多线程案例、线程池
目录
1、多线程案例
1.1、单例模式
1.2、阻塞队列
生产者消费者模型
标准库中的阻塞队列
模拟实现阻塞队列
2、线程池
2.1、ThreadPoolExecutor
工厂模式
拒绝策略
1、多线程案例
1.1、单例模式
上节说过了,这里简单回顾一下
单例模式强制要求,某个类在某个程序中,只有唯一一个实例,这里的一个实例指的是,一个进程中,只能包含唯一的实例对象
两种主要的实现方式:
1)饿汉模式(早)
2)懒汉模式(迟,效率更高)
这两种实现方式的核心操作是,都是用一个静态成员变量记录当前对象的引用,区别是饿汉模式是在类加载的时候创建,懒汉模式是在第一次调用 getInstance 方法的时候创建
关键要点:都是将构造方法设为 private
1.2、阻塞队列
阻塞队列是一种特殊的队列,也遵守 “先进先出” 的原则,是一种线程安全的数据结构
具有以下特性:
1. 当队列满的时候,继续入队列就会阻塞,直到有其他线程从队列中取走元素
2. 当队列空的时候,继续出队列也会阻塞,直到有其他线程往队列中插入元素
阻塞队列的一个典型应用场景就是 “生产者消费者模型”,是一种非常典型的开发模型
生产者消费者模型
生产者消费者模型:
在实际的开发中,经常会碰到如下场景:某个模块负责生产数据,这些数据由另一个模块来负责处理。产生数据的模块就形象的称为生产者,而处理数据的模块就称为消费者。只有生产者和消费者还不够,这个模型还必须要有一个缓冲区处于生产者和消费者之间,作为中介,生产者把数据放入缓冲区,而消费者从缓冲区中取出数据。这个缓冲区就是阻塞队列。
^
举个例子:
过年一家人一起包饺子,一般都是有明确分工,比如一个人负责擀饺子皮,其他人负责包。擀饺子皮的人就是 “生产者”,包饺子的人就是 “消费者",擀饺子皮的人不关心包饺子的人是谁(能包就行,无论是手工包,借助工具,还是机器包),包饺子的人也不关心擀饺子皮的人是谁(有饺子皮就行,无论是用擀面杖擀的,还是直接从超市买的)。擀好的饺子皮放到一个容器中,包饺子的就从这个容器中取饺子皮,这个容器就是生产消费的交易场所,这个交易场所,就是一个阻塞队列
生产者消费者模型的两个重要优势:
1. 解耦合(不一定是两个线程之间,也可以是两个服务器之间)
假设生产者和消费者是两个类,如果让生产者直接调用消费者的某个函数,那么生产者和消费者之间就会产生依赖(耦合)。反之如果消费者的代码发生变化,也可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合性也就降低了。
例如:两个服务器
如果是让 A 直接访问 B,此时 A 和 B 的耦合就更高。编写A的代码的时候,多多少少会有一些和B相关的逻辑,编写 B 的代码的时候,也会有一些 A 的相关逻辑,修改A 或 B 的代码,另一个的代码也要修改
^
使用生产者消费者模型,在两个服务器之间加入一个阻塞队列(很重要,甚至会把队列单独部署成一个服务,这种独立的服务的阻塞队列,称为 “消息队列”)
让 A 和队列交互,B 也和队列交互,A 和 B 不再直接交互了,A 的代码中就看不见 B了,B的代码中也看不见 A 了,A 和 B 的代码中只能看到队列。所以修改 A 或 B 的代码,另一个的代码不需要修改了,而队列一般不会修改,这样就达到了解耦合的目的
把阻塞队列单独包装成服务器程序,并且使用单独的机器(集群)来部署,这样的队列称为“消息队列”(MQ)
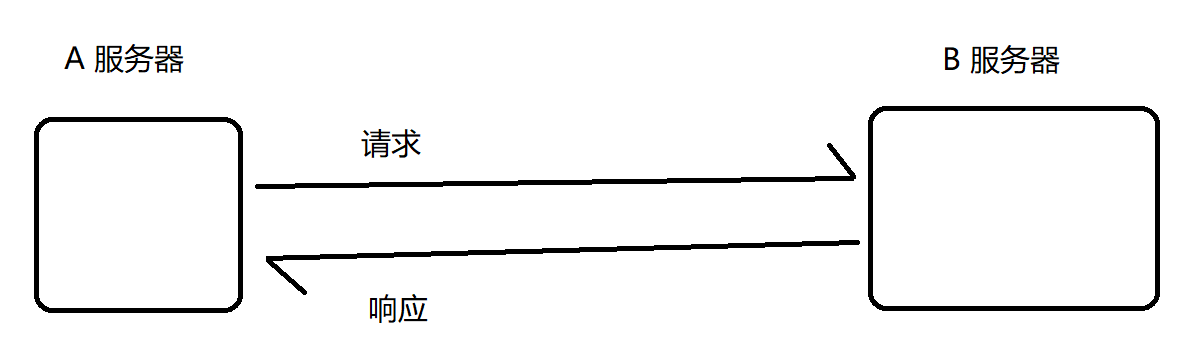
2. 削峰填谷(阻塞队列相当于一个缓冲区,平衡了生产者和消费者的处理能力)
服务器收到的请求量的曲线图:(峰:最高的;谷:最低点)
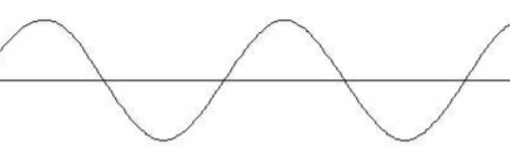
例如:大学抢课
只有在选课期间,服务器收到的请求量会达到高峰,其他时间都属于低谷。经历过选课的同学都知道,每次选课网站服务器都会挂,为什么会挂呢?
服务器处理每个请求时,是需要消耗一定的硬件资源的,包括不限于CPU,内存,硬盘,网络带宽等。如果同时有N个请求,消耗的量 * N,一旦消耗的总量,超出了机器硬件资源的上限,此时,对应的进程就可能会崩溃或者操作系统产生卡顿,这种情况就是平时说的挂了
A 这边遇到一波流量激增,此时每个请求都会转发给B,B也会承担一样的压力,很容易,就把 B 搞挂了。
一般来说 A 这种上游的服务器,尤其是入口的服务器,干的活更简单,单个请求消耗的资源数少,像B这种下游的服务器,通常承担更重的任务量(复杂的计算/存储工作),单个请求消耗的资源数更多。日常工作中,会给 B 这样角色的服务器分配更好的机器,但即使如此,也很难保证 B 承担的访问量能够比 A 更高
^
使用生产者消费者模型,在两个服务器之间加入一个阻塞队列,这个队列服务器,针对单个请求,做的事情很少(存储,转发),所以队列服务器往往是可以扛很高的请求量,原本 B 的压力转移到队列中了。
B 这边不关心队列中的数据量多少,按照自己的节奏,慢慢处理队列中的请求数据。因此即使遇到突发的流量峰值,也不会让 B 轻易就挂了。突发的峰值时间也会短,趁着峰值过去了,B 利用波谷的时间,赶紧消费之前积压的数据,这就是削峰填谷
生产者消费者模型付出的代价
1)引入阻塞队列之后,服务器的集群结构更复杂。需要部署更多的机器,维护的成本更高
2)性能会有影响。原本是两个服务器之间直接交互,变成了通过阻塞队列间接交互,效率会受到影响
标准库中的阻塞队列
在Java标准库中内置了阻塞队列(BlockingQueue)。如果我们需要在一些程序中使用阻塞队列,直接使用标准库中的即可
注:
1. BlockingQueue是一个接口,真正实现的类是LinkedBlockingQueue
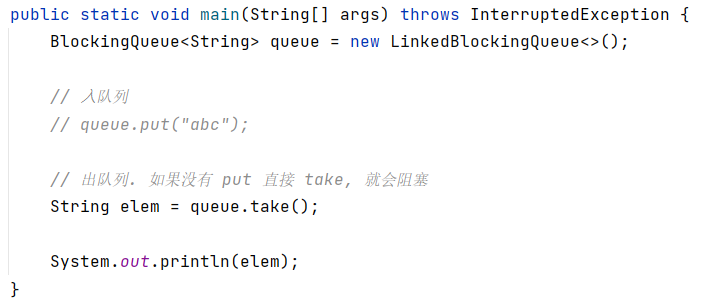
2. put 方法用于阻塞式的入队列,take用于阻塞式的出队列,使用时需要处理异常
3. BlockingQueue 也有offer,poll,peek等方法,但是这些方法不带有阻塞特性
4. 标准库中的阻塞队列,没有提供 “阻塞的获取队首元素” 的操作(对应普通队列的 peek 方法)
上面代码如果是普通队列会报异常,这里的执行结果是阻塞等待
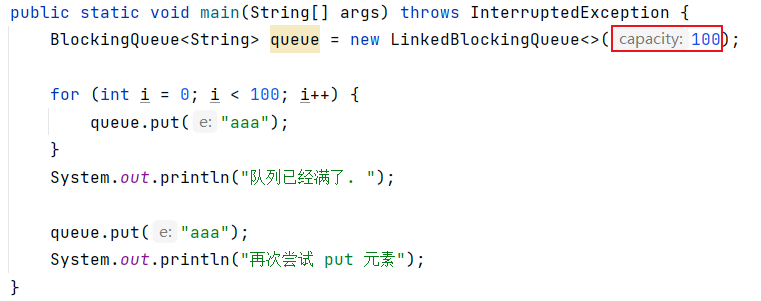
对阻塞队列添加容量参数(如果不设置,默认是一个非常大的数值)
实际开发中,一般建议设置需要的最大值,否则队列可能变的非常大,导致把内存耗尽,产生内存超出范围这样的异常
生产者消费者模型代码实现:
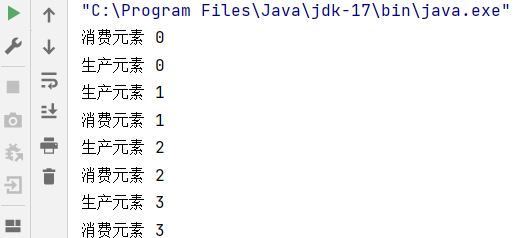
public class Demo30 {public static void main(String[] args) {// 至少生产者一个线程, 消费者一个线程.BlockingQueue<Integer> queue = new LinkedBlockingQueue<>();Thread producer = new Thread(() -> {int n = 0;while (true) {try {queue.put(n);System.out.println("生产元素 " + n);n++;} catch (InterruptedException e) {throw new RuntimeException(e);}}}, "producer");Thread consumer = new Thread(() -> {while (true) {try {Integer n = queue.take();System.out.println("消费元素 " + n);} catch (InterruptedException e) {throw new RuntimeException(e);}}}, "consumer");producer.start();consumer.start();}
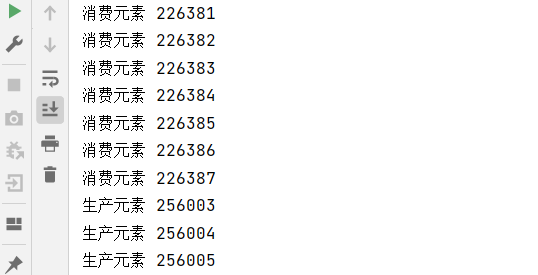
}直接运行,生产者和消费者两个线程的速度,二者的速度旗鼓相当,所以很难见到阻塞效果
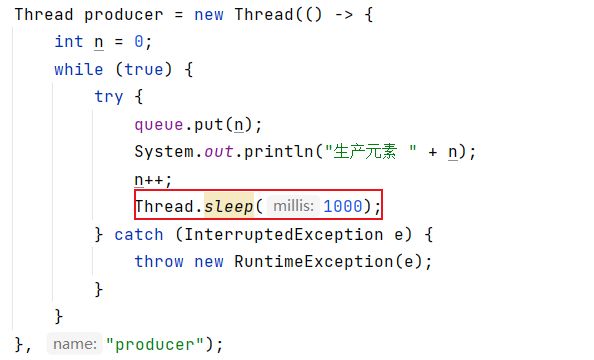
在生产者中加 sleep,消费就会因为生产的速度产生阻塞
小知识:
如何快速计算 字节 -> XB,例如 80 亿字节,是多少 GB
记住几个单词:
Thousand 千 对应 KB
Million 百万 对应 MB
Billion 十亿 对应 GB所以 80 亿字节,是 8 GB
模拟实现阻塞队列
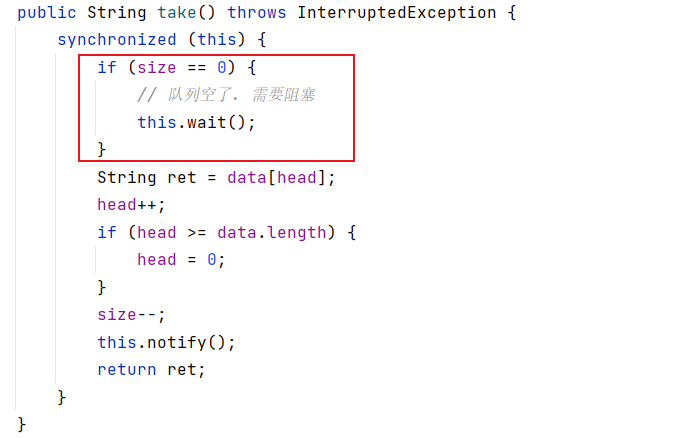
class MyBlockingQueue {// 不使用泛型,指定元素类型 Stringprivate String[] data = null;// 队首private int head = 0;// 队尾private int tail = 0;// 元素个数private int size = 0;public MyBlockingQueue(int capacity) {data = new String[capacity];}public void put(String elem) throws InterruptedException {synchronized (this) {while (size >= data.length) {// 队列满了. 需要阻塞this.wait();}data[tail] = elem;tail++;if (tail >= data.length) {tail = 0;}// 不建议这么写,因为不易理解且效率比上面这种方法低// tail = (tail + 1) % data.length;size++;this.notify();}}public String take() throws InterruptedException {synchronized (this) {while (size == 0) {// 队列空了. 需要阻塞this.wait();}String ret = data[head];head++;if (head >= data.length) {head = 0;}size--;this.notify();return ret;}}
}public class Demo31 {public static void main(String[] args) {// 基于模拟实现的阻塞队列的生产者消费者模型MyBlockingQueue queue = new MyBlockingQueue(1000);Thread producer = new Thread(() -> {int n = 0;while (true) {try {queue.put(n + "");System.out.println("生产元素 " + n);n++;} catch (InterruptedException e) {throw new RuntimeException(e);}}});Thread consumer = new Thread(() -> {while (true) {String n = null;try {n = queue.take();System.out.println("消费元素 " + n);Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}});producer.start();consumer.start();}
}说明:
1. 队列满的时候入队,需要阻塞到其他线程执行成功 take 的时候(队列不满了),所以在 take 方法中调用 notify
2. 队列为空的时候出队,需要阻塞到其他线程执行成功 put 的时候(队列不为空),所以在 put 方法中调用 notify
3. 若干线程使用这个队列,要么所有的线程阻塞在 put,要么所有的线程阻塞在 take,不可能有一些线程阻塞在 put,一些阻塞在 take,因为队列不可能既是满又是空
4. wait 是用来确保接下来的操作是有意义的,后续的操作要确保 size 不能为 0。正常情况下wait 的唤醒是通过另一个线程执行 put,put 成功了 size 肯定不是0,但 wait 不只能被 notify 唤醒,还可能被 Interrupt 中断,如果使用 if 作为 wait 的判定条件,就存在 wait 被提前唤醒的风险,把 if 改成 while 就可以解决这个问题
5. 循环的目的是为了 “二次验证”,wait 之前先判定一次,wait 唤醒也判定一次(再确认一下,队列是否不空)
6. 多个线程 take,多个线程 put 可能会有自己唤醒自己的风险,while 也可以解决这个问题。例如,3 个线程 put(1 2 3)都因为队列满阻塞了,第四个线程,take 了一下,唤醒上述的线程 1,线程 1 继续往下执行触发 notify,此时的 notify 是可能会唤醒刚才 2 3 线程的 put 的阻塞的,此时即使 wait 被唤醒,还会再次判定条件,再次进行阻塞
7. wait 一般都是搭配 while 使用

总结:
1. 通过 “循环队列” 的方式来实现
2. 使用 synchronized 进行加锁控制
3. put 插入元素的时候,判定如果队列满了,就进行 wait(注意,要在循环中进行wait,被唤醒时不一定队列就不满了,因为 wait 不只能被 notify 唤醒,还可能被 Interrupt 中断)
4. take取出元素的时候,判定如果队列为空,就进行wait(也是循环 wait)
2、线程池
线程池是由一组线程组成的线程队列,它们在程序启动时就被创建并一直存在。这些线程可被用来执行提交到线程池的各种任务,从而避免为每个任务都创建新线程。这种机制能够降低线程创建和销毁的开销,提高系统性能。Java的线程池,里面包含几个线程,是可以动态调整的。任务多的时候,自动扩容成更多的线程;任务少的时候,把额外的线程销毁,节省资源
最初引入线程的原因:频繁创建销毁进程,太慢了
随着互联网的发展,我们对于性能要求更进一步,现在觉得频繁创建销毁线程的开销也有些不能接受了,解决方案有两个:
1. 线程池
2. 协程(又叫 纤程 或 轻量级线程,Java 17左右才开始引入到标准库中,目前在 Java 圈子里还没有普遍使用)
为什么直接创建线程开销比从池子里取更大呢?
先从操作系统说起,一个操作系统 = 内核 + 配套的应用程序,
其中内核包含操作系统的各种核心功能
1)管理硬件设备
2)给软件提供稳定的运行环境
内核,要给所有的应用程序提供服务支持。如果有一段代码,需要进入到内核中,由内核负责完成一系列工作,这个过程不可控的,程序员写的代码干预不了;如果是应用程序中自行完成的,整个执行过程是可控的。通常认为,可控的过程要比不可控的过程更高效。
^
从线程池取现成的线程,纯应用程序代码就可以完成 [可控]
从操作系统创建新线程,需要操作系统内核配合完成 [不可控]
使用线程池,就可以省下应用程序切换到内核中运行的开销
2.1、ThreadPoolExecutor
Java 标准库也提供了直接使用的线程池(ThreadPoolExecutor:线程池执行器)
核心方法:submit(Runnable)
通过 Runnable 描述一段要执行的任务,通过 submit 把任务放到线程池中,线程池里的线程就会执行这个任务
ThreadPoolExecutor提供了四个构造方法:

以最后一个构造方法(参数最多的那个),对其参数进行解释:
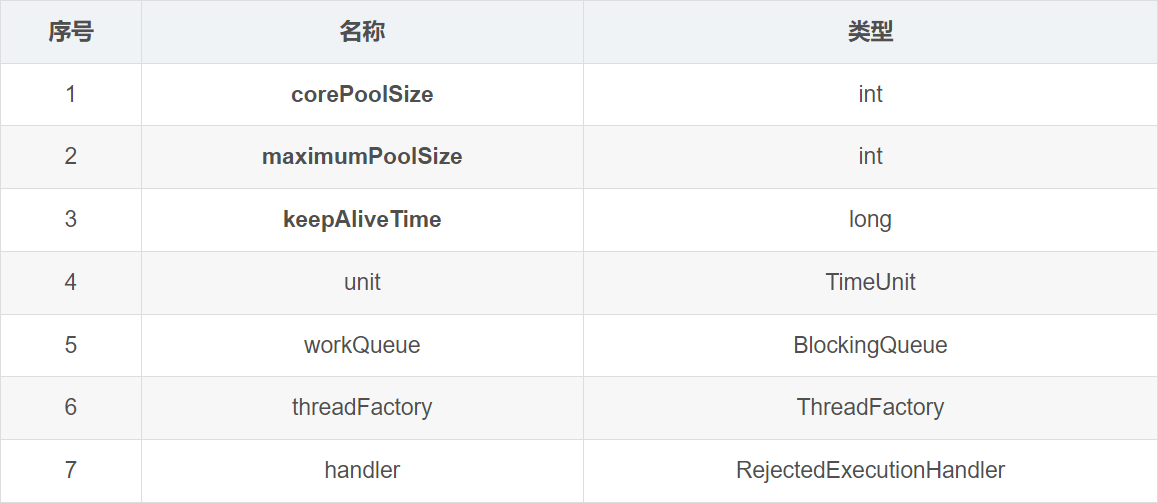
corePoolSize:核心线程数(至少有多少个线程)
线程池一创建,这些线程也要随之创建,直到整个线程池销毁,这些线程才会销毁
maximumPoolSize:最大线程数
核心线程 + 非核心线程(自适应,不繁忙就销毁,繁忙就再创建)
keepAliveTime:非核心线程允许空闲的最大时间
unit:枚举,keepAliveTime 的时间单位,包含常用的时间单位(秒、毫秒、微秒等)
workQueue:工作队列(传递任务的阻塞队列)
线程池,本质上也是生产者消费者模型,调用 submit 就是在生产任务线程池里的线程就是在消费任务,生产和消费之间需要一个阻塞队列。这个队列可以选择使用数组或链表、指定 capacity、指定是否要带有优先级 / 比较规则。
threadFactory:线程池中生成线程的工厂(是个接口,可以通过实现它提供的 newThread 方法完成创建线程的相关工作)
使用工厂模式,通过实现 threadFactory,统一的构造并初始化线程
handler:拒绝策略,当任务提交被拒绝时(工作队列满 并且 当前工作的线程数等于最大线程数)执行的处理逻辑。
submit 把任务添加到任务队列中,而任务队列是阻塞队列,队列满了再添加会阻塞。一般不希望程序阻塞太多,所以在线程池中,发现入队列操作时,队列满了,不会真的触发 “入队列操作”,不会真阻塞,而是执行拒绝策略相关的代码
工厂模式
也是一种设计模式,和单例模式是并列的关系,是用来弥补构造方法的缺陷的
有些情况下,需要几个参数列表相同的构造方法,但构造方法的名字是固定的,无法构成重载
例如:构造一个平面上的点

使用工厂模式就可以解决这个问题:
// 平面上的一个点
class Point {}class PointFactory {public static Point makePointByXY(double x, double y) {Point p = new Point();// 通过 x 和 y 给 p 进行属性设置return p;}public static Point makePointByRA(double r, double a) {Point p = new Point();// 通过 r 和 a 给 p 进行属性设置return p;}
}public class Demo33 {public static void main(String[] args) {Point p = PointFactory.makePointByXY(10, 20);}
}1. 用于构造对象的静态方法叫做工厂方法(makePointByXY、makePointByRA)。
2. 工厂方法的核心,就是通过静态方法,把构造对象 new 的过程和各种属性初始化的过程,封装起来。
3. 提供多组静态方法,就可以实现不同情况的构造了。
4. 提供工厂方法的类,就可以称为 “工厂类”(PointFactory)
拒绝策略
Java线程池提供了四种常见的拒绝策略:
1.ThreadPoolExecutor.AbortPolicy(默认策略):线程池直接抛出异常(线程池可能无法继续工作)
2.ThreadPoolExecutor.CallerRunsPolicy:让调用submit的线程自行执行任务
3. ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列中最老的任务
4. ThreadPoolExecutor.DiscardPolicy:丢弃最新的任务(当前submit的这个任务)
2.2、Executors
Java 标准库,也提供了另一组类,针对 ThreadPoolExecutor 进行了进一步封装,简化线程池的使用。也基于工厂设计模式
Executors 创建线程池的几种方式:
Executors.newFixedThreadPool(nThreads):创建固定线程数目的线程池(核心线程数和最大线程数一样)
Executors.newCachedThreadPool():创建线程数目动态增长的线程池(线程可以无限增加)
Executors.newSingleThreadExecutor:创建只包含单个线程的线程池
Executors.newScheduledThreadPool:设定延迟时间后执行命令,或者定期执行命令.是进阶版的Timer
1. 使用 Executors.newFixedThreadPool(10)能创建出固定包含10个线程的线程
2. 池返回值类型为 ExecutorService
3. 通过 submit 可以注册一个任务到线程池中

public class Demo34 {public static void main(String[] args) {// ExecutorService threadPool = Executors.newFixedThreadPool(4);ExecutorService threadPool = Executors.newCachedThreadPool();for (int i = 0; i < 1000; i++) {int id = i;threadPool.submit(() -> {System.out.println("hello " + id + ", " + Thread.currentThread().getName());});}// shutdown 能够把线程池里的线程全部关闭,但是不能保证线程池内的任务一定能全部执行完毕。// 所以,如果需要等待线程池内的任务全部执行完毕,需要调用 awaitTermination 方法。threadPool.shutdown();}
}阿里巴巴Java编程规范手册中明确说:使用线程池,要用ThreadPoolExecutor 这个版本,不要使用 Executors。理由是:使用 Executors 线程数目 / 拒绝策略等信息都是隐式的,可能不好控制(创建200多个线程,确实不是一件好事)