植物翻译官:基于 EfficientNetB7 的植物性状预测
植物翻译官:基于 EfficientNetB7 的植物性状预测
代码详见:https://github.com/xiaozhou-alt/PlantsTraits_Prediction
文章目录
- 植物翻译官:基于 EfficientNetB7 的植物性状预测
- 一、项目介绍
- 二、文件夹结构
- 三、数据集介绍
- 1.数据集背景
- 2. 数据集描述
- 四、LightGBM 算法介绍
- 1. 模型架构核心:复合缩放(Compound Scaling)
- 2. 主干网络:MBConv 模块
- 3. 多模态融合:图像 + 辅助特征
- 4. 迁移学习与微调策略
- 五、项目实现
- 1. 数据加载和预处理
- 2. 特征标准化
- 3. 图像处理函数
- 4. 创建TensorFlow数据集
- 5. 构建多模态模型
- 6. 编译模型
- 7. 设置回调函数
- 8. 开始训练!
- 9. 在验证集上评估
- 六、结果展示
一、项目介绍
本项目是一个基于深度学习的植物性状预测系统,使用多模态数据(植物图像和环境特征)来预测植物的多种性状。该系统结合了计算机视觉和机器学习技术,能够从植物图像和环境数据中提取特征,并准确预测包括叶片特性、生长状态等在内的多个植物性状指标
本项目源于:PlantTraits2024 - FGVC11 | Kaggle
二、文件夹结构
PlantsTraits_Prediction/
├── README.md
├── requirements.txt
├── train.py
├── data/├── README-data.md # 数据说明文档,描述数据来源和结构├── test_images ├── train_images├── sample_submission.csv # 提交样例文件├── target_name_meta.tsv # 预测目标名称├── test.csv # 测试集辅助特征数据└── train.csv # 训练集标签和辅助特征数据
├── log/
└── output/├── model/ # 模型保存目录└── pic/ # 图片输出目录
三、数据集介绍
以下数据集信息均来源于 Kaggle 官网比赛(PlantTraits2024 - FGVC11)
1.数据集背景
为了创建这个数据库,我们利用了 TRYTRYTRY 数据库(性状信息)和 iNaturalistiNaturalistiNaturalist 数据库(公民科学植物照片)。根据两个数据库中发现的物种名称,我们将从 TRYTRYTRY 数据库获得的性状观察结果(物种特异性平均值和标准差)与植物照片 (iNaturalist) 联系起来。根据每张植物照片附带的地理坐标,我们链接了辅助预测变量,这些预测变量源自全球可用的栅格数据(WORLDCLIM、SOIL、VOD、MODIS)。简而言之,WORLDCLIM 包括温度和降水数据,SOIL 是全球土壤网格数据集(各种土壤特性的插值产品,例如沙子含量或 pH 值),MODIS 是测量太阳光光学反射率的卫星数据(类似于相机,但具有许多波长),而 VOD 表示来自对植物含水量和生物量敏感的雷达星座的数据。除了植物照片之外,所有这些地理数据集都旨在作为支持信息。
2. 数据集描述
文件
- train_images - 包含训练图像的文件夹 (.jpeg)
- train.csv - 每个训练图像的标签和辅助数据(卫星数据、土壤数据、气候数据等)
- test_images - 包含测试图像 (.jpeg) 的文件夹,该文件夹将用于为提交创建预测。
- test.csv - 每个测试图像的辅助数据(卫星数据、土壤数据、气候数据等)
- target_name_meta.csv - 从 TRY 数据库获得的特征的全名。这对于了解我们预测的所有特征很重要
- sample_submission.csv - 格式正确的示例提交文件
列
id- 唯一 ID 和图像名称的前缀WORLDCLIM_BIO[*]- 这些是辅助气候变量,可用于促进性状预测。该选择基于 Schiller 等人,2021 年。SOIL_[*]- 这些是辅助土壤变量,可用于促进性状预测。MODIS_[*]/VOD_[*]- 这些是辅助的多时态卫星变量,可用于促进性状预测(详情见下文)。X[*]_mean- 这些是要预测的目标。有多个特征(X3112、X1080 等)。X[*]_sd- 这是每个物种发现的性状的标准差。您可以在训练过程中将其与基于响应的数据增强相结合。因此,您可以在训练期间通知模型物种的性状可能会有所不同(取决于环境条件,参见 Schiller 等人,2021 年)。
数据集图片展示:

四、LightGBM 算法介绍
EfficientNetB7 函数
参考:EfficientNet B0 到 B7(Keras)
keras.applications.EfficientNetB7(include_top=True,weights="imagenet",input_tensor=None,input_shape=None,pooling=None,classes=1000,classifier_activation="softmax",name="efficientnetb7",
)
参考
EfficientNet: 重新思考卷积神经网络的模型缩放 (ICML 2019)
此函数返回一个 Keras 图像分类模型,可选择加载在 ImageNet 上预训练的权重。
对于 图像分类 用例,请参阅 此页面 获取详细示例。
对于 迁移学习 用例,请务必阅读 迁移学习和微调指南。
注意:每个 Keras 应用都期待一种特定的输入预处理。对于 EfficientNetEfficientNetEfficientNet,输入预处理作为模型的一部分(作为一个 Rescaling 层)被包含在内,因此 keras.applications.efficientnet.preprocess_input 实际上是一个直通函数。EfficientNetEfficientNetEfficientNet 模型期望其输入是像素值为 [0-255] 范围的浮点张量。
参数
- include_top:是否包含网络顶部的全连接层。默认为
True。 - weights:以下之一:
None(随机初始化)、"imagenet"(在 ImageNetImageNetImageNet 上预训练)或要加载的权重文件路径。默认为"imagenet"。 - input_tensor:可选的 KerasKerasKeras 张量(即
layers.Input()的输出)用作模型的图像输入。 - input_shape:可选的形状元组,仅当
include_top为False时指定。它应该正好有 333 个输入通道。 - pooling:当
include_top为False时,用于特征提取的可选池化模式。默认为None。None表示模型的输出将是最后一个卷积层的 4D4D4D 张量输出。avg表示将全局平均池化应用于最后一个卷积层的输出,因此模型的输出将是一个 2D2D2D 张量。max表示将应用全局最大池化。
- classes:要将图像分类到的可选类别数量,仅当
include_top为True且未指定weights参数时指定。ImageNetImageNetImageNet 有 100010001000 个类别。默认为1000。 - classifier_activation:一个
str或可调用对象。用于“顶层”的激活函数。除非include_top=True,否则忽略。将classifier_activation=None设置为返回“顶层”的 logitslogitslogits。默认为'softmax'。加载预训练权重时,classifier_activation只能是None或"softmax"。 - name:模型的名称 (字符串)
EfficientNetB7 模型架构示意图:
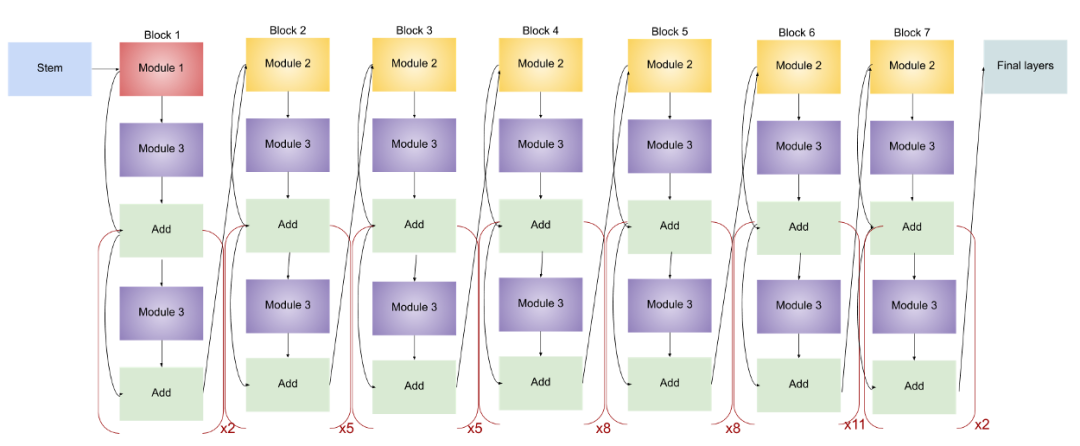
1. 模型架构核心:复合缩放(Compound Scaling)
EfficientNetB7 的核心创新在于 复合缩放策略(Compound Scaling),通过同时平衡网络深度(depth)、宽度(width)和输入分辨率(resolution)来提升模型性能。其缩放公式如下:
{深度:d=αϕ宽度:w=βϕ分辨率:r=γϕ分辨率:α⋅β2⋅γ2≈2α≥1,β≥1,γ≥1\left\{ \begin{array}{lr} \textbf{深度}:d = \alpha^{\phi} & \\ \textbf{宽度}:w = \beta^{\phi} & \\ \textbf{分辨率}:r = \gamma^{\phi} & \\ \textbf{分辨率}:\alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2 & \\ \alpha \geq 1,\quad \beta \geq 1,\quad \gamma \geq 1 \end{array} \right. ⎩⎨⎧深度:d=αϕ宽度:w=βϕ分辨率:r=γϕ分辨率:α⋅β2⋅γ2≈2α≥1,β≥1,γ≥1
其中:
- ddd,www,rrr 分别表示深度、宽度和分辨率的缩放系数;
- ϕϕϕ 是一个用户控制的缩放因子;
- ααα,βββ,γγγ 是通过神经架构搜索(NAS)确定的最优比例。
🤓🤓🤓小周有话说:
想象你要建一座大楼(模型):
深度(d)是楼层数,决定模型有多 “深” ;
宽度(w)是每层的房间数,决定每层能处理多少信息;
分辨率(r)是窗户的大小,决定你能看到多少细节。
EfficientNetB7 就像是精心设计的摩天大楼,既不太高(避免训练困难),也不太宽(避免计算爆炸),窗户也足够大(看清细节)
2. 主干网络:MBConv 模块
EfficientNetB7 由多个 MBConv(Mobile Inverted Bottleneck Conv)模块堆叠而成。每个模块包含:
- 一个扩展层(1×1卷积提升通道数);
- 一个深度可分离卷积(Depthwise Separable Conv);
- 一个压缩层(1×1卷积降低通道数);
- 可选的跳跃连接(Residual Connection)。
其计算可表示为:
MBConv(x)=Conv1×1(DepthwiseConv(Conv1×1(x)))MBConv(x)=Conv_{1×1} (DepthwiseConv(Conv _{1×1}(x))) MBConv(x)=Conv1×1(DepthwiseConv(Conv1×1(x)))
🤓🤓🤓小周有话说:
MBConv模块就像是一个“智能过滤器”:
1.先 扩大 通道数(像拉开拉链让内容展开);
2.用深度卷积 逐通道处理(像用不同的筛子筛选不同材料);
3.再 压缩 回原来的通道数(像合上拉链节省空间);
4.最后决定是否 跳过 本层(短路连接,避免信息丢失)。
这样既省计算量,又保留了重要特征。
3. 多模态融合:图像 + 辅助特征
在项目中,EfficientNetB7 作为图像特征提取器,与辅助特征(如气候数据)进行融合。模型结构可表示为:
Output=Dense(Concat[EfficientNetB7(I);MLP(A)])Output=Dense(Concat[EfficientNetB7(I);MLP(A)]) Output=Dense(Concat[EfficientNetB7(I);MLP(A)])
其中:
- III 是输入图像;
- AAA 是辅助特征向量;
- ConcatConcatConcat 表示特征拼接;
- DenseDenseDense 是全连接层进行回归预测。
4. 迁移学习与微调策略
项目使用了在 ImageNetImageNetImageNet 上预训练的 EfficientNetB7EfficientNetB7EfficientNetB7,并冻结前 150150150 层,仅 微调顶层。损失函数为均方误差(MSE):
L=1N∑i=1N(yi−y^i)2\mathcal{L}=\frac{1}{N}\sum_{i=1}^{N}\left(y_{i}-\hat{y}_{i}\right)^{2} L=N1i=1∑N(yi−y^i)2
优化器为 AdamAdamAdam,学习率设置为 0.00050.00050.0005,并配合 ReduceLROnPlateauReduceLROnPlateauReduceLROnPlateau (学习率调度器) 动态调整。
五、项目实现
1. 数据加载和预处理
- 使用
pandas加载训练和测试 CSV 文件 - 确保ID列是整数类型,避免后续处理中的类型错误
- 使用
train_test_split将训练数据划分为训练集和验证集(80%/20%80\%/20\%80%/20%) - 设置随机种子确保每次划分结果一致
- 打印训练和验证样本数量,便于了解数据规模
# 加载数据
print("Loading data...")
train_df = pd.read_csv(TRAIN_CSV_PATH)
test_df = pd.read_csv(TEST_CSV_PATH)# 确保ID列是整数类型
train_df['id'] = train_df['id'].astype(int)
test_df['id'] = test_df['id'].astype(int)# 划分训练集和验证集
train_ids, val_ids = train_test_split(train_df['id'].values, test_size=0.2, random_state=42
)train_data = train_df[train_df['id'].isin(train_ids)]
val_data = train_df[train_df['id'].isin(val_ids)]print(f"Training samples: {len(train_data)}")
print(f"Validation samples: {len(val_data)}")
2. 特征标准化
- 使用
StandardScaler对辅助特征进行标准化处理- 对训练集使用
fit_transform,计算并应用标准化参数 - 对验证集和测试集使用
transform,使用训练集计算的参数进行转换
- 对训练集使用
- 同样对目标变量进行标准化处理
- 标准化可以加速模型收敛并提高性能
# 数据预处理
# 标准化辅助特征
scaler_aux = StandardScaler()
train_aux_features = scaler_aux.fit_transform(train_data[AUX_FEATURE_COLS].values)
val_aux_features = scaler_aux.transform(val_data[AUX_FEATURE_COLS].values)
test_aux_features = scaler_aux.transform(test_df[AUX_FEATURE_COLS].values)# 标准化目标变量
scaler_target = StandardScaler()
train_targets = scaler_target.fit_transform(train_data[TARGET_COLS].values)
val_targets = scaler_target.transform(val_data[TARGET_COLS].values)
3. 图像处理函数
- 定义图像加载和预处理函数,确保图像 ID 为整数类型
- 使用
OpenCV读取图像文件 - 将 BGR 格式转换为 RGB 格式(
OpenCV默认使用 BGR) - 调整图像大小到指定尺寸,将像素值归一化到[0,1]\textbf{[0, 1]}[0, 1]范围
# 图像数据生成器
def load_and_preprocess_image(image_id, img_dir, img_size):# 确保image_id是整数image_id = int(image_id)img_path = os.path.join(img_dir, f"{image_id}.jpeg")img = cv2.imread(img_path)if img is None:# 如果图像无法加载,返回黑色图像img = np.zeros((*img_size, 3), dtype=np.uint8)print(f"Warning: Could not load image {image_id}.jpeg")else:img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)img = cv2.resize(img, img_size)img = img.astype(np.float32) / 255.0return img
4. 创建TensorFlow数据集
- 定义创建 TensorFlowTensorFlowTensorFlow 数据集的函数,使用生成器模式处理大型数据集,避免内存不足
- 根据是否为训练模式,定义不同的输出签名,对训练数据集进行
shuffle操作,增加随机性 - 使用批处理和预取操作优化数据加载性能,创建训练和验证数据集
# 创建TensorFlow数据集
def create_dataset(df, aux_features, targets, img_dir, img_size, batch_size, shuffle=True, is_training=True):image_ids = df['id'].valuesdef generator():for i in range(len(df)):img = load_and_preprocess_image(image_ids[i], img_dir, img_size)aux = aux_features[i]if is_training:target = targets[i]yield (img, aux), targetelse:yield (img, aux)if is_training:output_signature = ((tf.TensorSpec(shape=(*img_size, 3), dtype=tf.float32),tf.TensorSpec(shape=(len(AUX_FEATURE_COLS),), dtype=tf.float32)),tf.TensorSpec(shape=(len(TARGET_COLS),), dtype=tf.float32))else:output_signature = ((tf.TensorSpec(shape=(*img_size, 3), dtype=tf.float32),tf.TensorSpec(shape=(len(AUX_FEATURE_COLS),), dtype=tf.float32)))dataset = tf.data.Dataset.from_generator(generator,output_signature=output_signature)if shuffle:dataset = dataset.shuffle(buffer_size=1000)dataset = dataset.batch(batch_size)dataset = dataset.prefetch(tf.data.AUTOTUNE)return dataset# 创建数据集
print("Creating datasets...")
train_dataset = create_dataset(train_data, train_aux_features, train_targets, TRAIN_IMG_DIR, IMG_SIZE, BATCH_SIZE, shuffle=True
)
val_dataset = create_dataset(val_data, val_aux_features, val_targets,TRAIN_IMG_DIR, IMG_SIZE, BATCH_SIZE, shuffle=False
)
5. 构建多模态模型
- 定义多模态模型构建函数,包含图像和辅助特征两个输入分支
- 图像分支使用 EfficientNetB7EfficientNetB7EfficientNetB7 作为特征提取器
- 使用预训练的 ImageNetImageNetImageNet 权重
- 冻结前 150150150 层以减少可训练参数数量
- 添加 DropoutDropoutDropout 层防止过拟合
- 使用全连接层进一步提取特征
- 辅助特征分支处理环境特征
- 使用多个全连接层提取特征
- 添加 DropoutDropoutDropout 层防止过拟合
- 合并 两个分支的特征,使用多个全连接层处理合并后的特征
- 输出层使用线性激活函数,适用于回归任务
# 构建更大的模型
def create_enhanced_multimodal_model(img_shape, num_aux_features, num_targets):# 图像分支 - 使用更大的EfficientNetB7img_input = layers.Input(shape=(*img_shape, 3))base_model = applications.EfficientNetB7(include_top=False, weights='imagenet', input_shape=(*img_shape, 3),pooling='avg')# 冻结前150层以减少可训练参数但仍允许部分学习for layer in base_model.layers[:150]:layer.trainable = Falseimg_features = base_model(img_input)img_features = layers.Dropout(0.4)(img_features)img_features = layers.Dense(512, activation='relu')(img_features)img_features = layers.Dropout(0.3)(img_features)# 辅助特征分支 - 增加复杂度aux_input = layers.Input(shape=(num_aux_features,))aux_features = layers.Dense(128, activation='relu')(aux_input)aux_features = layers.Dropout(0.3)(aux_features)aux_features = layers.Dense(64, activation='relu')(aux_features)aux_features = layers.Dropout(0.2)(aux_features)aux_features = layers.Dense(32, activation='relu')(aux_features)# 合并特征combined = layers.concatenate([img_features, aux_features])combined = layers.Dense(256, activation='relu')(combined)combined = layers.Dropout(0.4)(combined)combined = layers.Dense(128, activation='relu')(combined)combined = layers.Dropout(0.3)(combined)combined = layers.Dense(64, activation='relu')(combined)# 输出层outputs = layers.Dense(num_targets, activation='linear')(combined)model = models.Model(inputs=[img_input, aux_input], outputs=outputs)return model# 创建模型
print("Creating enhanced model...")
model = create_enhanced_multimodal_model(IMG_SIZE, len(AUX_FEATURE_COLS), len(TARGET_COLS))
6. 编译模型
- 使用 AdamAdamAdam 优化器,设置较低的学习率(0.00050.00050.0005)以提高训练稳定性
- 使用 均方误差(MSEMSEMSE)作为损失函数,适用于回归问题
- 使用 平均绝对误差(MAEMAEMAE)作为评估指标
- 使用对象而不是字符串指定损失和指标,避免加载模型时的兼容性问题
# 编译模型 - 使用对象而不是字符串
model.compile(optimizer=optimizers.Adam(learning_rate=0.0005), # 降低学习率loss=tf.keras.losses.MeanSquaredError(), # 使用对象而不是字符串metrics=[tf.keras.metrics.MeanAbsoluteError()] # 使用对象而不是字符串
)
7. 设置回调函数
- 设置模型检查点回调,保存验证损失最小的模型
- 设置早停回调,当验证损失在 121212 个
epoch内没有改善时停止训练 - 设置学习率衰减回调,当验证损失在 555 个
epoch内没有改善时降低学习率 - 自定义进度条回调,显示训练进度和指标
# 回调函数
checkpoint_cb = callbacks.ModelCheckpoint("/kaggle/working/best_model.h5", save_best_only=True, monitor='val_loss', mode='min'
)
early_stopping_cb = callbacks.EarlyStopping(patience=12, # 增加耐心值restore_best_weights=True,monitor='val_loss',mode='min'
)
reduce_lr_cb = callbacks.ReduceLROnPlateau(factor=0.5, patience=5, min_lr=1e-7
)# 自定义进度条回调
class BatchProgressCallback(callbacks.Callback):def __init__(self, total_epochs, batches_per_epoch):super().__init__()self.total_epochs = total_epochsself.batches_per_epoch = batches_per_epochself.epoch_progress = Nonedef on_epoch_begin(self, epoch, logs=None):self.epoch_progress = tqdm(total=self.batches_per_epoch,desc=f'Epoch {epoch+1}/{self.total_epochs}',unit='batch')def on_batch_end(self, batch, logs=None):if self.epoch_progress:self.epoch_progress.update(1)loss_val = logs.get('loss', 'N/A')mae_val = logs.get('mean_absolute_error', 'N/A')if isinstance(loss_val, (int, float)):loss_str = f"{loss_val:.4f}"else:loss_str = str(loss_val)if isinstance(mae_val, (int, float)):mae_str = f"{mae_val:.4f}"else:mae_str = str(mae_val) self.epoch_progress.set_postfix({'loss': loss_str,'mae': mae_str}) def on_epoch_end(self, epoch, logs=None):if self.epoch_progress:self.epoch_progress.close()self.epoch_progress = Noneval_loss = logs.get('val_loss', 'N/A')val_mae = logs.get('val_mean_absolute_error', 'N/A')if isinstance(val_loss, (int, float)):val_loss_str = f"{val_loss:.4f}"else:val_loss_str = str(val_loss) if isinstance(val_mae, (int, float)):val_mae_str = f"{val_mae:.4f}"else:val_mae_str = str(val_mae)print(f"Epoch {epoch+1}/{self.total_epochs} - val_loss: {val_loss_str} - val_mae: {val_mae_str}")# 计算每个epoch的batch数量
steps_per_epoch = len(train_data) // BATCH_SIZE
if len(train_data) % BATCH_SIZE > 0:steps_per_epoch += 1
# 创建自定义进度条回调
batch_progress_cb = BatchProgressCallback(EPOCHS, steps_per_epoch)
8. 开始训练!
- 设置
verbose=0,使用自定义进度条而不是默认输出 - 保存训练历史到 JSON 文件,便于后续分析
- 保存训练历史到 Excel 文件,便于查看和分析
# 训练模型
print("Training enhanced model...")
history = model.fit(train_dataset,epochs=EPOCHS,validation_data=val_dataset,callbacks=[checkpoint_cb, early_stopping_cb, reduce_lr_cb, batch_progress_cb],verbose=0
)# 保存训练历史到JSON
with open('/kaggle/working/training_history.json', 'w') as f:json.dump(history.history, f)# 保存训练历史到Excel
history_df = pd.DataFrame(history.history)
history_df.to_excel('/kaggle/working/training_history.xlsx', index=False)
print("Training history saved to Excel.")
训练输出示例如下所示:
Epoch 1/15: 100%|██████████| 1480/1480 [29:19<00:00, 1.19s/batch, loss=0.9927, mae=0.1505]
Epoch 1/15 - val_loss: 13464.7295 - val_mae: 0.5924
…
Epoch 15/15 - val_loss: 13464.7031 - val_mae: 0.5834
9. 在验证集上评估
- 将预测结果和目标变量逆变换回原始尺度
- 计算每个目标变量的 R2R²R2 分数,评估模型性能
- 计算平均 R2R²R2 分数,评估整体性能
# 在验证集上评估
print("Evaluating on validation set...")
val_preds = model.predict(val_dataset, verbose=1)
val_preds_original = scaler_target.inverse_transform(val_preds)
val_targets_original = scaler_target.inverse_transform(val_targets)# 计算R2分数
r2_scores = []
for i, col in enumerate(TARGET_COLS):r2 = r2_score(val_targets_original[:, i], val_preds_original[:, i])r2_scores.append(r2)print(f"{col} R2 score: {r2:.4f}")print(f"Average R2 score: {np.mean(r2_scores):.4f}")
评估结果如下所示:
| Traits | score |
|---|---|
| X4_mean R2 score | -0.1221 |
| X11_mean R2 score | -0.0000 |
| X18_mean R2 score | -0.0002 |
| X26_mean R2 score | 0.0001 |
| X50_mean R2 score | -0.0003 |
| X3112_mean R2 score | -0.0001 |
Average R2 score | -0.0204 |
六、结果展示
训练的损失、MAE 以及学习率记录如下:

模型在验证集上随机选取 6 个样本测试得到的结果如下:

如果你喜欢我的文章,不妨给小周一个免费的点赞和关注吧!