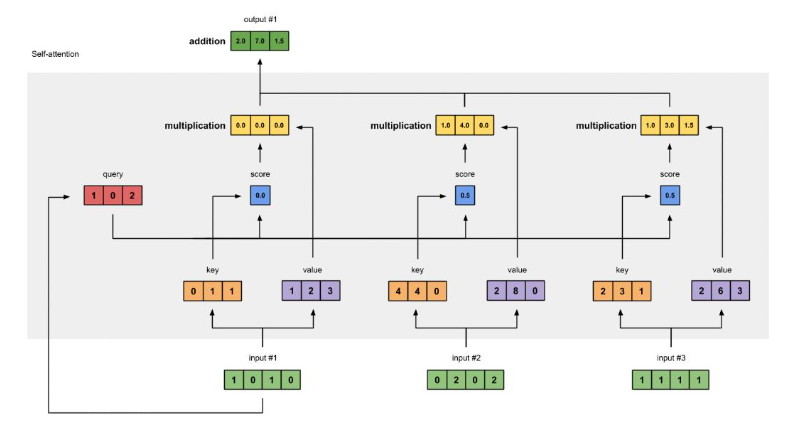
Self-Attention的实现
Self-Attention(自注意力机制)是 Transformer 模型的核心组件,它能让序列中的每个元素关注序列中其他元素的信息,从而捕捉元素间的依赖关系。下面结合代码详细说明其实现步骤:
1. 准备输入(词嵌入向量)
首先需要准备输入数据,这里输入是一个包含 3 个样本的词嵌入向量,每个样本是 4 维的向量。
import torch
x = [[1, 0, 1, 0], # Input 1[0, 2, 0, 2], # Input 2[1, 1, 1, 1] # Input 3
]
x = torch.tensor(x, dtype=torch.float32)
这一步是将原始的输入数据转换为 PyTorch 张量,作为后续计算的输入。
2. 初始化参数(Q、K、V 矩阵)
Self-Attention 机制需要三个权重矩阵:Query(Q)、Key(K)、Value(V)矩阵。这些矩阵在神经网络初始化时通常是随机采样的,并且维度可以根据需要输出的维度来确定。
w_key = [[0, 0, 1],[1, 1, 0],[0, 1, 0],[1, 1, 0]
]
w_query = [[1, 0, 1],[1, 0, 0],[0, 0, 1],[0, 1, 1]
]
w_value = [[0, 2, 0],[0, 3, 0],[1, 0, 3],[1, 1, 0]
]
w_key = torch.tensor(w_key, dtype=torch.float32)
w_query = torch.tensor(w_query, dtype=torch.float32)
w_value = torch.tensor(w_value, dtype=torch.float32)
这里定义了 Q、K、V 对应的权重矩阵,并转换为张量。输入是 4 维,Q、K 矩阵将输入转换为 3 维的向量,V 矩阵也将输入转换为 3 维的向量。
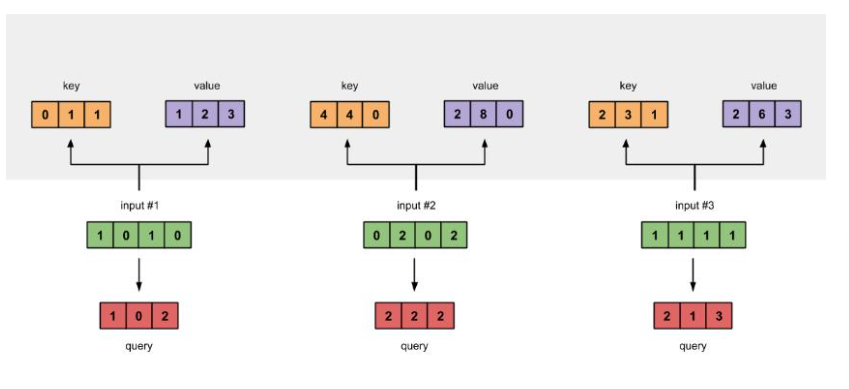
3. 获取 key,query 和 value
通过输入张量与 Q、K、V 权重矩阵进行矩阵乘法,得到 Query、Key 和 Value 向量。
keys = x @ w_key
querys = x @ w_query
values = x @ w_value
keys:每个输入样本与w_key矩阵相乘,得到每个样本的 Key 向量,用于和其他样本的 Query 向量计算注意力得分。querys:每个输入样本与w_query矩阵相乘,得到每个样本的 Query 向量,用于查询与其他样本的匹配程度。values:每个输入样本与w_value矩阵相乘,得到每个样本的 Value 向量,是最终要进行加权求和的内容。
4. 计算注意力分数
注意力分数用于衡量 Query 和 Key 之间的匹配程度,通过 Query 矩阵与 Key 矩阵的转置进行矩阵乘法得到。
attn_scores = querys @ keys.T
keys.T 是 Key 矩阵的转置,这样矩阵乘法的结果 attn_scores 中的每个元素 attn_scores[i][j] 表示第 i 个样本的 Query 与第 j 个样本的 Key 之间的注意力分数,反映了两者的关联程度。
5. 计算 softmax
对注意力分数进行 softmax 归一化,使得每个样本对其他样本的注意力分数之和为 1,这样可以将注意力分数转换为权重。
from torch.nn.functional import softmax
attn_scores_softmax = softmax(attn_scores, dim=-1)
# 为了可读性,这里近似处理后的值
attn_scores_softmax = [[0.0, 0.5, 0.5],[0.0, 1.0, 0.0],[0.0, 0.9, 0.1]
]
attn_scores_softmax = torch.tensor(attn_scores_softmax)
softmax 函数会对每行的注意力分数进行归一化,这样得到的 attn_scores_softmax 中的值就可以作为每个样本对其他样本 Value 向量的权重。这里为了后续计算方便,对 softmax 结果进行了近似处理。
6. 给 value 乘上 score 并加权求和
将每个样本的 Value 向量与对应的注意力权重相乘,然后进行加权求和,得到最终的自注意力输出。
weighted_values = values[:, None] * attn_scores_softmax.T[:, :, None]
# 然后进行求和等操作得到最终输出(代码中未完全展示求和步骤,实际需对加权后的 values 按相应维度求和)
values[:, None] 是为了扩展维度,方便与 attn_scores_softmax.T[:, :, None] 进行逐元素相乘。相乘后得到的 weighted_values 是每个样本的 Value 向量按注意力权重加权后的值,最后需要对这些加权后的 Value 向量在相应维度上进行求和,得到每个样本的自注意力输出结果。