Shell 秘典(卷八)—— 万流归宗秘术・AWK 通玄真解
文章目录
- 前言
- 一、概述
- 1.1 什么是 AWK?
- 1.2 应用场景
- 二、工作原理
- 2.1 逐行处理机制
- 2.2 awk 与 sed 的区别
- 三、基本语法与命令格式
- 3.1 命令格式
- 3.2 常用选项
- 四、内置变量
- 五、常用操作示例
- 5.1 打印整行或指定字段
- 5.2 条件匹配与过滤
- 5.3 使用 BEGIN 和 END 块
- 5.4 模糊匹配
- 5.5 数学运算
- 5.6 条件判断与逻辑运算
- 5.7 其他内置变量的用法
- 六、高级功能
- 6.1 awk 高级用法 if语句
- 6.2 awk 综合案例
- 6.3 awk 数组
- 七、实际应用案例
- 7.1 查看当前内存使用百分比
- 7.2 查看当前CPU空闲率
- 7.3 统计在线用户数
- 7.4 输出当前的主机名
- 7.5 查看CPU使用率
- 总结
前言
AWK 一脉,乃文本处理界的玄门重器,其法源于上世纪七十年代贝尔仙府,自诞生便肩负 “扫文本迷雾、滤数据杂质、统信息脉络、汇零散真机” 之重任。凡标准输入之流、管道传导之息、文件封存之秘,皆可凭其术拆解剖析。
如今在 CentOS 7 等现世 Linux 洞天中,此术已演化出 GNU 一脉的精进版本 gawk,威力更胜往昔。本文将循 “筑基 - 炼气 - 化神” 之序,详解 AWK 秘术的基础诀要、内置灵窍、高阶神通及实战玄案,助修士勘破文本迷障,洞悉数据真机,彻悟此门秘术的核心真意。
一、概述
1.1 什么是 AWK?
AWK 是一种处理文本文件的编程语言,其名称来源于三位创始人 Alfred Aho、Peter Weinberger 和 Brian Kernighan 的姓氏首字母。该语言支持从标准输入、管道或文件中获取数据,它被设计用于对文本数据进行扫描、过滤、统计和格式化输出。
1.2 应用场景
- 日志分析
- 数据提取与转换
- 报表生成
- 系统监控脚本
二、工作原理
2.1 逐行处理机制
awk 逐行读取输入文本,默认以空格或制表符(Tab)作为字段分隔符,将每行分割成多个字段,并存储到内置变量中。用户可定义模式或条件,对匹配的行执行相应操作。
处理流程如下:
- 读取第一行数据
- 检查是否匹配条件
- 若匹配则执行指定动作
- 继续处理下一行数据
- 默认不自动输出结果
若未定义匹配条件,则默认处理所有行。由于awk内置循环机制,条件匹配次数与动作执行次数完全对应。
2.2 awk 与 sed 的区别
sed主要用于整行处理;awk更倾向于将行拆分为字段后再进行处理,支持更复杂的字段级操作。
awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。
在使用awk命令的过程中,可以使用逻辑操作符&&表示"与"、||表示"或"、!表示"非";
还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
三、基本语法与命令格式
3.1 命令格式
awk [options] 'BEGIN{ print "start" } ‘pattern{ commands }’ END{ print "end"}' file
#其中:BEGIN END 是 AWK 的关键字部,因此必须大写;这两个部分开始块和结束块是可选的或者:
awk -f 脚本文件 文件1 文件2 ...
3.2 常用选项
-F:指定字段分隔符;-v:定义变量;-f:指定 AWK 脚本文件。
四、内置变量
awk 包含几个特殊的内建变量(可直接用)如下所示:
| 变量名 | 说明 |
|---|---|
FS | 输入字段分隔符,默认为空格或制表符 |
OFS | 输出字段分隔符,默认为空格 |
NF | 当前处理的行的字段个数 |
NR | 当前处理的行的行号(序数) |
FNR | 当前文件中的行号(多文件处理时重置) |
$0 | 当前行的完整内容 |
$n | 当前行的第 n 个字段 |
FILENAME | 当前处理的文件名 |
RS | 输入行分隔符,默认为换行符 |
ORS | 输出行分隔符,默认为换行符 |
五、常用操作示例
以下案例中使用zz和pass.txt进行演示。
# 创建 zz 文件
cat > zz << 'EOF'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
hello world
EOF# 创建 pass.txt 文件
cat > pass.txt << 'EOF'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
EOF
5.1 打印整行或指定字段
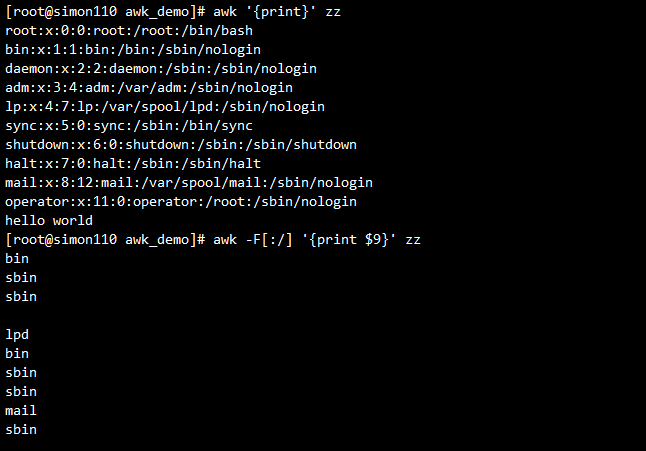
awk '{print}' zz # 打印所有行
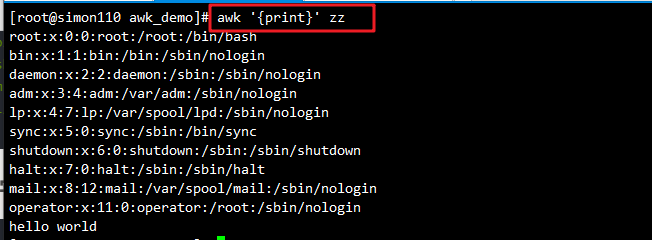
awk '{print $1}' zz # 打印每行第一列
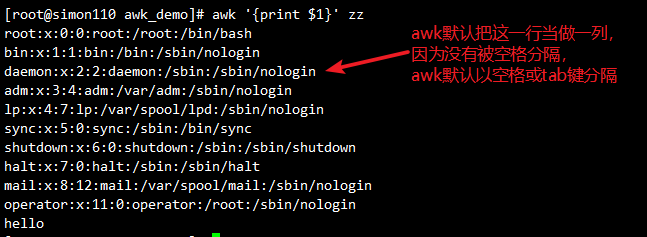
awk -F: '{print $5}' zz #自定义冒号为分隔符显示分隔之后的第五列(属主那一列)
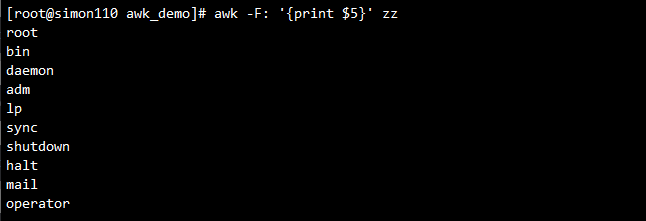
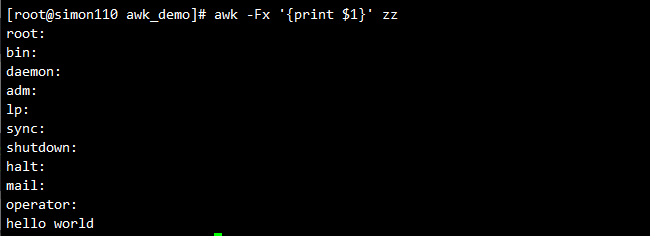
awk -Fx '{print $1}' /etc/passwd #用x作为分隔符
awk '{print $1" "$2}' zz #显示一个空格,空格需要用双引号引起来,如果不用引号默认以变量看待,如果是常量就需要双引号引起来
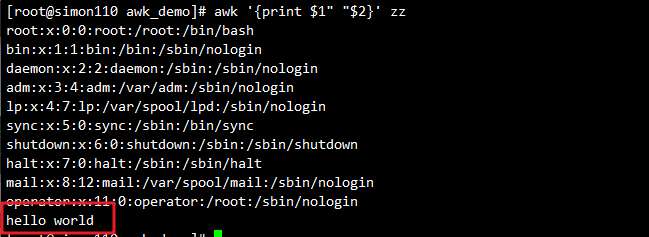
awk '{print $1,$2}' zz #逗号有空格效果
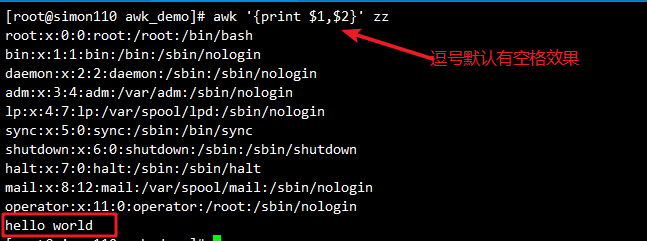
awk -F: '{print $1"\t"$2}' /etc/passwd #用制表符作为分隔符输出
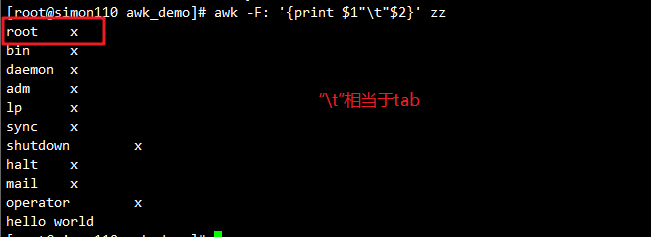
awk -F[:/] '{print $9}' zz #定义多个分隔符,只要看到其中一个都算作分隔符
5.2 条件匹配与过滤
awk '/root/' /etc/passwd # 打印包含root的行

awk -F: '/root/{print $0}' pass.txt # 打印包含root的整行内容

awk -F: '/root/{print $1}' pass.txt # 打印包含root的行的第一列

awk -F: '/root/{print $1,$6}' pass.txt #打印包含root的行的第一列和第六列

awk -F[:/] '{print NF}' zz #打印每一行的列数

awk -F[:/] '{print NR}' zz #显示行号

awk -F: '{print NR,$0}' pass.txt #冒号为分隔符读取pass.txt文件,输出每行内容并附加行号

awk 'NR==2' pass.txt #打印第二行,不加print也可以,默认是打印
awk 'NR==2{print}' pass.txt #同上效果

awk -F: 'NR==2{print $1}' /etc/passwd #打印第二行的第一列

awk -F: '{print $NF}' /etc/passwd #打印最后一列

awk 'END{print NR}' pass.txt #打印总行数

awk 'END{print $0}' pass.txt #打印文件最后一行

awk -F: '{print "当前行有"NF"列"}' pass.txt

awk -F: '{print "第"NR"行有"NF"列"}' pass.txt #第几行有几列

扩展生产案列:网卡的ip、流量
###扩展生产:网卡的ip、流量
ifconfig ens33 | awk '/netmask/{print "本机的ip地址是"$2}'
ifconfig ens33 | awk '/RX p/{print $5"字节"}'

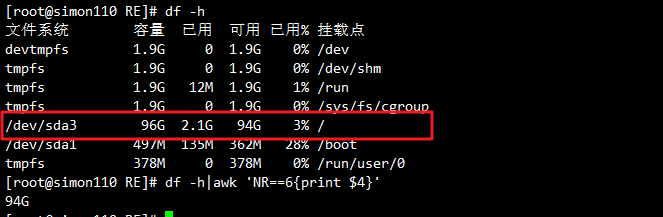
#根分区的可用量
df -h | awk 'NR==6{print $4}' #行号根据自己的电脑磁盘判断

5.3 使用 BEGIN 和 END 块
逐行执行开始之前执行什么任务,结束之后再执行什么任务,用BEGIN、END
- BEGIN一般用来做初始化操作,仅在读取数据记录之前执行一次
- END一般用来做汇总操作,仅在读取完数据记录之后执行一次
工作流程:
1、运行BEGIN{ commands }语句块中的语句。
2、从文件或标准输入(stdin)读取一行。然后运行pattern{ commands }语句块,它逐行扫描
文件,从第一行到最后一行反复这个过程。直到文件所有被读取完成。
3、当读至输入流末尾时,运行END{ commands }语句块。
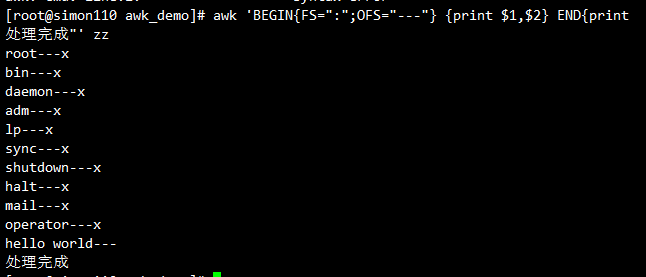
# 以:作为分隔符,打印第1列和第2列,输出的分隔符为---
awk 'BEGIN{FS=":";OFS="---"} {print $1,$2} END{print "处理完成"}' zz
5.4 模糊匹配
模糊匹配,用~表示包含,!~表示不包含
awk -F: '$1~/root/' /etc/passwd #从/etc/passwd文件中筛选出以冒号分隔后第一个字段包含root的行

awk -F: '$1~/ro/' /etc/passwd #在/etc/passwd文件中查找并输出首列(用户名)包含字符串"ro"的所有行,字段分隔符为冒号

#筛选/etc/passwd文件中登录shell不是nologin的用户,输出其用户名和对应的shell路径。
awk -F: '$7!~/nologin$/{print $1,$7}' /etc/passwd

5.5 数学运算
awk 'BEGIN{x=10;print x}' #如果不用引号awk就当作一个变量来输出了,所以不需要加$了
awk 'BEGIN{x=10;print x+1}' #BEGIN在处理文件之前,所以后面不跟文件名也不影响
awk 'BEGIN{x=10;x++;print x}' #自加操作,输出11

awk 'BEGIN{print x+1}' #不指定初始值,初始值就为0,如果是字符串,则默认为空

awk 'BEGIN{print 2.5+3.5}' #小数也可以运算
awk 'BEGIN{print 2-1}'
awk 'BEGIN{print 3*4}'

awk 'BEGIN{print 3**2}' #3的2次方
awk 'BEGIN{print 2^3}' #^和**都是幂运算
awk 'BEGIN{print 1/2}' # 除法

5.6 条件判断与逻辑运算
- 关于数值与字符串的比较
比较符号:==、!=、 <=、>=、 <、 > - 逻辑运算:&& ||
awk 'NR==5{print}' /etc/passwd #打印第5行
awk 'NR==5' /etc/passwd

awk 'NR<5' /etc/passwd # 打印小于5行的内容

awk -F: '$3==0' /etc/passwd #查找/etc/passwd文件中用户ID(UID)为0的账户
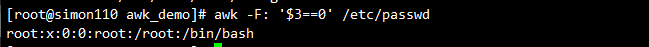
awk -F: '$1==root' /etc/passwd #在awk中,字符串需要用双引号或单引号括起来,否则会被当作变量处理
awk -F: '$1=="root"' /etc/passwd #精确匹配是root

awk -F: '$3>=1000' /etc/passwd #列出/etc/passwd文件中UID(用户ID)大于或等于1000的普通用户(非系统用户)账户信息

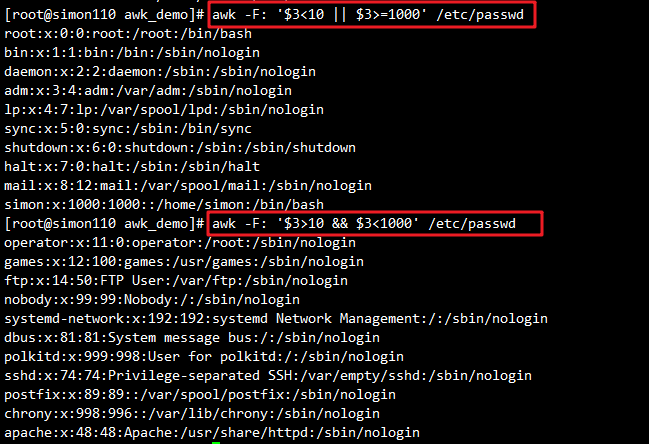
awk -F: '$3<10 || $3>=1000' /etc/passwd #筛选/etc/passwd文件中用户ID小于10(系统用户)或大于等于1000(普通用户)的行
awk -F: '$3>10 && $3<1000' /etc/passwd
awk -F: 'NR>4 && NR<10' /etc/passwd #打印/etc/passwd文件中第5到第9行

案例:
打印1-200之间所有能被7整除并且包含数字7的整数数字
seq 200|awk '$1%7==0 && $1~7'

5.7 其他内置变量的用法
- FS:输入字段的分隔符 默认是空格
- OFS:输出字段的分隔符 默认也是空格
- FNR:读取文件的记录数(行号),从1开始,新的文件重新重1开始计数
- RS:输入行分隔符 默认为换行符
- ORS:输出行分隔符 默认也是为换行符
awk 'BEGIN{FS=":"}{print $1}' pass.txt #在打印之前定义字段分隔符为冒号
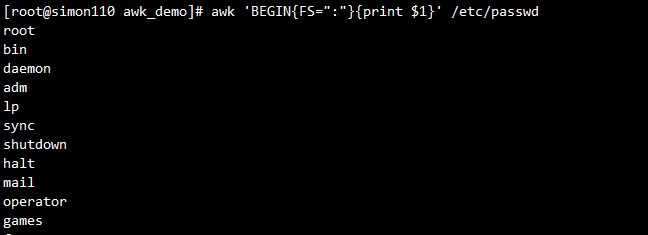
awk 'BEGIN{FS=":";OFS="---"}{print $1,$2}' /etc/passwd #OFS定义了输出时以什么分隔,$1$2中间要用逗号分隔,因为逗号默认被映射为OFS变量,而这个变量默认是空格
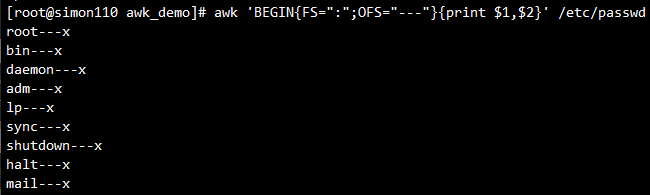
awk '{print FNR,$0}' /etc/resolv.conf /etc/hosts #可以看出FNR的行号在追加当有多个文件时的差异
awk '{print NR,$0}' /etc/resolv.conf /etc/hosts
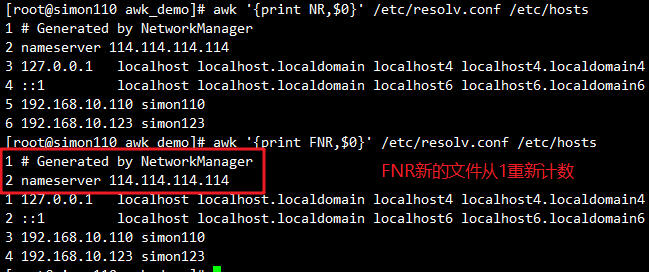
awk 'BEGIN{RS=":"}{print $0}' /etc/passwd #RS:指定以什么为换行符,这里指定是冒号,你指定的肯定是原文里存在的字符
awk 'BEGIN{ORS=" "}{print $0}' /etc/passwd #把多行合并成一行输出,输出的时候自定义以空格分隔每行,本来默认的是回车键
六、高级功能
6.1 awk 高级用法 if语句
awk的if语句也分为单分支、双分支和多分支
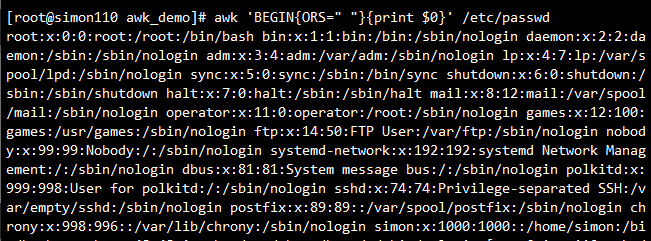
awk -F: '{if($3<10){print $0}}' /etc/passwd #第三列小于10的
打印整行
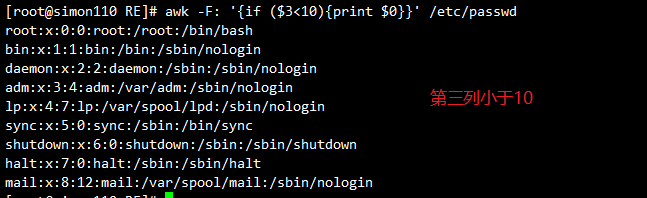
awk -F: '{if($3<10){print $3}else{print $1}}' /etc/passwd
#第三列小于10的打印第三列,否则打印第一列
6.2 awk 综合案例
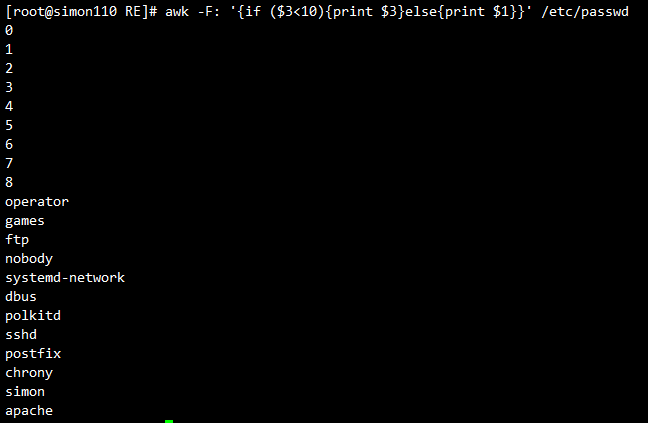
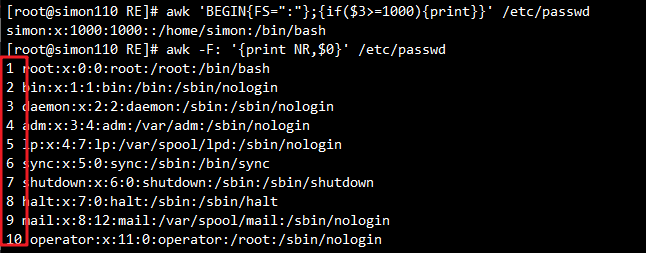
awk 'BEGIN{x=0};/\/bin\/bash$/ {x++;print x,$0};END{print x}' /etc/passwd
#统计以/ bin/bash结尾的行数,等同于
grep -c "/bin/bash$" /etc/passwd
BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作; awk再处理指定的文本,之后再执行END模式中指定的动作,END{}语句块中,往往会放入打印结果等语句
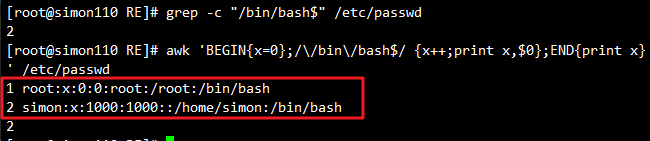
awk -F ":" '! ($3<200){print} ' /etc/passwd
#输出第3个字段的值不小于200的行

awk 'BEGIN {FS=":"} ;{if($3>=1000){print}}' /etc/passwd
#先处理完BEGIN的内容,再打印文本里面的内容

awk -F ":" '{print NR,$0}' /etc/passwd
#输出每行内容和行号,每处理完一条记录,NR值加1
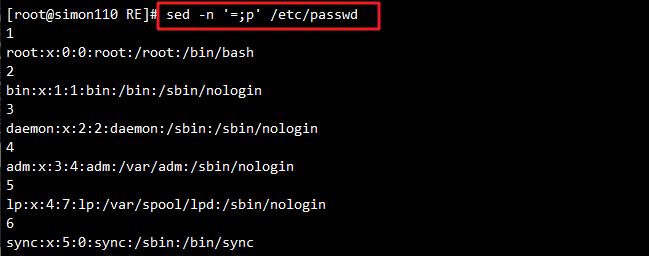
sed -n '=;p' /etc/passwd
awk -F ":" '$7~"bash"{print $1}' /etc/passwd
#输出以冒号分隔且第7个字段中包含/bash的行的第1个字段
awk -F: '/bash/ {print $1}' /etc/passwd

awk -F":" '($1~"root") && (NF==7) {print $1,$2,$NF } '
/etc/passwd
#第1个字段中包含root且有7列的行的第1、2和最后一个个字段

awk -F ":" '($7!="/bin/bash")&&($7!="/sbin/nologin"){print} '
/etc/passwd
#输出第7个字段既不为/bin/bash,也不为/sbin/nologin的所有行

通过管道、双引号调用shell 命令:
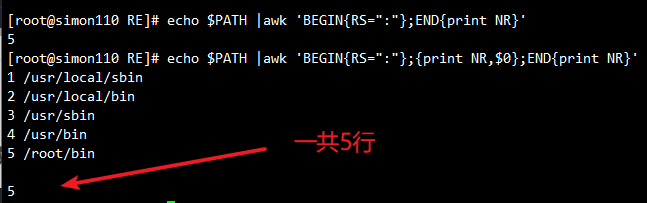
echo $PATH | awk 'BEGIN{RS=":"};END {print NR}'
#统计以冒号分隔的文本段落数,END{ }语句块中,往往会放入打印结果等语句
echo $PATH | awk 'BEGIN{RS=":"};{print NR,$0};END {print NR}'
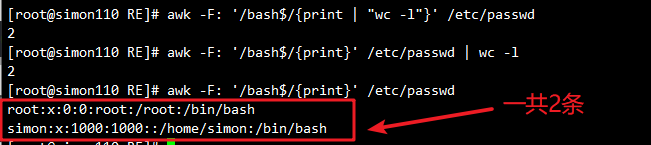
awk -F: '/bash$/{print | "wc -l"}' /etc/passwd
#调用wc -l命令统计使用bash 的用户个数,等同于grep -c "bash$" etc/passwd
awk -F: '/bash$/ {print}' /etc/passwd | wc -l
6.3 awk 数组
PS1:BEGIN中的命令只执行一次
PS2: awk数组的下标除了可以使用数字,也可以使用字符串,字符串需要使用双引号
awk 'BEGIN{a[0]=10;a[1]=20;print a[1]}'
awk 'BEGIN{a[0]=10;a[1]=20;print a[0]}'

awk 'BEGIN{a["abc"]=10;a["xyz"]=20;print a["abc"]}'
awk 'BEGIN{a["abc"]=10;a["xyz"]=20;print a["xyz"]}'
awk 'BEGIN{a["abc"]="aabbcc";a["xyz"]="xxyyzz";print a["xyz"]}'

#结合数组和for循环
awk 'BEGIN{a[0]=10;a[1]=20;a[2]=30;for(i in a){print i,a[i]}}

七、实际应用案例
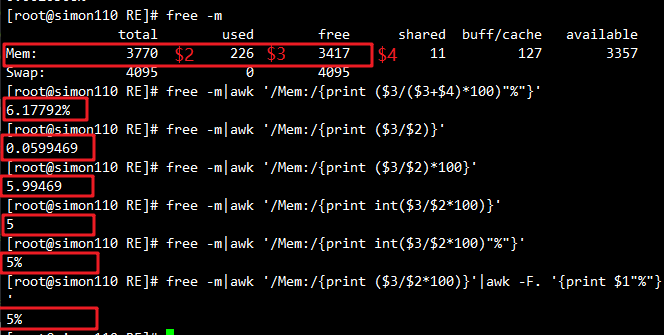
7.1 查看当前内存使用百分比
#查看当前内存使用百分比
free -m
free -m |awk '/Mem:/ {print ($3/($3+$4)*100)"%"}'
free -m | awk '/Mem:/ {print $3/$2}'
free -m | awk '/Mem:/ {print $3/$2*100}'
free -m | awk '/Mem:/ {print int($3/$2*100)}'
free -m | awk '/Mem:/ {print int($3/$2*100)"%"}'
free -m | awk '/Mem:/ {print $3/$2*100}' | awk -F. '{print $1
"%"}'
7.2 查看当前CPU空闲率
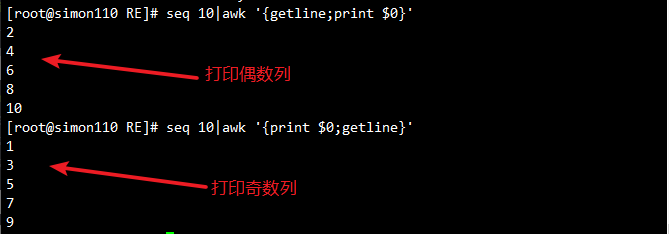
# getline用法:强制读取下一行到 $0(当前记录),跳过原当前行的处理。
seq 10 | awk '{getline; print $0 }'
seq 10 | awk '{ print $0 ; getline } '
top -bn1 | grep Cpu | awk -F ',' '{print $4}'| awk '{print
$1}'
#查看当前CPU空闲率,(-b -n 1表示只需要1次的输出结果)

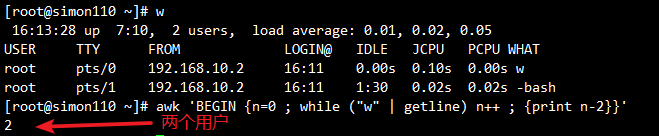
7.3 统计在线用户数
awk 'BEGIN {n=0 ; while ("w" | getline) n++ ; {print n-2}}'
#调用w命令,并用来统计在线用户数
7.4 输出当前的主机名
awk 'BEGIN { "hostname" | getline ; {print $0}}'
#调用hostname,并输出当前的主机名
#当getline左右无重定向符"<"或"|"时,awk首先读取到了第一行,就是1,然后getline,就得到了1下面的第二行,就是2,因为getline之后,awk会改变对应的NE,NR,FNR和$0等内部变量,所以此时的$O的值就不再是1,而是2了,然后将它打印出来。
#当getline左右有重定向符"<"或"|"时,getline则作用于定向输入文件,由于该文件是刚打开,并没有被awk读入一行,只是getline读入,那么getline返回的是该文件的第一行,而不是隔行。

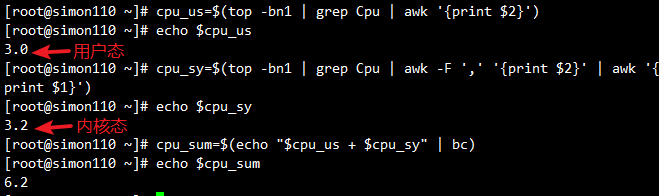
7.5 查看CPU使用率
cpu_us=$(top -bn1 | grep Cpu | awk '{print $2}')
#用户空间程序CPU的占用的比列
cpu_sy=$(top -bn1 | grep Cpu | awk -F ',' '{print $2}' | awk '{print $1}')
# 系统占用的时间比例
cpu_sum=$(echo "$cpu_us + $cpu_sy" | bc)
echo $cpu_sum
总结
AWK 秘术,实乃文本处理域的无上妙法,其灵变之性冠绝同侪,无论 “析文本脉络、取关键真机、炼报表真形” 等诸般要务,皆可从容应对。修士若能通晓其基础法诀、悟透内置灵窍、掌控高阶神通,便可于结构化文本数据的瀚海中纵横捭阖,不仅能精进 shell 符箓的炼制造诣,更可提升执掌 Linux 洞天的统御效率。
无论是日常勘破日志迷阵,还是炼制自动化监控符箓,AWK 秘术皆为 Linux 修行路上不可或缺的本命神通,得此术者,方能在文本处理之道上更进一层,趋近 “万流归宗、数据随心” 的至高境界。
附:常用命令速查表
awk '{print $1}':打印第一列awk -F: '{print $NF}':打印最后一列awk 'NR==1':打印第一行awk 'END{print NR}':打印总行数awk '/pattern/{print $0}':打印匹配模式的行
希望本文能帮助你更好地理解和使用 AWK,进一步提升文本处理能力。