(GeSCD)Towards Generalizable Scene Change Detection论文精读(逐段解析)
(GeSCD)Towards Generalizable Scene Change Detection论文精读(逐段解析)
(GeSCD)迈向可泛化的场景变化检测
光州科学技术院AI融合系,韩国光州
CVPR 2025
论文地址:https://arxiv.org/abs/2409.06214
官仓地址:https://github.com/1124jaewookim/towards-generalizable-scene-change-detection
【论文总结】提出GeSCD框架(可泛化场景变化检测框架)和GeSCF模型,通过巧妙地将预训练的SAM模型扩展到零样本场景变化检测任务。核心技术创新包括两个关键阶段:(1)初始伪掩码生成阶段,通过截取SAM内部的多头特征面(键特征面)计算双时相图像的特征相关性,并设计基于偏度统计的自适应阈值函数来二值化相似性图,自动识别潜在变化区域;(2)几何-语义掩码匹配阶段,利用SAM的类别无关分割掩码提供几何约束(几何交集匹配GIM),同时通过计算掩码嵌入间的余弦相似度进行语义验证(语义相似性匹配SSM),确保检测到的变化在语义上有意义。该方法完全无需训练,通过充分挖掘SAM内部特征表示的语义信息,实现了对输入顺序的完全时间一致性(TC=1.0),并在跨域泛化性能上相比现有方法平均提升19.2%(标准数据集)和30.0%(ChangeVPR数据集),有效解决了传统监督学习方法受限于特定训练数据分布而缺乏泛化能力的根本问题。
Abstract
While current state-of-the-art Scene Change Detection (SCD) approaches achieve impressive results in welltrained research data, they become unreliable under unseen environments and different temporal conditions; indomain performance drops from 77.6%77.6\%77.6% to 8.0%8.0\%8.0% in a previously unseen environment and to 4.6%4.6\%4.6% under a different temporal condition—calling for generalizable SCD and benchmark. In this work, we propose the Generalizable Scene Change Detection Framework (GeSCF), which addresses unseen domain performance and temporal consistency—to meet the growing demand for anything SCD. Our method leverages the pre-trained Segment Anything Model (SAM) in a zero-shot manner. For this, we design Initial Pseudo-mask Generation and GeometricSemantic Mask Matching—seamlessly turning user-guided prompt and single-image based segmentation into scene change detection for a pair of inputs without guidance. Furthermore, we define the Generalizable Scene Change Detection (GeSCD) benchmark along with novel metrics and an evaluation protocol to facilitate SCD research in generalizability. In the process, we introduce the ChangeVPR dataset, a collection of challenging image pairs with diverse environmental scenarios—including urban, suburban, and rural settings. Extensive experiments across various datasets demonstrate that GeSCF achieves an average performance gain of 19.2%19.2\%19.2% on existing SCD datasets and 30.0%30.0\%30.0% on the ChangeVPR dataset, nearly doubling the prior art performance. We believe our work can lay a solid foundation for robust and generalizable SCD research.
【翻译】虽然当前最先进的场景变化检测(SCD)方法在训练良好的研究数据上取得了令人印象深刻的结果,但在未见过的环境和不同的时间条件下变得不可靠;域内性能从77.6%77.6\%77.6%下降到在先前未见过的环境中的8.0%8.0\%8.0%,在不同时间条件下下降到4.6%4.6\%4.6%——呼唤可泛化的SCD和基准测试。在这项工作中,我们提出了可泛化场景变化检测框架(GeSCF),它解决了未见域性能和时间一致性问题——以满足对任意SCD日益增长的需求。我们的方法以零样本方式利用了预训练的分割一切模型(SAM)。为此,我们设计了初始伪掩码生成和几何-语义掩码匹配——无缝地将用户引导提示和基于单图像的分割转换为无需引导的成对输入场景变化检测。此外,我们定义了可泛化场景变化检测(GeSCD)基准测试以及新颖的指标和评估协议,以促进SCD在泛化性方面的研究。在此过程中,我们介绍了ChangeVPR数据集,这是一个包含多样化环境场景的具有挑战性的图像对集合——包括城市、郊区和农村环境。在各种数据集上的广泛实验表明,GeSCF在现有SCD数据集上实现了平均19.2%19.2\%19.2%的性能提升,在ChangeVPR数据集上实现了30.0%30.0\%30.0%的提升,几乎使先前技术的性能翻倍。我们相信我们的工作可以为稳健和可泛化的SCD研究奠定坚实的基础。
【解析】场景变化检测技术泛化性比较受限。现有的SCD方法虽然在自己熟悉的训练数据上表现优异,但一旦面对真实世界的复杂情况就会出现严重的性能退化。说明这些方法严重依赖于训练时见过的特定环境特征,缺乏真正的泛化能力。作者提出的GeSCF框架通过利用SAM模型来解决这一根本性问题。SAM是为单张图像的交互式分割设计的,需要用户提供点击或框选等提示信息。但场景变化检测需要处理两张图像的比较,且不应依赖人工提示。作者的创新在于设计了两个关键组件:初始伪掩码生成能够从SAM的内部特征中自动识别潜在的变化区域,而几何-语义掩码匹配则利用SAM生成的掩码的几何特性和语义信息来精确定位真正的变化。为了全面评估泛化能力,作者不仅提出了新的评估框架GeSCD,还构建了ChangeVPR数据集。这个数据集涵盖了城市、郊区、农村等多种环境,为测试算法在不同场景下的鲁棒性提供了重要基础。实验结果显示的19.2%19.2\%19.2%和30.0%30.0\%30.0%的性能提升,特别是在新数据集上近乎翻倍的表现,证明了零样本方法在解决泛化问题上的巨大潜力。
1. Introduction
Scene Change Detection (SCD) [37] is a pivotal technology that enables a wide range of applications: visual surveillance [54], anomaly detection [20], mobile robotics [31], and autonomous vehicles [21]. The ability to accurately identify meaningful changes in a scene across different time steps—despite challenges such as illumination variations, seasonal changes, and weather conditions—plays a key role in the system’s effectiveness and reliability.
【翻译】场景变化检测(SCD)[37]是一项关键技术,它支持广泛的应用:视觉监控[54]、异常检测[20]、移动机器人[31]和自动驾驶车辆[21]。在不同时间步骤中准确识别场景中有意义变化的能力——尽管面临诸如光照变化、季节变化和天气条件等挑战——在系统的有效性和可靠性中起到关键作用。
【解析】场景变化检测本质上是一个时序比较任务,需要算法能够在复杂的现实环境中准确区分真正的结构性变化和由外界因素引起的表观变化。难点在于如何在光照条件、天气状况、季节更替等外在因素持续变化的情况下,依然能够稳定地识别出场景中物体的增减、位置移动或结构改变等本质性变化。系统的鲁棒性直接决定了其在实际部署中的可靠程度,特别是在安全关键的应用场景中,如自动驾驶系统需要准确检测道路上新出现的障碍物,而监控系统需要区分正常的环境变化和潜在的安全威胁。
Recent SCD models have achieved remarkable improvement by leveraging deep features [3, 48] and advancing model architectures [11, 35, 44, 50]. However, this progress raises a fundamental question: “Can these models detect arbitrary real-world changes beyond the scope of research data?” Our findings, as shown in Fig. 1, indicate that their reported effectiveness does not hold in real-world applications. Specifically, we observe that they produce inconsistent change masks when the input order is reversed and exhibit significant performance drops when deployed to unseen domains with different visual features. It is because current SCD methods rely heavily on their training datasets, which are often limited in size [3, 42], sparse in coverage [3, 42, 44], and predominantly synthetic [25, 34, 35] due to the costly change annotation.
【翻译】最近的SCD模型通过利用深度特征[3, 48]和改进模型架构[11, 35, 44, 50]取得了显著改进。然而,这种进展提出了一个根本问题:"这些模型能否检测超出研究数据范围的任意真实世界变化?"我们的发现,如图1所示,表明它们报告的有效性在真实世界应用中并不成立。具体来说,我们观察到当输入顺序颠倒时,它们产生不一致的变化掩码,并且当部署到具有不同视觉特征的未见域时表现出显著的性能下降。这是因为当前的SCD方法严重依赖于其训练数据集,这些数据集通常规模有限[3, 42]、覆盖稀疏[3, 42, 44],并且由于变化标注成本高昂而主要是合成的[25, 34, 35]。
【解析】当前SCD模型面临的核心问题是训练数据与实际应用场景之间的巨大差距。深度学习模型的性能很大程度上取决于训练数据的质量和多样性,但变化检测任务的数据标注过程复杂且耗时。标注者需要精确地勾画出每个像素级别的变化区域,这不仅需要大量人力成本,还要求标注者具备足够的专业判断能力来区分有意义的变化和无关的环境噪声。因此,许多研究倾向于使用计算机生成的合成数据或者规模较小的真实数据集,这导致模型学习到的特征表示过于特定化,缺乏对真实世界复杂性的泛化能力。时序一致性问题进一步暴露了模型的局限性:一个真正鲁棒的变化检测系统应该对输入图像的顺序保持不变性,但实际上许多模型在处理(A,B)和(B,A)这样的图像对时会产生截然不同的结果,说明模型学习到的是数据集中的偏置模式而非真正的变化检测原理。
To address these challenges, we introduce the Generalizable Scene Change Detection Framework (GeSCF), the first zero-shot scene change detection method that operates robustly regardless of the temporal input order and environmental conditions. Our approach builds upon the Segment Anything Model (SAM) [23], a pioneering vision foundation model for image segmentation. While SAM excels at segmenting anything within a single image, directing SAM to identify and segment changes between two input images presents a significant challenge. This difficulty arises because SAM is designed for promptable interactive segmentation, relying on user-guided prompts and single-image inputs, whereas scene change detection necessitates processing image pairs to identify changes. To bridge this gap, we propose two innovations: the Initial Pseudo-mask Generation and the Geometric-Semantic Mask Matching. By analyzing the localized semantics of the SAM’s feature space, we effectively binarize pixel-level change candidates with zero additional cost. Additionally, we leverage the geometric properties of SAM’s class-agnostic masks and the semantics of mask embeddings to refine the final change masks—incorporating object-level information as well.
【翻译】为了应对这些挑战,我们引入了可泛化场景变化检测框架(GeSCF),这是第一个无论时间输入顺序和环境条件如何都能稳健运行的零样本场景变化检测方法。我们的方法建立在分割一切模型(SAM)[23]的基础上,这是一个用于图像分割的开创性视觉基础模型。虽然SAM在单张图像内分割任何内容方面表现出色,但指导SAM识别和分割两张输入图像之间的变化呈现出重大挑战。这种困难源于SAM是为可提示的交互式分割设计的,依赖于用户引导的提示和单图像输入,而场景变化检测需要处理图像对来识别变化。为了弥合这一差距,我们提出了两个创新:初始伪掩码生成和几何-语义掩码匹配。通过分析SAM特征空间的局部语义,我们有效地将像素级变化候选者进行二值化,且无需额外成本。此外,我们利用SAM类别无关掩码的几何特性和掩码嵌入的语义来精炼最终的变化掩码——同时融入了对象级信息。
【解析】SAM模型原本是针对单图像分割任务设计的,用户通过点击、框选等方式给出提示,然后模型在这张图像中分割出对应的区域。但是场景变化检测面临的是完全不同的问题:需要比较两张图像并找出其中的差异,而且理想情况下不应该需要人工提示。两者在输入格式和处理逻辑上都有本质差异。作者的解决方案分为两个核心组件。初始伪掩码生成是利用SAM内部的特征表示来自动发现可能存在变化的区域,这个过程不需要外部监督或额外的计算成本,而是直接从SAM已有的特征中提取信息。几何-语义掩码匹配则是对初步结果的精炼过程,它结合了SAM生成的掩码的几何形状信息(如大小、位置、边界)和语义信息(如掩码所代表的内容特征),确保最终检测到的变化既在空间上合理,也在语义上有意义。这种设计避免了从零开始训练一个新模型的需要,而是巧妙地重新利用了已经在大规模数据上训练好的SAM模型的内在能力。
Figure 1. Comparative results of the current state-of-the-art model and our GeSCF under various unseen environments (ChangeVPR). GeSCF outperforms with precise boundaries and edges, where the state-of-the-art model hardly captures changes.

【翻译】图1. 当前最先进模型和我们的GeSCF在各种未见环境(ChangeVPR)下的对比结果。GeSCF在精确边界和边缘方面表现优异,而最先进的模型几乎无法捕获变化。
【解析】这个对比图直观地展示了传统方法在面对新环境时的局限性。从图中可以看出,现有的最先进方法在处理训练时未曾见过的环境类型时,往往无法准确识别出真实的变化区域,检测结果要么过于稀疏错过了明显的变化,要么产生大量误报。相比之下,GeSCF方法不仅能够成功识别出变化区域,还能提供更加精确的边界定位。这种边界精度的提升对于实际应用非常重要,因为粗糙的变化检测结果往往难以支撑后续的决策过程。图中展示的结果证明了零样本方法相对于传统监督学习方法的优势:由于不依赖特定的训练数据分布,零样本方法能够更好地适应各种不同的环境条件和视觉特征。
Furthermore, we introduce the Generalizable Scene Change Detection (GeSCD) benchmark by developing novel metrics and an evaluation protocol to foster SCD research in generalizability; most conventional SCD methods have focused on individual benchmarks separately rather than the generalizability to unseen domains and temporal consistency. We believe our GeSCD can meet the growing needs for developing anything SCD in the era of diverse anything models [23, 51, 56, 58, 61, 66] with strong zero-shot capabilities. Concretely, our GeSCD performs extensive cross-domain evaluations to rigorously test the generalizability across diverse environments and assesses temporal consistency quantitatively. Our dual-focused evaluation strategy not only ensures the robustness and reliability of a method but also sets a new benchmark in the SCD field. In the process of designing GeSCD, we collect the ChangeVPR dataset, which comprises carefully annotated images sourced from three prominent Visual Place Recognition (VPR) datasets. This comprehensive dataset includes urban, suburban, and rural environments under challenging conditions, significantly expanding the traditional scope of SCD domains.
【翻译】此外,我们通过开发新颖的指标和评估协议来引入可泛化场景变化检测(GeSCD)基准测试,以促进SCD在泛化性方面的研究;大多数传统SCD方法都专注于单独的基准测试,而不是对未见域的泛化性和时间一致性。我们相信我们的GeSCD能够满足在具有强大零样本能力的多样化"一切"模型[23, 51, 56, 58, 61, 66]时代开发任意SCD的日益增长的需求。具体而言,我们的GeSCD执行广泛的跨域评估,以严格测试跨不同环境的泛化性,并定量评估时间一致性。我们的双重聚焦评估策略不仅确保了方法的鲁棒性和可靠性,还在SCD领域设立了新的基准。在设计GeSCD的过程中,我们收集了ChangeVPR数据集,该数据集包含来自三个著名视觉位置识别(VPR)数据集的精心标注图像。这个综合数据集包括在挑战性条件下的城市、郊区和农村环境,显著扩展了传统SCD域的范围。
【解析】作者不仅提出了新的算法,还构建了一套全新的评估体系来推动整个领域的发展。传统的SCD研究通常采用孤立的评估方式,即在单个数据集上训练和测试,这种方式无法真实反映算法在实际部署时的性能表现。GeSCD基准测试的核心理念是跨域泛化评估,它要求算法在一个环境中验证后,能够直接应用到完全不同的环境中而不需要重新训练。时间一致性评估则确保算法对于同一组输入在不同时间顺序下产生稳定的结果。这种双重评估策略反映了实际应用的核心需求:系统不仅要准确,还要稳定可靠。ChangeVPR数据集的构建进一步丰富了评估的场景多样性。通过整合来自视觉位置识别领域的数据集,作者获得了更加多样化的环境类型和更具挑战性的视觉条件,这些数据集原本是为解决机器人导航和地点识别问题而设计的,其图像通常包含复杂的光照变化、天气条件和季节变化,为变化检测算法提供了更严格的测试环境。
To summarize, our contributions are as follows:
- Problem Formulation. We introduce GeSCD, a novel task formulation in scene change detection. To the best of our knowledge, this is the first comprehensive effort to address the generalization problem and temporal consistency in SCD research.
- Model Design. To tackle the GeSCD task, we propose GeSCF, the first zero-shot scene change detection model. GeSCF exhibits complete temporal consistency and demonstrates strong generalizability over previous SCD models that are tightly coupled to their training datasets—ours resulting in a substantial performance gain in unseen domains.
- Benchmark Set up. We present new evaluation metrics, the ChangeVPR dataset, and an evaluation protocol that effectively measures an SCD model’s generalizability. These contributions provide a solid foundation to guide and inspire future research in the field.
【翻译】总结而言,我们的贡献如下:
- 问题表述。我们引入了GeSCD,这是场景变化检测中的一种新颖任务表述。据我们所知,这是首次在SCD研究中全面解决泛化问题和时间一致性的努力。
- 模型设计。为了解决GeSCD任务,我们提出了GeSCF,第一个零样本场景变化检测模型。GeSCF表现出完全的时间一致性,并且相对于那些与训练数据集紧密耦合的先前SCD模型展现出强大的泛化能力——我们的方法在未见域上取得了显著的性能提升。
- 基准测试建立。我们提出了新的评估指标、ChangeVPR数据集和一个有效衡量SCD模型泛化能力的评估协议。这些贡献为指导和启发该领域的未来研究提供了坚实的基础。
2. Related Works
Segment Anything Model. Segment Anything Model (SAM) [23] has set a new standard in image segmentation and made significant strides in various computer vision domains: medical imaging [63], camouflaged object detection [46], salient object detection [27], image restoration [61], image editing [56], and video object tracking [58]. By leveraging geometric prompts—such as points or bounding boxes—SAM showcases exceptional zero-shot transfer capabilities across diverse segmentation tasks and unseen image distributions. While SAM demonstrates impressive abilities, its potential for zero-shot scene change detection remains largely unexplored. In this work, we extend SAM’s utility beyond single-image segmentation by introducing a novel, training-free approach that guides SAM to detect changes between a pair of natural images.
【翻译】分割一切模型(SAM)[23]在图像分割方面建立了新标准,并在各种计算机视觉领域取得了重大进展:医学成像[63]、伪装物体检测[46]、显著性物体检测[27]、图像修复[61]、图像编辑[56]和视频物体跟踪[58]。通过利用几何提示——如点或边界框——SAM在不同分割任务和未见图像分布上展现了卓越的零样本迁移能力。虽然SAM表现出令人印象深刻的能力,但其在零样本场景变化检测方面的潜力在很大程度上仍未被探索。在这项工作中,我们通过引入一种新颖的、无需训练的方法来扩展SAM在单图像分割之外的实用性,该方法引导SAM检测一对自然图像之间的变化。
【解析】SAM建立了一个通用的图像分割框架,这个框架不局限于特定的物体类别或应用场景。传统的分割模型通常针对特定任务进行训练,比如专门分割人体、车辆或建筑物,而SAM通过在海量数据上的训练,学会了如何分割图像中的任意物体。其零样本迁移能力体现在它能够在没有针对性训练的情况下,处理从未见过的图像类型和分割任务。几何提示机制是SAM的关键交互方式,用户可以通过简单的点击或框选来指示需要分割的区域,模型会自动推断用户的意图并给出精确的分割结果。然而,SAM原本的设计理念是处理单张图像的分割任务,而场景变化检测需要比较两张不同时间的图像,这在技术实现上存在根本性的差异。作者的创新在于找到了一种方法,能够在不修改SAM原有架构、不进行额外训练的前提下,将其能力扩展到双图像比较的场景变化检测任务上。
Change Detection. In the field of Change Detection (CD), the research falls broadly into three areas based on data characteristics: remote sensing CD, video sequence CD, and natural scene CD—the focus of our work. Remote sensing CD [5–7, 10, 19, 32, 41] involves detecting surface changes over time using data captured by satellite or aerial platforms, providing a high-altitude perspective of phenomena such as urbanization, deforestation, and disaster damage. Additionally, video sequence CD focuses on segmenting frames into foreground and background regions, usually corresponding to moving objects [2, 28]. In contrast to these CDs, natural scene CD aims to detect localized changes from a ground-level perspective such as movement of vehicles [3], pedestrians [44], the appearance and disappearance of objects [3, 42, 44], and significant background changes like the construction or demolition of buildings [42, 44]. Moreover, the task inherently involves misaligned and noisy images due to the nature of data acquisition, as images are often captured by cameras mounted on moving vehicles or robots [26]. Overall, our work concentrates natural scene CD [3, 11, 25, 35, 43, 44, 48, 50]; for the remainder of this paper, we will refer to natural Scene CD as SCD.
【翻译】变化检测。在变化检测(CD)领域,基于数据特征,研究大致分为三个方面:遥感CD、视频序列CD和自然场景CD——我们工作的重点。遥感CD [5–7, 10, 19, 32, 41]涉及使用卫星或航空平台捕获的数据检测随时间的地表变化,提供城市化、森林砍伐和灾害损害等现象的高空视角。此外,视频序列CD专注于将帧分割成前景和背景区域,通常对应于移动物体[2, 28]。与这些CD相比,自然场景CD旨在从地面视角检测局部变化,如车辆的移动[3]、行人[44]、物体的出现和消失[3, 42, 44],以及建筑物建造或拆除等重大背景变化[42, 44]。此外,由于数据获取的性质,该任务本质上涉及不对齐和噪声图像,因为图像通常由安装在移动车辆或机器人上的相机捕获[26]。总的来说,我们的工作专注于自然场景CD [3, 11, 25, 35, 43, 44, 48, 50];在本文的其余部分,我们将自然场景CD称为SCD。
【解析】遥感变化检测通常处理的是大尺度、长时间跨度的地表变化,比如监测森林覆盖率的年际变化或追踪城市扩张的进程。这类检测的优势在于可以获得大范围的鸟瞰视图,但由于拍摄距离较远,往往无法捕捉到精细的地面细节。视频序列变化检测更像是传统的前景背景分离任务,主要关注运动物体的检测,技术相对成熟,但主要应用于监控等特定场景。自然场景变化检测面临的挑战是最复杂的,因为它需要在地面视角下处理各种类型的变化,从小物体的移动到大型建筑的变化都需要准确识别。更为复杂的是,这类数据的采集环境往往不受控制,摄像设备可能安装在移动平台上,导致图像之间存在几何不对齐、光照变化、噪声等问题,需要算法具备强大的鲁棒性来应对各种干扰因素。
Scene Change Detection (SCD). In exsiting SCD benchmarks, most methods are supervised [3, 11, 35, 43, 44, 48, 50] or semi-supervised [25], heavily optimized and evaluated on specific training datasets—leading to low generalizability. Although several works have proposed selfsupervised pre-training strategies [39] or leveraged temporal symmetry [50], they still exhibit significant performance gaps when deployed to unseen data. Moreover, the symmetric structure relies on a specific prior knowledge of the domain, rendering it impractical for unknown domains without the proper inductive bias. In contrast, our GeSCF stands as a unified, training-free framework displaying robust performance on unseen data while preserving symmetric architecture for all settings.
【翻译】场景变化检测(SCD)。在现有的SCD基准测试中,大多数方法是监督学习[3, 11, 35, 43, 44, 48, 50]或半监督学习[25],它们在特定训练数据集上进行了大量优化和评估——导致泛化能力低。虽然一些工作提出了自监督预训练策略[39]或利用了时间对称性[50],但当部署到未见数据时,它们仍然表现出显著的性能差距。此外,对称结构依赖于特定领域的先验知识,使其在没有适当归纳偏置的未知领域中不实用。相比之下,我们的GeSCF作为一个统一的、无需训练的框架,在未见数据上显示出鲁棒的性能,同时为所有设置保持对称架构。
【解析】现有SCD方法的核心问题在于过度依赖训练数据的特定分布模式。监督学习方法需要大量标注好的图像对来训练模型,这些标注不仅成本高昂,而且往往反映的是特定环境或特定类型的变化。当模型遇到训练时没有见过的环境类型、光照条件或物体类别时,性能会急剧下降。半监督方法虽然减少了对标注数据的需求,但仍然需要一定量的标注样本来指导学习过程。自监督预训练试图通过让模型从数据本身学习有用的表示来缓解这个问题,但实际效果仍然有限。时间对称性的利用是基于这样的假设:变化检测应该对输入图像的顺序保持不变,即处理(A,B)和(B,A)应该得到相同的结果。然而,这种对称性约束往往需要针对特定领域进行设计,在新的应用场景中可能不再适用。GeSCF的优势在于它完全绕过了训练过程,直接利用预训练模型的内在能力,因此不会受到特定训练数据分布的限制,能够在各种未见环境中保持稳定的性能表现。
Segment Anything with Change Detection. Previous works have primarily leveraged SAM in the remote sensing CD with the Parameter-Efficient Fine-Tuning (PEFT) strategy [57]. For instance, several works leveraged SAM variants [62, 64] with learnable adaptors [57], fine-tuning adaptor networks and change decoders tailored to specific datasets [13, 29]. In contrast to these approaches, our method is the first solid SAM-integrated framework in SCD, leveraging SAM’s internal byproducts to effectively binarize change candidates without any guidance and learnable parameters. Moreover, we further exploit valuable prior information [1, 12, 18, 56, 61] from SAM’s classagnostic masks—enabling robust zero-shot SCD across a broad range of domains for the first time.
【翻译】分割一切模型与变化检测。先前的工作主要在遥感CD中利用参数高效微调(PEFT)策略[57]来应用SAM。例如,一些工作利用SAM变体[62, 64]配合可学习适配器[57],针对特定数据集微调适配器网络和变化解码器[13, 29]。与这些方法相比,我们的方法是SCD中第一个稳固的SAM集成框架,利用SAM的内部副产品在没有任何指导和可学习参数的情况下有效地二值化变化候选者。此外,我们进一步利用来自SAM类别无关掩码的有价值先验信息[1, 12, 18, 56, 61]——首次实现了跨广泛领域的鲁棒零样本SCD。
【解析】现有的SAM应用于变化检测的方法主要采用参数高效微调策略,即在保持SAM主体参数不变的前提下,添加少量的可学习适配器模块来适应特定的变化检测任务。虽然这种方法相比完全重新训练模型更加高效,但它仍然需要在特定数据集上进行训练,因此无法摆脱对训练数据的依赖。更重要的是,这些方法主要集中在遥感领域,遥感图像的特点和自然场景图像存在显著差异。作者提出的方法完全不同,它不添加任何新的可学习参数,而是直接挖掘和利用SAM在处理图像时产生的中间结果和内部特征。这些内部副产品包括注意力图、特征相关性等,它们本身就蕴含了丰富的语义信息。类别无关掩码是SAM的另一个重要特性,它能够分割图像中的任意物体而不局限于特定类别,这种先验信息为变化检测提供了有价值的几何和结构约束。通过巧妙地组合这些内在能力,作者实现了真正的零样本变化检测,无需任何训练过程就能在不同领域间迁移。
3. GeSCF
3.1. 动机与概述
Despite the abundance of web-scale data [8, 33, 36] and the advent of various zero-shot generalizable models [22, 23, 60], current SCD still suffers from the curse of datasets due to the costly nature of change annotation [65]. Therefore, our research motivation arises from how SCD can benefit from recent web-scale trained models like SAM. By addressing this question, we aim to overcome the longstanding obstacle of creating a generalizable SCD model— culminating in our proposed GeSCF model.
【翻译】尽管存在丰富的网络规模数据[8, 33, 36]和各种零样本可泛化模型的出现[22, 23, 60],当前的SCD仍然由于变化标注的昂贵性质而遭受数据集诅咒[65]。因此,我们的研究动机源于SCD如何从像SAM这样的最新网络规模训练模型中受益。通过解决这个问题,我们旨在克服创建可泛化SCD模型的长期障碍——最终提出我们的GeSCF模型。
Fig. 2 gives an overview of the GeSCF pipeline. GeSCF handles the technical gap between SAM designed for promptable interactive segmentation with single-image inputs and SCD for identifying changes with image pairs through two key stages: Initial Pseudo-mask Generation and Geometric-Semantic Mask Matching. First, we intercept and correlate feature facets—one of query, key, and value—from the image encoder to obtain rich, multi-head similarity maps; then, we transform these similarity maps into a binary pseudo-mask by adaptively thresholding the low-similarity pixels using a skewness-based algorithm. Finally, we elaborate the pseudo-mask by leveraging the geometric properties of SAM’s class-agnostic masks; then, we further validate these masks by comparing the semantic similarities of the corresponding mask embeddings between bi-temporal images, ensuring that the detected changes are meaningful and contextually accurate.
【翻译】图2给出了GeSCF流水线的概述。GeSCF通过两个关键阶段来处理SAM(设计用于单图像输入的可提示交互式分割)和SCD(用于识别图像对变化)之间的技术差距:初始伪掩码生成和几何-语义掩码匹配。首先,我们从图像编码器中截取并关联特征面——查询、键和值中的一种——以获得丰富的多头相似性图;然后,我们使用基于偏度的算法对低相似性像素进行自适应阈值处理,将这些相似性图转换为二值伪掩码。最后,我们通过利用SAM类别无关掩码的几何属性来细化伪掩码;然后,我们通过比较双时相图像之间相应掩码嵌入的语义相似性来进一步验证这些掩码,确保检测到的变化是有意义且上下文准确的。
【解析】GeSCF框架的设计巧妙地解决了SAM和场景变化检测任务之间的根本性差异。作者通过两阶段的处理策略来弥补这一差距。在初始伪掩码生成阶段,作者充分挖掘了SAM内部的特征表示能力。Vision Transformer架构中的查询、键、值特征面包含了丰富的语义信息,通过计算两幅图像对应特征面之间的相关性,可以有效地识别出语义上发生变化的区域。多头注意力机制的使用进一步增强了这种相关性计算的鲁棒性,因为不同的注意力头会关注图像的不同语义层面。基于偏度的自适应阈值算法是一个重要的技术创新,它能够根据相似性分布的统计特性动态调整阈值,避免了固定阈值方法的局限性。在几何-语义掩码匹配阶段,作者进一步利用了SAM的类别无关分割能力。这些分割掩码提供了物体级别的几何约束,有助于将像素级的变化检测提升到更有意义的物体级变化检测。通过比较对应区域的语义嵌入相似性,系统能够进一步验证检测到的变化是否在语义上合理,从而减少误检并提高检测结果的可靠性。
3.2. 预备知识
Since our GeSCF exploits a set of image features intercepted from the SAM image encoder, we first recap how such features are obtained.
【翻译】由于我们的GeSCF利用了从SAM图像编码器中截取的一组图像特征,我们首先回顾这些特征是如何获得的。
【解析】作者在这里强调了一个关键的技术路线:他们并没有重新设计一个全新的特征提取器,而是直接从已经训练好的SAM模型中"拦截"特征。这种做法的优势在于可以充分利用SAM在大规模数据上学习到的丰富视觉表示,而无需额外的训练过程。所谓"截取"是指在SAM的前向传播过程中,在特定的网络层位置提取中间特征,这些中间特征包含了不同层次的语义信息。
Feature Facets. The SAM image encoder employs a Vision Transformer (ViT) architecture [15], consisting of multi-head self-attention layers and multi-layer perceptrons within each ViT block [15, 49]. In the multi-head selfattention layer of the lll -th ViT block, the query, key, and value facets are denoted by QKVl∈R3×N×H×W×C\mathbf{Q}\mathbf{K}\mathbf{V}_{l}\in\mathbb{R}^{3\times N\times H\times W\times C}QKVl∈R3×N×H×W×C , where N,H,WN,H,WN,H,W , and CCC represent the number of heads, height, width, and channel dimensions of facets, respectively.
【翻译】特征面。SAM图像编码器采用 Vision Transformer(ViT)架构[15],由每个ViT块内的多头自注意力层和多层感知器组成[15, 49]。在第lll个ViT块的多头自注意力层中,查询、键和值特征面记为QKVl∈R3×N×H×W×C\mathbf{Q}\mathbf{K}\mathbf{V}_{l}\in\mathbb{R}^{3\times N\times H\times W\times C}QKVl∈R3×N×H×W×C,其中N,H,WN,H,WN,H,W和CCC分别表示特征面的头数、高度、宽度和通道维度。
【解析】 Vision Transformer的核心机制是自注意力,而自注意力计算需要三个关键组件:查询(Query)、键(Key)和值(Value)。这三个组件通过线性变换从输入特征中产生,分别承担不同的角色:查询用于询问"我想要什么信息",键用于回答"我能提供什么信息",值则包含"实际的信息内容"。多头机制允许模型并行地关注不同类型的特征模式,每个头可能专注于不同的语义层面,比如有的头关注边缘信息,有的头关注纹理信息。张量维度3×N×H×W×C3\times N\times H\times W\times C3×N×H×W×C中的3表示查询、键、值三种特征面,N是多头的数量,H和W是特征图的空间分辨率,C是每个头的通道维度。这种结构化的特征表示为后续的相似性计算提供了丰富的语义信息。
Image Embedding and Mask Embedding. Similarly, we extract the image embedding El∈RH×W×C\mathbf{E}_{l}\in\mathbb{R}^{H\times W\times C}El∈RH×W×C from the final multi-layer perceptron layer of the lll -th ViT block. Furthermore, given the image embedding El\mathbf{E}_{l}El and an arbitrary binary mask mˉ\bar mmˉ, we compute the mask embedding Ml\mathcal{M}_{l}Ml by averaging image embedding El\mathbf{E}_{l}El over all spatial positions where the binary mask mˉ\bar mmˉ is non-zero, obtaining a single vector representation of the masked image.
【翻译】图像嵌入和掩码嵌入。类似地,我们从第lll个ViT块的最终多层感知器层中提取图像嵌入El∈RH×W×C\mathbf{E}_{l}\in\mathbb{R}^{H\times W\times C}El∈RH×W×C。此外,给定图像嵌入El\mathbf{E}_{l}El和任意二值掩码mˉ\bar mmˉ,我们通过在二值掩码mˉ\bar mmˉ非零的所有空间位置上对图像嵌入El\mathbf{E}_{l}El进行平均来计算掩码嵌入Ml\mathcal{M}_{l}Ml,从而获得被掩码图像的单一向量表示。
【解析】图像嵌入是ViT块处理后的特征表示,它包含了经过自注意力机制和前馈网络处理的语义信息。多层感知器(MLP)层通常位于ViT块的末尾,负责对注意力输出进行非线性变换和特征整合。掩码嵌入的计算过程实际上是一种空间聚合操作,它将二维的特征图压缩成一维的向量表示。具体而言,给定一个二值掩码(其中1表示感兴趣的区域,0表示背景),掩码嵌入只考虑掩码值为1的像素位置对应的特征向量,然后对这些特征向量进行平均池化。这种操作的结果是得到一个紧凑的向量表示,它编码了掩码区域内的整体语义信息。这种表示方式特别适合于后续的相似性比较,因为可以直接计算两个掩码嵌入之间的余弦相似度来判断它们的语义一致性。
3.3. 初始伪掩码生成
As demonstrated in [23], SAM preserves semantic similarities among mask embeddings within the same natural scene. Furthermore, as observed in prior studies [4, 9], attention maps can capture semantically meaningful objects in images. Building on these foundational insights, we expand SAM’s feature space utilization by extending its application to bi-temporal images and leveraging multi-head feature facets from various layers rather than relying solely on single-image embeddings [23].
【翻译】如[23]所示,SAM在同一自然场景中的掩码嵌入之间保持语义相似性。此外,如先前研究[4, 9]中观察到的,注意力图可以捕获图像中语义上有意义的物体。基于这些基础洞察,我们通过将其应用扩展到双时相图像并利用来自各层的多头特征面,而不是仅依赖单图像嵌入[23],来扩展SAM的特征空间利用。
【解析】这段话阐述了作者方法的理论基础和技术路线。首先,SAM模型具有一个重要特性:在同一场景中,相似物体的掩码嵌入在特征空间中会表现出相似性,这种语义一致性为变化检测提供了重要的先验知识。注意力机制的另一个关键发现是,注意力图本身就能够有效地定位和突出图像中的语义物体,这说明注意力权重不仅仅是计算过程中的中间产物,而是包含了丰富语义信息的有价值特征。基于这两个重要观察,作者设计了一个创新的技术路线:将原本设计用于单图像处理的SAM扩展到双时相图像对的处理。更重要的是,作者不再局限于使用SAM的最终输出嵌入,而是深入挖掘网络内部的多头特征面,这些特征面来自不同的网络层,包含了从低级视觉特征到高级语义特征的多层次信息。多头机制的使用进一步丰富了特征的多样性,每个注意力头可能专注于不同的视觉模式或语义方面。这种设计思路的核心在于充分利用SAM已经学习到的丰富内部表示,而不是简单地将其作为黑盒模型使用。
Figure 2. Illustration of the proposed GeSCF pipeline. The GeSCF pipeline consists of two major steps: (1) initial pseudo-mask generation and (2) geometric-semantic mask matching. First, we intercept facet features from the SAM image encoder and correlate them to obtain multi-head similarity maps, which are then converted into pseudo-masks using an adaptive threshold function. Next, SAM’s classagnostic masks and last image embeddings are utilized to refine these pseudo-masks based on both geometric and semantic information.
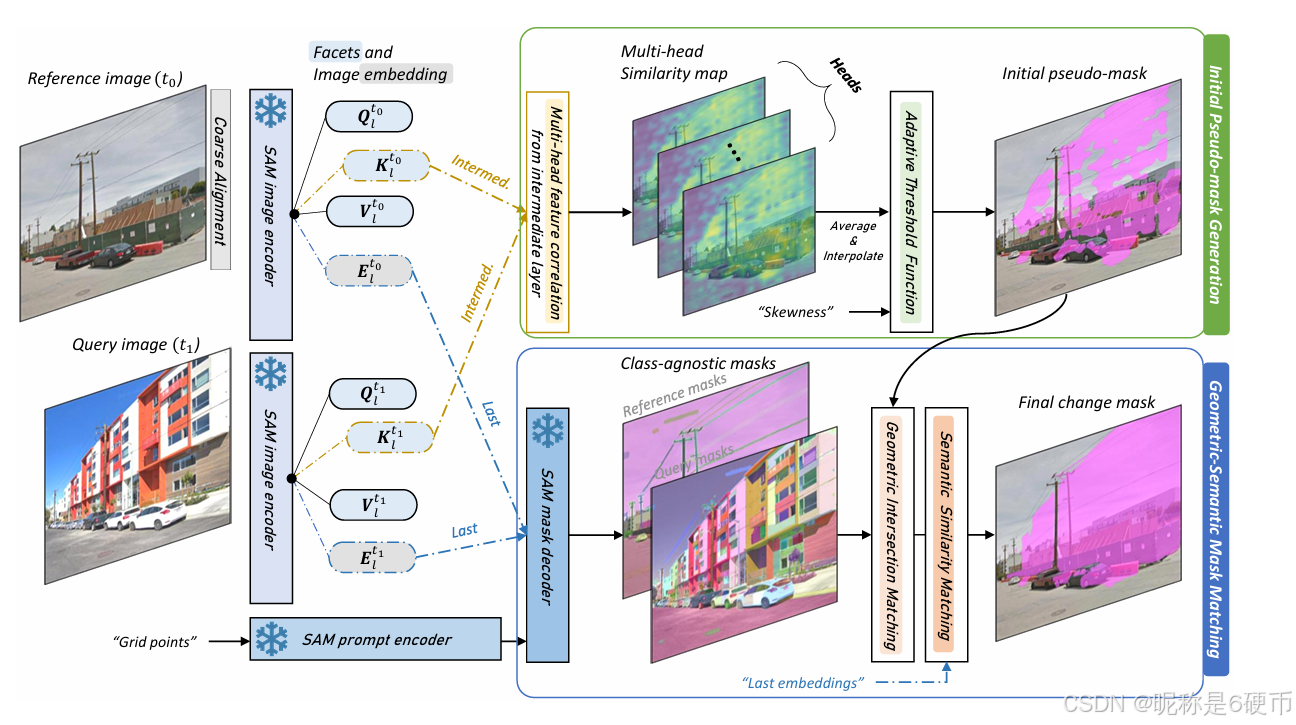
【翻译】图2. 提出的GeSCF流水线示意图。GeSCF流水线包含两个主要步骤:(1) 初始伪掩码生成和 (2) 几何-语义掩码匹配。首先,我们从SAM图像编码器中截取特征面特征并关联它们以获得多头相似性图,然后使用自适应阈值函数将其转换为伪掩码。接下来,利用SAM的类别无关掩码和最后的图像嵌入基于几何和语义信息来细化这些伪掩码。
【解析】这个图描述了整个GeSCF方法的技术流程架构。整个系统被设计为两个阶段,从粗到细的渐进式优化思想。第一阶段"初始伪掩码生成"主要解决的是如何从SAM的内部特征中快速定位可能发生变化的区域。这里的关键创新是直接利用Vision Transformer内部的查询、键、值特征面进行跨时相关联计算,而不是重新设计特征提取器。多头相似性图的计算能够从多个语义角度同时评估两幅图像的相似性,每个注意力头可能关注不同的视觉模式,比如纹理、形状、颜色等。自适应阈值函数则解决了固定阈值方法无法适应不同场景的问题,通过分析相似性分布的统计特性来动态调整阈值。第二阶段"几何-语义掩码匹配"则是一个精细化过程,它利用SAM原本的分割能力来提供物体级别的几何约束,同时通过语义嵌入相似性计算来验证检测到的变化是否在语义上合理,从而最终产生高质量的变化检测结果。
Multi-head Feature Correlation. Given a bi-temporal RGB image pair, we first estimate a coarse transformation [24, 26, 47] relating the bi-temporal images. Then, we intercept the feature facets Fl,nt0,Fl,nt1\mathbf{F}_{l,n}^{t_{0}},\mathbf{F}_{l,n}^{{t}_{1}}Fl,nt0,Fl,nt1 (one of Q,K{\bf Q},{\bf K}Q,K , and V\mathbf{V}V ) for the nnn -th head from the lll -th ViT block and compute multihead feature correlation as follows:
【翻译】多头特征关联。给定双时相RGB图像对,我们首先估计连接双时相图像的粗略变换[24, 26, 47]。然后,我们从第lll个ViT块中截取第nnn个头的特征面Fl,nt0,Fl,nt1\mathbf{F}_{l,n}^{t_{0}},\mathbf{F}_{l,n}^{{t}_{1}}Fl,nt0,Fl,nt1(Q,K{\bf Q},{\bf K}Q,K和V\mathbf{V}V中的一个),并计算多头特征关联如下:
【解析】多头特征关联是整个方法的核心技术环节。首先需要理解为什么要进行"粗略变换估计":由于拍摄时间不同,两幅图像之间可能存在轻微的视角差异、相机位置偏移或者图像配准不完全对齐的问题,这些几何差异会干扰语义变化的检测。通过估计粗略的几何变换关系,可以在一定程度上补偿这些非语义的空间差异。"截取特征面"每个注意力层都会生成查询(Q)、键(K)、值(V)三种特征表示,这些特征包含了不同层次的语义信息。第lll层表示网络的深度,不同深度的特征关注不同粒度的语义信息;第nnn个头表示多头注意力机制中的某个特定头,每个头可能专注于捕获特定类型的视觉模式。
S‾l,nt0↔t1=Fl,nt0⊤Fl,nt1,\overline{\mathbf{S}}_{l,n}^{t_0 \leftrightarrow t_1} = \mathbf{F}_{l,n}^{t_0}{}^{\top} \mathbf{F}_{l,n}^{t_1}, Sl,nt0↔t1=Fl,nt0⊤Fl,nt1,
【解析】这个公式计算的是两个时相图像在第lll层第nnn个头的特征相关性矩阵。矩阵转置操作⊤{}^{\top}⊤和矩阵乘法实际上计算的是两个特征图之间的内积相似性。从数学角度看,如果Fl,nt0\mathbf{F}_{l,n}^{t_0}Fl,nt0的形状是H×W×CH \times W \times CH×W×C(高度×宽度×通道),那么转置后变成C×HWC \times HWC×HW,与形状为HW×CHW \times CHW×C的Fl,nt1\mathbf{F}_{l,n}^{t_1}Fl,nt1相乘,得到HW×HWHW \times HWHW×HW的相关性矩阵。这个矩阵的每个元素(i,j)(i,j)(i,j)表示第一幅图像的第iii个像素位置与第二幅图像的第jjj个像素位置之间的特征相似度。双向箭头符号t0↔t1t_0 \leftrightarrow t_1t0↔t1强调了这种相关性计算的对称性质。
Slt0↔t1=ξ(∑n=1NS‾l,nt0↔t1),\mathbf{S}_{l}^{t_{0}\leftrightarrow t_{1}}=\xi\left(\sum_{n=1}^{N}\overline{{\mathbf{S}}}_{l,n}^{t_{0}\leftrightarrow t_{1}}\right), Slt0↔t1=ξ(n=1∑NSl,nt0↔t1),
【解析】这个公式执行两个重要操作:多头聚合和空间变换。首先,求和操作∑n=1N\sum_{n=1}^{N}∑n=1N将来自NNN个不同注意力头的相似性矩阵进行累加,这样做的原理是每个注意力头关注图像的不同方面,通过聚合多个头的信息可以获得更全面和鲁棒的相似性度量。然后,函数ξ(⋅)\xi(\cdot)ξ(⋅)执行空间重塑和双线性插值操作,将相关性矩阵从HW×HWHW \times HWHW×HW的形式转换回原始输入图像的空间分辨率。这个操作的必要性在于,经过ViT处理后的特征图通常具有较低的空间分辨率(由于patch embedding和下采样),而最终的变化检测结果需要与原始图像具有相同的分辨率。双线性插值是一种常用的上采样技术,能够平滑地恢复空间细节。
where ξ(⋅)\xi(\cdot)ξ(⋅) performs spatial reshaping and bilinear interpolation to the input image size. The correlation in Eq. (1) is a commutative operation that generates identical similarity maps S‾l,n\overline{{{\bf S}}}_{l,n}Sl,n even with the reversed order. Subsequently, the similarity maps are averaged over the head dimension— leveraging the semantic diversity across the NNN heads.
【翻译】其中ξ(⋅)\xi(\cdot)ξ(⋅)执行空间重塑和双线性插值到输入图像尺寸。公式(1)中的相关性是一个可交换操作,即使颠倒顺序也会生成相同的相似性图S‾l,n\overline{{{\bf S}}}_{l,n}Sl,n。随后,相似性图在头维度上进行平均——利用NNN个头之间的语义多样性。
【解析】这段话强调了方法设计中的两个重要数学性质。首先是可交换性(commutativity):由于矩阵乘法在这种特定形式下具有对称性,无论是计算Fl,nt0⊤Fl,nt1\mathbf{F}_{l,n}^{t_0}{}^{\top} \mathbf{F}_{l,n}^{t_1}Fl,nt0⊤Fl,nt1还是Fl,nt1⊤Fl,nt0\mathbf{F}_{l,n}^{t_1}{}^{\top} \mathbf{F}_{l,n}^{t_0}Fl,nt1⊤Fl,nt0,得到的相似性图都是相同的。这种性质对于变化检测任务至关重要,因为变化检测不应该依赖于图像输入的顺序,即从t0t_0t0到t1t_1t1的变化和从t1t_1t1到t0t_0t0的变化应该是一致的。其次是语义多样性的利用:多头注意力机制的核心优势在于不同的头会学习关注不同类型的特征模式,比如有些头专注于边缘信息,有些关注纹理,有些关注颜色等。通过在头维度上进行平均,系统能够综合利用这些多样化的语义视角,从而得到更加鲁棒和全面的相似性度量。
Facet and Layer Selection. As shown in Fig. 3 , the similarity map of SAM’s facets effectively highlights semantic changes while remaining relatively unaffected by visual variations, such as seasonal or illumination differences. Concretely, our feature selection strategy is guided by the following principles: (a) semantic changes should appear prominently in the similarity map compared to other visual variations; (b) the similarity values in changed regions should clearly contrast with surrounding areas; and © artifacts in unchanged regions should be minimized or appear faint. We empirically observe that all facets satisfy principle (a); however, principles (b) and © are particularly noticeable when using the key (or query) facet over the value facet. Moreover, we find that these principles hold more strongly in intermediate layers than in the initial or last layers. Consequently, we leverage the similarity map of key facets from intermediate layers as inputs to the subsequent steps in the pseudo-mask generation. For the detailed quantitative analysis, please refer to the supplementary material.
【翻译】特征面和层选择。如图3所示,SAM特征面的相似性图有效地突出了语义变化,同时相对不受视觉变化(如季节性或光照差异)的影响。具体而言,我们的特征选择策略遵循以下原则:(a) 语义变化应在相似性图中比其他视觉变化更加突出;(b) 变化区域的相似性值应与周围区域形成明显对比;© 未变化区域的伪影应被最小化或显得微弱。我们经验性地观察到所有特征面都满足原则(a);然而,原则(b)和©在使用键(或查询)特征面而非值特征面时特别明显。此外,我们发现这些原则在中间层比在初始层或最后层中表现得更强。因此,我们利用来自中间层的键特征面的相似性图作为伪掩码生成后续步骤的输入。详细的定量分析请参见补充材料。
【解析】这段阐述了作者如何从SAM的众多特征面和网络层中选择最优特征。作者建立了三个核心评价原则来指导特征选择决策。第一个原则强调语义变化与视觉噪声的区分能力:理想的特征应该能够强烈响应真正的语义变化(如建筑物的建造或拆除),而对于非语义的视觉变化(如不同季节的光照条件、阴影变化或天气差异)保持相对稳定。这种选择性响应正是变化检测所需要的核心特性。第二个原则关注空间对比度:变化区域的特征响应应该与其邻近的未变化区域形成鲜明的数值对比,这种强对比度有利于后续的阈值分割和边界定位。第三个原则涉及噪声抑制:在真正未发生变化的区域,理想的特征应该表现出较低的响应或者均匀的响应模式,避免产生误检。通过实验验证,作者发现Vision Transformer中的键(Key)特征面比值(Value)特征面更符合后两个原则。这可能是因为键特征面在注意力机制中负责编码"什么信息是可用的",因此对语义内容的变化更加敏感。而查询(Query)特征面的效果与键特征面相近,这说明它们在语义表示上具有相似的特性。关于网络层深度的选择,中间层的优势在于它们达到了特征抽象程度和空间分辨率之间的最佳平衡。初始层虽然保持了丰富的空间细节,但主要包含低级视觉特征,容易受到光照、纹理等表面变化的干扰。最后层虽然包含高级语义信息,但可能过于抽象,丢失了精确定位变化所需的空间细节。
Adaptive Threshold Function. To create a binary mask from an arbitrary similarity map, the most straightforward approach is to apply a fixed threshold (e.g., p=0.5p=0.5p=0.5 ) [17], where similarity scores below this threshold are classified as changes. However, this fixed threshold approach is inherently limited, as it fails to account for the relative nature of “change” within each similarity map. For instance, a similarity score of 0.7 may signify a change if all other values are close to one, whereas it may not indicate a change if most values are near zero. Consequently, the perception of “change” is context-dependent, necessitating an adaptive thresholding method that accounts for the relative distribution of similarity scores within each map.
【翻译】自适应阈值函数。要从任意相似性图创建二值掩码,最直接的方法是应用固定阈值(例如,p=0.5p=0.5p=0.5)[17],其中低于此阈值的相似性分数被归类为变化。然而,这种固定阈值方法本质上是有限的,因为它未能考虑每个相似性图内"变化"的相对性质。例如,如果所有其他值都接近1,则相似性分数0.7可能表示变化,而如果大多数值接近零,则可能不表示变化。因此,"变化"的感知是上下文相关的,需要一种自适应阈值方法来考虑每个图内相似性分数的相对分布。
【解析】这段探讨了变化检测中阈值设定的问题。传统的固定阈值方法p=0.5p=0.5p=0.5虽然简单直观,但存在缺陷。这种方法隐含地假设相似性分数的分布在所有图像对中都是一致的,这在实际应用中几乎不可能成立。问题的核心在于"变化"本身是一个相对概念而非绝对概念。作者通过具体的数值例子阐明了这一点:当相似性图中的大部分区域都表现出接近1的高相似性时,0.7这个数值就显得异常突出,说明该区域可能发生了显著变化。相反,在一个整体相似性都较低的图像对中,0.7可能是一个相对较高的相似性分数,不应被视为变化。这种相对性的根源在于不同场景的图像特征分布差异巨大:有些场景(如静态的建筑环境)天然具有高度的时间一致性,而有些场景(如自然环境)即使没有真正的语义变化也可能因为动态元素(如植被摆动、阴影移动)而表现出较低的整体相似性。自适应阈值方法的必要性在于它能够根据每个具体相似性图的统计特性来动态调整判断标准,从而更准确地区分真正的语义变化和由环境因素引起的相似性变化。
Therefore, a critical factor to binarize the similarity map is the skewness (γ)(\gamma)(γ) [38] of the similarity distribution (see Fig. 4). For right-skewed distributions, where the majority of pixels display lower similarity scores with a long tail of higher scores, a lower threshold is required to capture a larger portion of the distribution as changes. Conversely, for left-skewed distributions, where most scores are high with a small tail of lower values, a higher threshold is needed to avoid false positives. To this end, we propose an adaptive threshold function for dynamic adjustment based on the skewness of the distribution—enabling a more accurate and context-sensitive method for pseudo-mask generation, as detailed in the following formulation:
【翻译】因此,二值化相似性图的关键因素是相似性分布的偏度(γ)(\gamma)(γ) [38](见图4)。对于右偏分布,其中大多数像素显示较低的相似性分数,并有较高分数的长尾,需要较低的阈值来捕获分布的较大部分作为变化。相反,对于左偏分布,其中大多数分数较高,只有较小的低值尾部,需要较高的阈值以避免假阳性。为此,我们提出了一种基于分布偏度进行动态调整的自适应阈值函数——为伪掩码生成提供了更准确和上下文敏感的方法,详细公式如下:
【解析】这段话解决:如何将连续的相似性分数转换为离散的二值变化掩码。传统的固定阈值方法存在根本性局限,因为不同场景下相似性分数的分布特性差异很大。偏度(γ)(\gamma)(γ)是描述概率分布非对称性的重要统计量,它能够揭示数据分布的形状特征。右偏分布的特点是分布的主体部分集中在较小的数值区间,但存在向右延伸的长尾,这种情况下大部分像素对应较低的相似性分数,只有少数像素具有较高分数。在变化检测场景中,这通常说明大部分区域确实发生了变化,只有少数区域保持不变。因此需要设置较低的阈值来确保捕获到这些真实的变化区域。左偏分布则相反,主体部分集中在较大数值区间,存在向左的短尾,这说明大部分像素具有较高的相似性分数,即大部分区域没有发生变化,只有少数区域发生了变化。此时如果仍使用较低阈值,会将许多未变化的区域错误地标记为变化,产生大量假阳性检测。通过分析分布的偏度特征并据此动态调整阈值,可以使二值化过程更好地适应不同场景的统计特性,从而提高变化检测的准确性和鲁棒性。
F(γ)=bγ+c⋅sign(γ)⋅sγ⋅γ,\mathbf{F}(\gamma)=b_{\gamma}+c\cdot\mathrm{sign}(\gamma)\cdot s_{\gamma}\cdot\gamma, F(γ)=bγ+c⋅sign(γ)⋅sγ⋅γ,
【解析】这个自适应阈值函数的设计体现了几个重要的数学原理。基线阈值bγb_{\gamma}bγ提供了一个中性的起始点,通常设定为数据分布的中位数或均值附近的某个值。符号函数sign(γ)\mathrm{sign}(\gamma)sign(γ)确保阈值调整的方向性:当偏度为正时sign(γ)=+1\mathrm{sign}(\gamma)=+1sign(γ)=+1,说明分布右偏,需要降低阈值;当偏度为负时sign(γ)=−1\mathrm{sign}(\gamma)=-1sign(γ)=−1,说明分布左偏,需要提高阈值。偏度敏感因子sγs_{\gamma}sγ控制阈值对偏度变化的响应强度,这个参数需要根据具体应用场景进行调优。归一化常数ccc确保不同量级的偏度值都能产生合理范围内的阈值调整。整个公式的线性结构保证了计算的简洁和实时,同时偏度γ\gammaγ的直接使用使得阈值调整能够直接反映分布的非对称性程度。这种设计使得阈值能够根据每个具体场景的统计特性进行个性化调整,而不是使用一个对所有场景都相同的固定值。
where bγb_{\gamma}bγ is the baseline threshold, ccc is a normalization constant, sγs_{\gamma}sγ is the skewness sensitivity factor, γ\gammaγ is the skewness of the distribution, and sign(⋅)\mathrm{sign}({\cdot})sign(⋅) adjusts the threshold direction based on the skewness. By applying the computed adaptive threshold to the similarity map—normalized using the mean absolute deviation (MAD) [38]—we obtain the initial pseudo-mask essential for the subsequent GeometricSemantic Mask Matching.
【翻译】其中bγb_{\gamma}bγ是基线阈值,ccc是归一化常数,sγs_{\gamma}sγ是偏度敏感因子,γ\gammaγ是分布的偏度,sign(⋅)\mathrm{sign}({\cdot})sign(⋅)根据偏度调整阈值方向。通过将计算得到的自适应阈值应用于相似性图——使用平均绝对偏差(MAD) [38]进行归一化——我们获得了后续几何-语义掩码匹配所必需的初始伪掩码。
【解析】这段话详细说明了自适应阈值函数各个组成部分的具体作用。平均绝对偏差(MAD)归一化是一个重要的预处理步骤,其数学定义为MAD=median(∣xi−median(x)∣)\text{MAD} = \text{median}(|x_i - \text{median}(x)|)MAD=median(∣xi−median(x)∣),即数据点与中位数偏差的绝对值的中位数。相比于标准差,MAD对异常值更加鲁棒,特别适合处理可能包含噪声的相似性图。归一化过程确保了不同场景下的相似性图具有相似的数值范围,使得自适应阈值函数能够在统一的尺度下工作。初始伪掩码的生成是整个变化检测流水线的关键第一步,它为后续的几何-语义匹配提供了粗略但有效的变化区域候选。伪掩码虽然可能包含一些噪声和不完整的区域,但它提供了变化检测的重要先验信息,帮助后续的SAM掩码筛选和语义验证过程更加有针对性和高效。
Figure 3. Visualization of the similarity map depending on the facets and the layers. We use key facets from the intermediate layer of the SAM ViT image encoder, which is highlighted with a red bounding box.

【翻译】图3. 根据特征面和层的相似性图可视化。我们使用来自SAM ViT图像编码器中间层的键特征面,用红色边界框突出显示。
【解析】每个位置的相似性图反映了该特定层-特征面组合在突出图像变化方面的表现。红色边界框标注的位置对应于中间层的键特征面,这表明作者通过系统性的实验验证发现这个特定组合能够最好地满足前面提到的三个评价原则:强化语义变化、增强空间对比度、抑制背景噪声。中间层的选择反映了深度网络中特征表示的层次化特性:浅层主要捕获低级视觉特征如边缘和纹理,深层则更关注高级语义概念,而中间层恰好处于这两者之间,既具备足够的语义理解能力来区分真实变化,又保持了足够的空间细节来精确定位变化边界。键特征面的优势可能源于其在注意力机制中的特殊作用:键特征负责定义空间位置之间的关联强度,天然适合跨时相的空间对应关系建模。
Figure 4. Illustration of the adaptive thresholding process. We dynamically adjust the threshold based on the skewness of the distribution to generate the initial pseudo-masks.
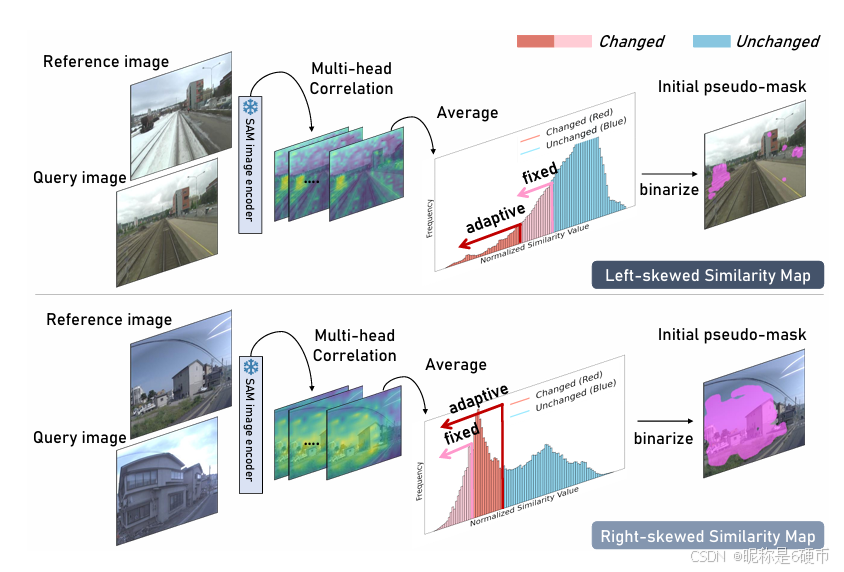
【翻译】图4. 自适应阈值处理过程示意图。我们基于分布的偏度动态调整阈值以生成初始伪掩码。
3.4. 几何-语义掩码匹配
Building upon the initial pseudo-masks, we elevate our focus to detecting object-level changes by using SAM’s class-agnostic object proposals. This transition from pixelwise analysis to object-level consideration enables a more comprehensive and interpretable change mask. Here, we introduce two matching strategies: geometric intersection matching (GIM) and semantic similarity matching (SSM).
【翻译】基于初始伪掩码,我们提升焦点到使用SAM的类别无关目标建议来检测目标级变化。这种从像素级分析到目标级考虑的转变使得变化掩码更加全面和可解释。在这里,我们引入两种匹配策略:几何交集匹配(GIM)和语义相似性匹配(SSM)。
【解析】初始伪掩码虽然能够指示潜在的变化区域,但它本质上是基于像素级特征相似性的粗略估计,可能包含噪声、不完整的边界或者碎片化的检测结果。SAM的类别无关目标建议机制提供了一个强大的解决方案,它能够自动分割出具有完整边界的目标区域,而无需预先知道目标的具体类别。这种特性对于变化检测特别有价值,因为变化的目标可能属于任意类别,从建筑物、车辆到自然景观等。从像素级到目标级的转变带来了几个关键优势:首先是边界完整性,SAM生成的掩码具有清晰的目标边界,避免了像素级检测常见的边缘模糊问题;其次是语义一致性,每个掩码对应一个完整的语义单元,使得检测结果更易于理解和后续处理;最后是噪声抑制,通过目标级的约束可以有效减少由于纹理变化或光照差异引起的虚假检测。两种匹配策略的设计体现了互补性原则:几何交集匹配(GIM)主要关注空间重叠关系,确保选中的目标掩码与初始检测的变化区域在空间上高度对应;语义相似性匹配(SSM)则从特征语义的角度验证变化的合理性,进一步提高检测的准确性。
Geometric Intersection Matching. The main idea of this strategy is to select SAM masks by evaluating their overlap with the initial pseudo-masks. We calculate the intersection ratio α\alphaα between each SAM mask and the pseudo-mask, retaining only those masks with α>αt\alpha{>}\alpha_{t}α>αt , where αt\alpha_{t}αt is a threshold. Since changes can occur bi-temporally, we apply the process for both t0t_{0}t0 and t1t_{1}t1 images—maintaining commutativity for the proposed GeSCF.
【翻译】几何交集匹配。此策略的主要思想是通过评估SAM掩码与初始伪掩码的重叠来选择SAM掩码。我们计算每个SAM掩码与伪掩码之间的交集比率α\alphaα,仅保留那些α>αt\alpha{>}\alpha_{t}α>αt的掩码,其中αt\alpha_{t}αt是阈值。由于变化可能双向发生,我们对t0t_{0}t0和t1t_{1}t1图像都应用此过程——为所提出的GeSCF维持可交换性。
【解析】几何交集匹配的核心是建立空间对应关系的量化度量。交集比率α\alphaα的计算通常采用α=∣SAM mask∩pseudo mask∣∣SAM mask∣\alpha = \frac{|\text{SAM mask} \cap \text{pseudo mask}|}{|\text{SAM mask}|}α=∣SAM mask∣∣SAM mask∩pseudo mask∣的形式,即SAM掩码与伪掩码重叠区域的像素数量除以SAM掩码的总像素数量。这个比率反映了SAM检测到的目标区域中有多大比例被初始伪掩码识别为变化区域。阈值αt\alpha_{t}αt的设定需要在召回率和精确率之间取得平衡:较低的阈值会保留更多的SAM掩码,提高召回率但可能引入更多噪声;较高的阈值则更加严格,提高精确率但可能遗漏一些真实的变化目标。双向处理的必要性在于变化检测的对称性要求:如果在时刻t0t_0t0某个目标出现而在t1t_1t1消失,那么无论是从t0t_0t0到t1t_1t1还是从t1t_1t1到t0t_0t0的分析,都应该能够检测到这个变化。可交换性的维持确保了方法的数学一致性和实际应用中的可靠性,这对于需要处理任意时序图像对的实际系统至关重要。几何匹配策略的优势在于其简单直观且计算高效,能够快速筛选出与变化区域空间重叠的目标候选,为后续的语义验证提供了有效的预筛选机制。
Semantic Similarity Matching. Although GIM provides reasonable masks for potential object-level changes, a set of unchanged regions is included due to noise in the initial pseudo-masks. To address this issue, we perform semantic verification of the overlapping regions by calculating the cosine similarity between the mask embeddings of the bitemporal images. Specifically, for each overlapping mask mˉo\bar m_{o}mˉo, we extract the corresponding mask embeddings Ml,ot0\mathcal{M}_{l,o}^{t_{0}}Ml,ot0 and Ml,ot1\mathcal{M}_{l,o}^{t_{1}}Ml,ot1 from the lll -th image embeddings El\mathbf{E}_{l}El at times t0t_{0}t0 and t1t_{1}t1 , respectively. We then compute a change confidence score using the cosine similarity c(Ml,ot0,Ml,ot1)c(\mathcal{M}_{l,o}^{t_{0}},\mathcal{M}_{l,o}^{{{t}}_{1}})c(Ml,ot0,Ml,ot1) which allows further refinement of the masks selected by GIM and generates the final change mask Ypred{\bf Y}_{\mathrm{pred}}Ypred . Through a layerwise analysis, we empirically observe that semantic differences are more pronounced in the last layer compared to the initial and intermediate layers, thereby utilizing final image embeddings for our SSM process.
【翻译】语义相似性匹配。尽管GIM为潜在的目标级变化提供了合理的掩码,但由于初始伪掩码中的噪声,仍包含一些未变化的区域。为了解决这个问题,我们通过计算双时相图像的掩码嵌入之间的余弦相似度来对重叠区域进行语义验证。具体而言,对于每个重叠掩码mˉo\bar m_{o}mˉo,我们分别从时刻t0t_{0}t0和t1t_{1}t1的第lll层图像嵌入El\mathbf{E}_{l}El中提取对应的掩码嵌入Ml,ot0\mathcal{M}_{l,o}^{t_{0}}Ml,ot0和Ml,ot1\mathcal{M}_{l,o}^{t_{1}}Ml,ot1。然后我们使用余弦相似度c(Ml,ot0,Ml,ot1)c(\mathcal{M}_{l,o}^{t_{0}},\mathcal{M}_{l,o}^{{{t}}_{1}})c(Ml,ot0,Ml,ot1)计算变化置信度分数,这允许进一步细化由GIM选择的掩码并生成最终的变化掩码Ypred{\bf Y}_{\mathrm{pred}}Ypred。通过分层分析,我们经验性地观察到与初始层和中间层相比,语义差异在最后一层更加明显,因此我们使用最终图像嵌入进行SSM过程。
【解析】语义相似性匹配是在几何匹配基础上的关键补充步骤,它解决了纯粹基于空间重叠可能引入的误检问题。几何交集匹配虽然能够筛选出与变化区域空间重叠的目标,但这种重叠可能是由于初始伪掩码中的噪声或不准确边界造成的,导致一些实际未发生变化的区域也被错误地包含进来。语义验证通过比较同一空间位置在不同时刻的特征表示,能够从更深层的语义层面判断该区域是否真正发生了有意义的变化。余弦相似度c(Ml,ot0,Ml,ot1)c(\mathcal{M}_{l,o}^{t_{0}},\mathcal{M}_{l,o}^{t_{1}})c(Ml,ot0,Ml,ot1)的计算公式为c=Ml,ot0⋅Ml,ot1∣∣Ml,ot0∣∣⋅∣∣Ml,ot1∣∣c = \frac{\mathcal{M}_{l,o}^{t_{0}} \cdot \mathcal{M}_{l,o}^{t_{1}}}{||\mathcal{M}_{l,o}^{t_{0}}|| \cdot ||\mathcal{M}_{l,o}^{t_{1}}||}c=∣∣Ml,ot0∣∣⋅∣∣Ml,ot1∣∣Ml,ot0⋅Ml,ot1,其值域为[-1, 1],值越接近1说明两个时刻的特征表示越相似,变化可能性越小;值越接近-1或者越小说明特征差异越大,变化可能性越高。掩码嵌入Ml,ot0\mathcal{M}_{l,o}^{t_{0}}Ml,ot0和Ml,ot1\mathcal{M}_{l,o}^{t_{1}}Ml,ot1是通过在第lll层的图像嵌入El\mathbf{E}_{l}El上应用掩码mˉo\bar m_{o}mˉo得到的,这个过程实际上是在提取该掩码区域对应的特征向量。变化置信度分数的引入使得系统能够对每个候选变化区域进行定量评估,而不是简单的二值判断,这为后续的阈值筛选和最终掩码生成提供了更加精细的控制手段。关于层次选择的实验发现具有重要的理论和实践价值:深度神经网络的不同层次编码了不同层次的特征信息,最后一层的特征表示包含了最丰富的语义信息和最强的判别能力,因此在进行语义相似性比较时能够更准确地识别真实的语义变化而非表面的视觉差异。这种设计确保了SSM过程能够有效过滤由光照变化、视角差异或纹理噪声引起的虚假检测,同时保留真正具有语义意义的变化检测结果。
4. GeSCD
Since the introduction of the first SCD benchmark [42] in 2015, the generalizability to unseen domains and temporal consistency of predictions have not been consistently or comprehensively addressed in the SCD field. Most traditional SCD approaches train and evaluate models on individual datasets separately [3, 11, 25, 35, 43, 44, 48, 50]. Only [39] performed cross-domain evaluation, however, it still suffers from domain gaps and limited training datasets. Moreover, in contrast to the remote sensing CD [65], the temporal consistency is often overlooked in model design [3, 11, 25, 35, 43, 44, 48] or training objectives [3, 11, 25, 35, 43, 44, 48, 50] in the SCD field. The temporal symmetry proposed in [50] is unsuitable for real-world applications since it assumes perfect inductive bias of the application domain, which is not feasible in real-world scenarios. Further, as we are in the age of diverse anything models [23, 51, 56, 58, 61, 66] with strong zero-shot prediction and generalizability, the necessity of anything SCD model that can adapt to various change scenarios has become increasingly important in the research community.
【翻译】自2015年首个SCD基准测试[42]引入以来,对未见领域的泛化能力和预测的时间一致性在SCD领域中尚未得到一致或全面的解决。大多数传统的SCD方法在各个数据集上分别训练和评估模型[3, 11, 25, 35, 43, 44, 48, 50]。只有[39]进行了跨领域评估,然而,它仍然存在领域差距和有限训练数据集的问题。此外,与遥感变化检测[65]不同,在SCD领域中,时间一致性在模型设计[3, 11, 25, 35, 43, 44, 48]或训练目标[3, 11, 25, 35, 43, 44, 48, 50]中经常被忽视。[50]中提出的时间对称性不适用于真实世界应用,因为它假设应用领域的完美归纳偏置,这在真实世界场景中是不可行的。此外,随着我们进入具有强零样本预测和泛化能力的多样化通用模型[23, 51, 56, 58, 61, 66]时代,能够适应各种变化场景的通用SCD模型的必要性在研究社区中变得越来越重要。
Based on these requirements, we propose GeSCD—a novel task approach that addresses the generalizability of broader scenarios and temporal consistency of SCD models. By pioneering new metrics, an evaluation dataset, and a comprehensive evaluation protocol, our approach fulfills the critical need for SCD research that is genuinely applicable and effective across diverse settings.
【翻译】基于这些需求,我们提出了GeSCD——一种新颖的任务方法,解决了SCD模型更广泛场景的泛化能力和时间一致性问题。通过开创性地提出新的度量标准、评估数据集和全面的评估协议,我们的方法满足了SCD研究在不同环境下真正适用和有效的关键需求。
Metrics. To evaluate the environmental and temporal robustness of the methods simultaneously, we report conventional metrics (e.g., Intersection over Union and F1-score) for both temporal directions in contrast to previous methods that typically report performance for a single temporal direction [3, 11, 25, 35, 43, 44, 48, 50]. Furthermore, we propose the Temporal Consistency (TC) metric by measuring the union intersection between t0→t1t0{\rightarrow}t1t0→t1 and t1→t0t1{\rightarrow}t0t1→t0 predictions as follows:
TemporalConsistency(TC)=Ypredt0→t1∩Ypredt1→t0Ypredt0→t1∪Ypredt1→t0,{\mathrm{Temporal~Consistency~(TC)}}={\frac{\mathbf{Y}_{\mathrm{pred}}^{t0\to t1}\cap\mathbf{Y}_{\mathrm{pred}}^{t1\to t0}}{\mathbf{Y}_{\mathrm{pred}}^{t0\to t1}\cup\mathbf{Y}_{\mathrm{pred}}^{t1\to t0}}}, Temporal Consistency (TC)=Ypredt0→t1∪Ypredt1→t0Ypredt0→t1∩Ypredt1→t0,
where the proposed TC score indicates how much the SCD algorithms can generate consistent change masks in bidirectional orders.
【翻译】度量标准。为了同时评估方法的环境和时间鲁棒性,我们报告了两个时间方向的传统度量标准(例如,交并比和F1分数),这与之前通常只报告单一时间方向性能的方法形成对比[3, 11, 25, 35, 43, 44, 48, 50]。此外,我们通过测量t0→t1t0{\rightarrow}t1t0→t1和t1→t0t1{\rightarrow}t0t1→t0预测之间的并集交集提出了时间一致性(TC)度量标准,其中所提出的TC分数表示SCD算法能够在双向顺序中生成一致变化掩码的程度。
【解析】这段描述了作者为了全面评估场景变化检测方法而设计的新评估体系。传统的变化检测方法通常只考虑从时刻t0t_0t0到t1t_1t1这一个方向的变化检测性能,但这种单向评估存在明显的局限性。在理想情况下,无论是从t0t_0t0分析到t1t_1t1还是从t1t_1t1分析到t0t_0t0,检测算法都应该能够识别出相同的变化区域,这体现了算法的时间对称性和一致性。时间一致性(TC)度量的设计非常巧妙,它通过计算两个方向预测结果的交集与并集的比值来量化这种一致性。具体而言,分子Ypredt0→t1∩Ypredt1→t0\mathbf{Y}_{\mathrm{pred}}^{t0\to t1}\cap\mathbf{Y}_{\mathrm{pred}}^{t1\to t0}Ypredt0→t1∩Ypredt1→t0表示两个方向都检测到的变化区域,即算法在两个方向上都一致认为发生了变化的像素;分母Ypredt0→t1∪Ypredt1→t0\mathbf{Y}_{\mathrm{pred}}^{t0\to t1}\cup\mathbf{Y}_{\mathrm{pred}}^{t1\to t0}Ypredt0→t1∪Ypredt1→t0表示至少在一个方向上被检测为变化的所有区域。当TC值接近1时,说明算法在两个时间方向上的预测高度一致;当TC值较低时,则表明算法存在明显的时间偏置或不一致性。这个度量标准的引入填补了变化检测领域在时间一致性评估方面的空白,为开发更加可靠和稳定的变化检测算法提供了重要的评估工具。环境鲁棒性的评估通过在不同数据集和场景下测试模型来实现,而时间鲁棒性则通过这个新提出的TC度量来量化,两者结合为算法的全面评估提供了更加严格和科学的标准。
Evaluation Datasets. First, we consider three standard SCD datasets with different characteristics: VL-CMUCD [3], TSUNAMI [42], and ChangeSim [34]. These datasets represent urban environments in the USA, disasterimpacted urban areas in Japan, and industrial indoor settings within simulation environments, respectively. Furthermore, for the quantitative evaluation on broader unseen domains, we create a new dataset named the ChangeVPR. The ChangeVPR comprises 529 image pairs collected from the SF-XL (urban, U) [8], St Lucia (suburban, S) [30], and Nordland (rural, R) [45] datasets, which are widely used in the Visual Place Recognition (VPR) research. We carefully sampled image pairs from each dataset to reflect various SCD challenges such as weather conditions and seasonal changes, and hand-labeled the ground-truth change masks for each image pair. We employ ChangeVPR only for the evaluation to assess unseen domain performance. Please refer to the supplementary material for more details.
【翻译】评估数据集。首先,我们考虑三个具有不同特征的标准SCD数据集:VL-CMUCD [3]、TSUNAMI [42]和ChangeSim [34]。这些数据集分别代表美国的城市环境、日本受灾影响的城市区域以及仿真环境中的工业室内设置。此外,为了在更广泛的未见领域进行定量评估,我们创建了一个名为ChangeVPR的新数据集。ChangeVPR包含从SF-XL(城市,U)[8]、St Lucia(郊区,S)[30]和Nordland(农村,R)[45]数据集中收集的529对图像,这些数据集在视觉地点识别(VPR)研究中被广泛使用。我们仔细地从每个数据集中采样图像对,以反映各种SCD挑战,如天气条件和季节变化,并为每对图像手动标注了真实变化掩码。我们仅将ChangeVPR用于评估以评估未见领域性能。更多详细信息请参阅补充材料。
Evaluation Protocol. We perform extensive cross-domain evaluation for SCD models. First, we train each model on the three standard SCD datasets; the training stage results in three distinctive models for each method. Then, we assess each of the three distinctive models in two stages. First, we evaluate the three models on the three conventional SCD datasets; this process totals nine assessments. If the method of interest does not involve training, we evaluate the model on the three datasets (three assessments). Next, we evaluate the models on the proposed ChangeVPR dataset. Since we use ChangeVPR only for evaluation, this stage contains three assessments per model (due to three splits of ChangeVPR). As a result, the proposed protocol estimates performance on both seen and unseen domains—ensuring a thorough evaluation of SCD performance in various environmental scenarios with arbitrary real-world changes.
【翻译】评估协议。我们对SCD模型进行广泛的跨领域评估。首先,我们在三个标准SCD数据集上训练每个模型;训练阶段为每种方法产生三个不同的模型。然后,我们分两个阶段评估这三个不同的模型。首先,我们在三个传统SCD数据集上评估这三个模型;此过程总共包含九次评估。如果感兴趣的方法不涉及训练,我们在三个数据集上评估模型(三次评估)。接下来,我们在提出的ChangeVPR数据集上评估模型。由于我们仅将ChangeVPR用于评估,此阶段每个模型包含三次评估(由于ChangeVPR的三个分割)。因此,提出的协议估计了在已见和未见领域上的性能——确保在具有任意真实世界变化的各种环境场景中对SCD性能进行彻底评估。
Figure 5. Qualitative results on VL-CMU-CD dataset with F1- scores. Our model generates reasonable change masks and does not display annotation bias.

【翻译】图5. VL-CMU-CD数据集上的定性结果及F1分数。我们的模型生成合理的变化掩码且不显示标注偏置。
5. Experiments
5.1. 对比研究
We compare our method with four state-of-the-art SCD models: CSCDNet [44], CDResNet [44], DR-TANet [11], and C-3PO [50]. For C-3PO, we adopt the (I+D)(\mathrm{I+D})(I+D) structure for the VL-CMU-CD and the (I+A+D+E)\mathrm{(I+A{+}D{+}E)}(I+A+D+E) ) structure for the TSUNAMI and ChangeSim datasets, following the configurations proposed in the paper. To verify the temporal consistency, we additionally train all models with bi-temporal objective [65]; the performance of these bi-temporally trained models has not been reported in the literature.
【翻译】我们将我们的方法与四种最先进的SCD模型进行比较:CSCDNet [44]、CDResNet [44]、DR-TANet [11]和C-3PO [50]。对于C-3PO,我们按照论文中提出的配置,对VL-CMU-CD采用(I+D)(\mathrm{I+D})(I+D)结构,对TSUNAMI和ChangeSim数据集采用(I+A+D+E)\mathrm{(I+A{+}D{+}E)}(I+A+D+E)结构。为了验证时间一致性,我们额外使用双时间目标[65]训练所有模型;这些双时间训练模型的性能在文献中尚未报告。
Quantitative Comparison. Tab. 1 displays the quantitative comparison results on the standard SCD datasets. The results attest that GeSCF outperforms the baselines with a large margin in every unseen domain (off-diagonal results) and on-par performance on seen domains (diagonal results), along with complete TC score (TC=1.0)(\mathrm{TC}{=}1.0)(TC=1.0) ) for all settings—demonstrating its superior generalizability over diverse environments and temporal conditions. The current best performance on the VL-CMU-CD dataset drops sharply from 77.6%77.6\%77.6% to 4.6%4.6\%4.6% when the temporal order is reversed and to 8.0%8.0\%8.0% when deployed to the unseen TSUNAMI dataset. Remarkably, our GeSCF even outperforms the supervised baselines for the ChangeSim dataset by an F1-score of 54.8%54.8\%54.8% in a zero-shot manner. Overall, the average performance of our method on standard SCD datasets surpasses that of the second-best by a substantial margin (+19.2%)(+19.2\%)(+19.2%) . Furthermore, the majority of baselines do not display a complete TC score which is crucial for the system’s reliability. The temporal consistency of C-3PO does not hold in VL-CMU-CD settings as shown in its low TC scores. We find that simple bi-temporal training does not guarantee complete temporal consistency and unseen domain performance, even worsening the unitemporal performances—indicating different data characteristics from [65] and the significance of our commutative architecture. Tab. 2 presents the quantitative comparison results on the proposed ChangeVPR dataset. The results consistently show that GeSCF outperforms the baselines across all unseen domains with a +30.0%+30.0\%+30.0% margin (nearly doubling the prior art performance), extending beyond the conventional urban-/synthetic-only SCD scope. Notably, GeSCF demonstrates exceptional performance in Nordland [45] split, a challenging dataset with severe seasonal variation (summer-winter).
【翻译】定量比较。表1显示了在标准SCD数据集上的定量比较结果。结果证明GeSCF在每个未见领域(非对角结果)都以很大的优势超越了基线方法,在已见领域(对角结果)上表现相当,同时在所有设置下都获得了完整的TC分数(TC=1.0)(\mathrm{TC}{=}1.0)(TC=1.0)——证明了其在不同环境和时间条件下的卓越泛化能力。当前在VL-CMU-CD数据集上的最佳性能从77.6%77.6\%77.6%急剧下降到时间顺序颠倒时的4.6%4.6\%4.6%,部署到未见TSUNAMI数据集时下降到8.0%8.0\%8.0%。值得注意的是,我们的GeSCF甚至以零样本方式在ChangeSim数据集上以54.8%54.8\%54.8%的F1分数超越了监督基线。总体而言,我们方法在标准SCD数据集上的平均性能以显著优势(+19.2%)(+19.2\%)(+19.2%)超越了第二名。此外,大多数基线方法没有显示完整的TC分数,这对系统的可靠性至关重要。C-3PO的时间一致性在VL-CMU-CD设置中不成立,如其低TC分数所示。我们发现简单的双时间训练不能保证完整的时间一致性和未见领域性能,甚至会恶化单时间性能——表明与[65]不同的数据特征以及我们可交换架构的重要性。表2展示了在提出的ChangeVPR数据集上的定量比较结果。结果一致显示GeSCF在所有未见领域都以+30.0%+30.0\%+30.0%的优势超越基线(几乎是现有技术性能的两倍),扩展了传统仅限城市/合成的SCD范围。值得注意的是,GeSCF在Nordland [45]分割上表现出色,这是一个具有严重季节变化(夏季-冬季)的挑战性数据集。
Qualitative Comparison. As illustrated in Fig. 1, GeSCF adeptly adapts to various unseen images, accurately delineating changed objects—significantly outperforming the current state-of-the-art model. Moreover, as a zero-shot framework, GeSCF does not learn annotation biases in a dataset (see Fig. 5). For instance, GeSCF generates a more accurate and interpretable mask for the object and identifies unannotated changes—displaying resilience to erroneous GTs. These results suggest that GeSCF’s outputs are more reasonable than baselines, even though its quantitative results are lower for some samples in the in-domain settings.
【翻译】定性比较。如图1所示,GeSCF巧妙地适应各种未见图像,准确地描绘变化对象——显著超越当前最先进的模型。此外,作为零样本框架,GeSCF不会学习数据集中的标注偏置(见图5)。例如,GeSCF为对象生成更准确和可解释的掩码,并识别未标注的变化——显示出对错误真实标签的韧性。这些结果表明GeSCF的输出比基线更合理,尽管在某些域内设置的样本中其定量结果较低。
Table 1. Quantitative results (F1-score) on standard SCD datasets.
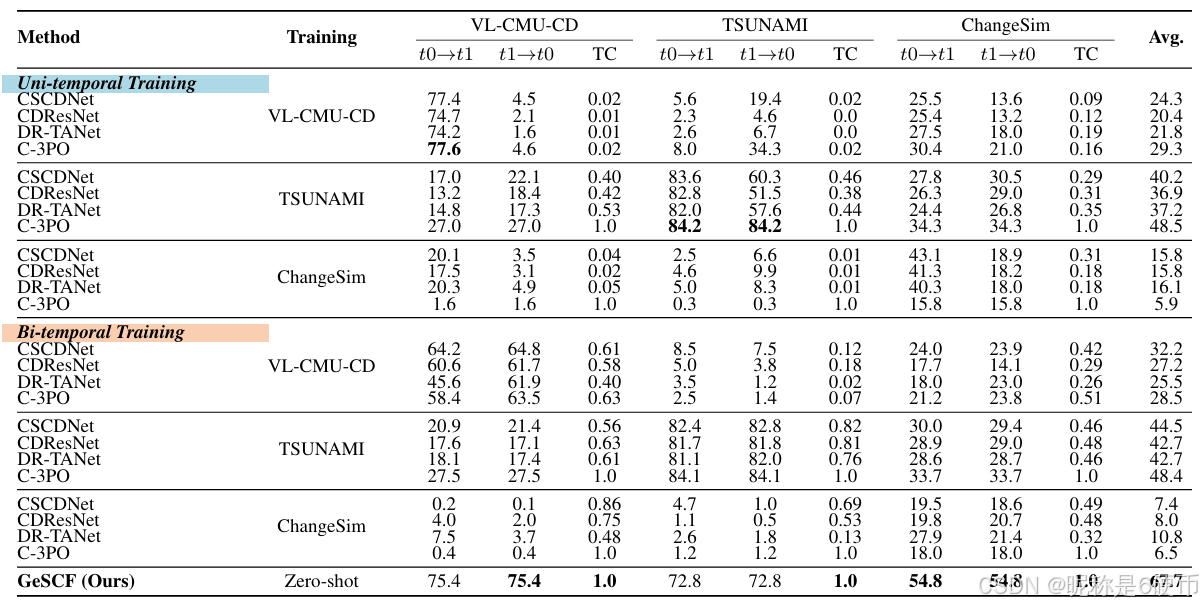
【翻译】表1. 标准SCD数据集上的定量结果(F1分数)。
Table 2. Quantitative results (F1-score) on the ChangeVPR dataset.
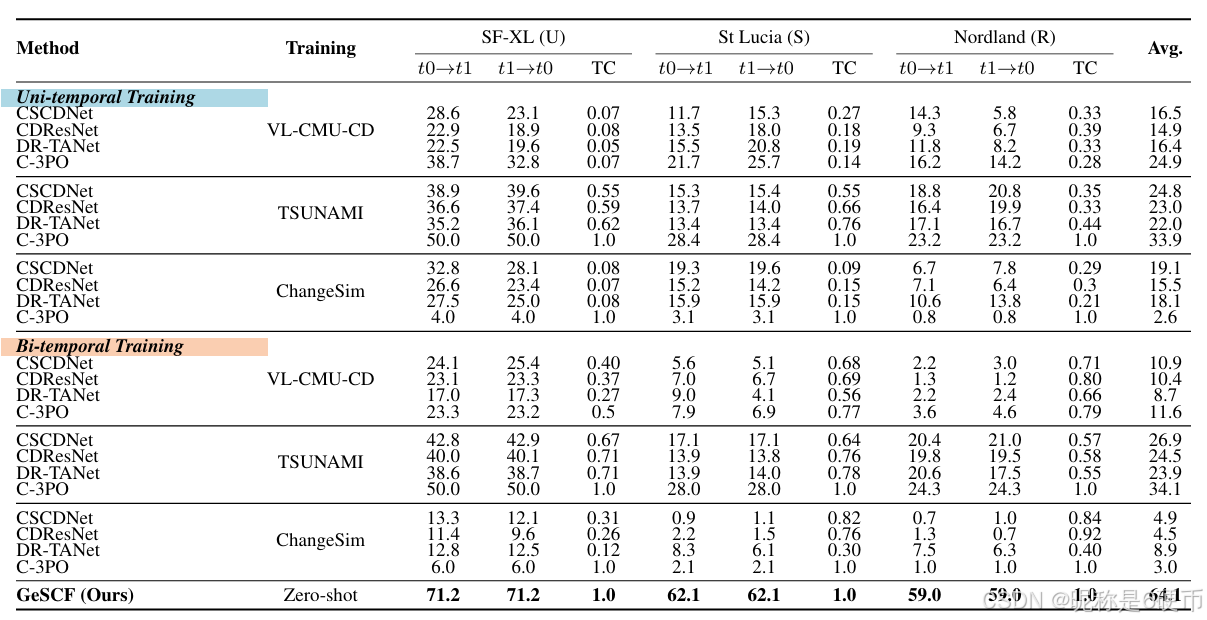
【翻译】表2. ChangeVPR数据集上的定量结果(F1分数)。
5.2. 消融研究
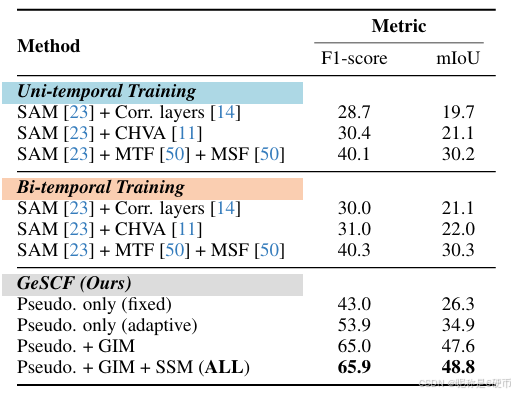
To understand the effectiveness of our contributions, we conducted comprehensive ablation studies across three standard SCD datasets and ChangeVPR (see Tab. 3). We utilized baselines trained on TSUNAMI [42], which demonstrated superior average performance over others.
【翻译】为了理解我们贡献的有效性,我们在三个标准SCD数据集和ChangeVPR上进行了全面的消融研究(见表3)。我们使用在TSUNAMI [42]上训练的基线,该基线在其他方法中表现出优越的平均性能。
Fine-tuning Strategy. We fine-tuned various SCD-based adapter networks on the frozen SAM image encoder, involving correlation layers [14], CHVA [11], and the feature merging module [50]. Our experiments reveal that finetuning the adaptor model on relatively small SCD datasets significantly undermines its zero-shot capabilities, resulting in a substantial performance drop compared to our proposed GeSCF. Notably, our initial pseudo-masks alone achieve an F1-score that surpasses the fine-tuned variants.
【翻译】微调策略。我们在冻结的SAM图像编码器上微调了各种基于SCD的适配器网络,包括相关层[14]、CHVA [11]和特征合并模块[50]。我们的实验表明,在相对较小的SCD数据集上微调适配器模型显著削弱了其零样本能力,与我们提出的GeSCF相比导致性能大幅下降。值得注意的是,仅我们的初始伪掩码就获得了超越微调变体的F1分数。
Effectiveness of the Proposed Modules. We validated the effectiveness of each proposed module, including the Initial Pseudo-mask Generation with adaptive threshold function, Geometric-Semantic Mask Matching with geometric intersection matching (GIM), and semantic similarity matching (SSM). The findings suggest that each introduced module positively influences GeSCF’s overall performance, with the initial pseudo-mask generation (adaptive) and GIM demonstrating significant enhancement.
【翻译】提出模块的有效性。我们验证了每个提出模块的有效性,包括带有自适应阈值函数的初始伪掩码生成、带有几何交集匹配(GIM)的几何-语义掩码匹配,以及语义相似性匹配(SSM)。研究结果表明,每个引入的模块都对GeSCF的整体性能产生积极影响,其中初始伪掩码生成(自适应)和GIM表现出显著的增强效果。
5.3. 超越场景变化检测
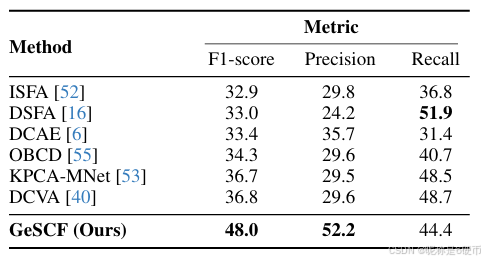
Although our research primarily focuses on natural scene CDs and each CD field tends to focus on its own [25], we discovered that GeSCF can also be applied to zero-shot remote sensing CD. Following the standard evaluation metrics of the remote sensing domain, we evaluated our model against several unsupervised methods [6, 16, 40, 52, 53, 55] on the SECOND [59] benchmark (see Tab. 4). Remarkably, our GeSCF outperforms other baselines with 48.0%48.0\%48.0% in F1-score and a high precision of 52.2%52.2\%52.2% —underscoring its zero-shot potential for different CD domains.
【翻译】尽管我们的研究主要关注自然场景CD,且每个CD领域都倾向于专注于自己的领域[25],但我们发现GeSCF也可以应用于零样本遥感CD。按照遥感领域的标准评估指标,我们在SECOND [59]基准上将我们的模型与几种无监督方法[6, 16, 40, 52, 53, 55]进行了评估(见表4)。值得注意的是,我们的GeSCF以48.0%48.0\%48.0%的F1分数和52.2%52.2\%52.2%的高精度超越了其他基线——突显了其在不同CD领域的零样本潜力。
Table 3. Ablation study results.
【翻译】表3. 消融研究结果。
Table 4. Quantitative comparison with unsupervised remote sensing CD methods on the SECOND (test) benchmark.
【翻译】表4. 在SECOND(测试)基准上与无监督遥感CD方法的定量比较。
6. Conclusion
In this study, we attempted to address the generalization issue and temporal bias of scene change detection using the Segment Anything Model for the first time to the best of our knowledge; we define GeSCD along with the novel metrics, evaluation dataset (ChangeVPR), and an evaluation protocol to effectively assess the generalizability and temporal consistency of SCD models. Furthermore, we proposed GeSCF, a generalizable zero-shot approach for the SCD task using the localized semantics of the SAM that does not require costly SCD labeling. Our extensive experiments demonstrated that the proposed GeSCF significantly outperforms existing SCD models on standard SCD datasets and overwhelms them on the ChangeVPR dataset while achieving complete temporal consistency. We expect our methods can serve as a solid step towards robust and generalizable Scene Change Detection research.
【翻译】在这项研究中,据我们所知,我们首次尝试使用Segment Anything Model解决场景变化检测的泛化问题和时间偏置;我们定义了GeSCD以及新颖的指标、评估数据集(ChangeVPR)和评估协议,以有效评估SCD模型的泛化能力和时间一致性。此外,我们提出了GeSCF,这是一种可泛化的零样本SCD任务方法,使用SAM的局部语义,无需昂贵的SCD标注。我们的广泛实验表明,所提出的GeSCF在标准SCD数据集上显著超越现有SCD模型,在ChangeVPR数据集上压倒性地超越它们,同时实现完整的时间一致性。我们期望我们的方法能够成为稳健且可泛化的场景变化检测研究的坚实一步。