算法与数据结构实战技巧:从复杂度分析到数学优化
算法与数据结构实战技巧:从复杂度分析到数学优化
引言:为什么算法能力决定你的代码“天花板”
作为程序员,你是否曾遇到这样的困惑:同样是处理数据,别人的代码能轻松扛住10万并发请求,而你的系统在1万数据量时就开始卡顿甚至崩溃?这背后的差距,往往不在于编程语言的选择或框架的新旧,而在于对算法与数据结构的理解深度。
在实际开发中,很多人习惯用“能跑就行”的标准衡量代码质量,却忽略了隐藏在运行效率背后的核心逻辑。当数据规模小时,暴力循环或许能应付;但随着用户量增长、业务复杂度提升,算法的优劣直接决定了系统的性能天花板。一个用哈希表(O(1)查询)优化的缓存系统,和一个用数组遍历(O(n)查询)实现的版本,在百万级数据面前会呈现天壤之别的响应速度。
核心问题:为什么看似功能相同的代码,在面对大规模数据时会出现性能鸿沟?答案就藏在算法的时间复杂度、空间复杂度设计,以及数据结构的合理选型中。本文将从基础概念拆解到实战优化思路,用“接地气”的方式帮你掌握提升代码性能的关键技巧,让你的程序从“能用”进化到“能扛”。
无论是求职面试中的算法题,还是工作中面对的性能瓶颈,算法能力都是程序员不可绕开的核心竞争力。接下来,我们将一步步揭开复杂度分析的面纱,探索数据结构的优化奥秘,让你真正理解:好的算法,是写出“抗打”代码的前提。
算法的定义与本质:不止于“步骤”的解题逻辑
算法的通俗定义:从“菜谱”到“解题步骤”
提到“算法”,你可能会联想到复杂的代码或高深的数学公式,但其实它就藏在我们的日常生活里——比如你每天做饭时遵循的菜谱,就是一套完美的“算法原型”。
用“菜谱逻辑”拆解算法本质
想象你要做一道番茄炒蛋:首先需要准备番茄、鸡蛋、调料(输入),然后按步骤完成切菜、热锅、翻炒、调味(处理),最终得到一盘色香味俱全的菜品(输出)。这个“食材→步骤→成品”的流程,正是算法的核心框架。
但算法比普通菜谱多了两个关键约束:
- 有限步骤:必须在确定次数内完成。就像菜谱会明确“翻炒3分钟”,而不是“炒到天荒地老”。
- 确定性:每一步指令必须清晰无歧义。如果菜谱写“加盐少许”,可能会让新手困惑;但算法会精确到“加盐5克”,确保无论谁执行都能得到相同结果。
算法的黄金法则:
✅ 必须有明确的输入和输出
✅ 步骤有限且可执行
✅ 每步指令清晰无歧义
反例:为什么“随机试密码”不是算法?
假设你忘记了手机密码,打算随机尝试组合——这种方式永远不能称为算法。因为密码可能有10000种组合(4位数字),极端情况下需要尝试到最后一次才能成功,步骤数量是“潜在无限”的。而算法的本质是“用有限步骤解决问题”,就像菜谱绝不会让你“无限尝试火候直到菜熟”。
通过这个类比你会发现:算法其实是“解决问题的标准化流程”,它像菜谱一样让复杂任务变得可操作,又比菜谱更严谨可靠。下一次当你听到“算法”时,不妨想想厨房里的那些步骤——它们背后藏着相同的逻辑智慧。
算法的核心特征:判断“好算法”的四把标尺
作为程序员,我们每天都在与算法打交道,但你是否思考过:一个“合格”的算法究竟要具备哪些核心特质?学术定义中的算法特征往往抽象难懂,今天我们就从实战角度,用四把“程序员标尺”拆解算法的必备素质,并结合经典的“两数之和”问题,看看这些特征如何在代码中落地。
一、四把标尺:从学术定义到代码实践
算法的本质是“解决问题的步骤”,但不是所有步骤都能称为算法。从程序员视角看,一个可靠的算法必须满足以下四个核心特征:
算法四特征·程序员版
- 明确输入输出:像函数定义一样,有清晰的“原材料”(参数)和“成品”(返回值)
- 步骤有限性:不会陷入无限循环,执行次数有明确边界
- 每步确定性:逻辑分支(如if-else)清晰无歧义,计算机能“看懂”
- 可行性:能用代码实现,不依赖“理论上存在但工程不可行”的步骤
二、代码实例:“两数之和”如何体现四特征?
以LeetCode经典题目“两数之和”为例(给定整数数组nums和目标值target,返回和为target的两个元素下标),我们用暴力解法代码逐一标注这些特征:
python
def twoSum(nums, target):# 遍历数组中每个元素(i为第一个数下标)for i in range(len(nums)):# 遍历i之后的元素(j为第二个数下标,避免重复计算)for j in range(i + 1, len(nums)):# 判断两数之和是否等于目标值if nums[i] + nums[j] == target:return [i, j] # 找到则返回下标对return [] # 无结果时返回空列表
1. 明确输入输出:函数的“契约精神”
代码中def twoSum(nums, target):定义了输入为数组nums(待查找的数字集合)和整数target(目标和),返回值为整数数组[i, j](满足条件的下标对)。这种“参数→返回值”的明确对应,就像工厂的“原料入口”和“产品出口”,是算法可复用的基础。
2. 步骤有限性:拒绝“无限循环”陷阱
外层循环for i in range(len(nums))和内层循环for j in range(i + 1, len(nums))严格限制了执行次数:假设数组长度为n,外层循环最多执行n次,内层循环最多执行n-1次,总步骤数不超过n*(n-1)/2。即使面对空数组或无结果的情况,也会在遍历完所有可能后返回[],绝不会陷入“死循环”。
3. 每步确定性:计算机的“导航图”
代码中所有逻辑分支都清晰无歧义:
- 循环变量
i和j的取值范围由range()严格定义,没有“可能取这个值也可能取那个值”的模糊性; - 条件判断
if nums[i] + nums[j] == target是明确的布尔表达式,结果非真即假,计算机能精准执行“返回下标”或“继续循环”的操作。 这种“步步有依据”的特性,确保算法不会“迷路”。
4. 可行性:从想法到代码的“落地能力”
整个逻辑用Python实现,无需依赖任何理论上的“理想条件”(如无限内存、超高速计算)。即使是初学者,也能通过编译器将这段代码转化为可执行程序,在普通电脑上处理长度为1000的数组——这正是“可行性”的核心:算法必须能被工程化实现,而不是停留在纸面上的空想。
三、总结:四把标尺的实战意义
判断一个算法是否“合格”,本质是判断它能否稳定、高效、无歧义地解决问题。明确输入输出确保算法“知道要做什么”,步骤有限性保证“不会做不完”,每步确定性确保“不会做错”,可行性则让“想法变成现实”。这四把标尺不仅是理论要求,更是我们日常写代码时排查bug的“ checklist ”——比如当代码陷入死循环,很可能是“步骤有限性”出了问题;当函数返回值混乱,往往是“输入输出定义”不清晰。
下次写算法时,不妨用这四把标尺“量一量”,你会发现:好算法的本质,就是把复杂问题拆解成计算机能理解的“确定性步骤”。
数据结构:算法的“舞台”,效率的“隐形推手”
数据结构的本质:数据的“收纳方式”
想象你走进一家仓库,货架上的物品摆放方式直接决定了你找到目标商品的速度——这就是数据结构的本质:数据的“收纳艺术”。就像按编号整齐排列的抽屉能让你瞬间定位物品,而杂乱堆放的箱子需要逐个翻找,不同的数据结构通过对数据的组织方式,深刻影响着算法操作的效率1。
两种经典“收纳方案”的对决
数组(顺序存储) 如同超市货架上按编号排列的商品,所有数据在内存中连续存放,每个元素都有固定的“位置编号”(索引)。这种结构的最大优势是 随机访问 ——无论数据量多大,只要知道索引,就能像打开指定编号的抽屉一样直接获取数据,时间复杂度为 O(1)。比如要找第 5 个元素,直接通过 arr[4](假设从 0 开始计数)即可完成,无需遍历其他元素。
链表(链式存储) 则像挂在钩子上的一串钥匙,每个数据节点通过指针(或引用)连接下一个节点,内存中可以分散存放。这种“弹性连接”使其在 插入/删除操作 上极具优势:只需改变相邻节点的指针指向,就像在钥匙串中间加一把钥匙只需解开前后连接,无需移动其他钥匙,时间复杂度为 O(1)。但代价是查找时必须从头节点开始逐个遍历,直到找到目标,时间复杂度为 O(n)。
代码片段直击操作差异
我们通过 Python 伪代码直观对比“查找目标元素”的步骤差异:
数组查找(已知索引):
python
def array_search(arr, index):# 直接通过索引访问,一步到位return arr[index]# 使用示例:查找第3个元素(索引2)
result = array_search([10, 20, 30, 40], 2) # 结果:30
链表查找(需从头遍历):
python
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = nextdef linked_list_search(head, target):current = head# 必须从头节点开始,逐个检查下一个节点while current:if current.val == target:return currentcurrent = current.nextreturn None # 未找到# 使用示例:查找值为30的节点
# 链表结构:10 -> 20 -> 30 -> 40
head = ListNode(10, ListNode(20, ListNode(30, ListNode(40))))
result = linked_list_search(head, 30) # 需遍历3个节点才找到
核心启示:没有“万能收纳法”,只有“场景适配”——当需要频繁随机访问数据时(如数据库索引),数组是最优解;当需要频繁增删节点时(如实时消息队列),链表更具优势。选择数据结构的本质,就是在“空间占用”与“操作效率”之间找到平衡。
从仓库管理到代码世界,数据结构的“收纳逻辑”始终不变:用对结构,效率倍增;选错结构,事倍功半。理解这种底层逻辑,是写出高性能代码的第一步。
算法与数据结构:“演员”与“舞台”的共生关系
如果把程序开发比作一场电影拍摄,那么算法就像演员的表演——它决定了“如何做”的逻辑流程;而数据结构则是舞台布景,决定了“在哪里做”的基础环境。就像优秀的舞台设计能让演员的表演更具张力,合适的数据结构也能让算法效率得到质的飞跃。
以用户信息查询为例,当我们用哈希表存储用户数据时,通过键值对直接定位的特性,查询效率能比传统数组提升10倍。这种“好舞台成就好表演”的案例,在实际开发中比比皆是。但反过来,如果选错了“舞台”,即便算法逻辑再精妙,也可能陷入“英雄无用武之地”的困境。
比如实现一个需要频繁插入的队列:若用数组作为底层数据结构,每次插入元素都需要移动后续所有元素,时间复杂度为O(n);而改用链表实现时,只需调整指针指向,插入操作可在O(1)时间内完成。这个对比生动说明:数据结构不是算法的附属品,而是决定其发挥空间的关键框架。
核心启示:算法与数据结构的关系,本质是“逻辑”与“载体”的共生。就像电影需要根据剧情选择实景拍摄还是绿幕特效,开发者也必须根据业务场景(如查询频率、插入需求)选择匹配的数据结构,才能让算法真正释放价值。
无论是提升10倍效率的哈希表,还是O(n)与O(1)的性能鸿沟,都在印证同一个道理:在程序世界里,没有绝对“好”的算法,只有与数据结构“适配”的解决方案。理解这种共生关系,正是从“会写代码”到“写好代码”的关键一步。
复杂度分析:衡量算法效率的“通用语言”
时间复杂度:算法“跑多快”的量化指标
为什么同样处理1000条数据,有的程序瞬间完成,有的却要卡顿几秒?这背后的核心差异,就藏在时间复杂度这个算法的“速度密码”里。它不关心你用的是最新款电脑还是老旧手机,只专注于一个问题:当数据量(专业上称为“问题规模n”)增长时,算法的执行次数会如何变化。
时间复杂度的本质:用“执行次数随问题规模n的增长趋势”来衡量算法效率,忽略硬件性能、编程语言等外部因素,只关注核心的数学规律。比如处理100条数据时执行100次,处理1000条时执行1000次,这种“n增长多少倍,执行次数就增长多少倍”的规律,就是时间复杂度要捕捉的核心。
用大O符号给算法“测速”
描述时间复杂度时,我们通常用大O符号(O(f(n))),其中f(n)是问题规模n的函数。这个符号像一把“效率标尺”,告诉我们当n足够大时,算法执行次数的增长上限。比如:
- O(1):常数时间,执行次数不随n变化,像数学里的“常数函数”
- O(n):线性时间,执行次数和n成正比,像“一次函数”
- O(log n):对数时间,执行次数随n增长但增速缓慢,像“对数函数”
- O(n log n):线性对数时间,n和log n的乘积
- O(n²):平方时间,执行次数是n的平方,像“二次函数”
这些符号看似抽象,其实在生活中随处可见。我们用“快递分拣”的场景来拆解它们:
快递分拣员的“复杂度课堂”
假设你是仓库分拣员,面前有n个快递包裹,该如何高效找到目标包裹?不同策略对应不同时间复杂度:
- O(1):直接定位货架 如果每个快递都有唯一编号,且货架按编号分区(比如A区放1-100号,B区放101-200号),你可以直接走到对应货架拿起包裹。无论n是100还是10000,你都只需要1步——这就是常数时间,执行次数和n无关。
- O(n):逐个翻找所有包裹 如果包裹杂乱堆放,没有编号规律,你只能从第一个开始逐个检查,直到找到目标。运气差时要翻完所有n个包裹——这就是线性时间,执行次数随n线性增长。
- O(log n):二分查找编号 如果包裹按编号从小到大排列,你可以用“猜数字”的思路:先看中间包裹的编号,如果比目标小,就只查后半部分;如果比目标大,就只查前半部分。每次查找都能排除一半包裹,n=1000时最多只需10步(因为2¹⁰=1024)——这就是对数时间,执行次数随n增长但增速极慢。
代码里的“速度对决”:冒泡排序 vs 快速排序
理论讲完,我们看实战。同样是给n个数排序,冒泡排序和快速排序的效率差异,正是时间复杂度的直观体现:
冒泡排序(O(n²))
核心思路是“相邻元素比大小,小的往前冒”,需要两层嵌套循环:
python
def bubble_sort(arr):n = len(arr)for i in range(n): # 外层循环n次for j in range(0, n-i-1): # 内层循环约n次if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j]
当n=1000时,执行次数约为1000×1000=10⁶次;n=10000时,直接飙升到10⁸次,时间随n的平方爆炸增长。
快速排序(O(n log n))
核心思路是“分而治之”,通过基准值将数组分成两部分,递归排序:
python
def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr)//2] # 选中间元素为基准left = [x for x in arr if x < pivot] # 小于基准的部分middle = [x for x in arr if x == pivot] # 等于基准的部分right = [x for x in arr if x > pivot] # 大于基准的部分return quick_sort(left) + middle + quick_sort(right) # 递归处理子数组
排序n个元素时,需要log n层递归(类似二分查找),每层处理n个元素,总执行次数约为n log n。n=10000时,执行次数约为10000×14≈1.4×10⁵次,仅为冒泡排序的1/700!
常见时间复杂度速查表
为了更清晰对比,我们整理了算法世界中最常见的复杂度类型、特征及适用场景:
| 复杂度类型 | 增长特征(n增大时) | 典型场景 |
|---|---|---|
| O(1) | 执行次数恒定,不随n变化 | 数组直接访问、哈希表查找 |
| O(log n) | 增长缓慢,n翻倍时执行次数仅+1 | 二分查找、平衡二叉树操作 |
| O(n) | 执行次数与n成正比 | 线性查找、单层循环遍历 |
| O(n log n) | 增长适中,n log n级 | 快速排序、归并排序、堆排序 |
| O(n²) | 增长迅速,n翻倍执行次数×4 | 冒泡排序、选择排序、嵌套循环 |
关键结论:选择算法时,优先关注复杂度的“数量级”。O(n log n)算法在n=10⁶时,效率可能是O(n²)算法的10万倍!这就是为什么大厂面试总把复杂度分析作为“敲门砖”——它直接决定了系统能否扛住海量数据的冲击。
通过时间复杂度,我们能穿透代码表象,看到算法的“数学本质”。下一次优化程序时,不妨先问自己:这段代码的执行次数,会随着数据量增长如何变化?这或许就是从“写对代码”到“写好代码”的关键一步。
空间复杂度:算法“占多大地方”的衡量标准
当我们评价一个算法时,除了关注它“跑多快”,还得关心它“占多大地方”——这就是空间复杂度的核心意义。想象你整理衣柜:同样是收纳10件衣服,有人需要额外搬一个储物箱(占用额外空间),有人却能原地重新排列(不占额外空间),算法的空间占用差异与此类似。
空间复杂度的准确定义:算法在运行过程中额外占用的存储空间,不包含输入数据本身所需要的空间。这就像我们计算搬家成本时,只统计行李箱之外额外打包的纸箱体积,而不包括你原本要搬的家具。
常见的空间复杂度类型
实际开发中,我们最常遇到两种空间复杂度:
- O(1):原地操作,空间恒定 这类算法就像“原地整理衣柜”,无论输入数据规模多大,额外占用的空间始终不变。例如冒泡排序,它通过交换数组内部元素完成排序,整个过程只需要几个临时变量,空间复杂度就是O(1)。
- O(n):线性增长,按需分配 这类算法需要额外开辟与输入规模成正比的空间。比如归并排序,为了合并两个有序子数组,需要创建一个临时数组来存储中间结果,输入数据量翻倍时,临时数组的大小也会翻倍,空间复杂度即为O(n)。
递归 vs 迭代:斐波那契数列的空间差异
最能体现空间复杂度差异的经典案例,莫过于斐波那契数列的两种实现方式。我们以计算第n个斐波那契数为例,看看递归和迭代在空间占用上的天壤之别。
递归实现(空间复杂度O(n))
递归方法通过不断调用自身求解子问题,每一次递归调用都会在内存的“调用栈”中保存当前的函数状态(包括参数、返回地址等)。当计算第n个斐波那契数时,调用栈的深度会达到n层,因此额外空间复杂度为O(n)。
python
def fib_recursive(n):if n <= 1:return n# 每次递归调用都会新增栈帧,栈深度为nreturn fib_recursive(n-1) + fib_recursive(n-2)
迭代实现(空间复杂度O(1))
迭代方法则完全不同,它通过循环更新有限的变量来计算结果,整个过程只需要存储前两个数的值,无论n多大,额外空间始终是固定的3个变量(a, b, c),空间复杂度优化为O(1)。
python
def fib_iterative(n):if n <= 1:return na, b = 0, 1for _ in range(2, n+1):c = a + ba, b = b, c # 仅更新变量,无额外空间增长return b
关键差异总结:递归实现因调用栈深度产生线性空间占用,而迭代实现通过“滚动更新”将空间压缩到常数级别。这个对比揭示了算法设计的重要原则:有时通过改变实现方式,能在不影响功能的前提下大幅降低空间消耗。
这种空间优化的思路,也为我们后续讨论“时间与空间的权衡”埋下伏笔——当内存资源有限时(如嵌入式设备、移动端开发),选择迭代实现能避免递归可能导致的“栈溢出”风险;而在追求代码简洁性的场景,递归虽占用更多空间,却可能让逻辑更清晰。理解空间复杂度,正是做出这类技术决策的基础。
时间复杂度优先的现实逻辑:用户体验“不等人”
想象一下电商平台的秒杀场景:当你盯着屏幕等待抢购心仪商品时,10秒的加载时间足以让你错失机会,甚至直接关闭页面——用户对“即时性”的敏感度远超想象。但很少有人会在意手机是512MB内存还是1GB内存,因为这类空间资源的差异在日常使用中几乎无感。这就是为什么在算法设计中,时间复杂度往往比空间复杂度更值得优先考量:用户体验的核心诉求是“不等待”,而速度感知直接决定产品生死。
相比之下,空间资源的问题往往有更简单的解决方案。硬盘不够可以加容量,内存不足可以插内存条,这些硬件扩容手段能快速缓解空间压力。但CPU的处理速度却像一道“硬门槛”,被算法效率死死卡住。就像O(n²)这样的低效算法,当数据量n达到10万时,即便用上最顶级的服务器,也会因为需要执行1万亿次运算而陷入卡顿——此时硬件再好,也成了“巧妇难为无米之炊”。
真实案例印证:某支付系统曾因采用O(n²)算法,在用户高峰期响应时间高达800ms,导致大量用户投诉。团队重构算法为O(n log n)后,响应时间骤降至50ms,用户投诉率直接下降90%。这个数据清晰地说明:优化时间复杂度,本质上是在拯救用户体验。
从电商秒杀到支付结算,从社交媒体刷新到导航路线规划,用户对“瞬间响应”的期待从未改变。与其在硬件升级上投入无底洞,不如先审视算法是否存在“效率瓶颈”——毕竟,没有用户愿意为糟糕的时间体验买单。
大思维视角:从伪代码到问题建模的“降维打击”
伪代码:剥离细节,直击问题本质
当程序员在白板上推演算法、团队协作讨论思路时,你是否见过这样的场景:有人纠结于用 Python 的缩进还是 Java 的大括号,有人争论变量命名该用 camelCase 还是 snake_case,却没人关注「这个逻辑到底能不能解决问题」?这正是伪代码要破解的困局——用自然语言与代码逻辑的混合体,剥离语法细节,让注意力聚焦在算法的核心步骤上。
伪代码的「极简主义」表达
伪代码就像算法的「草稿纸」,它不追求编译通过,只在乎逻辑清晰。比如要实现「查找数组中最大值」这个经典问题,伪代码可以这样写:
plaintext
function findMax(arr):max = arr[0]for i from 1 to len(arr)-1:if arr[i] > max:max = arr[i]return max
这段不到 10 行的文字,已经把解决问题的核心思路讲得明明白白。你不需要考虑数组越界的语法处理(比如 Python 的 try-except 或 Java 的 ArrayIndexOutOfBoundsException),也不用纠结循环变量的声明方式,只需专注「如何通过遍历比较找到最大值」这一本质问题。
藏在伪代码里的「三要素」
看似简单的伪代码,其实暗藏算法分析的关键信息。以 findMax 为例,我们能清晰拆解出三个核心参数:
- 算法逻辑:通过「初始化最大值为首个元素,遍历剩余元素并更新最大值」的步骤,实现查找功能;
- 问题规模:用
len(arr)直接体现输入数据的大小,这是后续复杂度分析的基础; - 输入量:明确接收数组
arr作为输入,界定了算法的适用范围。
伪代码的「验证神器」作用:当你写完这段伪代码,很容易发现潜在问题——如果数组为空(len(arr) = 0),arr[0] 会直接报错;如果数组只有一个元素,循环不会执行但结果正确。这种「快速暴露边界条件」的能力,让伪代码成为算法设计的「第一关测试」,比直接写代码调试更高效。
为什么每个程序员都该掌握伪代码?
伪代码的价值,在于它构建了一个「通用语言层」:无论你熟悉 Python、C++ 还是 JavaScript,都能通过伪代码快速理解他人思路;在面试推导算法时,用伪代码展示逻辑比纠结语法错误更能体现思维能力;甚至在系统设计初期,用伪代码勾勒核心流程,能帮团队规避「为实现而实现」的陷阱。
说到底,写伪代码的过程,就是用「问题解决者」的视角重新审视需求——当你能用简洁的逻辑描述清楚「如何做」,具体用什么语言实现,不过是水到渠成的事。
伪方法三参数:量化算法效率的“通用模型”
要理解算法效率的本质,我们需要一个能精确描述其执行时间规律的框架。伪方法三参数模型正是这样一种工具,它将算法的执行时间定义为三个核心要素的函数:T(A, n, I) = 算法A在问题规模n、输入I下的执行时间。这个简洁的公式背后,藏着理解算法性能的关键逻辑。
用“快递配送”理解三参数模型
如果把算法比作一场快递配送任务,三个参数的含义会变得非常直观:
- A(算法策略):对应快递的配送方案。比如有的公司按区域划分配送路线(类似排序算法中的“分治策略”),有的则按距离远近优先配送(类似“贪心策略”),不同策略直接影响整体效率。
- n(问题规模):对应待配送的包裹总数。10个包裹和1000个包裹对配送时间的要求完全不同,这就像算法处理10条数据和100万条数据时的性能差异。
- I(输入特性):对应包裹的地址分布。如果所有包裹都集中在同一个小区(类似“已排序数组”),配送会很高效;如果地址分散在城市各个角落(类似“随机无序数组”),则需要更多时间。
通过这个类比可以发现,算法的执行时间T并非固定值,而是由策略、规模和输入特性共同决定的动态结果。
核心价值:伪方法模型的真正意义,在于帮我们剥离具体场景的干扰,聚焦最本质的问题——当问题规模n持续增大时,执行时间T会如何增长? 这个增长规律,就是我们常说的“时间复杂度”。它像一把尺子,让我们能在不依赖具体硬件环境的情况下,预判算法在大数据量下的表现,为后续深入分析CPU指令集层面的优化奠定理论基础。
无论是评估排序算法的优劣,还是优化数据库查询效率,伪方法三参数模型都提供了一套通用的分析语言。它让我们从“算法跑多快”的表象,深入到“算法为什么快/慢”的本质,这正是复杂度分析的起点。
CPU指令集与复杂度优化:为何数学模型是“王道”
CPU指令集:时间复杂度的“物理基础”
想象一下,计算机的CPU就像一家精密运转的工厂,而指令集则是这家工厂里固定不变的“生产工序”。每个指令都有明确的执行时间——比如加法指令可能耗时1ns,跳转指令需要2ns,就像流水线上焊接工序需要3分钟,质检工序需要5分钟一样。
算法在CPU上的执行过程,本质就是调用这些“工序”的过程。它的总耗时可以用一个简单公式计算:算法执行时间 = (加法指令次数×1ns)+(跳转指令次数×2ns)+ ... 。所有指令的执行次数与各自耗时的乘积之和,构成了算法的真实运行成本。
我们用两个经典例子来具体理解:
- O(n)算法:假设它核心操作是执行n次加法,那么总耗时就是 n×1ns。当数据规模n翻倍时,耗时也会随之翻倍。
- O(n²)算法:如果核心操作是执行n²次加法,总耗时则为 n²×1ns。当n从100增加到200时,耗时会从10,000ns飙升到40,000ns,增长幅度远超数据规模的变化。
核心洞察:时间复杂度分析的本质,正是对算法执行过程中指令集调用次数集合的抽象描述。它忽略了具体指令的耗时差异(比如1ns或2ns),只关注当数据规模n增长时,指令总执行次数的增长趋势——这就是为什么O(n²)算法在大数据量下会比O(n)算法慢得多的“物理基础”。
这种将复杂问题抽象为“次数集合”的思维,让我们能在不依赖具体硬件的情况下,预判算法的效率瓶颈。就像工厂管理者不需要知道每台机器的具体功率,只需通过工序数量的增长模式,就能判断生产线能否应对订单量的激增。
硬件优化的局限与数学模型的“优越性”
当系统性能遇到瓶颈时,你会先想到升级服务器配置,还是优化代码逻辑?很多人下意识选择前者,但硬件优化的“性价比陷阱” 往往被忽略——相比之下,数学模型与算法优化可能才是更可持续的解决方案。
硬件优化的三大“致命伤”
硬件升级看似直接,却藏着难以逾越的障碍:
成本高企:更换CPU、扩容内存等硬件操作,成本通常是软件优化的10倍以上。某电商平台曾测算,通过硬件升级支持千万级并发需投入上千万元,而算法优化仅需重构核心模块,成本不到百万。
性能天花板触手可及:CPU主频从3GHz提升到4GHz仅带来33%的理论提速,且受限于物理定律,近年单核性能提升已进入“龟速时代”。与之对比,算法优化的收益堪称“指数级飞跃”——当数据量达到10万时,将O(n²)复杂度优化为O(n log n),实际运行速度可提升1000倍,这是任何硬件升级都无法实现的突破。
兼容性泥潭:不同硬件架构的指令集差异(如x86与ARM),让硬件级优化难以通用。某金融系统曾为适配新服务器的AVX-512指令集重构代码,结果旧型号服务器无法运行,反而引发线上故障。
数学建模:用“智慧”替代“蛮力”
真正的性能优化高手,往往通过数学模型重构解决问题。以搜索算法为例,传统线性查询(O(n))在数据量增长时会变得异常缓慢。而引入跳表数据结构(本质是“空间换时间”的数学思路)后,通过建立多层索引,查询时间直接降至O(log n)。
某社交平台的实践证明:在不更换任何硬件的情况下,仅通过这次数学建模优化,系统就从支持百万级数据查询,升级为轻松处理千万级数据,响应速度反而提升了80%。这正是数学模型的“优越性”——它不依赖硬件迭代,而是通过优化问题的本质解法,释放算力潜力。
与其在硬件军备竞赛中不断投入,不如回归代码与算法的本质。毕竟,优秀的数学模型,才是突破性能瓶颈的“金钥匙”。
时间复杂度的“真实面目”:平均值而非渐近线
渐近线的“理想与现实”:最坏/最好情况的局限性
在算法复杂度分析中,我们常常用渐近线来描述最坏情况和最好情况的时间复杂度,但这两种极端场景往往难以反映算法在真实世界中的实际表现。
极端情况的局限性
以经典的快速排序(快排)为例,其最坏时间复杂度为 O(n²),这种情况通常发生在输入数据几乎有序(如完全正序或逆序)时。但在随机数据分布下,这种极端场景的发生概率极低,实际工程中几乎可以忽略不计。与之相对的最好情况(如已排序数组且选择中间元素作为 pivot)时间复杂度可达 O(n log n),但这种“完美输入”在现实业务中同样不具普遍性——大多数数据都是随机分布的,而非经过特殊预处理的理想状态。
用“考试分数”理解真实性能
如果把算法性能比作学生的考试分数,渐近线分析中的最坏情况和最好情况就像是“最低分”和“最高分”。某学生某次考试最低 50 分(对应最坏情况)、最高 100 分(对应最好情况),但这两个极端分数都无法准确反映他的真实水平。真正能代表其学习实力的,其实是多次考试后的 平均分 85 分——这就像算法的“平均情况复杂度”,更贴近实际运行时的普遍表现。
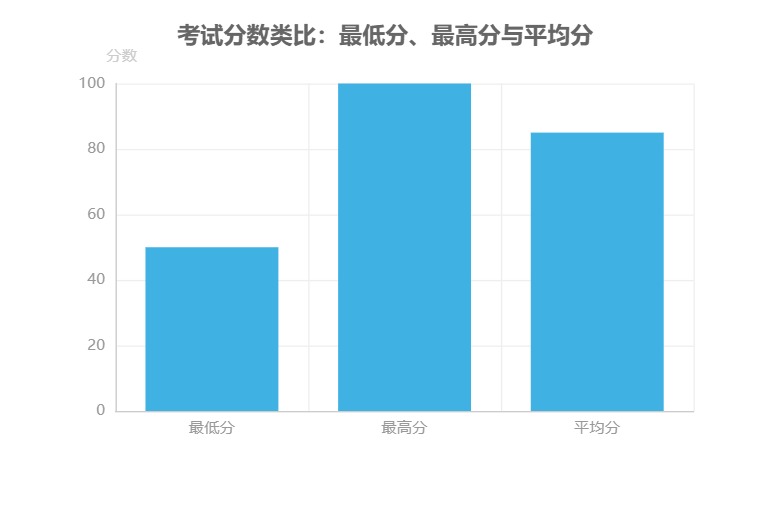
核心启示:在评估算法性能时,仅关注最坏/最好情况就像仅凭一次考试的最高分或最低分判断学生能力。平均情况复杂度(如快排的 O(n log n))才是衡量算法在随机数据下普遍表现的“真实成绩单”。
通过这个类比我们能更清晰地认识到:渐近线分析提供的是理论边界,而实际应用中需要结合数据分布特点,关注更具普遍性的平均情况复杂度,才能做出更合理的技术选型。
平均复杂度:工程中的“决策依据”
在算法设计与数据结构选型中,复杂度分析是评估性能的核心工具,但工程实践中真正指导决策的往往不是理论上的极端情况,而是更贴近真实运行状态的平均复杂度。以我们日常开发中频繁使用的哈希表为例,就能清晰看到这种权衡的智慧。
哈希表的性能表现存在三种典型情况:最好情况是当哈希函数完美分配数据,无冲突发生时,插入、查找、删除操作均可达到 O(1) 的常数级效率;最坏情况则出现在所有数据都哈希到同一位置(即哈希冲突极端严重)时,操作复杂度退化为 O(n),相当于线性遍历;而平均复杂度则是在随机输入下,通过合理设计哈希函数(如扰动函数、动态扩容机制)将冲突概率控制在极低水平后,实际表现出的 O(1) 效率。
这种平均复杂度主导工程决策的现象,在主流编程语言的标准库实现中得到了充分验证。以 Java 的 HashMap 为例,其官方文档明确标注“平均查找时间为 O(1) ”,而非最坏情况下的 O(n)。这一细节揭示了一个关键事实:在大多数实际应用场景中,平均复杂度更能反映算法的真实效率,是工程师做技术选型时的核心参考。
工程启示:平均复杂度之所以成为决策依据,本质是因为它平衡了理论严谨性与实际可用性。当通过技术手段(如哈希函数优化、负载因子控制、红黑树退化保护)将极端情况的概率降低到可接受范围时,算法的平均表现就成为衡量其实际价值的最有效指标。
为更直观地理解三种复杂度的适用边界,我们可以通过表格对比其核心差异:
| 复杂度类型 | 定义场景 | 工程适用场景 | 典型应用案例 |
|---|---|---|---|
| 最好复杂度 | 理想输入下的最优表现 | 理论极限分析、算法潜力评估 | 演示算法最优性能边界 |
| 最坏复杂度 | 极端输入下的最差表现 | 系统稳定性验证、极端场景容错设计 | 实时系统的最坏响应时间评估 |
| 平均复杂度 | 随机输入下的期望表现 | 日常开发的性能预估、数据结构选型 | HashMap 查找/插入操作、数据库索引设计 |
理解平均复杂度的工程意义,能帮助开发者跳出纯理论的桎梏,在“完美但不实用”与“可用但有缺陷”之间找到平衡点——这正是从算法理论走向工程实践的关键思维转变。
总结与实战建议:从“懂”到“用”的跨越
很多同学学完算法与数据结构后,常会陷入“懂原理却做不出题”的困境——明明记得复杂度公式,实际解题时还是下意识写出暴力解法;知道数组和链表的特性,却选不对适合的存储结构。今天我们就来拆解从“理论理解”到“实战应用”的落地方法,用四个核心技巧+一套标准化流程,帮你把知识转化为解题能力。
一、四个核心技巧:让算法从“抽象”到“具体”
算法应用的本质,是用数学思维解决实际问题。这四个技巧能帮你建立“解题直觉”:
核心技巧速览
- 动笔先画再写:写代码前用流程图或伪代码梳理逻辑,就像盖房子先画图纸。比如解决“排序问题”时,先画出冒泡和快排的步骤对比,能直观发现快排的分治逻辑更优,避免“写一半发现思路走不通”。
- 复杂度优先原则:优先选择时间复杂度更低的算法。比如查找元素时,O(log n)的二分法比O(n)的线性遍历效率高得多——想象在1000页的字典里找“算法”一词,按拼音索引(二分思路)比逐页翻(遍历)快20倍以上。
- 数据结构“对症选药”:根据操作场景匹配结构:频繁增删用链表(像排队时插队/离队灵活,无需移动整体),随机访问用数组(像按座位号找人,直接定位index);需要去重选哈希表,需要有序选红黑树。
- 数学优化是捷径:优化先从数学模型入手,把问题“翻译”成数学关系。比如“两数之和”本质是“找complement=target-nums[i]是否存在”,用哈希表存储已遍历元素,比双层循环更高效,这就是数学转化的力量。
二、实战四步走:从“拿到问题”到“写出最优解”
面对新问题时,别急着敲代码,按这四步走,能让你少走90%的弯路:
实战标准化流程
- 拆解问题:先明确核心需求和约束。比如“两数之和”的核心是“找两个数相加等于目标值”,约束是“返回索引且不能重复使用元素”。
- 伪代码描述:用自然语言写思路,比如“遍历数组,对每个元素i,检查数组中是否存在target - nums[i],且索引不等于i”。
- 复杂度诊断:分析伪代码的时间/空间成本。暴力解法双层for循环是O(n²)时间复杂度(n为数组长度),空间复杂度O(1);当n=10000时,需执行约1亿次运算,会超时。
- 优化与实现:针对瓶颈调整。“两数之和”的瓶颈是“重复遍历”,用哈希表存储已遍历元素(key=值,value=索引),每次遍历只需查哈希表(O(1)时间),时间复杂度降至O(n),最后编码实现。
三、案例演示:“两数之和”如何从O(n²)优化到O(n)
用上面的流程,我们完整走一遍“两数之和”的优化过程,直观感受“从懂到用”的跨越:
问题:给定数组nums = [2,7,11,15],target = 9,返回两个元素的索引(答案是[0,1])。
步骤1:拆解问题
核心需求:找两个数之和=target,输入是数组和target,输出是索引数组。
步骤2:伪代码描述
plaintext
for i from 0 to len(nums)-1:for j from i+1 to len(nums)-1:if nums[i] + nums[j] == target:return [i,j]
步骤3:复杂度诊断
时间复杂度O(n²)(两层循环),空间复杂度O(1)。当n=10000时,运算次数达10⁸,远超面试题时间限制(通常要求10⁶以内)。
步骤4:优化与实现
用“数学转化+哈希表”优化:
- 数学转化:将问题变为“对每个i,找complement=target-nums[i]是否存在”;
- 数据结构优化:用哈希表存储已遍历元素(key=值,value=索引),每次遍历查哈希表(O(1)时间);
- 新伪代码:
plaintext
创建哈希表map
for i from 0 to len(nums)-1: complement = target - nums[i] if complement in map: return [map[complement], i] map[nums[i]] = i # 存储当前元素和索引
此时时间复杂度O(n)(一次遍历),空间复杂度O(n)(存储哈希表),效率提升显著。
写在最后
算法学习的终极目标不是“记住知识点”,而是“建立解题思维”。从画伪代码到分析复杂度,再到用数学模型优化,这套方法能帮你把“书本知识”转化为“实战能力”。下次做题时,试试按这四步走,你会发现:写出最优解,其实没那么难。
记住:好的程序员用时间换空间,优秀的程序员用思维换效率。从“懂”到“用”的跨越,差的就是这一套标准化的实战流程。