《单链表经典问题全解析:5 大核心题型(移除元素 / 反转 / 找中点 / 合并 / 回文判断)实现与详解》
目录
题目一 : 移除链表元素
1.1 代码结构与变量定义
1.2 核心遍历与筛选逻辑(while 循环)
1.3 处理新链表尾部(避免野指针)
1.4 返回新链表
1.5 完整代码
题目二 : 反转链表
2.1 代码结构与变量定义
2.2 核心反转逻辑(while 循环)
2.3 返回新的头节点
2.4 完整代码
题目三: 回链表的中间结点
3.1 核心思路:快慢指针
3.2 代码逐行解析
3.3 完整代码
题目四: 合并两个有序链表
4.1 核心思路
4.2 代码逐行解析
4.3 完整代码
题目五: 链表的回文结构
5.1 整体逻辑框架
5.2 逐部分代码解析
5.2.1 链表节点定义与辅助函数(反转链表)
5.2.2 主函数:判断回文的核心步骤
5.3 完整代码
题目一 : 移除链表元素
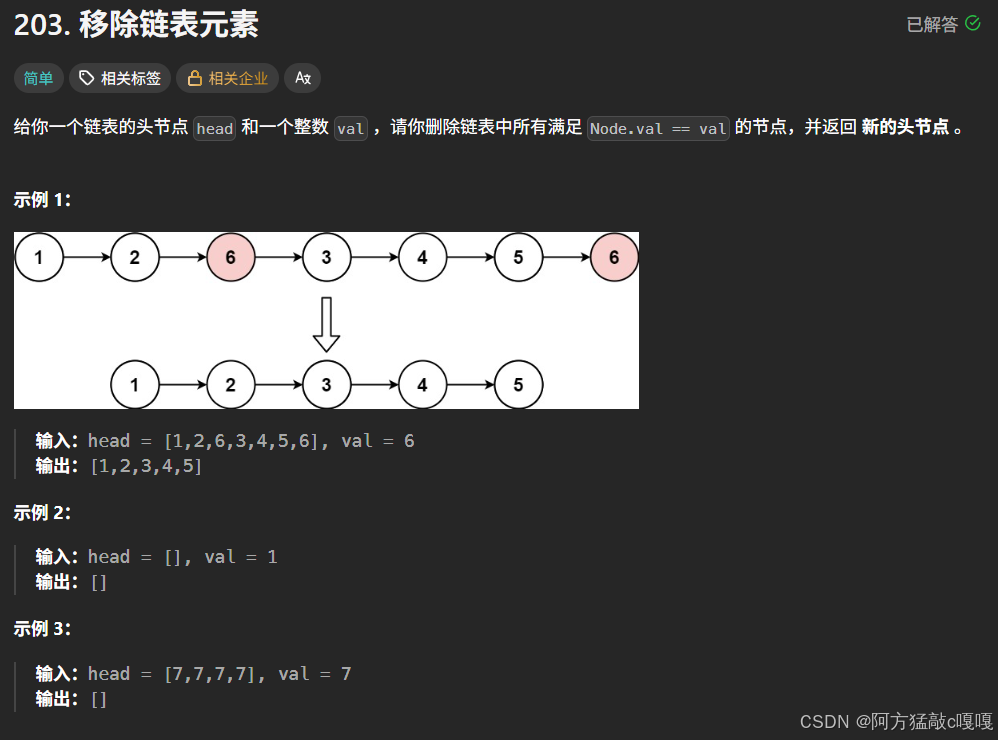
1.1 代码结构与变量定义
// 定义新链表的头指针(phead)和尾指针(ptail)
struct ListNode* phead;
struct ListNode* ptail;
phead = ptail = NULL; // 初始化新链表为空(头、尾均指向NULL)// 定义遍历原链表的指针(pcur),初始指向原链表的头节点
struct ListNode* pcur = head;
phead:新链表的头指针,用于记录最终要返回的新链表起点。ptail:新链表的尾指针,用于快速将有效节点接入新链表尾部(避免每次遍历找尾)。pcur:原链表的遍历指针,从头部开始逐个检查每个节点的值。
1.2 核心遍历与筛选逻辑(while 循环)
while (pcur) { // 等价于 while (pcur != NULL),遍历原链表直到末尾if (pcur->val != val) { // 只处理“值不等于val”的有效节点if (phead == NULL) { // 情况1:新链表为空(第一次接入有效节点)phead = ptail = pcur; // 新链表的头、尾都指向当前有效节点} else { // 情况2:新链表已有节点(后续接入有效节点)ptail->next = pcur; // 1. 将当前有效节点接在新链表尾部ptail = ptail->next; // 2. 尾指针后移,指向新的尾部}}pcur = pcur->next; // 无论当前节点是否有效,都遍历原链表的下一个节点
}
遍历逻辑的核心是 **“只保留有效节点”**:
- 当
pcur->val != val(节点有效):- 若新链表为空(
phead == NULL):说明是第一个有效节点,新链表的头和尾都指向这个节点(新链表从无到有)。 - 若新链表非空:通过
ptail->next = pcur将有效节点接入新链表尾部,再让ptail后移到新尾部(保证下次接入仍能直接找尾)。
- 若新链表为空(
- 当
pcur->val == val(节点无效):直接跳过,不做任何操作(相当于 “删除” 该节点)。 - 每次循环末尾
pcur = pcur->next:确保遍历能覆盖原链表的所有节点,直到pcur变为NULL(遍历结束)。
1.3 处理新链表尾部(避免野指针)
if (ptail) // 若新链表非空(ptail != NULL)ptail->next = NULL; // 将新链表的尾部节点的next置为NULL
这是一个关键的边界处理:
- 原链表中最后一个有效节点的
next可能指向一个 “无效节点”(值为val的节点)或NULL。 - 若不手动将
ptail->next置为NULL,新链表的尾部会残留原链表的指针,可能导致后续访问时出现 “野指针” 或 “链表遍历无法终止” 的问题。 - 例如:原链表为
1→2→3→4(删除val=3),最后一个有效节点是2,其next原本指向3(无效节点),必须将2->next改为NULL,否则新链表会变成1→2→3→4(未真正截断无效节点)。
1.4 返回新链表
return phead;
- 若原链表中所有节点都无效(或原链表为空),
phead始终为NULL,返回NULL(符合预期)。 - 若存在有效节点,
phead指向新链表的第一个有效节点,返回后即可访问完整的新链表。
1.5 完整代码
// 定义新链表的头指针(phead)和尾指针(ptail)
struct ListNode* phead;
struct ListNode* ptail;
phead = ptail = NULL; // 初始化新链表为空(头、尾均指向NULL)// 定义遍历原链表的指针(pcur),初始指向原链表的头节点
struct ListNode* pcur = head;
while (pcur) { // 等价于 while (pcur != NULL),遍历原链表直到末尾if (pcur->val != val) { // 只处理“值不等于val”的有效节点if (phead == NULL) { // 情况1:新链表为空(第一次接入有效节点)phead = ptail = pcur; // 新链表的头、尾都指向当前有效节点} else { // 情况2:新链表已有节点(后续接入有效节点)ptail->next = pcur; // 1. 将当前有效节点接在新链表尾部ptail = ptail->next; // 2. 尾指针后移,指向新的尾部}}pcur = pcur->next; // 无论当前节点是否有效,都遍历原链表的下一个节点
}
if (ptail) // 若新链表非空(ptail != NULL)ptail->next = NULL; // 将新链表的尾部节点的next置为NULL
return phead;题目二 : 反转链表
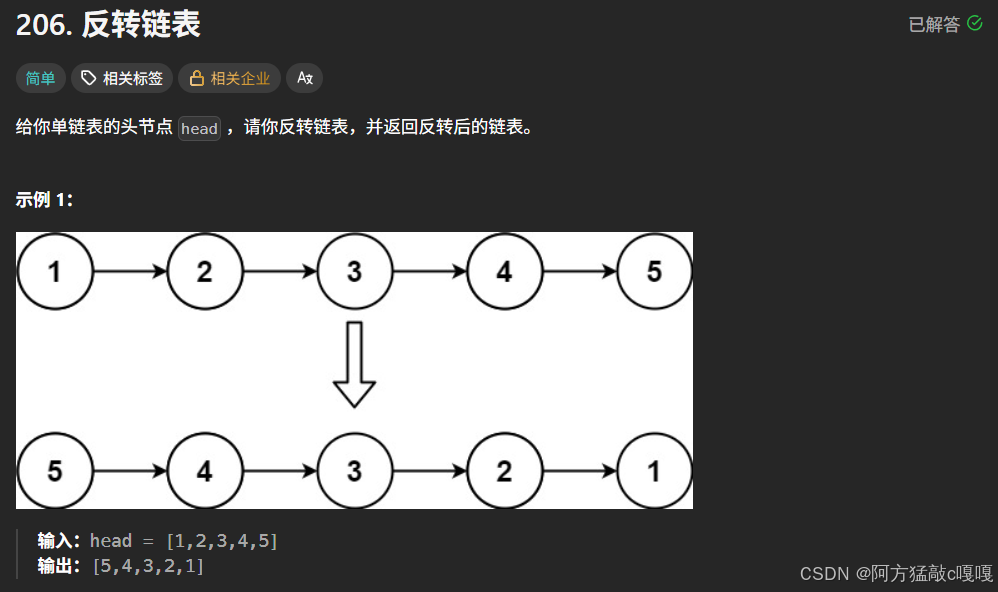
2.1 代码结构与变量定义
// 处理空链表情况:若链表为空,直接返回NULL
if (head == NULL)return head;// 定义三个指针,用于反转操作
struct ListNode *n1, *n2, *n3;
n1 = NULL; // 初始指向NULL(反转后链表的前驱节点,初始为原链表头节点的前一个位置)
n2 = head; // 初始指向原链表的头节点(当前需要反转的节点)
n3 = head->next; // 初始指向原链表的第二个节点(保存当前节点的下一个节点,避免反转后丢失)
n1:始终指向n2的 “前一个节点”(反转后n2->next要指向的位置)。n2:当前正在处理的节点(需要将其next指针反转指向n1)。n3:提前保存n2的下一个节点(因为n2->next会被修改为n1,若不提前保存会丢失后续节点)。
2.2 核心反转逻辑(while 循环)
while (n2) { // 当n2不为NULL时,继续处理(直到遍历完所有节点)n2->next = n1; // 1. 反转n2的指向:让当前节点指向它的前一个节点n1// 2. 三个指针依次后移,准备处理下一个节点n1 = n2; // n1移动到当前节点n2的位置n2 = n3; // n2移动到原下一个节点n3的位置// 3. 若n3不为NULL,n3继续后移;若n3为NULL(已到原链表末尾),则保持NULLif (n3)n3 = n3->next;
}
循环的核心是 **“反转指向→指针后移”** 的重复操作,每一轮循环处理一个节点的反转:
- 反转指向:
n2->next = n1是实现反转的关键,让当前节点n2从原本指向后一个节点,改为指向前一个节点n1。 - 指针后移:
n1、n2、n3依次向后移动一个位置,确保下一轮能处理下一个节点。 - 边界处理:
if (n3)确保当n3为NULL时(即n2是原链表最后一个节点),不会执行n3->next(避免空指针异常)。
2.3 返回新的头节点
return n1; // 循环结束后,n1指向原链表的最后一个节点,即反转后新链表的头节点
- 当循环结束时,
n2已变为NULL(遍历完所有节点),而n1恰好指向原链表的最后一个节点 —— 这个节点就是反转后新链表的第一个节点(头节点)。
2.4 完整代码
struct ListNode* reverseList(struct ListNode* head) {if (head == NULL)return head;struct ListNode *n1, *n2, *n3;n1 = NULL;n2 = head;n3 = head->next;while (n2) {n2->next = n1;n1 = n2;n2 = n3;if (n3)n3 = n3->next;}return n1;
}题目三: 回链表的中间结点
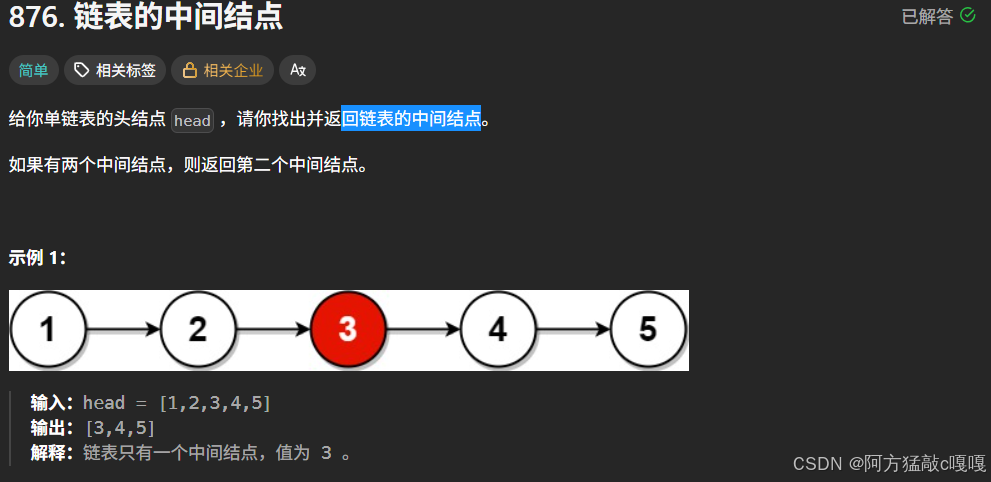
3.1 核心思路:快慢指针
快慢指针法的关键是让两个指针以不同速度遍历链表:
- 慢指针(slow):每次移动 1 个节点
- 快指针(fast):每次移动 2 个节点
当快指针到达链表末尾时,慢指针恰好指向链表的中间节点。
3.2 代码逐行解析
-
初始化指针
struct ListNode* slow, *fast; slow = head; // 慢指针从头部开始 fast = head; // 快指针从头部开始快慢指针同时从链表头部出发,确保起点一致。
-
遍历链表(核心逻辑)
while (fast->next != NULL && fast->next->next != NULL) {slow = slow->next; // 慢指针走1步fast = fast->next->next; // 快指针走2步 }循环条件保证:
-
fast->next != NULL:快指针不会因下一步走 1 步而越界 -
fast->next->next != NULL:快指针不会因下一步走 2 步而越界
当循环结束时,快指针已接近链表末尾,慢指针位置与链表长度有关。
-
-
判断并返回中间节点
if (fast->next == NULL)return slow; // 链表长度为奇数时 elsereturn slow->next; // 链表长度为偶数时-
若
fast->next == NULL:说明快指针已到最后一个节点,链表长度为奇数,慢指针恰好指向正中间节点。 -
若
fast->next != NULL:说明快指针到倒数第二个节点,链表长度为偶数,返回中间两个节点中的后一个(符合题目常见要求)。
-
3.3 完整代码
struct ListNode* middleNode(struct ListNode* head) {struct ListNode* slow,*fast;slow=head;fast=head;while(fast->next!=NULL&&fast->next->next!=NULL){
slow=slow->next;
fast=fast->next->next;}if(fast->next==NULL)return slow;elsereturn slow->next;
}题目四: 合并两个有序链表
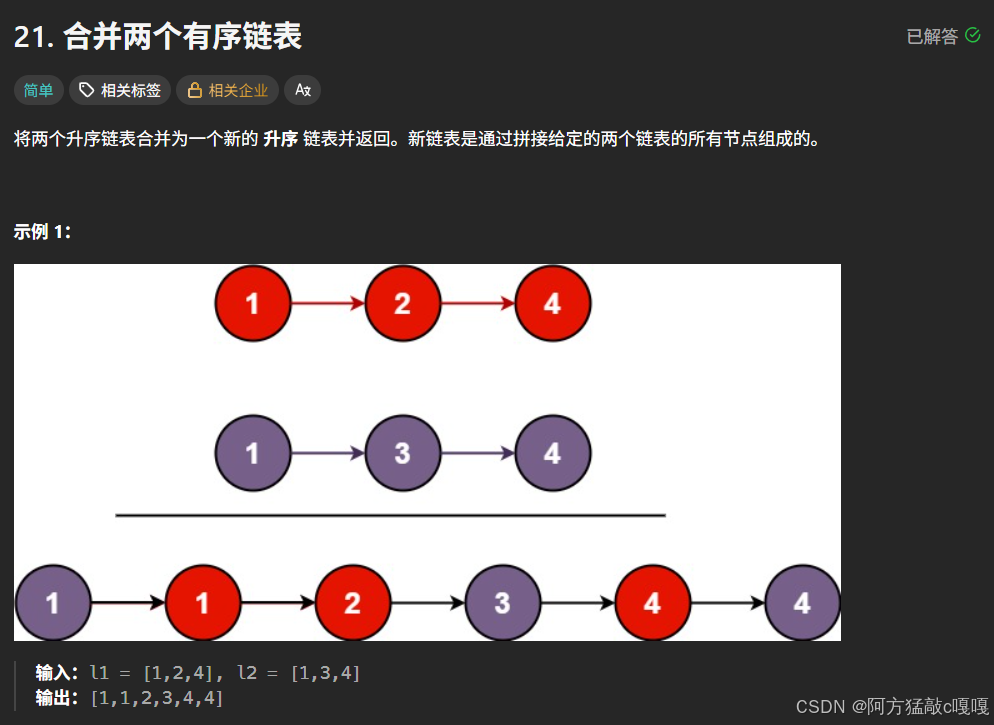
4.1 核心思路
合并两个有序链表的关键是:通过比较两个链表当前节点的值,逐个选择较小的节点接入新链表,最终形成一个整体有序的新链表。代码使用虚拟头节点简化了新链表的初始化和头节点处理。
4.2 代码逐行解析
-
处理空链表边界情况
if (list1 == NULL)return list2; // 若list1为空,直接返回list2 if (list2 == NULL)return list1; // 若list2为空,直接返回list1提前处理任一链表为空的情况,避免后续无效操作。
-
初始化指针与虚拟头节点
struct ListNode *n1, *n2; n1 = list1; // 遍历list1的指针 n2 = list2; // 遍历list2的指针struct ListNode* newhead; struct ListNode* newtail; // 创建虚拟头节点(不存储实际数据,仅用于简化逻辑) newhead = newtail = (struct ListNode*)malloc(sizeof(struct ListNode));-
n1和n2分别作为两个原链表的遍历指针。 -
newhead和newtail用于构建新链表,newhead是虚拟头节点(后续会释放),newtail始终指向新链表的尾部,方便接入新节点。
-
-
合并核心逻辑(遍历比较)
while (n1 != NULL && n2 != NULL) { // 同时遍历两个链表,直到其中一个结束if (n1->val > n2->val) { // 若n1的值更大,选择n2节点接入新链表newtail->next = n2; // 尾部接入n2newtail = newtail->next; // 尾指针后移n2 = n2->next; // n2指针后移,继续遍历list2} else { // 否则选择n1节点接入新链表newtail->next = n1; // 尾部接入n1newtail = newtail->next; // 尾指针后移n1 = n1->next; // n1指针后移,继续遍历list1} }循环中通过比较
n1->val和n2->val,始终将值较小的节点接入新链表尾部,并移动对应指针,保证新链表的有序性。 -
处理剩余节点
if (n1) { // 若list1还有剩余节点newtail->next = n1; // 直接接入新链表尾部 } if (n2) { // 若list2还有剩余节点newtail->next = n2; // 直接接入新链表尾部 }当其中一个链表遍历结束后,另一个链表的剩余节点(已有序)可直接整体接入新链表尾部。
-
释放虚拟头节点并返回结果
struct ListNode* pp = newhead->next; // 虚拟头节点的下一个才是新链表的真实头 free(newhead); // 释放虚拟头节点,避免内存泄漏 return pp; // 返回合并后的新链表头虚拟头节点完成使命后释放,返回真实的新链表头节点。
4.3 完整代码
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {if (list1 == NULL)return list2;if (list2 == NULL)return list1;struct ListNode *n1, *n2;n1 = list1;n2 = list2;struct ListNode* newhead;struct ListNode* newtail;newhead = newtail = (struct ListNode*)malloc(sizeof(struct ListNode));while (n1 != NULL && n2 != NULL) {if (n1->val > n2->val) {newtail->next = n2;newtail = newtail->next;n2 = n2->next;} else {newtail->next = n1;newtail = newtail->next;n1 = n1->next;}}if (n1) {newtail->next = n1;}if (n2) {newtail->next = n2;}struct ListNode* pp=newhead->next;free(newhead);return pp;
}题目五: 链表的回文结构
5.1 整体逻辑框架
回文结构的核心特征是 “正读与反读内容一致”(如链表 1→2→2→1)。由于链表无法像数组一样直接 “倒着读”,代码通过三步巧妙实现判断:
- 找中点:用快慢指针定位链表中间节点,将链表分为前后两段;
- 反转后半段:将后半段链表反转,使其 “倒序”,方便与前半段正序对比;
- 对比两段:用两个指针分别遍历前半段和反转后的后半段,逐节点比较值是否一致;
- 恢复链表(可选):若需保持原链表结构,将反转的后半段恢复原状(不影响判断结果)。
5.2 逐部分代码解析
5.2.1 链表节点定义与辅助函数(反转链表)
// 链表节点定义:每个节点包含值和指向下一节点的指针
struct ListNode {int val;struct ListNode *next;
};// 辅助函数:反转链表(原地反转,空间O(1))
struct ListNode* reverseList(struct ListNode* head) {struct ListNode *prev = NULL, *curr = head, *next = NULL;while (curr != NULL) {next = curr->next; // 1. 保存curr的下一个节点(避免反转后丢失)curr->next = prev; // 2. 反转curr的指向:从指向next改为指向prevprev = curr; // 3. prev后移到curr(为下一轮反转做准备)curr = next; // 4. curr后移到保存的next(继续遍历)}return prev; // 反转后,prev是新的头节点(原链表的尾节点)
}
-
反转链表是核心辅助操作,例如将
2→1反转为1→2,为后续 “正序对比” 提供条件。
5.2.2 主函数:判断回文的核心步骤
步骤 1:处理边界情况(空链表 / 单节点)
if (A == NULL || A->next == NULL) {return true;
}
-
空链表(无节点)或单节点链表(只有一个值),本身就是回文结构,直接返回
true。
步骤 2:快慢指针找中间节点
struct ListNode *slow = A, *fast = A;
while (fast->next != NULL && fast->next->next != NULL) {slow = slow->next; // 慢指针:每次走1步fast = fast->next->next; // 快指针:每次走2步
}
-
原理:快指针速度是慢指针的 2 倍,当快指针到达链表末尾时,慢指针恰好停在中间位置。
-
两种情况:
-
若链表长度为奇数(如
1→2→3→2→1):fast 最终指向最后一个节点(fast->next=NULL),slow 指向正中间节点(3); -
若链表长度为偶数(如
1→2→2→1):fast 最终指向倒数第二个节点(fast->next->next=NULL),slow 指向前半段的末尾节点(第一个2)。
-
-
最终目的:将链表分为 “前半段(A 到 slow)” 和 “后半段(slow->next 到末尾)”。
步骤 3:反转后半段链表
struct ListNode* secondHalf = reverseList(slow->next);
-
从
slow->next开始反转后半段(避免包含中间节点,确保两段长度一致):-
例 1(奇数长度
1→2→3→2→1):后半段是2→1,反转后为1→2; -
例 2(偶数长度
1→2→2→1):后半段是2→1,反转后为1→2。
-
步骤 4:对比前半段与反转后的后半段
struct ListNode* p1 = A; // p1:遍历前半段(从表头开始)
struct ListNode* p2 = secondHalf; // p2:遍历反转后的后半段(从反转后的表头开始)
bool result = true; // 初始假设是回文,发现不相等再改为falsewhile (result && p2 != NULL) { // p2遍历完(后半段结束)则对比结束if (p1->val != p2->val) { // 发现对应节点值不相等,不是回文result = false;}p1 = p1->next; // p1后移(前半段继续)p2 = p2->next; // p2后移(后半段继续)
}
-
对比逻辑:前半段正序遍历,后半段(反转后)也正序遍历,若所有对应节点值相等,则是回文;
-
为什么用 p2 判断结束:后半段长度 ≤ 前半段长度(奇数时后半段短 1 个节点),p2 遍历完则对比完成,无需再遍历 p1。
步骤 5:恢复链表(可选,不影响判断结果)
slow->next = reverseList(secondHalf);
-
若业务需要保持原链表结构,将反转后的后半段再次反转,恢复为原始顺序(如
1→2转回2→1); -
若无需恢复,可删除此步骤(不影响回文判断的正确性)。
步骤 6:返回结果
return result;
-
若所有节点对比一致,返回
true(是回文);否则返回false(不是回文)。
5.3 完整代码
#include <stdbool.h>
#include <stdlib.h>// 链表节点定义
struct ListNode {int val;struct ListNode *next;
};// 辅助函数:反转链表
struct ListNode* reverseList(struct ListNode* head) {struct ListNode *prev = NULL, *curr = head, *next = NULL;while (curr != NULL) {next = curr->next; // 保存下一个节点curr->next = prev; // 反转当前节点的指向prev = curr; // 移动prev指针curr = next; // 移动curr指针}return prev; // 返回反转后的头节点
}// 主函数:判断链表是否为回文结构
bool isPalindrome(struct ListNode* A) {// 空链表或单节点链表都是回文if (A == NULL || A->next == NULL) {return true;}// 步骤1:找到链表的中间节点(使用快慢指针)struct ListNode *slow = A, *fast = A;while (fast->next != NULL && fast->next->next != NULL) {slow = slow->next; // 慢指针走1步fast = fast->next->next; // 快指针走2步}// 此时slow指向中间节点(奇数长度)或前半部分末尾(偶数长度)// 步骤2:反转后半部分链表struct ListNode* secondHalf = reverseList(slow->next);// 步骤3:对比前半部分和反转后的后半部分struct ListNode* p1 = A; // 前半部分指针struct ListNode* p2 = secondHalf; // 后半部分指针bool result = true;while (result && p2 != NULL) {if (p1->val != p2->val) { // 发现值不相等,不是回文result = false;}p1 = p1->next; // 移动前半部分指针p2 = p2->next; // 移动后半部分指针}// 步骤4:恢复链表(可选,根据需求决定是否恢复)slow->next = reverseList(secondHalf);return result;
}