TLSF内存算法适配HTOS
TLSF 内存分配算法详解
在本人写的HTOS基础上进一步优化了原本的静态堆内存分配方法,使用了TLSF进行内存分配,在快速随机分配压测实测下不会出现异常情况。
代码开源于:https://github.com/yeyue1/HTOS

1. 概念简介
TLSF(Two-Level Segregated Fit)是一种面向实时系统的动态内存分配器设计,旨在在分配(malloc)和释放(free)操作上提供恒定时间复杂度 O(1) 的响应时间,同时保持较低的内部/外部碎片。TLSF 由 Matthew Wilson 等人提出,常用于嵌入式或实时系统中对延迟有严格要求的场景。
核心思想:通过两级分离空闲列表(一级按区间级别划分,二级按子区间细分)并结合位图(bitmap)快速定位合适的空闲块,从而将查找时间限定为常数级别。
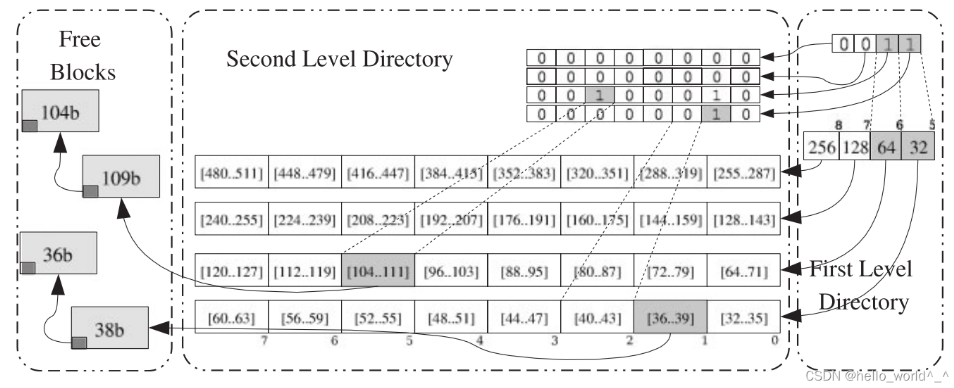
这是从网上找的一个示例。很好的解释了TLSF算法是如何进行分配内存的。
2. 设计目标
- 分配和释放的最坏时间复杂度为 O(1)。
- 低延迟抖动(低抖动性),适合实时系统。
- 保持合理的内存利用率与碎片控制。
- 简单的分离列表与位图实现,便于在资源受限设备上部署。
3. 基本数据结构
TLSF 的关键数据结构包括:
-
Block(内存块)
- 每个块有一个头部,通常包含块大小(带标志位,如“是否已使用”)、前一物理块的大小或指针(用于快速合并)等。
- 空闲块会包含用于链表的指针(next_free / prev_free)。
-
两级索引(FL/SL)
- FL(First Level index):按块大小的高阶位分组,通常类似对数分组(例如按 2 的幂划分区间)。
- SL(Second Level index):在每个 FL 组内细分成若干子区间,用于更精细的匹配。
-
空闲列表数组:一种二维数组或等价结构,索引为 [FL][SL],每个单元保存对应大小区间的空闲块链表头。
-
位图(bitmaps)
- FL bitmap:记录哪些 FL 索引目前有空闲块(用于快速跳转到下一个非空 FL)。
- 对每个 FL 的 SL bitmap:记录该 FL 下哪些 SL 有空闲块。
这些位图通常用原子或整数操作维护,从而能以常量时间查找下一个可用区间。
4. 大小到索引的映射(核心映射函数)
将请求大小 size 映射到 (fl, sl):
- 如果 size 小于最小可分配块(min_block_size),就上调到 min_block_size(并对齐)。
- fl = floor_log2(size)(找到 size 的最高位,表示大概的2的幂);
- 在该 fl 下,用 size 的低位来计算 sl(即 size 在 [2^fl, 2^{fl+1}) 区间内的偏移),常见做法是:
- normalization = size - 2^fl
- sl = normalization >> (fl - SL_BITS)
其中 SL_BITS 是二级分割的位数(例如 SL_BITS=4 则每个 FL 有 16 个子区间)。
这样可以把连续的大小区间映射到二维索引,保证类似大小被放到同一或相邻的 SL,从而降低碎片和提升命中率。
实现时还有细节:
- 对齐(alignment)会影响映射:在计算索引前先做向上对齐。
- 对于非常大的请求,直接映射到最高 FL,并将 sl 设为某个边界值。
5. malloc(分配)流程(高层)
- 根据请求大小计算适当的 (fl, sl)。
- 在 SL 对应位图中查找当前 SL 或更高 SL 是否存在空闲块(通过先查看 SL bitmap,然后可能向上查找 FL bitmap)。
- 查找过程:先查看该 FL 的 SL 位图(找到 >= sl 的第一个 set 位),若找不到则在 FL 位图中找到下一个有空闲块的 FL,然后在其 SL 位图中查找第一个 set 位。
- 找到目标空闲块后,从对应链表中移除它。
- 如果块比请求大小大很多,可以拆分:保留一部分给分配(并标记为已用),剩余部分作为新的空闲块放入合适的 FL/SL。
- 返回用户指针(通常是块头之后的地址)。
伪代码(简化):
- alloc(size):
- size = align_up(max(size, min_block_size))
- (fl, sl) = size_to_index(size)
- (fl2, sl2) = find_suitable(fl, sl) // O(1) via bitmaps
- if not found: return NULL
- block = remove_free_block(fl2, sl2)
- if block.size - size >= min_split_size: split block and insert remainder
- mark block as used
- return block_to_user_ptr(block)
6. free(释放)流程(高层)
- 将块标记为自由。
- 与前后物理邻居检查是否为空闲块;如果是则合并(coalesce)为更大的空闲块。
- 将合并后的空闲块插入到对应的 FL/SL 空闲链表,并在位图上置位相应 bit。
伪代码(简化):
- free(ptr):
- block = user_ptr_to_block(ptr)
- mark block as free
- if prev_phys_is_free: block = merge(prev, block)
- if next_phys_is_free: block = merge(block, next)
- (fl, sl) = size_to_index(block.size)
- insert_free_block(block, fl, sl)
- set_bitmap(fl, sl)
7. 为什么是 O(1)?
- 位图允许用常数时间的位运算(比如 ffs / clz / tzcnt)来找到第一个置位。查找空闲 FL 与 SL 都是常量复杂度的位操作。插入和删除空闲块是链表操作,也是 O(1)。
- 由于所有步骤(索引计算、位图查找、链表插入/删除、可能的拆分/合并)都是常数次操作,所以算法满足在最坏情形下的常数时间上限(在实现上依赖常数级 SL 数量与有效的位扫描指令)。
8. 实现细节与注意点
-
对齐和最小块大小
- 必须定义对齐(如 4 或 8 字节)并在所有请求上生效。最小块大小应能容纳空闲链表指针和必要头信息。
-
块头和标志位
- 通常把 “已用” 标志藏在大小字段的低位(利用对齐保证低几位为 0)。保存前一块是否空闲的信息可以通过前一块的大小或其他字段实现,便于合并。
-
位图实现
- FL bitmap 的位宽等于 FL 数量(例如如果支持 32 个 FL,用一个 32 位整数即可)。
- SL 位图对每个 FL 保持一段位图(例如 16 或 32 位)。
- 查找第一个 set 位需要高效指令:在 x86 中可使用 _BitScanForward / __builtin_ctz 等;在没有硬件支持的平台,可用小查表或手写查找(仍是常数时间,因为 SL 和 FL 的范围固定)。
-
内存边界与大块处理
- 对超出最大可索引范围的请求,可专门处理(例如直接放入单独的“超大块”链表,或将其映射到最高 FL)。
-
并发/多线程
- 原始 TLSF 设计面向单线程或需要外部同步的场景。若在多线程环境中使用,需要在 allocator 层加锁或使用更精细的锁分离策略(例如按 FL 分段锁),或者设计无锁变体(复杂且难以保证在任意平台上的 O(1) 原子性)。
-
可移植性
- TLSF 的常数时间假设依赖于能以 O(1) 找到位图第一个 set 位的操作。某些编译器/架构可能没有高效内建指令,这时实现者需要使用小范围查找表来保持常数时间属性。
9. 边界情况与常见陷阱
- 内存耗尽:find_suitable 可能无法找到合适块,应返回 NULL 并在上层处理。
- 频繁的小碎片:虽然 TLSF 减少了查找时间,但碎片仍可能在极端分配模式下出现,需结合拆分/合并策略与最小块控制来缓解。
- 对齐需求很高的请求:可能导致内部碎片增多。
- 多线程并发导致的竞态:必须一并考虑同步策略。
10. 小示例(参数说明)
- 假设:SL_BITS = 4(每个 FL 有 16 个 SL),最小对齐 8 字节。
- 请求 200 字节:
- 找到 fl = floor_log2(200) = 7(2^7 = 128)
- normalization = 200 - 128 = 72
- sl = normalization >> (7 - 4) = 72 >> 3 = 9
- 索引到 (fl=7, sl=9),在该单元或更高单元中查找第一个空闲块。
11. 性能与应用场景
-
优点:
- 实时性好,最坏时间复杂度可控(O(1))。
- 分配/释放延迟低、抖动小,适合对时延敏感的系统(RTOS、嵌入式)。
- 实现相对简单,空间开销由位图与空闲链表引入,但通常可控。
-
缺点:
- 并发支持需额外工作。
- 对极端碎片模式并不能完全避免碎片产生。
- 在没有快速位扫描指令的平台上,常数时间的实现需要额外工作(查表等)。
-
常见使用场景:实时操作系统(RTOS)、嵌入式系统、游戏引擎某些子系统、低延迟服务。
12. 与其他分配器比较
- ptmalloc(glibc 的 malloc)和 jemalloc:这些通常优化了总体吞吐量与多线程并发,在一般用途下表现优秀,但最坏时间通常不是 O(1),可能不适合硬实时约束。
- dlmalloc:是常见的通用分配器,注重平均性能与空间利用。
- TLSF:在需要对延迟有严格上界时更合适,但不是对吞吐量或多线程场景的万能最优解。
13. 参考与进一步阅读
- TLSF 原始论文 / 报告(英文):Matthew Wilson 等人的 “TLSF: A Dynamic Memory Allocator for Real-Time Systems”(可在线检索以阅读详尽实现细节与证明)。
- 开源实现:有若干开源 TLSF 实现,可在 GitHub 上搜索 “tlsf allocator” 以获取示例代码与移植版本。
14. 总结
TLSF 是一种为实时/嵌入式场景设计的分配器,通过二级分离的空闲列表和位图实现,能将分配与释放的最坏时间限定为常数 O(1)。实现时的关键点是合理设计 FL/SL 映射、位图实现、块头布局及对齐与拆分/合并策略。对于需要确定性延迟的系统,TLSF 是一个优秀的选择。