MySQL的utf8 、utf8mb3 和 utf8mb4 的区别和排序规则
官网说明:https://dev.mysql.com/doc/refman/8.0/en/charset-unicode.html
MySQL常用字符集说明
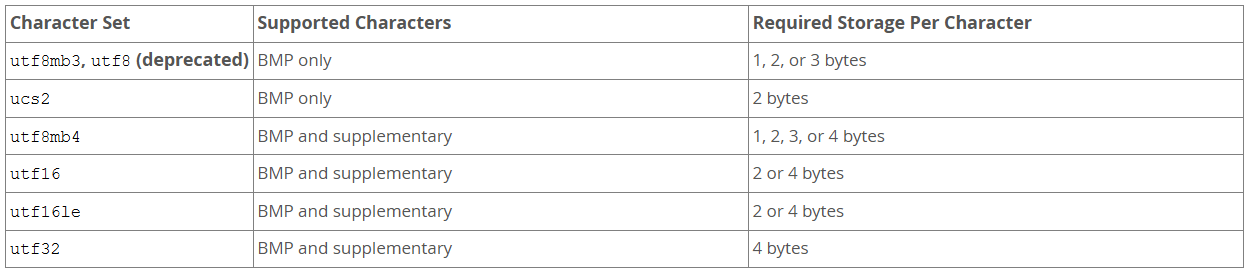
utf8
utf8是utf8mb3的别名,除此之外并无不同,并且utf8已经弃用。
utf8mb3
只支持最长三个字节的BMP(Basic Multilingual Plane,基本多文种平面)字符(不支持补充字符)。

utf8mb4
mb4即 most bytes 4,即最多使用4个字节来表示完整的UTF-8,具有以下特征:
- 支持BMP和补充字符。
- 每个多字节字符最多需要四个字节。
它是utf8的超集并完全兼容它,是MySQL 在 5.5.3 版本之后增加的一个新的字符集,能够用四个字节存储更多的字符,几乎包含了世界上所有能看到见的语言字符。

比较
排序规则
介绍
排序规则(collation),字符串在比较和排序时所遵循的规则。不同的字符集有不同的排序规则,同一个字符集也可以有多种排序规则。在 MySQL 8.0.1 及更高版本中将 utf8mb4_0900_ai_ci(属于 utf8mb4_unicode_ci 中的一种) 作为默认排序规则,在这之前 utf8mb4_general_ci 是默认排序规则。
MySQL常用的排序规则
MySQL常用排序规则有:utf8mb4_general_ci、utf8mb4_unicode_ci、utf8mb4_bin、utf8mb4_0900_ai_ci
- _bin : 按二进制方式比较字符串,区分大小写和重音符号。
- _ai_ci:按照特定语言或地区方式比较字符串,不区分大小写和重音符号。
- _unicode_ci: 按 Unicode 标准方式比较字符串,不区分大小写和重音符号。
- _general_ci:按一般方式比较字符串,不区分大小写和重音符号。
ci:即case insensitive,不区分大小写,即排序时 p 和 P相同 。
ai:指口音不敏感,即排序时 e,è,é,ê 和 ë 相同。
as:即口音敏感,也就是说,排序时 e,è,é,ê 和 ë 互不相同。
0900: 是 Unicode 校对算法版本。
utf8mb4_unicode_ci 和 utf8mb4_general_ci 的区别
utf8mb4_unicode_ci: 能够在各种语言之间精确排序,Unicode排序规则为了能够处理特殊字符的情况,实现了略微复杂的排序算法。
utf8mb4_general_ci: 不支持扩展,它仅能够在字符之间进行逐个比较。utf8_general_ci 比较速度很快,但比 utf8mb4_unicode_ci 的准确性稍差一些。
准确性
utf8mb4_unicode_ci 是精确排序,utf8mb4_general_ci 没有实现 Unicode 排序规则,在遇到某些特殊语言或者字符集,排序结果可能不一致。
因此,准确性是utf8mb4_unicode_ci > utf8mb4_general_ci
性能
utf8mb4_general_ci 在比较和排序的时候更快。
utf8mb4_unicode_ci 在特殊情况下,Unicode 排序规则为了能够处理特殊字符的情况,实现了略微复杂的排序算法。
因此,性能方面是utf8mb4_general_ci > utf8mb4_unicode_ci
如何选择?
如果在创建数据库时对特殊字符的顺序并不需要那么精确,排序规则可使用utf8mb4_general_ci 。推荐用 utf8mb4_unicode_ci,但是用 utf8mb4_general_ci 也没问题
以上内容借鉴了:https://blog.csdn.net/Lo_CoCo_vE/article/details/132084412