[Ai Agent] 打造一个真正可落地的客服智能体
相关专栏:AI Agent实战
前言:
在之前的两篇文章里,我们已经初步搭建好了一个加入知识库检索,能根据问题,援引知识库里的网页检索,本地文档/图片检索的智能体。(如果不太了解知识库检索,推荐先前往上篇文章:
[Ai Agent] 本地知识库检索运用-CSDN博客 熟悉相关操作)
如果已了解,推荐直接导入我github的相关资源,开始下面的学习。
本文智能体实现功能包括:
回忆上下文逻辑,识别无关问题并提醒,实时录入用户问答数据,去掉无图片时的文本输出等。
一、识别当前智能体不足
先打开我们上篇文章末尾创建的智能体:
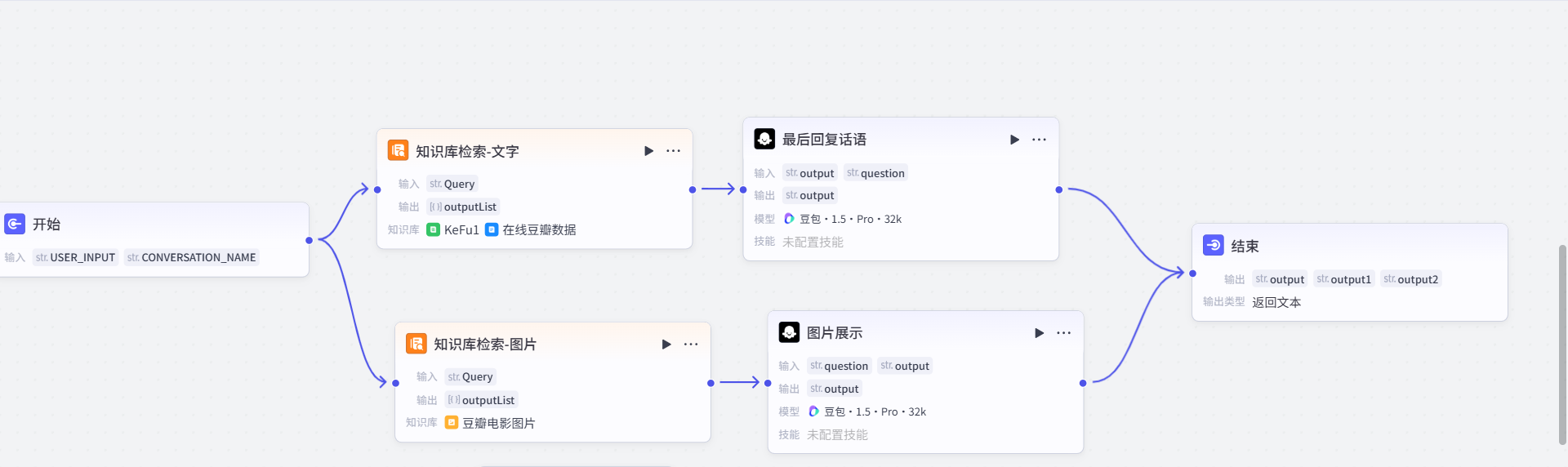
这个过程看起来没有问题,但细想之下,问题还是存在:
其一,有一个不容易发现的问题:就是,它能感知上下文吗?不能的。这点也请读者在日后使用时务必要注意:感知上下文并关联回答必须也要列入智能体构建的一环,不然它智商还是不太行:
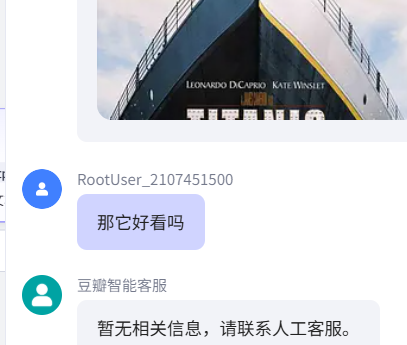
其二,如果客户问了个完全无关的问题,这个问题还要想这样完整走一遍检索流程吗,很明显不,所以我们需要加个逻辑,判断是否有关,如果无关应走无检索的逻辑。
其三,哪怕我们为图片这个智能体写了非常多的限制语句,它还是无法在没有图片的情况下“闭嘴”,明显需要我们再为其思考一下架构 ↓

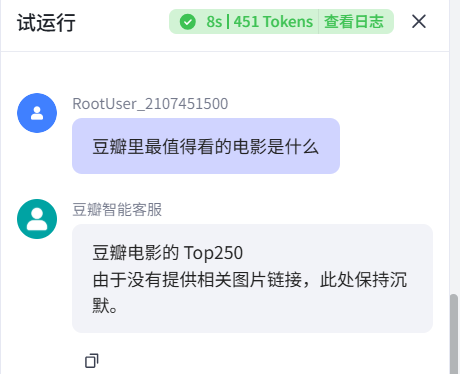
其四(实际上应算需求),我们还想将用户使用产生的数据(问题/回答)实时返回,就需要加入一些其他组件。
以上,我们试着分别把这些问题或者说功能分章节逐个思考解决掉。
二、处理上下文逻辑
如图,在开始和知识库检索的中间,我们新增一个问题优化-上下文判断的大模型。
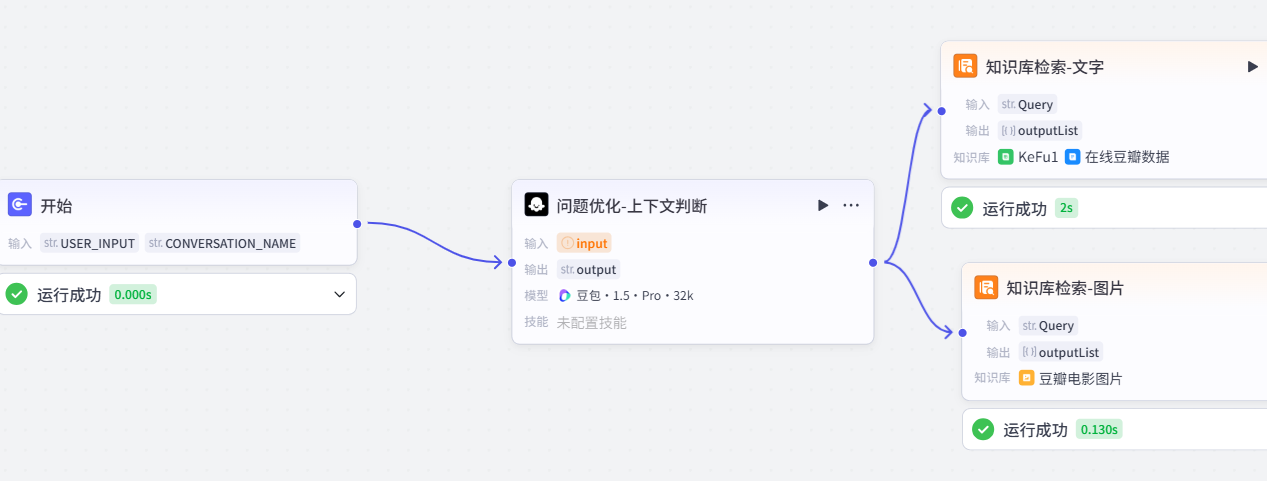
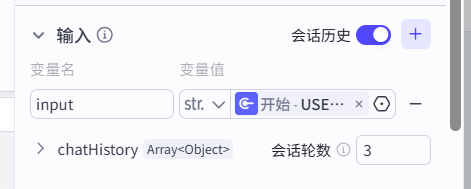
把这个会话历史打开它才可以思考上下文。
提示词如下
# 角色
你是一个用户问题简洁理解专家,你的任务是结合对话上下文和用户的问题,快速且简洁地理解每次用户的问题,并对用户的问题进行精准、简要地表达。# 工作流程
## 步骤一:结合上下文信息理解用户问题
- 快速结合上下文信息和用户当前的提问,精准理解用户在问什么问题。例如用户先问“泰坦尼克号是什么”,接着问“还有其他电影吗”,结合上下文理解第二个问题,明确用户是在询问“除泰坦尼克号外还有哪些电影推荐”。
## 步骤二:结合步骤一的理解对用户问题进行重新描述
- 依据步骤一的理解,用简洁语言对当前用户的问题进行重新表述,突出关键信息。
这里注意一些小的细节,以后加入新节点时也务必先这样思考下:
多少节点需要变动?
问题优化-上下文判断 节点加入后,我们现在看图思考:
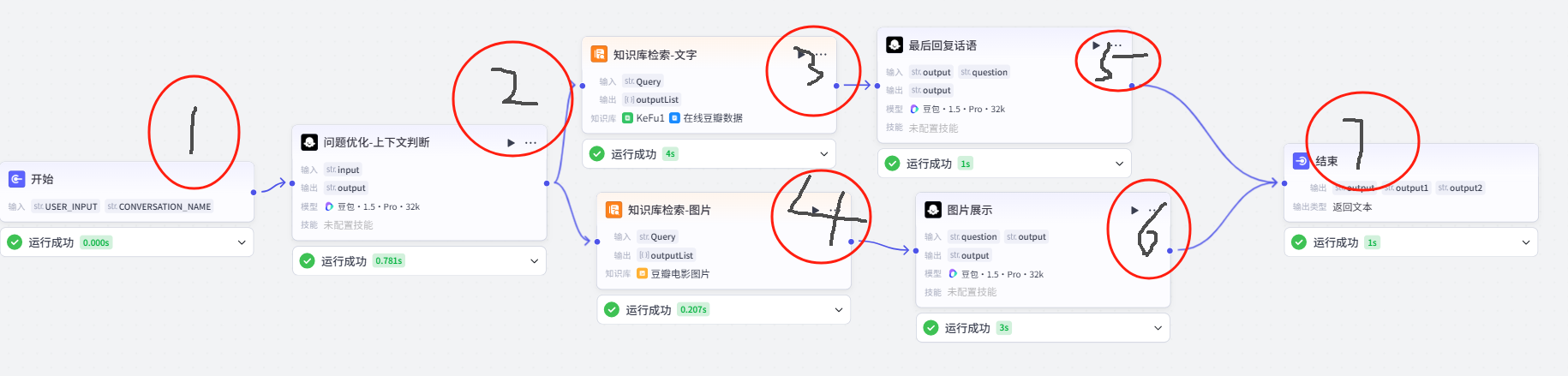
其中我们需要在2里把1的问题作为变量交给他,3和4传入参数也应由1变为2,而5和6同样传入的问题参数也需要由1变成2,最后的7则不需要变动,仍由5和6输出。
所以发现没有?一个节点的加入就需要思考全局变量的变动,但凡哪个细微处没有思考到就容易踩错。
 如图,上下文逻辑加入完成。
如图,上下文逻辑加入完成。
三、去掉无关回复
这里要引入一个新节点:意图识别--其作用就是判断意图从而选分支
你可以近似将其看做if/else,但在ai大模型语境中不好确定的判断if,就用这个作为新if
大致架构如下:
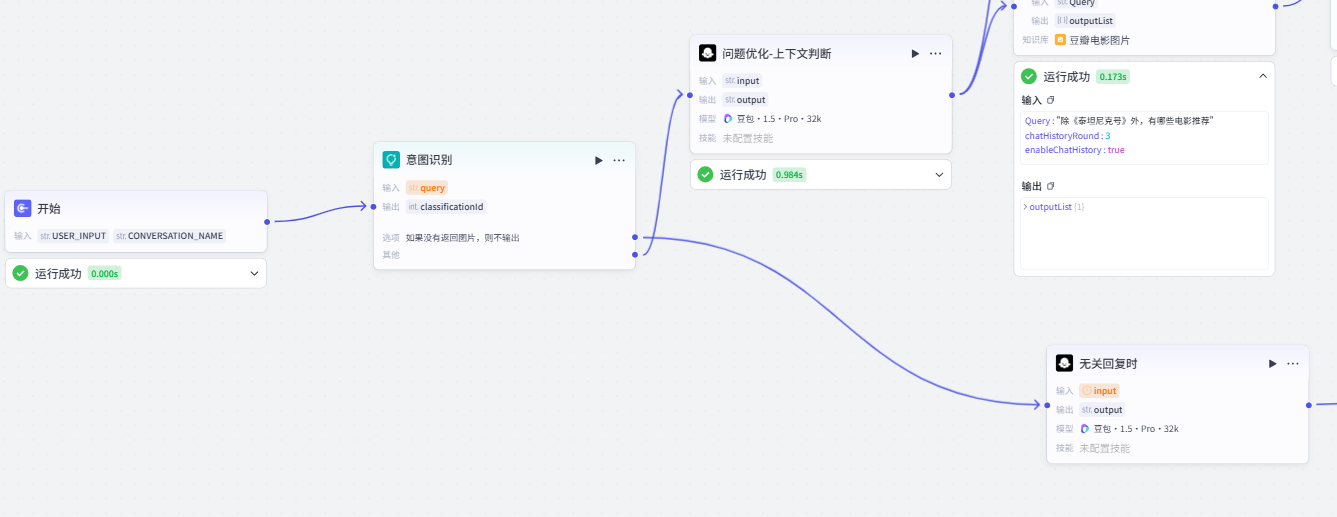
意图识别先判定开始的内容是否有关豆瓣客服,如果有关走上面,如果无关走下面,下面的无关回复时节点再直接对接结束节点,直接输出。
这里再重点讲一下这个意图识别的易错点:
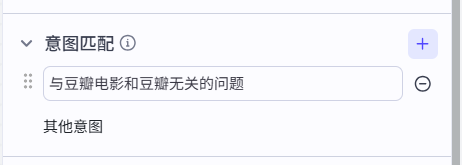
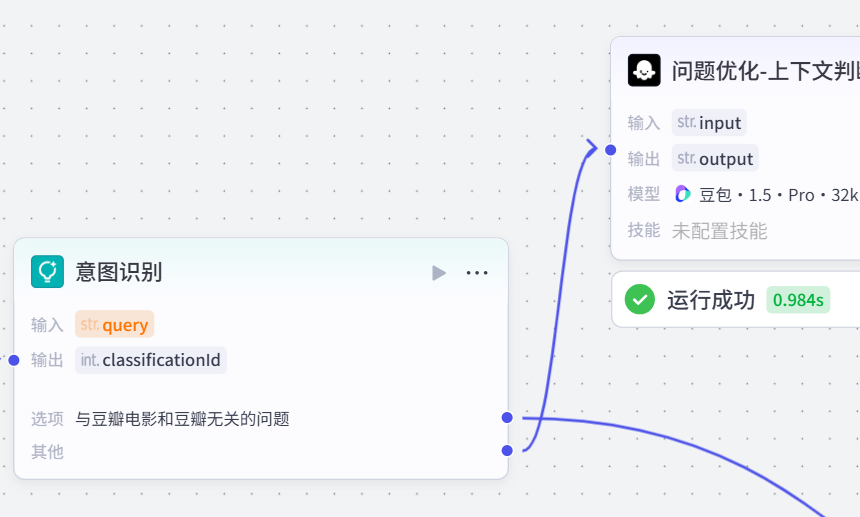
如上,意图识别里写好意图匹配后,就会开始匹配。上面的点就是对应匹配到的,下面的点则是匹配不到。
很多人肯定还有疑问:那我意图写成xx有关,直接上点连上面下点连下面不更直观吗?
确实,但要假设这么个问题:电影好不好看? 这种问题就是模棱两可的,如果你写个有关才能走上面,大概率就会被直接扔掉。但如果像上面写无关的话,它也不属于无关,就会选择走上面。
所以关键在于:你想让那些模棱两可的问题往哪个方向走。
接下来同样,更改对应地方的输入的变量节点与值,这点做法之前的二、已经讲过怎么做,此处不再赘述。测试下:
 成功。
成功。
四、去掉无图片时的文本输出
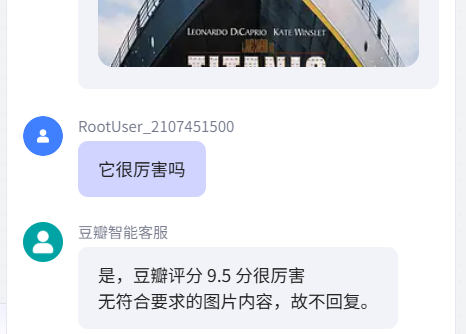
想要去掉类似上图这种底下的图片,我们需要重新从整个agent架构分析下:
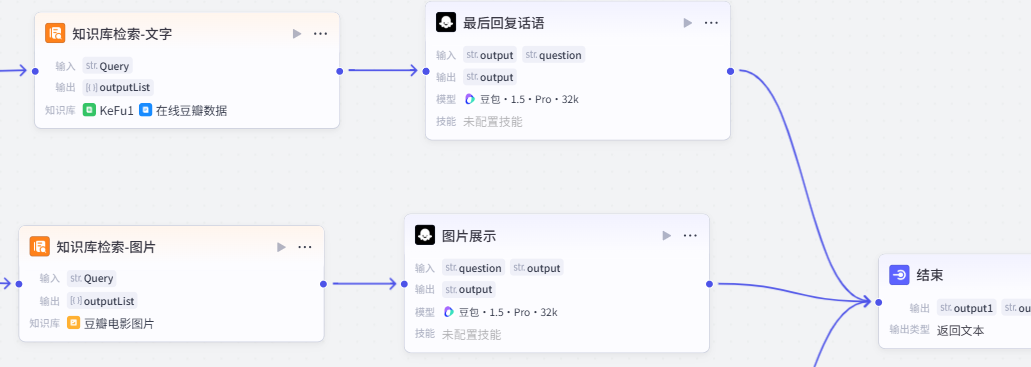
首先明确结束输出的图片展示{{output}}无法更改,我们要保证最后有输出必须要加上它。
那么,我们能着手的地方就是图片展示与结束中间。
但是,大模型是必定会输出东西的,无论你给它加多少限定词它一定会输出内容。所以,这里我们的想法就是为其添加一个代码判断,如果有图片不操作,如果无图片则把输出内容改为空。

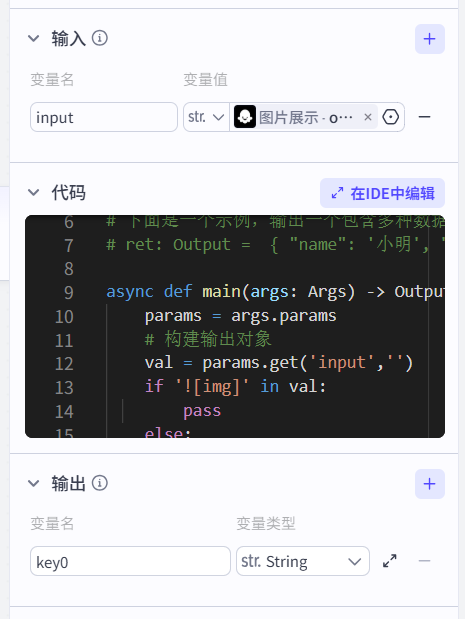
# 在这里,您可以通过 'args' 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为'input'的值:
# params = args.params;
# input = params['input'];
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": '小明', "hobbies": ["看书", "旅游"] };async def main(args: Args) -> Output:params = args.params# 构建输出对象val = params.get('input','')if '![img]' in val:passelse:val = ''ret: Output = {"key0": val}return ret这里简略讲下怎么写coze里的代码:
先改成py格式;
固定丢给你的params = args.params就是传入的参数,直接从里面提取你想要的值即可,比如我这里就是想提取上面图片识别大模型里传入的input。
后面的ret: Output = {...} 这一段也不要动,只动里面的... 即可,返回的ret必须是字典格式,同时键会对应你输出的变量名与值(变量在外面还要再设置一下,比如我上面的key0)
这样就完成了,依次连完线并把对应变量对接,测试一下:
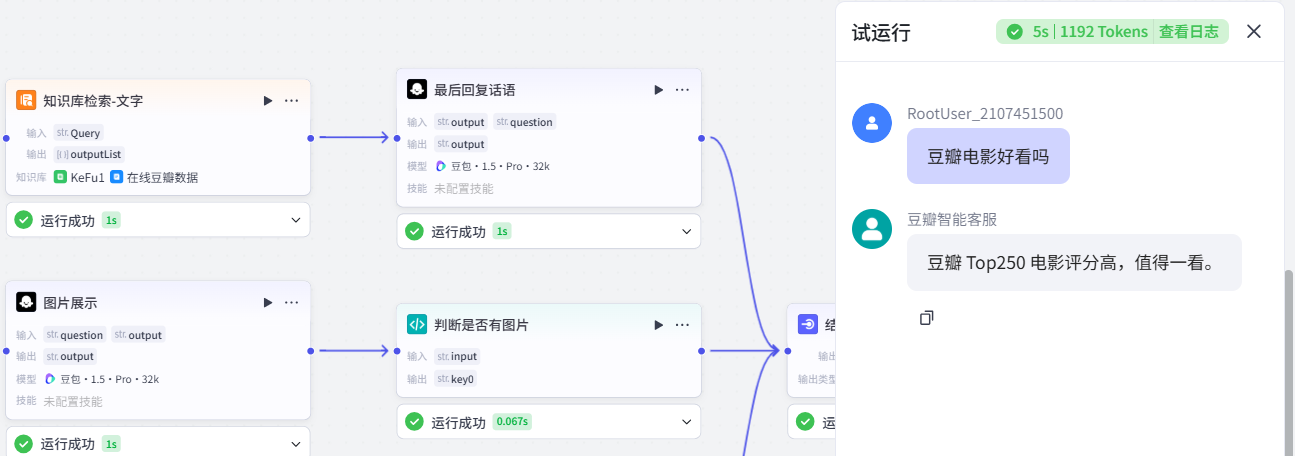
如图,可以看到走了图片演示的大模型,但不再输出这个大模型的输出,功能实现。
五、同步录入用户使用数据
现在我们希望能加个功能,让用户与智能客服的问答实时录入相关文件,这就需要加一些插件。
还是老规矩,看看架构: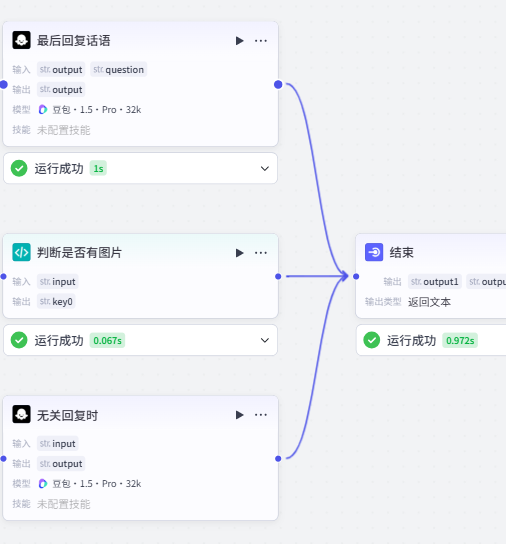
既然我们是要录入数据,那就应该在整个智能体的最终阶段将数据返回。
这里选择飞书表格作为录入方式,
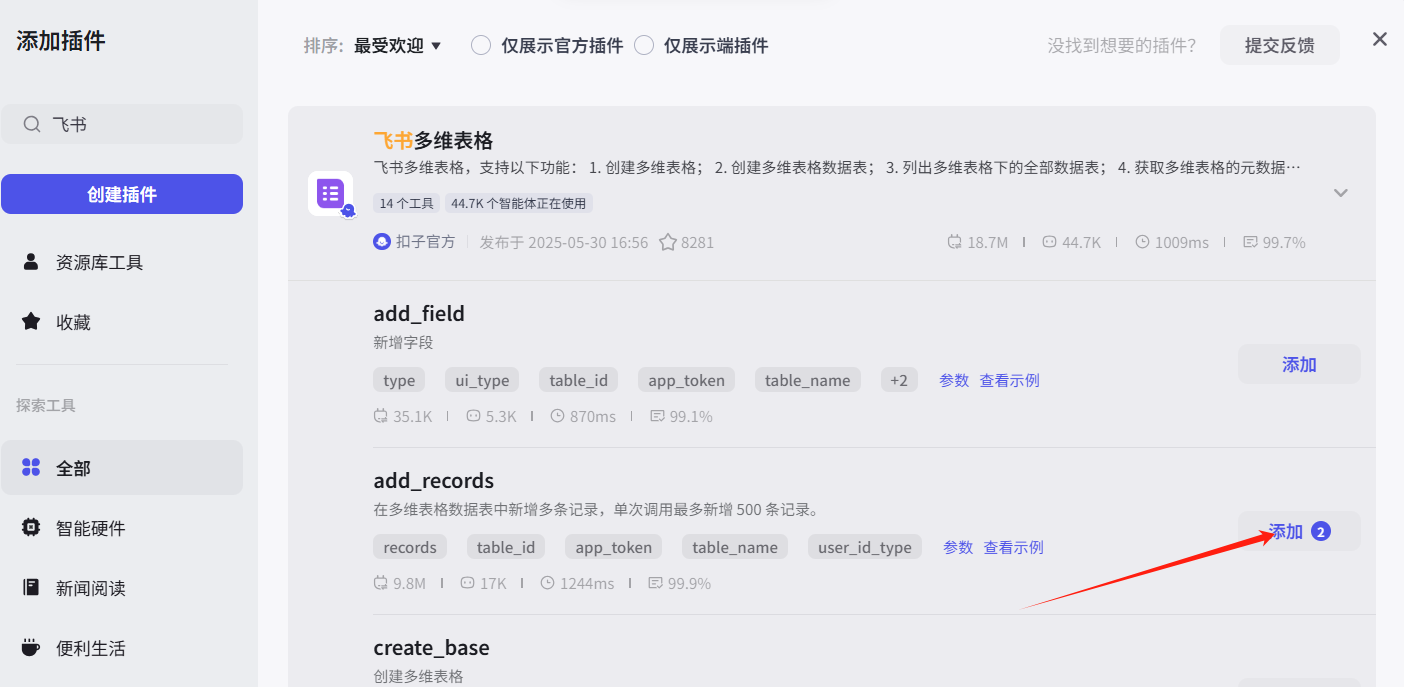
(授权一路跟着操作就行,这里不再演示了)
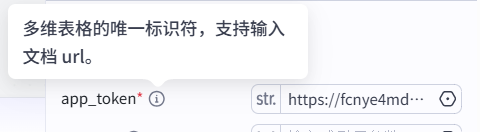
这里需要先获取下app_token(表格的url链接)
访问:飞书多维表格,创建一下账号,新建一个多维表格,再按分享,复制链接,获取app_token如图:
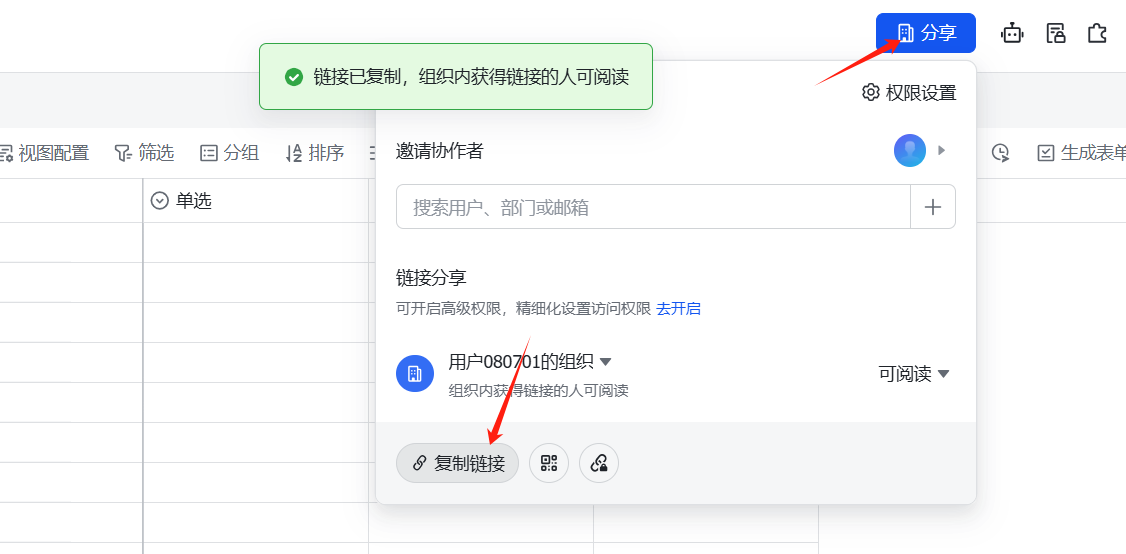
然后把这个链接丢给智能体里的app_token即可。
同时再将表格标题变成这样: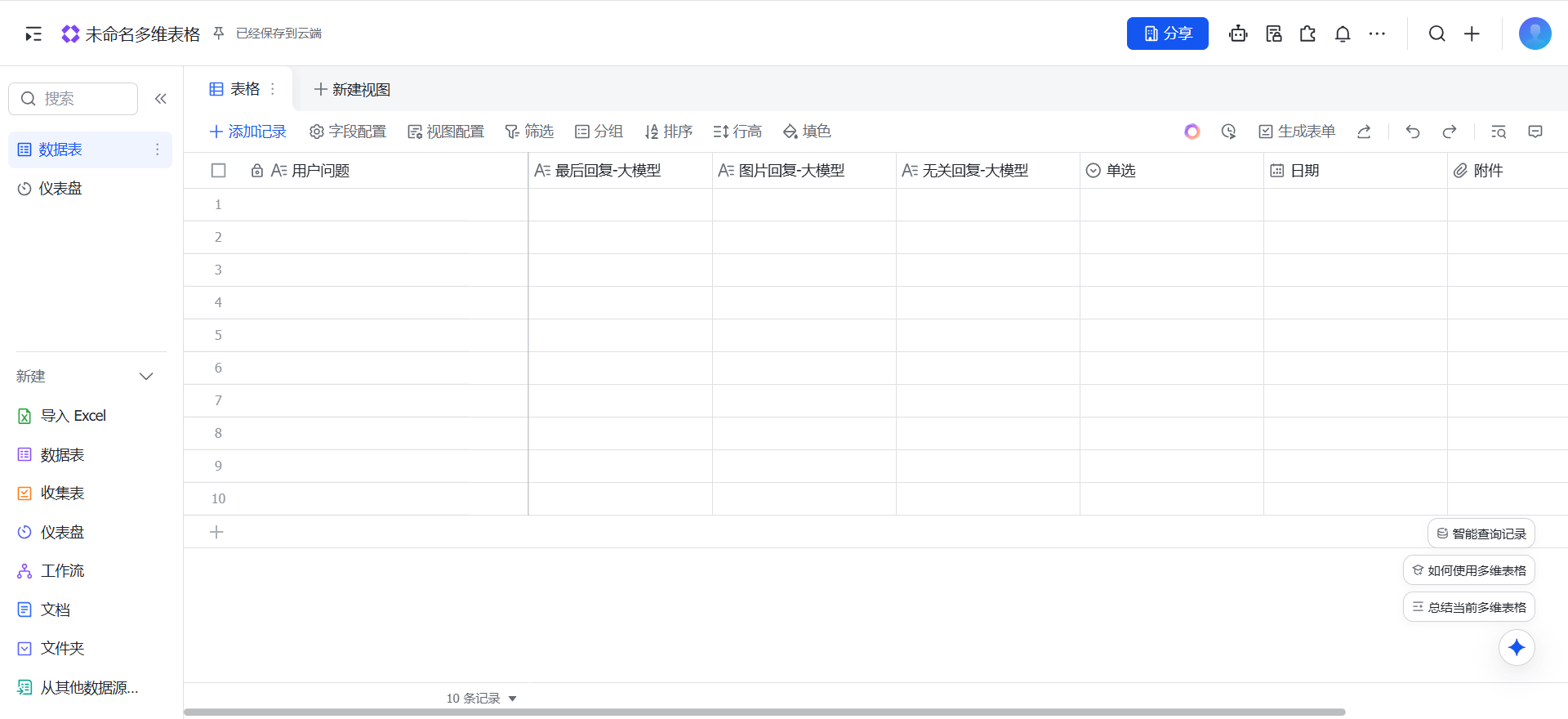
看一眼coze里的其他字段:
不太直观,我们这样看:
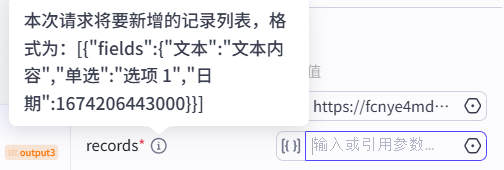
直观了,把对应fields改成我们应变成的形式: 这就是我们应该输入的。
这就是我们应该输入的。
但很明显,现在的传入参数不是这种,需要加点料改改格式,选择代码节点放进来:
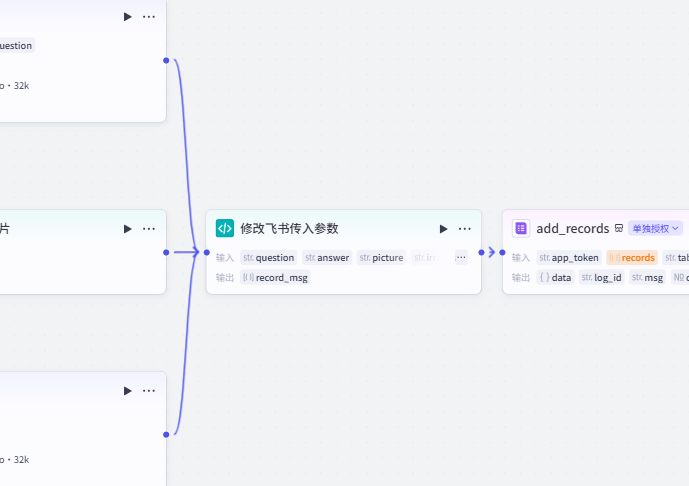
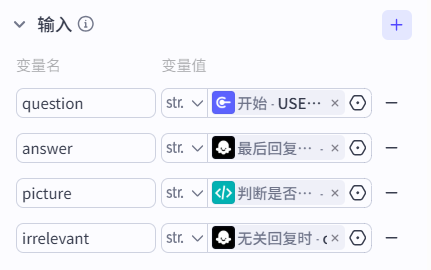
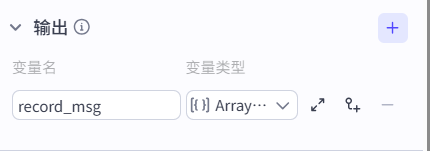
这里注意:
在进代码写作前,务必要先把这些外部的输入输出全部写好再进去,不然你在写代码时还想操作外面的,是导不进来而且会报错的。
代码如下:
# 在这里,您可以通过 'args' 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为'input'的值:
# params = args.params;
# input = params['input'];
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": '小明', "hobbies": ["看书", "旅游"] };async def main(args: Args) -> Output:params = args.params# 构建输出对象question = params["question"]answer = params["answer"]picture = params["picture"]irrelevant = params["irrelevant"]ret: Output = {'record_msg':[{"fields":{'用户问题':question,'最后回复-大模型':answer,'图片回复-大模型':picture,'无关回复-大模型':irrelevant}}]}return ret最后运行看效果如何:
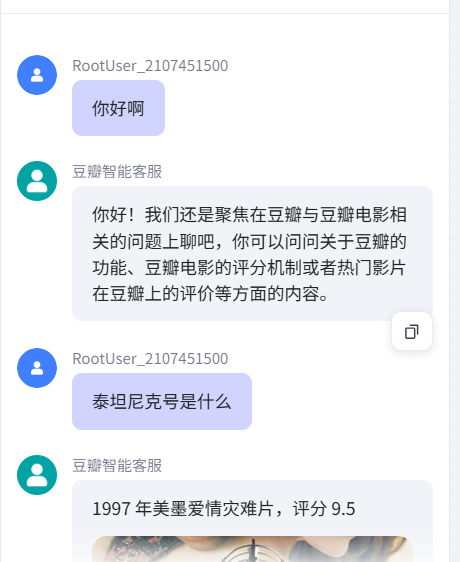
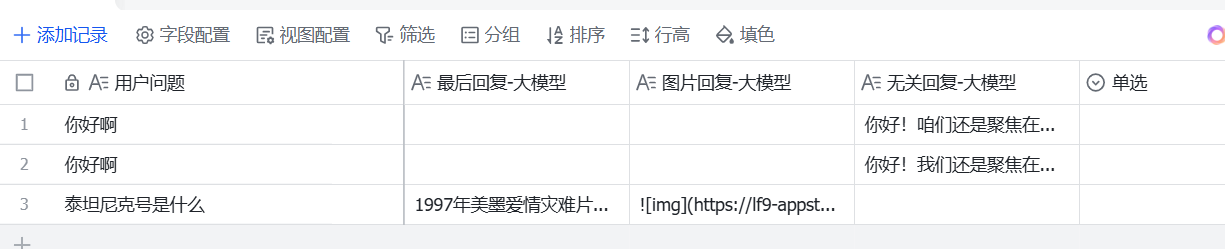
录入没问题,工作完成。
六、小结
至此,我们完整完成了一个豆瓣智能客服的智能体构建,它涵盖了知识库检索、上下文判断、无关逻辑分析、问答数据实时录入等功能,同时还涉及了一些低代码以及整体架构思路的设计。
虽然这个智能体可能还比较糙,离真正的商业化还比较远,但这已经是入门了一大步。有了本文的基础再开始做其他方向的智能体会简易上很多。
这里强烈建议把这篇文章看完并扎实复盘实操一遍,感受一下低代码创建的魅力所在。