【ICCV 2025 顶会论文】,新突破!卷积化自注意力 ConvAttn 模块,即插即用,显著降低计算量和内存开销。
![]()
Bilibili:CV缝合救星

🌈 小伙伴们看过来~
写推文真的不容易,每一行字、每一张图都倾注了我们的心血💦 如果你觉得这篇内容对你有帮助、有启发,别忘了顺手点个赞、转发一下、或者点个“在看” 支持我们一下哈~✨
你的一点鼓励🌟,对我们来说就是超大的动力!
👀 小声提醒:用电脑打开阅读更舒服哟,排版清晰、体验更棒!谢谢大家~我们会继续努力产出优质内容,陪你一起进步呀✌️❤️



01 论文信息

论文题目:Emulating Self-attention with Convolution for Efficient Image Super-Resolution (ICCV 2025 顶会论文)
中文题目:用卷积模拟自注意力的高效图像超分辨率方法
即插即用模块:Convolutional Attention 卷积注意力(ConvAttn模块)
02 论文概要

Highlight
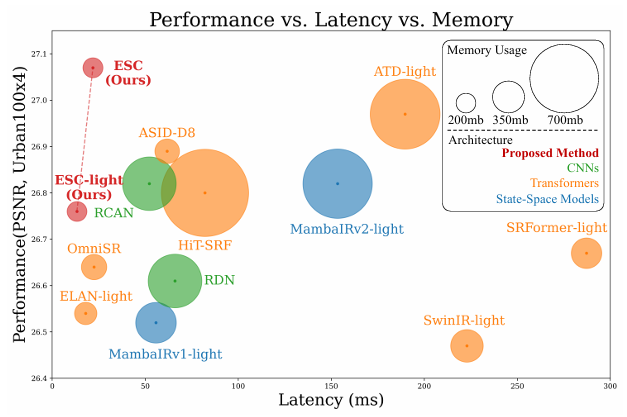
图 1. 性能、延迟和内存使用的比较。我们的方法与代表性的超分辨率模型进行评估,包括 CNN、Transformer 和状态空间模型(SSM)。
03 研究背景

🌧️ 存在的问题(背景动因)
① 自注意力的高内存开销:自注意力需要显式构建大规模相似度矩阵,涉及复杂的张量变换与内存访问,难以在轻量级任务和资源受限设备上部署。
② 卷积的局部性限制:传统卷积只能在固定核大小范围内捕捉局部特征,难以建模长程依赖,导致表达力不足。
③ 注意力与卷积割裂使用:现有方法往往单独使用注意力或卷积,两者优缺点难以互补,既无法保证全局建模,又难兼顾高效推理。
💡 解决思路(ConvAttn 核心贡献)
① 卷积化的注意力建模:提出 ConvAttn 模块,将自注意力的长程建模与输入依赖性转化为卷积操作,通过共享大核和动态小核实现高效替代。
② 共享大核捕获全局依赖:利用统一的大尺度卷积核在整个网络中复用,模拟自注意力的长程交互,避免重复计算与冗余存储。
③ 动态小核实现输入自适应:引入动态卷积核,根据输入特征生成权重,自适应建模局部依赖,保留了注意力的实例敏感性。
④ 高效轻量与可移植性:ConvAttn 在内存与计算上显著低于自注意力,同时保持表达力,可直接替换网络中大部分注意力层,适用于多种轻量化视觉任务。
04 模块原理解读

📌 模块解析 | Convolutional Attention 卷积注意力模块(ConvAttn 模块)
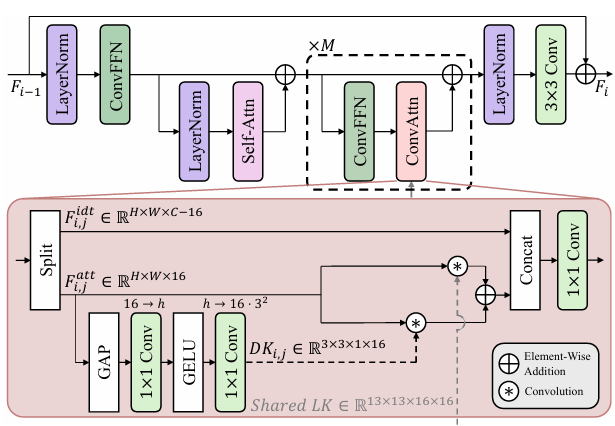
图 2. 所提出的ConvAttn模块流程图
📌 ConvAttn 模块聚焦于“长程依赖”与“输入自适应”的统一建模,其核心由以下三个关键特点构成:
① 共享大核建模长程依赖:通过统一的大尺度卷积核(13×13),在整个网络范围内复用,以模拟自注意力的长程交互能力。该设计有效减少了层间的冗余计算,并避免重复构建注意力矩阵,从而在保持全局感知力的同时大幅降低内存占用。
② 动态小核实现输入依赖:基于输入特征生成动态卷积核(3×3),自适应捕获局部邻域特征,模拟自注意力的实例敏感性。该机制能够针对不同输入灵活调整权重,使模型具备输入自适应的表达能力。
③ 高效轻量化实现:ConvAttn 仅在部分通道上施加大核与动态卷积,结合 1×1 卷积进行特征融合,显著降低内存访问与计算开销。相较于显式的自注意力矩阵构建,ConvAttn 在保持表示能力的同时具备更强的可部署性。
🔍 该模块通过“共享大核的全局依赖”与“动态小核的局部自适应”的协同作用,有效模拟了自注意力的核心优势,既维持了 Transformer 的长程建模能力,又缓解了内存瓶颈,在图像超分辨率等轻量化任务中表现出色。
05 创新思路

CV缝合救星原创模块
🧠 模块名称:MiLK-ConvAttn Block —— Mixture-of-Large-Kernels Convolutional Attention(混合大核卷积注意力模块)
💡 长按识别🔍,领取💾源码

💡 设计动机:在轻量化视觉网络中,传统 ConvAttn 以“共享大核 + 动态小核”近似自注意力,但共享大核对输入不敏感、层间重复度高;而单一动态 3×3 又难以覆盖长程依赖。MiLK-ConvAttn 通过“大核字典路由 + 动态小核 + 双路径软门控”三重机制,让长程分支随输入与通道自适应,同时保持局部分支的实例敏感性与低开销,兼顾可部署性与表达力。
📌 核心创新点
1. 大核字典路由(创新点⭐)
以少量可学习“大核基(bases)”构成字典,通过样本×通道级路由权重在字典上线性混合,生成按样本×通道的 depthwise 大核,实现对远程依赖的输入自适应建模,避免单一共享大核带来的表达僵化与层间冗余。
2. 动态 3×3 局部聚合(创新点⭐)
使用全局上下文驱动的轻量 MLP 产生通道特定的 3×3 动态卷积核,逐通道 depthwise 卷积捕获细粒度结构与纹理变化,保留实例敏感性与局部精度。
3. 双路径软门控融合(创新点⭐)
引入通道级二维门控,对“长程(MiLK)/局部(Dyn-3×3)”两条分支施行softmax 竞争融合,自适应分配语义与细节的权重,避免简单相加造成的信息冲突。
4. 可插拔外部共享大核(创新点⭐)
保留外部 lk_filter 全卷积路径接口,便于与既有 ConvAttn/ESC 体系对齐做可控对比实验或作为“先验长程”信号参与融合。
5. 低开销与易部署(创新点⭐)
大核在通道维度做 depthwise,字典规模小(如 6–8 个基核),路由与门控均为 1×1/全局池化 MLP,显存与时延友好,适合轻量化与移动端场景。
📌 输入输出
输入:
x ∈ [B, C, H, W] (输入特征图)可选外部大核滤波器
输出:
[B, C, H, W] (与输入同形状)
📌 过程步骤
Step 1:通道划分
将输入特征分为前一部分参与注意力建模,后一部分作为旁路保留,降低整体计算开销。
Step 2:大核字典路由
利用全局信息生成路由权重,在大核字典中进行动态混合,得到随输入自适应的长程卷积核,捕获大范围上下文关系。
Step 3:动态 3×3 局部聚合
通过小核卷积生成动态卷积核,对局部邻域特征进行细粒度聚合,增强对纹理和边缘的刻画能力。
Step 4:可选外部分支
若提供外部共享大核,则作为附加路径叠加到长程分支,提升特征的全局一致性。
Step 5:双路径软门控融合
通过轻量化门控,对长程分支和局部分支的输出做软性融合,自适应调整两者的权重比例。
Step 6:残差输出
融合后的结果经 1×1 卷积投影,与输入残差相加,再与旁路通道拼接,得到最终输出特征图。
👉 总结:
MiLK-ConvAttn 模块通过 大核字典路由 + 动态小核聚合 + 双路径软门控 的协同优化,不仅有效模拟了自注意力的长程依赖与输入自适应特性,还保持了轻量化与可部署性。该模块在分类、检测、分割和超分辨率等任务中,兼顾全局上下文与局部细节,显著提升了模型的表达能力与性能。
06 模块适用任务

🎯 ConvAttn 模块适用任务(Convolutional Attention,卷积注意力模块)
1. 轻量化超分辨率任务:在保证长程依赖建模的同时降低内存和延迟,适合移动端实时图像/视频超分辨率。
2. 图像去噪与复原:利用大核捕捉全局依赖,小核动态聚合局部细节,提升在低对比度和噪声干扰下的还原能力。
3. 语义分割与场景解析:模拟自注意力的全局依赖关系,适合对大范围上下文敏感的分割与解析任务。
4. 小目标检测与细节识别:动态小核增强局部纹理建模,提高对小目标与边界区域的检测精度。
5. 通用可移植性:作为可替换自注意力层的轻量化组件,可嵌入 CNN 或 Transformer 主干,提升模型的全局-局部融合能力。
🎯 MiLK-ConvAttn 模块适用任务(Mixture-of-Large-Kernels Convolutional Attention,混合大核卷积注意力模块)
1. 多尺度上下文建模:大核字典路由适应不同场景尺度,适合复杂场景分割、遥感影像与医学影像解析。
2. 小目标检测与增强:长程大核与局部动态 3×3 联合建模,提升对行人、车辆、病灶等小目标的捕捉能力。
3. 跨场景适应性任务:双路径软门控融合机制能自适应调配全局与局部特征,适合开放场景检测和多类别识别。
4. 轻量化实时应用:字典规模小、计算量可控,适合自动驾驶、移动端实时分割和视频理解等对延迟敏感的任务。
5. 高扩展性嵌入:既能作为 CNN 的增强单元,也可与 Transformer 结合,兼顾全局建模与局部细节,适合分类、检测、分割等多任务场景。
📌 总结对比
ConvAttn(原始版):更适合 轻量化和单一场景任务,突出 共享大核建模长程依赖 + 动态小核增强局部细节 的结合。它在超分辨率、图像复原和实时分割等场景下表现稳定,优势在于 高效替代自注意力、内存占用低、部署简单。
MiLK-ConvAttn(增强版):更适合 多尺度和复杂场景任务,突出 大核字典路由 + 动态小核聚合 + 双路径软门控 的协同优化。相比原始 ConvAttn,它在 多尺度感知、跨场景适应性和小目标检测 上更具优势,能够在保证轻量化的同时实现更强的全局–局部联合建模,适合 自动驾驶、遥感、医学影像 等需要语义完整性和细节还原的任务。
07 运行结果与即插即用代码

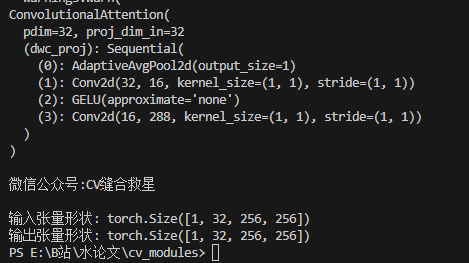
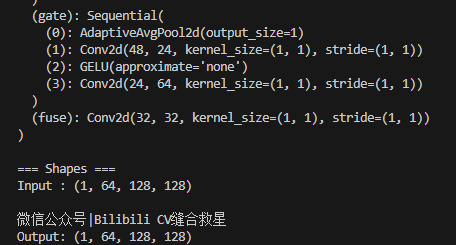
运行结果
🎯 ConvAttn模块

🎯MiLK-ConvAttn模块
本文代码获取
立即加星标

每天看好文



扫码关注
福高照 祭灶神
扫尘土 贴窗花