使用 Python mlxtend库进行购物篮分析、关联规则
本篇文章From Data to Dollars: A Simple Approach to Market Basket Analysis with Python适合新手学习市场篮子分析(MBA),其亮点在于清晰地解释了关联规则的概念,如支持度、置信度和提升度,并通过简单的Python示例展示了如何实现这些分析。文章介绍的Apriori算法有效地发现频繁项集,帮助读者快速上手。
文章目录
- 1 关联规则的语言
- 2 Apriori 算法
- 3 代码 mlxtend
- 4 实际影响
- 5 结论
![Market Basket Analysis [MBA] | AI 生成图片。Google Gemini, 2025。](https://i-blog.csdnimg.cn/img_convert/1b8d84055c8daa52b5c5c6b74f89555a.png)
你是否曾走进一家商店,心想:“嗯,枫糖浆展示区就在煎饼旁边,这真是太方便了”?
或者,在网上浏览时,你是否看到过一个写着“购买此商品的顾客还购买了…”的区域?
这些并非偶然。它们是名为**市场篮子分析(MBA)**的强大数据科学技术的结果。那么,这到底是怎么回事呢?
市场篮子分析的核心是一种数据挖掘技术,用于揭示经常一起购买的商品之间的有趣关系。其目标是找到这些隐藏的模式,并利用它们做出更明智的商业决策,从而直接促进销售并改善客户体验。
让我们在本文中深入了解这项技术。
1 关联规则的语言
市场篮子分析的魅力在于它能够生成所谓的关联规则。这些规则是简单的“如果-那么”语句。
如果顾客购买牛奶,那么他们也很可能会购买面包。
但为了确保这些规则有用而不仅仅是随机观察,我们使用三个关键指标:
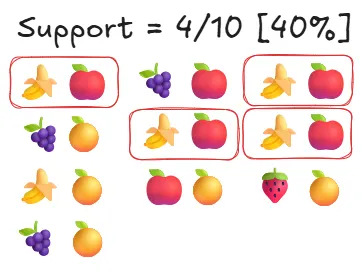
支持度(Support): 这表示某个商品或商品组合的受欢迎程度。它是包含该特定商品或组合的所有交易的百分比。 支持度低意味着它不是一个非常常见的购买。
- 总交易数: 10
- 包含苹果和香蕉的交易数: 4(共 10 笔)
- 计算: [同时包含两者的交易数] / [总交易数]
- 支持度: [4 / 10 = 0.4(或 40%)]
置信度(Confidence): 这就是有趣的地方。置信度衡量“如果-那么”规则的可靠性。具体来说,如果顾客购买了第一个商品(苹果),那么他们购买第二个商品(香蕉)的可能性有多大?
- 包含苹果的交易数: 6
- 同时包含苹果和香蕉的交易数: 4
- 计算: [同时包含两者的交易数] / [仅包含第一个商品的交易数]
- 置信度: [4 / 6 = 0.67(或 67%)]
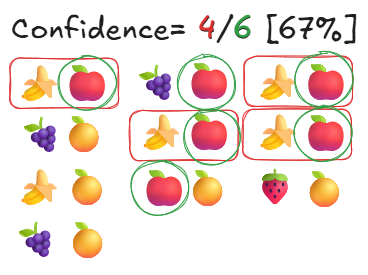
置信度概念图。作者供图。
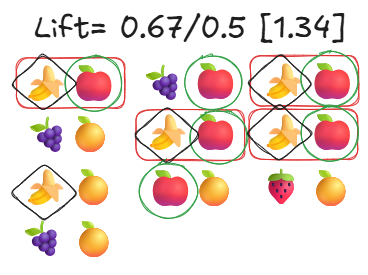
提升度(Lift): 最关键的指标。它告诉我们,如果顾客已经购买了苹果,那么他们购买香蕉的可能性,与他们单独购买香蕉的普遍可能性相比,高出多少。它有助于将真正的关联与随机机会区分开来。
- 置信度(如上所示): 0.67
- 香蕉的支持度(我们的第二个商品): 10 笔交易中有 5 笔,所以是 0.5
- 计算: 置信度 / 第二个商品的支持度
- 提升度: [0.67 / 0.5 = 1.34]
- 提升度 > 1: 比偶然情况更有可能一起购买
- 提升度 = 1: 没有真正的关联。
- 提升度 < 1: 一起购买的可能性较小。它们甚至可能是替代品(例如购买橙子而不是苹果)。
现在,让我们转向算法。
2 Apriori 算法
为了找到这些关联,数据科学家通常会使用 Apriori 算法。这种经典算法旨在高效地发现数据集中的频繁项集。
它的工作原理很巧妙:
- 首先,它找出所有满足特定流行度阈值(最小支持度)的单个商品。
- 然后,在此基础上寻找商品对,接着是商品三元组,依此类推。
- 在此过程中,它会剪除任何不符合阈值的组合。这使得整个过程比检查每一个可能的商品组合要快得多。
3 代码 mlxtend
让我们通过一个简单的 Python 示例来实际操作。
我编写了一个使用 mlxtend 库的小型 Python 脚本。在运行之前,如果你尚未安装该库,需要先安装它:pip install mlxtend。
该脚本将逐步引导你完成从数据准备到规则生成和过滤的整个过程。
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
from mlxtend.preprocessing import TransactionEncoder
首先,我们创建一些示例交易数据。这表示一个客户交易列表,其中每个内部列表包含一次交易中购买的商品。
transactions = [ ['milk', 'bread', 'butter'], ['beer', 'diapers', 'chips'], ['milk', 'bread', 'eggs'], ['beer', 'chips'], ['milk', 'diapers'], ['bread', 'butter', 'coffee'], ['beer', 'diapers', 'milk'], ['milk', 'bread', 'butter', 'coffee'], ['beer', 'chips', 'coffee', 'cookies'], ['milk', 'diapers', 'bread'], ['milk', 'bread', 'butter', 'coffee'], ['beer', 'chips', 'coffee', 'cookies'], ['milk', 'diapers', 'bread'], ['cookies'], ['coffee', 'cookies'], ['beer','coffee', 'cookies'] ]
接下来,我们必须转换数据,例如进行独热编码。Apriori 算法需要一个独热编码的 DataFrame。这意味着每个商品都成为一个列,并且“True”或“1”表示它在交易中存在。
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
df = pd.DataFrame(te_ary, columns=te.columns_)

现在数据已转换,我们可以使用 Apriori 算法找到频繁项集。我们设置 min_support=0.25 的阈值。这意味着一个项集必须出现在至少 25% 的所有交易中才被视为“频繁”。
frequent_itemsets = apriori(df, min_support=0.25, use_colnames=True)
最后,让我们生成关联规则。我们将从频繁项集中找到规则,使用 metric='confidence' 并设置一个最小置信度阈值。这意味着一个规则必须具有一定的真实可能性。
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.8)
计算完成后,我们可以过滤并显示规则。提升度 > 1 表示商品之间存在正相关关系。
print("All Generated Association Rules:")
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])
提升度越高,关联性越强。
All Generated Association Rules: antecedents consequents support confidence lift
0 (chips) (beer) 0.250 1.000000 2.666667
1 (butter) (bread) 0.250 1.000000 2.285714
2 (bread) (milk) 0.375 0.857143 1.714286
3 (cookies) (coffee) 0.250 0.800000 1.828571
4 (diapers) (milk) 0.250 0.800000 1.600000
例如,让我们通过过滤提升度 > 2 来检查最高的关联规则。
print("\nStrong Rules (Lift > 1.2):")
strong_rules = rules[rules['lift'] > 2]
print(strong_rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])
Strong Rules (Lift > 2): antecedents consequents support confidence lift
0 (chips) (beer) 0.25 1.0 2.666667
1 (butter) (bread) 0.25 1.0 2.285714
4 实际影响
那么,除了经典的“啤酒和尿布”故事,你还能用这些洞察力做些什么呢?
- 零售业: 你可以通过将互补产品放置在一起优化商店布局。你还可以创建有效的捆绑产品和促销活动。例如,如果你的分析显示“牛奶”和“麦片”之间存在很强的关联,你可能会向刚将牛奶加入购物车的顾客提供麦片折扣。
- 电子商务: 这是市场篮子分析最常见的应用形式。亚马逊和 Netflix 上的所有推荐引擎?它们都由理解哪些商品或电影经常一起被消费的算法提供支持。
- 其他行业: 市场篮子分析不仅仅适用于零售业。银行可以利用它来识别可能预示欺诈活动的共同发生交易。医疗保健提供者可以分析患者数据,以发现症状和疾病之间的关联。
5 结论
市场篮子分析是一个很好的例子,说明数据科学如何将原始数据转化为可操作的商业智能。
通过了解产品之间的关系,你可以从猜测客户需求转变为确切地了解客户需求。这有助于你创建更相关的产品,改善客户体验,并最终推动更多收入。
想了解更多吗?请在此处查看 mlxtend 库的文档:https://rasbt.github.io/mlxtend/user_guide/frequent_patterns/apriori/。
祝你在数据中发现隐藏的模式!