【Doris入门】Doris数据表模型使用指南:核心注意事项与实践
目录
引言
1 建表规范与实践
1.1 列类型选择建议
1.2 建表示例
2 聚合模型的局限性及解决方案
2.1 聚合模型的核心局限性
2.2 聚合模型局限性示例
2.3 count(*)查询的性能问题
2.4 解决方案
2.4.1 方案一:增加SUM类型的count列
2.4.2 方案二:使用REPLACE类型的count列
3 Unique模型的写时合并实现优势
3.1 性能优势对比
3.2 实际应用示例
4 Key列在不同模型中的不同意义
4.1 Key列的含义对比
4.2 各模型Key列特点
4.3 实际应用中的影响
5 数据模型选择建议
5.1 模型选择决策流程
5.2 各模型适用场景
5.2.1 Aggregate模型适用场景
5.2.2 Unique模型适用场景
5.2.3 Duplicate模型适用场景
5.3 模型选择决策表
6 总结
引言
Apache Doris作为一款高性能的分布式分析型数据库,提供了三种主要的数据模型:
- 明细模型(Duplicate Key Model)
- 聚合模型(Aggregate Key Model)
- 主键模型(Unique Key Model)
每种数据模型都有其特定的适用场景和局限性,正确选择和使用数据模型对于系统性能和业务需求满足至关重要。
1 建表规范与实践
1.1 列类型选择建议
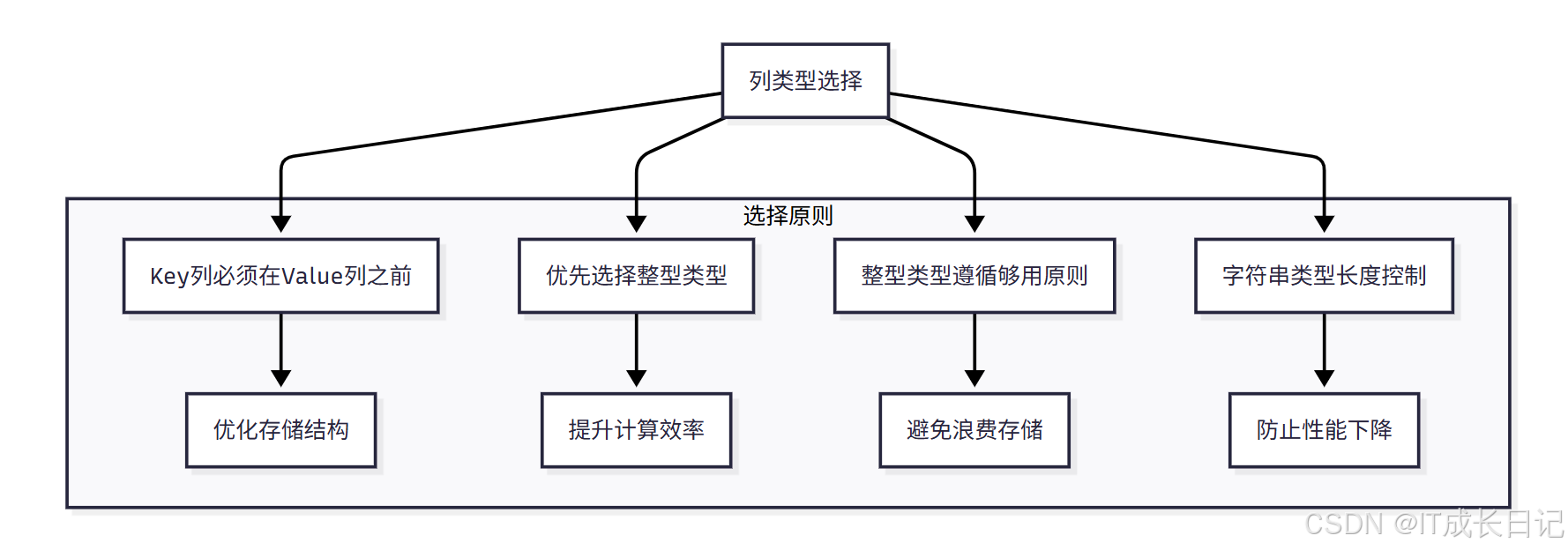
- 在建表时,列类型的选择直接影响查询性能和存储效率,需要特别注意以下几点:
具体建议:
- Key列必须在所有Value列之前
- 这是Doris的硬性要求,违反会导致建表失败
- Key列用于数据排序和分组,Value列用于存储实际业务数据
- 合理的列顺序可以优化存储结构和查询性能
- 尽量选择整型类型
- 整型类型的计算和查找效率远高于字符串类型
- 常用整型类型:TINYINT、SMALLINT、INT、BIGINT、LARGEINT
- 整型类型在内存占用和CPU计算方面都有优势
- 整型类型遵循够用原则
- 根据数据范围选择合适的整型长度
- 例如年龄字段用TINYINT(0-255)足够,无需使用INT
- 避免过度使用大类型造成存储浪费
- VARCHAR和STRING类型长度控制
- 遵循"够用即可"原则,避免定义过大的长度
- 例如用户名定义VARCHAR(50)而非VARCHAR(1000)
- 合理的长度定义可以显著提升压缩率和查询性能
1.2 建表示例
-- 推荐的建表示例
CREATE TABLE IF NOT EXISTS ods_db.optimized_user_profile(user_id BIGINT NOT NULL COMMENT "用户ID",register_date DATE NOT NULL COMMENT "注册日期",user_age TINYINT COMMENT "年龄",city_code SMALLINT COMMENT "城市编码",user_level TINYINT COMMENT "用户等级",last_login_time DATETIME COMMENT "最后登录时间",total_consumption DECIMAL(10,2) COMMENT "总消费金额",login_count INT COMMENT "登录次数",is_active TINYINT COMMENT "是否活跃"
)DUPLICATE KEY(user_id, register_date)
DISTRIBUTED BY HASH(user_id) BUCKETS 1
PROPERTIES ("replication_allocation" = "tag.location.default: 1","compression" = "zstd"
);2 聚合模型的局限性及解决方案
2.1 聚合模型的核心局限性
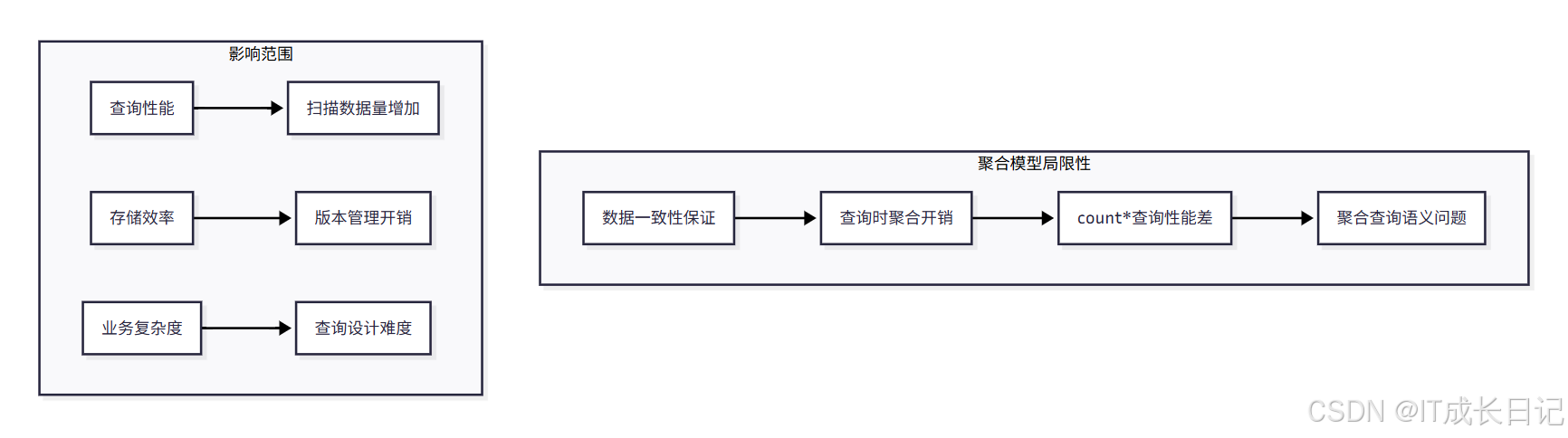
- 聚合模型虽然通过预聚合机制提升了查询性能,但也存在一些重要的局限性:
主要局限性:
- 数据一致性保证机制
- 聚合模型需要保证不同导入批次的数据最终聚合结果的一致性
- 在查询引擎中加入聚合算子来保证数据对外的一致性
- 这种一致性保证在某些查询中会极大地降低查询效率
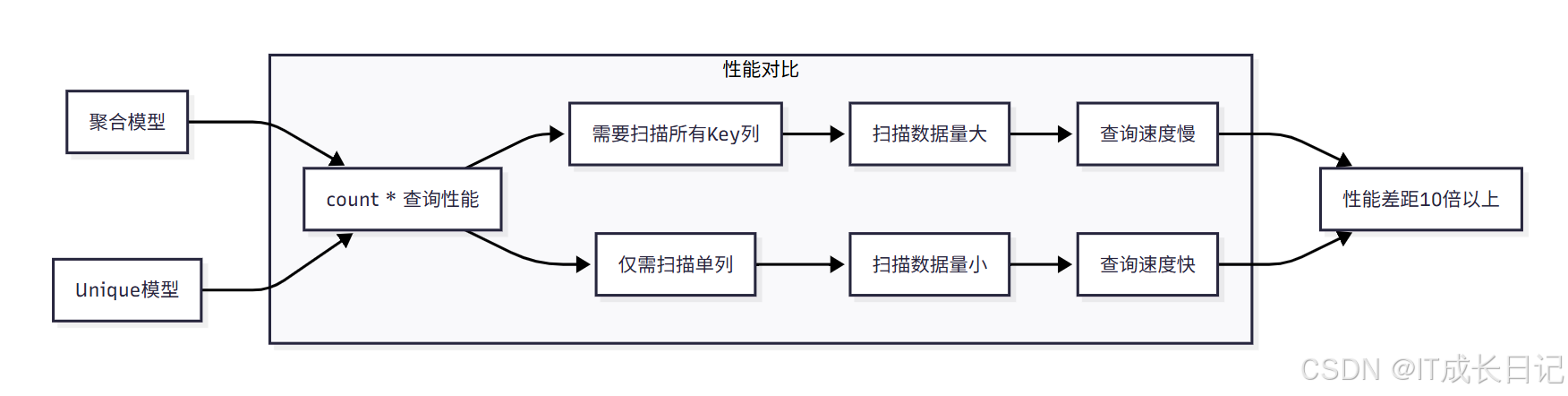
- count(*)查询性能问题
- 在聚合模型中,count(*)查询需要扫描所有的AGGREGATE KEY列
- 必须同时读取所有Key列的数据,加上查询时聚合,才能得到正确结果
- 当聚合列非常多时,count(*)查询需要扫描大量的数据
2.2 聚合模型局限性示例
| ColumnName | Type | AggregationType | Comment |
| user_id | LARGEINT | 用户id | |
| date | DATE | 数据灌入日期 | |
| cost | BIGINT | SUM | 用户总消费 |
- 导入两批次数据:
| user_id | date | cost |
| 10001 | 2025/11/20 | 50 |
| 10002 | 2025/11/21 | 39 |
| user_id | date | cost |
| 10001 | 2025/11/20 | 1 |
| 10001 | 2025/11/21 | 5 |
| 10003 | 2025/11/22 | 22 |
- 最终聚合结果:
| user_id | date | cost |
| 10001 | 2025/11/20 | 51 |
| 10001 | 2025/11/21 | 5 |
| 10002 | 2025/11/21 | 39 |
| 10003 | 2025/11/22 | 22 |
2.3 count(*)查询的性能问题
-- 这个查询在聚合模型中性能很差
SELECT COUNT(*) FROM user_cost_table;
-- 正确结果应该是4,但需要扫描所有Key列才能得到问题分析:
- 如果只扫描user_id列,加上查询时聚合,得到3(10001, 10002, 10003)
- 如果不加查询时聚合,得到5(两批次一共5行数据)
- 两个结果都不正确,必须同时读取user_id和date列才能得到正确结果4
2.4 解决方案
2.4.1 方案一:增加SUM类型的count列
-- 修改表结构,增加count列
CREATE TABLE ads_db.user_cost_table_optimized(user_id BIGINT,date DATE,cost BIGINT SUM,count BIGINT SUM -- 用于计算count
)AGGREGATE KEY(user_id, date)
PROPERTIES ("replication_num" = "1"
);- 导入数据时,count列值恒为1:
-- 导入数据
INSERT INTO ads_db.user_cost_table_optimized VALUES
(10001, '2025-08-20', 50, 1),
(10002, '2025-08-21', 39, 1);INSERT INTO ads_db.user_cost_table_optimized VALUES
(10001, '2025-08-20', 1, 1),
(10001, '2025-08-21', 5, 1),
(10003, '2025-08-22', 22, 1);- 查询优化:
-- 使用sum(count)替代count(*)
SELECT SUM(count) FROM ads_db.user_cost_table_optimized;
-- 这个查询效率远高于直接使用COUNT(*)
mysql> SELECT SUM(count) FROM ads_db.user_cost_table_optimized;
+--------------+
| sum(`count`) |
+--------------+
| 5 |
+--------------+
1 row in set (0.31 sec)mysql> 2.4.2 方案二:使用REPLACE类型的count列
-- 修改表结构,使用REPLACE聚合类型
CREATE TABLE ads_db.user_cost_table_optimized_v2(user_id BIGINT,date DATE,cost BIGINT SUM,count BIGINT REPLACE
) AGGREGATE KEY(user_id, date)
DISTRIBUTED BY HASH(user_id) BUCKETS 1 -- 指定分桶键和桶数量
PROPERTIES ("replication_num" = "1"
);
# 优势: 没有导入重复行的限制,sum(count)和count(*)的结果一致3 Unique模型的写时合并实现优势
3.1 性能优势对比
3.2 实际应用示例
-- 创建使用写时合并的Unique表
CREATE TABLE dwd_db.user_profile_unique(user_id BIGINT NOT NULL,username VARCHAR(50) NOT NULL,city VARCHAR(20),age INT,last_login_time DATETIME,login_count INT DEFAULT "0"
) UNIQUE KEY(user_id, username)
DISTRIBUTED BY HASH(user_id) BUCKETS 1
PROPERTIES ("enable_unique_key_merge_on_write" = "true","replication_num" = "1"
);-- 数据导入
INSERT INTO dwd_db.user_profile_unique VALUES
(1001, 'tom', 'beijing', 25, '2025-01-01 10:00:00', 10),
(1002, 'jerry', 'shanghai', 30, '2025-01-01 11:00:00', 5);-- 更新数据
INSERT INTO dwd_db.user_profile_unique VALUES
(1001, 'tom', 'beijing', 26, '2025-01-02 10:00:00', 15);-- count(*)查询性能优异
SELECT COUNT(*) FROM dwd_db.user_profile_unique;4 Key列在不同模型中的不同意义
4.1 Key列的含义对比

4.2 各模型Key列特点
| 模型 | Key列含义 | 唯一约束 | 数据处理 |
| Duplicate | 仅作为排序列 | 无 | 保留所有数据,包括重复数据 |
| Aggregate | 排序列+唯一标识列 | 有 | 按聚合函数处理重复数据 |
| Unique | 排序列+唯一标识列 | 有 | 保留最新数据,覆盖旧数据 |
4.3 实际应用中的影响
-- Duplicate模型:Key列只用于排序
CREATE TABLE ods_db.logs_duplicate(log_time DATETIME,log_type INT,content VARCHAR(1024)
)DUPLICATE KEY(log_time, log_type)
PROPERTIES ("replication_num" = "1"
);-- Aggregate模型:Key列用于聚合
CREATE TABLE ads_db.stats_aggregate(date DATE,user_id BIGINT,amount BIGINT SUM
)AGGREGATE KEY(date, user_id)
PROPERTIES ("replication_num" = "1"
);-- Unique模型:Key列用于去重
CREATE TABLE dwd_db.users_unique(user_id BIGINT,username VARCHAR(50),last_login_time DATETIME REPLACE
)UNIQUE KEY(user_id, username)
PROPERTIES ("replication_num" = "1"
);5 数据模型选择建议
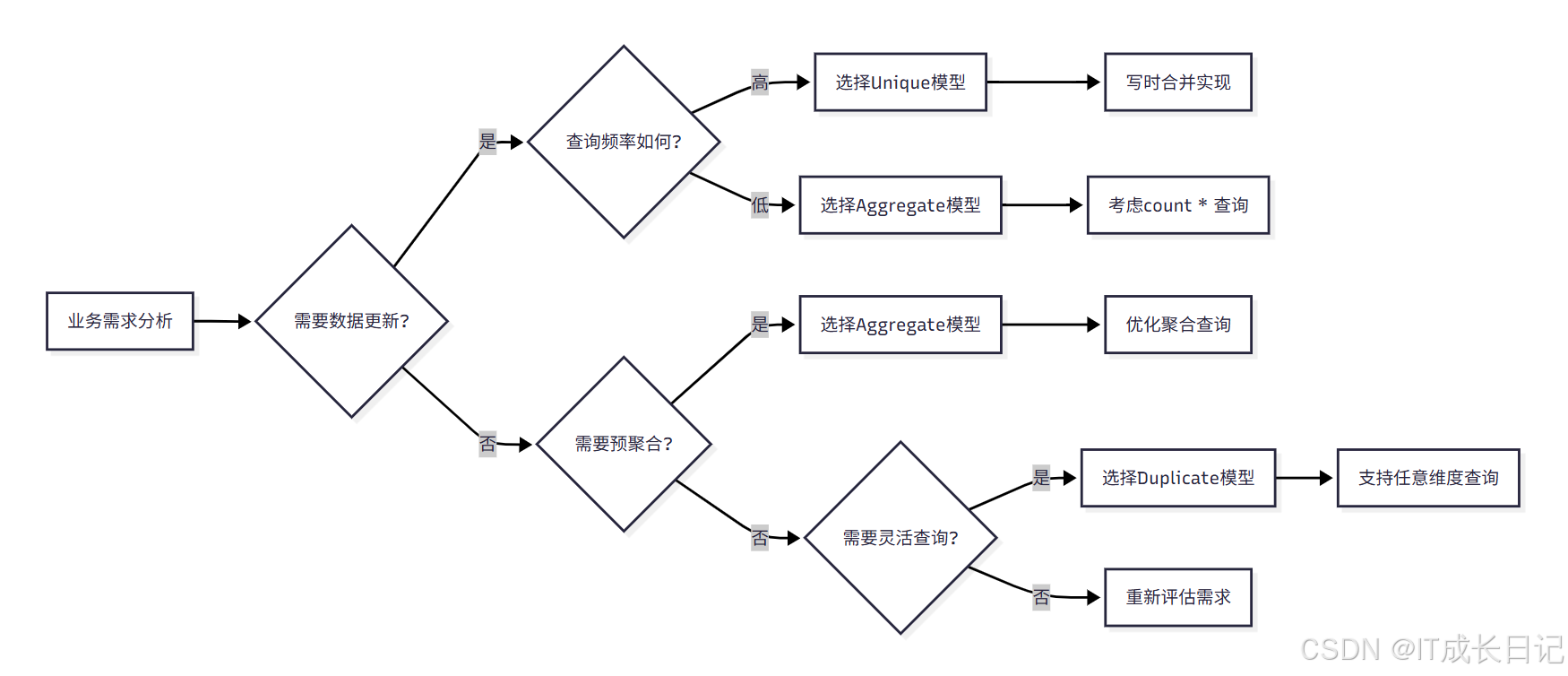
5.1 模型选择决策流程
5.2 各模型适用场景
5.2.1 Aggregate模型适用场景
适用场景:
- 有固定模式的报表类查询
- 需要预聚合统计的场景
- 数据量大且需要汇总分析
- 对count(*)查询要求不高的场景
不适用场景:
- 频繁的count(*)查询
- 需要灵活Ad-hoc查询的场景
- 数据需要频繁更新的场景
5.2.2 Unique模型适用场景
适用场景:
- 需要数据更新的场景
- 有主键唯一约束的业务需求
- 对查询性能要求高的场景
- 频繁进行count(*)查询的场景
推荐实现:
- 优先使用写时合并实现(2.1+版本默认)
- 对于写多读少的场景,可考虑读时合并
5.2.3 Duplicate模型适用场景
适用场景:
- 需要保留原始明细数据的场景
- 需要支持任意维度Ad-hoc查询的场景
- 有数据审计和追溯需求的场景
- 数据相对稳定,很少更新的场景
不适用场景:
- 需要频繁更新数据的场景
- 对存储空间敏感的场景
- 有固定查询模式的场景
5.3 模型选择决策表
| 业务需求 | 推荐模型 | 实现方式 | 原因 |
| 频繁count(*)查询 | Unique | 写时合并 | 性能最优,支持高效count |
| 固定报表查询 | Aggregate | 默认 | 预聚合,查询性能好 |
| 灵活Ad-hoc查询 | Duplicate | 默认 | 支持任意维度查询 |
| 数据需要更新 | Unique | 写时合并 | 支持数据更新和去重 |
| 数据需要审计 | Duplicate | 默认 | 保留原始数据 |
| 存储空间敏感 | Aggregate | 默认 | 预聚合节省空间 |
| 写多读少场景 | Unique | 读时合并 | 写入性能好 |
6 总结
正确选择和使用Doris数据表模型是充分发挥其性能优势的关键。在实际应用中,我们需要:
- 深入理解各模型特点:充分了解Aggregate、Unique、Duplicate三种模型的优势和局限性
- 根据业务需求选择:结合具体的业务场景、查询模式、更新需求等因素选择合适的模型
- 持续优化和监控:建立完善的监控体系,持续优化查询性能和存储效率
- 关注最佳实践:遵循本文提到的最佳实践,避免常见的性能陷阱
通过合理的数据模型选择和优化,Doris能够为各种大数据分析场景提供卓越的性能支持,助力企业构建高效的数据分析平台。