论文理解:Reflexion: Language Agents with Verbal Reinforcement Learning
你是否也和我一样好奇,语言模型能否像人类那样从失败中学习,而不是一遍遍地重新训练自己?在传统强化学习中,我们常常依赖大量样本和昂贵的微调。而这篇论文提出的 Reflexion 框架,则展示了一种不依赖参数更新的巧妙方法:让模型“口头反思”——用一句话总结失败,在下一轮尝试中吸取经验,这样的大脑仿佛能写作业时自我点评一样高效、可解释。
方法核心:语言反馈驱动强化,而非梯度更新
-
Reflexion 的关键是——不通过微调模型,而是采用语言形式“强化”决策。
-
每次失败后,Self-Reflection 模型会生成一句话反思(例如:“我错认了物品没有拿到,下一次应该检查是否真正拿到”),将其存入记忆,用来引导下一次动作。
-
这种“语言反思”被视为一种 语义梯度(semantic gradient),提供比传统标量反馈更具指导性的信号。
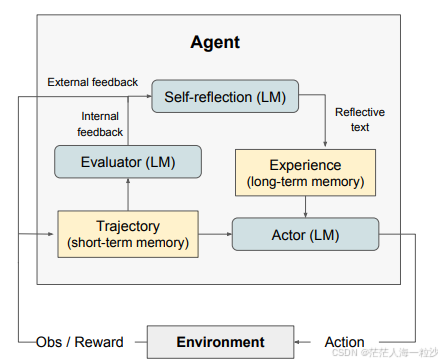
架构揭秘:三个角色协同合作
-
Actor:负责生成行为或文本,让 LLM 扮演策略网络。
-
Evaluator:评估行为正确性,可以是简单规则或另一个 LLM 实现。
-
Self-Reflection:失败后生成反思总结,补充上下文记忆。
同时设置短期记忆(当前轨迹)与长期记忆(反思语句),通过 API 每轮交互不断积累经验,记忆上限通常为 1–3 条反思记录。
实验亮点:多任务,多场景,稳健提升
-
AlfWorld(复杂文本环境决策):
-
Reflexion + ReAct 在 12 次训练内完成 130/134 个任务,远超 ReAct 作初始尝试的效果。
-
自反思机制能快速识别错误原因,例如“错以为拿到物体”但其实没拿到,从而修正行为路径。
-
-
HotPotQA(多文档推理问答):
-
在没有提供上下文的情况下加入反思机制,准确率显著提升(CoT + Reflexion 最高提升约 14%)。
-
引入 Episodic Memory(记忆机制)还额外带来约 8%收益。
-
-
HumanEval 编程任务(代码生成与测试):
-
Reflexion 在 pass@1 指标上达到了 91%,超过 GPT-4 的 80%;Rust、MBPP、LeetCode Hard 也有显著提升。
-
Reflexion 有何魅力?
-
节省算力:无须微调,只需 prompt 设计即可无缝接入大模型。
-
反馈可解释:每条反思都是可读的自然语言,有助于调试与理解决策过程。
-
可迁移能力强:反思逻辑具通用性,可应用于不同任务类型。
-
人类式学习思维:像学生写错题后的自我反思,逐步改进策略。
小结与前瞻
Reflexion 让我们看到了一个新范式:让模型“用语言思考”,在对话记忆中逐步提升,而不是反复训练。这不仅成本低廉,还更灵活、解释性更强。未来,或许可以把这种“语言回炉”的机制与传统值学习、策略优化结合,让 LLM 学得更快、更稳。
参考资料
https://arxiv.org/pdf/2303.11366
NeurIPS Poster Self-Refine: Iterative Refinement with Self-Feedback