【Day 43】Shell-awk
一、awk 工具概述
awk 是 Linux/Unix 系统中功能强大的文本处理与数据提取工具,其核心优势在于按列分割文本、灵活的条件匹配与格式化输出,广泛用于日志分析、数据统计、配置文件解析等场景。
1、awk 核心作用
- 按自定义分隔符分割文本,提取指定列数据(如从
/etc/passwd提取用户名、Shell 路径); - 基于条件筛选文本(如筛选行号、匹配关键词、数值比较);
- 数据统计与计算(如统计用户 Shell 类型数量、计算日志访问量平均值);
- 格式化输出结果(如对齐列、自定义输出格式)。
2、awk 核心工作流程
awk 按 “行” 处理文本,默认流程如下:
- 读取行:从输入文本/标准输入中逐行读取,赋值给内置变量
$0(未被分割的整行内容); - 分割列:按默认分隔符(空白字符,包括空格、Tab)分割当前行,分割后的数据分别存入
$1(第 1 列)、$2(第 2 列)...$n(第 n 列);若通过 -F 或 FS 指定分隔符,则按指定符号分割; - 匹配 pattern:判断当前行是否满足 pattern(条件),若满足则执行后续操作;若不指定pattern ,则默认处理所有行
- 执行操作:执行 {} 中的命令(如 print 输出、变量计算、数组操作);
- 循环:重复步骤 1-4,直到所有行处理完毕;若存在
END模式,则在所有行处理完成后执行END中的操作。
二、awk 基础使用
- awk [选项] 'pattern{action}' 文件名 // awk 基本使用格式
在 awk 命令中,script(脚本)是一组用于定义文本处理逻辑的指令集合,是 awk 的核心 —— 它告诉 awk“要筛选哪些行、对这些行执行什么操作(比如打印、计算、修改)”。
awk 的 script 本质是 “规则” 的组合,每条规则由 pattern(匹配条件) 和 action(处理动作) 两部分构成,基本格式为:pattern { action } 两部分可单独存在(即 “只有条件无动作” 或 “只有动作无条件”),最终共同决定 awk 如何处理文件内容。
1、选项
| 选项 | 作用说明 | 示例 |
|---|---|---|
| -F 分隔符 | 指定文本分割符(替代内置变量 FS ) | awk -F: '{print $1}' /etc/passwd(用 : 分割 ) |
| -v 变量名=值 | 定义自定义变量(在处理文本前初始化) | awk -v sum=0 '{sum+=$2}' END{print sum}' 数据文件 |
| --posix | 启用 POSIX 标准模式,兼容更多正则语法 | awk --posix '/^[a-z]+$/{print $0}' 文本文件 |
| -f 脚本文件 | 从外部文件读取 awk 脚本 | awk -f analyze.awk access.log |
2、文件名
该格式中的 “文件名” 支持单个文件、多个文件,或通过管道(|)接收标准输入(无需指定文件名),适配不同数据来源场景:
(1)处理多个文件
awk 会按顺序处理多个文件,内置变量 FILENAME 可区分当前处理的文件,NR 记录累计行号。
# 处理 /etc/hosts 和 /etc/redhat-release 两个文件,输出文件名、行号、内容
awk '{print "文件:" FILENAME, "行号:" NR, "内容:" $0}' /etc/hosts /etc/redhat-release
(2)从标准输入读取数据(管道传递)
当数据来自其他命令的输出(如 head、grep)时,无需指定文件名,通过管道将数据传递.
# 先用 head 取 /etc/passwd 前5行,再用 awk 提取用户名
head -n 5 /etc/passwd | awk -F: '{print "前5个用户:" $1}'
# 输出示例:
# 前5个用户:root
# 前5个用户:bin
# 前5个用户:daemon
# 前5个用户:adm
# 前5个用户:lp3、操作(action)
若 script 用双引号,$1 会被 Shell 解析(如 awk -F: "{print $1}" /etc/passwd 会输出空值或错误),必须用单引号;
核心输出命令:print(简单输出,自动换行)和 printf (格式化输出,需手动控制换行)。
(1) print 操作
print 支持直接输出变量、常量或自定义内容,默认用空格分隔多个输出项,且自动在末尾添加换行符。
基础案例:
# 1. 提取 /etc/passwd 前3行的“用户名($1)、宿主目录($6)、Shell($7)”
head -n 3 /etc/passwd | awk -F: '{print $1, $6, $7}'
# 输出结果(空格分隔):
# root /root /bin/bash
# bin /bin /sbin/nologin
# daemon /sbin /sbin/nologin# 2. 输出自定义内容(常量需用双引号包裹)
head -n 3 /etc/passwd | awk -F: '{print "用户名:", $1, "宿主目录:", $6, "Shell:", $7}'
# 输出结果(自定义标签+数据):
# 用户名: root 宿主目录: /root Shell: /bin/bash
# 用户名: bin 宿主目录: /bin Shell: /sbin/nologin
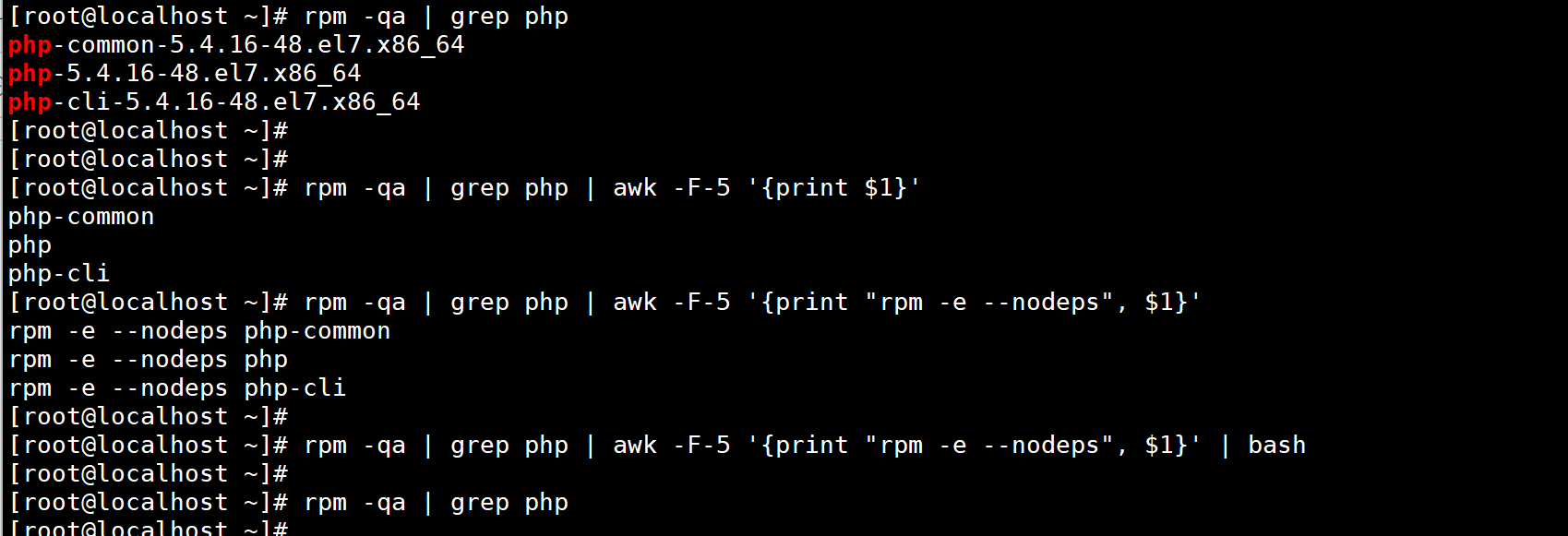
实用场景:生成批量操作命令
例如,批量卸载所有 PHP 相关 RPM 包(先构造卸载命令,再通过 bash 执行):
rpm -qa | grep php | awk -F-7 '{print "rpm -e --nodeps", $1}' | bash
# 逻辑:grep 筛选 PHP 包 → awk 提取包名前缀(分割符 -7)→ 构造 rpm 卸载命令 → bash 执行
(2) printf 格式化输出
printf 支持通过占位符控制输出格式(如列宽、对齐方式、数据类型)。
常用占位符
| 占位符 | 作用 | 示例 |
|---|---|---|
| %s | 输出字符串 | %8s(占 8 个字符宽度,默认右对齐)、%-8s(左对齐) |
| %d | 输出整数 | %5d(占 5 个字符宽度,不足补空格) |
| %f | 输出浮点数 | %.2f(保留 2 位小数)、%6.2f(占 6 位宽度 + 2 位小数) |
// printf 不会自动换行,需手动加 \n,否则所有输出会挤在一行;
基础案例:对齐输出 /etc/passwd 前 3 行的关键信息

# 格式:%-8s(用户名左对齐,占8位)、%-7s(宿主目录左对齐,占7位)、%-20s(Shell左对齐,占20位)
head -n 3 /etc/passwd | awk -F: '{printf "%-8s%-7s%-20s\n", $1, $6, $7}'
# 输出结果(列对齐,可读性强):
root /root /bin/bash
bin /bin /sbin/nologin
daemon /sbin /sbin/nologin

(3)多个操作(用分号分隔)
# 操作1:计算当前行列数(NF);操作2:输出行号(NR)、列数、整行内容
awk -F: '{count=NF; printf "行号%d:%d列,内容:%s\n", NR, count, $0}' /etc/passwd
# 输出示例:
# 行号1:7列,内容:root:x:0:0:root:/root:/bin/bash
# 行号2:7列,内容:bin:x:1:1:bin:/bin:/sbin/nologin三、pattern 模式
pattern是 awk 的 “筛选器”,指定哪些行需要被处理。若不指定 pattern,则默认处理所有行。
常用模式分为 4 类:
1、 表达式模式(数值 / 字符串比较)
通过比较运算符匹配行,支持数值比较、字符串比较与逻辑组合。
常用运算符
- 比较运算符:
==(等于)、!=(不等于)、>(大于)、>=(大于等于)、<(小于)、<=(小于等于); - 逻辑运算符:
&&(与)、||(或)、!(非); - 注意:字符串比较需用双引号包裹(如
$1=="root"),数值比较无需引号(如$3>=1000)。
案例 1:按行号筛选
# 筛选 /etc/passwd 行号 <=4 的行,输出用户名
awk -F: 'NR<=4{print $1}' /etc/passwd
# 输出:
# root
# bin
# daemon
# adm
案例 2:按数值条件筛选(系统用户与普通用户)
# 筛选 UID 在 1~199 之间的系统用户(/etc/passwd 第3列是 UID)
awk -F: '$3>=1 && $3<=199{print "系统用户:", $1, "UID:", $3}' /etc/passwd
案例 3:按字符串条件筛选(指定 Shell)
# 筛选 Shell 为 /sbin/nologin 的用户(字符串需加双引号)
awk -F: '$7=="/sbin/nologin"{print "用户:", $1, "Shell:", $7}' /etc/passwd
案例 4:按磁盘使用率筛选(数值转换技巧)
# 筛选根分区(/)使用率 > 20% 的磁盘($6 是使用率,需加 + 转为数值)
df -hT | awk '/^\/dev/{if(+$6>20) print "高使用率磁盘:", $NF, "使用率:", $6}'
# 说明:df -hT 中 $6 是字符串(如 "30%"),+ $6 可将其转为数值 30
2、正则表达式模式(关键词匹配)
通过正则表达式匹配行内容,格式为 /正则表达式/,支持基础正则语法(如 ^ 行首、$ 行尾、. 任意字符、* 任意次数)。
基础案例
# 1. 筛选以 tcp 开头的行(netstat 结果)
netstat -tunlp | awk '/^tcp/{print "TCP 服务:", $0}'# 2. 筛选以 /dev 开头的磁盘行(df 结果)
df -hT | awk '/^\/dev/{print "本地磁盘:", $0}'# 3. 筛选 Shell 以 nologin 结尾的用户($7 匹配正则)
awk -F: '$7 ~ /nologin$/{print $1}' /etc/passwd # ~ 表示“匹配正则”
awk -F: '$7 !~ /nologin$/{print $1}' /etc/passwd # !~ 表示“不匹配正则”
进阶案例:日志时间范围筛选
# 筛选 /var/log/messages 中 5月23日 10:00:01 到 10:51:29 的日志
awk '/May 23 10:00:01/,/May 23 10:51:29/{print $0}' /var/log/messages
# 说明:/A/,/B/ 表示“从匹配 A 的行开始,到匹配 B 的行结束”
补充:忽略大小写匹配
通过 -v IGNORECASE=1 启用忽略大小写模式:
# 忽略大小写,筛选包含“root”或“ROOT”的行
awk -v IGNORECASE=1 '/root/{print $0}' /etc/passwd
3、 BEGIN 模式(处理前初始化)
BEGIN 模式仅在 awk 开始处理文本前执行一次,常用于初始化变量、输出表头、设置分隔符等。
案例 1:输出表头 + 数据
# 先输出表头,再输出 /etc/passwd 前3行的用户名与 Shell
head -n 3 /etc/passwd | awk -F: '
BEGIN{print "----- 用户列表 -----"; # 表头print "用户名\tShell路径"; # 列名(\t 是 Tab 分隔)
}
{print $1 "\t" $7} # 输出数据
'
# 输出:
# ----- 用户列表 -----
# 用户名 Shell路径
# root /bin/bash
# bin /sbin/nologin
# daemon /sbin/nologin
案例 2:初始化计算变量
# 计算 /opt/file02 第2列的平均值(BEGIN 中初始化 sum=0)
awk '
BEGIN{sum=0; print "开始计算第2列平均值..."}
NR>=2{sum+=$2} # 跳过表头,累加第2列
END{avg=sum/(NR-1); # NR-1 是数据行数(减去表头行)printf "第2列总和: %d, 平均值: %.2f\n", sum, avg
}
' /opt/file02
# 输出:
# 开始计算第2列平均值...
# 第2列总和: 390, 平均值: 130.00
4、 END 模式(处理后收尾)
END 模式仅在 awk 处理完所有行后执行一次,常用于输出最终统计结果、计算汇总值等。
案例:统计 /etc/passwd 总用户数
# 处理完所有行后,输出总用户数(NR 是最后一行的累计行号,即总用户数)
awk -F: 'END{print "系统总用户数:", NR}' /etc/passwd
# 输出:系统总用户数: 40
四、awk 变量详解
awk 变量分为内置变量(系统预定义,直接使用)和自定义变量(用户手动定义),无需声明类型(弱类型语言,自动适配字符串 / 数值)。
(一)内置变量
内置变量用于获取文本处理过程中的关键信息(如行号、列数、文件名).
1、行号相关:NR 与 FNR
NR (Number of Records):累计行号,处理多个文件时,行号连续递增;
FNR(File Number of Records):单个文件行号,处理多个文件时,处理新文件时,每个文件行号从 1 重新计数。
案例对比:
# 处理两个文件,用 NR 输出累计行号
awk '{print "累计行号:", NR, "内容:", $0}' /etc/hosts /etc/redhat-release
# 输出(行号连续:1→2→3):
# 累计行号: 1 内容: 127.0.0.1 localhost localhost.localdomain
# 累计行号: 2 内容: ::1 localhost localhost.localdomain
# 累计行号: 3 内容: CentOS Linux release 7.9.2009 (Core)# 处理两个文件,用 FNR 输出单个文件行号
awk '{print "当前文件行号:", FNR, "内容:", $0}' /etc/hosts /etc/redhat-release
# 输出(第二个文件行号重置为1):
# 当前文件行号: 1 内容: 127.0.0.1 localhost localhost.localdomain
# 当前文件行号: 2 内容: ::1 localhost localhost.localdomain
# 当前文件行号: 1 内容: CentOS Linux release 7.9.2009 (Core)
实用场景:提取指定行
# 提取 /etc/passwd 的第4行(三种等价方式)
sed -n '4p' /etc/passwd
head -n 4 /etc/passwd | tail -n 1
awk 'NR==4{print $0}' /etc/passwd # 用 NR==4 匹配第4行
# 输出:adm:x:3:4:adm:/var/adm:/sbin/nologin
2、列数相关:NF
NF(Number of Fields):当前行被分割后的总列数,$NF 代表当前行的最后一列。
# 1. 查看 /etc/passwd 第1行的总列数(用 : 分割,共7列)
head -n 1 /etc/passwd | awk -F: '{print "总列数:", NF}'
# 输出:总列数: 7# 2. 查看自定义文件的列数与最后一列
cat /opt/file01 # 先查看文件内容
# MySQL Oracle
# Linux Unix
# shell Python Golangawk '{print "列数:", NF, "最后一列:", $NF}' /opt/file01
# 输出:
# 列数: 2 最后一列: Oracle
# 列数: 2 最后一列: Unix
# 列数: 3 最后一列: Golang
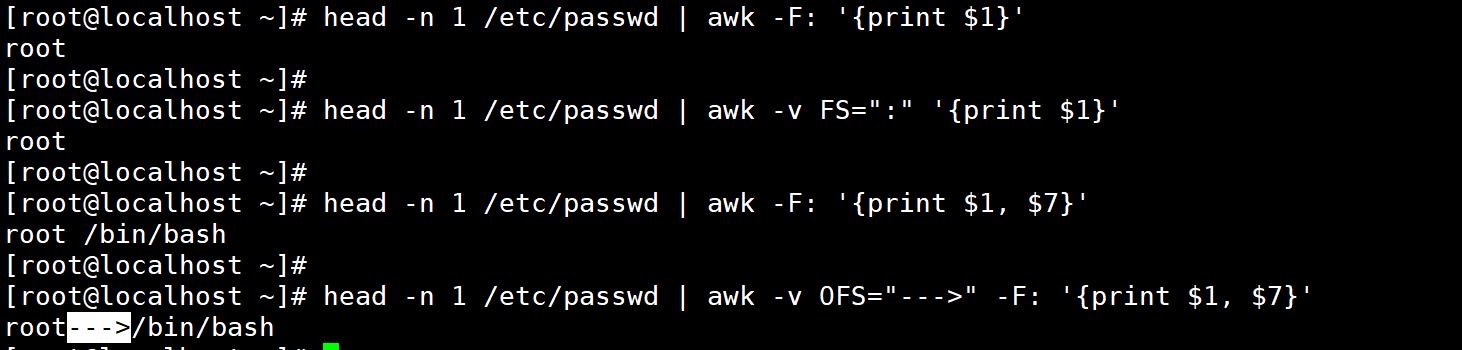
3、分隔符相关:FS 与 OFS
FS (Field Separator):输入列分隔符,等价于 -F 选项,默认是空白字符;
OFS(Output Field Separator):输出列分隔符,默认是空格,用于自定义
print/printf输出时的列分隔符。
# 1. 用 FS 指定输入分隔符(等价于 -F:)
head -n 1 /etc/passwd | awk -v FS=":" '{print "用户名:", $1, "Shell:", $7}'
# 输出:用户名: root Shell: /bin/bash# 2. 用 OFS 指定输出分隔符(将输出分隔符改为 --->)
head -n 1 /etc/passwd | awk -v FS=":" -v OFS="--->" '{print $1, $7}'
# 输出:root--->/bin/bash
4、文件名相关:FILENAME
FILENAME:当前处理的文件名,适用于多文件处理时区分输出来源。
# 处理两个文件,输出当前文件名与内容
awk '{print "当前文件:", FILENAME, "内容:", $0}' /etc/hosts /etc/redhat-release
# 输出:
# 当前文件: /etc/hosts 内容: 127.0.0.1 localhost localhost.localdomain
# 当前文件: /etc/hosts 内容: ::1 localhost localhost.localdomain
# 当前文件: /etc/redhat-release 内容: CentOS Linux release 7.9.2009 (Core)
5、补充内置变量:ARGC 与 ARGV
ARGC:命令行参数的总个数(包括
awk本身);ARGV:命令行参数的数组(
ARGV[0]是awk,ARGV[1]开始是目标文件 / 自定义参数)。
案例:查看参数个数与参数列表
awk 'BEGIN{print "参数总个数:", ARGC;for(i=0; i<ARGC; i++){print "ARGV["i"]:", ARGV[i]}
}' /etc/hosts /etc/redhat-release
# 输出:
# 参数总个数: 3
# ARGV[0]: awk
# ARGV[1]: /etc/hosts
# ARGV[2]: /etc/redhat-release
(二)自定义变量
自定义变量用于存储临时数据(如统计计数器、计算结果),定义方式有 3 种:
1、 用 -v 选项定义(处理文本前初始化)
# 定义变量 name=Angelina,在 BEGIN 模式中输出
awk -v name="Angelina" 'BEGIN{print "用户名:", name}'
# 输出:用户名: Angelina
2、在 BEGIN 模式中定义(仅初始化一次)
# 在 BEGIN 中定义变量 age=25,直接输出
awk 'BEGIN{age=25; print "年龄:", age}'
# 输出:年龄: 25
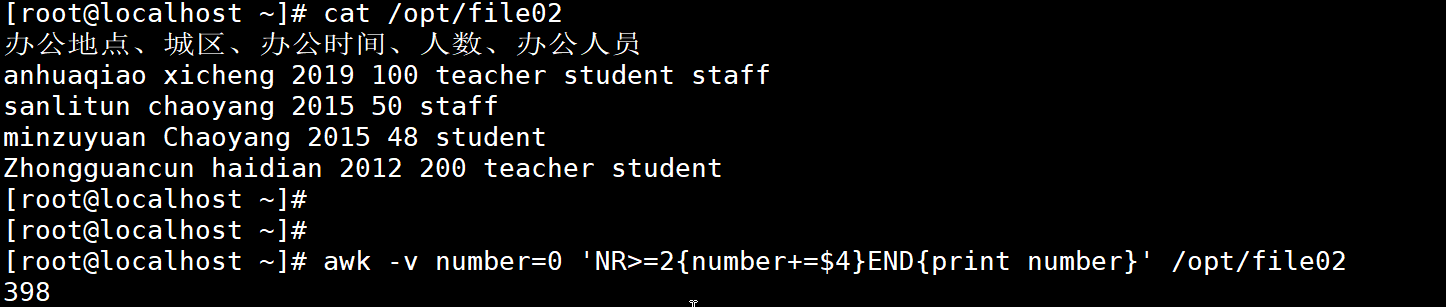
3、在处理过程中定义(按行动态赋值)
# 处理 /opt/file02,定义 sum 累加第2列数值(NR>=2 跳过表头)
awk -v sum=0 'NR>=2{sum+=$2} END{print "第2列总和:", sum}' /opt/file02
# 输出:第2列总和: 390
注意:awk 变量未定义时,默认值为空字符串(字符串类型)或 0(数值类型)。
五、awk 逻辑控制语句
awk 支持常见的逻辑控制语句,用于实现复杂的条件判断与循环操作。
1、条件判断:if 语句
# 单分支
if(条件){操作}# 双分支
if(条件){操作1}else{操作2}# 多分支
if(条件1){操作1}else if(条件2){操作2}else{操作3}
案例 1:按 UID 分类用户
# 分析 /etc/passwd:UID=0→root,1<=UID<=199→系统用户,UID>=1000→普通用户
awk -F: '
{if($3==0){print "超级用户:", $1}else if($3>=1 && $3<=199){print "系统用户:", $1}else{print "普通用户:", $1}
}
' /etc/passwd
案例 2:磁盘使用率预警
# 磁盘使用率 > 80% 输出“警告”,否则输出“正常”
df -h | awk '/^\/dev/{usage=+$5; # 提取使用率数值(去掉 %)if(usage>80){printf "警告:%s 使用率 %.0f%%\n", $NF, usage}else{printf "正常:%s 使用率 %.0f%%\n", $NF, usage}
}'
2、循环语句:for 循环
awk 的 for 循环支持两种格式:“数值循环” 与 “数组遍历循环”。
(1)数值循环(固定次数)
- for(初始化变量; 循环条件; 变量更新){操作}
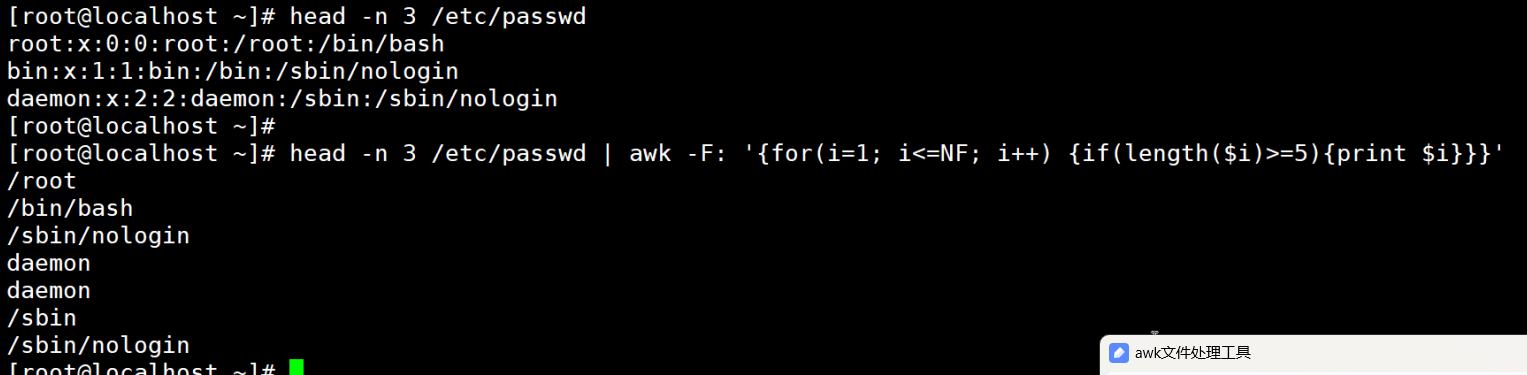
案例:遍历当前行的所有列,筛选长度≥6 的字段
# 查看 /etc/passwd 前3行,输出长度≥6的字段
head -n 3 /etc/passwd | awk -F: '{print "当前行:", $0;for(i=1; i<=NF; i++){ # i 从1到总列数 NFif(length($i)>=6){ # length($i) 是字段长度print " 长字段["i"]:", $i}}
}'
# 输出(示例):
# 当前行: root:x:0:0:root:/root:/bin/bash
# 长字段[7]: /bin/bash
# 当前行: bin:x:1:1:bin:/bin:/sbin/nologin
# 长字段[7]: /sbin/nologin

(2) 数组遍历循环(for...in)
- for(数组下标 in 数组名){操作} // 适用于遍历数组的所有元素(无需知道数组长度)。
案例:遍历自定义数组
awk 'BEGIN{# 定义数组(下标为软件名,值为版本)soft["mysql"]="8.0";soft["httpd"]="2.4";soft["php"]="7.2";# 遍历数组for(name in soft){print "软件:", name, "版本:", soft[name]}
}'
# 输出(数组遍历顺序不固定):
# 软件: httpd 版本: 2.4
# 软件: php 版本: 7.2
# 软件: mysql 版本: 8.0
案例:过滤出长度大于等于5个字符的词
3、 循环语句:while 与 do-while
(1)while 循环(先判断后执行)
- while(循环条件){操作
案例:累加 1~10 的和
awk 'BEGIN{sum=0;i=1;while(i<=10){ # 条件:i≤10sum+=i;i++; # 变量自增}print "1~10 的和:", sum;
}'
# 输出:1~10 的和: 55
(2)do-while 循环(先执行后判断)
- do{操作}while(循环条件)
// 区别于 while:至少执行一次操作
案例:确保至少执行一次累加
awk 'BEGIN{sum=0;i=11; # 初始值>10,while 会跳过,但 do-while 会执行一次do{sum+=i;i++;}while(i<=10);print "sum =", sum; # sum=11(仅执行一次)
}'
# 输出:sum = 11
习题:从访问日志 access_log中提取 IP 地址,统计每个 IP 的出现次数,按倒序排序后取前3名
awk '{print $1}' access_log | sort | uniq -c | sort -nr | head -n 3- uniq -c // 对相邻的重复 IP去重并计数
- sort -nr // 对计数结果按数字倒序排序(
-n表示按数值排序,-r表示倒序)
六、awk 数组应用(核心重点)
awk 数组是关联数组(下标可以是字符串或数字,无需连续),是实现数据统计的核心工具,常用场景:统计频次、去重、分组汇总。
1、数组基本操作
(1)数组定义与赋值
无需声明数组,直接通过 “数组名 [下标]= 值” 赋值:
awk 'BEGIN{# 数字下标arr[1]="apple";arr[2]="banana";# 字符串下标arr["fruit1"]="orange";arr["fruit2"]="grape";# 输出指定元素print arr[2]; # 输出 bananaprint arr["fruit1"]; # 输出 orange
}'
(2) 数组遍历(for...in)
通过 for(下标 in 数组) 遍历所有元素:
awk 'BEGIN{# 定义数组city["beijing"]="north";city["shanghai"]="east";city["guangzhou"]="south";# 遍历数组for(c in city){print "城市:", c, "区域:", city[c]}
}'
# 输出:
# 城市: beijing 区域: north
# 城市: shanghai 区域: east
# 城市: guangzhou 区域: south
(3) 数组元素删除(delete)
通过 delete 数组名[下标] 删除指定元素:
awk 'BEGIN{arr["a"]=1; arr["b"]=2; arr["c"]=3;delete arr["b"]; # 删除下标为 b 的元素for(k in arr){print k, arr[k]}
}'
# 输出(仅 a 和 c):
# a 1
# c 3
2、数组核心实用案例
案例 1:统计 /etc/passwd 中各类 Shell 的用户数
逻辑:将 Shell 路径($7)作为数组下标,每遇到一次相同 Shell,计数器加 1(user[$7]++),最后遍历数组输出统计结果。
# 统计 Shell 类型及对应用户数,按用户数倒序排序(sort -k2 -n -r)
awk -F: '{user[$7]++} # 核心:Shell 作为下标,计数+1
END{print "Shell 类型\t用户数";for(sh in user){print sh "\t" user[sh]}
}' /etc/passwd | sort -k2 -n -r # 按第2列(用户数)数值倒序
# 输出(示例):
# Shell 类型 用户数
# /sbin/nologin 35
# /bin/bash 5
# /sbin/halt 1
案例 2:分析 Nginx 访问日志(access_log)
场景 1:统计每个 IP 的访问量(用户访问量 UV)
# 日志格式示例:192.168.1.1 - - [10/May/2024:10:00:00 +0800] "GET / HTTP/1.1" 200 1234
# $1 是 IP,$7 是访问的 URL# 1. 统计每个 IP 的访问次数
awk '{uv[$1]++} # IP 作为下标,计数+1
END{print "IP 地址\t访问次数";for(ip in uv){print ip "\t" uv[ip]}
}' access_log# 2. 筛选访问量前2的 IP
awk '{uv[$1]++}
END{for(ip in uv){print ip, uv[ip]}
}' access_log | sort -k2 -n -r | awk 'NR<=2{print $1}' # 取前2名 IP
场景 2:统计每个 URL 的访问量(页面访问量 PV)
# 统计每个 URL($7)的访问次数
awk '{pv[$7]++}
END{print "URL 路径\t访问次数";for(url in pv){print url "\t" pv[url]}
}' access_log
# 输出(示例):
# URL 路径 访问次数
# / 102
# /favicon.ico 202
# /index.html 58
场景 3:统计 404 错误的请求(状态码 $9)
# 筛选状态码为 404 的请求,统计每个 URL 的 404 次数
awk '$9=="404"{err404[$7]++}
END{print "404 URL\t错误次数";for(url in err404){print url "\t" err404[url]}
}' access_log
案例 3:处理 CSV 文件(按列分组统计)
假设有 sales.csv 文件(格式:地区,产品,销售额):
地区,产品,销售额
北京,手机,5000
上海,电脑,8000
北京,平板,3000
上海,手机,6000
北京,电脑,7000
需求:按 “地区” 分组,统计各地区总销售额
# 用 -F"," 分割 CSV,跳过表头(NR>1),累加各地区销售额
awk -F"," '
NR>1{ # 跳过第1行表头total[$1]+=$3 # 地区作为下标,累加销售额
}
END{print "地区\t总销售额";for(area in total){print area "\t" total[area]}
}' sales.csv
# 输出:
# 地区 总销售额
# 北京 15000
# 上海 14000
七、awk 常见实用场景汇总
提取配置文件关键信息:
从 nginx.conf 中提取 server_name 和 listen 端口:
awk '/server_name|listen/{gsub(/;|"/,""); print $1, $2}' nginx.conf
批量修改文件名:
将当前目录下所有 .txt 文件改为 .log(结合 xargs):
ls *.txt | awk -F".txt" '{print "mv "$0" "$1".log"}' | xargs bash
计算日志中某字段的平均值:
从 access_log 中提取响应大小($10),计算平均值:
awk 'NR>1{sum+=$10; count++} END{print "平均响应大小:", sum/count " bytes"}' access_log
去重文本中的重复行:
用数组下标唯一性去重(无需 sort -u):
awk '!arr[$0]++' 文本文件 # arr[$0]++ 为0时输出,之后为1不输出