LeetCode算法日记 - Day 29: 重排链表、合并 K 个升序链表
目录
1. 重排链表
1.1 题目解析
1.2 解法
1.3 代码实现
2. 合并 K 个升序链表
2.1 题目解析
2.2 解法
2.3 代码实现
1. 重排链表
143. 重排链表 - 力扣(LeetCode)
给定一个单链表 L 的头节点 head ,单链表 L 表示为:
L0 → L1 → … → Ln - 1 → Ln
请将其重新排列后变为:
L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → …
不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例 1:
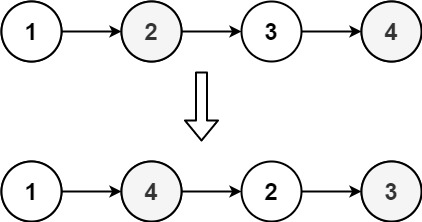
输入:head = [1,2,3,4] 输出:[1,4,2,3]
示例 2:
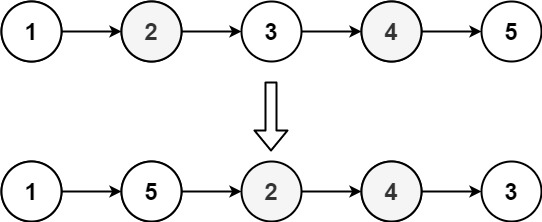
输入:head = [1,2,3,4,5] 输出:[1,5,2,4,3]
提示:
- 链表的长度范围为
[1, 5 * 104] 1 <= node.val <= 1000
1.1 题目解析
题目本质
把链表“重排”为首尾交替:L0, L1, …, Ln → L0, Ln, L1, Ln-1, …。本质是按位置重新连接指针,不能改节点值、不能新建整条链,只能原地改 .next。
常规解法
最直观:把所有节点放进数组,然后双指针从两端往中间,按顺序重连。
问题分析
数组法需要 O(n) 额外空间,不满足“尽量原地”的典型考点;且频繁重连要小心断链与成环。期望是 O(1) 额外空间、O(n) 时间 的指针操作。
思路转折
要首尾交替,其实就是:
1)找到中点,把链表一分为二;
2)反转后半段,使其顺序变为 Ln, Ln-1, …;
3)交替合并前半(L0, L1, …)和反转后的后半(Ln, …)。
这样天然实现“首尾交替”。中点建议取左中点((while (fast.next != null && fast.next.next != null)),保证后半长度 ≤ 前半,合并时只需“把后半用尽”为止,循环条件写 while (p2 != null) 最稳。
1.2 解法
算法思想
设链表为 head:
-
慢快指针找左中点 slow;
-
断开:second = slow.next; slow.next = null;
-
反转 second 得 revSecond;
-
两指针 p1 = head, p2 = revSecond,交替接:
n1 = p1.next; n2 = p2.next; p1.next = p2; p2.next = n1; p1 = n1; p2 = n2; -
当 p2 用尽,结束(奇数长度时前半多一个尾结点,正好留在末尾)。
i)左中点:while (fast.next != null && fast.next.next != null) { slow=slow.next; fast=fast.next.next; }
ii)断开:second = slow.next; slow.next = null;
iii)反转后半:三指针 prev/curr/next 原地反转,返回新头 prev。
iiii)交替合并:每轮先保存 n1 = p1.next, n2 = p2.next,再改指针,最后推进到 n1/n2。
iiiii)结束:函数为 void,就地修改,无需返回。
易错点
-
早退条件:if (head == null || head.next == null) return;(不是 &&)。
-
快慢指针写法:为得到左中点,条件用 fast.next != null && fast.next.next != null。
-
断开前半尾:slow.next = null; 必须断开,否则可能成环。
-
反转必须先存 next:next:next = curr.next; 之后再改 curr.next = prev,否则断路找不到后继。
-
合并时别用错指针:保存/连接用 p1/p2 的 next,不是 head/second 的 next。
-
循环条件:while (p2 != null),因为后半长度 ≤ 前半,合并完后半即完成。
-
不创建新节点:只能改 .next,不能重新 new 组成整条链。
1.3 代码实现
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public void reorderList(ListNode head) {// 0) 早退:空链或单节点,无需处理if (head == null || head.next == null) return;// 1) 快慢指针找“左中点” slowListNode slow = head, fast = head;while (fast.next != null && fast.next.next != null) {slow = slow.next;fast = fast.next.next;}// 2) 断开并反转后半段ListNode second = slow.next;slow.next = null; // 断开前半尾second = reverse(second); // 原地反转后半// 3) 交替合并:前半(head)与后半(second, 已反转)ListNode p1 = head, p2 = second;while (p2 != null) {ListNode n1 = p1.next, n2 = p2.next; // 先保存后继,避免断路p1.next = p2;p2.next = n1;p1 = n1;p2 = n2;}// 就地修改,void 无需返回}// 三指针原地反转private ListNode reverse(ListNode head) {ListNode prev = null, curr = head;while (curr != null) {ListNode next = curr.next; // 保存旧路口curr.next = prev; // 反转指向prev = curr; // prev 前进curr = next; // curr 走向旧路口}return prev; // 新头}
}
复杂度分析
-
时间复杂度:O(n)(找中点 O(n/2) + 反转 O(n/2) + 合并 O(n))。
-
空间复杂度:O(1)(只用常数级指针变量,原地修改)。
2. 合并 K 个升序链表
23. 合并 K 个升序链表 - 力扣(LeetCode)
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [1->4->5,1->3->4,2->6 ] 将它们合并到一个有序链表中得到。 1->1->2->3->4->4->5->6
示例 2:
输入:lists = [] 输出:[]
示例 3:
输入:lists = [[]] 输出:[]
提示:
k == lists.length0 <= k <= 10^40 <= lists[i].length <= 500-10^4 <= lists[i][j] <= 10^4lists[i]按 升序 排列lists[i].length的总和不超过10^4
2.1 题目解析
题目本质
把 k 条已升序的链表合成 1 条升序链表。抽象成:从 k 个“有序流”的当前表头中,持续选出最小元素并接到结果尾部,直到所有流耗尽。
常规解法
每一步在 k 个表头里线性找最小,接到结果链表尾部。
问题分析
线性扫描每步 O(k),总共有 N 次选择(N 为所有节点总数),总时间 O(N·k)。当 k 很大(最多 10^4)时会明显超时。
思路转折
要把“每步找最小”从 O(k) 降到 O(log k):
-
路线 A:小根堆装 k 个表头,poll/offer 均 O(log k),整体 O(N log k)。
-
路线 B:分治两两合并(像归并排序):每层线性合并,总层数 log k,整体 O(N log k)。
建议: -
代码短、直观:小根堆。
-
不想引入堆、掌握分治:两两合并。
2.2 解法
2.2.1 分治两两合并
把区间 [0..k-1] 的链表递归二分为 [l..m] 和 [m+1..r],分别合并成两条有序链,再调用“合并两条有序链表”得到当前区间的答案。
递推:mergeRange(l,r) = mergeTwo( mergeRange(l,m), mergeRange(m+1,r) )。
i)边界:lists == null或lists.length == 0 返回 null;l==r 返回 lists[l](可为 null)。
ii)递归:中点 m = l + (r-l)/2,分别合并左右。
iii)合并两条链:用局部 dummy 与 tail,每次接更小的那个节点;某一条耗尽后把另一条一次性挂尾。
易错点
-
dummy/tail 必须是合并函数的局部变量,不要复用全局,否则容易把不同子问题的结果“接成环”,遍历超时。
-
合并时推进顺序:tail.next = a/b → 移动 a/b = a/b.next → tail = tail.next。
-
收尾:不要循环一个个接剩余部分,直接 tail.next = (a!=null ? a : b)。
-
输入可能包含空链:初始化和递归都要兼容 null。
2.2.2 小根堆
维护一个小根堆保存“每条链当前表头”,每次弹出最小节点接入结果;若该节点有 next,把 next 放回
易错点
-
Java 用 PriorityQueue<ListNode>,比较器使用 Integer.compare(a.val, b.val),避免 b - a 溢出。
-
只把表头入堆,而不是把整条链全部入堆。
2.3 代码实现
方案一:分治两两合并
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode mergeKLists(ListNode[] lists) {if (lists == null || lists.length == 0) return null;return mergeRange(lists, 0, lists.length - 1);}private ListNode mergeRange(ListNode[] lists, int l, int r) {if (l == r) return lists[l]; // 可能为 null,无妨int m = l + (r - l) / 2;ListNode a = mergeRange(lists, l, m);ListNode b = mergeRange(lists, m + 1, r);return mergeTwo(a, b);}private ListNode mergeTwo(ListNode a, ListNode b) {ListNode dummy = new ListNode(0);ListNode tail = dummy;while (a != null && b != null) {if (a.val <= b.val) {tail.next = a; a = a.next;} else {tail.next = b; b = b.next;}tail = tail.next;}tail.next = (a != null) ? a : b; // 一次性挂尾return dummy.next;}
}
复杂度分析
-
时间:O(N log k)(每层线性合并,总层数约 log k)。
-
空间:O(log k)(递归栈;若考虑输出链表为必需空间则不计入额外空间)。
方案二:小根堆
import java.util.PriorityQueue;class Solution {public ListNode mergeKLists(ListNode[] lists) {if (lists == null || lists.length == 0) return null;PriorityQueue<ListNode> pq = new PriorityQueue<>((x, y) -> Integer.compare(x.val, y.val));for (ListNode h : lists) if (h != null) pq.offer(h);ListNode dummy = new ListNode(0), tail = dummy;while (!pq.isEmpty()) {ListNode node = pq.poll();tail.next = node; tail = node;if (node.next != null) pq.offer(node.next);}return dummy.next;}
}
复杂度分析
-
时间:O(N log k)。
-
空间:O(k)(堆大小)。