑k=0M−1w∗k∗u(n−k)∗e∗(n)]=∑k=0M−1w∗k∗E[u(n−k)∗e∗(n)]E\left\lbrack \widehat{d}(n)*e^{*}(n) \right\rbrack = E\left\lbrack \sum_{k = 0}^{M - 1}{{w^{*}}_{k}*u(n - k)}*e^{*}(n) \right\rbrack = \sum_{k = 0}^{M - 1}{{w^{*}}_{k}*E\lbrack u(n - k)}*e^{*}(n)\rbrackE[d(n)∗e∗(n)]=E[k=0∑M−1w∗k∗u(n−k)∗e∗(n)]=k=0∑M−1w∗k∗E[u(n−k)∗e∗(n)]
当满足正交条件时,即
E[u(n−k)∗e∗0(n)]=0,k=0,1,2,3,……M−1E\left\lbrack u(n - k)*{e^{*}}_{0}(n) \right\rbrack = 0,k = 0,1,2,3,\ldots\ldots M - 1E[u(n−k)∗e∗0(n)]=0,k=0,1,2,3,……M−1
e(n)=d(n)−d^(n)→J最小d(n)−d^0(n)=e0(n)e(n) = d(n) - \widehat{d}(n)\overset{J最小}{\rightarrow}d(n) - {\widehat{d}}_{0}(n) = e_{0}(n)e(n)=d(n)−d(n)→J最小d(n)−d0(n)=e0(n)
上式进一步变为如下所示,其中w∗0k{w^{*}}_{0k}w∗0k表示最优条件下的滤波器系数。
E[d^(n)∗e∗(n)]⇒J最小∑k=0M−1w∗0k∗E[u(n−k)∗e∗0(n)]=0E\left\lbrack \widehat{d}(n)*e^{*}(n) \right\rbrack\overset{J最小}{\Rightarrow}\sum_{k = 0}^{M - 1}{{w^{*}}_{0k}*E\lbrack u(n - k)}*{e^{*}}_{0}(n)\rbrack = 0E[d(n)∗e∗(n)]⇒J最小k=0∑M−1w∗0k∗E[u(n−k)∗e∗0(n)]=0
重新整理一下可得正交性原理的推论:在最优条件下,滤波器的输出估计值d^(n)\widehat{d}(n)d(n)正交与估计误差e(n)e(n)e(n),即
E[d^(n)∗e∗(n)]=0E\left\lbrack \widehat{d}(n)*e^{*}(n) \right\rbrack = 0E[d(n)∗e∗(n)]=0
正交原理总结:
-
滤波器工作在最优条件下,期望响应的估值用d^0(n){\widehat{d}}_{0}(n)d0(n)表示,相应的估计误差e0(n)e_{0}(n)e0(n)与他们互相正交
E[d^0(n)∗e∗0(n)]=0E\left\lbrack {\widehat{d}}_{0}(n)*{e^{*}}_{0}(n) \right\rbrack = 0E[d0(n)∗e∗0(n)]=0 -
滤波器工作在最优条件下,估计误差e0(n)e_{0}(n)e0(n)正交与n时刻进入期望响应估计的每一个输入样值
E[u(n−k)∗e∗0(n)]=0E\lbrack u(n - k)*{e^{*}}_{0}(n)\rbrack = 0E[u(n−k)∗e∗0(n)]=0
k=0,1,2,3,……M−1k = 0,1,2,3,\ldots\ldots M - 1k=0,1,2,3,……M−1
接下来利用正交原理以及推论进一步推导维纳滤波器及其最优解。
同时将E[u(n−k)∗e∗0(n)]=0,k=0,1,2,3,……M−1E\left\lbrack u(n - k)*{e^{*}}_{0}(n) \right\rbrack = 0,k = 0,1,2,3,\ldots\ldots M - 1E[u(n−k)∗e∗0(n)]=0,k=0,1,2,3,……M−1
e(n)=d(n)−d^(n)→J最小d(n)−d^0(n)=e0(n)e(n) = d(n) - \widehat{d}(n)\overset{J最小}{\rightarrow}d(n) - {\widehat{d}}_{0}(n) = e_{0}(n)e(n)=d(n)−d(n)→J最小d(n)−d0(n)=e0(n)
代入正交公式E[u(n−k)∗e∗0(n)]=0E\lbrack u(n - k)*{e^{*}}_{0}(n)\rbrack = 0E[u(n−k)∗e∗0(n)]=0,可得:
E[u(n−k)∗e∗0(n)]=E[u(n−k)∗(d∗(n)−d^0∗(n))]=E[u(n−k)∗(d∗(n)−∑i=oM−1u∗(n−i)∗w0i)]=0{E\left\lbrack u(n - k)*{e^{*}}_{0}(n) \right\rbrack = E\left\lbrack u(n - k)*\left( d^{*}(n) - {{\widehat{d}}_{0}}^{*}(n) \right) \right\rbrack }{= E\left\lbrack u(n - k)*\left( d^{*}(n) - \sum_{i = o}^{M - 1}{u^{*}(n - i)*}w_{0i} \right) \right\rbrack = 0}E[u(n−k)∗e∗0(n)]=E[u(n−k)∗(d∗(n)−d0∗(n))]=E[u(n−k)∗(d∗(n)−i=o∑M−1u∗(n−i)∗w0i)]=0
展开并整理可继续得到
E[u(n−k)∗d∗(n)]=∑i=oM−1w0i∗E[u(n−k)u∗(n−i)]E\left\lbrack u(n - k)*d^{*}(n) \right\rbrack = \sum_{i = o}^{M - 1}{w_{0i}*E\lbrack u(n - k)u^{*}(n - i)}\rbrackE[u(n−k)∗d∗(n)]=i=o∑M−1w0i∗E[u(n−k)u∗(n−i)]
继续定义自相关函数
r(i−k)=E[u(n−k)u∗(n−i)]r(i - k) = E\left\lbrack u(n - k)u^{*}(n - i) \right\rbrackr(i−k)=E[u(n−k)u∗(n−i)]
互相关函数
p(−k)=E[u(n−k)∗d∗(n)]p( - k) = \ E\left\lbrack u(n - k)*d^{*}(n) \right\rbrackp(−k)= E[u(n−k)∗d∗(n)]
利用这两个相关函数,进一步得到了最优滤波器的另一个充要条件,也就是维纳-霍夫方程
∑i=0M−1w0i∗r(i−k)=p(−k),k=0,1,2,3,……M−1\sum_{i = 0}^{M - 1}w_{0i}*r(i - k) = p( - k),k = 0,1,2,3,\ldots\ldots M - 1i=0∑M−1w0i∗r(i−k)=p(−k),k=0,1,2,3,……M−1
其中 r(i−k)r(i - k)r(i−k) 代表相隔i-k个延迟的滤波器输入的自相关函数(u(n−k)u(n - k)u(n−k)
and u(n−i)u(n - i)u(n−i))
其中 p(−k)p( - k)p(−k)代表了滤波器输入与期望输出相隔-k个延迟的互相关(u(n−k)u(n - k)u(n−k) and d(n)d(n)d(n))
由此我们从正交性原理出发,结合实际的自相关函数和互相关函数,我们得到了滤波器的最优解是满足维纳-霍夫方程的,也就得到了滤波器的再最优条件下的系数的取值w0iw_{0i}w0i
为了方便求解维纳-霍夫方程,下面采用矩阵的形式。
首先定义u(n)u(n)u(n)的自相关矩阵R,它是一个M X M的方矩阵。
R=E[u→∗u→H]R = E\lbrack{\overset \rightarrow {u}}*{{\overset \rightarrow {u}}}^{H}\rbrackR=E[u→∗u→H]
其中u→{\overset \rightarrow {u}}u→和u→H{{\overset \rightarrow {u}}}^{H}u→H的定义如下,其中上标H代表取厄米共轭,即转置+共轭
u→=[u(n)u(n−1)u(n−2)...u(n−M+1)],u→H=[u∗(n)u∗(n−1)u∗(n−2)...u∗(n−M+1)]\overset \rightarrow{u} = \begin{bmatrix} u(n) \\ u(n - 1) \\ u(n - 2) \\ ... \\ u(n - M + 1) \end{bmatrix},\ {{\overset \rightarrow {u}}}^{H} = \begin{bmatrix} u^{*}(n) & u^{*}(n - 1) & u^{*}(n - 2) & ... & u^{*}(n - M + 1) \end{bmatrix}u→=u(n)u(n−1)u(n−2)...u(n−M+1), u→H=[u∗(n)u∗(n−1)u∗(n−2)...u∗(n−M+1)]
因此可得
R=[r(0)r(1)r(2)...r(M−1)r∗(1)r(0)r(1)...r(M−2)r∗(2)r∗(1)r(0)...r(M−3)...............r∗(M−1)r∗(M−2)r∗(M−3)...r(0)]R = \begin{bmatrix} r(0) & r(1) & r(2) & ... & r(M - 1) \\ r^{*}(1) & r(0) & r(1) & ... & r(M - 2) \\ r^{*}(2) & r^{*}(1) & r(0) & ... & r(M - 3) \\ ... & ... & ... & ... & ... \\ r^{*}(M - 1) & r^{*}(M - 2) & r^{*}(M - 3) & ... & r(0) \end{bmatrix}R=r(0)r∗(1)r∗(2)...r∗(M−1)r(1)r(0)r∗(1)...r∗(M−2)r(2)r(1)r(0)...r∗(M−3)...............r(M−1)r(M−2)r(M−3)...r(0)
矩阵各个元素计算举例
r(0)=E[u(n)∗u∗(n)]=E[u(n−1)∗u∗(n−1)]=E[u(n−M+1)∗u∗(n−M+1)]r(1)=E[u(n)∗u∗(n−1)]=E[u(n−1)∗u∗(n−2)]=E[u(n−M+2)∗u∗(n−M+1)]r∗(1)=(r(1))∗=(E[u(n)∗u∗(n−1)])∗=E[u(n−1)∗u∗(n)]=E[u(n−M+1)∗u∗(n−M+2)]{r(0) = E\left\lbrack u(n)*u^{*}(n) \right\rbrack = E\left\lbrack u(n - 1)*u^{*}(n - 1) \right\rbrack = E\left\lbrack u(n - M + 1)*u^{*}(n - M + 1) \right\rbrack }{r(1) = E\lbrack u(n)*u^{*}(n - 1)\rbrack = E\lbrack u(n - 1)*u^{*}(n - 2)\rbrack = E\lbrack u(n - M + 2)*u^{*}(n - M + 1)\rbrack }{r^{*}(1) = (r(1))^{*} = (E\lbrack u(n)*u^{*}(n - 1)\rbrack)^{*} = E\lbrack u(n - 1)*u^{*}(n)\rbrack = E\lbrack u(n - M + 1)*u^{*}(n - M + 2)\rbrack}r(0)=E[u(n)∗u∗(n)]=E[u(n−1)∗u∗(n−1)]=E[u(n−M+1)∗u∗(n−M+1)]r(1)=E[u(n)∗u∗(n−1)]=E[u(n−1)∗u∗(n−2)]=E[u(n−M+2)∗u∗(n−M+1)]r∗(1)=(r(1))∗=(E[u(n)∗u∗(n−1)])∗=E[u(n−1)∗u∗(n)]=E[u(n−M+1)∗u∗(n−M+2)]
接下来定义互相关矩阵P
P=E[u∗d∗(n)]=E[[u(n)u(n−1)u(n−2)…u(n−M+1)]∗d∗(n)]=[p(0)p(−1)p(−2)...p(−M+1)]P = E\left\lbrack \overset{}{u}*d^{*}(n) \right\rbrack = E\left\lbrack \begin{bmatrix} u(n) \\ u(n - 1) \\ u(n - 2) \\ \ldots \\ u(n - M + 1) \end{bmatrix}*d^{*}(n) \right\rbrack = \begin{bmatrix} p(0) \\ p( - 1) \\ p( - 2) \\ ... \\ p( - M + 1) \end{bmatrix}P=E[u∗d∗(n)]=Eu(n)u(n−1)u(n−2)…u(n−M+1)∗d∗(n)=p(0)p(−1)p(−2)...p(−M+1)
矩阵各个元素计算举例
p(0)=E[u(n)∗d∗(n)]p(−1)=E[u(n−1)∗d∗(n)]{p(0) = E\left\lbrack u(n)*d^{*}(n) \right\rbrack }{p( - 1) = E\left\lbrack u(n - 1)*d^{*}(n) \right\rbrack}p(0)=E[u(n)∗d∗(n)]p(−1)=E[u(n−1)∗d∗(n)]
将P和R代入,即可得到
R∗w→0=PR*{\overset \rightarrow {w}}_{0} = PR∗w→0=P
其中w→0{\overset \rightarrow {w}}_{0}w→0就是最优条件下的滤波器系数,即
w→0=[w01w02…w0M−1]{\overset \rightarrow {w}}_{0} = \begin{bmatrix} w_{01} \\ \begin{matrix} w_{02} \\ \ldots \end{matrix} \\ w_{0M - 1} \end{bmatrix}w→0=w01w02…w0M−1
如果R矩阵是非奇异的,可以解出w→0{\overset \rightarrow {w}}_{0}w→0矩阵,即
w→0=R−1∗P{\overset \rightarrow {w}}_{0} = R^{- 1}*Pw→0=R−1∗P
因此为了求取最优条件下的滤波器抽头系数(或者说最优抽头权向量)需要知道两个条件:
-
输入的自相关函数
-
输入和期望输出的互相关函数
小结
这一节我们从正交性原理出发,推得维纳霍夫方程。也就是说,满足维纳-霍夫方程就可以使得滤波器工作在最优条件,此时估计误差的均方值最小。
估计误差的均方值J最小
↓\downarrow↓
∇kJ=0\nabla_{k}J = 0∇kJ=0
↓\downarrow↓
E[u(n−k)∗e∗0(n)]=0E\lbrack u(n - k)*{e^{*}}_{0}(n)\rbrack = 0E[u(n−k)∗e∗0(n)]=0
↓\downarrow↓
w→0=R−1∗P{\overset \rightarrow {w}}_{0} = R^{- 1}*Pw→0=R−1∗P
正交性原理->最小均方误差
接下来利用正交原理来推导估计的均方误差的最小值,即代价函数最小值。
重写最优估计误差e0(n)e_{0}(n)e0(n),期望输出d(n)d(n)d(n)和最优估计值d^0(n){\widehat{d}}_{0}(n)d0(n)三者之间的关系。
d(n)−d^0(n)=e0(n)d(n) - {\widehat{d}}_{0}(n) = e_{0}(n)d(n)−d0(n)=e0(n)
也可以写成
d(n)=d^0(n)+e0(n)d(n) = {\widehat{d}}_{0}(n) + e_{0}(n)d(n)=d0(n)+e0(n)
上式的左右两边分别取方差,左式的方差就是
var(d(n))=E[(d(n)−E(d(n)))2]=σd2{var}(d(n)) = E\lbrack(d(n) - E(d(n)))^{2}\rbrack = {\sigma_{d}}^{2}var(d(n))=E[(d(n)−E(d(n)))2]=σd2
右式的方差就是
var(d^0(n)+e0(n))=E[(d^0(n)+e0(n)−E[d^0(n)+e0(n)])2]=E[(d^0(n)−E[d^0(n)])2]+E[(e0(n)−E[e0(n)])2]−2∗E[[d^0(n)−E[d^0(n)]]∗[e0∗(n)−E[e0∗(n)]]]=σd^02+E[(e0(n)2]−2[E[d^0(n)∗e0∗(n)]−E[d^0(n)]∗E[e0∗(n)]]=σd^02+J[E[d^0(n)∗e0∗(n)]−E[d^0(n)]∗E[e0∗(n)]]min=σd^02+Jmin{{var}({\widehat{d}}_{0}(n) + e_{0}(n)) = E\lbrack({\widehat{d}}_{0}(n) + e_{0}(n) - E\lbrack{\widehat{d}}_{0}(n) + e_{0}(n)\rbrack)^{2}\rbrack }{= E\lbrack({\widehat{d}}_{0}(n) - E\lbrack{\widehat{d}}_{0}(n)\rbrack)^{2}\rbrack + E\lbrack(e_{0}(n) - E\lbrack e_{0}(n)\rbrack)^{2}\rbrack }{- 2*E\left\lbrack \left\lbrack {\widehat{d}}_{0}(n) - E\lbrack{\widehat{d}}_{0}(n)\rbrack \right\rbrack*\left\lbrack {e_{0}}^{*}(n) - E\lbrack{e_{0}}^{*}(n)\rbrack \right\rbrack \right\rbrack }{= {\sigma_{{\widehat{d}}_{0}}}^{2} + E\lbrack(e_{0}(n)^{2}\rbrack - 2\left\lbrack E\lbrack{\widehat{d}}_{0}(n)*{e_{0}}^{*}(n)\rbrack - E\lbrack{\widehat{d}}_{0}(n)\rbrack*E\lbrack{e_{0}}^{*}(n)\rbrack \right\rbrack }{= {\sigma_{{\widehat{d}}_{0}}}^{2} + {J\left\lbrack E\lbrack{\widehat{d}}_{0}(n)*{e_{0}}^{*}(n)\rbrack - E\lbrack{\widehat{d}}_{0}(n)\rbrack*E\lbrack{e_{0}}^{*}(n)\rbrack \right\rbrack}_{\min} }{= {\sigma_{{\widehat{d}}_{0}}}^{2} + J_{\min}}var(d0(n)+e0(n))=E[(d0(n)+e0(n)−E[d0(n)+e0(n)])2]=E[(d0(n)−E[d0(n)])2]+E[(e0(n)−E[e0(n)])2]−2∗E[[d0(n)−E[d0(n)]]∗[e0∗(n)−E[e0∗(n)]]]=σd02+E[(e0(n)2]−2[E[d0(n)∗e0∗(n)]−E[d0(n)]∗E[e0∗(n)]]=σd02+J[E[d0(n)∗e0∗(n)]−E[d0(n)]∗E[e0∗(n)]]min=σd02+Jmin
上式在求解过程中用到了:
-
即输入u(n)u(n)u(n)是0均值的,即E(d^0(n))=E(∑k=0M−1w∗k∗u(n−k))=∑k=0M−1w∗k∗E(u(n−k))=0E\left( {\widehat{d}}_{0}(n) \right) = E\left( \sum_{k = 0}^{M - 1}{{w^{*}}_{k}*u(n - k)} \right) = \sum_{k = 0}^{M - 1}{{w^{*}}_{k}*E\left( u(n - k) \right)} = 0E(d0(n))=E(k=0∑M−1w∗k∗u(n−k))=k=0∑M−1w∗k∗E(u(n−k))=0
-
正交原理
E[d^0(n)∗e∗0(n)]=0E\lbrack{\widehat{d}}_{0}(n)*{e^{*}}_{0}(n)\rbrack = 0E[d0(n)∗e∗0(n)]=0
- 最优估计误差的均方,就是最小的代价函数
JminJ_{\min}Jmin
联立左右两式的方差结果可得
σd2=σd^02+Jmin{\sigma_{d}}^{2} = {\sigma_{{\widehat{d}}_{0}}}^{2} + J_{\min}σd2=σd02+Jmin
或者
Jmin=σd2−σd^02J_{\min} = {\sigma_{d}}^{2} - \ {\sigma_{{\widehat{d}}_{0}}}^{2}Jmin=σd2− σd02
其中 σd\sigma_{d}σd 是期望输出的方差,σd^0\sigma_{{\widehat{d}}_{0}}σd0是最优估计的方差,JminJ_{\min}Jmin就是最优估计时的代价函数的最小值
回顾一下,d^(n)\widehat{d}(n)d(n) 表示估值,它由FIR滤波器计算得到,形式如下
d^(n)=∑k=0M−1w∗k∗u(n−k)\widehat{d}(n) = \sum_{k = 0}^{M - 1}{{w^{*}}_{k}*u(n - k)}d(n)=k=0∑M−1w∗k∗u(n−k)
同时引用上面定义的矩阵:
u→=[u(n)u(n−1)u(n−2)...u(n−M+1)],w→=[w0w1w2...wM−1],w→H=[w∗0w∗1w∗2...w∗M−1]{\overset \rightarrow {u}} = \begin{bmatrix} u(n) \\ u(n - 1) \\ u(n - 2) \\ ... \\ u(n - M + 1) \end{bmatrix},\ {\overset \rightarrow {w}} = \begin{bmatrix} w_{0} \\ w_{1} \\ w_{2} \\ ... \\ w_{M - 1} \end{bmatrix},{\overset \rightarrow {w}}^{H} = \begin{bmatrix} {w^{*}}_{0} & {w^{*}}_{1} & {w^{*}}_{2} & ... & {w^{*}}_{M - 1} \end{bmatrix}u→=u(n)u(n−1)u(n−2)...u(n−M+1), w→=w0w1w2...wM−1,w→H=[w∗0w∗1w∗2...w∗M−1]
因此可以将FIR滤波器重新写成
d^(n)=∑k=oM−1u(n−k)∗w∗k=[w∗0w∗1w∗2...w∗M−1]∗[u(n)u(n−1)u(n−2)...u(n−M+1)]=w→H∗u→{\widehat{d}(n) = \sum_{k = o}^{M - 1}{u(n - k)*}{w^{*}}_{k} }{= \begin{bmatrix} {w^{*}}_{0} & {w^{*}}_{1} & {w^{*}}_{2} & ... & {w^{*}}_{M - 1} \end{bmatrix}*\begin{bmatrix} u(n) \\ u(n - 1) \\ u(n - 2) \\ ... \\ u(n - M + 1) \end{bmatrix} = {\overset \rightarrow {w}}^{H}*{\overset \rightarrow {u}}}d(n)=k=o∑M−1u(n−k)∗w∗k=[w∗0w∗1w∗2...w∗M−1]∗u(n)u(n−1)u(n−2)...u(n−M+1)=w→H∗u→
因此估计的均方σd^2{\sigma_{\widehat{d}}}^{2}σd2也可以改写如下,其中E(d^(n))=0E\left( \widehat{d}(n) \right) = 0E(d(n))=0
σd^2=E[(d^(n)−E(d^(n))2]=E[(d^(n))2]=E[d^(n)d^∗(n)]=E[w→Hu→∗(w→Hu→)H]=E[w→H∗u→∗u→H∗w→]=w→H∗E(u→∗u→H)∗w→=w→HRw→{{\sigma_{\widehat{d}}}^{2} = E\left\lbrack {(\widehat{d}(n) - E(\widehat{d}(n))}^{2} \right\rbrack = E\left\lbrack \left( \widehat{d}(n) \right)^{2} \right\rbrack = E\left\lbrack \widehat{d}(n){\widehat{d}}^{*}(n) \right\rbrack = E\lbrack{\overset \rightarrow {w}}^{H}{\overset \rightarrow {u}}*({\overset \rightarrow {w}}^{H}{\overset \rightarrow {u}})^{H}\rbrack }{= E\lbrack{\overset \rightarrow {w}}^{H}*{\overset \rightarrow {u}}*{{\overset \rightarrow {u}}}^{H}*{\overset \rightarrow {w}}\rbrack = {\overset \rightarrow {w}}^{H}*E({\overset \rightarrow {u}}*{{\overset \rightarrow {u}}}^{H})*{\overset \rightarrow {w}} = {\overset \rightarrow {w}}^{H}R{\overset \rightarrow {w}}}σd2=E[(d(n)−E(d(n))2]=E[(d(n))2]=E[d(n)d∗(n)]=E[w→Hu→∗(w→Hu→)H]=E[w→H∗u→∗u→H∗w→]=w→H∗E(u→∗u→H)∗w→=w→HRw→
其中R就是之前被定义的自相关函数矩阵
R=[r(0)r(1)r(2)...r(M−1)r∗(1)r(0)r(1)...r(M−2)r∗(2)r∗(1)r(0)...r(M−3)...............r∗(M−1)r∗(M−2)r∗(M−3)...r(0)]R = \begin{bmatrix} r(0) & r(1) & r(2) & ... & r(M - 1) \\ r^{*}(1) & r(0) & r(1) & ... & r(M - 2) \\ r^{*}(2) & r^{*}(1) & r(0) & ... & r(M - 3) \\ ... & ... & ... & ... & ... \\ r^{*}(M - 1) & r^{*}(M - 2) & r^{*}(M - 3) & ... & r(0) \end{bmatrix}R=r(0)r∗(1)r∗(2)...r∗(M−1)r(1)r(0)r∗(1)...r∗(M−2)r(2)r(1)r(0)...r∗(M−3)...............r(M−1)r(M−2)r(M−3)...r(0)
回忆一下之前的矩阵形式的维纳-霍夫方程,也就是说当维纳滤波器工作在最优条件时,最优滤波器系数w→0{\overset \rightarrow {w}}_{0}w→0应当满足下式:
R∗w→0=PR*{\overset \rightarrow {w}}_{0} = PR∗w→0=P
或者
w→0=R−1∗P{\overset \rightarrow {w}}_{0} = R^{- 1}*Pw→0=R−1∗P
将维纳-霍夫方程代入σd^2{\sigma_{\widehat{d}}}^{2}σd2的表达式,可继续得到在最优条件下的σd^02{\sigma_{{\widehat{d}}_{0}}}^{2}σd02转化为:
σd^02=w→0HRw→0=((w→0H(Rw→0))H)H=((Rw→0)H∗w→0)H=(PH∗w→0)H=(PHR−1P)H{{\sigma_{{\widehat{d}}_{0}}}^{2} = {{\overset \rightarrow {w}}_{0}}^{H}R{\overset \rightarrow {w}}_{0} = (({{\overset \rightarrow {w}}_{0}}^{H}(R{\overset \rightarrow {w}}_{0}))^{H})^{H} = ((R{\overset \rightarrow {w}}_{0})^{H}*{\overset \rightarrow {w}}_{0})^{H} = (P^{H}*{\overset \rightarrow {w}}_{0})^{H} }{= {(P^{H}R^{- 1}P)}^{H}}σd02=w→0HRw→0=((w→0H(Rw→0))H)H=((Rw→0)H∗w→0)H=(PH∗w→0)H=(PHR−1P)H
因为σd^02{\sigma_{{\widehat{d}}_{0}}}^{2}σd02一定是实数,而实数的厄米共轭还是自己本身,因此σd^02{\sigma_{{\widehat{d}}_{0}}}^{2}σd02可继续转化为
σd^02=(σd^02)H=((PHR−1P)H)H=PHR−1P{\sigma_{{\widehat{d}}_{0}}}^{2} = \left( {\sigma_{{\widehat{d}}_{0}}}^{2} \right)^{H} = {(\left( P^{H}R^{- 1}P \right)^{H})}^{H} = P^{H}R^{- 1}Pσd02=(σd02)H=((PHR−1P)H)H=PHR−1P
然后我们得到了最优估计时的代价函数的最小值
JminJ_{\min}Jmin,或者说最小均方误差
Jmin=σd2−σd^02=σd2−PHR−1PJ_{\min} = {\sigma_{d}}^{2} - {\sigma_{{\widehat{d}}_{0}}}^{2} = {\sigma_{d}}^{2} - P^{H}R^{- 1}PJmin=σd2−σd02=σd2−PHR−1P
总结,利用正交原理,我们最终得到了最优解条件下的最小均方误差。