pytorch可视化工具(训练评估:Tensorboard、swanlab)
pytorch可视化工具
- 1、Tensorboard
- 1. 教程
- 2.标签页 (页面布局)
- 3. DataFrame 访问 TensorBoard 数据
- 4. add_scalars
- 不支持日期
- 5. add_figure
- 2、swanlab可视化工具 (类似Tensorboard)
- 3、现成的AI模型训练+评估框架
- 1. PyTorch Lightning + TensorBoard + ModelCheckpoint + EarlyStopping
- 核心代码示例:
- 2. TensorFlow / Keras + TensorBoard + ModelCheckpoint + EarlyStopping
- 3. Stable Baselines3 (强化学习)
- 4. Huggingface Trainer(NLP)
- 5. 结合Weights & Biases(W\&B)
- 总结推荐
1、Tensorboard
1. 教程
官方:
https://github.com/tensorflow/tensorboard
https://tensorflowcn.cn/tensorboard
https://pytorch.ac.cn/tutorials/intermediate/tensorboard_tutorial.html
https://pytorch.ac.cn/tutorials/beginner/introyt/tensorboardyt_tutorial.html
https://pytorch.ac.cn/docs/stable/tensorboard.html
推荐看下面两个:
https://pytorch.ac.cn/tutorials/intermediate/tensorboard_tutorial.html
https://pytorch.ac.cn/tutorials/beginner/introyt/tensorboardyt_tutorial.html
https://docs.pytorch.ac.cn/docs/stable/tensorboard.html
使用 TensorBoard 可视化模型、数据和训练:
PyTorch 集成了 TensorBoard,这是一个专门用于可视化神经网络训练结果的工具。本教程将介绍 TensorBoard 的一些功能,使用 Fashion-MNIST 数据集,该数据集可以使用 torchvision.datasets 加载到 PyTorch 中。
- 支持的摘要作包括:
tf.summary.scalar
tf.summary.image
tf.summary.audio
tf.summary.text
tf.summary.histogram
SB3示例:
https://stable-baselines3.readthedocs.io/en/master/guide/tensorboard.html#tensorboard
您可以使用以下 bash 命令在训练期间或之后监控 RL 代理:
tensorboard --logdir ./a2c_cartpole_tensorboard/您还可以添加过去的日志记录文件夹:
tensorboard --logdir ./a2c_cartpole_tensorboard/;./ppo2_cartpole_tensorboard/# 用不了
# tensorboard --logdir ./tb_log/a2c_cartpole_tensorboard/;./tb_log/ppo/
# 可以,放在同个目录
# tensorboard --logdir ./tb_log2.标签页 (页面布局)
官方:https://github.com/tensorflow/tensorboard
https://blog.csdn.net/x1664/article/details/142186422
https://zhuanlan.zhihu.com/p/115802478
https://zhuanlan.zhihu.com/p/471198169
pytorch API文档:https://pytorch.ac.cn/docs/stable/tensorboard.html
-
标签页对应的函数
自 1.14 版本起,仅支持以下插件:标量、自定义标量、图像、音频、图表、投影仪(部分)、分布、直方图、文本、PR 曲线、网格。此外,不支持 Google Cloud Storage 上的日志目录。https://github.com/tensorflow/tensorboard
(only the following plugins are supported: scalars, custom scalars, image, audio, graph, projector (partial), distributions, histograms, text, PR curves, mesh. In addition, there is no support for log directories on Google Cloud Storage.)- 标签页对应的函数
-
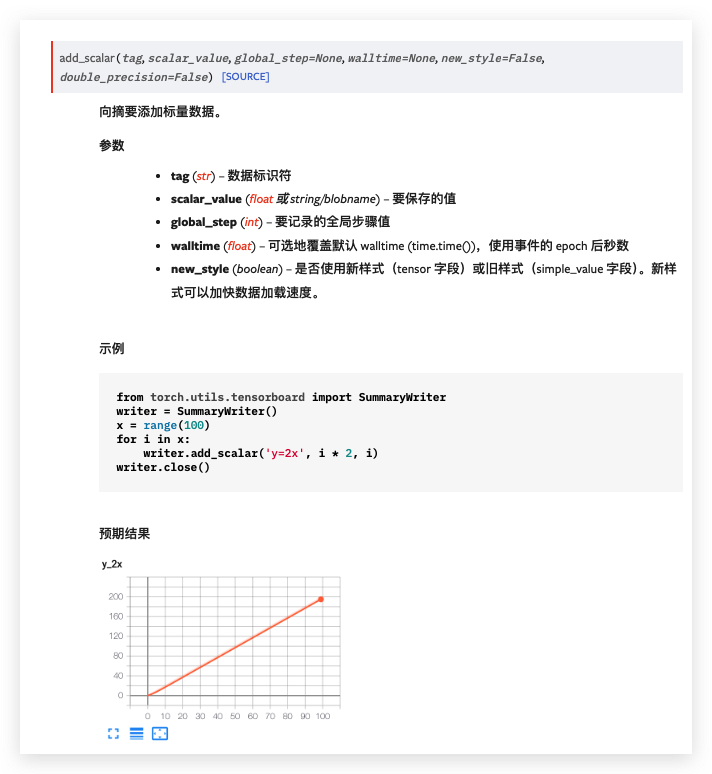
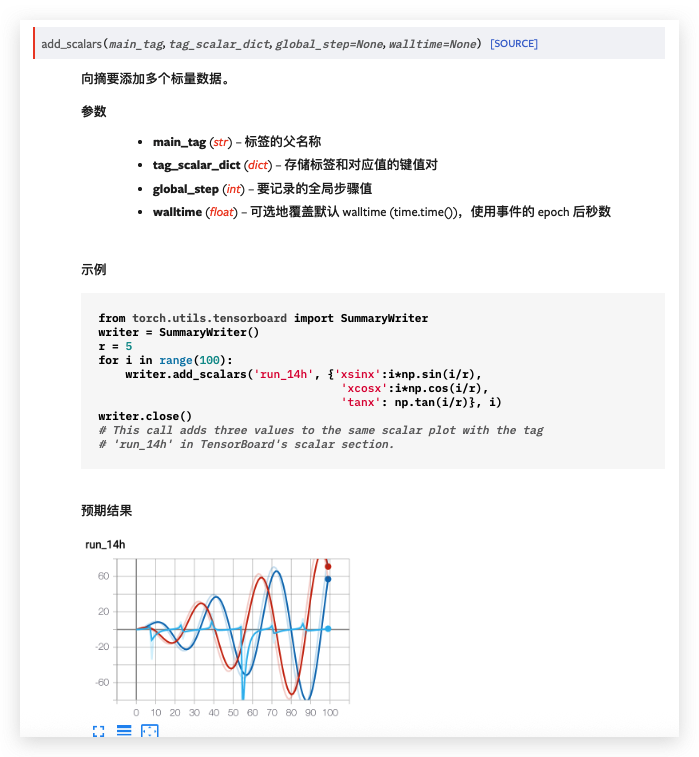
add_scalars
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
功能:在一个坐标轴中绘制多条曲线。常用于曲线对比。 -
add_figure
add_figure(tag, figure, global_step=None, close=True, walltime=None)
功能:将matplotlib的figure绘制到tensorboard中。 -
add_image
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats=‘CHW’)
功能:绘制图像。 -
add_images
add_images(tag, img_tensor, global_step=None, walltime=None, dataformats=‘NCHW’)
功能:绘制图像序列,常用于数据清洗,卷积核,特征图的可视化。 -
add_histogram
add_histogram(tag, values, global_step=None, bins=‘tensorflow’, walltime=None, max_bins=None)
功能:绘制直方图。这里的global_step表明会得到多个直方图,详情请看图理解。 -
add_video:绘制视频
add_audio:绘制音频,可进行音频播放。
add_text:绘制文本
add_graph:绘制pytorch模型拓扑结构图。
add_embedding:绘制高维数据在低维的投影
add_pr_curve:绘制PR曲线,二分类任务中很实用。
add_mesh:绘制网格、3D点云图。
add_hparams:记录超参数组,可用于记录本次曲线所对应的超参数。
-
- 标签页对应的函数
-
示例:scalars 和 Images标签页
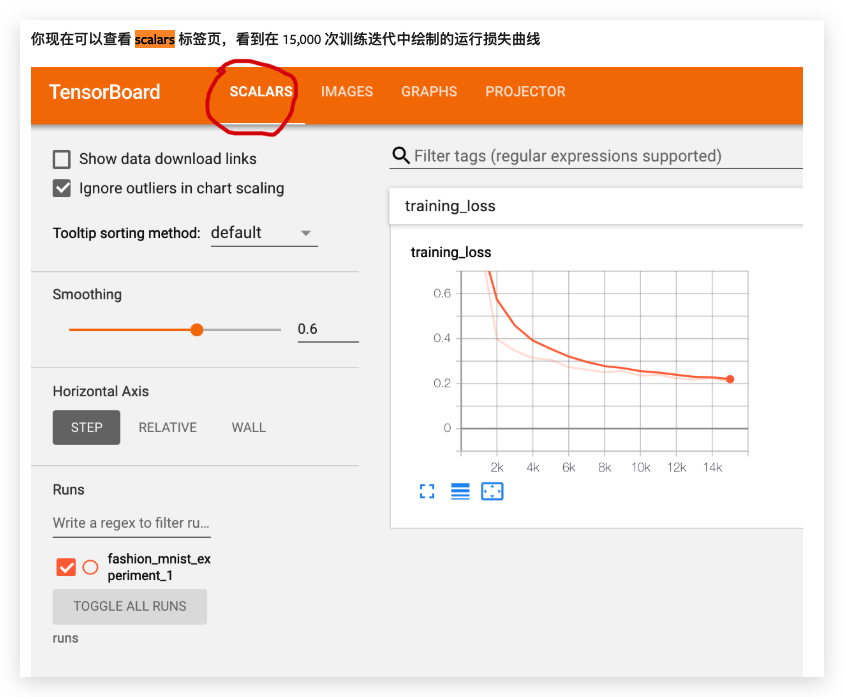
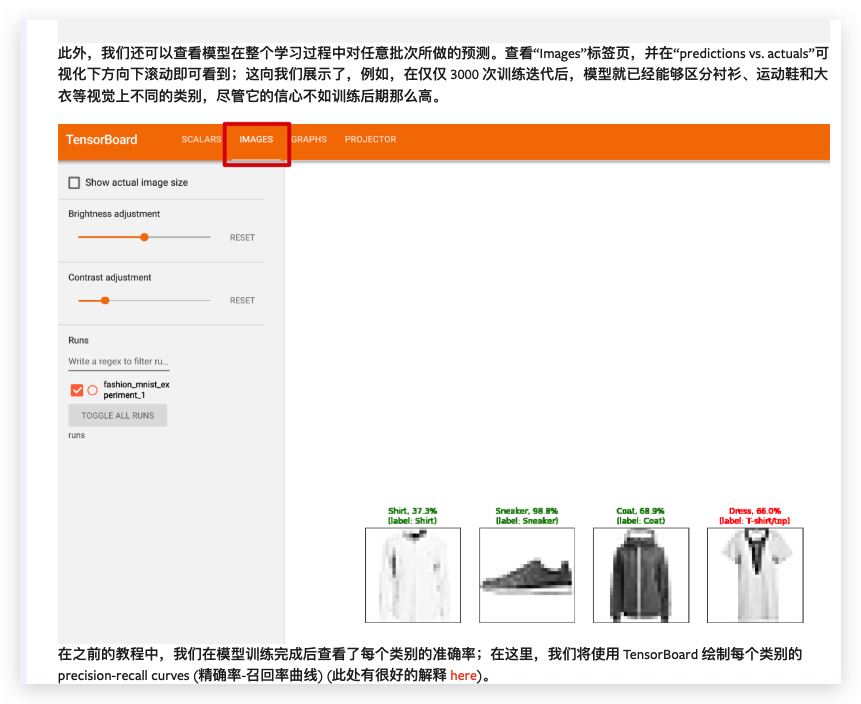
你现在可以查看scalars 标签页,看到在 15,000 次训练迭代中绘制的运行损失曲线,此外,我们还可以查看模型在整个学习过程中对任意批次所做的预测。查看“Images”标签页,并在“predictions vs. actuals”可视化下方向下滚动即可看到;这向我们展示了,例如,在仅仅 3000 次训练迭代后,模型就已经能够区分衬衫、运动鞋和大衣等视觉上不同的类别,尽管它的信心不如训练后期那么高。参考:https://pytorch.ac.cn/tutorials/intermediate/tensorboard_tutorial.html
-
整个页面布局:
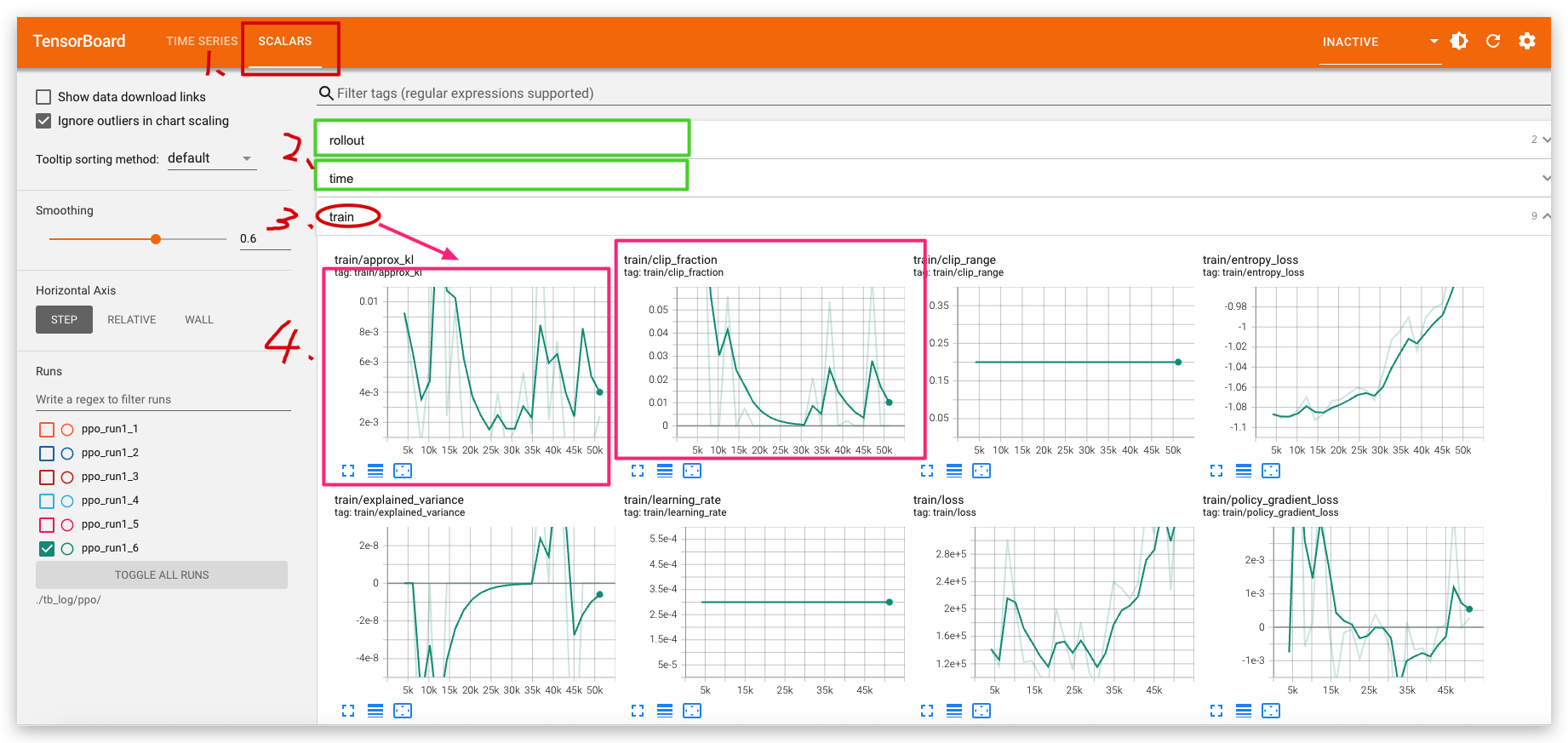
对本例中创建的可视化内容以及可找到它们的仪表盘(顶部导航栏中的选项卡)的简要概述:
参考:https://github.com/tensorflow/tensorboard/blob/master/docs/get_started.ipynb
- 标量(Scalars):展示损失和指标在每个轮次(epoch)的变化情况。你也可借助它们追踪训练速度、学习率以及其他标量值。标量可在“时间序列(Time Series)”或“标量(Scalars)”仪表盘找到。
- 图形(Graphs):助你可视化模型。此处展示的是Keras层图形,能帮你确认模型构建正确。图形可在“图形(Graphs)”仪表盘找到。
- 直方图和分布(Histograms and Distributions):展示张量随时间的分布情况。这对可视化权重和偏置、验证其是否按预期变化很有用。直方图可在“时间序列(Time Series)”或“直方图(Histograms)”仪表盘找到,分布可在“分布(Distributions)”仪表盘找到 。
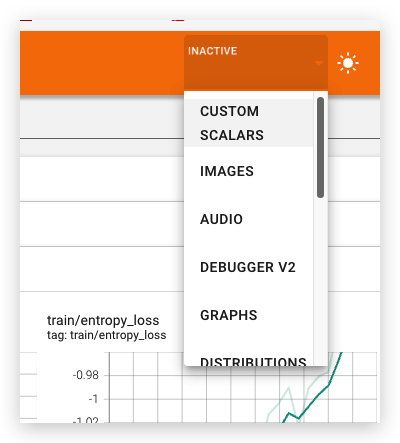
- 当你记录其他类型数据时,其他TensorBoard仪表盘会自动启用。比如,Keras TensorBoard回调还能让你记录图像和嵌入向量。你可点击
右上角的“未激活(inactive)”下拉菜单,查看TensorBoard中还有哪些其他可用仪表盘 。
3. DataFrame 访问 TensorBoard 数据
获取TensorBoard中的数据
https://tensorflow.google.cn/tensorboard/dataframe_api?hl=zh-cn
https://github.com/tensorflow/tensorboard
4. add_scalars
https://pytorch.ac.cn/docs/stable/tensorboard.html
https://pytorch.ac.cn/tutorials/beginner/introyt/tensorboardyt_tutorial.html
pytorch API文档:https://pytorch.ac.cn/docs/stable/tensorboard.html
add_scalars:
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
功能:在一个坐标轴中绘制多条曲线。常用于曲线对比。
然后可以使用 TensorBoard 对其进行可视化,TensorBoard 可以通过以下方式安装和运行
pip install tensorboard
tensorboard --logdir=runs
一个实验可以记录很多信息。为了避免 UI 混乱并更好地对结果进行聚类,我们可以通过分层命名来对图表进行分组。例如,“Loss/train” 和 “Loss/test” 将被分在一组,而 “Accuracy/train” 和 “Accuracy/test” 将在 TensorBoard 界面中单独分组。
from torch.utils.tensorboard import SummaryWriter
import numpy as npwriter = SummaryWriter()for n_iter in range(100):writer.add_scalar('Loss/train', np.random.random(), n_iter)writer.add_scalar('Loss/test', np.random.random(), n_iter)writer.add_scalar('Accuracy/train', np.random.random(), n_iter)writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
目录分开:
from torch.utils.tensorboard import SummaryWriter
import numpy as npimport os
from glob import glob
from torch.utils.tensorboard import SummaryWriterdef get_next_log_dir(base_dir="runs/run"):"""自动获取一个不存在的 log 目录(exp0, exp1, exp2, ...)"""i = 0while os.path.exists(f"{base_dir}_{i}"):i += 1return f"{base_dir}_{i}"log_dir = get_next_log_dir() # e.g., runs/exp3
writer = SummaryWriter(log_dir=log_dir)# writer = SummaryWriter()
# writer = SummaryWriter(log_dir='./runs/test', comment='exp_1')for n_iter in range(100):writer.add_scalar('Loss/train', np.random.random(), n_iter)writer.add_scalar('Loss/test', np.random.random(), n_iter)writer.add_scalar('Accuracy/train', np.random.random(), n_iter)writer.add_scalar('Accuracy/test', np.random.random(), n_iter)writer.close()print(f"TensorBoard logs saved to: {log_dir}")writer = SummaryWriter('runs‘): log_dir (str) – 保存目录位置。默认值为 runs/CURRENT_DATETIME_HOSTNAME,每次运行时都会更改。使用分层文件夹结构可以轻松比较不同运行。例如,对于每个新实验,传入 ‘runs/exp1’、‘runs/exp2’ 等以进行比较。
官方API:
pytorch API文档:https://pytorch.ac.cn/docs/stable/tensorboard.html
不支持日期
要使用 TensorBoard 的 add_scalar 方法,以日期为 x 轴绘制股票数据(如收盘价),需要注意的是:add_scalar 的 x 轴是 step(int 类型),不是直接支持 datetime 类型。但你可以将日期转为 step index,再通过日期的映射在 TensorBoard 中查看。
不过,我们可以保留日期信息作为 tag 或写到日志中,同时通过 Pandas 来把日期转为 step,并使用 add_scalar(tag, scalar_value, global_step) 来记录数据。
✅ 示例代码:使用 SummaryWriter.add_scalar 绘制股票收盘价
假设我们有如下的股票数据(Date, Close):
import pandas as pd
from torch.utils.tensorboard import SummaryWriter# 假设这是你的股票数据
data = pd.DataFrame({'Date': pd.date_range(start='2024-01-01', periods=100),'Close': pd.Series(range(100)) + 100 # 模拟价格
})
data.set_index('Date', inplace=True)# 创建 TensorBoard writer
writer = SummaryWriter(log_dir='runs/stock_prices')# 遍历数据,写入 TensorBoard(step = index)
for i, (date, row) in enumerate(data.iterrows()):writer.add_scalar('Stock/Close', row['Close'], global_step=i)# 可选:将日期写入文本记录writer.add_text('Stock/Date', f'{i}: {date.strftime("%Y-%m-%d")}', global_step=i)writer.close()
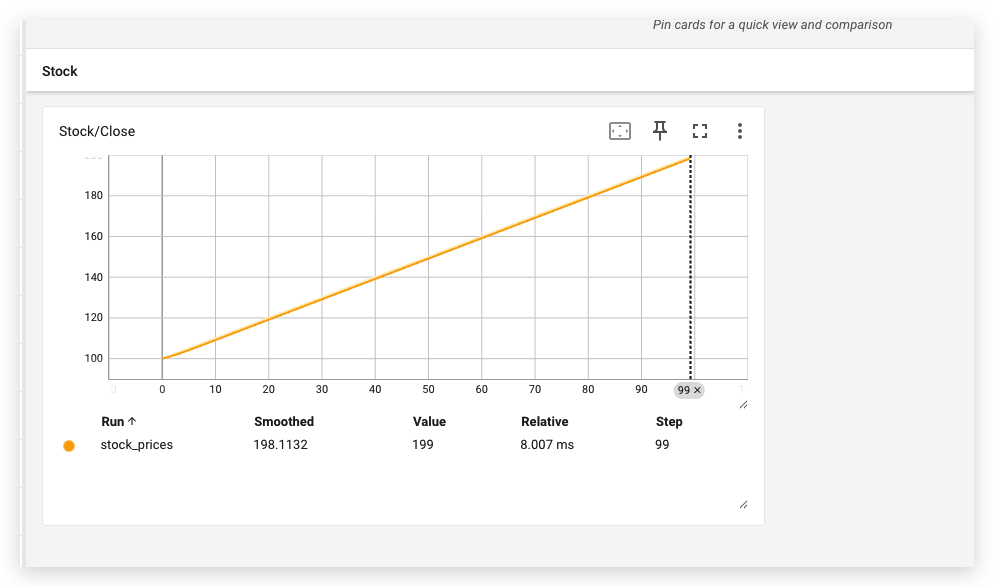
📈 查看日期信息的方式:
由于 TensorBoard 默认 x 轴是 step,你可以:
- 在 TensorBoard 中 hover 鼠标,看到 step 和 Close 值。
- 利用
add_text保存 step 对应的日期,便于你查找。 - 或者把时间戳转为 step 的形式,例如:
step = int(date.timestamp()) # 可行,但粒度太大,图像不连续
通常不推荐直接用时间戳当 step,而是保留顺序索引即可。
🧠 小贴士:用 Matplotlib 画日期更合适
如果你更关心“以日期为 x 轴”的直观可视化,可以考虑用 matplotlib:
import matplotlib.pyplot as pltdata.plot(y='Close', use_index=True)
plt.title('Stock Close Price')
plt.xlabel('Date')
plt.ylabel('Close')
plt.grid(True)
plt.show()
🔁 总结:
| 方法 | 日期为 x 轴? | 优势 | 劣势 |
|---|---|---|---|
add_scalar | ❌(只能用 step) | 可集成训练指标、支持 TensorBoard | x 轴不能显示日期 |
matplotlib | ✅ | 直观显示时间序列 | 不支持 TensorBoard |
add_text 辅助 | ⚠️(辅助展示) | 可以保留 step -> 日期 映射 | 需要手动查 |
如你想“自定义 TensorBoard x 轴为时间”,那就需要使用 TensorBoard.dev 或者对 protobuf logs 自定义写入(较复杂)。
需要我帮你封装一个完整函数或把多个股票一起画?可以继续说。
5. add_figure
add_figure
add_figure(tag, figure, global_step=None, close=True, walltime=None)
功能:将matplotlib的figure绘制到tensorboard中。
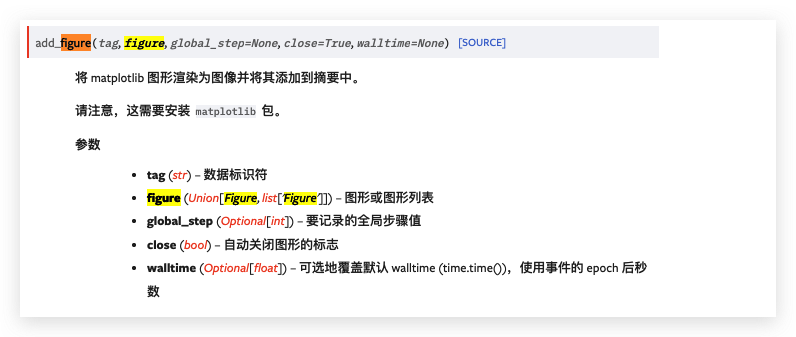
import pandas as pd
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter# 模拟股票数据
data = pd.DataFrame({'Date': pd.date_range(start='2024-01-01', periods=500),'Close': pd.Series(range(500)) + 100,'Volume': pd.Series(range(500)) * 10000
})
data.set_index('Date', inplace=True)# 创建 TensorBoard 写入器
writer = SummaryWriter("runs/stock_with_figure7")# 绘制股票收盘价图
fig, ax = plt.subplots(figsize=(10, 4))
data['Close'].plot(ax=ax)
ax.set_title("Stock Close Price")
ax.set_xlabel("Date")
ax.set_ylabel("Price")
ax.grid(True)
# 添加图像到 TensorBoard
writer.add_figure("Stock/ClosePriceFigure", fig, global_step=0)# 绘制成交量图
fig, ax = plt.subplots(figsize=(10, 4))
data['Volume'].plot(ax=ax) # 用 ax 绘制
ax.set_title("Stock Volume")
ax.set_xlabel("Date")
ax.set_ylabel("Volume")
ax.grid(True)
# 添加图像到 TensorBoard
writer.add_figure("Stock/VolumeFigure", fig, global_step=0)
# writer.add_figure("Stock/VolumeFigure", fig, global_step=1)
# writer.add_figure("Stock/ClosePriceFigure", fig, global_step=1)# 2、*********图像列表*********
import matplotlib.pyplot as pltfigures = []for i in range(3): # 生成3个Figurefig, ax = plt.subplots()ax.plot([1, 2, 3], [x * (i + 1) for x in [1, 2, 3]]) # 简单绘图,数据随i变化ax.set_title(f'Figure {i+1}')figures.append(fig)# 现在 figures 是一个包含3个 Figure 对象的列表
# 记录单个图形
writer.add_figure("Stock_figures/figures", figures, global_step=0)writer.close()2、swanlab可视化工具 (类似Tensorboard)
https://swanlab.cn/
https://docs.swanlab.cn/examples/lstm_stock.html
入门教程:https://docs.swanlab.cn/guide_cloud/general/quick-start.html
SB3示例:https://docs.swanlab.cn/guide_cloud/integration/integration-sb3.html
一些示例:https://docs.swanlab.cn/examples/lstm_stock.html
SwanLab 是一款开源、轻量级的 AI 模型训练跟踪与可视化工具,专为人工智能研究者设计,提供实验跟踪、记录、比较及团队协作功能 。它支持 Cloud / Self-hosted 部署模式,兼具现代化界面设计和高效的数据分析能力,常被称作“中国版 Weights & Biases + Tensorboard” 。
其核心功能包括:
- 训练可视化:实时监控实验指标(如损失、准确率等),并通过看板直观展示 。
- 自动日志记录:自动捕捉超参数、模型版本及训练过程中的关键数据 。
- 实验对比:支持多实验结果的横向对比,便于优化模型性能 。
- 多人协作:团队成员可共享实验记录,基于可视化结果进行远程协作 。
- 私有化部署:提供灵活的本地化部署方案,满足不同团队的安全与定制需求 。
SwanLab 兼容多种 AI 框架,适用于本地开发或云端协作场景,旨在提升 AI 研发效率 。目前其 GitHub 项目已获得超过 1k Star,社区活跃度较高 。
1. 安装SwanLab
使用 pip 在Python3环境的计算机上安装swanlab库。打开命令行,输入:pip install swanlab
按下回车,等待片刻完成安装。如果遇到安装速度慢的问题,可以指定国内源安装:
pip install swanlab -i https://mirrors.cernet.edu.cn/pypi/web/simple2. 登录账号
如果你还没有SwanLab账号,请在 官网 免费注册。打开命令行,输入:swanlab login
当你看到如下提示时:swanlab: Logging into swanlab cloud.
swanlab: You can find your API key at: https://swanlab.cn/settings
swanlab: Paste an API key from your profile and hit enter, or press 'CTRL-C' to quit:
在用户设置页面复制您的 API Key,粘贴后按下回车(你不会看到粘贴后的API Key,请放心这是正常的),即可完成登录。之后无需再次登录。INFO如果你的计算机不太支持swanlab login的登录方式,也可以使用python脚本登录:import swanlab
swanlab.login(api_key="你的API Key", save=True)
3. 开启一个实验并跟踪超参数
在Python脚本中,我们用swanlab.init创建一个SwanLab实验,并向config参数传递将一个包含超参数键值对的字典:import swanlabrun = swanlab.init(# 设置项目project="my-project",# 跟踪超参数与实验元数据config={"learning_rate": 0.01,"epochs": 10,},
)
run是SwanLab的基本组成部分,你将经常使用它来记录与跟踪实验指标。4. 记录实验指标
在Python脚本中,用swanlab.log记录实验指标(比如准确率acc和损失值loss)。用法是将一个包含指标的字典传递给swanlab.log:swanlab.log({"accuracy": acc, "loss": loss})
5. 完整代码,在线查看可视化看板
我们将上面的步骤整合为下面所示的完整代码:import swanlab
import random# 初始化SwanLab
run = swanlab.init(# 设置项目project="my-project",# 跟踪超参数与实验元数据config={"learning_rate": 0.01,"epochs": 10,},
)print(f"学习率为{run.config.learning_rate}")offset = random.random() / 5# 模拟训练过程
for epoch in range(2, run.config.epochs):acc = 1 - 2**-epoch - random.random() / epoch - offsetloss = 2**-epoch + random.random() / epoch + offsetprint(f"epoch={epoch}, accuracy={acc}, loss={loss}")# 记录指标swanlab.log({"accuracy": acc, "loss": loss})运行代码,访问SwanLab,查看在每个训练步骤中,你使用SwanLab记录的指标(准确率和损失值)的改进情况。
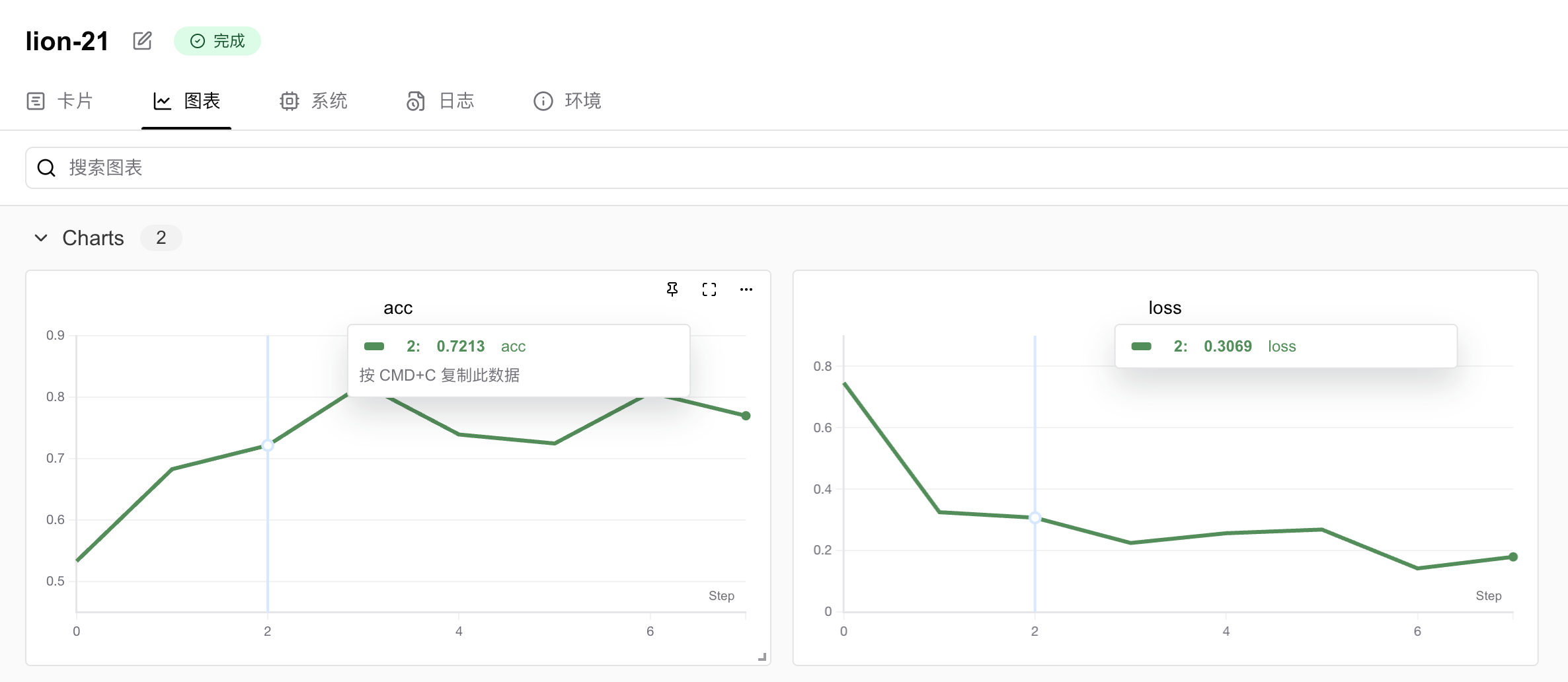
3、现成的AI模型训练+评估框架
推荐:
Hugging Face Trainer(✅)
PyTorch Lightning
提问:现成的ai模型训练评估框架,包括tersorboard查看训练数据、筛选模型、评估效果
提问:
简单概述主流现成的AI模型训练+评估框架,包含:训练过程中的数据监控(比如通过 TensorBoard 可视化损失、指标)模型筛选(如自动保存最优模型、早停)评估效果(自动计算指标,方便比较模型)
你想要的是一个现成的AI模型训练+评估框架,包含:
- 训练过程中的数据监控(比如通过 TensorBoard 可视化损失、指标)
- 模型筛选(如自动保存最优模型、早停)
- 评估效果(自动计算指标,方便比较模型)
下面给你推荐几个主流且功能完整的框架/工具组合,覆盖你需求的这几个点:
1. PyTorch Lightning + TensorBoard + ModelCheckpoint + EarlyStopping
- 训练监控:Lightning内置对TensorBoard的支持,训练时自动记录loss、metric到TensorBoard。
- 模型筛选:内置
ModelCheckpoint,可自动保存指标最优模型(如val_loss最小、准确率最高)。 - 早停:内置
EarlyStopping,当验证指标不再提升时自动停止训练。 - 评估效果:支持训练、验证、测试阶段指标计算和记录。
核心代码示例:
import pytorch_lightning as pl
from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStoppingcheckpoint_callback = ModelCheckpoint(monitor='val_loss', # 监控验证损失mode='min', # 取最小值对应模型save_top_k=1,verbose=True,
)early_stop_callback = EarlyStopping(monitor='val_loss',patience=5,verbose=True,mode='min'
)trainer = pl.Trainer(max_epochs=50,callbacks=[checkpoint_callback, early_stop_callback],logger=pl.loggers.TensorBoardLogger('tb_logs/')
)trainer.fit(model, train_dataloader, val_dataloader)
启动后,在终端运行 tensorboard --logdir=tb_logs/ 即可实时查看训练过程。
2. TensorFlow / Keras + TensorBoard + ModelCheckpoint + EarlyStopping
- TensorFlow内置支持TensorBoard,训练时会自动写入日志。
- ModelCheckpoint可保存验证指标最优模型。
- EarlyStopping自动停止训练避免过拟合。
示例:
callbacks = [tf.keras.callbacks.TensorBoard(log_dir='./logs'),tf.keras.callbacks.ModelCheckpoint('best_model.h5', monitor='val_loss', save_best_only=True),tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)
]model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=50, callbacks=callbacks)
3. Stable Baselines3 (强化学习)
- 自带
EvalCallback用于训练过程中自动评估模型表现。 CheckpointCallback用于保存模型。- 训练日志可通过 TensorBoard 监控。
示例:
from stable_baselines3.common.callbacks import EvalCallback, CheckpointCallbackeval_callback = EvalCallback(eval_env, best_model_save_path='./logs/',log_path='./logs/', eval_freq=10000, deterministic=True)
checkpoint_callback = CheckpointCallback(save_freq=5000, save_path='./logs/')model.learn(total_timesteps=100000, callback=[eval_callback, checkpoint_callback])
运行 tensorboard --logdir=./logs 可查看指标变化。
4. Huggingface Trainer(NLP)
- 内置日志记录(支持TensorBoard、WandB等)
- 自动保存最优模型和早停(EarlyStoppingCallback)
- 评估指标自动计算和记录
示例:
from transformers import Trainer, TrainingArguments, EarlyStoppingCallbacktraining_args = TrainingArguments(output_dir='./results',evaluation_strategy='epoch',save_strategy='epoch',logging_dir='./logs',logging_steps=10,load_best_model_at_end=True,
)trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,callbacks=[EarlyStoppingCallback(early_stopping_patience=3)],
)trainer.train()
然后使用TensorBoard查看 ./logs 文件夹。
5. 结合Weights & Biases(W&B)
(即WandB)
- 支持各种框架(PyTorch、TensorFlow、Lightning、SB3、HF等)
- 自动记录训练日志、模型、超参
- 支持在线实时可视化和对比多个实验
- 支持模型版本管理和筛选
官网:https://wandb.ai/site
总结推荐
| 框架/工具 | 训练监控(TensorBoard) | 自动保存最优模型 | 早停 | 评估指标 | 简单易用 | 适用范围 |
|---|---|---|---|---|---|---|
| PyTorch Lightning | ✅ | ✅ | ✅ | ✅ | ✅ | PyTorch通用 |
| TensorFlow / Keras | ✅ | ✅ | ✅ | ✅ | ✅ | TensorFlow/Keras |
| Stable Baselines3 | ✅ | ✅ | 部分 | ✅ | ✅ | 强化学习 |
| Huggingface Trainer | ✅ | ✅ | ✅ | ✅ | ✅ | NLP及Transformer模型 |
| Weights & Biases ((WandB)) | ✅ | ✅ | ✅ | ✅ | ✅ | 各类深度学习框架 |
如果你告诉我你用的是哪种框架,我可以帮你写具体的训练+评估+TensorBoard配置示例,或者帮你搭建完整的训练流水线。你看?