基于树莓派与Jetson Nano集群的实验边缘设备上视觉语言模型(VLMs)的性能评估与实践探索
概述
2018年,TensorFlow Lite团队的Pete Warden曾提出:“机器学习的未来在于微型化”。如今,随着人工智能向高性能视觉强大的视觉语言模型(Vision-language models, VLMs)发展,对高性能计算资源的需求急剧增长。图形处理器(GPU)的需求达到历史峰值,引发了对长期可持续性的担忧。时至2025年,七年后的今天,一个关键问题浮现——我们是否已迈入这一微型化未来?本文通过定制的树莓派集群与Jetson Nano开发板,在边缘设备上对视觉语言模型展开测试。
在本系列博客中,我们将在多种开发板上进行广泛实验,旨在探寻适用于边缘部署的快速、高效视觉语言模型,同时竭力避免设备过热损坏。
树莓派与Jetson Nano集群配置

树莓派的宽度实则与圆周率值(3.14)无关,前文提及此点仅为戏谑。以下为构建集群所使用的开发板:
- 树莓派2 Model B(2GB内存,无冷却装置)
- 树莓派4 Model B(4GB内存,无冷却装置)
- 树莓派4 Model B(8GB内存,无冷却装置)
- 树莓派5(8GB内存,无冷却装置)
- Jetson Nano开发板(2GB内存,带散热片,无风扇)
- Jetson Nano(4GB内存,带散热片,无风扇)
- Jetson Orin Nano(8GB内存,256GB SSD,带散热片与风扇)
除Jetson Orin Nano外,所有开发板均配备64GB SD卡。集群构建的辅助组件包括以太网交换机与电源模块。所有设备均采用原厂配置,未作任何硬件修改,旨在首先考察其开箱即用状态下的性能表现,因此未额外添加散热片或冷却风扇。需说明的是,本实验并非严格意义上的设备性能对比测试。
这些开发板能否承受负载而不出现过热故障?后续内容将揭晓答案。
边缘设备集群运行VLM的优势
集群环境为部署前测试各类模型提供了理想平台,且可根据需求灵活定制。构建集群不仅具有实践价值,亦充满探索乐趣。定制化树莓派与Jetson Nano集群的主要优势包括:
- 单一交换机实现以太网集中连接
- 便于监控与管理
- 配置简洁
- 架构可扩展
- 适合实验场景
我们将进一步通过3D打印外壳、支架、支撑件及端口配件等实现集群的定制化改造,相关完整构建方案与健康监测工具将在后续文章中详述。

边缘设备运行VLM的实验设置
众多模型宣称可在低至2GB内存的边缘设备上高效运行,我们将逐步对这些模型进行测试。本文选取Moondream2与Qwen2.5VL作为测试对象。
实验通过PC端SSH远程访问所有开发板,以便进行设备间的并行对比。本地模型的下载与管理采用Ollama工具,其默认拉取4位量化模型,加载过程中不进行额外量化处理。
主控设备(本实验中为PC)维护一个包含测试脚本与图像的GitHub仓库,所有必要修改均在此完成,随后按需同步至各边缘设备。环境配置完成后,即可运行带输入参数的测试脚本。
1.1 Ollama工具简介
Ollama是一款轻量级跨平台框架,支持在本地设备直接下载、运行和管理视觉语言模型(及大语言模型)。该工具提供命令行界面(CLI)、图形用户界面(GUI,截至2025年9月仅支持Windows系统),以及关键的Python SDK。Python客户端库可通过PyPi获取,其封装了Ollama的本地HTTP API,实现与Python环境的直接交互。
Ollama拥有独立的精选模型库,支持模型下载功能。这些模型采用GGUF+Modelfile格式:GGUF(GPT生成统一格式)为模型文件格式,Modelfile类似于包含模型运行需求的requirements.txt文件。用户也可根据这些规范在Ollama中部署自定义模型。
1.2 设备上的Ollama安装
Ollama可在官方网站获取,支持Windows、Linux与Mac系统。需注意,Python客户端需通过PyPi单独安装,命令为pip install ollama。本实验中所有开发板均采用相同方式安装Ollama。
视觉语言模型评估方法
视觉语言模型的评估较单模态(纯视觉或纯语言)模型更为复杂,因其需同时在跨模态感知与推理能力上表现优异。评估方法具有任务特异性,本研究从更广泛视角简化测试与对比流程,涉及以下任务:

(i) 图像描述生成(Image Captioning):生成自然语言句子描述图像的整体内容。
- 输出形式:单句或段落
- 评估重点:全局理解能力与泛化能力
(ii) 视觉问答(Visual Question Answering, VQA):以自然语言回答关于图像的问题,输出可为单个数字、单词、句子或段落。
(iii) 视觉定位(Visual Grounding):模型在图像中识别并定位物体的能力,输出形式包括位置描述句、边界框坐标或物体掩码。
(iv) 图像文本检索(Image Text Retrieval):模型从图像中识别并理解文本内容的能力。
注:视觉语言模型的评估任务还包括跨模态检索、组合与逻辑推理、视频时序推理等,每项任务均有对应的基准数据集。相关评估方法的详细讨论将在后续文章中展开。
边缘设备运行VLM的代码实现
使用以下命令下载模型,本实验将依次获取qwen2.5vl:3b与moondream,总下载量约5.5GB,下载时间取决于网络连接速度。
ollama pull qwen2.5vl:3b
ollama pull moondream
以下代码片段实现模型加载、图像与查询定义功能。代码中集成参数解析器,支持灵活修改模型、图像路径或查询内容。模型响应通过ollama.chat()函数获取,该函数接受模型名称、查询内容与图像路径作为参数。脚本中仅对生成时间进行测量。
# 导入库
import ollama
import time
import argparse# 定义主函数
def main():# 添加参数解析器parser = argparse.ArgumentParser(description="使用图像+查询运行Ollama视觉语言模型")parser.add_argument("--model", type=str, default="qwen2.5vl:3b", help="模型名称(默认:qwen2.5vl:3b)")parser.add_argument("--image", type=str, default="./tasks/esp32-devkitC-v4-pinout.png", help="输入图像路径")parser.add_argument("--query", type=str, default="用100个字描述这张图像的内容。", help="模型的查询字符串")args = parser.parse_args()# 初始化开始时间变量以测量生成时间start_time = time.time()# 获取模型响应response = ollama.chat(model=args.model,messages=[{"role": "user","content": args.query,"images": [args.image],}])end_time = time.time()print("模型输出:\n", response["message"]["content"])print("\n生成时间: {:.2f} 秒".format(end_time - start_time))if __name__ == "__main__":main()
Qwen2.5VL(3B)模型推理实验
Qwen2.5VL(3B)由阿里巴巴达摩院Qwen团队开发,作为Qwen VL系列的成员于2025年1月发布。该模型性能优于Qwen2VL(7B),后缀"3B"表示其包含30亿参数,具有体积小而性能强的特点。
- 内存消耗:约5GB
- 模型大小:3.2GB
4.1 Qwen2.5VL(3B)的核心特性
该模型的主要功能与任务能力包括:
- 多模态感知能力
- 智能体交互性:支持操作桌面或移动界面等工具
- 扩展视频理解:采用动态帧率采样与时间编码,支持长达一小时的视频分析
- 精确视觉定位:可生成边界框、JSON格式点坐标等
- 结构化数据提取:能将发票、表单、表格等文档解析为结构化格式
关于Qwen2.5VL的架构分析及其在视频分析与内容审核中的应用,可参考相关文章。
4.2 Qwen2.5VL(3B)的视觉问答测试

实验使用两张图像:一张包含坑洼的图像与一张显示人员在车间被电缆绊倒的图像。模型需完成的VQA任务为:
- 图像中有多少个坑洼?
- 该人员为何摔倒?
点击图像可查看放大视图。实验表明,内存低于4GB的设备无法运行该模型。尽管可通过增加SWAP分区大小解决此问题,但本实验旨在考察模型在开箱即用状态下的性能。
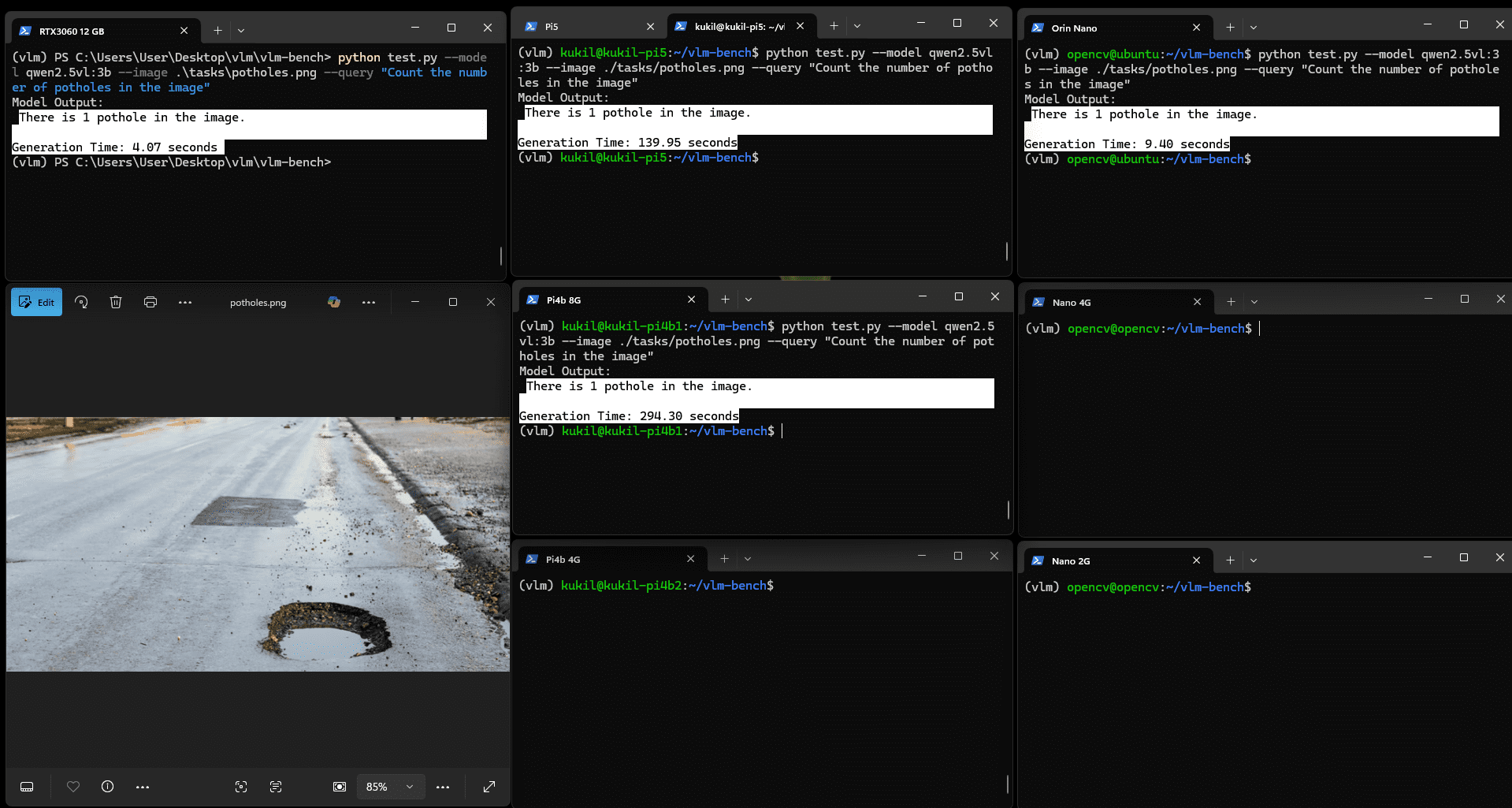
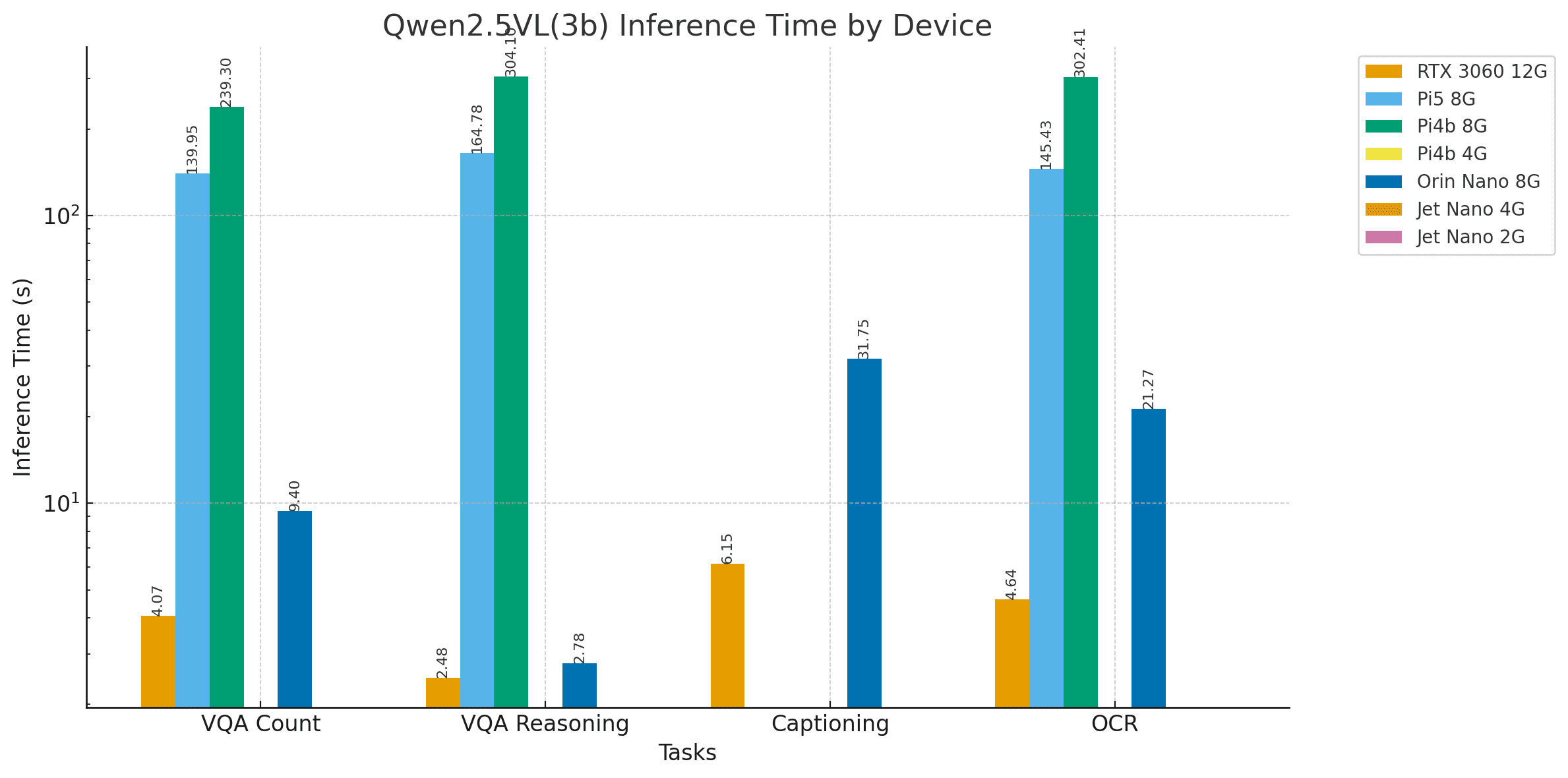
图:Qwen2.5VL(3b)坑洼计数VQA任务结果
该模型在所有适用开发板上均能精确计数坑洼数量,但推理时间差异显著。实验中加入RTX 3060 12GB GPU作为参考设备(固定于左上角),结果显示Jetson Orin Nano 8G与RTX 3060的推理时间分别为4秒与9.4秒,性能相当;而树莓派设备则分别需要约2分钟与5分钟。
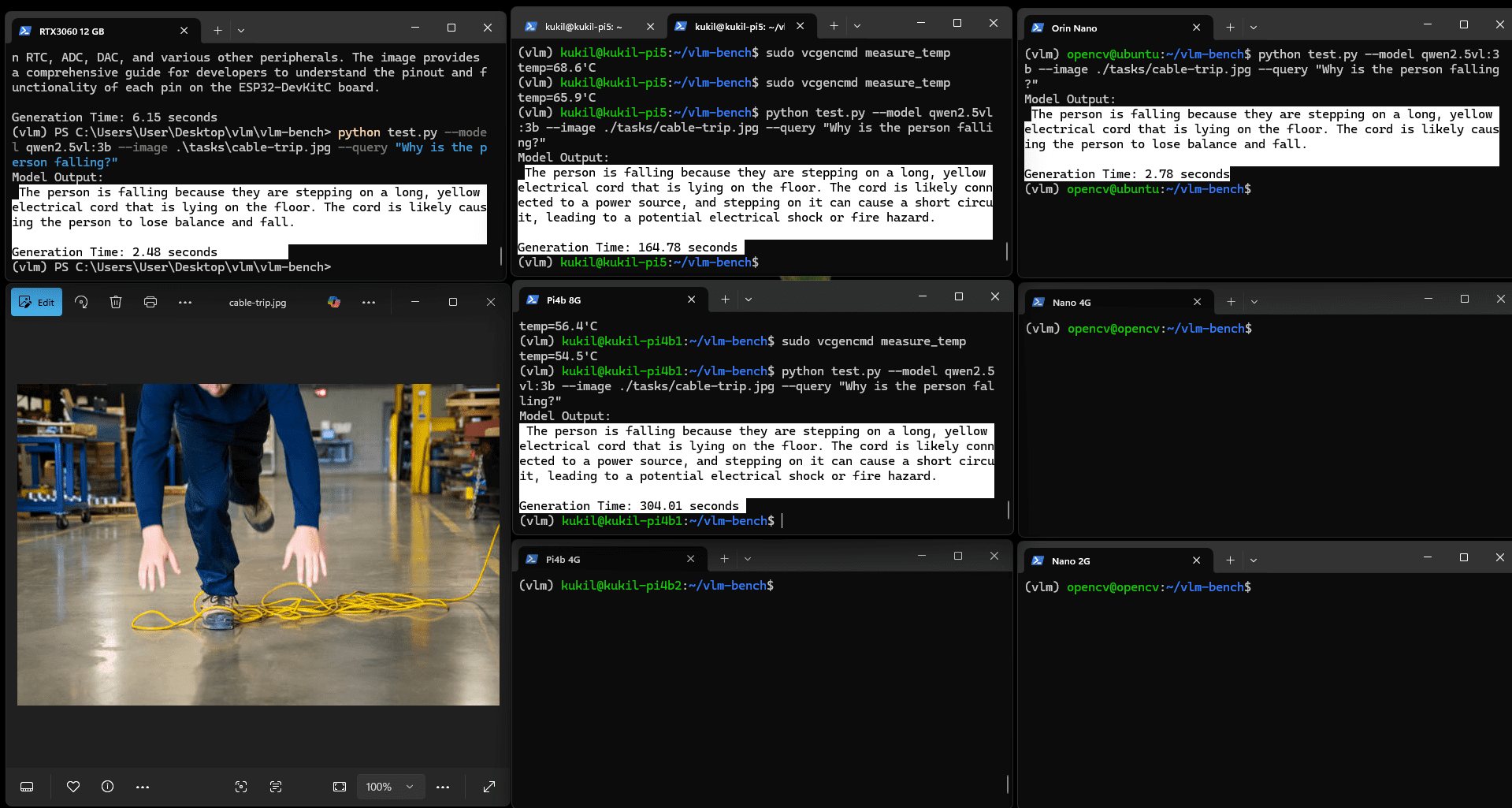
图:Qwen2.5VL(3b)推理VQA任务结果
所有内存4GB以上的开发板均能正确运行模型,时间分布模式相似。RTX 3060与Orin Nano的推理时间分别降至2.48秒与2.78秒,考虑到Jetson Orin Nano的物理尺寸,其性能表现值得肯定。
4.3 Qwen2.5VL(3B)的OCR能力测试
实验向模型输入包含Gemma 2论文标题与段落的图像,任务指令为"读取图像中的文本并解释"。所有内存4GB以上的设备均能良好运行。关于Gemma模型的详细分析可参考Gemma 3论文解读。
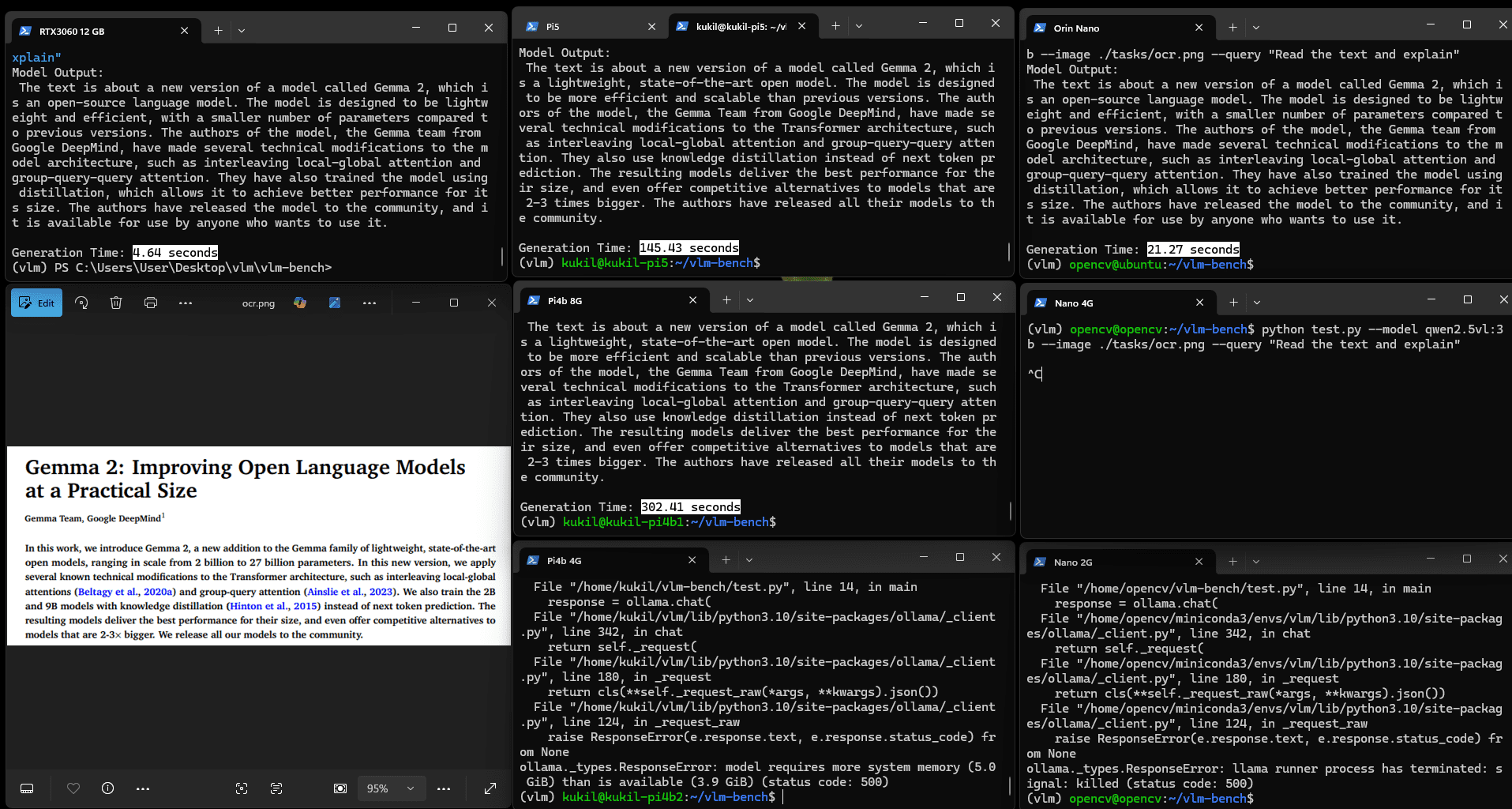
图:Qwen2.5VL(3b)的OCR与解释结果
OCR任务的耗时略长于计数或非文本推理类VQA任务:Orin Nano耗时21.27秒,Pi5耗时145.43秒,Pi4b 8G耗时302.41秒,其余设备则出现"内存不足"错误。这一结果在多数实际场景中仍可接受,因现实应用通常无需毫秒级的页面读取速度。
4.4 Qwen2.5VL(3b)的图像描述生成测试
实验使用Espressif的ESP32开发板引脚图图像,任务为"用100字生成图像的整体描述"。默认视图下细节可能不清晰,点击图像可放大查看。
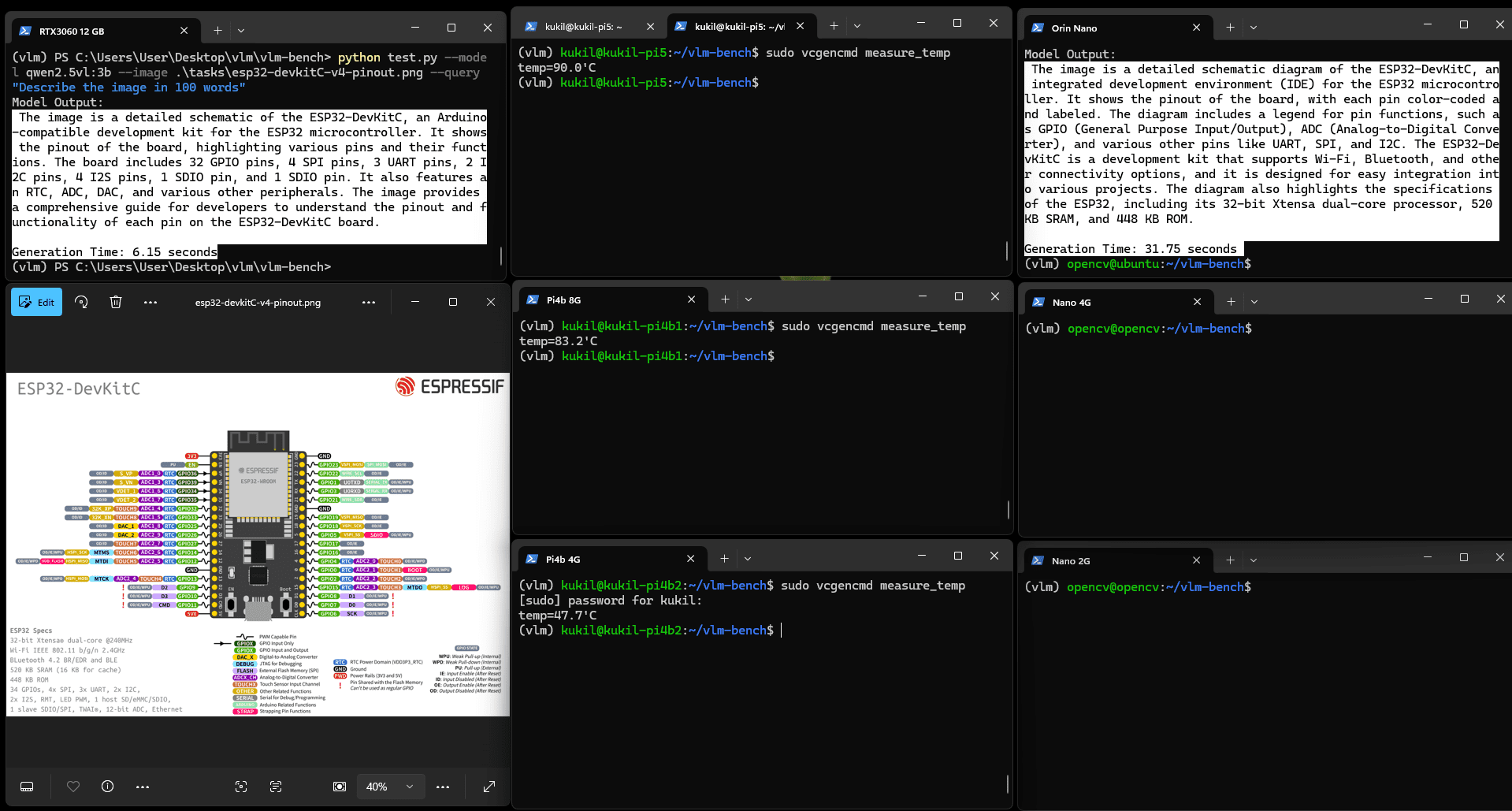
图:Qwen2.5VL(3b)图像描述生成示例
该图像包含文本、绘图、图表与符号等复杂元素,Orin Nano的生成结果质量优良,能清晰理解技术细节。
然而,树莓派设备的表现不佳。在进行描述生成测试时,树莓派出现性能下降:当温度达到90摄氏度时,设备开始降频,其中两台树莓派在10分钟后仍未生成输出。
未运行任务的Pi4b 4G温度为47摄氏度,而尝试运行描述生成任务的Pi5与Pi4b温度升至90摄氏度。显然,在边缘设备上运行VLM至少需要配备散热片进行被动冷却。
4.5 结果讨论
Jetson Orin Nano在速度与准确性方面表现优异,但需注意该开发板配备大型散热片与主动风扇(原厂配置),因此此对比并非完全公平。再次强调,本实验并非严格的设备性能比较。

Moondream2——边缘设备优化型VLM推理实验
Moondream号称世界上最小的视觉语言模型,仅含18亿参数,可在仅2GB内存的设备上运行,几乎适用于所有边缘设备。
- 内存需求:小于2GB
- 模型大小:1.7GB
- 基础模型:基于sigLIP
- 投影器:基于Phi-1.5
该模型通过提取并微调SigLIP(一种基于sigmoid的对比损失模型)与微软Phi-1.5语言模型的组件构建而成。关于DeepMind SigLIP的更多信息可参考相关文章。
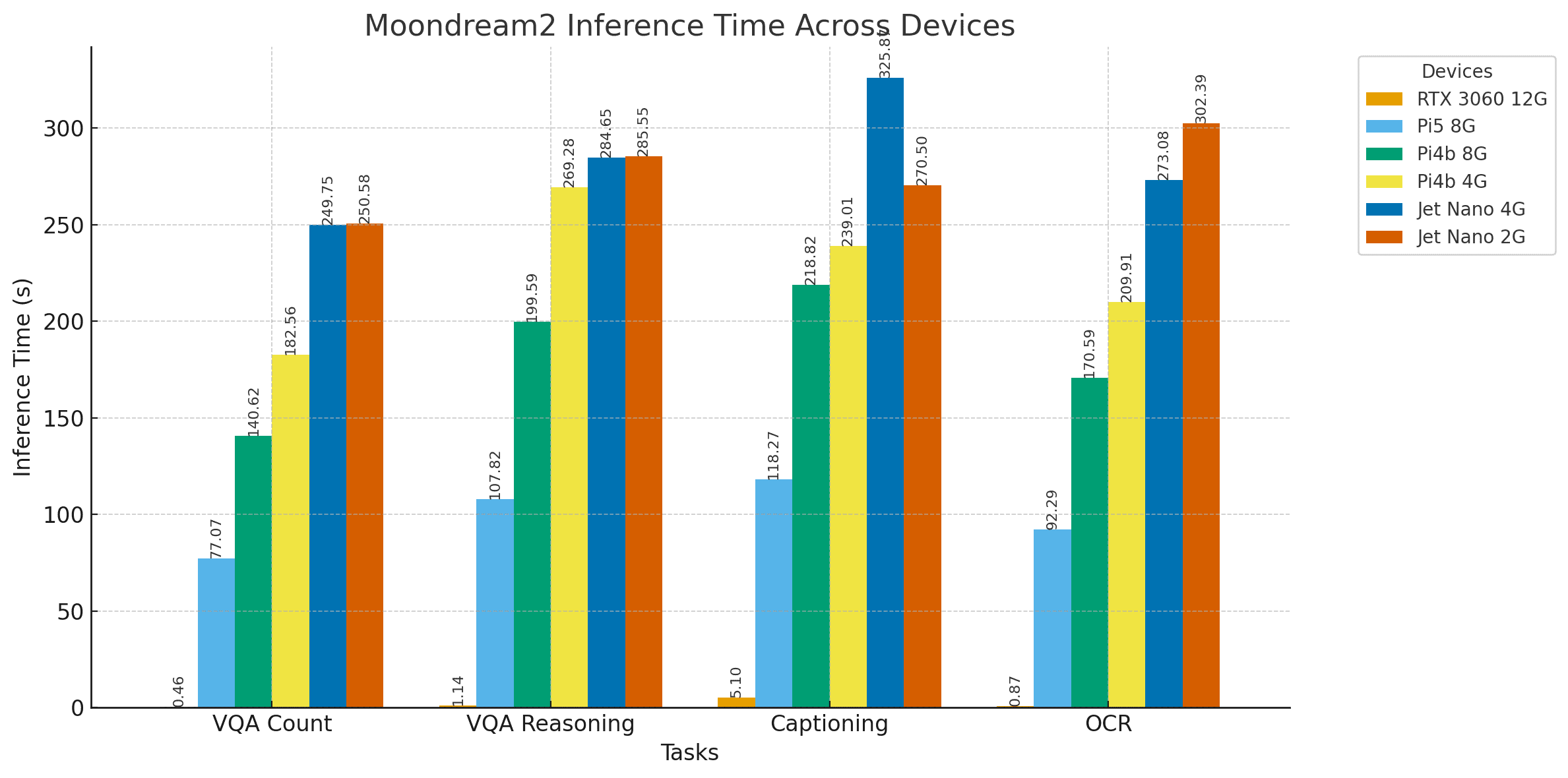
实验中,Moondream2模型接受与上述相同的测试,结果记录如下。
5.1 Moondream2的视觉问答测试
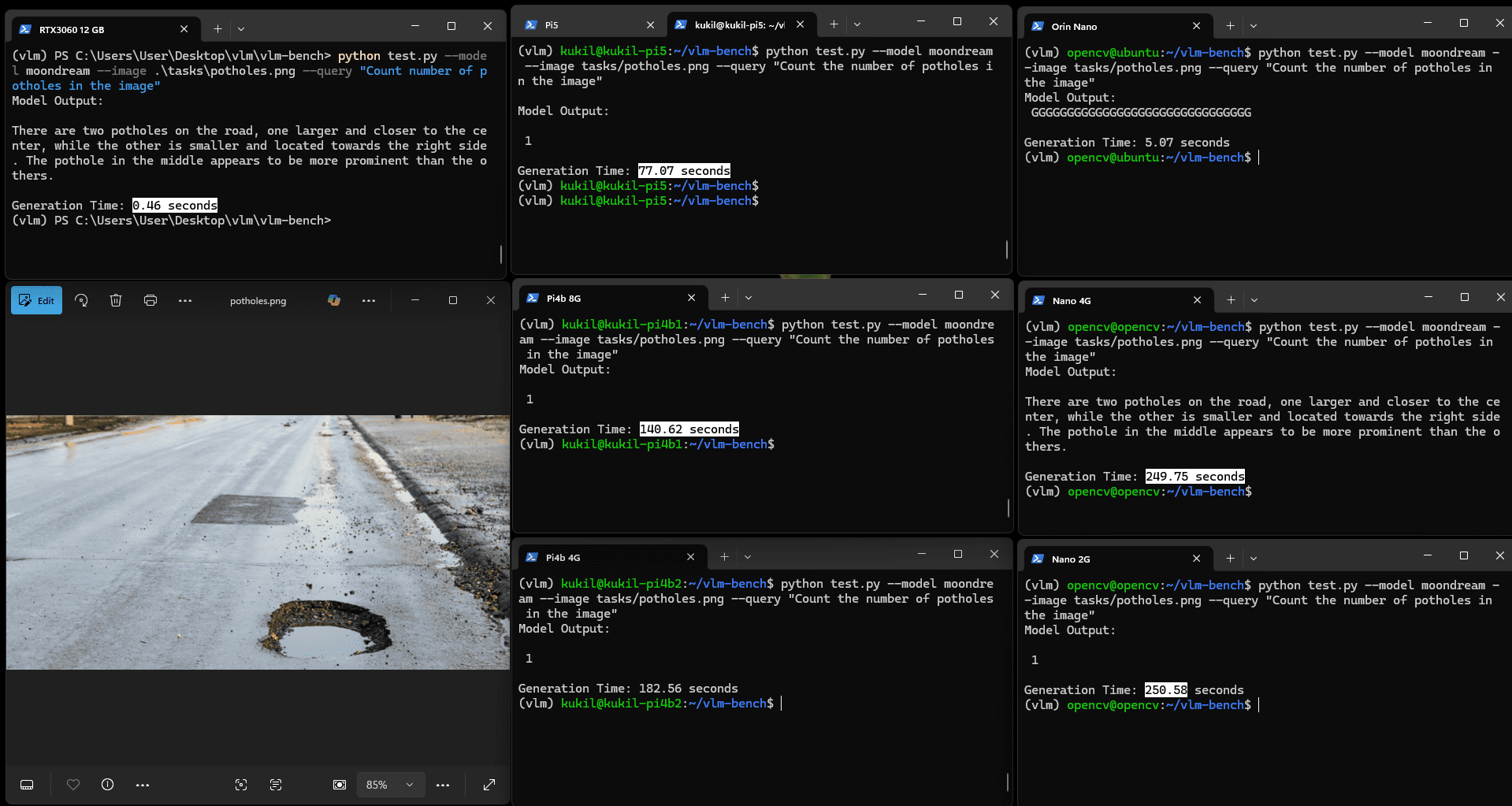
图:Moondream2坑洼计数VQA任务结果
Moondream2的推理速度显著更快,但实验发现Jetson Orin Nano出现错误输出。此问题仅在Moondream模型上观察到,在测试LlaVA 7b、Llava-llama3、Gemma2:4b、Gemma3n等其他模型时未出现,且已有用户报告类似问题。我们将深入调查并在后续更新中说明原因及解决方案。此外,RTX 3060与Jetson Nano 4GB也出现了部分计数错误。
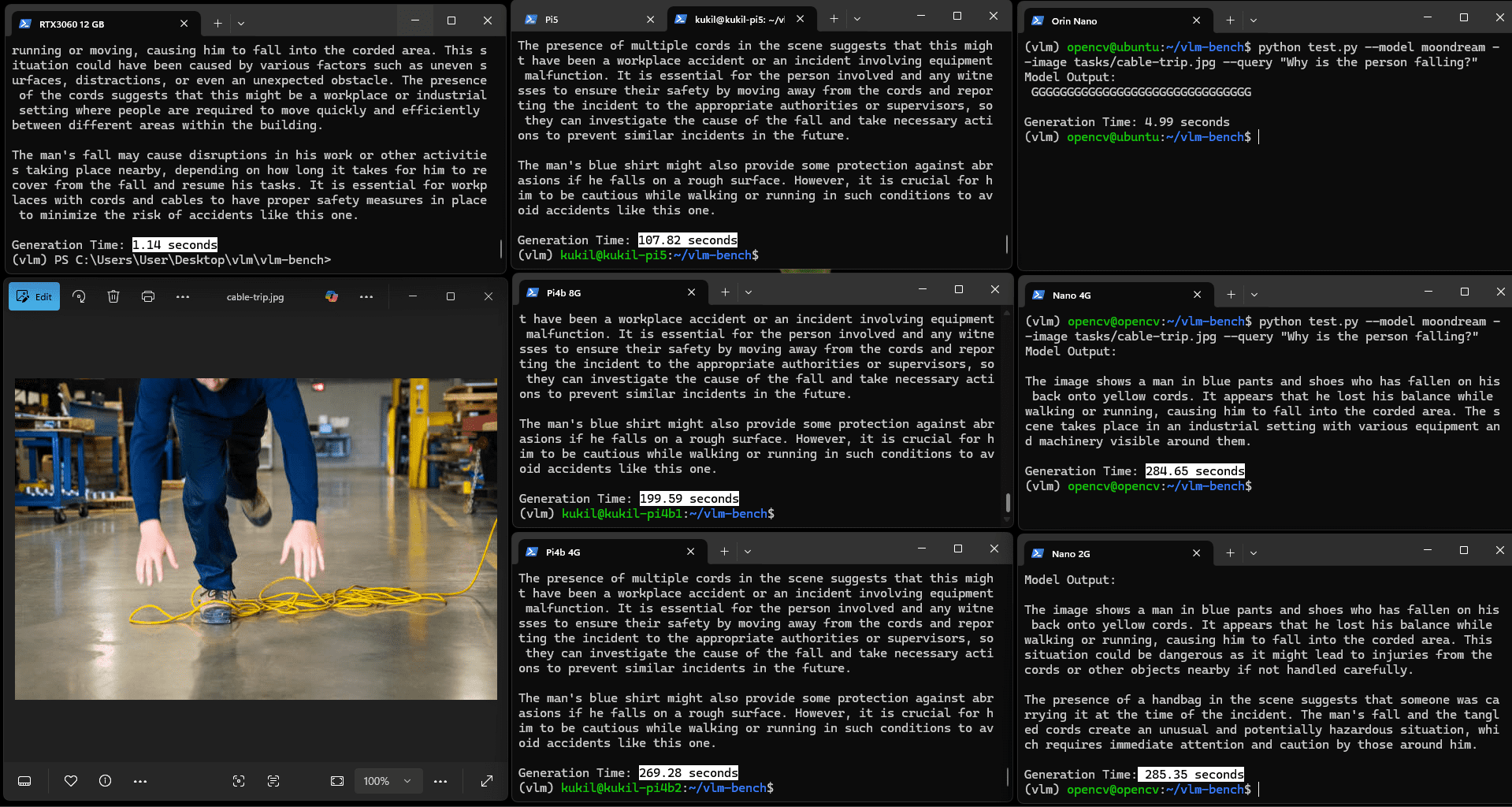
图:Moondream推理VQA任务结果
Moondream2认为图中人员可能因跑步摔倒,同时检测到了缠绕的电缆,但未能建立摔倒与电缆缠绕之间的因果关系。相比之下,Qwen2.5VL能清晰识别原因,仅耗时略长。
5.2 Moondream2的OCR能力测试

图:Moondream2的OCR与解释结果
所有设备的字符识别效果良好,除Jetson Orin Nano在特定情况下生成了"GGGG"等错误内容。
5.3 Moondream2的图像描述生成测试
尽管耗时存在差异,所有设备均按预期完成任务,能清晰描述图像中包含ESP32开发板引脚图及相关信息,但存在轻微的"幻觉"现象。
问:生成模型中的"幻觉"指什么?
正如其名,幻觉是指模型自信地生成虚假信息并将其呈现为真实内容,即模型编造信息——类似前文虚构树莓派宽度为3.4英寸的情况。
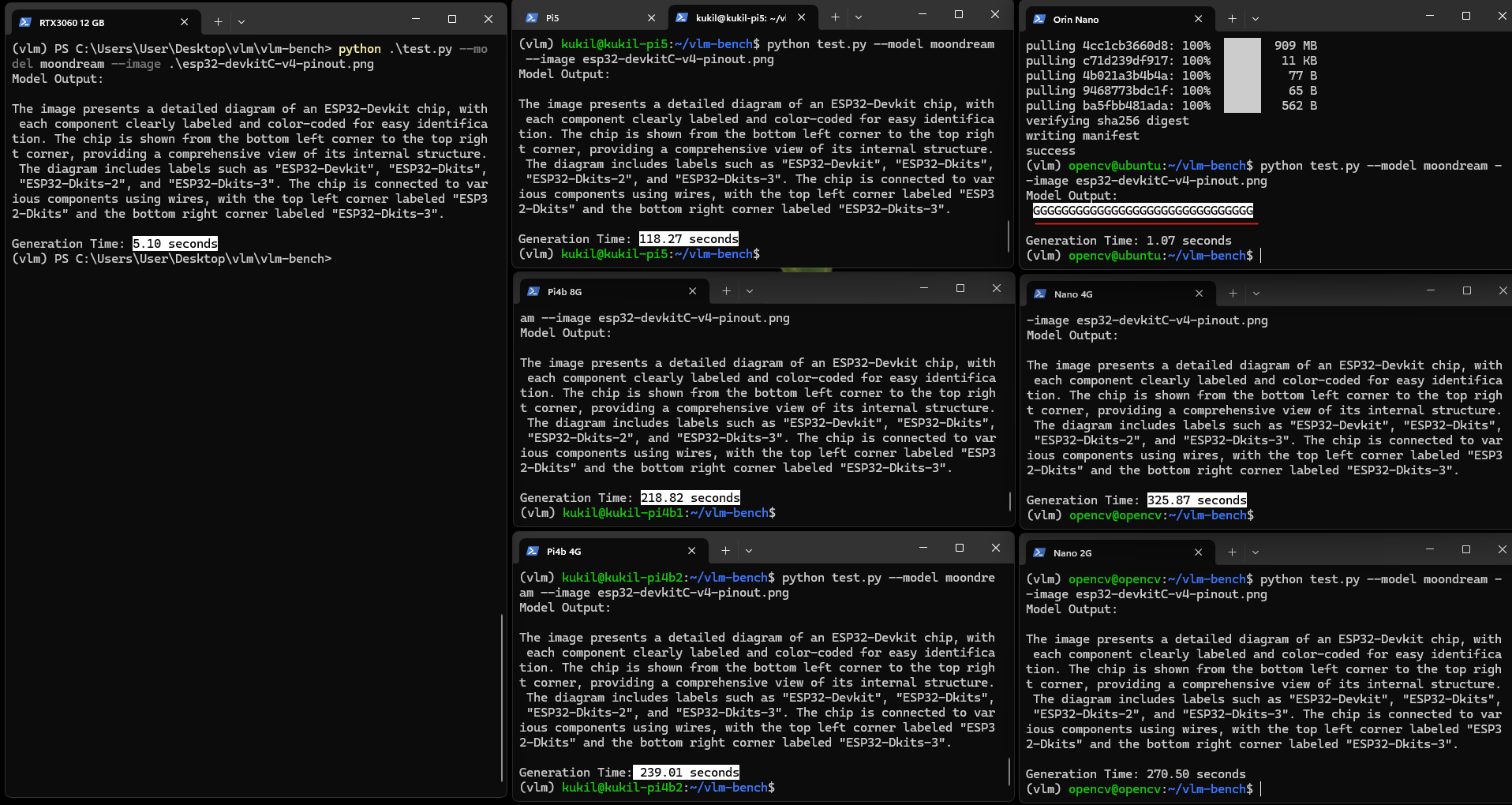
图:Moondream2图像描述生成示例
尽管设备耗时存在差异,但所有设备均按预期运行,能清晰描述图像中包含ESP32开发板引脚图及相关信息,同时观察到轻微的幻觉现象。
5.4 结果讨论

结论
本研究完成了在开箱即用状态下边缘设备运行VLM的实验。Moondream2专为紧凑的边缘友好型推理设计,在约1000个令牌的有限上下文窗口下运行,适用于受限硬件上的快速多模态任务。
Qwen2.5-VL(3B)是功能更强的多模态模型,支持长达125K令牌的超长上下文窗口,能够处理大型文档、视频、多图像序列及智能体管道。
本文仅搭建了基础测试框架,后续研究将添加散热片、冷却风扇与SSD以提升性能,并通过安装transformers库测试更多来自Hugging Face的模型。