轻量化注意力+脉冲机制,Transformer在低功耗AI中再度进化
关注gongzhonghao【CVPR顶会精选】
Transformer还能卷出新花样吗?回想一下2017年那篇经典论文,从NLP到CV一路狂飙,如今引用早已破十万,几乎成了深度学习的代名词。可别以为它已经饱和了——最近不少SOTA依旧是以Transformer为核心骨架展开的。
其在效率优化、长序列建模、跨模态融合等方向仍然存在大量潜力,很多问题还远没被真正解决。围绕Transformer“再造一遍”,依旧是很有含金量的研究路线。今天小图给大家精选3篇CVPR有关transformer方向的论文,请注意查收!
论文一:Progressive Focused Transformer for Single Image Super-Resolution
方法:
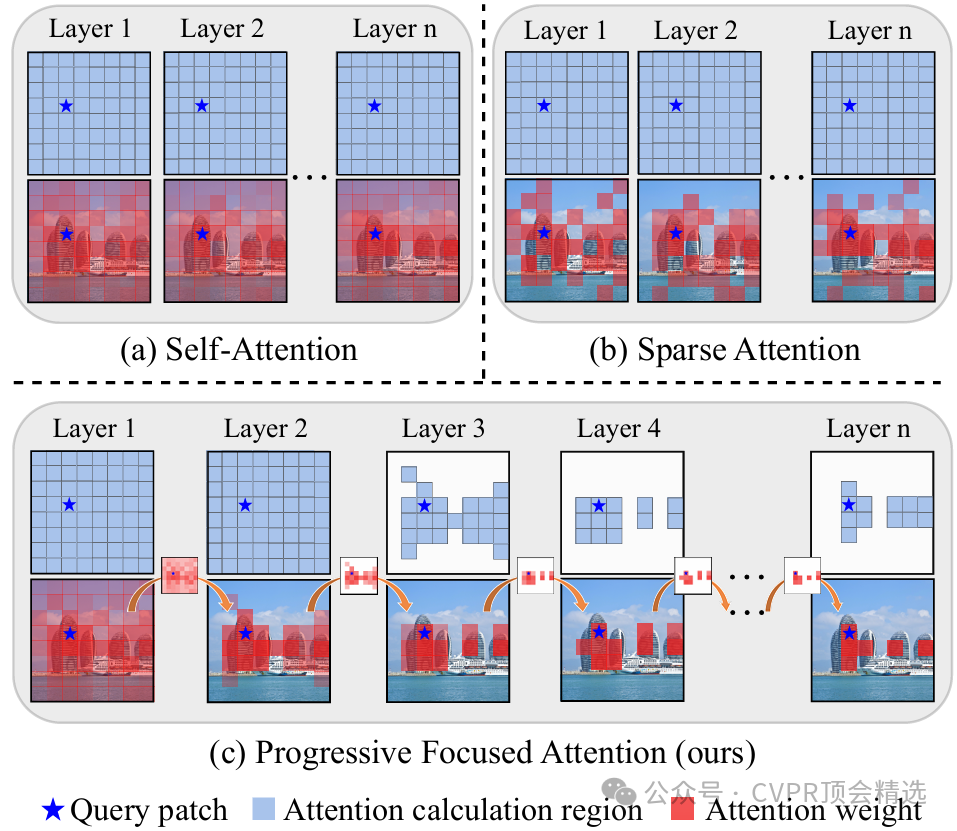
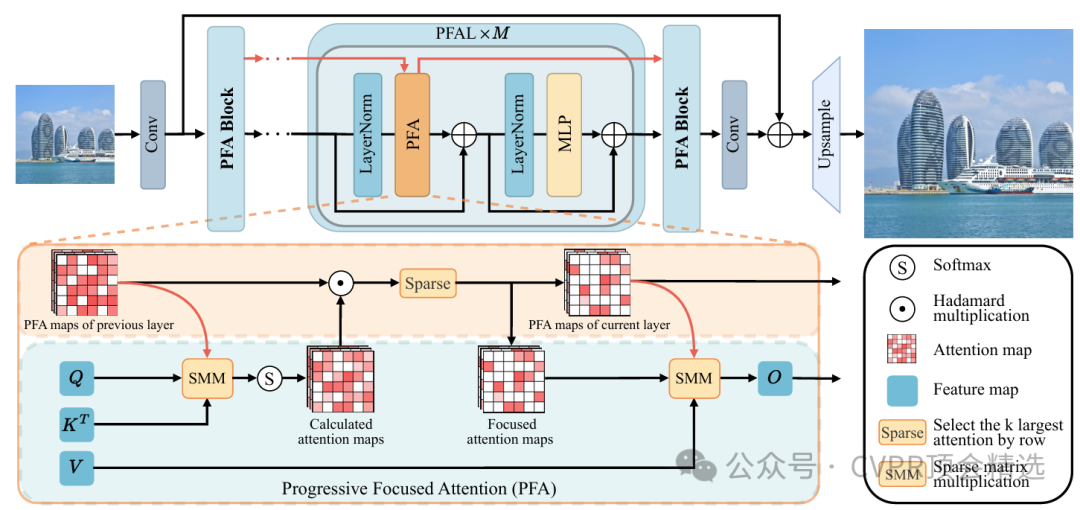
文章首先利用多阶段的特征提取结构,逐步聚焦并放大输入图像中的高频和关键区域,在每一阶段自适应调整注意力分布以捕捉细粒度信息。随后,作者引入动态聚焦模块,对图像内容复杂度进行评估,并针对性分配计算资源,极大提高了模型推理的性价比。最后,通过端到端训练,模型在保持较低计算成本的情况下,实现了对图像超分辨率任务的优异表现,有效提升了细节还原能力。
创新点:
提出渐进聚焦Transformer架构,实现对关键特征的逐步挖掘和高效利用。
设计了一种动态特征关注模块,自适应地分配计算资源到图像的细节丰富区域。
通过多层次处理策略,有效平衡了模型性能与实际推理效率。
论文链接:
https://arxiv.org/abs/2503.20337
图灵学术科研辅导
论文一:Decision SpikeFormer: Spike-Driven Transformer for Decision Making.
方法:
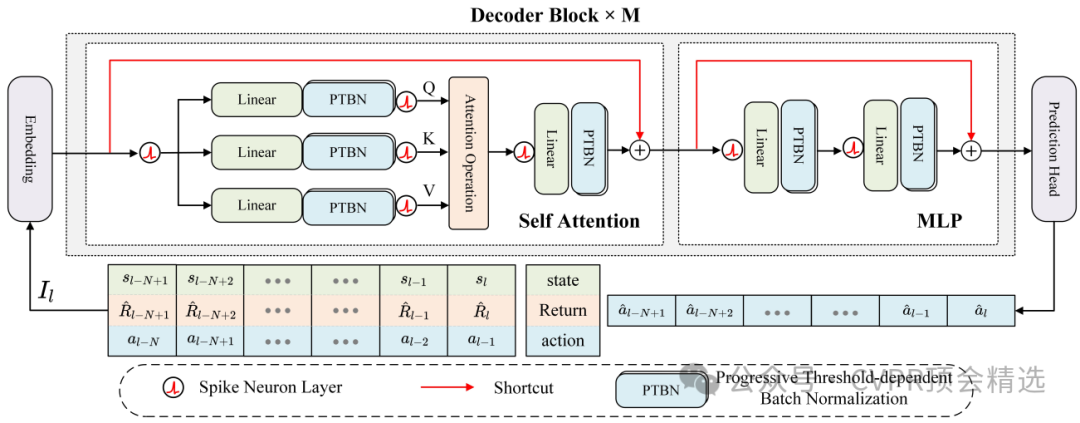
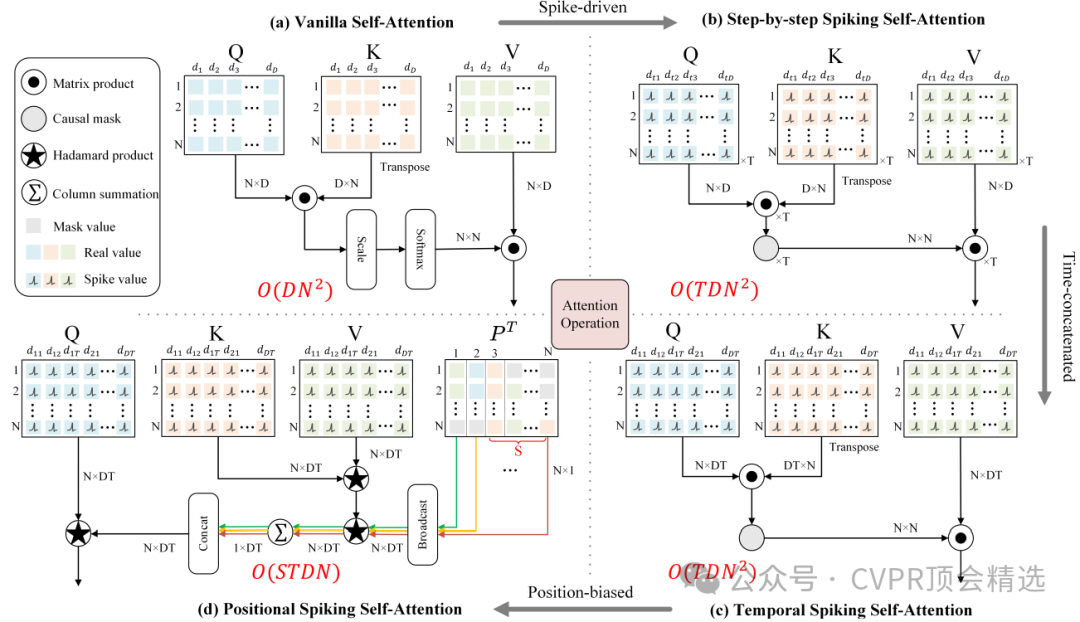
文章首先以脉冲神经元为核心单元重构Transformer,每层通过稀疏脉冲信号传递信息,有效降低能耗并提升推理响应速度。模型设计上同时结合时序自注意力,捕获决策过程中的历史依赖关系,以及位置自注意力,增强对状态空间结构的理解和利用。实验部分通过离线强化学习任务全面评测,DSFormer不仅实现了更高的决策准确率,还显著减少了计算资源消耗,展示了在实际智能体决策场景下的广阔应用前景。
创新点:
引入Spike-Driven机制,将生物启发的脉冲神经元特性融入Transformer结构,实现低能耗推理。
融合时序自注意力与位置自注意力,有效捕捉决策过程中的动态与结构信息。
在离线强化学习场景下,系统性地评估并验证模型在效率、性能和能耗上的综合优势。
论文链接:
https://arxiv.org/html/2504.03800v1
图灵学术科研辅导
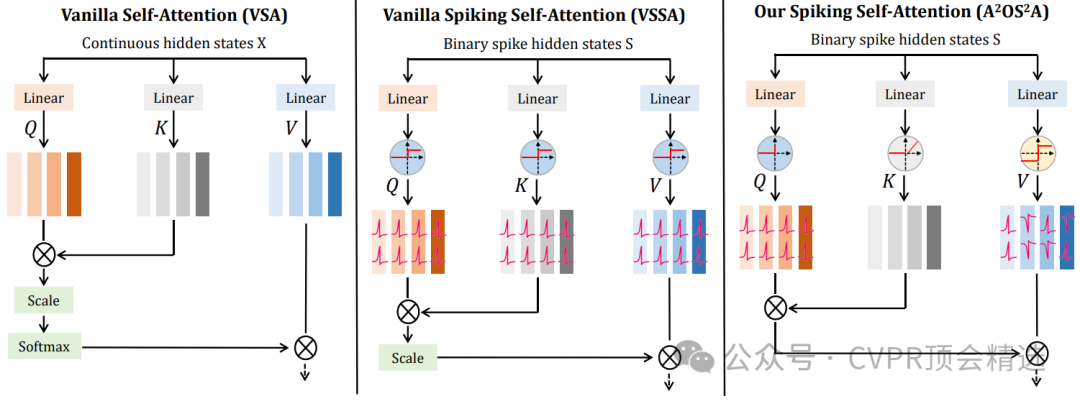
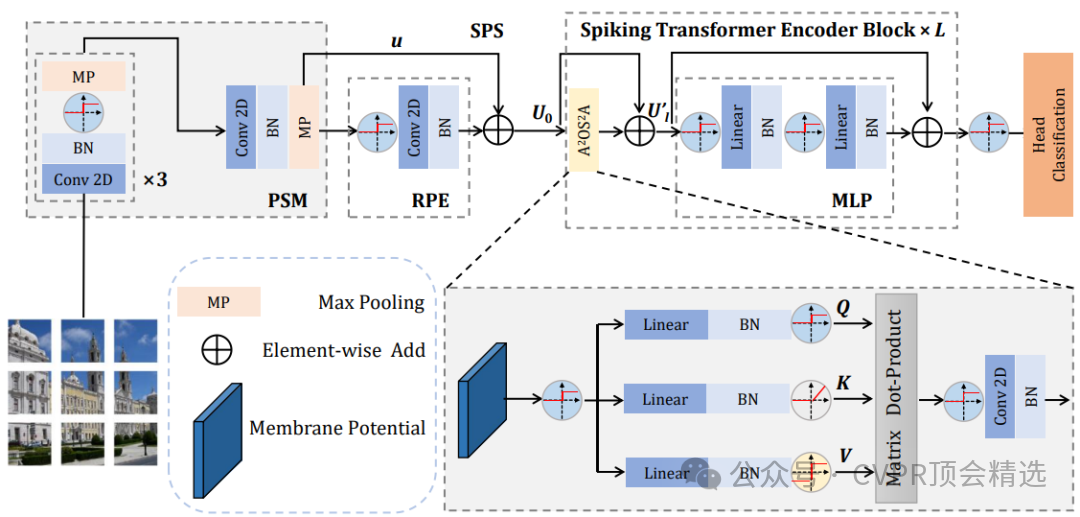
论文二:Spiking Transformer: Introducing Accurate Addition-Only Spiking Self-Attention for Transformer
方法:
文章首先设计了一套全加法型的脉冲自注意力机制,通过稀疏脉冲信号实现高效信息交互,大幅降低了计算资源消耗。随后,将该机制无缝嵌入标准Transformer流程,利用SNN的事件驱动特性实现稀疏激活,提高整体运算效率。最终,在ImageNet-1K等视觉基准上进行系统评测,模型在保持极低能耗的同时取得了78.66%的高准确率,展现了脉冲Transformer在实际大规模应用中的巨大潜力。
创新点:
提出仅用加法运算实现的脉冲自注意力模块,显著提升能效,降低了硬件实现的复杂度。
创新性地将脉冲神经网络与Transformer架构深度融合,兼顾稀疏性与建模能力。
在ImageNet-1K等大规模数据集上实证,首次让脉冲Transformer达到主流视觉任务的高准确率。
论文链接:
https://arxiv.org/abs/2503.00226
本文选自gongzhonghao【CVPR顶会精选】