【菜狗学聚类】聚类的一些评估指标——20250901
🐕1、(调节后的)兰德系数——[-1,1]——越大越好
① RI兰德系数
② ARI调整的兰德系数
🐕2、NMI标准互信息——[0,1]——越大越好
① 互信息 (Mutual Information, MI)
② 归一化互信息 (NMI)
🐕3、Homogeneity / Completeness / V-measure——同质性、完整性——越大越好
🐕4、Fowlkes-Mallows Scores(FMI)—— [0,1]——越接近1越好
🐕1、(调节后的)兰德系数——[-1,1]——越大越好
聚类性能评估-ARI(调兰德指数) - 知乎转载
ARI取值范围为[-1,1],值越大越好,反映两种划分的重叠程度,使用该度量指标需要数据本身有类别标记。
① RI兰德系数
用C表示实际的类别划分,K表示聚类结果。定义a 为在C中被划分为同一类,在K中被划分为同一簇的实例对数量。定义b为在C中被划分为不同类别,在K中被划分为不同簇的实例对数量。定义Rand Index(兰德系数):
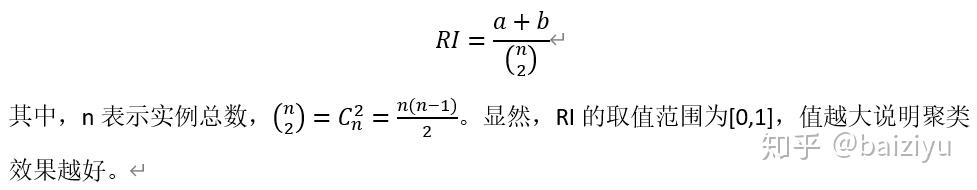
from sklearn.metrics import rand_score
rand_score(y_true,y_predict)② ARI调整的兰德系数
Rand Index无法保证随机划分的聚类结果的RI值接近0。于是,提出了Adjusted Rand index(调节的兰德系数):
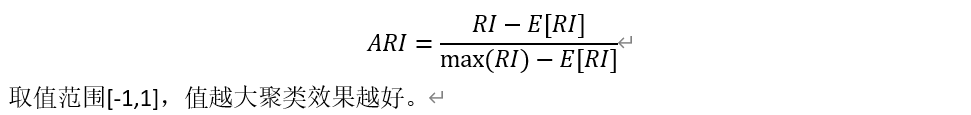
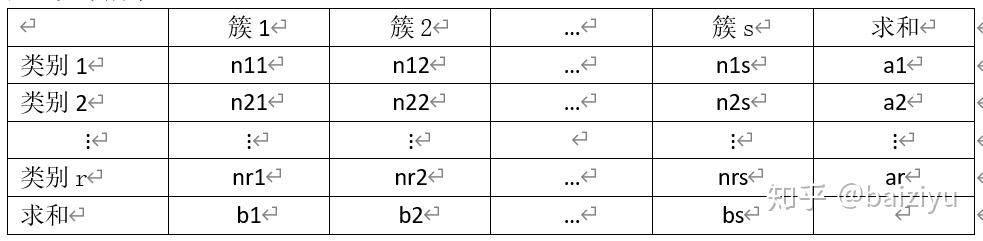
为了计算ARI的值,引入contingency table(列联表),反映实例类别划分与聚类划分的重叠程度,表的行表示实际划分的类别,表的列表示聚类划分的簇标记,nij表示重叠实例数量,如下所示:
有了列联表,即可用它计算ARI:
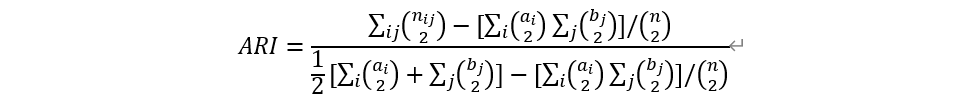
这里,显然把max(RI)替换成了mean(RI)。
from sklearn.metrics import adjusted_rand_scoreadjusted_rand_score(y_true,y_predict)🐕2、NMI标准互信息——[0,1]——越大越好
① 互信息 (Mutual Information, MI)
直观理解:表示两个随机变量之间共享的信息量。即,知道其中一个变量后,能减少另一个变量多少不确定性。

from sklearn.metrics import mutual_info_scoremutual_info_score(y_true,y_predict)② 归一化互信息 (NMI)
NMI 用于评估两个聚类结果(或一个聚类结果与真实标签)之间的一致性。它的核心思想是:如果我知道你的聚类结果,那么我能多大概率猜出它的真实类别?(反之亦然)

这种“信息的增益”就是互信息(Mutual Information, MI)。如果两个聚类结果越一致,它们共享的“信息”就越多,MI值就越高。
MI有个问题:它对聚类数量敏感。例如,如果给每个样本都单独分一个簇,MI会很高,但这显然不是一个好的聚类。因此,我们需要将其归一化(Normalized),得到一个介于 [0, 1] 之间的值,这就是NMI。
from sklearn.metrics import normalized_mutual_info_scorenormalized_mutual_info_score(y_true,y_predict)🐕3、Homogeneity / Completeness / V-measure——同质性、完整性——越大越好
聚类算法性能评估_聚类算法评估-CSDN博客
同质性homogeneity:每个群集只包含单个类的成员。
from sklearn.metrics import homogeneity_scorehomogeneity_score(y_true,y_predict)完整性completeness:给定类的所有成员都分配给同一个群集。
from sklearn.metrics import completeness_scorecompleteness_score(y_true,y_predict)V-measure:是同质性homogeneity和完整性completeness的调和平均数。
from sklearn.metrics import v_measure_scorev_measure_score(y_true,y_predict)优点:
分数明确:从0到1反应出最差到最优的表现;
解释直观:差的调和平均数可以在同质性和完整性方面做定性的分析;
对簇结构不作假设:可以比较两种聚类算法如k均值算法和谱聚类算法的结果。
缺点:
以前引入的度量在随机标记方面没有规范化,这意味着,根据样本数,集群和先验知识,完全随机标签并不总是产生相同的完整性和均匀性的值,所得调和平均值V-measure也不相同。特别是,随机标记不会产生零分,特别是当簇的数量很大时。
当样本数大于一千,聚类数小于10时,可以安全地忽略该问题。对于较小的样本量或更大数量的集群,使用经过调整的指数(如调整兰德指数)更为安全。
🐕4、Fowlkes-Mallows Scores(FMI)—— [0,1]——越接近1越好
FMI是Precision(精度)和 Recall(召回)的几何平均数。取值范围为 [0,1],越接近1越好。
from sklearn.metrics import fowlkes_mallows_scorefowlkes_mallows_score(y_true,y_predict)——小狗照亮每一天
2025.9.1