搭建机器学习模型的数据管道架构方案
本篇文章Designing Data Pipeline Architectures for Machine Learning Models适合对数据管道架构感兴趣的读者,亮点在于详细解析了传统数据仓库、云原生数据湖和现代湖仓这三种架构,帮助理解如何将原始数据转化为可操作的预测。文中还强调了不同架构的优缺点,提供了清晰的比较。
文章目录
- 1 简介
- 2 传统数据仓库
- 2.1 案例研究 — 股票价格预测
- 2.2 添加暂存区
- 3 云原生数据湖
- 3.1 标准ELT方法
- 3.2 推送ELT方法
- 3.3 ETLT(提取、轻量转换、加载和转换)方法
- 3.4 数据摄取模式
- 3.5 Lambda架构
- 3.6 Kappa架构
- 3.6.1 案例研究 — 股票价格预测
- 4 现代湖仓一体架构
- 4.1 案例研究 — 股票价格预测
- 5 结论

1 简介
数据管道架构是指导将原始数据转化为可操作预测的战略蓝图。
但设计架构似乎很复杂,因为它涉及众多组件,并且每个组件的具体选择都取决于数据的特性和业务需求。
在本文中,我将结构化这些组件,并探讨三种常见模式:
- 传统数据仓库
- 云原生数据湖
- 现代湖仓一体架构
并以股票价格预测作为实际用例。
数据管道架构定义了数据从摄取到可用于分析和机器学习状态的结构、组件和流向。
下图展示了数据管道架构中的关键组件和主要选项:

关键组件包括:
- 数据源(Data Source):数据的来源。
- 摄取(Ingestion):收集数据并将其引入系统的方法。
- 存储(Storage):数据存放的位置。
- 处理(Processing):数据的转换和清洗。
- 服务(Serving):使处理后的数据可供最终用户和应用程序访问。
- 治理(Governance):确保数据质量、安全性、隐私和合规性。
处理部分涉及加载策略,如全量加载、增量加载和增量更新,以及数据转换,如清洗、插补和预处理。
每个组件的选择都由数据特性驱动,包括其多样性(variety)、数据量(volume)和数据速度(velocity),以及具体的业务需求。
- 多样性(Variety):数据的多样性(结构化、半结构化、非结构化)影响存储选择。
- 数据量(Volume):数据的庞大数量决定了对可扩展、分布式技术(如Spark、Hadoop)和经济高效的存储解决方案(如云对象存储)的需求。
- 数据速度(Velocity):数据生成和处理的速度决定了它是应该采用用于高速数据的实时流式架构,还是用于低速数据的批处理架构。
- 业务需求是最终的指导力量。
由于某些选项之间存在强关联性,我将在下一节中介绍三种常见组合,并以股票价格预测为例。
2 传统数据仓库
第一种组合是使用 ETL(提取、转换、加载) 方法的传统数据仓库架构。
下图展示了其标准架构,其中原始数据被提取并转换为结构化数据,然后加载以适应数据仓库中预定义的模式:
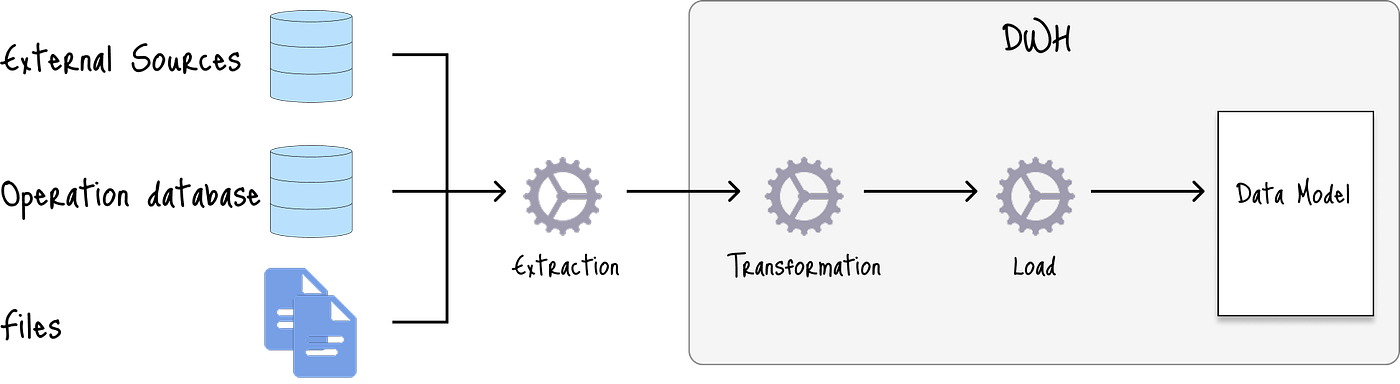
每个组件中选择的典型选项是:
- 数据源:结构化、批处理
- 摄取:批处理
- 存储:数据仓库
- 处理:ETL(提取、转换、加载)
- 服务:BI、低频报告和分析
ETL过程在加载之前严格清洗和转换数据,这确保了:
- 对稳定、定义明确的数据源的访问,
- 高水平的准确性和一致性,以及
- 非常快的查询性能。
缺点包括:
- 数据类型:不适用于图像、文本等非结构化或半结构化数据。
- 成本:维护数据仓库可能很昂贵。
- 延迟:批处理过程意味着数据是按计划更新的,例如每日或每周。不适用于实时推理。
2.1 案例研究 — 股票价格预测
该架构最适合基于季度或年度财务报告以及历史日终股票价格的长期预测。
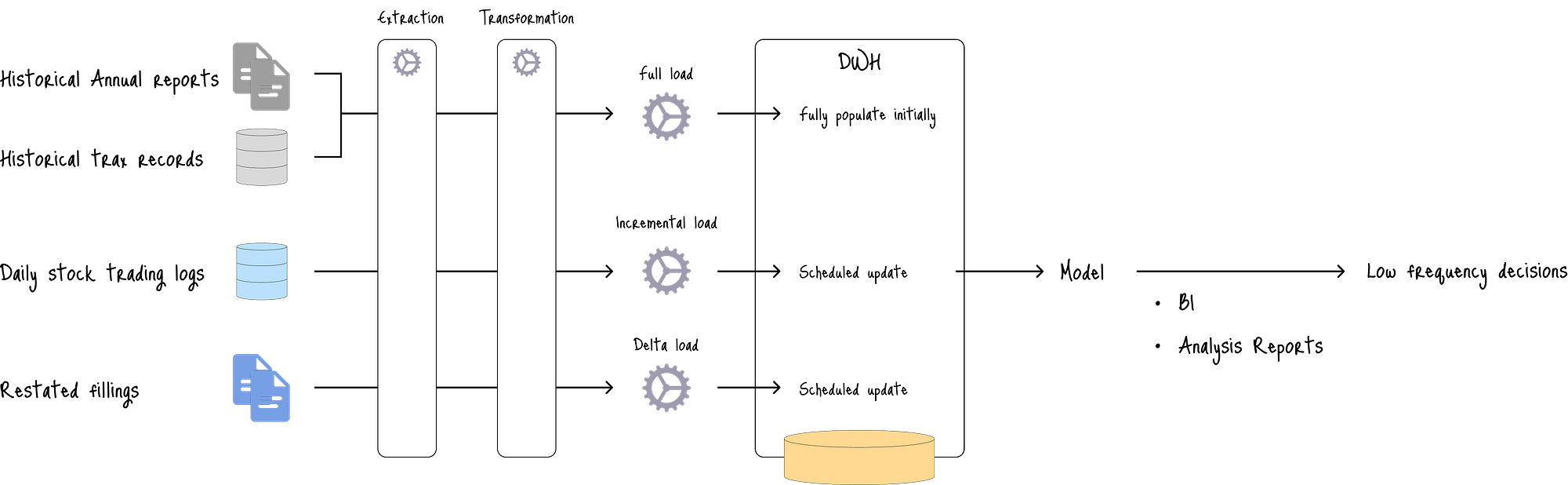
在图中,该架构首先用数十年的历史数据填充数据仓库。
然后,每日股票交易量通过计划的批处理过程(例如,每日或每周)增量加载。
当财务记录调整时,批处理过程还会执行增量更新以更新数据仓库。
然后,结构化数据用于训练模型,该模型为低频决策提供预测服务。
这种结构不适合实时股票预测,因为计划的批处理过程会在数据和预测之间产生延迟。
2.2 添加暂存区
一种高级方法是利用暂存区在通过SQL查询转换之前存储提取的数据:
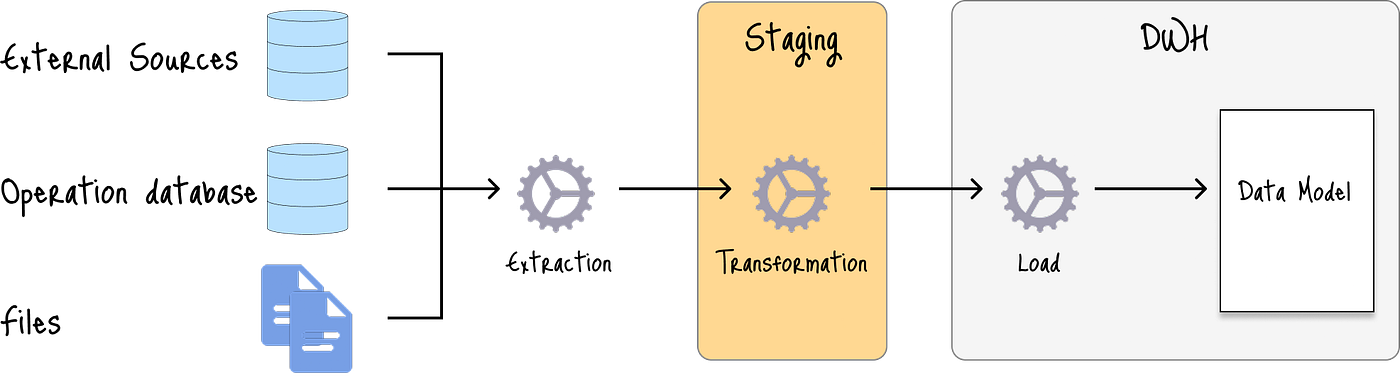
主要区别在于转换过程的隔离和效率。
如果没有暂存区,转换将直接在源系统或目标数据仓库中完成。这可能效率低下且存在风险:
- 源系统过载:复杂转换会减慢系统速度,影响核心业务操作。
- 数据仓库瓶颈:减慢查询和报告速度,消耗数据仓库的计算资源。
暂存区可以通过将原始数据加载到临时存储空间(如专用的S3存储桶)来将繁重的转换过程从数据仓库或源系统卸载。
然后,一个单独的处理引擎(如Apache Spark)运行转换,而不会影响源系统或数据仓库。
尽管这增加了操作复杂性,但其他优点包括:
- 错误处理:即使转换失败,数据仓库中的原始数据也不会受到影响。只需在暂存区中重新运行转换即可。
- 数据质量控制:通过在暂存区中向转换添加多步骤(如清洗、特征工程和预处理),确保只有高质量的数据加载到数据仓库中。
3 云原生数据湖
第二种组合是云原生数据湖架构。
这种架构灵活且经济高效,非常适合处理大量多样化数据,包括非结构化数据。
主要有三种方法:
- 标准ELT(提取、加载、转换)
- 推送ELT
- EtLT(提取、轻量转换、加载和转换)
3.1 标准ELT方法
标准方法利用ELT处理:
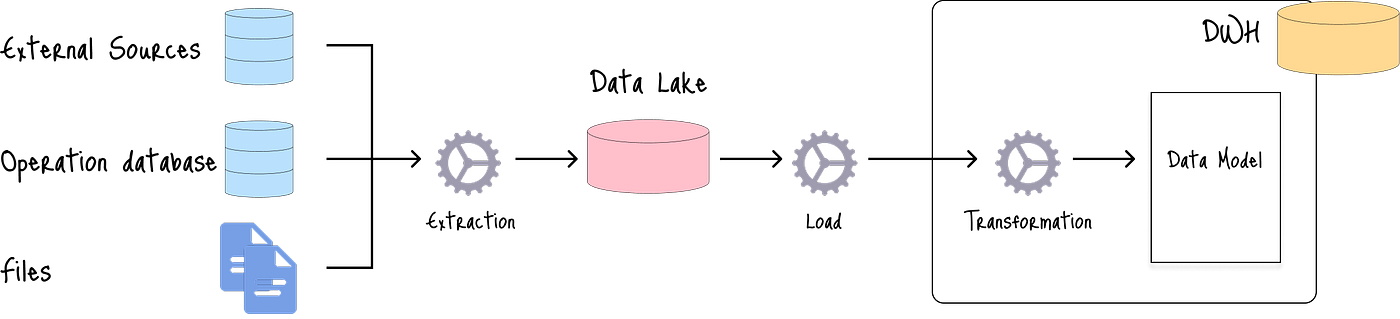
首先,原始数据被提取到数据湖中,然后加载并转换以存储在数据仓库中。
3.2 推送ELT方法
数据摄取到数据湖的另一种方法是推送(Push)方法,其中外部源直接将数据提取到数据湖:
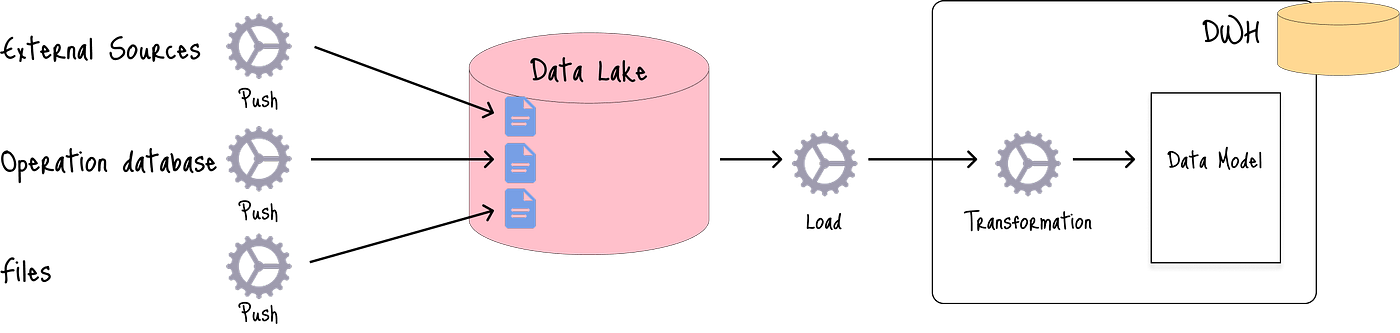
这种方法可能导致对数据提取的控制有限,在数据丢失或损坏的情况下,需要与负责数据源的团队进行协调。
3.3 ETLT(提取、轻量转换、加载和转换)方法
从源中提取的数据可能包含不应被未经授权的个人访问的机密数据。
EtLT方法包括一个额外的“轻量”转换步骤,其中敏感信息在加载数据到数据湖之前被屏蔽或加密:
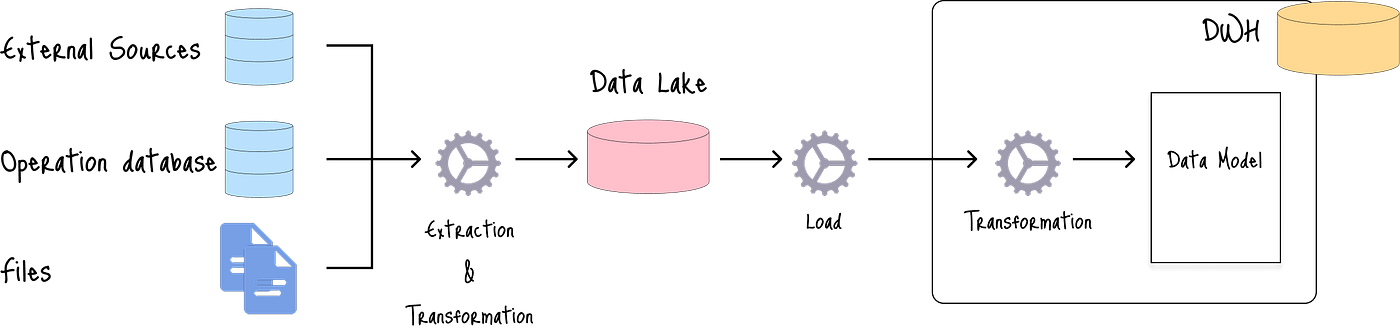
在每种方法中,数据湖和数据仓库的组合适合对存储在数据湖中的原始数据应用不同的分析技术。
每个组件中选择的典型选项是:
- 数据源:数据结构通用,流式
- 摄取:适用于流式,但批处理也可以是一种选择。
- 存储:数据湖 + 数据仓库
- 处理:ELT 或 EtLT
尽管每种方法都增加了管理多个工具的复杂性,但其他优点包括:
- 可扩展性:摄取和转换过程的分离增强了可扩展性和灵活性。
- 可管理性:易于存储、跟踪和审查SQL查询(转换)。
3.4 数据摄取模式
所有方法都可以用于批处理和流式管道。
然而,由于ELT和EtLT先加载后转换的特性,它们非常适合流式数据的实时需求。
但像Lambda和Kappa这样的混合架构旨在无缝结合批处理和流式摄取,以提供全面的数据处理。
让我们来看看。
3.5 Lambda架构
Lambda架构采用双路径方法,其中批处理层遵循ETL过程来转换大型历史数据集,而速度层处理适用于ELT或EtLT方法的实时数据。
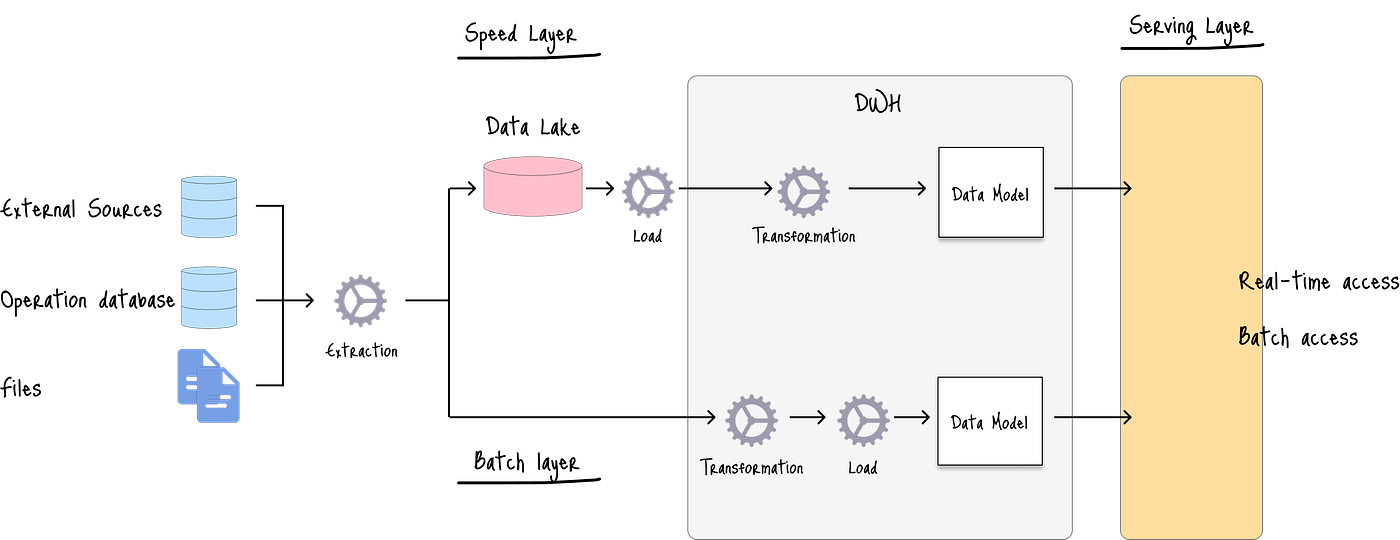
该架构可以根据业务需求提供实时和批处理访问预测。
在前面架构中相同的股票价格预测案例中,Lambda架构可以扩展为通过速度层提供实时预测,而批处理层则提供长期预测。
来自两层的预测被组合并提供给用户,从而提供稳定、长期的展望和波动、实时的预测。
3.6 Kappa架构
Kappa架构通过使用单一、统一的流处理管道来处理实时和历史数据,从而简化了Lambda架构。
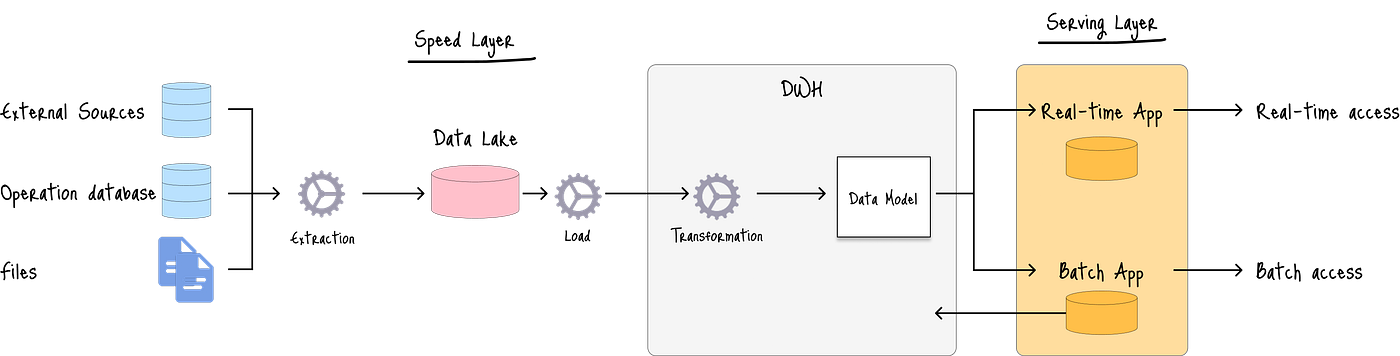
Kappa架构利用ELT模型,其中来自不同源的所有数据都作为流加载,然后由单一处理引擎进行转换。
3.6.1 案例研究 — 股票价格预测
在股票价格预测的相同用例中,当公司优先考虑降低开发复杂性和运营开销,同时提供实时预测和长期预测时,Kappa是最佳选择。
4 现代湖仓一体架构
最后一种组合是湖仓一体架构。
湖仓一体架构旨在结合数据仓库和数据湖的最佳特性,创建一个统一的平台,可以处理结构化和非结构化数据:
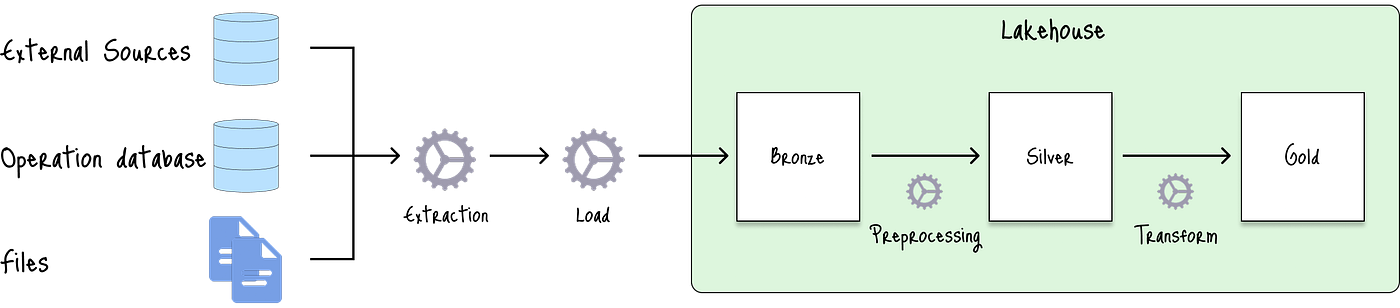
组件选项包括:
- 数据源:通用(适用于结构和数据流)
- 摄取:批处理、流式
- 存储:湖仓一体
- 处理:ELT(提取、加载、转换)
在湖仓一体架构中,**青铜层(Bronze Layer)**作为数据湖,用于摄取来自外部源的原始数据。
然后,**白银层(Silver Layer)**通过清洗和结构化原始数据来处理数据转换。
**黄金层(Gold Layer)**为特定项目构建精选表,执行特征工程以生成未来预测所需的特征。
这种组合在一个简化系统中提供了数据湖的灵活性以及数据仓库的可靠性和性能。
主要优点包括:
- 统一存储:湖仓一体架构可以在一个平台上存储所有类型的数据——结构化、非结构化和半结构化。
- 成本效益:利用S3等低成本、基于云的对象存储。
- 开放性:通过使用Apache Spark、Delta Lake等开源技术和Parquet等开放文件格式,避免供应商锁定。
这种架构涉及实现和数据治理的复杂性。
4.1 案例研究 — 股票价格预测
该架构在一个平台上处理历史数据和实时流。
带有青铜层、白银层和黄金层的奖章结构逐步将原始数据细化为高质量特征。
假设我们有来自三个数据源的原始数据:
- API — 非结构化股票价格
- RSS源 — 非结构化新闻
- 内部数据库 — 结构化财务记录
青铜层:
青铜层作为数据湖,用于存储来自多个数据源的原始数据。
白银层:
然后,白银层清洗和结构化原始数据:
- 运行查询以将所有股票价格与相应的财务记录连接起来,
- 清洗新闻源中杂乱的文本数据,以及
- 提取给定日期范围的新闻文章。
黄金层:
最后,黄金层运行特征工程,例如计算30天移动平均线、波动性指标和从清洗后的新闻数据中获取的市场情绪得分。
这个最终的、高度精炼的数据集用于训练模型。
5 结论
数据管道架构在将原始数据转化为有意义的预测方面发挥着关键作用。
在本文中,我们了解到三种常见架构——传统数据仓库、云原生数据湖和现代湖仓一体架构——各有优缺点。
最佳架构不是一刀切的解决方案,而是根据对数据特性和业务目标的仔细评估而做出的战略选择。