select, poll, epoll
文章目录
- select
- return val :
- 什么是 fd_set?
- poll
- pollfd
- return value
- select 与poll 的区别
- poll 的 timeout 以毫秒计 与select的timeout 对比 ,poll的timeout有什么改进
- 如何理解select接口返回0, poll接口返回0
- poll 与内核有什么关系?
- Epoll
- epoll_wait的timeout参数和select , poll 中的timeout参数设计
- I/O 多路复用的其他设计范式
- 1. 异步 I/O(AIO):完全无阻塞,内核 “包办一切”
- 2. 多线程 / 多进程 + 阻塞 I/O:分摊阻塞压力
- Reactor 模式(基于 I/O 多路复用)
- Reactor 模式的核心逻辑
- Proactor
- 总结
select
return val :
- 就绪 fd 的总数;
出错返回 -1
超时返回 0:
select 返回 0 表示“时间到了,但没有任何 fd 就绪”。
这正是 timeout != NULL 时才可能出现的情况;
例如:
触发条件:把一个有限时间(如 5 秒)塞进 struct timeval,5 秒内没有任何 fd 可读/可写/异常。
语义:不是错误,只是“超时”事件,让你有机会干点别的事。
常见处理:记录日志、发心跳、统计、检查配置热更新、关闭空闲连接
什么是 fd_set?
fd_set 不是普通 C 数组,而是 按位压缩的 1024 位位图
一个 1024 位的数组,数组下标就是 fd 号,数组元素 0/1 表示是否关心/就绪
fd_set 是一个 位图结构(内部实现通常是 long int 数组),每一位对应一个 fd。
- 你把关心的 fd “按位” 写入 fd_set,告诉 select 你要监听谁。
- FD_ZERO 清零、FD_SET 置位、FD_ISSET 检查置位
timeout 决定 select 愿意等多长时间才“醒”过来告诉你结果
-
timeout == NULL → 无限阻塞,直到至少有一个 fd 就绪。
只要没有任何套接字/文件描述符达到“可读、可写或异常”状态,线程就一直睡着;一旦其中任何一个就绪,内核立刻把线程唤醒,select 返回正值 -
timeout->tv_sec ==5 && timeout->tv_usec == 0 → 线程最多阻塞 5 秒,时间到就立即返回,即使没有 fd 就绪
把 timeout 设为 {5,0} 时,这 5 秒内线程并没有“溜号”去干别的事——它仍然阻塞在 select() 内部,只是这次最长只肯睡 5 秒;时间一到,内核就把它唤醒,返回 0,告诉你“超时了,没人就绪”。 -
timeout->tv_sec == 0 && timeout->tv_usec == 0 → 纯轮询,立即返回,告诉你当前谁已经就绪。
-
timeout->tv_sec > 0 || timeout->tv_usec > 0 → 最多等这么久,时间到就返回 0,表示“超时”。
select 返回 >0 只告诉“有几个 fd 就绪了”,具体是哪几个,必须用 FD_ISSET 逐一判断;
判断清楚后,必须立刻进行相应的 I/O 操作(读、写、accept、close),否则就浪费了这一次就绪通知,导致漏数据、阻塞或连接堆积
在 select 模型里,“IO 业务处理”并不是指 select 本身去读写数据,而是指 在 select 返回“就绪”之后,你在用户态对那个就绪 fd 做的“下一步系统调用 + 业务逻辑”。
最常见的动作就是下面 4 类,90 % 的 TCP 服务器都是这 4 件事的反复循环:
-
accept —— 监听套接字可读
场景:listen_fd 就绪
动作:conn = accept(...)
业务:把新连接设为非阻塞,塞进 连接表,后续继续 select。 -
recv/read —— 已连接套接字可读
场景:conn_fd 就绪
动作:n = recv(conn, buf, len, 0)
业务:
• 把收到的字节流做协议解析(HTTP、Redis、自定义包头)。
• 拆包、拼包、校验、生成响应。
• 若一次没读完,把剩余数据留在应用层 buffer,等待下一次可读。 -
send/write —— 已连接套接字可写
场景:内核发送缓冲区空出来了
动作:m = send(conn, outbuf, outlen, 0)
业务:把应用层 输出队列 里的剩余数据继续发;发完就移除写关注,避免忙轮询。 -
close —— 连接结束或出错
场景:recv 返回 0(对端 FIN)或 <0(错误)
动作:close(conn)
业务:从连接表、定时器、输出队列里全部清理,防止 fd 泄漏。
一句话归纳
select 只负责“通知”;真正的 IO 业务处理 就是
“accept → recv → 处理协议 → send → close” 这 5 步在用户态的循环。
fcntl :
fcntl 和 select 没有“功能耦合”,它只是 配合 select 做“前置配置”
fcntl把套接字设成非阻塞,防止在 select 返回就绪后,真正的 I/O 调用又阻塞住线程。
为什么要“非阻塞”?
select 告诉你“fd 可读”,但实际去读时,可能只剩 1 字节;
如果你用 阻塞读,而业务代码却想一次读 4 KB,就会再次阻塞。
select 告诉你“fd 可写”,但内核缓冲区只剩 100 B;
若一次想写 1 MB,同样会阻塞。
于是经典套路:
“select 负责等,fcntl 负责把 fd 设成非阻塞,这样后续 read/write 永远不会阻塞。”
总结:
fcntl 把 fd 设成非阻塞,select 负责“什么时候”可以 I/O;
二者组合成“非阻塞 + 事件驱动”的经典单线程高并发模型
poll
pollfd
struct pollfd {
int fd; /* 要监听的文件描述符(如套接字、标准输入等) /
short events; / 我们关注的事件(输入参数,由用户设置) /
short revents; / 实际发生的事件(输出参数,由内核填充) */
};
events:关注的事件(输入参数)
由用户设置,指定希望内核监控的事件类型(通过宏定义,如 POLLIN、POLLOUT 等)。
常用事件宏:
POLLIN:表示 “可读事件”(如套接字有新数据、新连接,标准输入有输入)。
POLLOUT:表示 “可写事件”(如套接字缓冲区可写入数据)。
POLLERR:关注错误事件(通常由内核自动设置,无需用户指定)。
revents:实际发生的事件(输出参数)
由内核填充,告知用户该 fd 上实际发生的事件(是 events 中被触发的子集,或额外的错误事件)。
例如:若用户设置 events = POLLIN,当 fd 有数据可读时,内核会将 revents 设为 POLLIN。
可能包含错误事件(如 POLLERR 表示连接出错,POLLHUP 表示连接被关闭),即使 events 中未指定,内核也会在 revents 中返回。
总结:
fd 和 events 是 用户填好的“请求参数”,内核只读不改。
revents 才是 内核回写的“结果标志位”,告诉用户这个 fd 上实际发生了什么事件(如 POLLIN、POLLOUT、POLLERR 等)。
return value
-
0:超时
-
-1:出错
-
0:就绪文件描述符个数(即 revents 非0的个数)
无论是 select 还是 poll,当返回值为正整数时,其本质含义就是:
“你告诉内核要监听的那些文件描述符(fd)中,有至少一个 fd 发生了「你关心的 I/O 事件」,
但不会直接告诉你 “具体是哪个 fd 发生了什么事件”,需要你遍历 fd_set/pollfd 数组,检查每个****fd 的 revents,才能知道具体是哪个 fd 发生了什么事件”
后续只需要通过 FD_ISSET(select)或检查 pollfd.revents(poll),就能精准定位到 “哪个 fd 就绪了什么事件”,再执行对应的处理逻辑(如 read/accept)即可
比如:
若你监听的是 STDIN_FILENO(标准输入)的 “读事件”,返回值 > 0 可能意味着用户输入了字符(有数据可读);
若你监听的是 listen_fd(TCP 监听套接字)的 “读事件”,返回值 > 0 可能意味着有新客户端发起连接(可调用 accept);
若你监听的是 conn_fd(已连接套接字)的 “读事件”,返回值 > 0 可能意味着客户端发送了数据(可调用 read)。
系统调用 返回值 > 0 时的具体含义
select 返回 “就绪的文件描述符的总数”(但注意:若一个 fd 同时就绪多个事件,仍只算 1 个)
poll 返回 “就绪的 pollfd 结构体的个数”(每个 pollfd 对应一个 fd,逻辑与 select 类似)
select 与poll 的区别
1 select 通过三个 fd_set(读、写、异常)管理事件,而 poll 用 struct pollfd 数组
2 早期 select 的 FD_SETSIZE 限制(1024)在高并发场景(如大量客户端连接的服务器)中严重不足。pollfd 采用动态数组,理论上可支持任意多的 FD(仅受系统资源限制)
3 select 的 fd_set 每次调用都要重置(因为内核会修改它),而 pollfd 的 events 是输入参数,内核不会修改,只需在处理后重置 revents 即可重复使用,减少了初始化开销
例如,用实际场景理解“清空并重建 fd_set”的必要性
-
场景起点(第1轮 select 前)
- 活跃连接:listenfd=3,客户端A=4,客户端B=5
- 你构建监控集:FD_ZERO→FD_SET(3/4/5)
- select 返回:假设本轮只有A(4)可读,内核把 rfds 改成只剩下4
-
第2轮,如果你不清空/不重建
- 你直接把“上轮被改写后的 rfds”再次传给 select,此时 rfds 里只有4
- 结果:你只监控A,完全丢掉了监听fd=3和客户端B=5
- 后果:
- 新连接来了(listenfd=3 可读),你收不到
- 客户端B发数据(fd=5 可读),你也收不到
- 程序像“瞎了”一样只盯着A
-
第2轮,正确做法(清空并重建)
- FD_ZERO(&rfds)
- 遍历当前活跃表(fd_array):再 FD_SET(3/4/5)
- 结果:本轮你继续同时监控 3、4、5;谁就绪都能收到
-
更动场景(连接动态变化)
- 第2轮前,客户端A断开(你在 Recver 里 close(4),并将 fd_array[pos]=defaultfd)
- 如果不清空 rfds,可能遗留“旧的4位”或错过“新的6位”(新连接)
- 清空并重建能确保:移除已关闭的4,加入新接入的6,集合始终和 fd_array 同步
一句话:每轮先清空,再按“当前真实活跃fd列表”重建,才能保证既不会遗忘新老连接,又不会监控已死的fd。
struct pollfd 通过 “FD + 关注事件 + 实际事件” 的绑定设计,解决了 select 在事件管理
poll 的 timeout 以毫秒计 与select的timeout 对比 ,poll的timeout有什么改进
select: timeval 会被内核改写为“剩余时间”,每轮都要重新赋值,否则下一轮超时会异常变短
select 中需要每轮设置 timeval(且它是输入输出型参数)
poll: 传入的毫秒整数一般不被内核修改,便于复用同一个变量
功能等价的取值:
select: NULL 无限阻塞;{0,0} 立即返回;{sec,usec} 指定超时(但会被改写)
poll: -1 无限阻塞;0 立即返回;>0 毫秒超时。
如何理解select接口返回0, poll接口返回0
select 返回 0:超时,没有任何被监控的 fd 就绪(前提:传入的 timeout 非 NULL 且非 0)。
poll 返回 0:超时,没有任何被监控的 fd 就绪(前提:timeout > 0)
三个实际运行场景
场景A:poll 设 3000ms,无 I/O 发生
3 秒后 poll 返回 0 → 进入 “time out…” 分支。
常用于触发周期任务(扫描空闲连接、心跳等)。
场景B:select 设 {1,0}(1秒),无 I/O 发生
1 秒后 select 返回 0 → 进入 “time out, 1.0” 分支。
注意:每轮必须重置 timeval,因为 select 会改写它。
场景C:超时设为“立即返回”
select 传 {0,0} 或 poll 传 0 → 立刻返回 0,表示“当前无就绪事件”,常用于“非阻塞轮询一次”的检查
如果 poll/select的timeout参数传 -1 或 NULL,线程会一直阻塞到有 I/O 事件 ,线程才会停止阻塞,timeout设置>0的作用就是防止一直阻塞 ,就算此时没有IO事件 , 让线程只在timeout时间内阻塞
实际运行对比
场景1:无 timeout(-1 或 NULL)
时间 0ms: poll/select 开始等待
时间 100ms: 无I/O事件 → 继续阻塞
时间 1000ms: 无I/O事件 → 继续阻塞
时间 10000ms: 无I/O事件 → 继续阻塞
时间 60000ms: 无I/O事件 → 继续阻塞
... 无限等待,直到有I/O事件
场景2:有 timeout(3000ms)
时间 0ms: poll/select 开始等待
时间 100ms: 无I/O事件 → 继续阻塞
时间 1000ms: 无I/O事件 → 继续阻塞
时间 3000ms: 无I/O事件 → 超时唤醒,执行timeout逻辑
时间 3000ms: 重新开始等待
时间 6000ms: 无I/O事件 → 再次超时唤醒
... 每3秒至少唤醒一次
在 poll/select执行timeout逻辑中执行非紧急、可批量的任务,是一种常见的 “轮询 + 额外任务” 设计,能在不浪费阻塞时间的前提下提升效率,但需要注意超时任务不会干扰 I/O 事件的响应。
超时后执行的任务必须是 “短耗时” 的,不能阻塞太久,会导致下一次 I/O 监听的 “间隔被拉长”,可能错过紧急的 I/O 事件(比如客户端连接请求被延迟处理)。
timeout = -1 或 NULL:无限阻塞,线程"睡死"在内核
timeout > 0:有限阻塞,最多等待 timeout 时间,然后强制唤醒
timeout = 0:立即返回,不阻塞(非阻塞模式)
poll 与内核有什么关系?
select 用 位图(fd_set),有 1024 上限;
poll 用 数组,理论上无上限;
内核遍历每个 pollfd:
如果该 fd 已就绪,直接设置 revents 并累加计数。
如果未就绪,把当前进程挂到 每个 fd 的等待队列 上,然后让进程睡眠。
当任意 fd 产生事件(数据到达、缓冲区可写、连接到达等),对应的 驱动/子系统 唤醒等待队列里的进程。
进程醒来后再次扫描整份列表,把就绪的 revents 填好,返回用户态。
Epoll
Epoll 原理图:
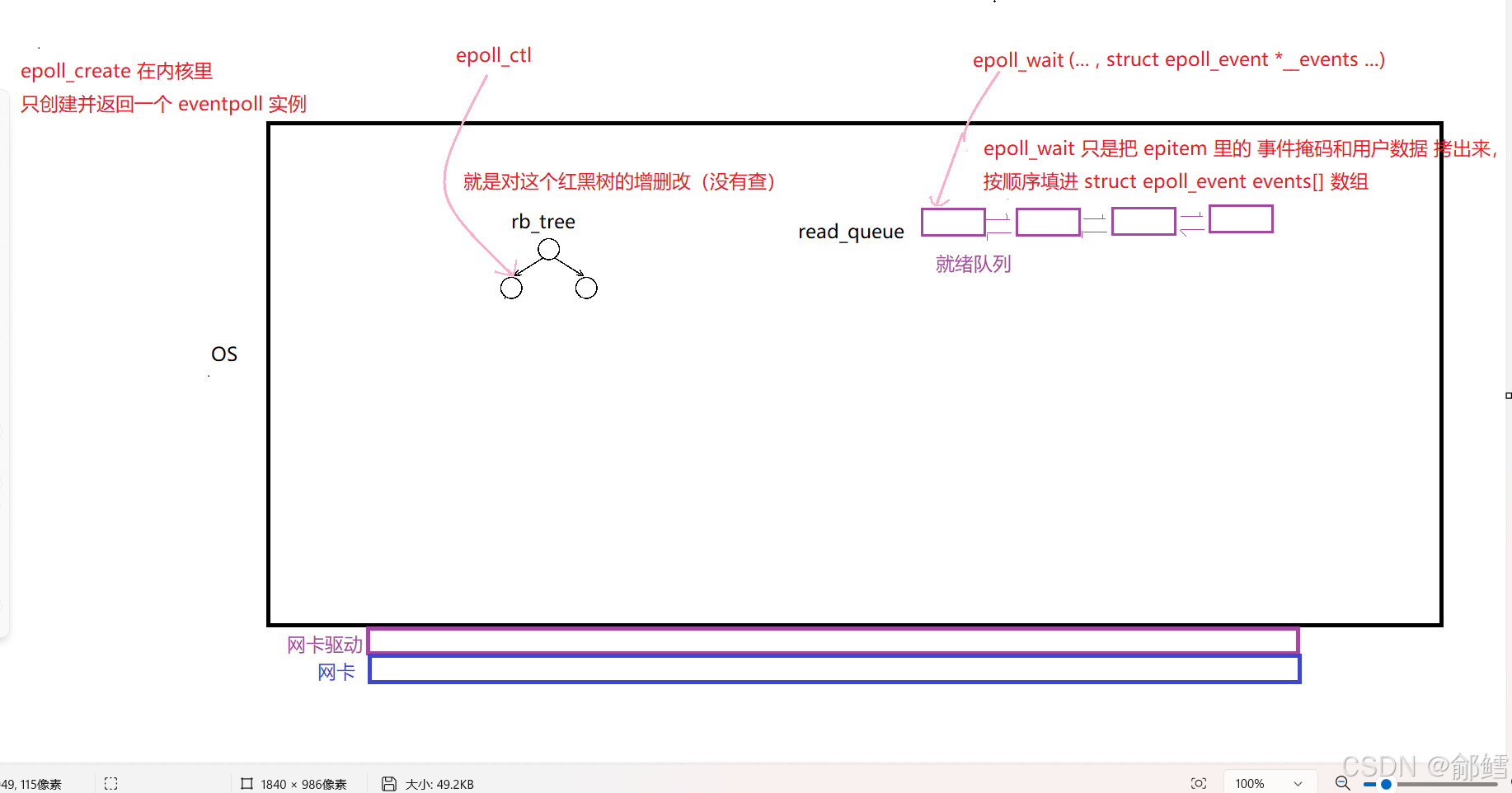
下面给出 Linux 5.15 内核源码 中 eventpoll 与 epitem 的 完整展开版本,并一次说清二者的关系与字段含义,可直接拿去和本地源码对照。
- 顶层对象:eventpoll
(每个 epoll 实例对应一个,存在 file->f_private 中)
/* include/linux/eventpoll.h + fs/eventpoll.c */
struct eventpoll {/* 1. 并发控制 */rwlock_t lock; // 读写锁:保护整棵红黑树/就绪链表struct mutex mtx; // 互斥锁:epoll_ctl 路径串行化/* 2. 等待队列 */wait_queue_head_t wq; // 阻塞在 epoll_wait 的进程队列wait_queue_head_t poll_wait; // epoll fd 自身被 poll/select/epoll 监控时使用/* 3. 核心数据结构 */struct list_head rdllist; // 就绪链表头(双向循环链表)struct rb_root_cached rbr; // 红黑树根(带最左缓存,加速最小节点访问)/* 4. 事件溢出处理 */struct epitem *ovflist; // epoll_wait 正在扫描时,新事件挂这里struct user_struct *user; // 所属 user 的引用计数struct file *file; // 指向 epoll 实例自身的 struct filewait_queue_entry_t poll_wait_entry;
};
- 事件节点:epitem (每注册一个 fd 就分配一个,同时挂在红黑树 + 就绪链表)
struct epitem {/* 2.1 红黑树节点(插入到 eventpoll.rbr) */union {struct rb_node rbn; // 红黑树节点struct rcu_head rcu; // 用于延迟释放};/* 2.2 就绪链表节点(插入到 eventpoll.rdllist) */struct list_head rdllink;/* 2.3 文件描述符信息 */struct epoll_filefd ffd; // { struct file *file; int fd; }/* 2.4 所属 epoll 实例 */struct eventpoll *ep;/* 2.5 用户注册事件 & 当前结果 */struct epoll_event event; // 用户注册时填的 events/dataunsigned int revents; // 当前实际发生的事件(内部用)/* 2.6 等待队列钩子 */wait_queue_entry_t wait; // 挂在目标文件 poll 队列struct list_head pwqlist; // 同一文件上的所有 epitem 链表struct list_head fllink; // 反向挂到 struct file->f_ep_linksstruct list_head txlink; // 传输链路(内部调试/日志用)/* 2.7 引用计数 & 标志位 */atomic_t usecnt;unsigned long flags; // EP_PRIVATE_BITS(内部状态位)
};
- 关联关系用一张图表示
eventpoll (epoll 实例)├── rbr (红黑树根)│ └── epitem[0].rbn│ └── epitem[1].rbn│ └── …│└── rdllist (就绪链表头)└── epitem[A].rdllink└── epitem[B].rdllink└── …
- “一实例” ↔ “多事件”:
每个eventpoll通过rbr管理 N 个epitem(红黑树节点),通过rdllist收集“就绪”的epitem(链表节点)。 - “一事件” ↔ “一文件”:
每个epitem通过ffd指向具体(struct file *, fd),并把wait钩子插到该文件的等待队列,实现事件回调。
- 实际代码定位(5.15 源码)
# 下载并切到对应版本
git clone --depth 1 -b v5.15 git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
cd linux
# 查看原始定义
vim fs/eventpoll.c +141
vim include/linux/eventpoll.h +40
epoll_wait的timeout参数和select , poll 中的timeout参数设计
三者的 timeout 参数本质都是 “最大阻塞时长”,而非 “固定阻塞时长”,核心行为逻辑完全一致,具体表现为:
- 有事件就绪时立即返回:若在
timeout设定的时间内,监控的文件描述符(fd)有事件就绪(如可读、可写),函数会立即终止阻塞,返回就绪事件的数量(或相关标识),优先处理事件。 - 超时无事件时返回 “无事件” 标识:若 timeout 时间耗尽仍无事件就绪,函数会返回 0, 程序进入超时逻辑(如执行轮询任务、打印日志等),之后再次调用
epoll_wait,重新开始计时。 - 支持非阻塞模式:若
timeout设为0,函数会立即返回(不阻塞),仅检查当前是否有事件就绪(相当于 “轮询一次”)。
void Start(){// 将listensock添加到epoll中 -> listensock和他关心的事件,添加到内核epoll模型中rb_tree._epoller_ptr->EpllerUpdate(EPOLL_CTL_ADD, _listsocket_ptr->Fd(), EVENT_IN);struct epoll_event revs[num];for (;;){int n = _epoller_ptr->EpollerWait(revs, num);if (n > 0){// 处理就绪事件(连接/数据)lg(Debug, "event happened, fd is : %d", revs[0].data.fd);Dispatcher(revs, n);}//将epoll_wait的timeout设置为正数,可让程序在等待事件的间隙定期进入该分支,执行额外任务else if (n == 0){// 超时返回(无事件),此处可添加轻量级任务lg(Info, "time out ...");// TODO: 执行其他任务(如定期清理、状态上报等)}else{lg(Error, "epll wait error");}}}
| 对比维度 | select 的 timeout | poll 的 timeout | epoll_wait 的 timeout |
|---|---|---|---|
| 参数类型 | struct timeval*(包含秒和微秒) | int(毫秒,直接传递数值) | int(毫秒,直接传递数值) |
| 传递方式 | 值 - 结果参数(value-result):内核会修改该结构体的数值,下次调用前需重新初始化(否则会被上次的剩余时间影响)。 | 输入参数:仅传递超时毫秒数,内核不修改该值,下次调用无需重新设置。 | 输入参数:与 poll 一致,仅作为输入,内核不修改,复用性更强。 |
| 使用便利性 | 低:需手动维护 struct timeval 结构体,容易因忘记重置导致逻辑错误。 | 高:直接传递整数,使用简单。 | 高:与 poll 一致,使用简单。 |
| 内核处理效率 | 与 select 整体低效有关(需轮询所有 fd),但 timeout 本身不是效率瓶颈。 | 与 poll 整体低效有关(需轮询所有 fd),timeout 设计无额外开销。 | 与 epoll 高效机制匹配(红黑树 + 就绪链表),timeout 仅控制阻塞时长,不影响事件检测效率。 |
select 和 poll 也遵循完全相同的模式,仅在代码细节上略有差异(如 select 需要重置 timeval 结构体):
// select 的超时处理示例
struct timeval tv;
fd_set readfds;while (true) {// 重置 timeout(select 的 timeout 是值-结果参数,必须每次重置)tv.tv_sec = 1; // 1秒超时tv.tv_usec = 0;FD_ZERO(&readfds);FD_SET(listen_fd, &readfds); // 监控监听套接字int n = select(listen_fd + 1, &readfds, NULL, NULL, &tv);if (n > 0) {// 处理事件handle_select_events(&readfds);} else if (n == 0) {// 超时任务do_timeout_task();// 下一次循环会重新设置 tv,无需手动修改}
}
“超时无事件返回 0 → 执行超时逻辑 → 重新调用等待函数” 是 I/O 多路复用机制的标准设计,其本质是通过 “阻塞等待事件 + 超时间隙处理任务” 的组合,在 “及时响应事件” 和 “高效利用资源” 之间取得平衡,这也是所有主流服务器(如 Nginx、Redis)的事件循环核心模式
阻塞等待事件这样不就影响效率了吗,必须阻塞等待吗 ,只能这样设计吗?
这里的 “阻塞” 并非指程序完全 “卡死” 无法响应,而是进程 / 线程在等待 I/O 事件时,主动放弃 CPU 使用权,被内核挂起—— 这恰恰是 “高效” 的关键。我们通过对比两种极端情况来理解:
反面案例:非阻塞轮询(无阻塞等待)
如果不使用阻塞等待,最直接的替代是 “非阻塞轮询”:程序用 while(1) 循环不断检查是否有 I/O 事件(比如每秒检查 1000 次)。这种方式的问题是:
- CPU 空转严重:即使没有任何 I/O 事件,CPU 也在不停执行循环检查,导致单个进程可能占用 100% 的 CPU 核心,浪费宝贵的计算资源。
- 响应延迟不可控:如果轮询间隔设为 1ms,CPU 占用高;如果设为 100ms,事件响应可能延迟 100ms,无法满足实时性需求。
正面案例:阻塞等待(epoll_wait/select)
当调用 epoll_wait(timeout) 时,进程会被内核 “挂起”,不再占用 CPU;直到以下两种情况发生时,内核才会 “唤醒” 进程:
-
有 I/O 事件就绪(如客户端发数据):内核立即唤醒进程处理事件,响应延迟极低(微秒级)。
-
超时时间耗尽:内核唤醒进程执行超时逻辑(如清理过期连接),之后重新进入阻塞等待。
阻塞等待的 “阻塞” 是 “有意义的等待”—— 放弃无用的 CPU 空转,只在需要处理事件时才占用 CPU,这正是它比非阻塞轮询高效的根本原因
阻塞等待是主流方案,但并非唯一选择。根据场景需求,还可以选择以下模式:
| 模式 | 核心逻辑 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 阻塞等待(主流) | epoll_wait (timeout>0) 挂起进程,内核唤醒 | CPU 占用极低,实现简单,响应实时性好 | 进程被挂起时,无法处理非 I/O 相关的紧急任务 | 绝大多数服务器(Nginx、Redis、MySQL) |
| 非阻塞等待 | epoll_wait (timeout=0) 立即返回 | 不阻塞进程,可随时穿插处理其他任务 | CPU 占用高(需循环调用),效率低 | 实时性要求极高的短任务(如实时数据采集) |
| 阻塞 + 信号中断 | epoll_wait 阻塞时,用信号(如 SIGUSR1)唤醒 | 兼顾阻塞的低 CPU 占用,又能处理紧急任务 | 实现复杂(信号安全、竞态条件处理) | 需处理紧急事件的服务器(如强制关闭连接) |
举例:非阻塞等待的代码(timeout=0)
当 epoll_wait 的 timeout=0 时,它会立即返回(不阻塞),无论是否有事件:
while (true) {// timeout=0:不阻塞,立即返回int n = epoll_wait(epfd, events, 1024, 0); if (n > 0) {handle_events(events, n); // 有事件则处理}// 无论是否有事件,都执行其他任务(如计算、日志)do_other_tasks(); // 这里可能占用大量 CPU
}
这种模式下,程序不会被阻塞,但 while(true) 会疯狂循环调用 epoll_wait,导致 CPU 占用飙升 —— 除非 do_other_tasks() 本身是耗时任务(如 heavy computation),否则不推荐用于服务器主循环。
I/O 多路复用的其他设计范式
1. 异步 I/O(AIO):完全无阻塞,内核 “包办一切”
- 程序发起 I/O 请求后(如
aio_read),立即返回,继续执行其他任务; - 内核会在后台完成整个 I/O 操作(包括等待数据到达、拷贝数据到用户空间);
- 操作完成后,内核通过信号或回调通知程序处理结果。
优点:完全不阻塞进程,CPU 利用率理论上最高;
缺点:
- 实现复杂(回调嵌套、错误处理繁琐);
- 兼容性差(Linux 的 AIO 仅支持 O_DIRECT 模式,不支持标准文件缓存,实际使用受限);
- 调试困难(异步流程难以追踪)。
目前主流服务器(Nginx、Redis)均未采用 AIO,而是坚持用 epoll 的阻塞等待模式 —— 因为 “够用且简单”
2. 多线程 / 多进程 + 阻塞 I/O:分摊阻塞压力
早期服务器(如 Apache 的 prefork 模式)采用 “一个连接一个进程 / 线程” 的设计:
- 主线程监听端口,收到连接后 fork 子进程,子进程用阻塞 I/O(如
read)处理该连接; - 多个连接对应多个进程,某个进程阻塞时,不影响其他进程处理请求。
epoll 等 I/O 多路复用,用单进程 / 线程阻塞等待多个 I/O 事件,避免了进程切换的开销。
Reactor 模式(基于 I/O 多路复用)
Reactor 模式的核心逻辑
Reactor 模式的本质是:用 “单线程(或少量线程)阻塞监听多个 I/O 事件”(依赖 epoll/select/poll),一旦某个事件就绪,就 “分发” 给对应的处理器处理,避免为每个连接创建线程。
Proactor
- Reactor 模式:基于同步 I/O。epoll 通知 “事件就绪” 后,需要用户线程主动调用
read()/write()完成 I/O(如 “socket 可读了,你快自己读”)。 - Proactor 模式:基于异步 I/O(如 Linux 的
aio_*系列函数)。用户线程直接发起异步 I/O 请求,内核会自动完成 “读 / 写” 并将数据拷贝到用户缓冲区,完成后再通知用户线程(如 “我已经把数据读好了,你直接用”)。
总结
epoll 只做一件事:“fd 已经就绪”这一瞬间的通知。
通知出去以后:
- 读不读、写不写、做不做业务处理,epoll 一概不管;
- 通知一次还是多次,取决于你选 LT 还是 ET、以及你怎么处理 fd;
- 让哪个线程/进程去等(
epoll_wait),也完全由开发者决定。