Shell编程(二):正则表达式
正则表达式
- 前言
- 一、正则表达式概述
- 1.1 正则表达式的定义与功能
- 1.2 正则表达式的用途
- 1.3 Linux中的正则表达式分类
- 二、正则表达式的组成
- 2.1 普通字符
- 2.2 元字符
- 三、grep命令的使用
- 3.1 grep命令简介
- 3.2 grep命令的常用选项
- 3.3 grep命令的实例
- 四、基础正则表达式与扩展正则表达式
- 4.1 基础正则表达式(BRE)
- 4.2 扩展正则表达式(ERE)
- 五、元字符操作案例
- 5.1 查找特定字符
- 5.2 中括号集合
- 5.3 定位符
- 5.4 点与星
- 5.5 次数限定符
- 六、结语
前言
在当今的计算机科学和信息技术领域,文本处理是一项至关重要的任务。无论是系统管理员在管理服务器时对日志文件的分析,还是程序员在编写代码时对配置文件的解析,都离不开对文本的高效处理。而正则表达式作为一种强大的文本处理工具,能够帮助我们快速、准确地检索、替换和过滤符合特定规则的字符串,极大地提高了文本处理的效率。本文将围绕正则表达式展开,详细介绍其在Linux系统中的应用,特别是与Shell编程中常用文本处理器(如grep、sed、awk等)的结合使用,通过理论讲解与实际案例相结合的方式,帮助读者全面掌握正则表达式的使用技巧。
一、正则表达式概述
1.1 正则表达式的定义与功能
正则表达式(Regular Expression),在代码中常简写为regex、regexp或RE,是计算机科学中一个重要的概念。它是一种用来描述字符串模式的规则,主要功能包括检索、替换和过滤符合特定规则的字符串。通过使用正则表达式,我们可以轻松地从大量文本中提取出所需的信息,或者对文本进行批量修改,从而提高工作效率。
1.2 正则表达式的用途
正则表达式在多个领域都有广泛的应用,包括但不限于:
- 系统日志筛选:例如,定位系统日志中的“登录失败”或“服务启动失败”等关键信息,帮助管理员快速定位和解决问题。
- 配置文件解析:在处理复杂的配置文件时,正则表达式可以帮助我们提取出所需的配置项,简化配置管理过程。
- 文本查找替换:在文档编辑或代码编写过程中,正则表达式可以用于批量查找和替换特定的文本模式,提高编辑效率。
- 脚本编程中的条件匹配:在编写Shell脚本或其他编程语言的脚本时,正则表达式可以用于条件判断,实现更加灵活和强大的脚本功能。
1.3 Linux中的正则表达式分类
在Linux系统中,常用的正则表达式主要分为两大类:基础正则表达式(BRE)和扩展正则表达式(ERE)。
- 基础正则表达式(BRE):这是一种传统的正则表达式语法,功能相对有限。在BRE中,一些常用的元字符(如量词
{}、+、?、()等)需要进行转义才能使用,常用的工具包括grep和sed。 - 扩展正则表达式(ERE):相比BRE,ERE提供了更强大的功能和更简洁的语法。在ERE中,
+、?、()、{}、|等元字符无需转义即可使用,常用的工具包括egrep(即grep -E)和awk。
二、正则表达式的组成
正则表达式主要由普通字符和元字符组成。
2.1 普通字符
普通字符包括大小写字母、数字、标点符号及其他一些符号,它们在正则表达式中表示其本身的含义,没有特殊的匹配规则。
2.2 元字符
元字符是正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符在目标对象中的出现模式。常见的元字符包括:
.:匹配除换行符\r\n之外的任意单个字符。[]:匹配列表中的一个字符,例如[a-z]表示匹配任意一个小写字母。[^list]:匹配任意不在列表中的一个字符,例如[^a-z]表示匹配任意一个非小写字母的字符。^:匹配输入字符串的开始位置,即行首。$:匹配输入字符串的结尾位置,即行尾。\:转义符,用于去除其后紧跟的元字符或通配符的特殊意义。*:匹配前面的子表达式零次或多次。\+:匹配前面的字符出现最少1次,即至少出现一次。\{n\}:匹配前面的子表达式恰好n次。\{n,\}:匹配前面的子表达式不少于n次,即至少出现n次。\{n,m\}:匹配前面的子表达式n到m次,即在n到m的范围内出现。
三、grep命令的使用
3.1 grep命令简介
grep(Global Regular Expression Print)是一个强大的文本搜索工具,它可以在文件中搜索符合特定模式的行,并将匹配的行打印出来。grep命令支持多种选项,可以根据不同的需求进行灵活使用。
3.2 grep命令的常用选项
-E:启用扩展正则表达式。-c:统计匹配的行数。-i:忽略大小写。-o:只输出匹配的内容。-v:反向匹配,即输出不包含匹配字符串的行。-n:显示匹配行的行号。--color=auto:将匹配的关键词部分以颜色高亮显示。
3.3 grep命令的实例
- 统计匹配行数:例如,统计
/etc/passwd文件中包含root的行数,可以使用命令grep -c root /etc/passwd。
- 不区分大小写匹配:例如,在
web.sh文件中不区分大小写查找包含the的行,可以使用命令grep -i "the" web.sh。
- 反向匹配:例如,输出
/etc/passwd文件中不包含root的行,可以使用命令grep -v root /etc/passwd。
- 提取IP地址:例如,从
ifconfig命令的输出中提取IP地址,可以使用命令ifconfig ens33 | grep -o "[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+" | head -1。

四、基础正则表达式与扩展正则表达式
4.1 基础正则表达式(BRE)
基础正则表达式是传统的正则表达式语法,功能相对有限。在BRE中,一些常用的元字符需要进行转义才能使用。常见的BRE元字符包括:
^:行首。$:行尾。.:任意单字符。[]:匹配字符集。[^list]:反向匹配。*:0次或多次。\{n\}:精确次数。\{n,\}:至少n次。\{n,m\}:n到m次。
4.2 扩展正则表达式(ERE)
扩展正则表达式提供了更强大的功能和更简洁的语法。在ERE中,+、?、()、{}、|等元字符无需转义即可使用。常见的ERE元字符包括:
+:一个或多个。?:0或1次。|:或者(OR)。():分组。()+:匹配重复的组。
五、元字符操作案例
5.1 查找特定字符
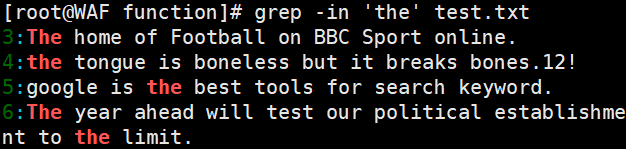
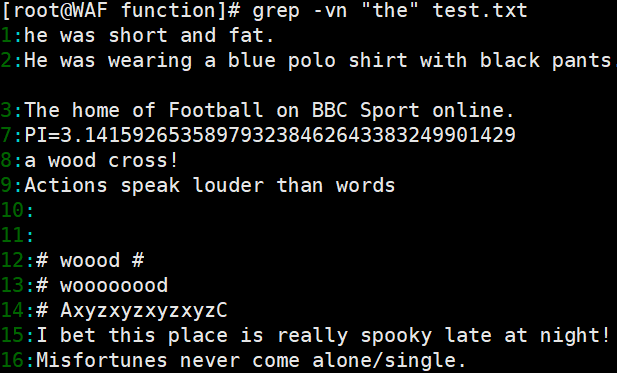
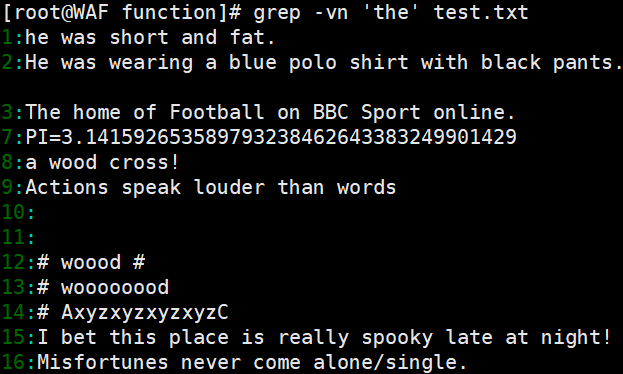
- 查找特定字符:例如,在
test.txt文件中查找包含the的行,可以使用命令grep -n 'the' test.txt;反向查找不包含the的行,可以使用命令grep -vn 'the' test.txt。
5.2 中括号集合
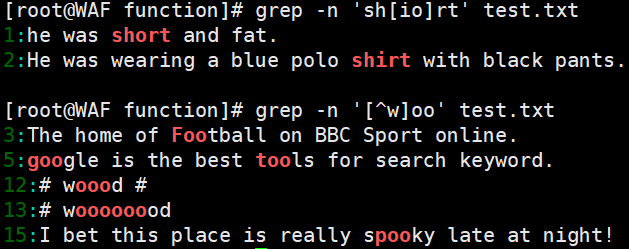
- 查找集合字符:例如,查找包含
shirt或short的行,可以使用命令grep -n 'sh[io]rt' test.txt;查找oo前面不是w的行,可以使用命令grep -n '[^w]oo' test.txt。
5.3 定位符
- 行首与行尾匹配:例如,查找行首是
the的行,可以使用命令grep -n '^the' test.txt;查找行尾是.的行,可以使用命令grep -n '\.$' test.txt;查找空行,可以使用命令grep -n '^$' test.txt。

5.4 点与星
- 任意字符与重复字符:例如,查找以
w开头、d结尾,中间有两个字符的行,可以使用命令grep -n 'w..d' test.txt;查找以w开头、d结尾,中间o可有可无的行,可以使用命令grep -n 'woo*d' test.txt;查找以w开头、d结尾,中间任意字符的行,可以使用命令grep -n 'w.*d' test.txt;查找任意数字所在的行,可以使用命令grep -n '[0-9][0-9]*' test.txt。

5.5 次数限定符
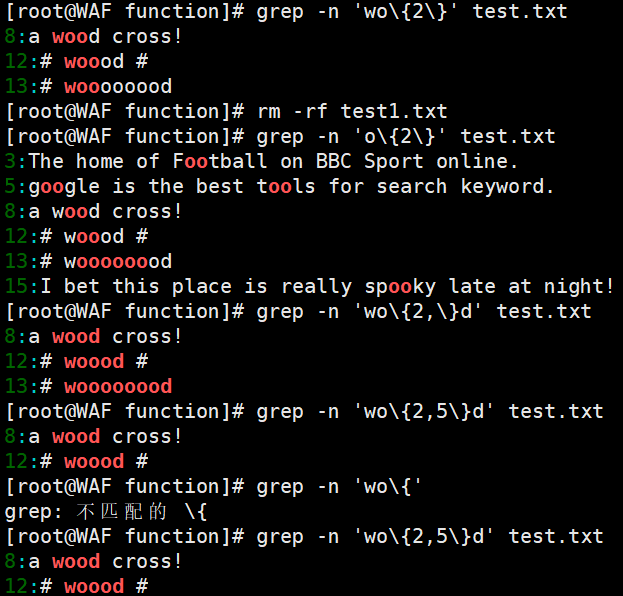
- 限定重复次数:例如,查询两个
o的字符,可以使用命令grep -n 'o\{2\}' test.txt;查询以w开头、d结尾,中间包含2到5个o的字符串,可以使用命令grep -n 'wo\{2,5\}d' test.txt;查询以w开头、d结尾,中间包含2个或2个以上o的字符串,可以使用命令grep -n 'wo\{2,\}d' test.txt。
六、结语
正则表达式作为一种强大的文本处理工具,在Linux系统管理和脚本编程中发挥着重要作用。通过本文的介绍,我们从正则表达式的基本概念出发,详细讲解了其在Linux系统中的应用,特别是与Shell编程中常用文本处理器(如grep、sed、awk等)的结合使用。我们不仅学习了基础正则表达式和扩展正则表达式的区别与联系,还通过大量的实例展示了如何使用grep命令进行文本搜索和处理。
掌握正则表达式不仅能够提高我们的文本处理效率,还能帮助我们更好地理解和编写复杂的脚本程序。希望本文的内容能够为读者在正则表达式的学习和应用中提供有价值的参考,助力大家在Linux系统和脚本编程的道路上走得更远。未来,随着技术的不断发展,正则表达式的应用场景将更加广泛,掌握这一技能将为我们的职业发展和技术能力提升带来更多可能。
温馨提示:正则表达式的学习需要不断的实践和积累,建议读者在实际工作中多尝试使用正则表达式解决实际问题,通过不断的练习来加深理解和提高技能。