GPU 通用手册:裸机、Docker、K8s 环境实战宝典
前言:
随着数字化时代的到来,GPU 已成为高性能计算和人工智能的关键驱动力。它强大的并行计算能力为复杂的数据分析和深度学习模型训练提供了显著的加速效果。然而,计算环境的多样化,从裸机到 Docker 容器,再到 Kubernetes 集群,给 GPU 的高效利用带来了挑战。
本文旨在帮助读者在这些主流环境中充分发挥 GPU 的性能。无论你是在裸机上部署应用,还是在 Docker 中共享 GPU 资源,或是在 Kubernetes 集群中管理 GPU,本文都将提供实用的指南和操作建议。通过阅读本文,你将学会如何在不同环境中配置、优化和管理 GPU,从而提升计算效率。
让我们一起探索 GPU 在多样化环境中的应用,释放其无限潜力。
1:先睹为快:揭开序幕的震撼概览
尽管以 NVIDIA GPU(Linux 环境)为示例展开,但所述流程在逻辑上适用于其他厂商的 GPU 设备。
对于裸机环境,只需要安装对应的 GPU Driver 以及 CUDA Toolkit 。 对应 Docker 环境,需要额外安装 nvidia-container-toolkit 并配置 docker 使用 nvidia runtime。 对应 k8s 环境,需要额外安装对应的 device-plugin 使得 kubelet 能够感知到节点上的 GPU 设备,以便 k8s 能够进行 GPU 管理。 注:一般在 k8s 中使用都会直接使用 gpu-operator 方式进行安装,本文主要为了搞清各个组件的作用,因此进行手动安装。 换个写法
2:裸机启航:直面硬件的原始力量
启用裸机 GPU 计算能力,依赖以下两个关键软件层:
✅ GPU 驱动:负责硬件通信与资源管理
✅ CUDA Toolkit:提供开发与运行时支持
二者的关系可以通过 NVIDIA 官网上的相关图示来直观理解。
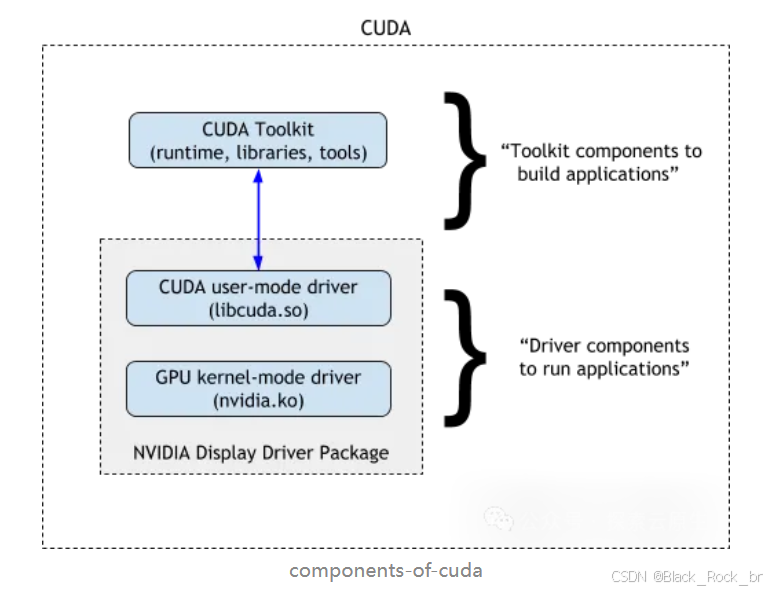
GPU 驱动不仅包含用于硬件控制的图形驱动,还集成了 CUDA 驱动(即内核级支持库),用于启用 GPU 的通用计算能力。而 CUDA Toolkit 则提供了包括 CUDA 运行时(CUDA Runtime)在内的开发与执行环境支持。
作为一条 PCIe 设备,GPU 在正确安装驱动后,会出现在系统的设备树中。可通过 lspci 命令查看设备列表,确认 GPU 是否已被系统识别。建议首先执行此步骤,确保硬件已正确安装并可被操作系统发现。

从该设备的配置来看,它拥有两张 Tesla T4 GP
2.1驱动安装
首要操作是访问 NVIDIA 驱动下载网址 [1],下载与您的显卡相匹配的驱动程序
官方提供的 GPU 驱动通常以 .run 文件形式发布,如 NVIDIA-Linux-x86_64-550.54.14.run。这类文件是自包含的可执行安装脚本,只需通过 sh 运行即可启动安装流程
安装过程中将进入图形化交互界面,建议根据实际环境需求确认选项,通常可直接选择默认项(Yes/OK)继续。
安装结束后,建议立即运行以下命令以验证驱动状态:
![]()
看到显卡信息就代表安装成功了,如下图所示
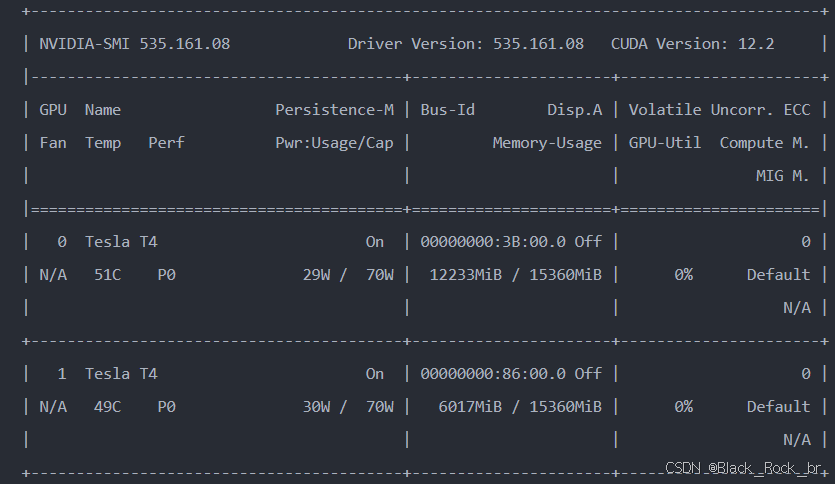
至此,GPU 驱动已成功安装,系统可以正常识别并管理 GPU 设备。
此处显示的 CUDA 版本表示当前驱动程序所支持的最高 CUDA 版本,不代表已安装完整的 CUDA 开发环境
2.2 安装 CUDA Toolkit
对于深度学习程序,CUDA 环境通常是必需的,因此需要在机器上安装 CUDA Toolkit。
同样,前往 NVIDIA CUDA Toolkit 下载页面[2],下载对应的安装包,选择操作系统和安装方式即可。

注意:若已安装 NVIDIA 驱动,请在运行 CUDA .run 文件时跳过驱动安装环节,仅选择安装 CUDA Toolkit 及相关组件,避免重复安装导致冲突
安装完成后输出如下:
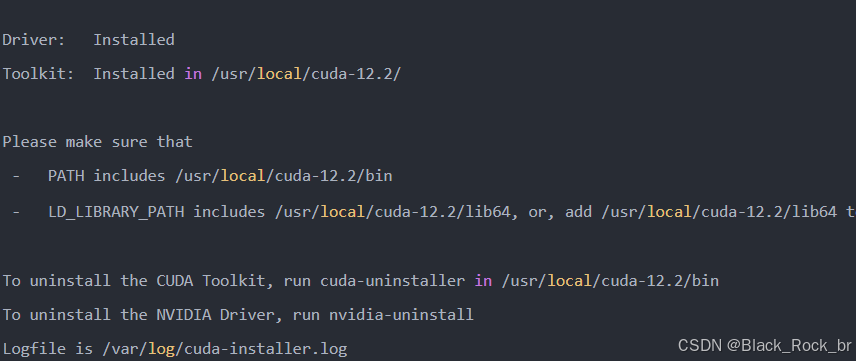
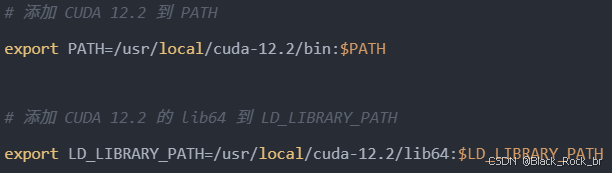
根据提示配置下 PATH
执行以下命令查看版本,确认安装成功
~# nvcc -V
3:容器跃迁:进入 Docker 中的 GPU 加速世界
上一阶段,我们已在裸机环境中成功部署 GPU 驱动与 CUDA Toolkit,实现了宿主机对 GPU 的直接调用。
现在,若希望在 Docker 容器中同样启用 GPU 加速能力,需进行容器环境的专项配置。核心步骤如下:
- 安装
nvidia-container-toolkit,为容器提供 GPU 支持能力 - 配置 Docker 使用
nvidia作为默认运行时(runtime) - 启动容器时通过
--gpus参数显式声明 GPU 资源分配
3.1 第一步,从安装 nvidia-container-toolkit 开始……
NVIDIA Container Toolkit 的主要作用是将 NVIDIA GPU 设备挂载到容器中,它兼容生态系统中的任意容器运行时,例如 Docker、containerd 和 cri-o 等。
安装指南可以参考 NVIDIA 官方文档:nvidia-container-toolkit-install-guide。
对于 Ubuntu 系统,安装命令如下:
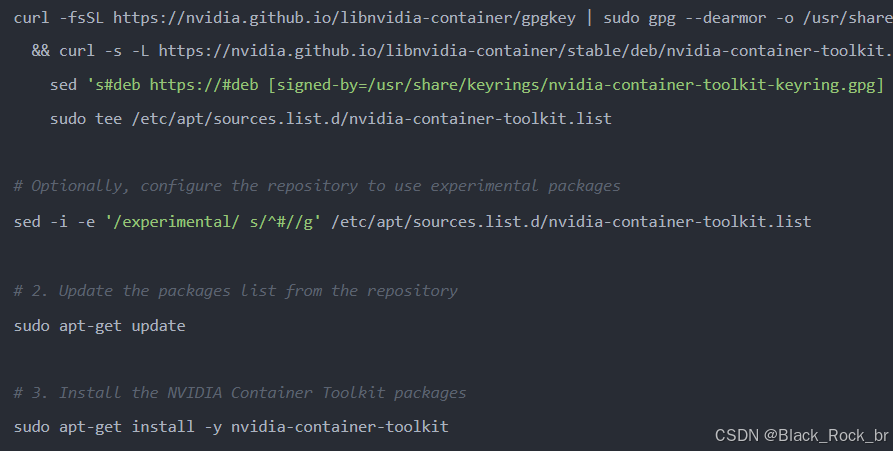
3.1 配置 NVIDIA GPU Runtime
支持 Docker、Containerd、CRI-O、Podman 等多种 CRI。
以 Docker 为例,旧版本需要手动在 `/etc/docker/daemon.json` 文件中添加配置,指定使用 NVIDIA 的 runtime。
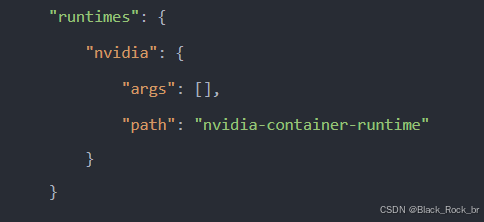
新版 toolkit 附带了 nvidia-ctk 工具,只需执行以下命令,即可一键完成配置:
![]()
重启docker!
sudo systemctl restart docker
4:Kubernetes 集群环境
4.1在 Kubernetes 环境中进一步使用 GPU,需要在集群中部署以下组件:
GPU 设备插件(gpu-device-plugin):用于管理 GPU。该插件以 DaemonSet 的形式运行在集群的各个节点上,以便感知节点上的 GPU 设备,从而使 Kubernetes 能够对节点上的 GPU 设备进行管理。
GPU 监控工具(gpu-exporter):用于监控 GPU 的使用情况。
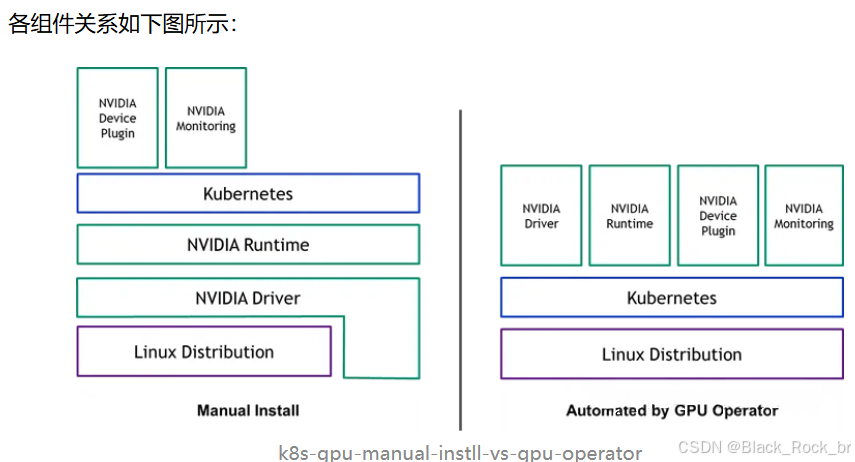
左图展示了手动安装的情况,仅需在集群中安装 device-plugin 和监控组件,即可投入使用。
右图为使用 gpu-operator 安装的场景,本文暂不涉及。
大致工作流程如下:
1:每个节点的 kubelet 组件负责维护该节点的 GPU 设备状态(哪些已用,哪些未用),并定时将状态报告给调度器,使调度器知晓每个节点可用的 GPU 卡数量。
2. 调度器在为 Pod 选择节点时,会从符合条件的节点中挑选一个节点。
3. Pod 调度到节点后,kubelet 组件会为 Pod 分配 GPU 设备 ID,并将这些 ID 作为参数传递给 NVIDIA Device Plugin。
4. NVIDIA Device Plugin 接收这些 ID 后,会将它们写入到 Pod 容器的环境变量 NVIDIA_VISIBLE_DEVICES 中,随后将相关信息反馈给 kubelet。
5. kubelet 接收反馈后,启动容器。
6. NVIDIA Container Toolkit 检测到容器 spec 中存在环境变量 NVIDIA_VISIBLE_DEVICES 后,会根据该变量的值将对应的 GPU 设备挂载到容器中。
7. 在 Docker 环境中,我们通常在启动容器时通过 --gpu 参数手动指定分配给容器的 GPU;而在 Kubernetes 环境中,GPU 的分配则由 device-plugin 自动管理。
5:安装 device-plugin 步骤全解析
Device-plugin 通常由 GPU 厂商提供,例如 NVIDIA 的 k8s-device-plugin[5]。安装过程非常容易,只需将对应的 YAML 文件应用到集群即可。
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.15.0/deployments/static/nvidia-device-plugin.yml
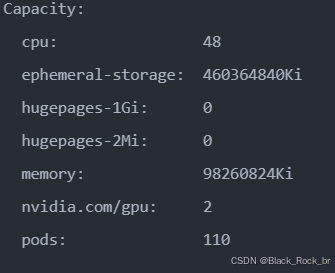
Device-plugin 启动之后,会识别节点上的 GPU 设备,并将这些信息上报给 kubelet,随后 kubelet 将其提交到 kube-apiserver。
因此,我们可以在 Node 的可分配资源中看到 GPU,具体如下:
6:实时监控 GPU:安装监控工具
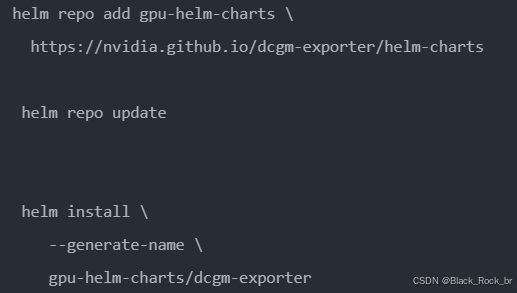
6.1 除此之外,若需对集群 GPU 资源使用情况进行监控,还需安装 DCCM exporter[6],并借助 Prometheus 输出 GPU 资源监控信息。
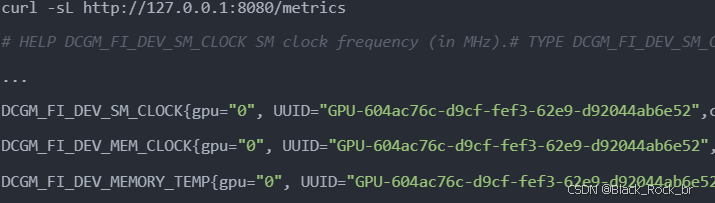
查看 metrics
总结
本文主要介绍了在裸机、Docker 环境和 Kubernetes 环境中如何使用 GPU。
对于裸机环境,只需安装对应的 GPU 驱动程序即可。
在 Docker 环境中,除了安装 GPU 驱动程序外,还需要安装 **nvidia-container-toolkit** 并配置 Docker 使用 **nvidia runtime**。
在 Kubernetes 环境中,除了上述步骤外,还需要安装 **device-plugin**,以便 kubelet 能够感知节点上的 GPU 设备,从而实现对 GPU 的有效管理。
目前,大多数场景都在 Kubernetes 环境中使用 GPU。为了简化安装步骤,NVIDIA 提供了 **gpu-operator**,它能够极大地简化 GPU 的安装和部署过程。